1 flume 常见channel介绍
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件,Flume对于Channel,则提供了Memory Channel、JDBC Chanel、File Channel。
MemoryChannel可以实现高速的吞吐,但是无法保证数据的完整性。
FileChannel保证数据的完整性与一致性。
Spillable Memory Channel基于内存和磁盘,内存不够时将数据存储在磁盘中,数据出错恢复时,只恢复磁盘中的数据,还在测试阶段不建议在生产环境用。

1.1 file channel
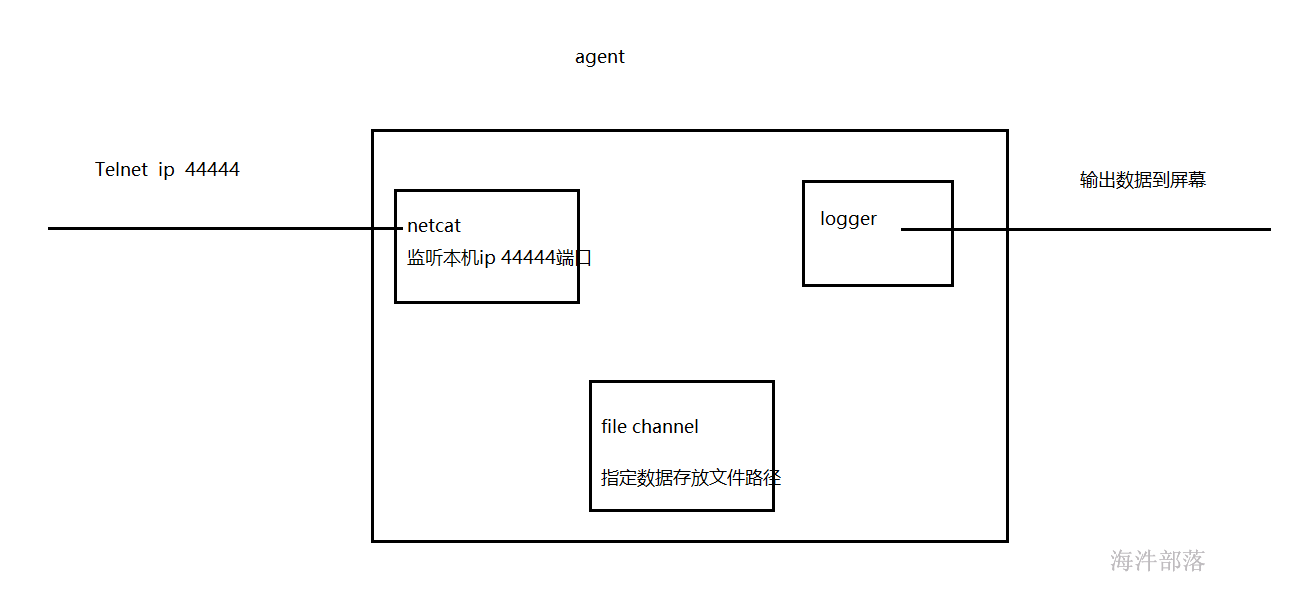
# file channel
#给agent组件起名
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#定义source
a1.sources.r1.type=netcat
a1.sources.r1.bind=11.90.214.80
a1.sources.r1.port=44444
#定义channel
a1.channels.c1.type=file
a1.channels.c1.dataDirs = /root/filedata
#定义sink
a1.sinks.k1.type=logger
#绑定
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
创建数据输出目录
mkdir -p /root/filedata启动flume agent a1 服务端
flume-ng agent -n a1 -c /usr/local/flume/conf/ -f ./fileroll.agent -Dflume.root.logger=INFO,console测试:

数据存放到文件中

控制台也有输出

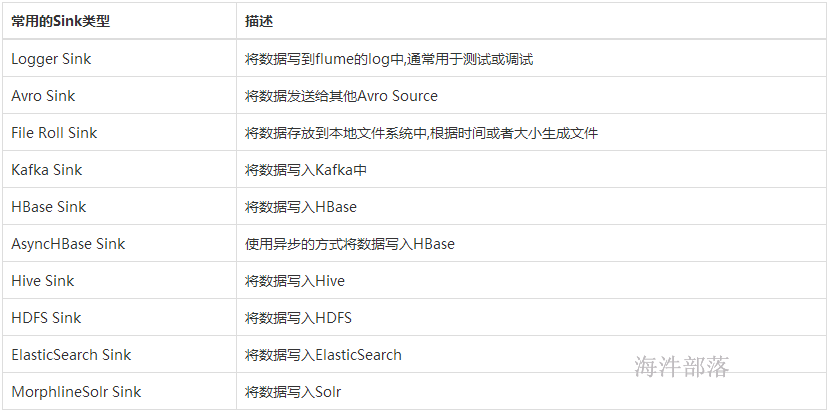
2 flume 常见Sink介绍
Flume Sink取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。Flume也提供了各种sink的实现,包括HDFS sink、Logger sink、Avro sink、File Roll sink、HBase sink,。
Flume Sink在设置存储数据时,可以向文件系统中,数据库中,hadoop中储数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据,在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
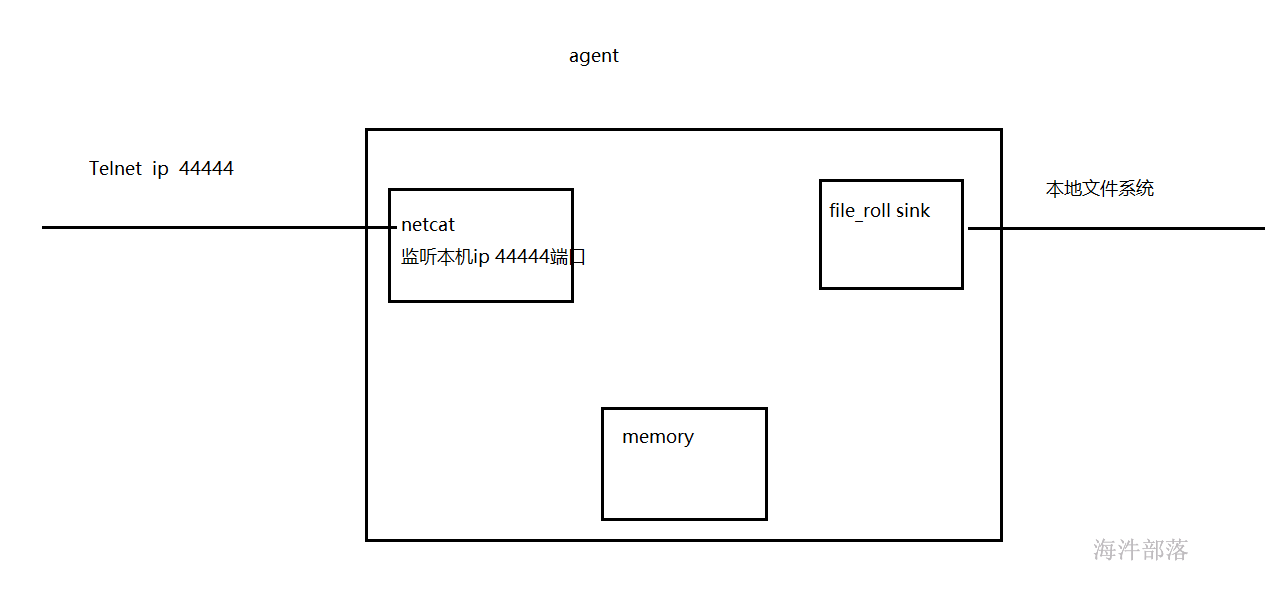
2.1 File_roll Sink
File_roll sink是将收集到的数据存放在本地文件系统中,根据指定的时间生成新的文件用来保存数据
# file_role sink
#给agent组件起名
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#定义source
a1.sources.r1.type=netcat
a1.sources.r1.bind=worker-1
a1.sources.r1.port=44444
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=file_roll
a1.sinks.k1.sink.directory=/root/file_role
a1.sinks.k1.sink.rollInterval=60
#绑定
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1创建数据输出目录
mkdir -p /root/file_role启动flume agent a1 服务端
flume-ng agent -n a1 -c /usr/local/flume/conf/ -f ./file_roll.agent -Dflume.root.logger=INFO,console测试:

2.2 hdfs sink
hdfs sink是将flume收集到的数据写入到hdfs中,方便数据可靠的保存
其中:
sink 输出到hdfs中,默认每10个event 生成一个hdfs文件,hdfs文件目录会根据hdfs.path 的配置自动创建。
sink hdfs 配置参数描述:
| 名称 | 描述 |
|---|---|
| hdfs.path | hdfs目录路径 |
| hdfs.filePrefix | 文件前缀。默认值FlumeData |
| hdfs.fileSuffix | 文件后缀 |
| hdfs.rollInterval | 多久时间后close hdfs文件。单位是秒,默认30秒。设置为0的话表示不根据时间close hdfs文件 |
| hdfs.rollSize | 文件大小超过一定值后,close文件。默认值1024,单位是字节。设置为0的话表示不基于文件大小 |
| hdfs.rollCount | 写入了多少个事件后close文件。默认值是10个。设置为0的话表示不基于事件个数 |
| hdfs.fileType | 文件格式, 有3种格式可选择:SequenceFile(默认), DataStream(不压缩) or CompressedStream(可压缩) |
| hdfs.batchSize | 批次数,HDFS Sink每次从Channel中拿的事件个数。默认值100 |
| hdfs.minBlockReplicas | HDFS每个块最小的replicas数字,不设置的话会取hadoop中的配置 |
| hdfs.maxOpenFiles | 允许最多打开的文件数,默认是5000。如果超过了这个值,越早的文件会被关闭 |
| hdfs.callTimeout | HDFS操作允许的时间,比如hdfs文件的open,write,flush,close操作。单位是毫秒,默认值是10000 |
| hdfs.codeC | 压缩编解码器。以下之一:gzip,bzip2,lzo,lzop,snappy |
# hdfs sink
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#定义source
a1.sources.r1.type=netcat
a1.sources.r1.bind=worker-1
a1.sources.r1.port=44444
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=/data/xinniu/output/%Y-%m-%d
a1.sinks.k1.hdfs.useLocalTimeStamp=true
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.filePrefix=hainiu-
a1.sinks.k1.hdfs.fileSuffix=.log
#绑定
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1测试:
由于需要将数据存储在hdfs中,所以需要hadoop的支持,重新启动镜像添加hadoop共用组件
配置flume所在服务器为hadoop客户端
将hadoop安装目录拷贝到flume所在linux服务器

scp -r hadoop-2.7.3 root@11.99.16.127:/opt/flume所在服务器配置hadoop环境变量
export HADOOP_HOME=/opt/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin启动flume agent a1 服务端
flume-ng agent -n a1 -c /usr/local/flume/conf/ -f ./hdfssink.agent -Dflume.root.logger=INFO,console测试:

查看hdfs是否有数据文件产生

查看文件内容

2.3 avro sink
将flume收集到的数据通过avro sink序列化出去,通常用于数据跨服服务多级流动。
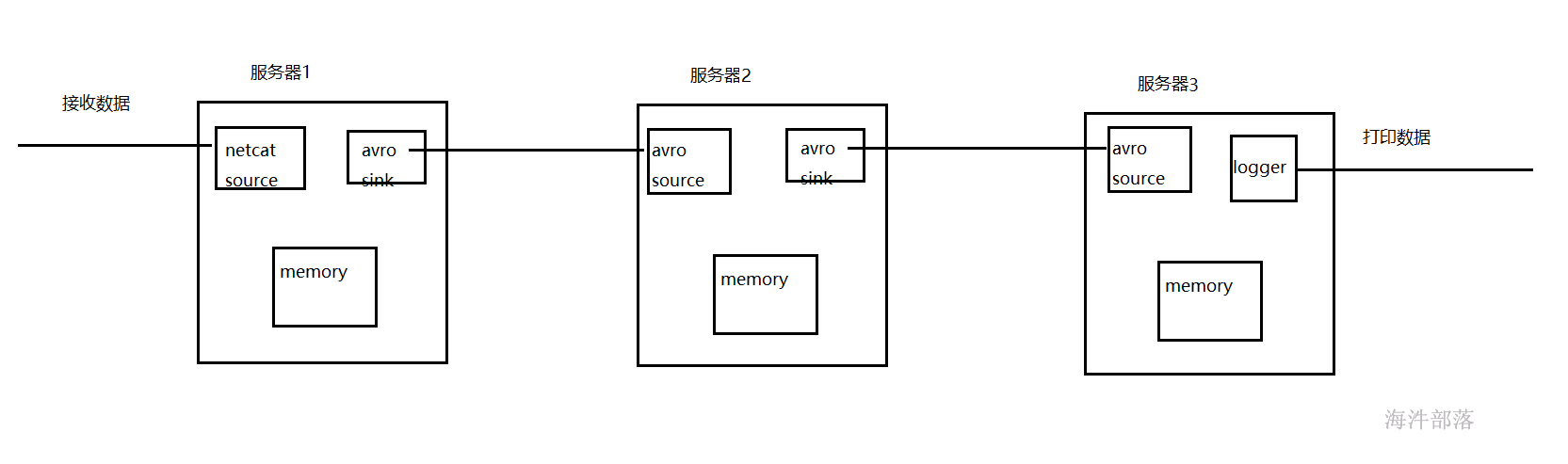
准备三台linux服务器,用于多级流动测试
在另外两台服务器上安装jdk
rpm -ivh /public/software/java/jdk-8u144-linux-x64.rpm 将flume安装目录拷贝到其他两台服务器上
scp -r apache-flume-1.10.1-bin root@linux-85098:/usr/local/并分别在另外两台服务器上创建flume安装包的软链接
ln -s apache-flume-1.10.1-bin flume将修改好的环境变量文件拷贝到另外两台服务器
scp /etc/profile root@linux-85098:/etc
#让环境变量生效
source /etc/profile在第一台节点编写agent
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=netcat
a1.sources.r1.bind=worker-1
a1.sources.r1.port=44444
a1.channels.c1.type=memory
a1.channels.c1.capacity=100000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=avro
a1.sinks.k1.hostname = 10.10.10.10
a1.sinks.k1.port = 55555
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1第二台节点编写agent
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=avro
a1.sources.r1.bind=11.94.204.87
a1.sources.r1.port=55555
a1.channels.c1.type=memory
a1.channels.c1.capacity=100000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=avro
a1.sinks.k1.hostname =11.147.251.96
a1.sinks.k1.port = 55555
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1第三台节点编写agent
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=avro
a1.sources.r1.bind=11.147.251.96
a1.sources.r1.port=55555
a1.channels.c1.type=memory
a1.channels.c1.capacity=100000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=logger
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1从后往前分别启动三台agent
flume-ng agent -n a1 -c /usr/local/flume/conf/ -f ./avro.agent -Dflume.root.logger=INFO,console测试给第一台flume发送数据,第三台节点打印数据到控制台

第三台收到数据
还可以通过avro sink 实现扇出操作:即第一台服务器收集数据,将数据发送到第二台和第三台服务器
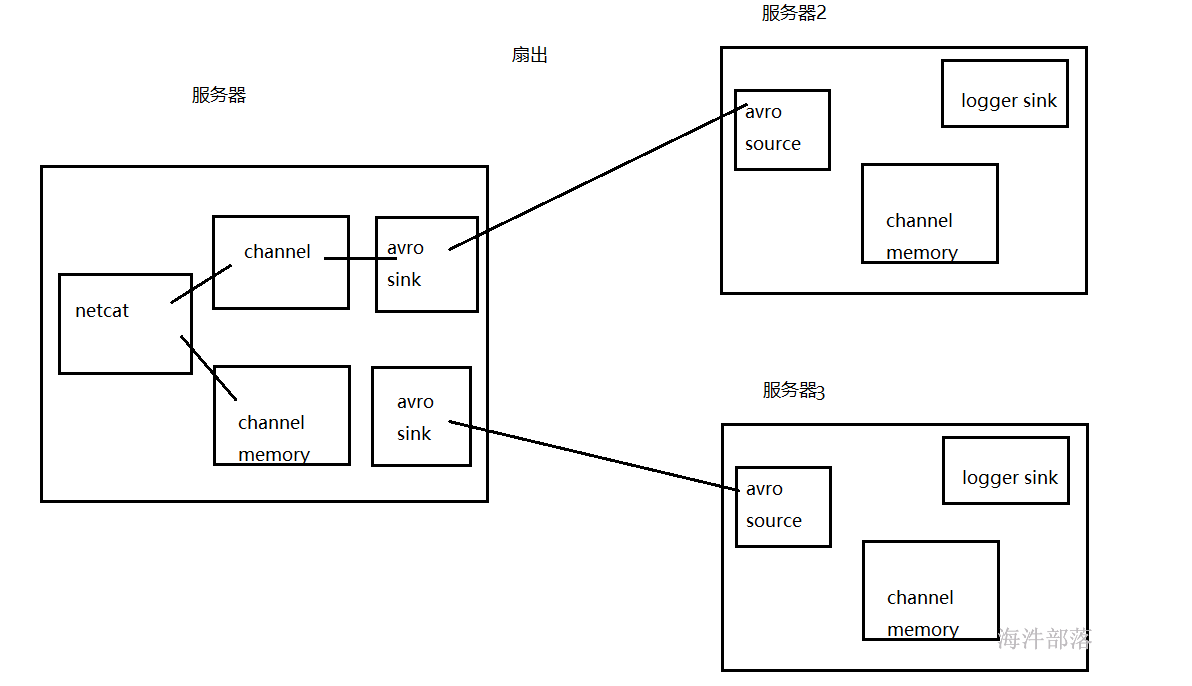
需要修改第一台服务器agent
a1.sources=r1
a1.sinks=k1 k2
a1.channels=c1 c2
a1.sources.r1.type=netcat
a1.sources.r1.bind=worker-1
a1.sources.r1.port=44444
a1.channels.c1.type=memory
a1.channels.c1.capacity=100000
a1.channels.c1.transactionCapacity=100
a1.channels.c2.type=memory
a1.channels.c2.capacity=100000
a1.channels.c2.transactionCapacity=100
a1.sinks.k1.type=avro
a1.sinks.k1.hostname = worke-1
a1.sinks.k1.port = 55555
a1.sinks.k2.type=avro
a1.sinks.k2.hostname = worke-2
a1.sinks.k2.port = 55555
a1.sources.r1.channels=c1 c2
a1.sinks.k1.channel=c1
a1.sinks.k2.channel=c2第二台和第三台agent编写如下:
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=avro
a1.sources.r1.bind=11.147.251.96
a1.sources.r1.port=55555
a1.channels.c1.type=memory
a1.channels.c1.capacity=100000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=logger
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1从后往前分别启动三台agent
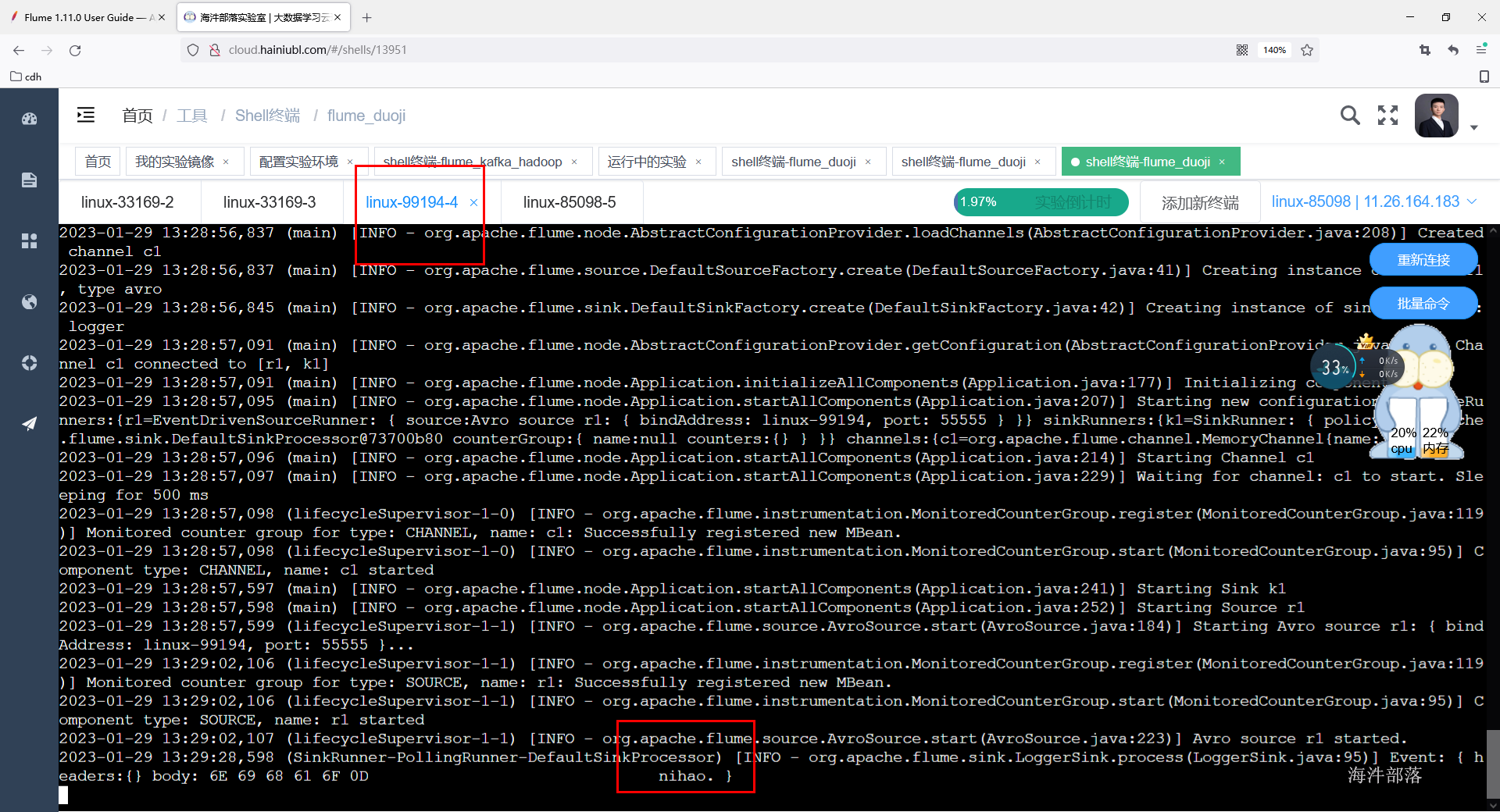
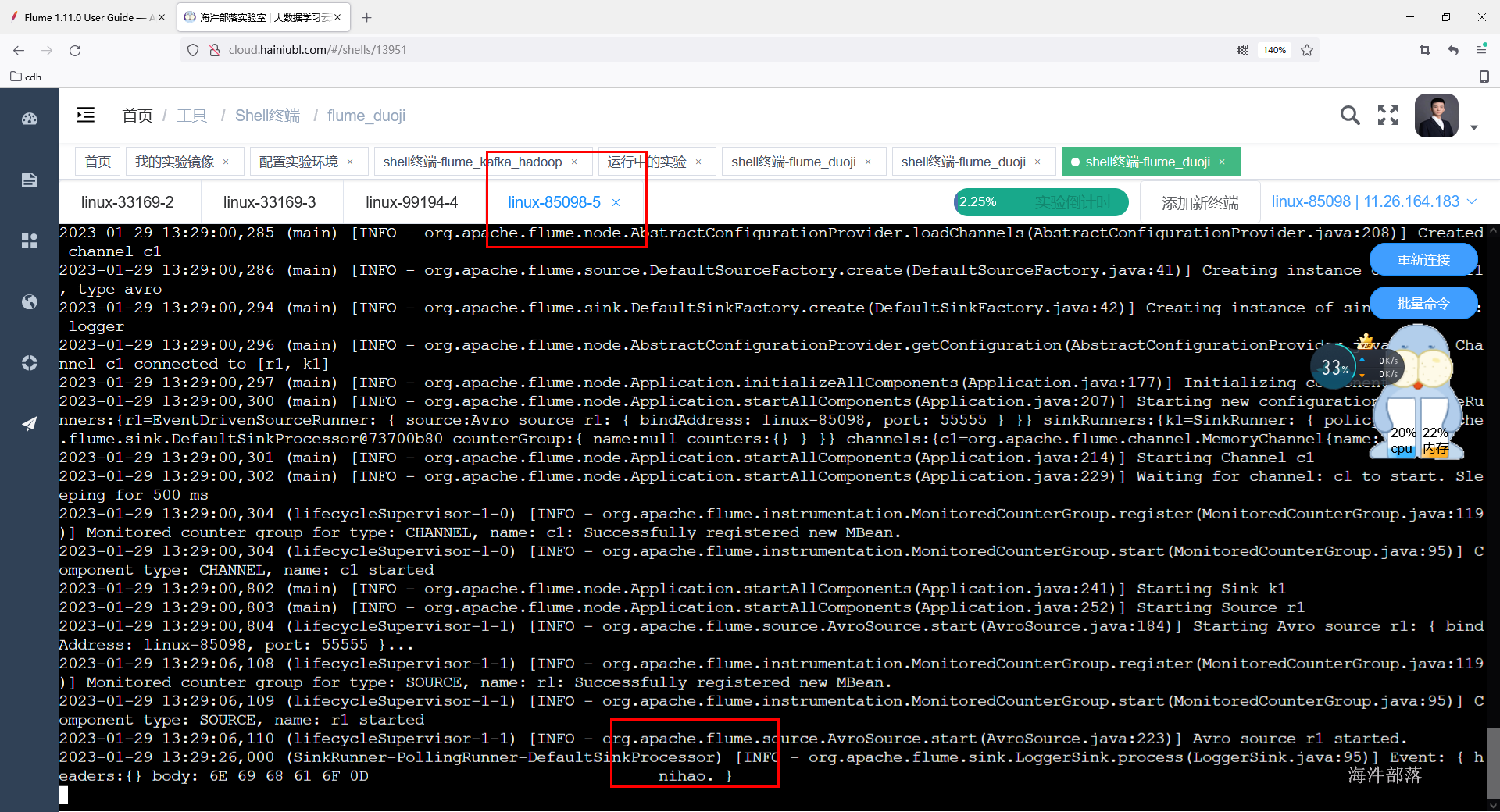
flume-ng agent -n a1 -c /usr/local/flume/conf/ -f ./avro.agent -Dflume.root.logger=INFO,console测试给第一台flume发送数据,第二台和第三台节点打印数据到控制台
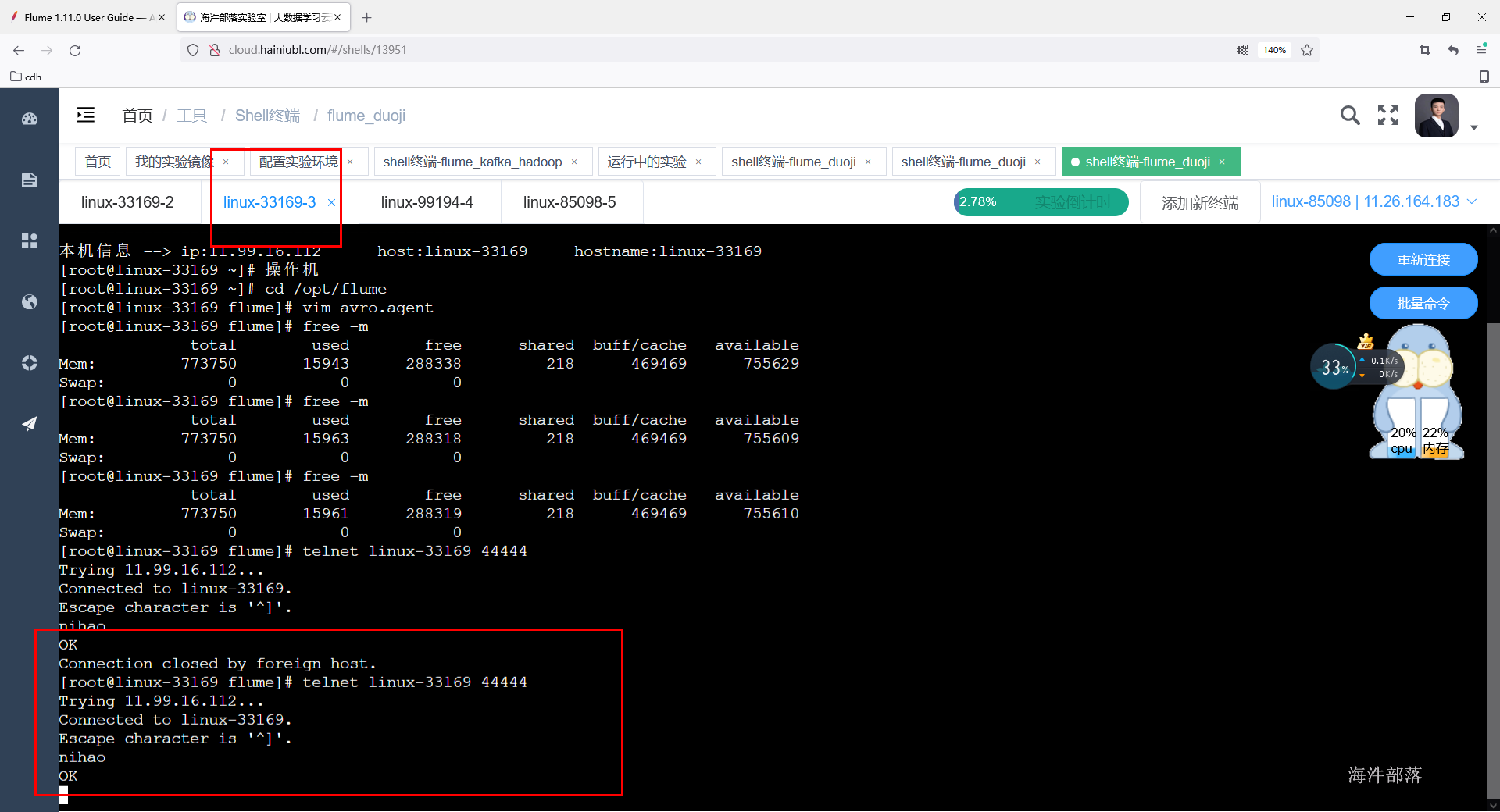
第二台和第三台收到消息
还可以通过avro sink 实现扇入操作:即第一台和第二台手机数据,将数据发送到第三台服务器
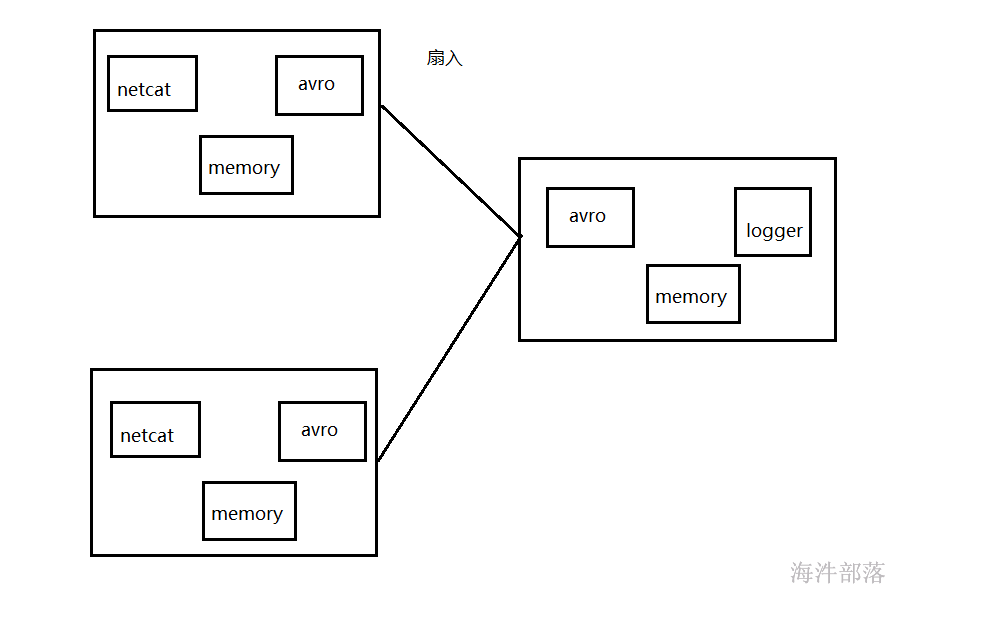
这个问题留给大家自行实现,小手动起来。


