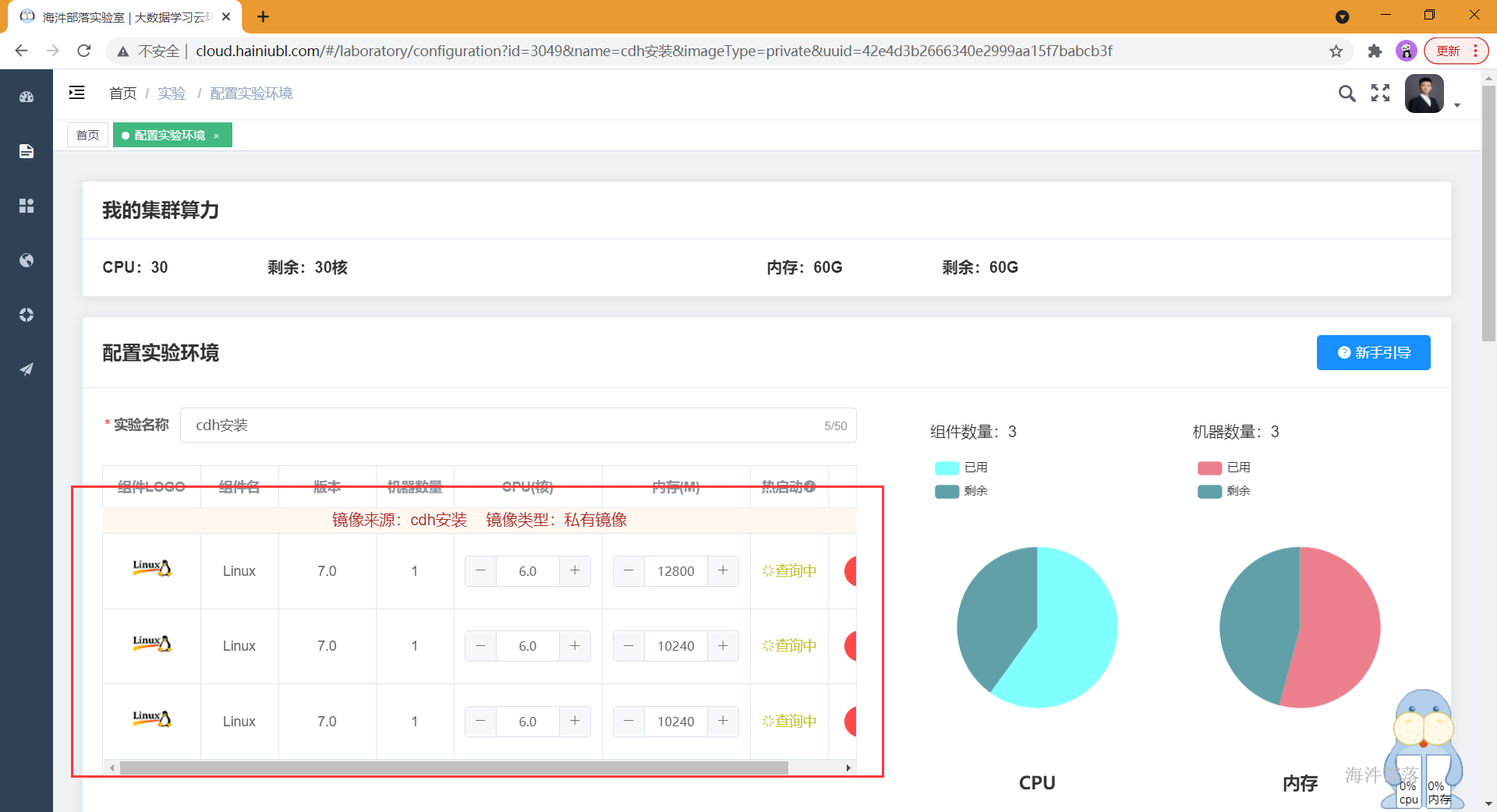
环境准备
准备三台linux服务器,并配置资源
启动三台服务器
2 cdh集群安装
2.1 解压cdh压缩包
解压安装包
tar -xvf /public/software/bigdata/cdh6.3.2.tar -C /tmp
2.2. 组件安装
-
kudu 需要以下组件
配置目的:kudu依赖
#所有节点
yum install gcc python-devel -y
yum install cyrus-sasl* -y2.3 调整host文件
配置目的:域名访问
# 在所有节点修改hosts文件配置ip地址和主机名的映射,替换为自己环境实际ip与hostname
192.168.88.220 worker-1
192.168.88.221 worker-2
192.168.88.222 worker-3
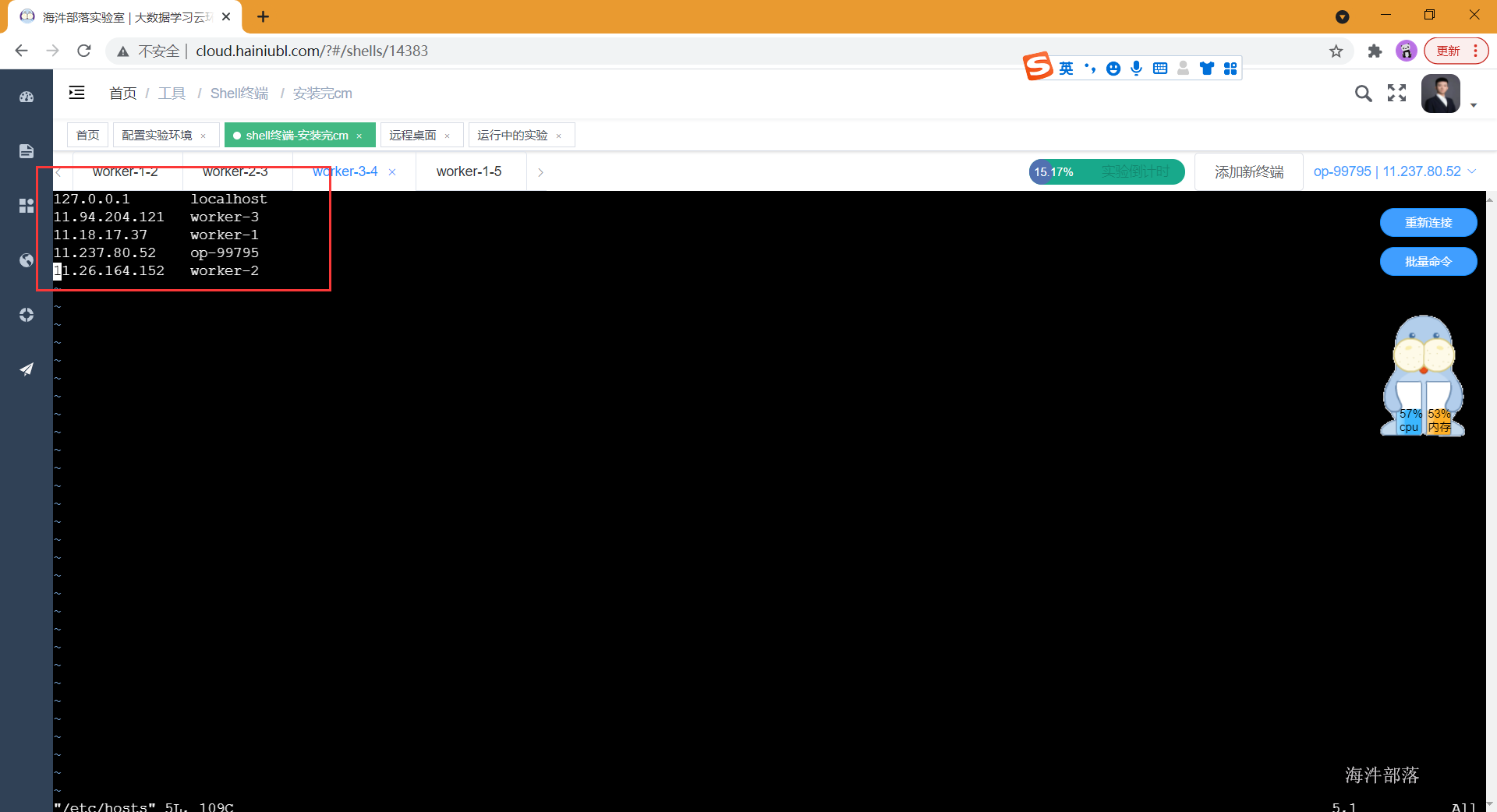
2.4 所有节点修改hostname
# 在所有节点修改/etc/hostname文件
vim /etc/hostname
修改完hostname之后,需要重启镜像hostname才生效
重启之后:
2.4 安装jdk
配置目的:Java必不可少
# 所有节点执行
#安装jdk 在我们的cdh安装包中
cd /tmp/
# 包分发到其他节点上
scp oracle-j2sdk1.8-1.8.0+update181-1.x86_64.rpm root@worker-2:/tmp/
scp oracle-j2sdk1.8-1.8.0+update181-1.x86_64.rpm root@worker-3:/tmp/
# 所有节点执行
cd /tmp/
yum install oracle-j2sdk1.8-1.8.0+update181-1.x86_64.rpm -y
ln -s /usr/java/jdk1.8.0_181-cloudera /usr/java/latest
# 配置环境变量
cat >> /etc/profile <<EOF
export JAVA_HOME=/usr/java/latest
export JRE_HOME=\$JAVA_HOME/jre
export CLASSPATH=.:\$CLASSPATH:\$JAVA_HOME/lib:\$JRE_HOME/lib
export PATH=\$PATH:\$JAVA_HOME/bin:\$JRE_HOME/bin
EOF
#source环境变量及验证是否生效
source /etc/profile
java -version2.5 安装、配置mysql
方式1:
rpm包安装
#在worker-1上安装即可
# 由于网络原因,本课程采用离线安装方式
# 解压安装包
mkdir -p /opt/tools/mysql
tar -xf mysql-5.7.22-1.el7.x86_64.rpm-bundle.tar -C /opt/tools/mysql
# 删除系统自带的MySQL-libs
yum remove -y mysql-libs
# 安装server时要依赖
yum install -y net-tools
# 离线安装
rpm -vih /opt/tools/mysql/mysql-community-common-5.7.22-1.el7.x86_64.rpm
rpm -vih /opt/tools/mysql/mysql-community-libs-5.7.22-1.el7.x86_64.rpm
rpm -vih /opt/tools/mysql/mysql-community-client-5.7.22-1.el7.x86_64.rpm
yum install -y /opt/tools/mysql/mysql-community-server-5.7.22-1.el7.x86_64.rpm
rpm -ivh /opt/tools/mysql/mysql-community-libs-compat-5.7.22-1.el7.x86_64.rpm
# 启动MySQL
systemctl start mysqld
systemctl status mysqld
# cat /var/log/mysqld.log | grep password 查看初始化密码
# 登录
mysql -uroot -p
# 输入初始化密码
# 设置校验密码的长度
set global validate_password_policy=LOW;
# 修改密码
set password=PASSWORD('12345678');
# 对外开放权限
set global validate_password_policy=LOW;
grant all privileges on *.* to 'root'@'%' identified by '12345678';
flush privileges;
# 修改my.cnf,默认在/etc/my.cnf,执行:vim /etc/my.cnf,添加如下内容:
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character_set_server=utf8
# 重启生效
systemctl restart mysqld方式2:
tar包安装
# 由于网络原因,本课程采用离线安装方式
# 解压安装包
tar -zxvf /public/software/database/mysql-5.7.20-linux-glibc2.12-x86_64.tar.gz -C /opt/
#清除多余的mysql相关包
rpm -qa|grep mariadb
rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64
#创建mysql用户组
groupadd mysql
#创建mysql用户
useradd -g mysql mysql
#给mysql用户设置密码
passwd mysql
#修改解压后的mysql目录
mv mysql-5.7.20-linux-glibc2.12-x86_64/ mysql
#修改mysql目录的所有者和属组为mysql
chown -R mysql:mysql mysql/
#进入mysql目录创建数据存放目录data
cd mysql
mkdir data
chown mysql:mysql data
#编辑mysql配置文件
vim /etc/my.cnf
#填写以下内容
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
skip-name-resolve
#设置3306端口
port = 3306
# 设置mysql的安装目录
basedir=/opt/mysql
# 设置mysql数据库的数据的存放目录
datadir=/opt/mysql/data
# 允许最大连接数
max_connections=200
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
lower_case_table_names=1
max_allowed_packet=16M
#安装和初始化mysql
bin/mysql_install_db --user=mysql --basedir=/opt/mysql/ --datadir=/opt/mysql/data/报错:

#安装依赖包
yum remove -y libaio
yum -y install numactl.x86_64再次初始化安装成功
#修改环境变量文件
vim /etc/profile
#添加以下内容
export PATH=$PATH:/opt/mysql/bin
#让环境变量生效
source /etc/profile启动mysql服务
/opt/mysql/support-files/mysql.server start登录mysql并修改密码
#临时密码 cat /root/.mysql_secret
mysql -u root -p
#修改密码
set PASSWORD = PASSWORD('12345678');2.6 创建cm元数据库
Cloudera manager service的元库
登陆mysql,创建数据库与用户,以及远程授权。
mysql -uroot -pset global validate_password_policy=LOW;
create database metastore default character set utf8;
create user 'hive'@'%' identified by 'hivedemima';
grant all privileges on metastore.* to 'hive'@'%';
create database cm default character set utf8;
create user 'cm'@'%' identified by 'cmdemima';
grant all privileges on cm.* to 'cm'@'%';
create database am default character set utf8;
create user 'am'@'%' identified by 'amdemima';
grant all privileges on am.* to 'am'@'%';
create database rm default character set utf8;
create user 'rm'@'%' identified by 'rmdemima';
grant all privileges on rm.* to 'rm'@'%';
create database hue default character set utf8;
create user 'hue'@'%' identified by 'huedemima';
grant all privileges on hue.* to 'hue'@'%';
create database oozie default character set utf8;
create user 'oozie'@'%' identified by 'ooziedemima';
grant all privileges on oozie.* to 'oozie'@'%';
create database sentry default character set utf8;
create user 'sentry'@'%' identified by 'sentrydemima';
grant all privileges on sentry.* to 'sentry'@'%';
create database nas default character set utf8;
create user 'nas'@'%' identified by 'nasdemima';
grant all privileges on nas.* to 'nas'@'%';
create database nms default character set utf8;
create user 'nms'@'%' identified by 'nmsdemima';
grant all privileges on nms.* to 'nms'@'%';
flush privileges;
exit;
2.7 配置http服务
配置本地的http,用于parcels配置,安装过程中使用本地的parcels,而不是使用在线安装。
#所有节点安装
#安装及开启http服务
yum install httpd -y
systemctl start httpd
systemctl status httpd
#主节点执行
#配置http服务
#移动两个文件夹到html目录下
mkdir -p /var/www/html/cm6.3.1
mkdir -p /var/www/html/cdh6.3.2
cd /tmp
mv CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel* manifest.json /var/www/html/cdh6.3.2/
mv allkeys.asc cloudera-manager-* enterprise-debuginfo-6.3.1-1466458.el7.x86_64.rpm /var/www/html/cm6.3.1/- 使用浏览器测试访问
- 创建cm的repo
创建cdh介质的本地源,在yum安装的时候使用本地库,避免在线安装(速度慢还经常断)。
#在worker-1上安装createrepo工具
#createrepo 是一个对rpm 文件进行索引建立的工具。大体功能就是对指定目录下的rpm文件进行检索,把每个rpm文件的信息存储到指定的索引文件中,这样方便远程yum命令在安装更新时进行检索。
yum install createrepo -y
cd /var/www/html/cm6.3.1
createrepo .
#所有节点执行 baseurl改成我们上面配置的cm的http地址
cat > /etc/yum.repos.d/cloudera.repo <<EOF
[Cloudera_Manager]
name=Cloudera Manager 6.3.1
baseurl=http://worker-1/cm6.3.1/
enabled=1
gpgcheck=0
EOF
yum repolist
2.8 安装CDH6
2.8.1 配置mysql驱动包
复制mysql的连接驱动,并创建软连接,在初始化元数据库时需要使用到mysql的连接驱动。mysql的驱动包可以在maven官方下载或者在本地的maven库中找。
maven仓库官方链接:
#所有节点
#复制MySQL的JDBC包
mkdir /usr/share/java
#主节点执行
scp /tmp/mysql-connector-java-5.1.35.jar root@worker-2:/tmp/
scp /tmp/mysql-connector-java-5.1.35.jar root@worker-3:/tmp/
#所有节点执行
mv /tmp/mysql-connector-java-5.1.35.jar /usr/share/java/
ln -s /usr/share/java/mysql-connector-java-5.1.35.jar /usr/share/java/mysql-connector-java.jar2.8.2 安装CM服务
安装cm(Cloudera manager server)服务,安装完成后,在cm界面部署cdh集群。
在安装的过程中可以看到repository列,是否是我们上面本地yum源,如果不是,速度会非常慢,甚至失败。
#只在主节点执行
yum install -y cloudera-manager-server cloudera-manager-agent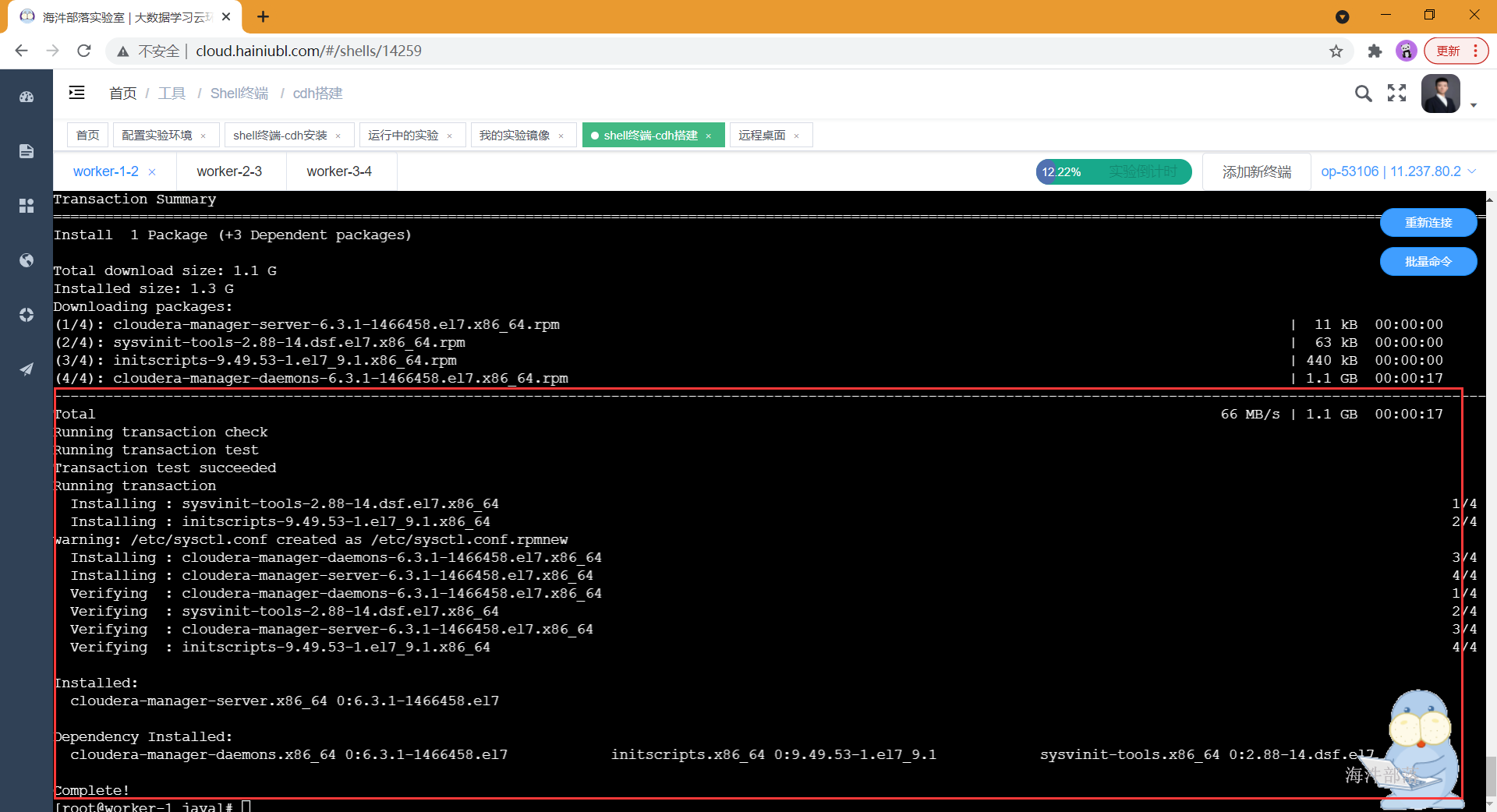
-
初始化CM元数据库
初始化cm的元库,初始化完成后会建立cm服务使用的表,可以在mysql中查看,这里的-h参数是部署mysql服务的节点地址,两个cm是库名与用户名
/opt/cloudera/cm/schema/scm_prepare_database.sh mysql -h worker-1 cm cm cmdemima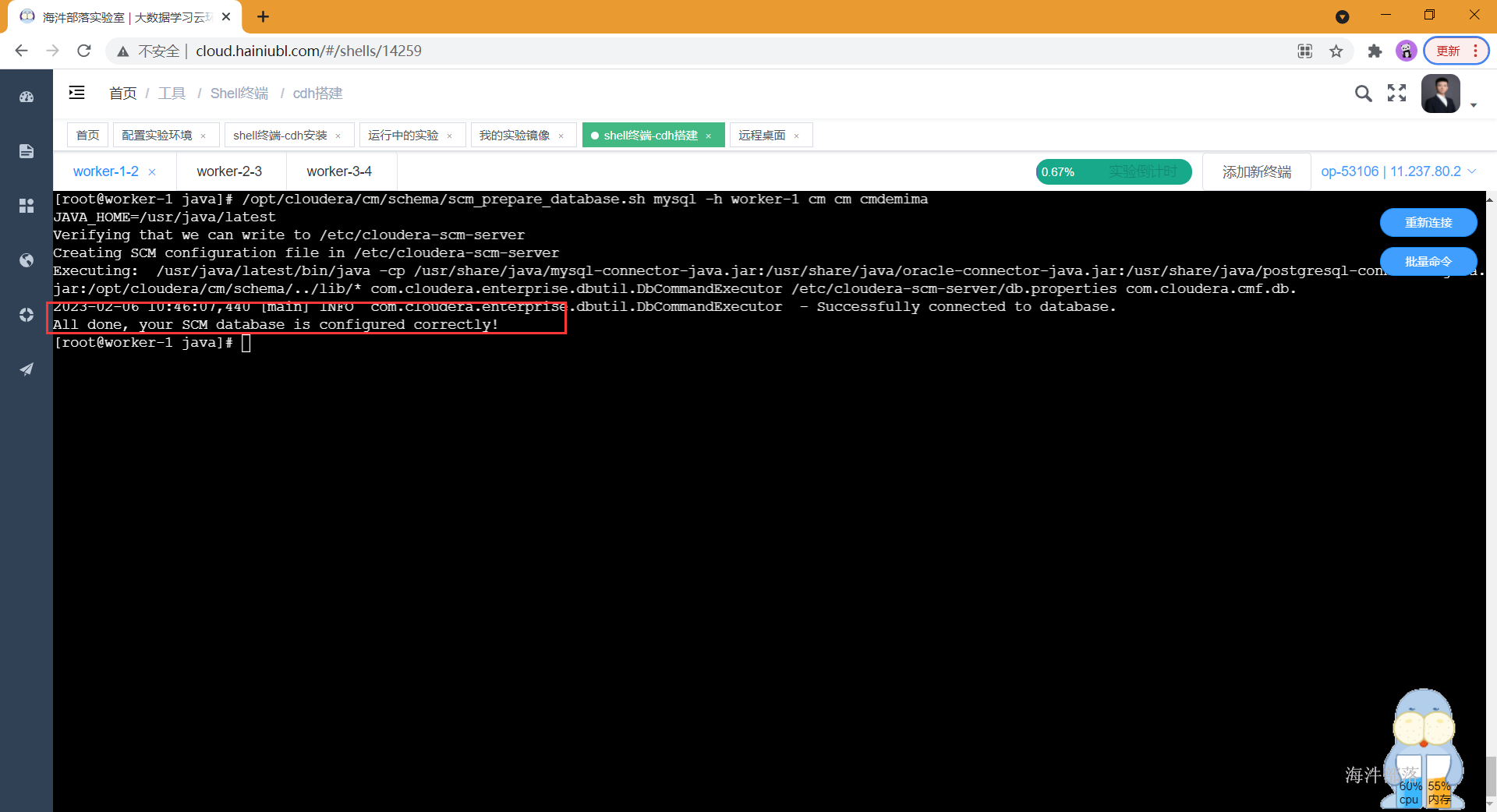
在从节点安装 cloudera-manager-agent
yum install -y cloudera-manager-agent所有节点安装完cloudera-manager-agent会导致systemctl命令不能使用,需要进行替换systemctl文件
#三台都执行
cp /public/data/systemctl /usr/bin修改三台服务器cloudera-agent的config.ini文件,将server_host修改成worker-1
vim /etc/cloudera-scm-agent/config.ini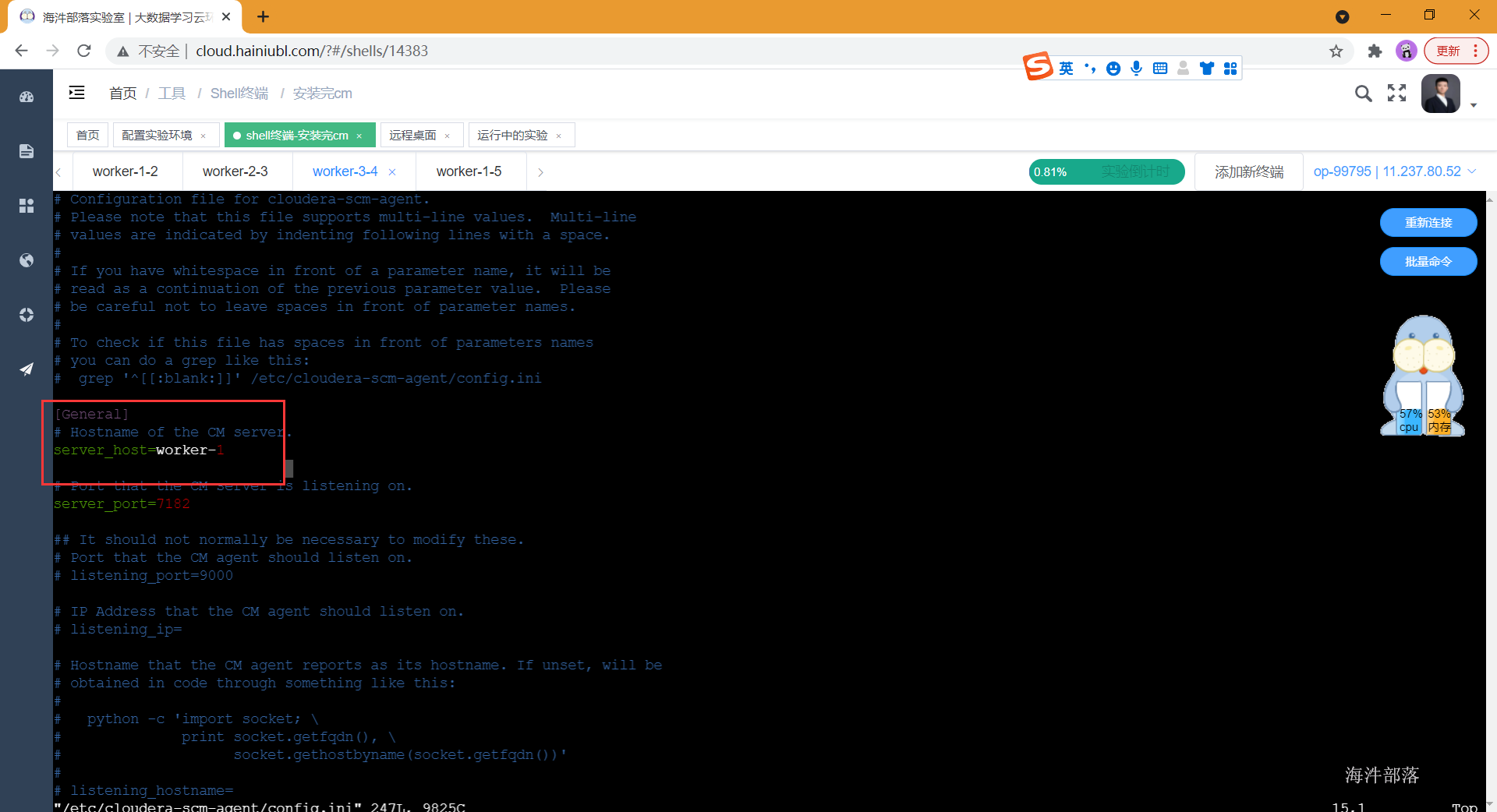
- 在主节点启动cm服务
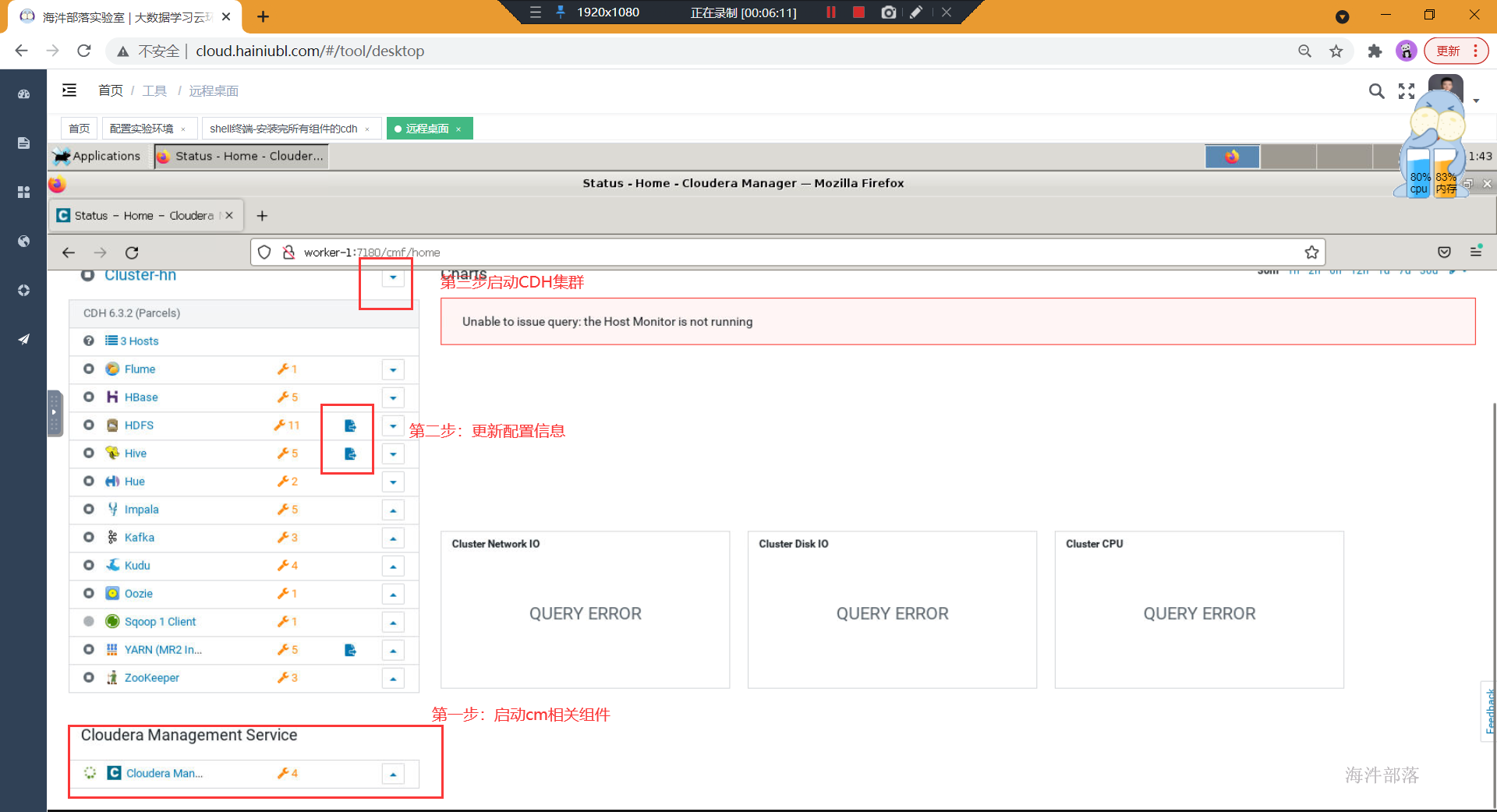
主节点启动cm服务,这个服务可能要启动一会儿,当启动完成后,可以通过netstat -apn | grep 7180监控到端口占用情况,也可以通过tail -f的方式监控cm启动日志,当出现started的时候,表示启动完成。
#主节点执行
systemctl start cloudera-scm-server
systemctl status cloudera-scm-server
#检查端口状态
netstat -apn | grep 7180
查看日志
tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log 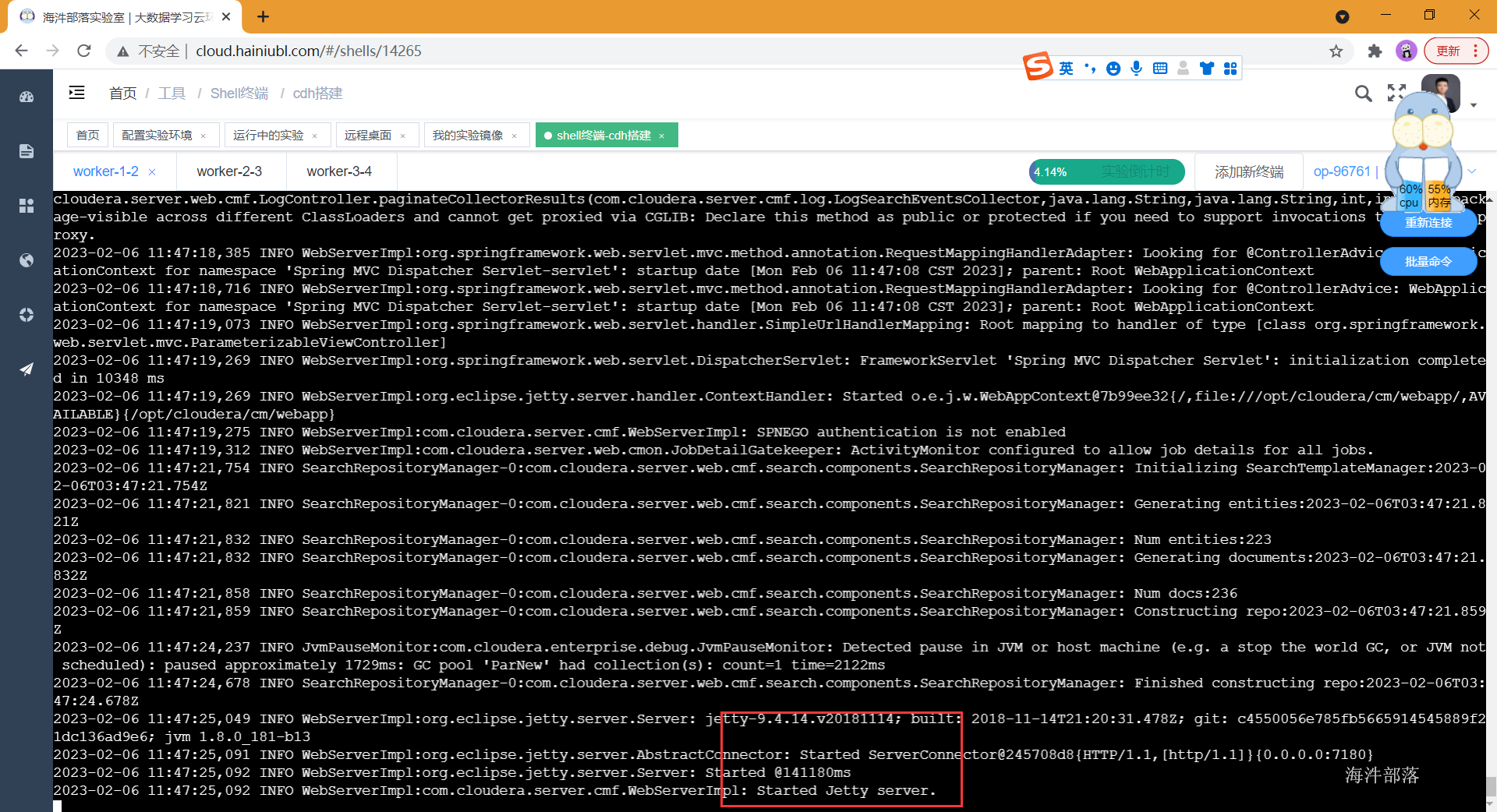
- 在主节点启动rpcbind
systemctl start rpcbind- 在三台节点启动supervisord
systemctl start supervisord- 在三台节点启动cloudera-scm-agent
systemctl start cloudera-scm-agent2.9 网页登陆
在cm web页面中配置cdh集群。
登录cloudera manager管理页面,默认的账号、密码为:admin/admin
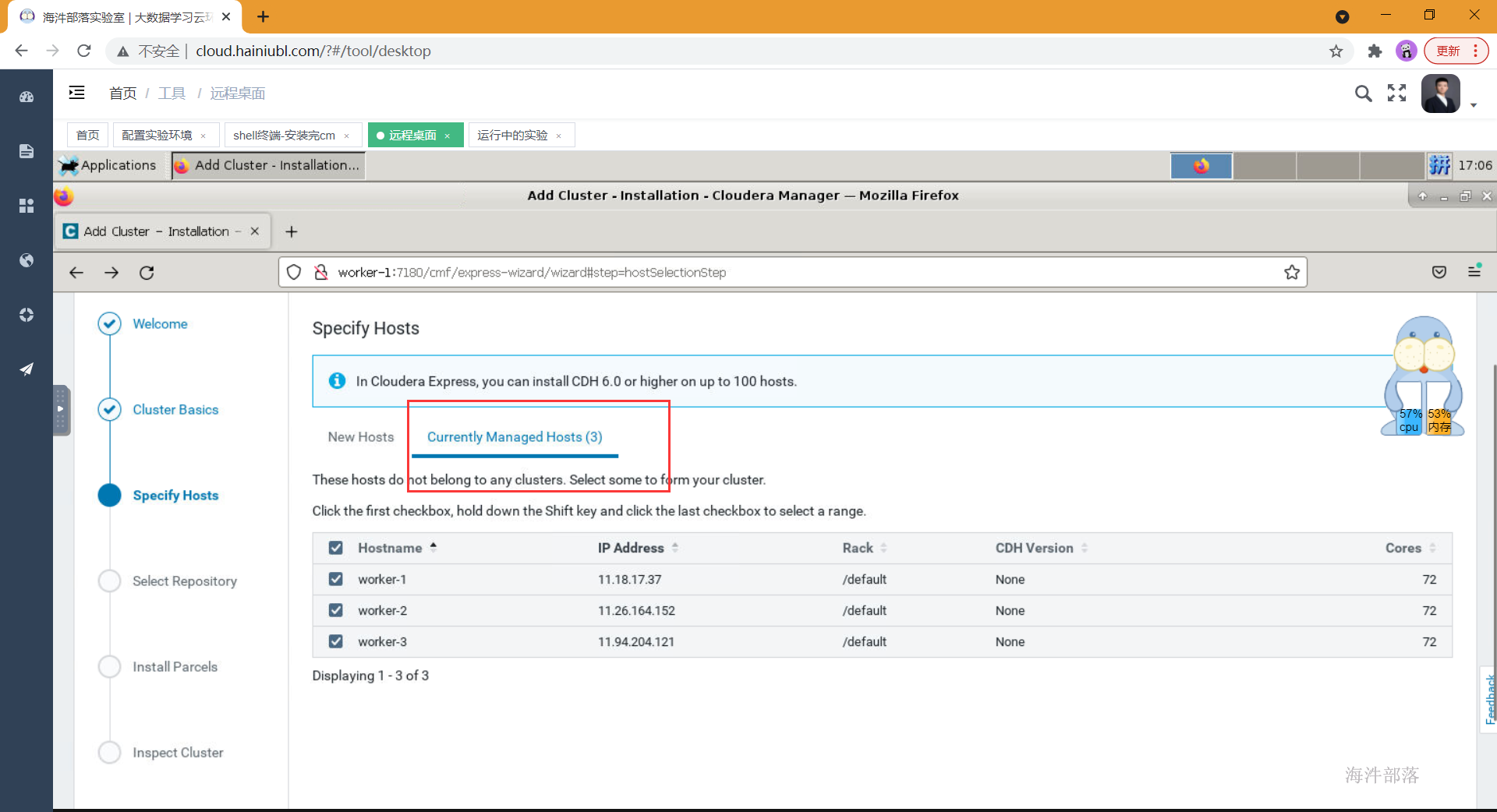
"同意协议" -> "选择Cloudera Express" -> "选择节点" ->
这里的主机名称为你要配置的所有节点的hostname,需要在你本机的hosts中也配置了这些节点。
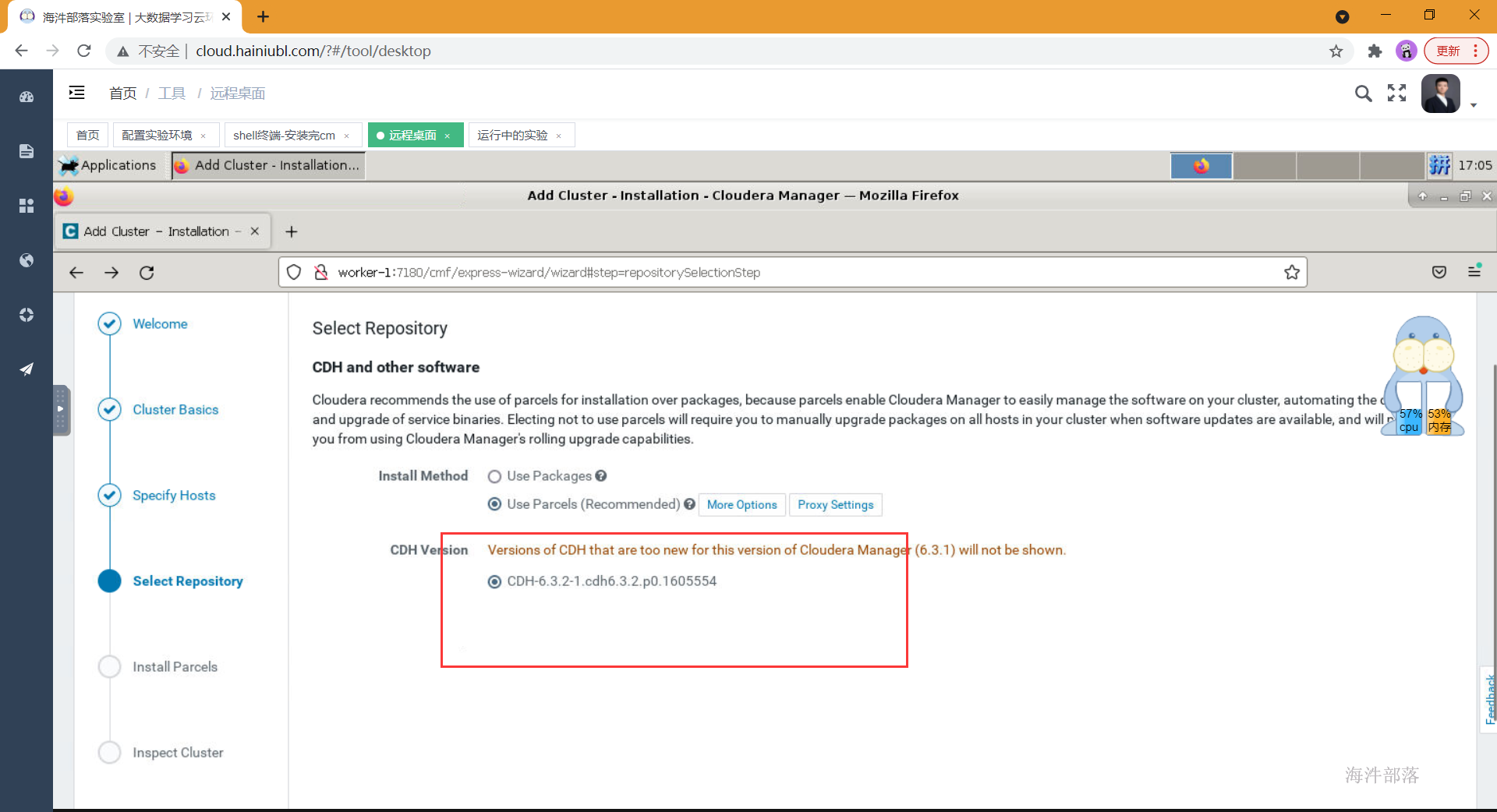
集群安装时库选择,这里使用的就是我们前面配置的httpd服务,使用本地下载,避免在线安装的各种问题。域名改成自己相应的域名。
parcel的远程安装库为:http://worker-1/cdh6.3.2/
进入到安装parcels的界面,这里也是自动进行的,如果中间出现各种错误,可以查看日志定位,在web界面上就可以看到错误日志,也可以在cm的日志中查找,/var/log目录下Cloudera manager server的日志。
如上,环境检查完成后,进行选择安装组件的环节,可以先选择一些基础组件安装,后面需要什么组件在添加即可。比如可以先安装hdfs、yarn、zookeeper,其他服务等集群全部安装完成后再集成,因为部分组件间有依赖关系,如果缺少了依赖,那会导致安装失败。
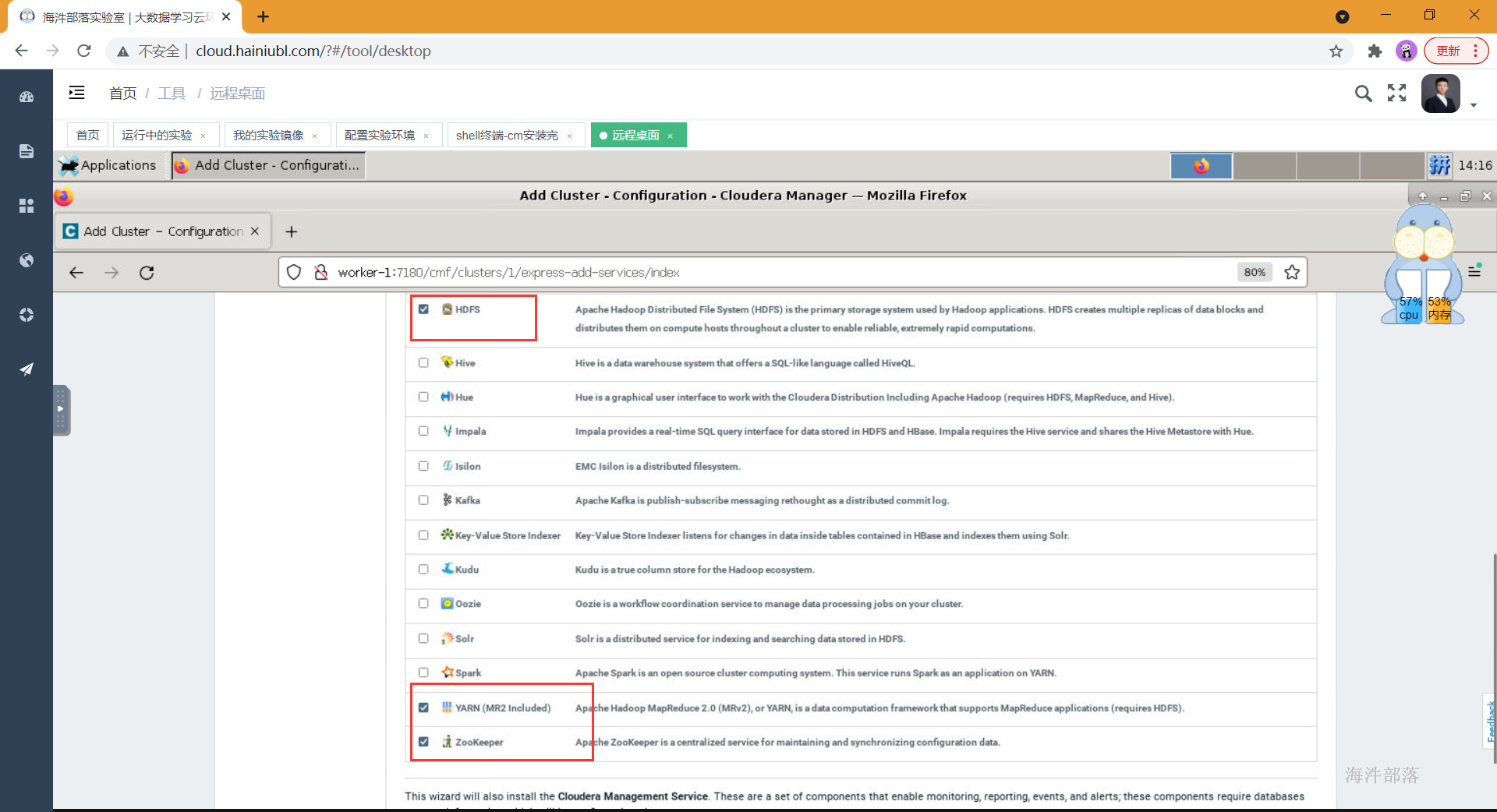
如上选择好安装组件后点击继续,为每个服务配置节点,如果是单节点就没得选择了,在生产环境中这个规划通常在角色规划中已经规划好,按照架构设计配置即可,通常我们会选择一个管理节点,这个管理节点上部署一些管理服务,其他计算与存储节点上不部署管理服务,如果节点资源紧张也可以在管理节点上部署存储与计算服务,还有一种极端的情况就是节点资源都很紧张,那面就要把服务尽量均衡到每个节点上,除个别服务,比如hive的元库肯定部署在和mysql相同的节点上。
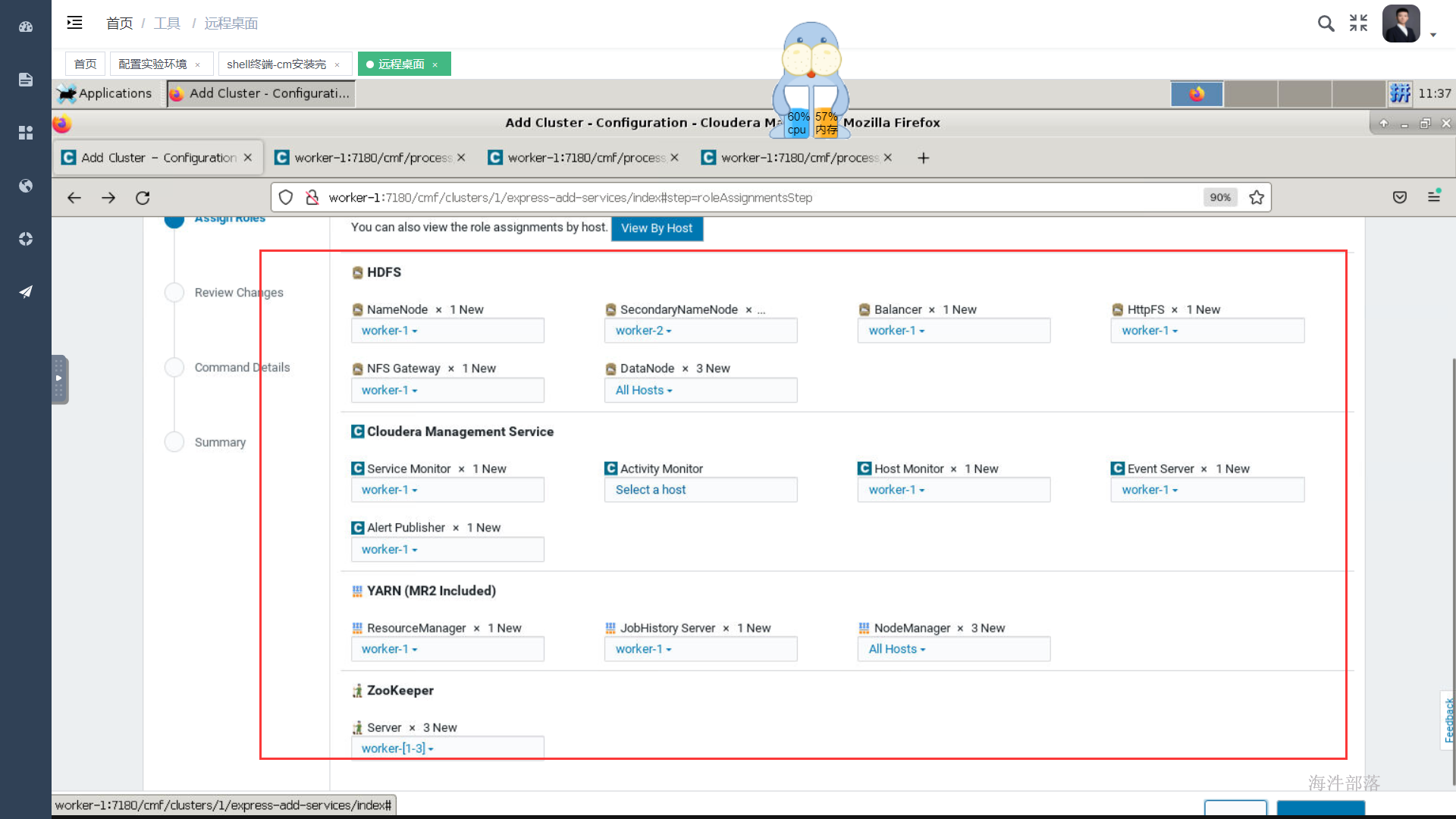
等待安装
在执行命令界面如果创建/tmp等路径的命令报错了,这是因为你的namenode处于安全模式,你需要去服务器后台把它恢复到正常,使用如下命令
vi /etc/passwd
vi之后找到hdfs用户,修改末尾的“/sbin /nologin”,需要改成“/bin/bash”保存退出
su - hdfs
hadoop dfsadmin -safemode leave
#将hdfs的根路径/的权限设置为777
hadoop fs -chmod -R 777 /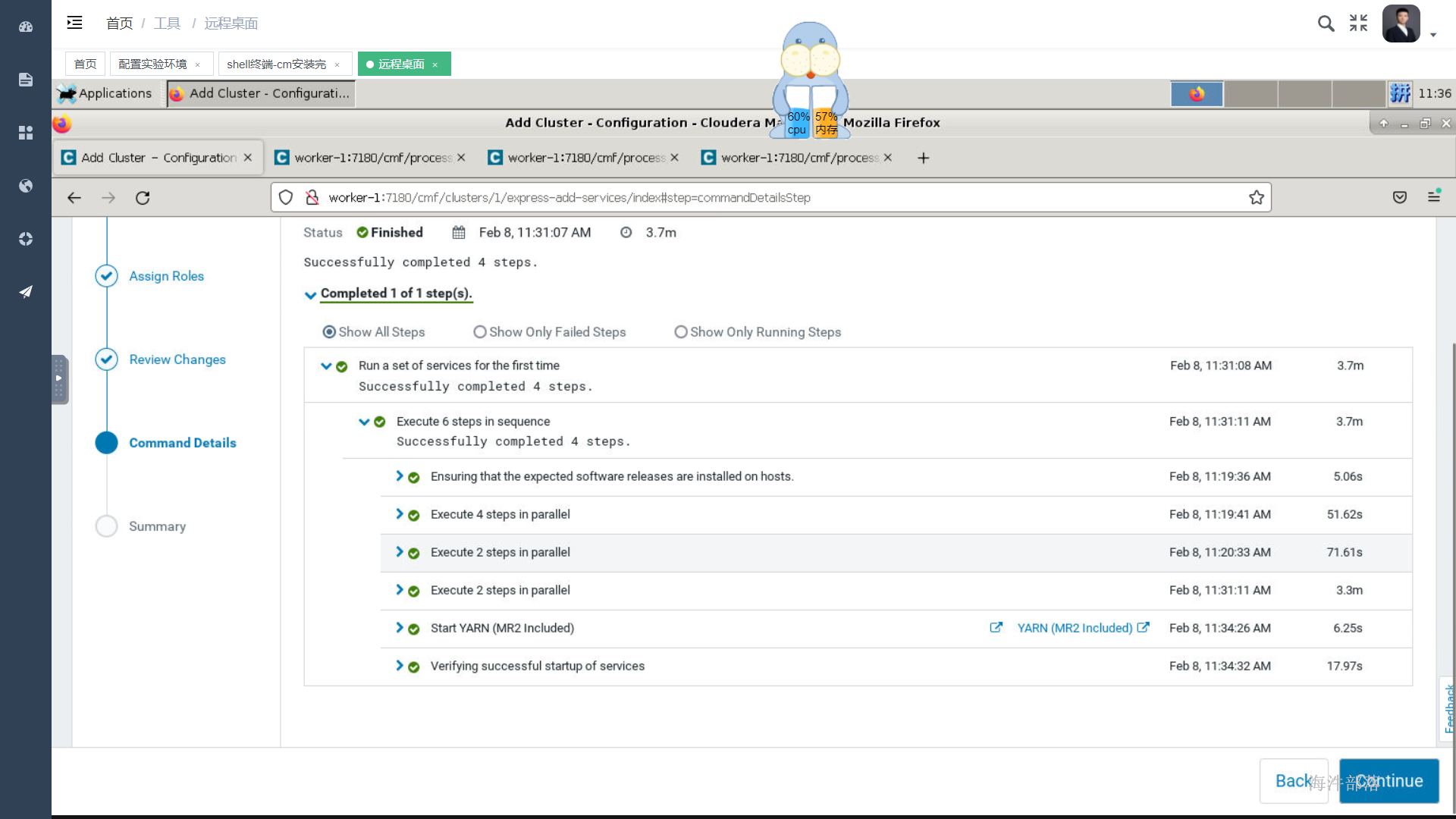
安装成功之后
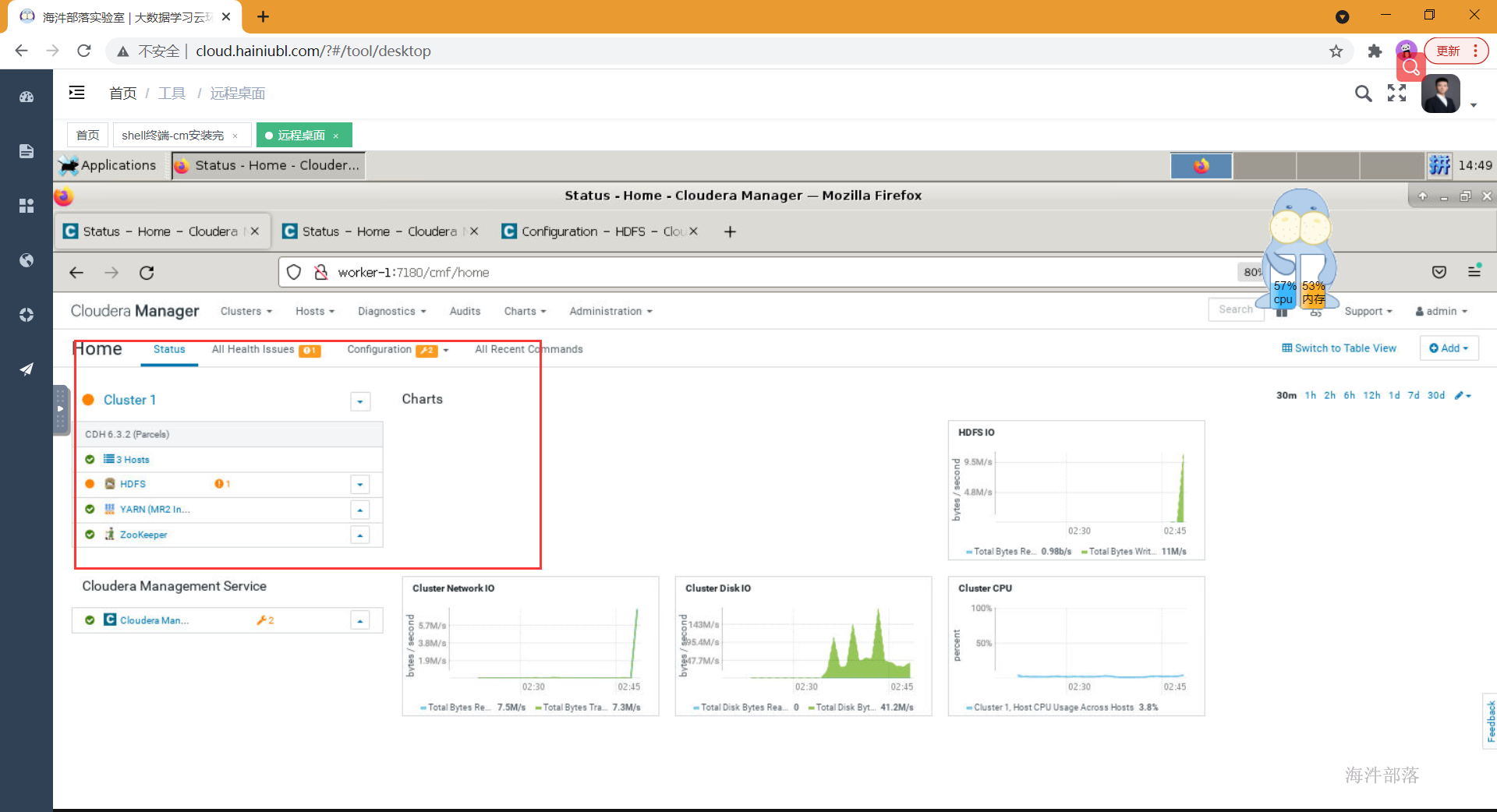
2.10 开启HA
- hdfs组件操作下拉按钮中选择启用high availability
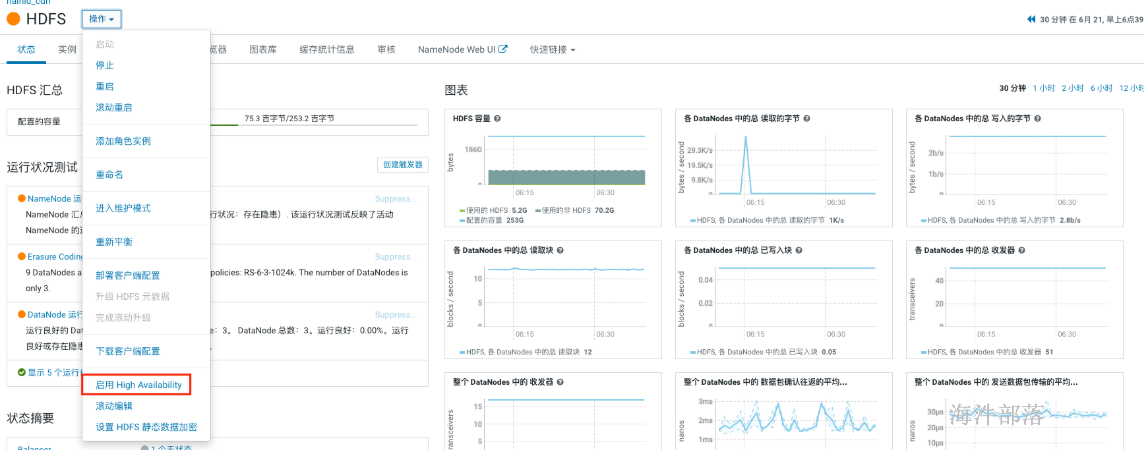
- 填写nameservice名称,比如我们在开源版本中配置的ns1,其实就是这个。
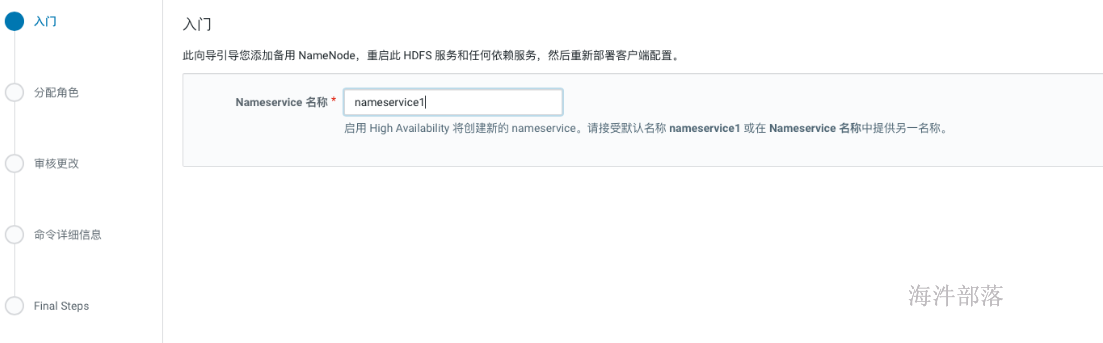
- 选择secondnamenode与journalnode节点,journalnode节点必须是大于等于3且奇数个。
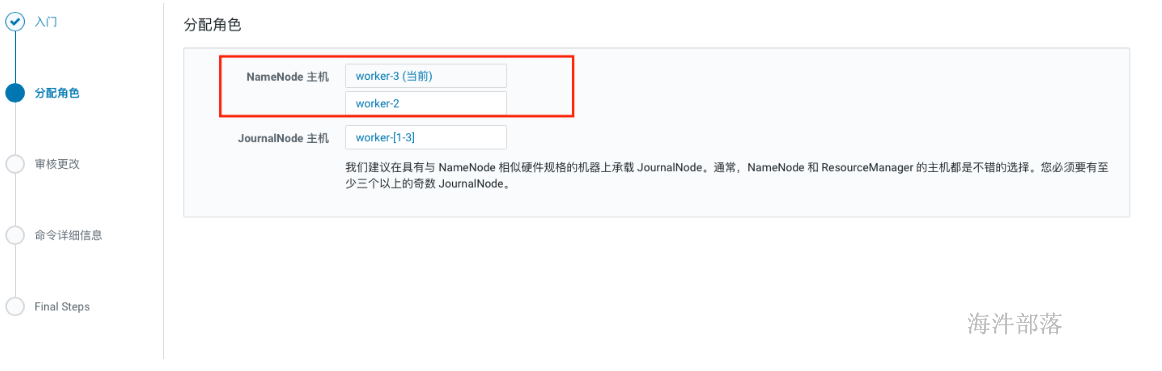
- 配置数据目录
- HA生效
在开启HA的过程中如果hdfs非空,会在格式化的时候报一个警告,因为非空所以格式化失败,不用理会,也不敢理会。
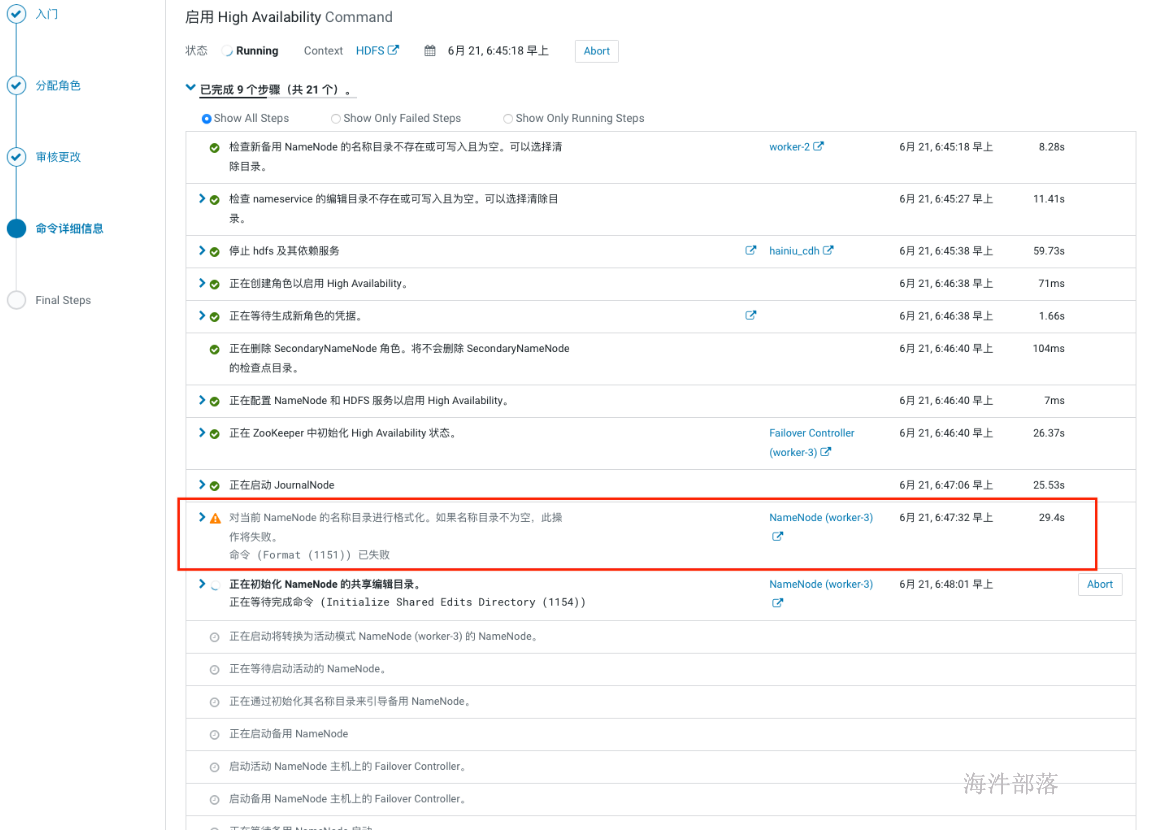
-
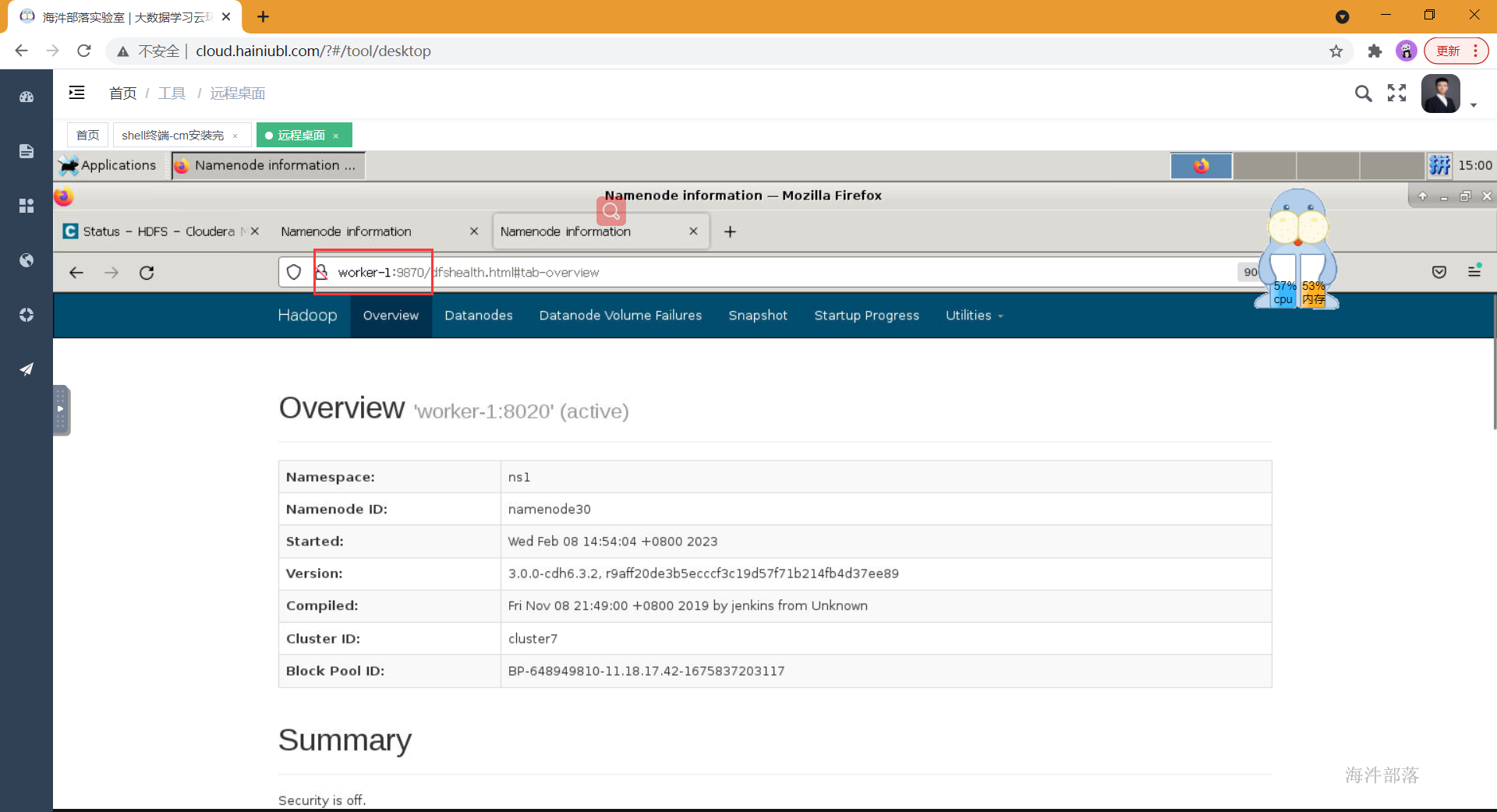
验证HA
worker-1机器所在的namenode是active
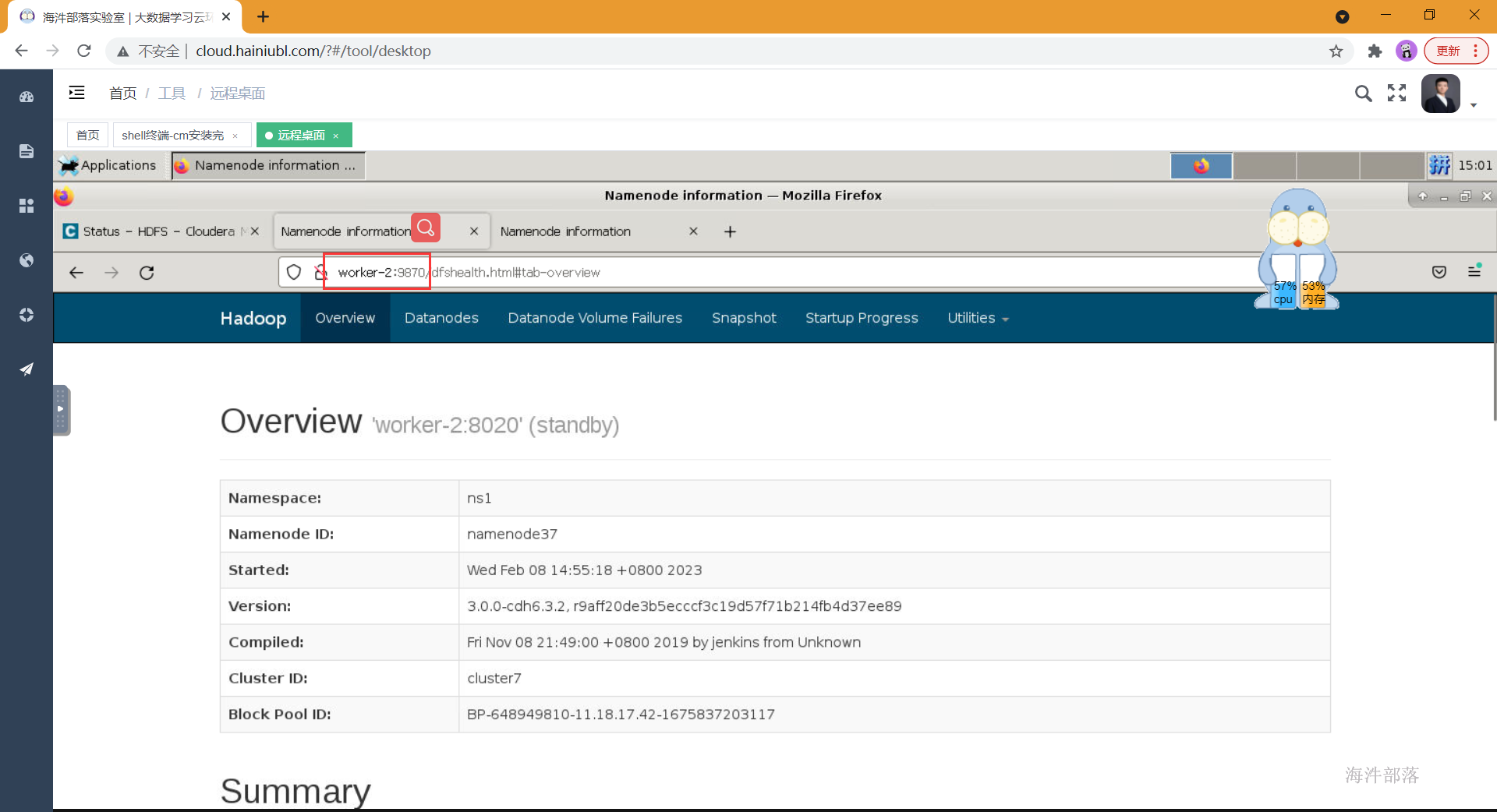
worker-2机器所在的namenode是standby
2.11 配置yarn资源
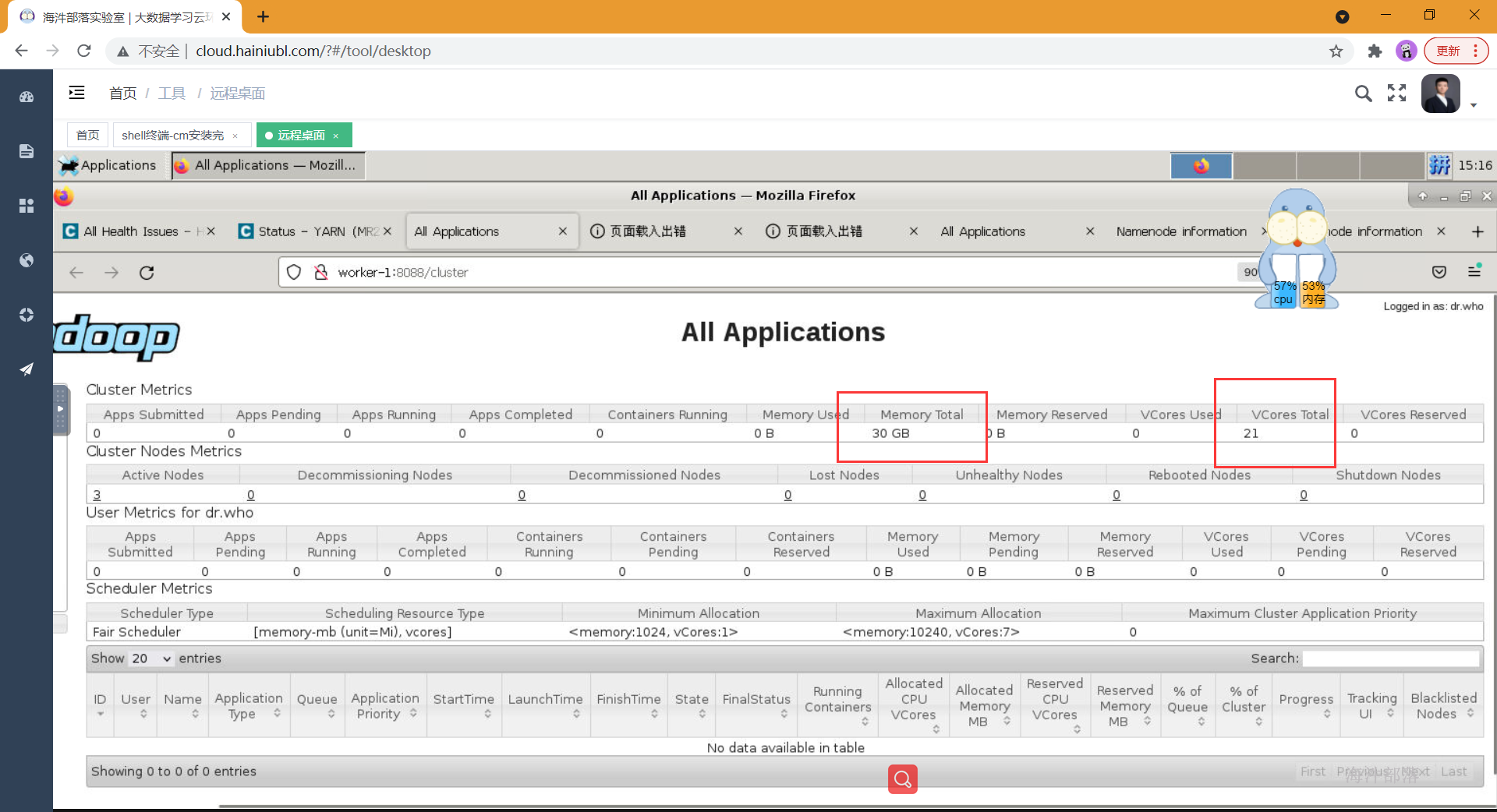
配置前可以看yarn webui,发现资源分配不合理,需要手动配置。
1)配置内存
修改以下配置:
# mapper任务内存
mapreduce.map.memory.mb: 1G
# reducer任务内存
mapreduce.reduce.memory.mb: 1G
# yarn容器内存
yarn.nodemanager.resource.memory-mb : 10G2)配置CPU核
修改以下配置:
# mapper任务虚拟CPU核数
mapreduce.map.cpu.vcores: 1
# reducer任务虚拟CPU核数
mapreduce.reduce.cpu.vcores: 1
# yarn容器虚拟CPU核数
# 【注意】:在生产环境里,1个cup核 对应 4G的内存。
yarn.nodemanager.resource.cpu-vcores : 7
# yarn容器最大虚拟CPU核数
yarn.scheduler.maximum-allocation-vcores 74)修改调度器内存数
修改以下配置:
# yarn容器最大内存
yarn.scheduler.maximum-allocation-mb 10G
配置好后重新更新配置。
查看yarn-webui资源情况
2.12 将当前实验环境保存镜像
- 找到运行中的镜像,将安装好的组件打成新镜像,并给新的镜像起名
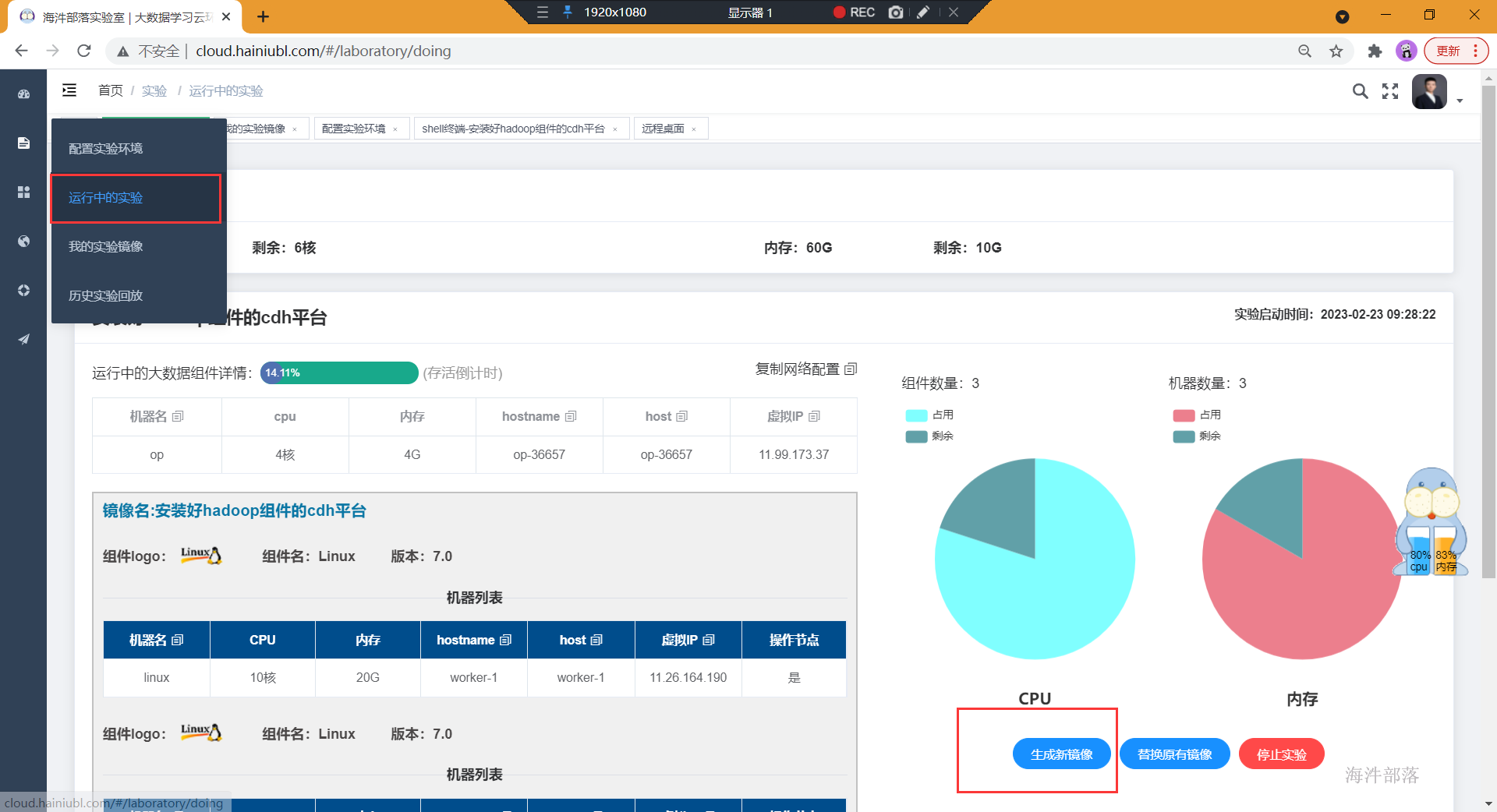
- 启动打好的镜像
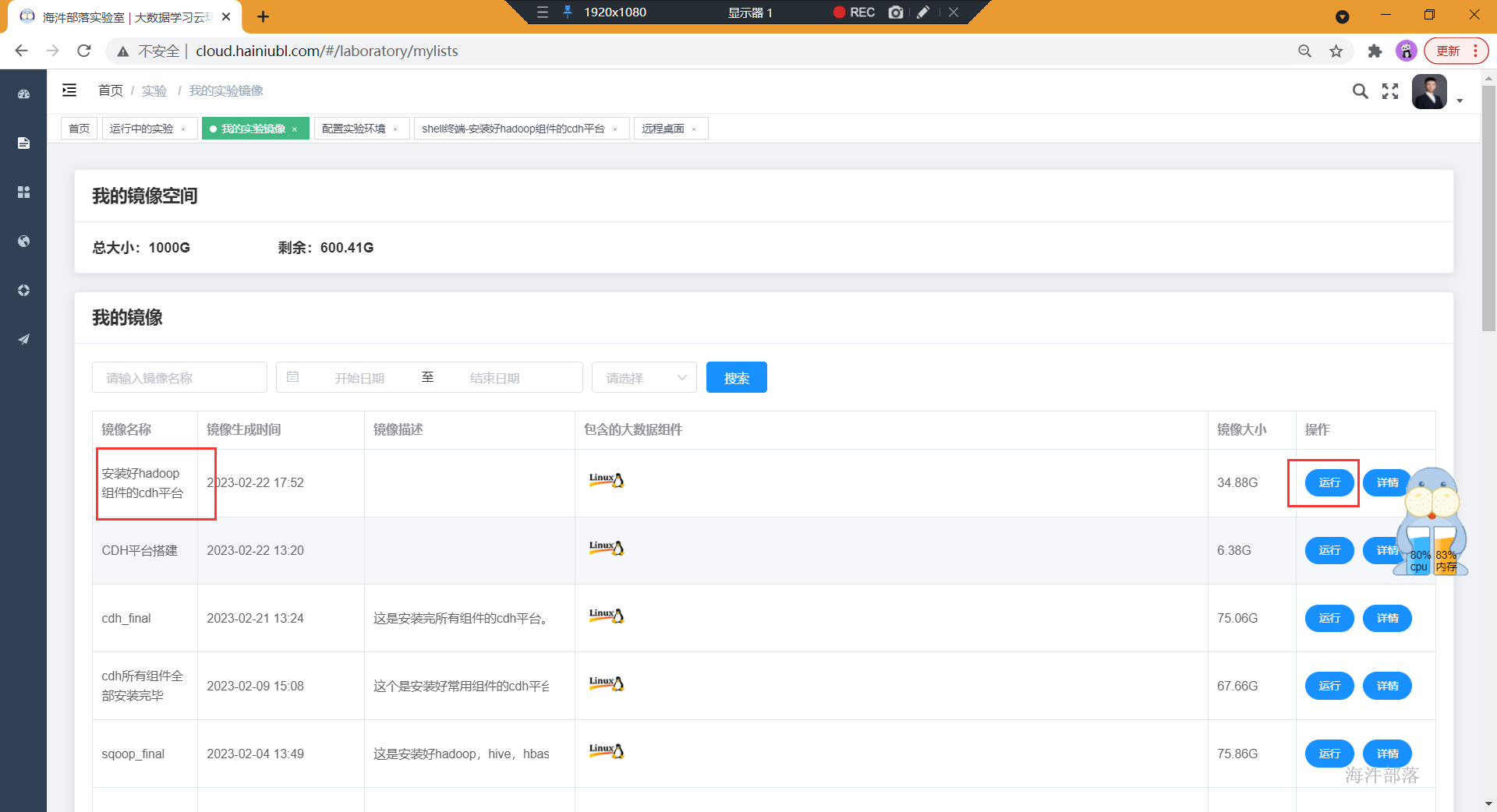
- 等到镜像热启动变成已就绪,就可以快速启动了!!
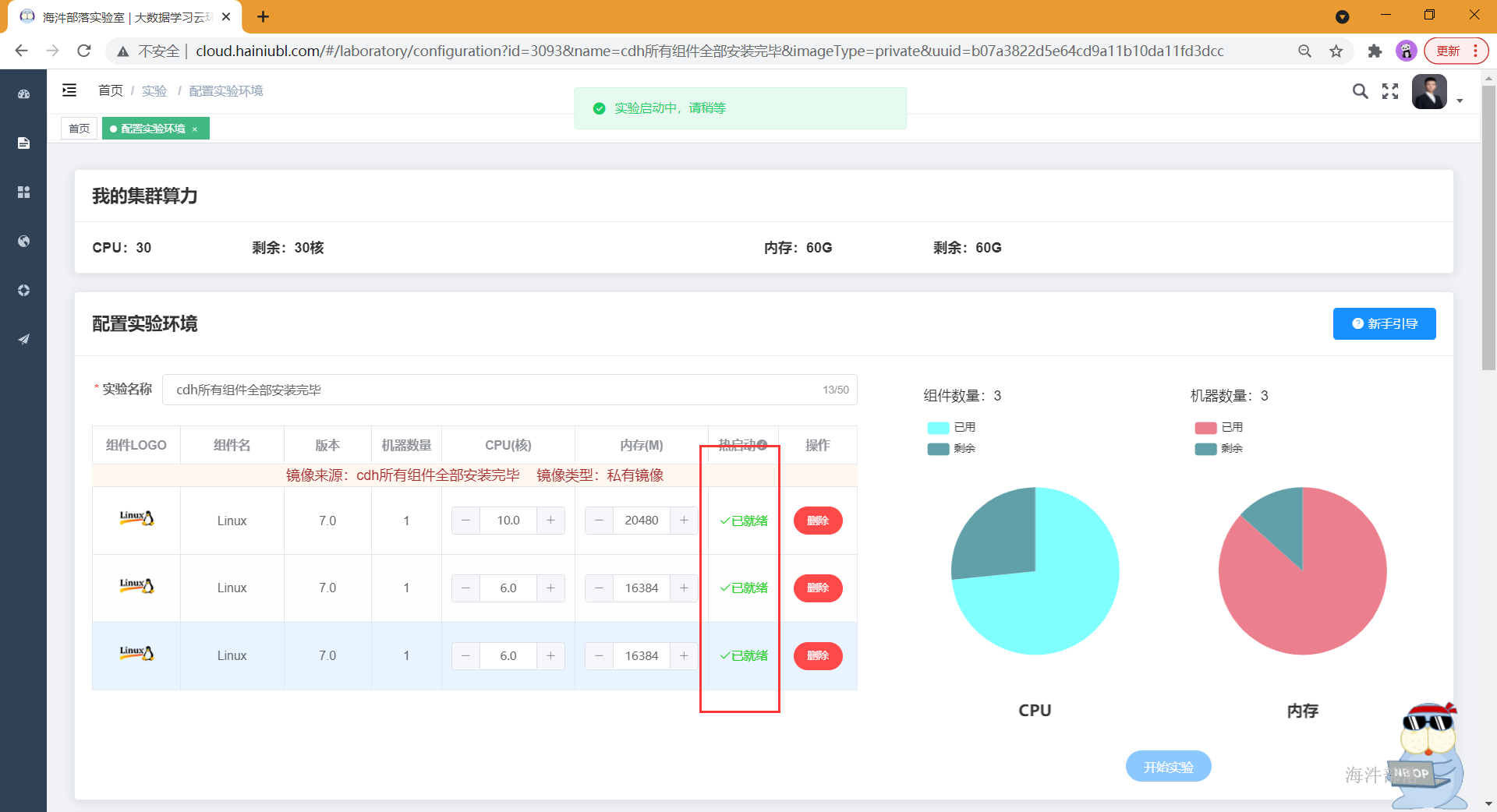
- 镜像启动成功需要按顺序启动一下所需服务
#1.在worker-1 上启动mysql
systemctl start mysqld
#2,在三台机器上启动httpd
systemctl start httpd
#3,在worker-1 上启动cm server
systemctl start cloudera-scm-server
#4,等待cm启动成功 在worker-1启动rpcbind
systemctl start rpcbind
#5,在三台节点启动supervisord
systemctl start supervisord
#6,在三台节点启动cm agent
systemctl start cloudera-scm-agent5.访问cm
http://worker-1:7180 输入admin/admin 进入
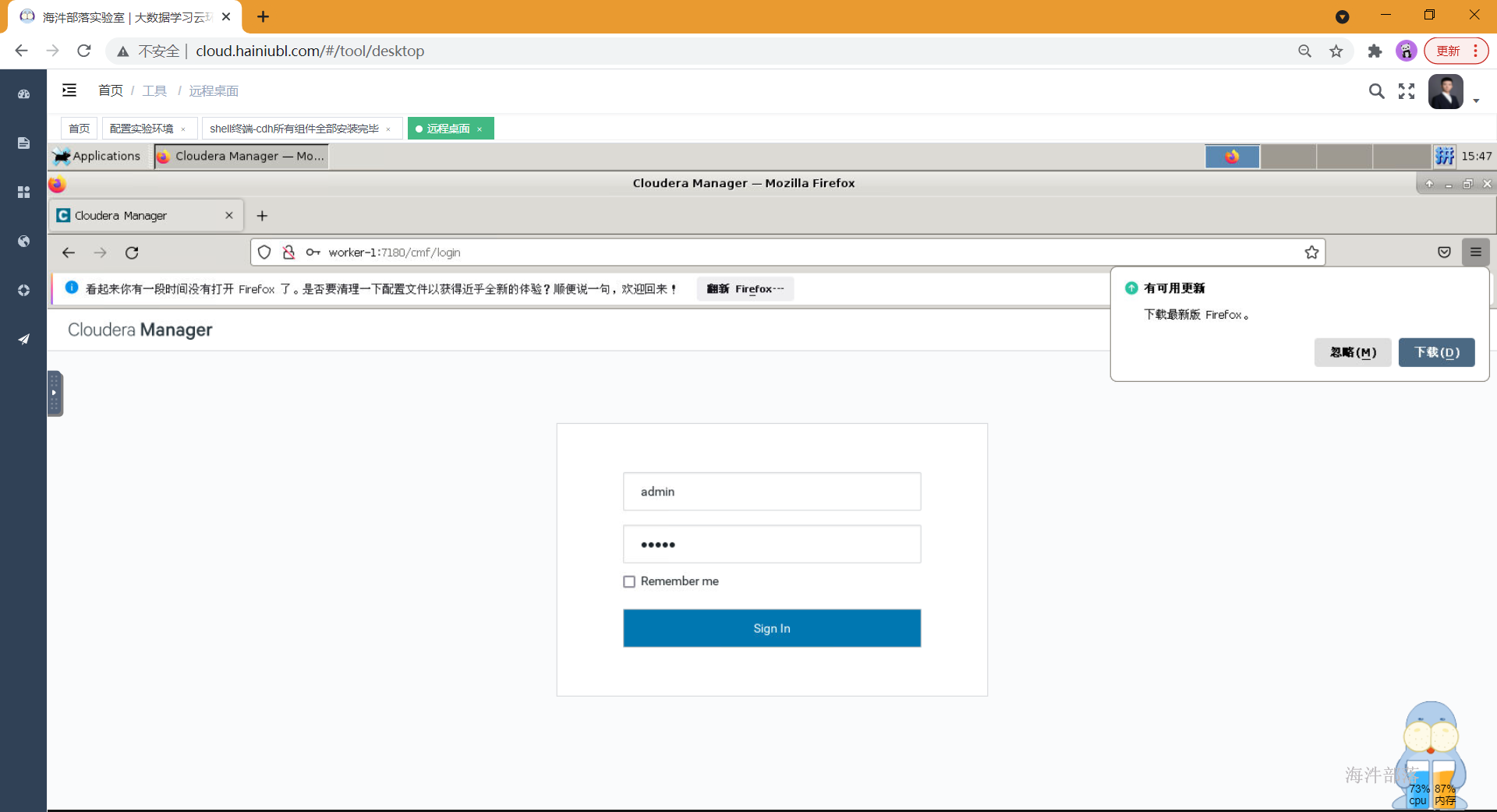
- 重启完镜像之后,需要重启所有组件,等待启动完成即可正常使用。
3 安装hive
3.1 hive概述
Hive是一个基于Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据。它是Facebook 2008年8月开源的一个数据仓库框架,提供了类似于SQL语法的HQL(hiveSQL)语句作为数据访问接口。通常用于离线批处理。
3.2 cdh集成hive
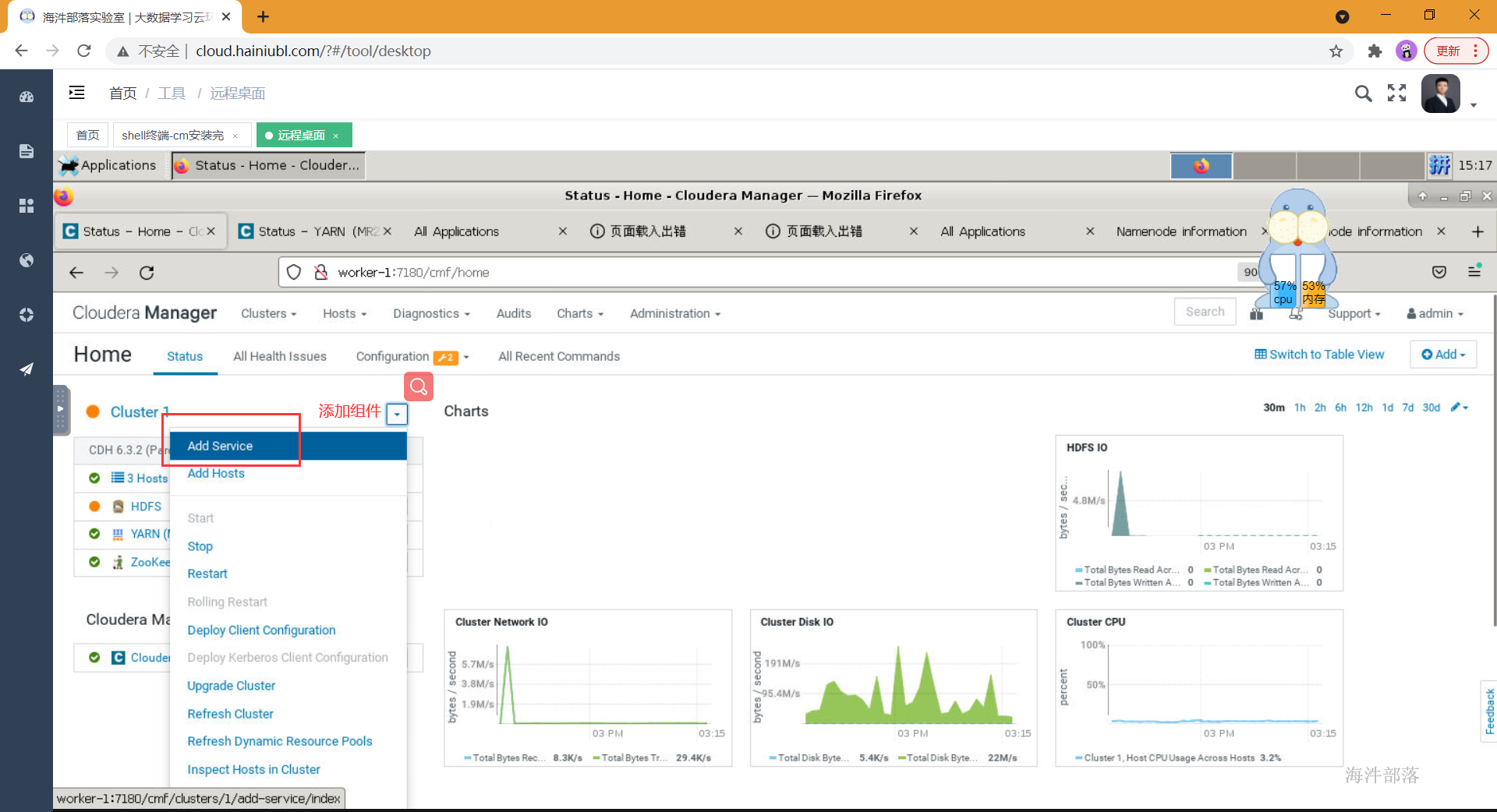
- 选择添加组件
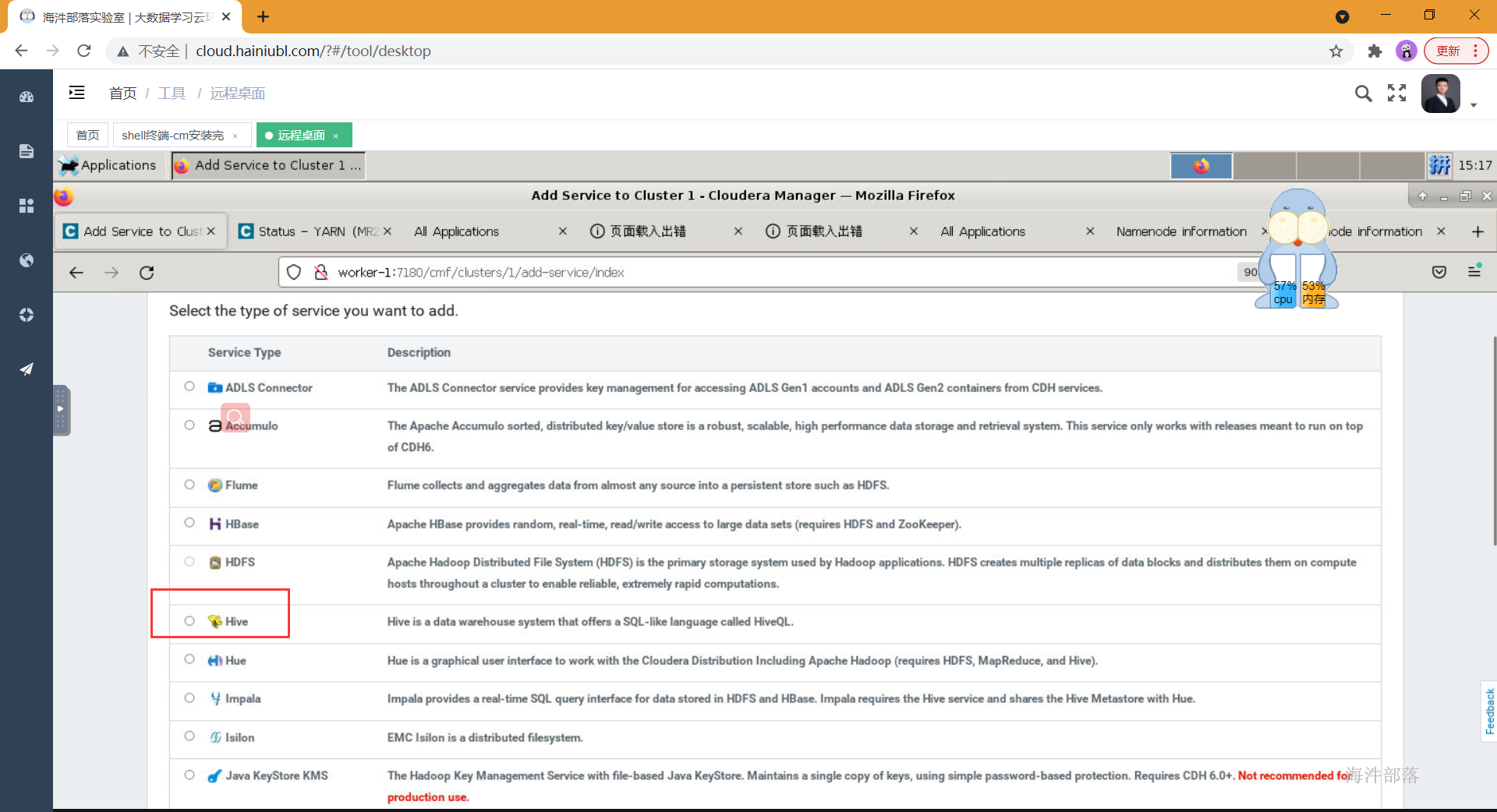
- 选择hive组件
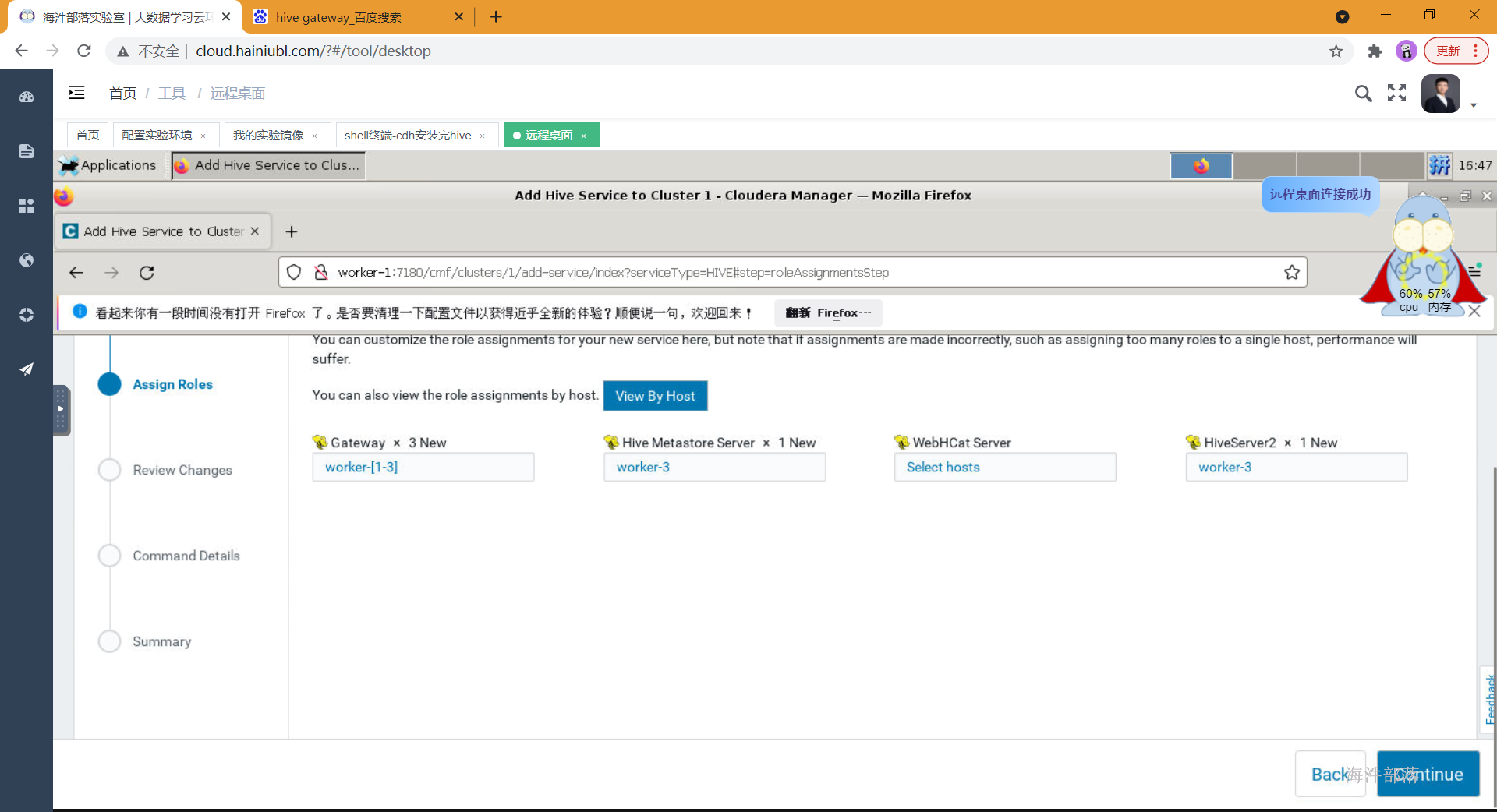
- 选择对应的组件安装到对应的节点上
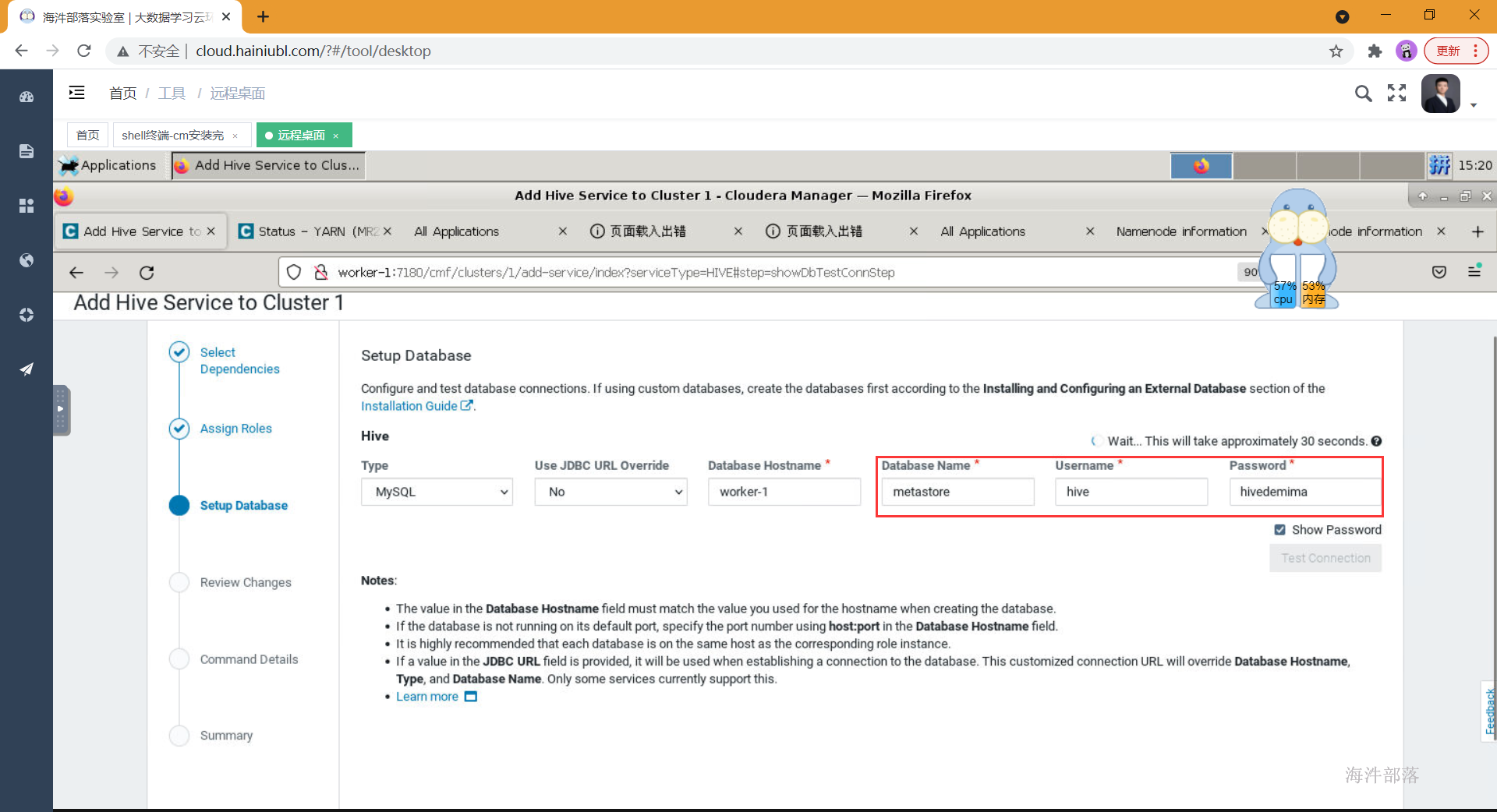
- 配置hive的元数据库,测试连接
- 等待全部启动成功
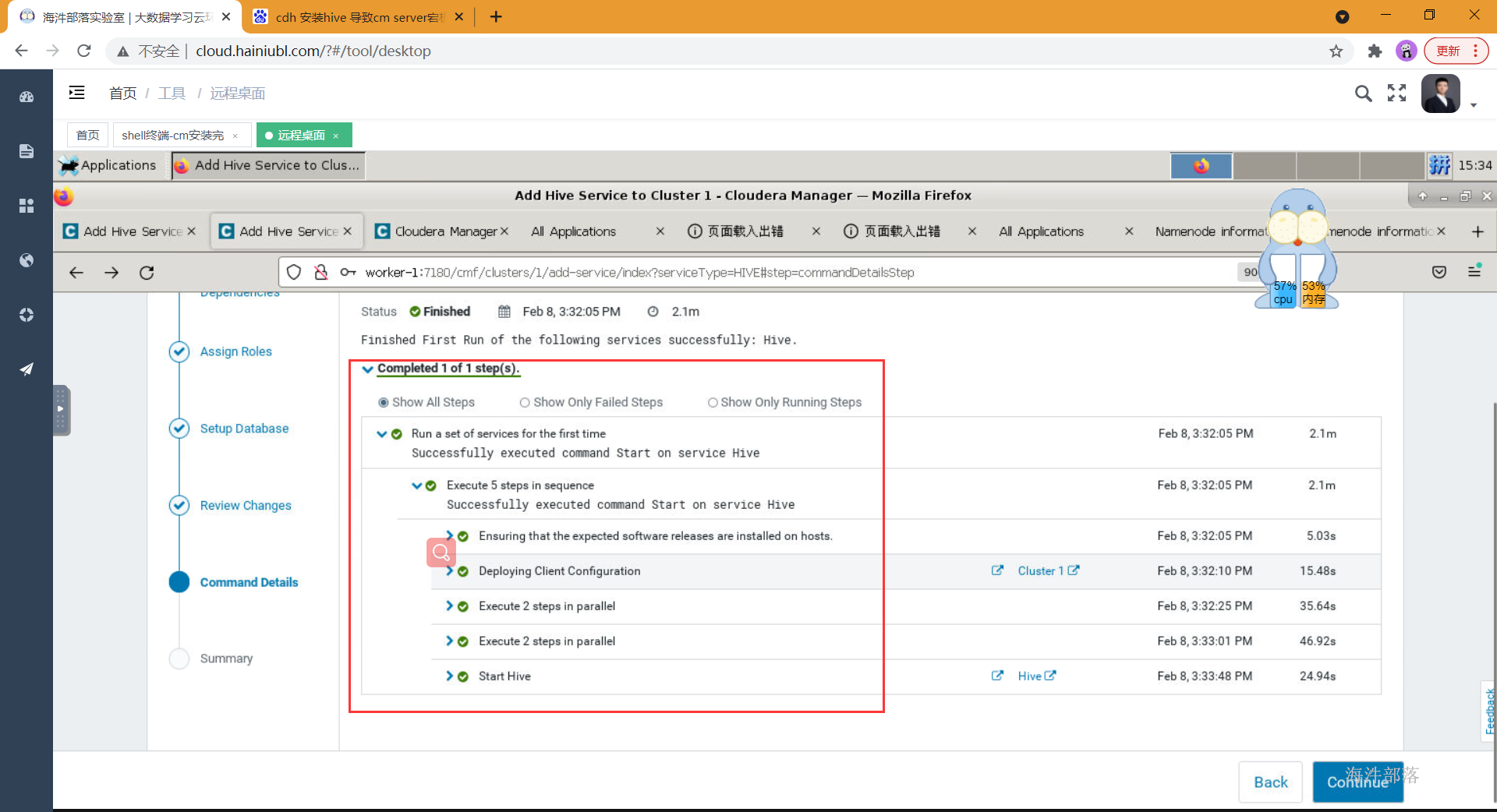
- 最终安装界面
- 通过客户端接口连接hive测试:
#显示所有数据库
show databases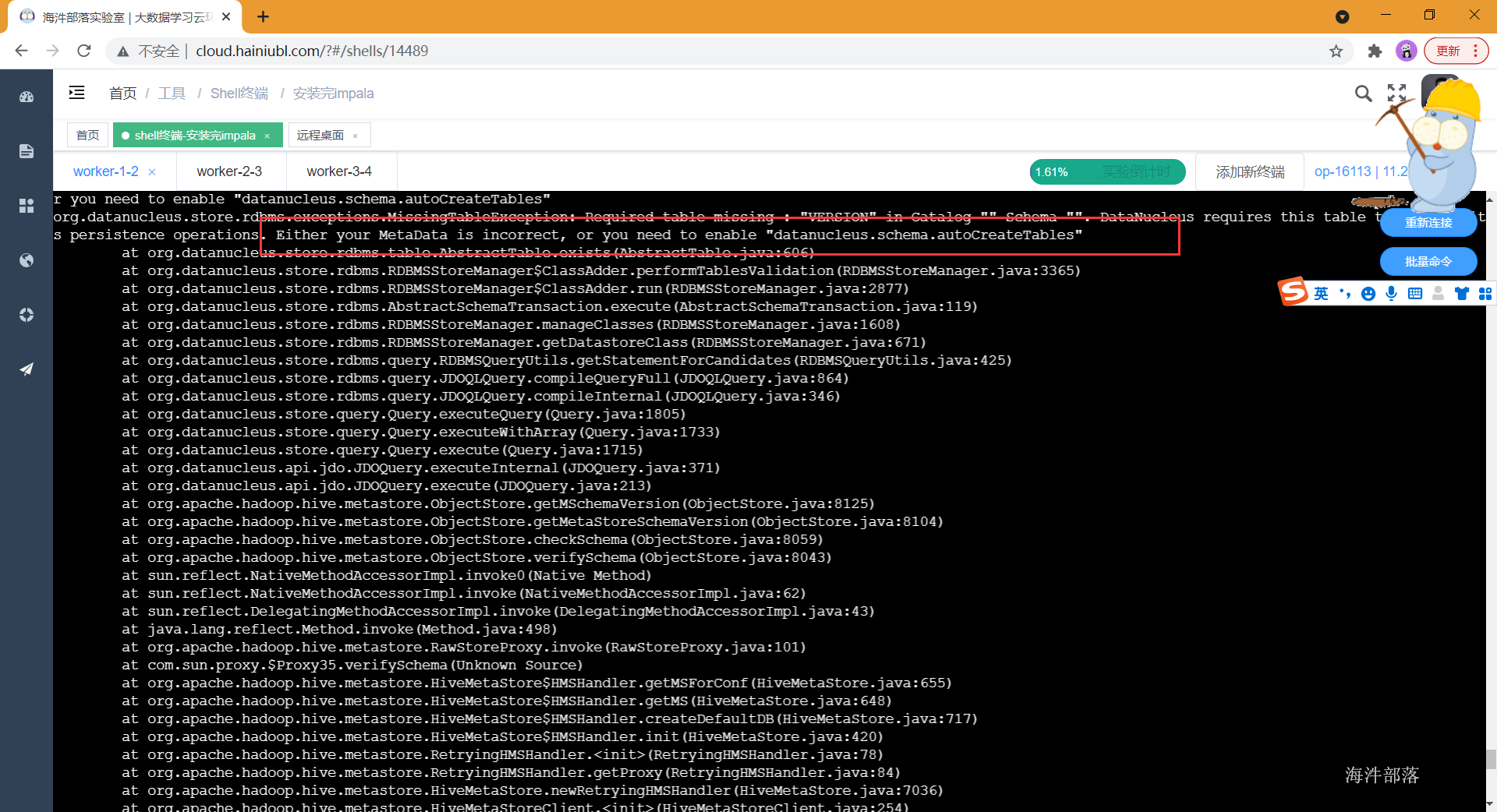
- 需要开启此参数
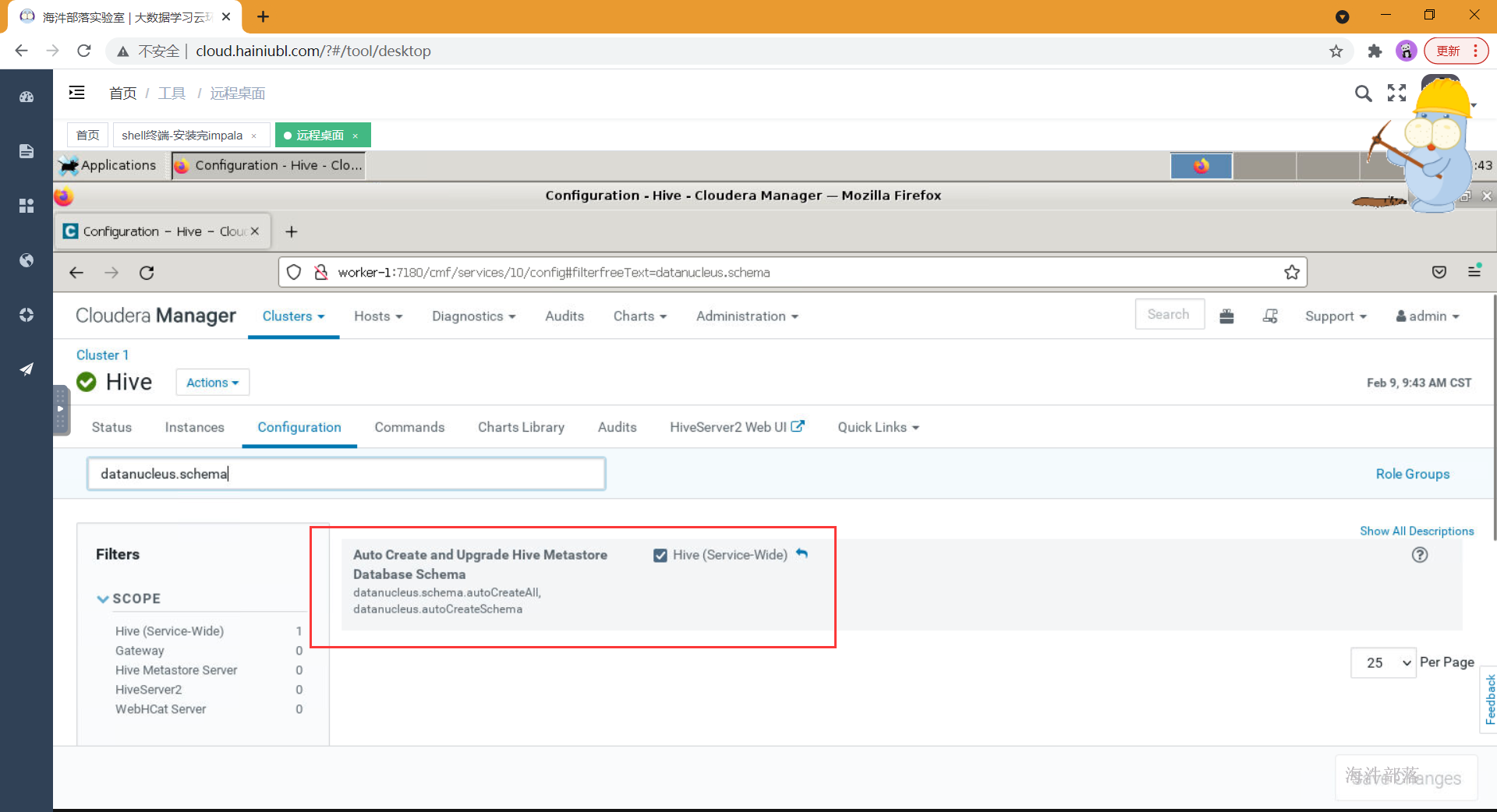
- 连接hive并测试
#创建库
create database demo;
#创建表
create table demotab(id int,name string);
#插入数据
insert into demotab values(1,'zs')- 通过beeline连接hive并测试
#jdbc:hive2://xxx:10000 xxx代表hiveserver2服务所在的ip或者主机名
beeline -u jdbc:hive2://worker-3:10000 -n root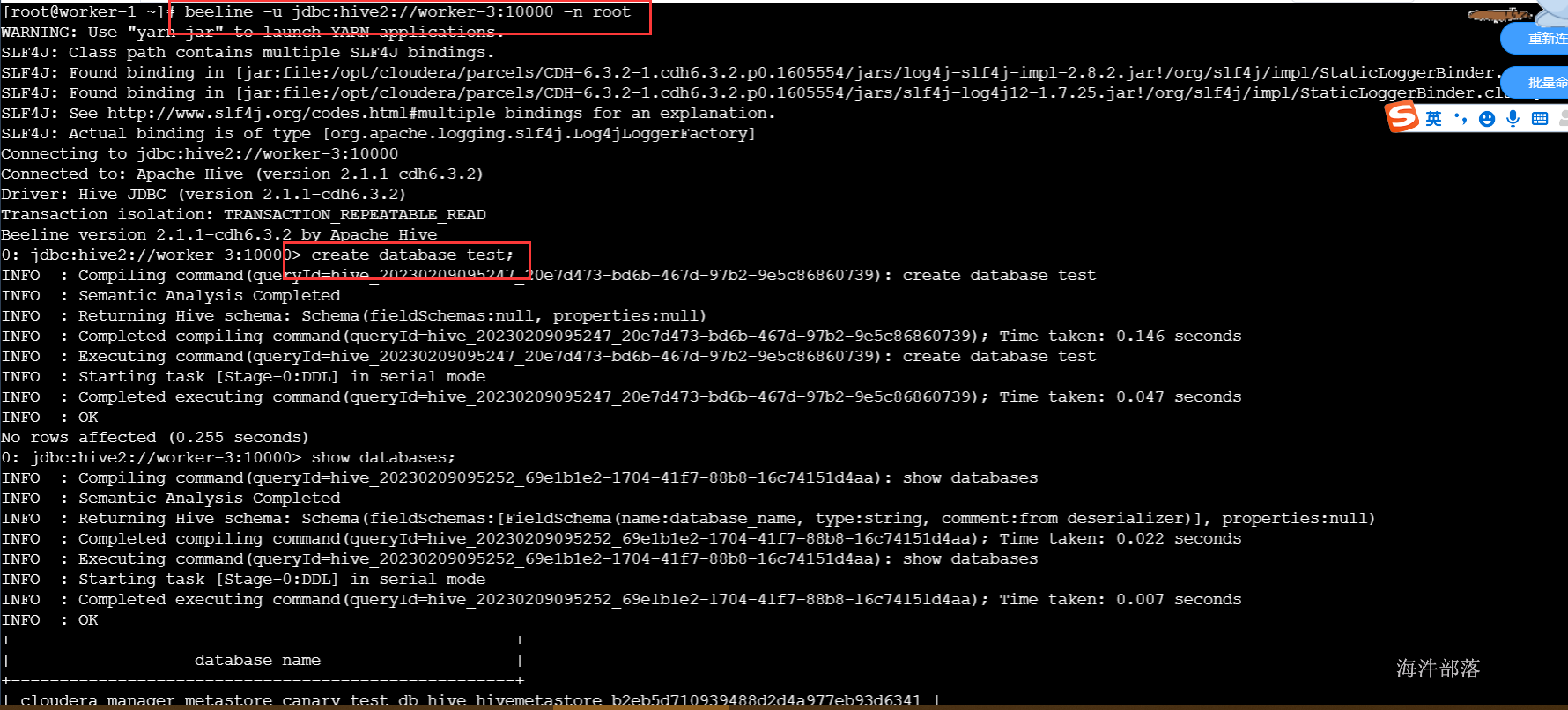
4 安装hbase
4.1 hbase概述
HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随机读写操作,HBase正是为此而出现。HBase参考 Google 的 Bigtable 实现,以键值对的形式存储。项目的目标就是快速在主机内数十亿行数据中定位所需的数据并访问它。
- 建立在HDFS之上的分布式面向列的数据库
- KV结构数据库,原生不支持标准SQL,属于NOSQL数据库
- 支持快速随机读写海量数据
- 具备HDFS的高容错能力
- 不属于关系型数据库,适合存储非结构化数据
4.2 cdh集成hbase
- 选择添加组件
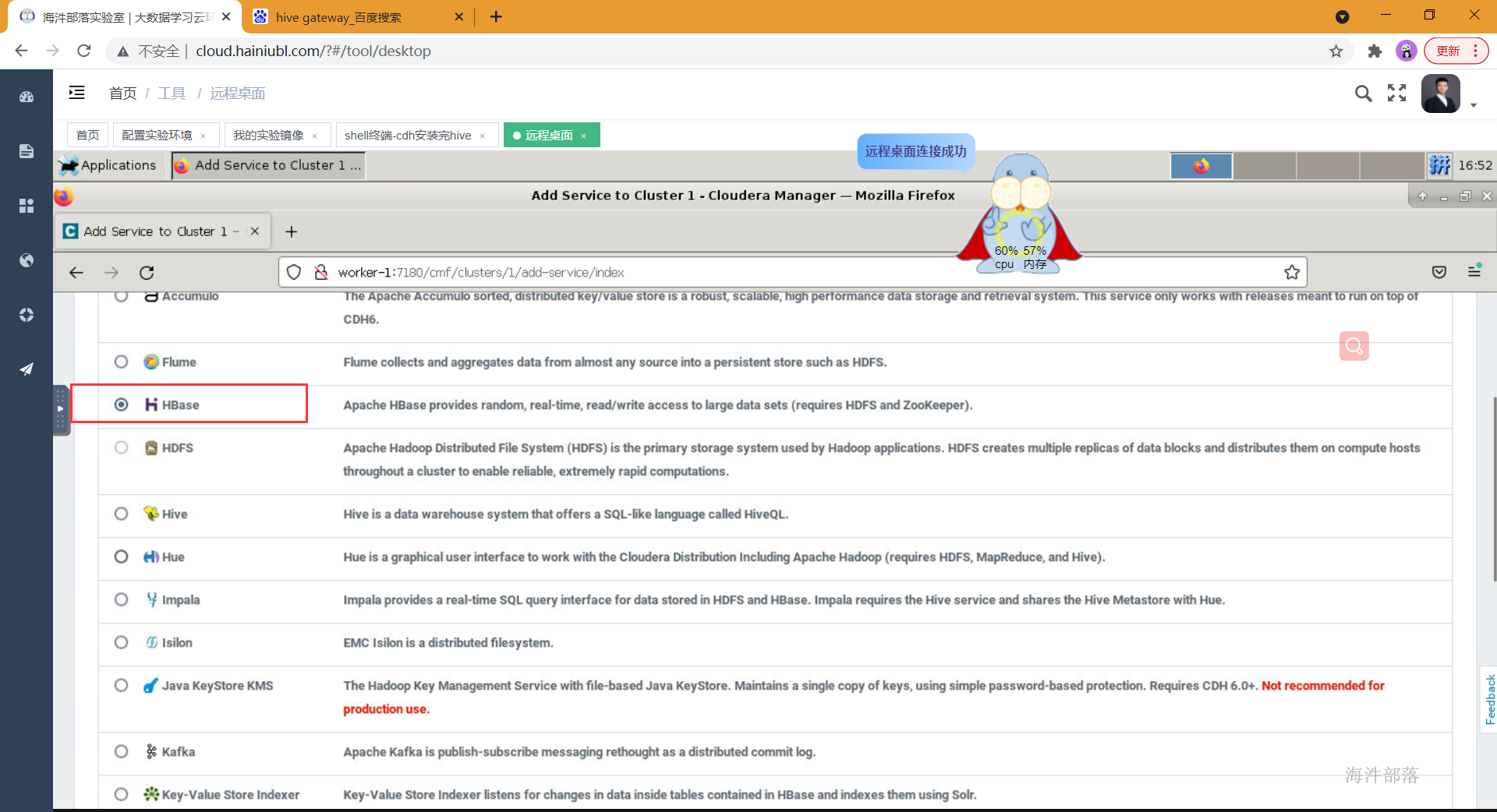
- 选择hbase组件
- 选择相应的组件安装到哪台节点
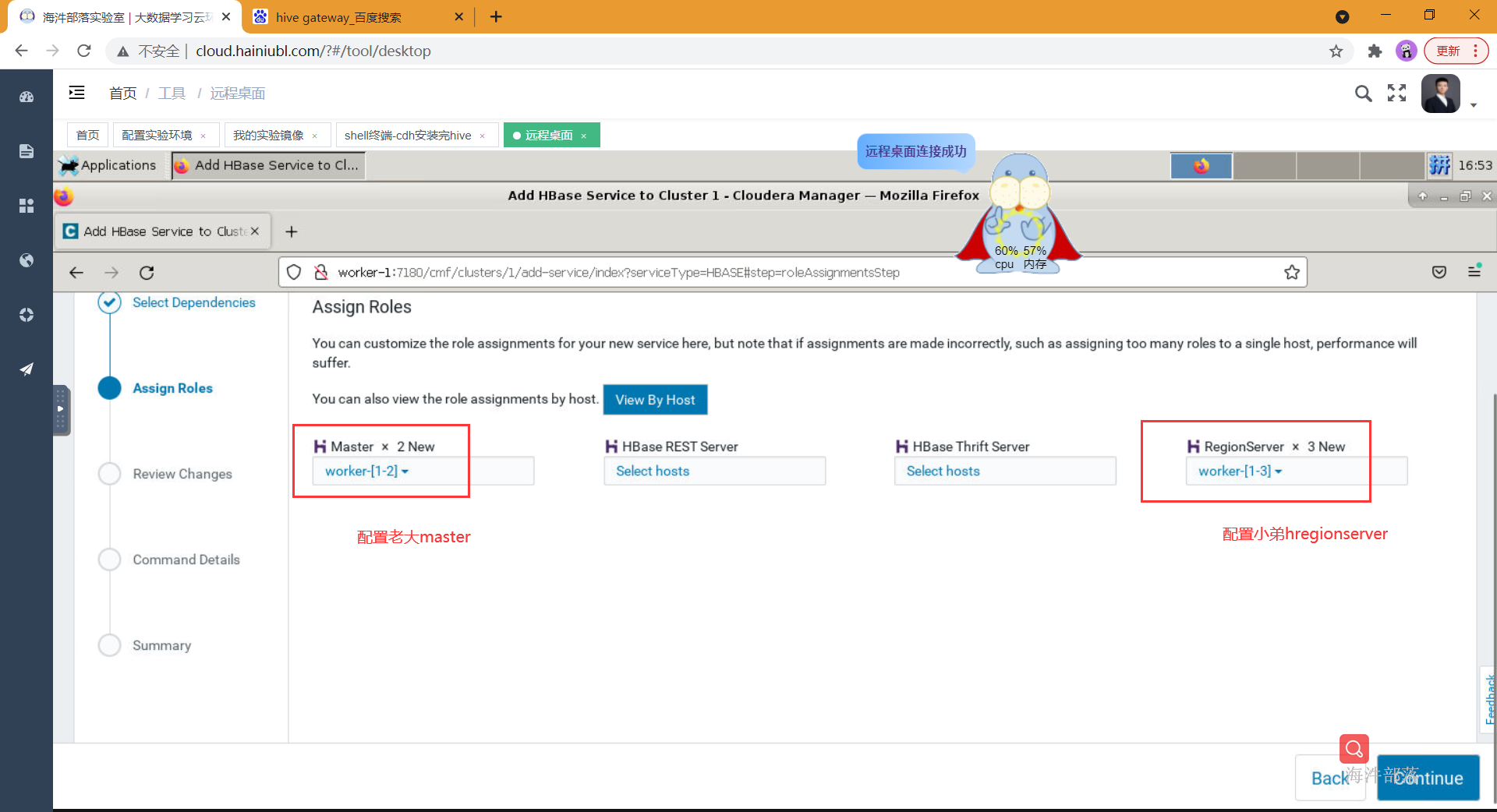
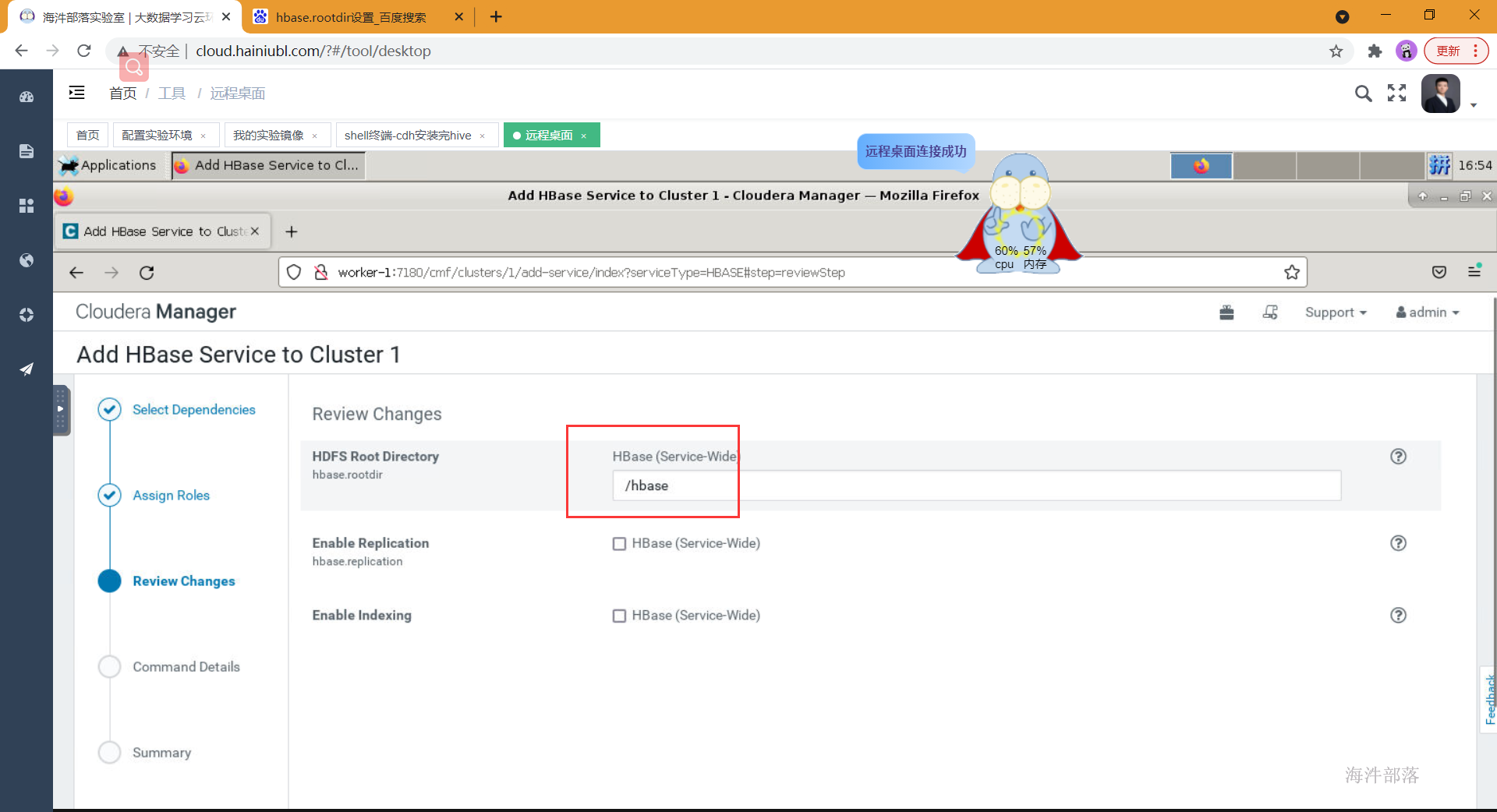
- 设置hbase在hdfs数据存放的目录
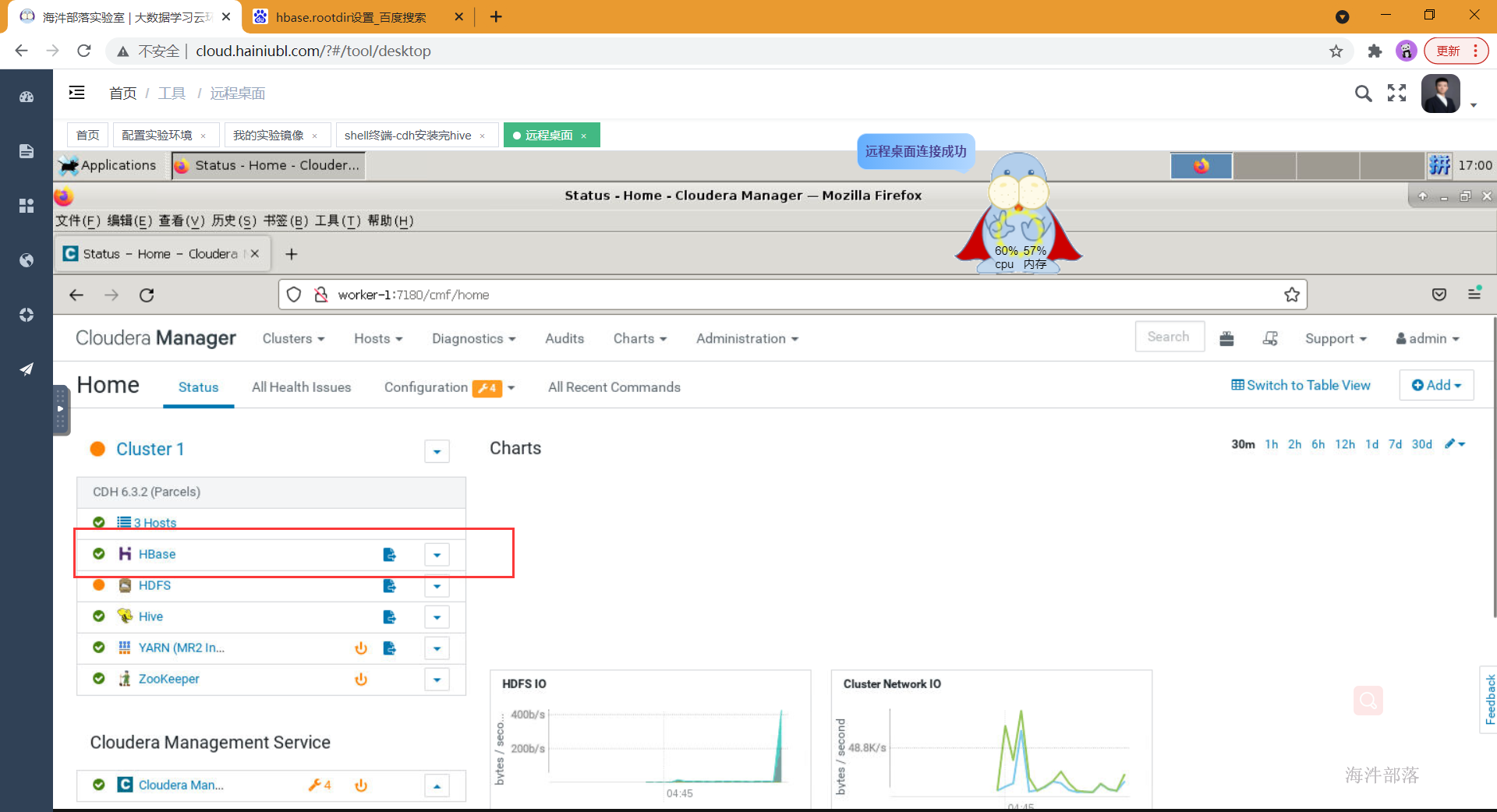
5.等待安装成功并启动hbase
- 启动hbase 并测试
[root@worker-1 ~]# hbase shell
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.1.0-cdh6.3.2, rUnknown, Fri Nov 8 05:44:07 PST 2019
Took 0.0008 seconds
hbase(main):001:0> create_namespace 'hainiu'
Took 1.1227 seconds
hbase(main):002:0> create 'hainiu:demo','cf1','cf2'
Created table hainiu:demo
Took 2.4512 seconds
=> Hbase::Table - hainiu:demo
hbase(main):003:0> put 'hainiu:demo','x0001','cf1:name','zhangsan'
Took 0.4682 seconds
hbase(main):004:0> scan 'hainiu:demo'
ROW COLUMN+CELL
x0001 column=cf1:name, timestamp=1675907703421, value=zhangsan
1 row(s)
Took 0.1364 seconds
hbase(main):005:0> 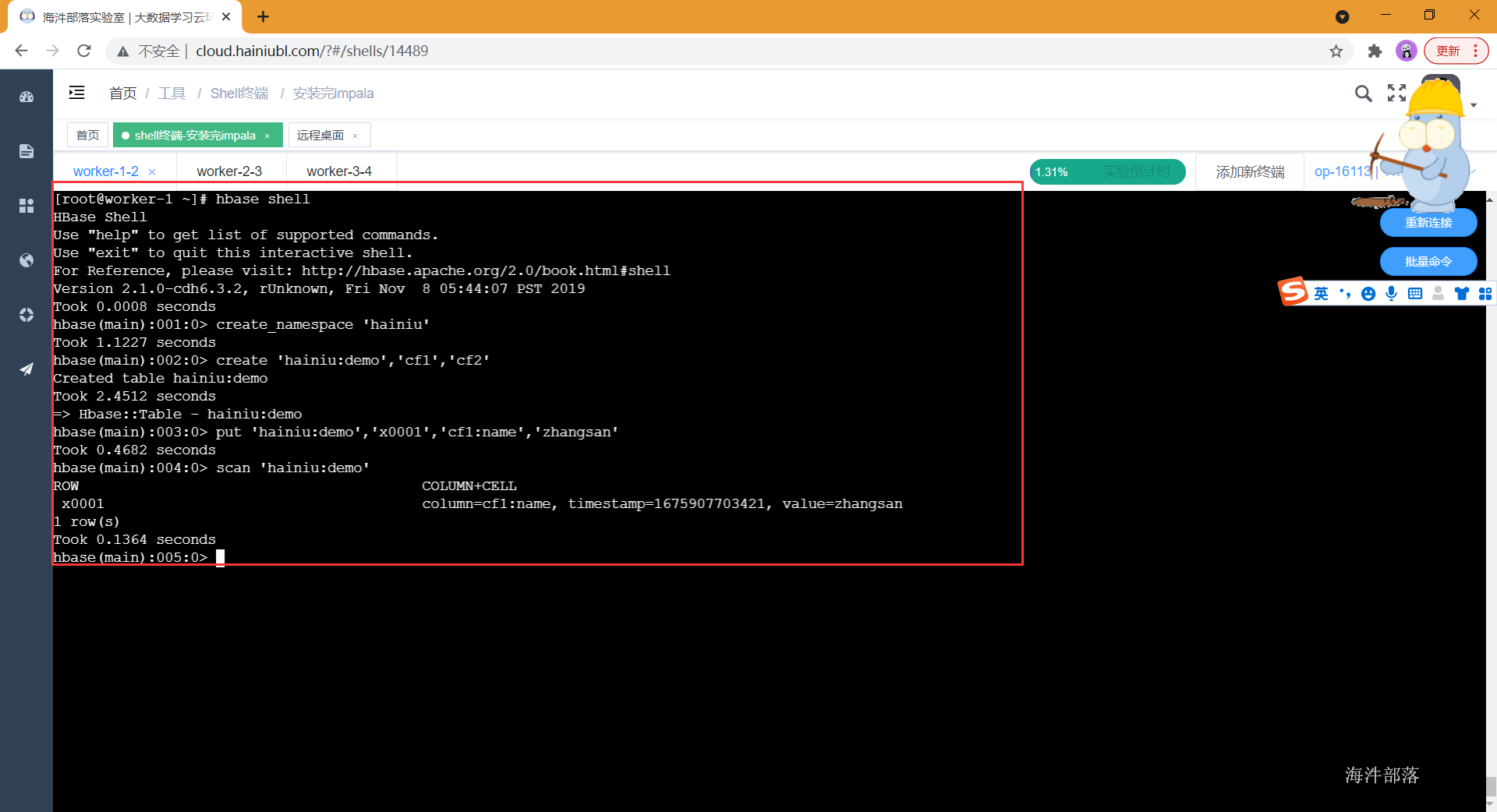
5 安装 impala
5.1 impala概述
Cloudera Impala是一款开源的MPP架构的SQL查询引擎,它提供在hadoop环境上的低延迟、高并发的BI/数据分析,是一款开源、与Hadoop高度集成,灵活可扩展的查询分析引擎,目标是基于SQL提供高并发的即席查询。
与其他的查询引擎系统(如presto、spark sql、hive sql)不同,Impala基于C++和Java编写,支持Hadoop生态下的多种组件集成(如HDFS、HBase、Metastore、YARN、Sentry等),支持多种文件格式的读写(如Parqeut、Avro、RCFile等)。
5.2 cdh集成impala
- 选择组件并安装
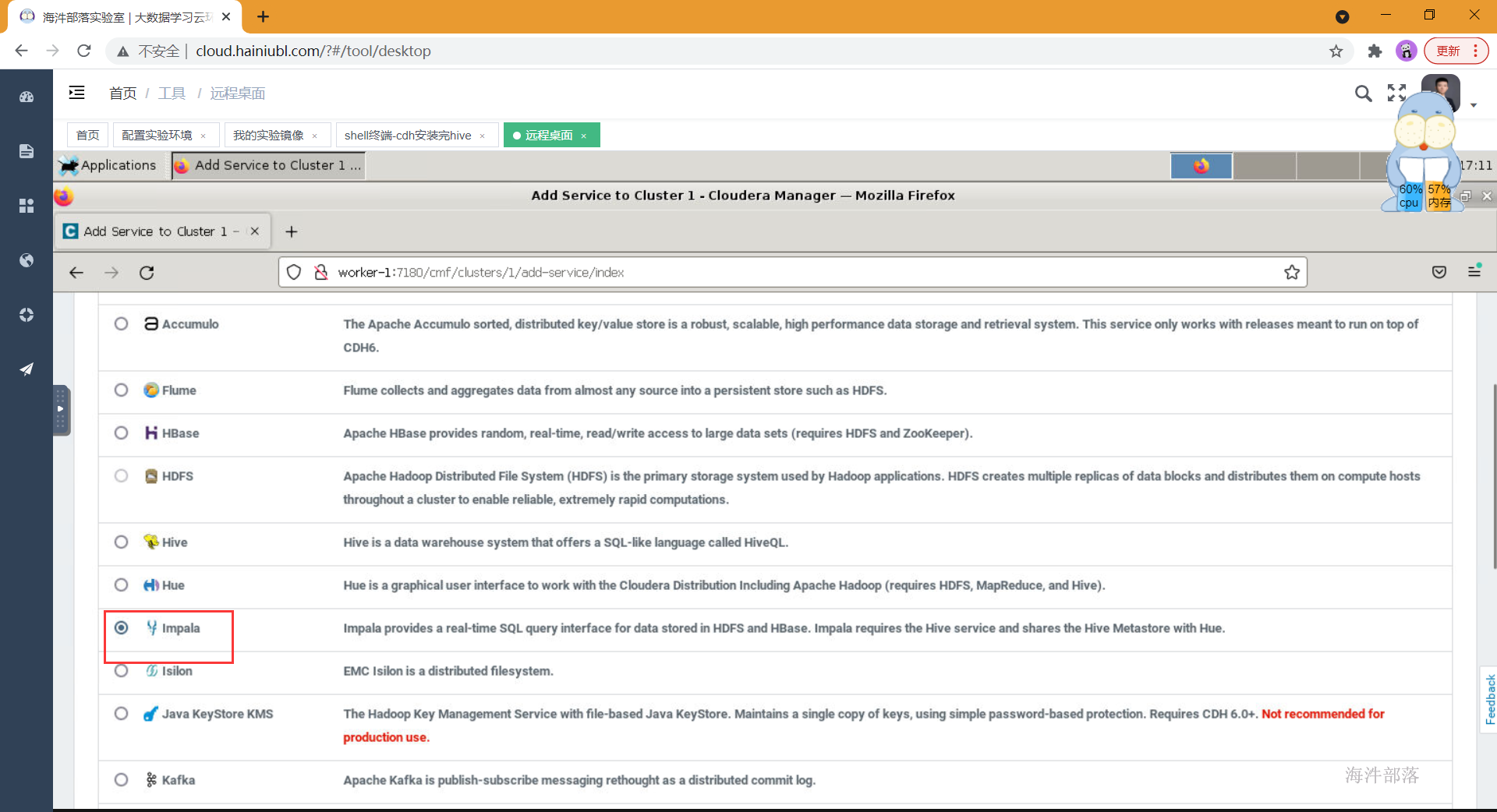
- 选择依赖
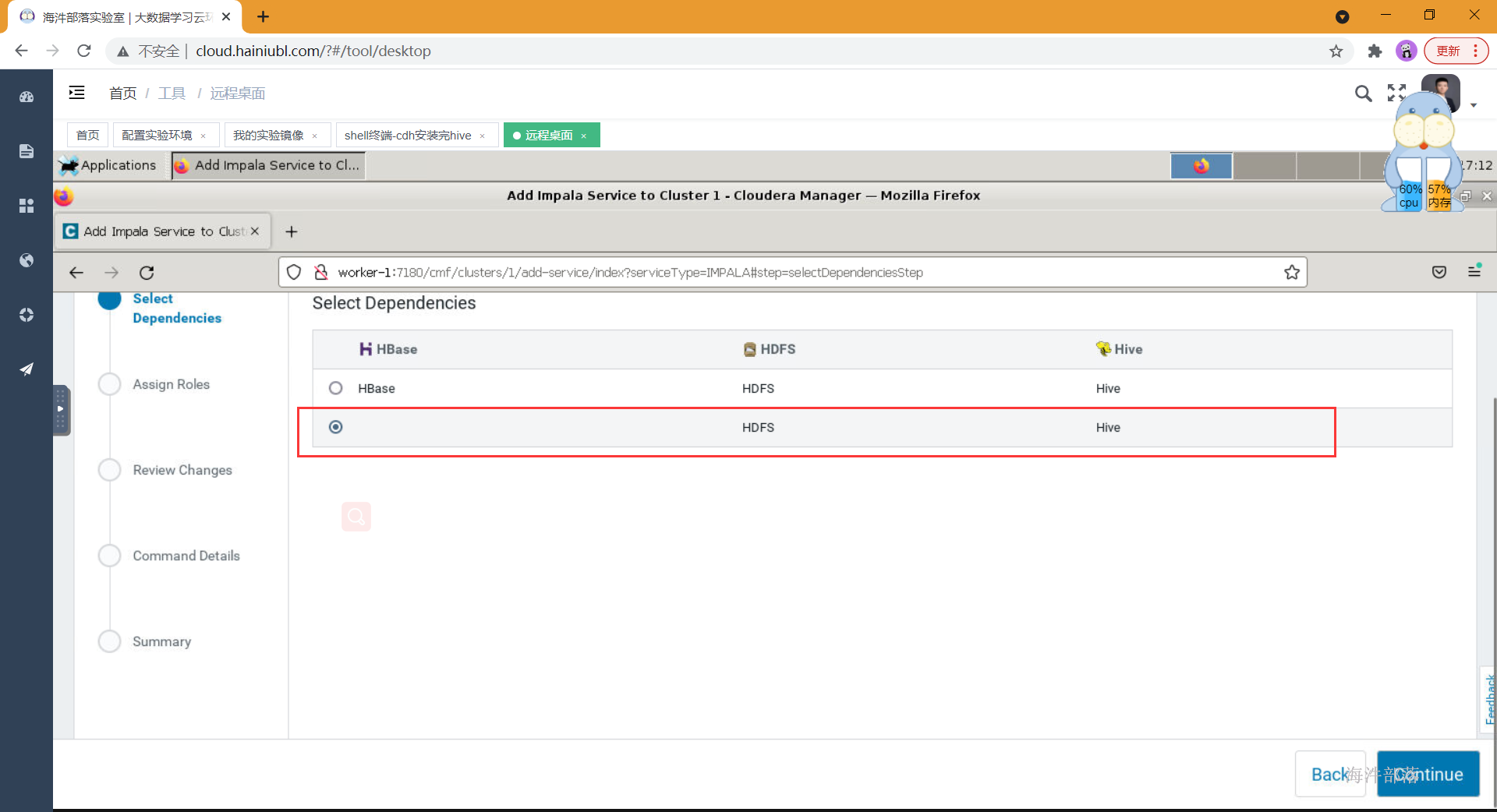
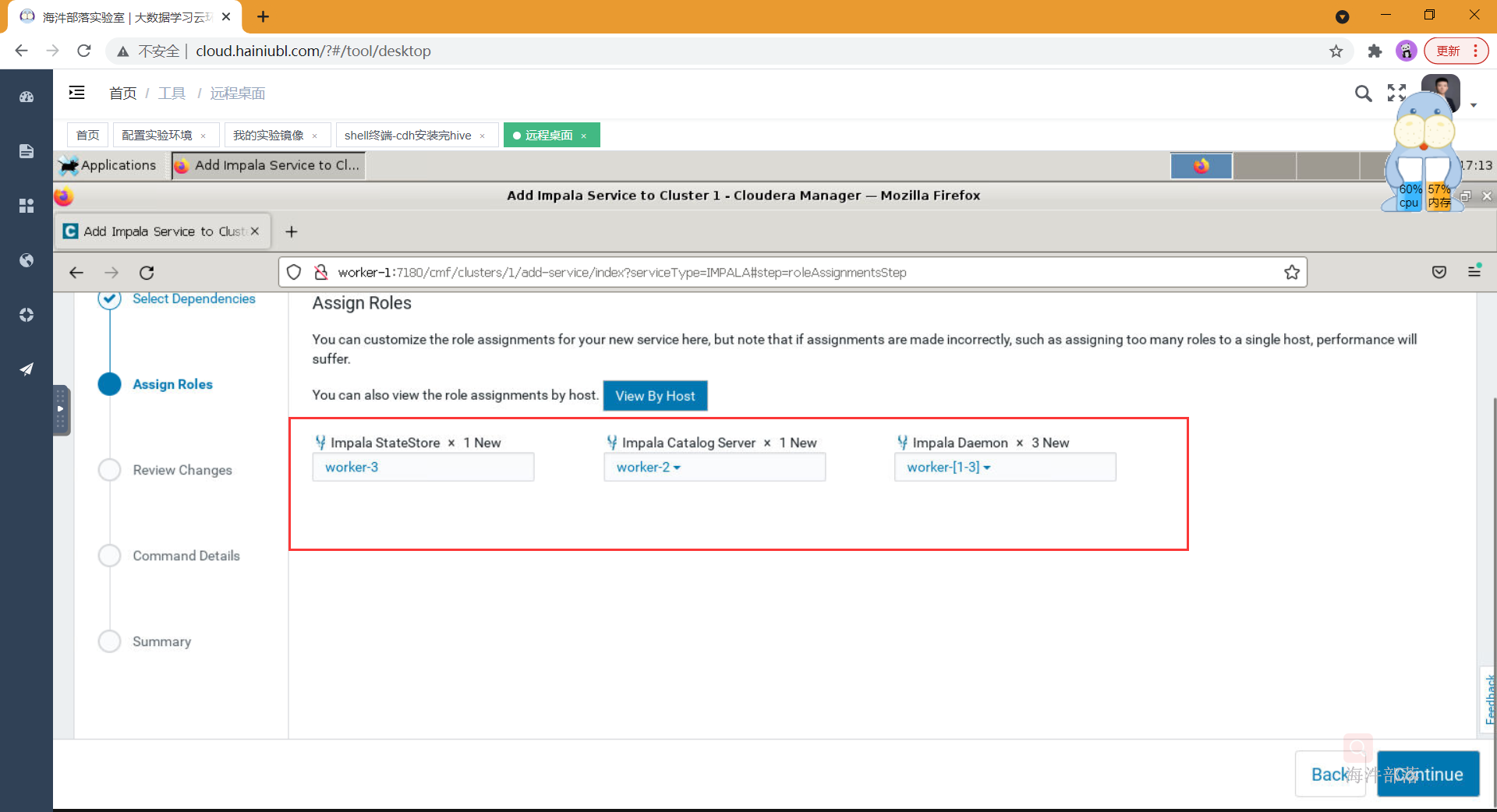
- 分配角色到相应的节点
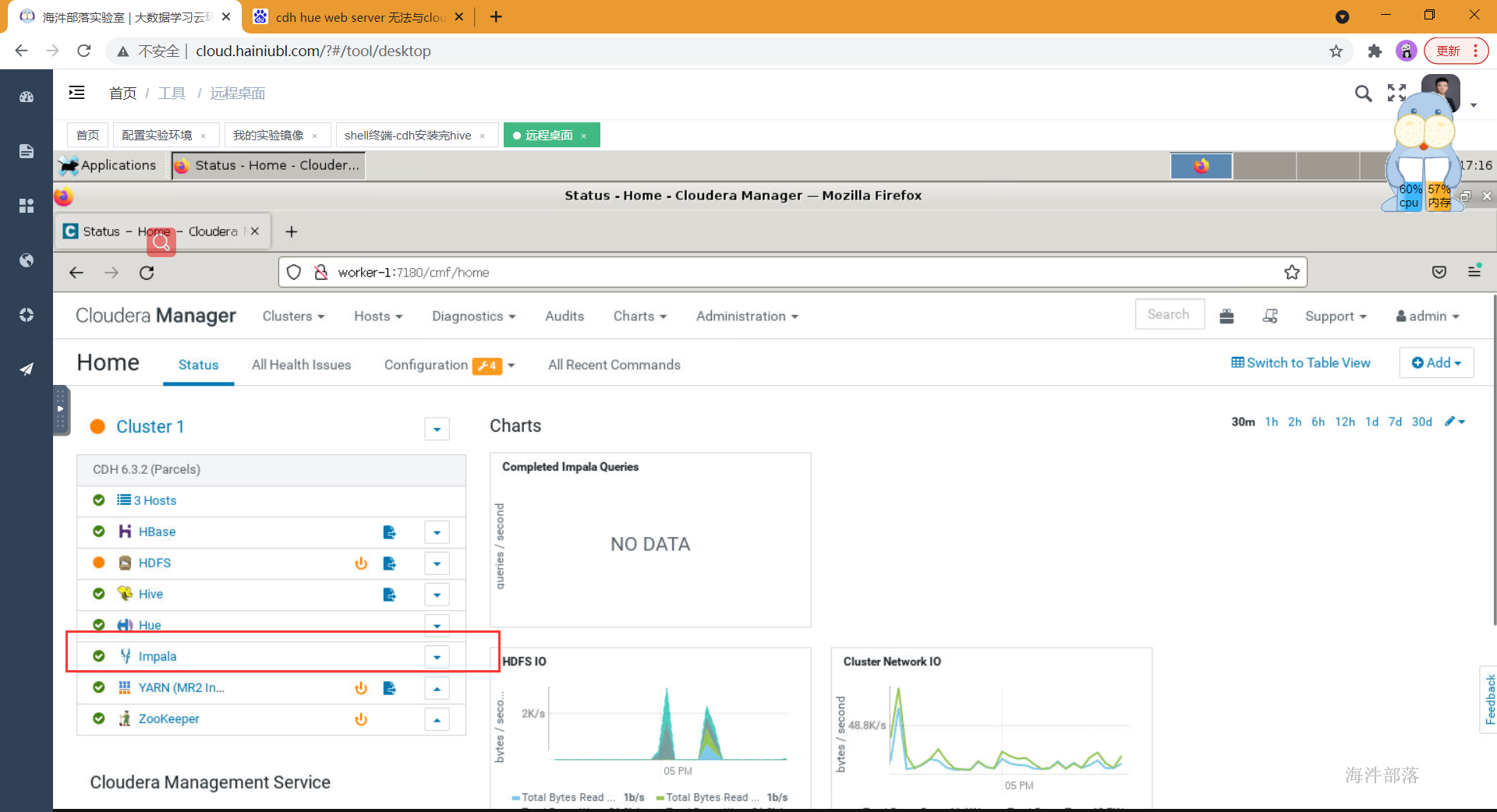
- 安装成功并启动impala组件
- 启动并测试
#启动impala
impala-shell -i worker-1
#剩下语法和hive类似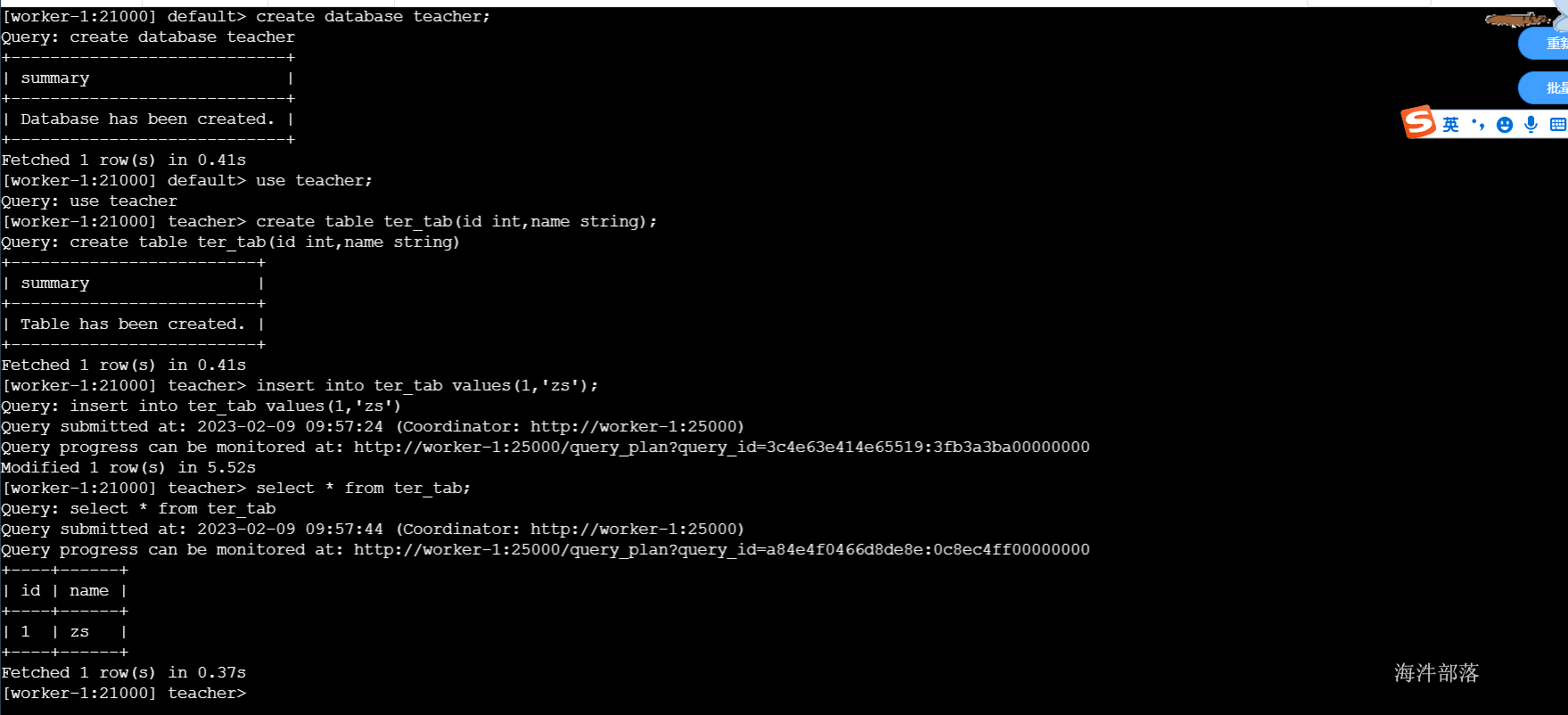
如果impala查询数据一直卡着不动。
可以添加一下配置信息,重启impala即可正常使用
--rpc_encryption=disabled
--rpc_authentication=disabled
--trusted_subnets=0.0.0.0/0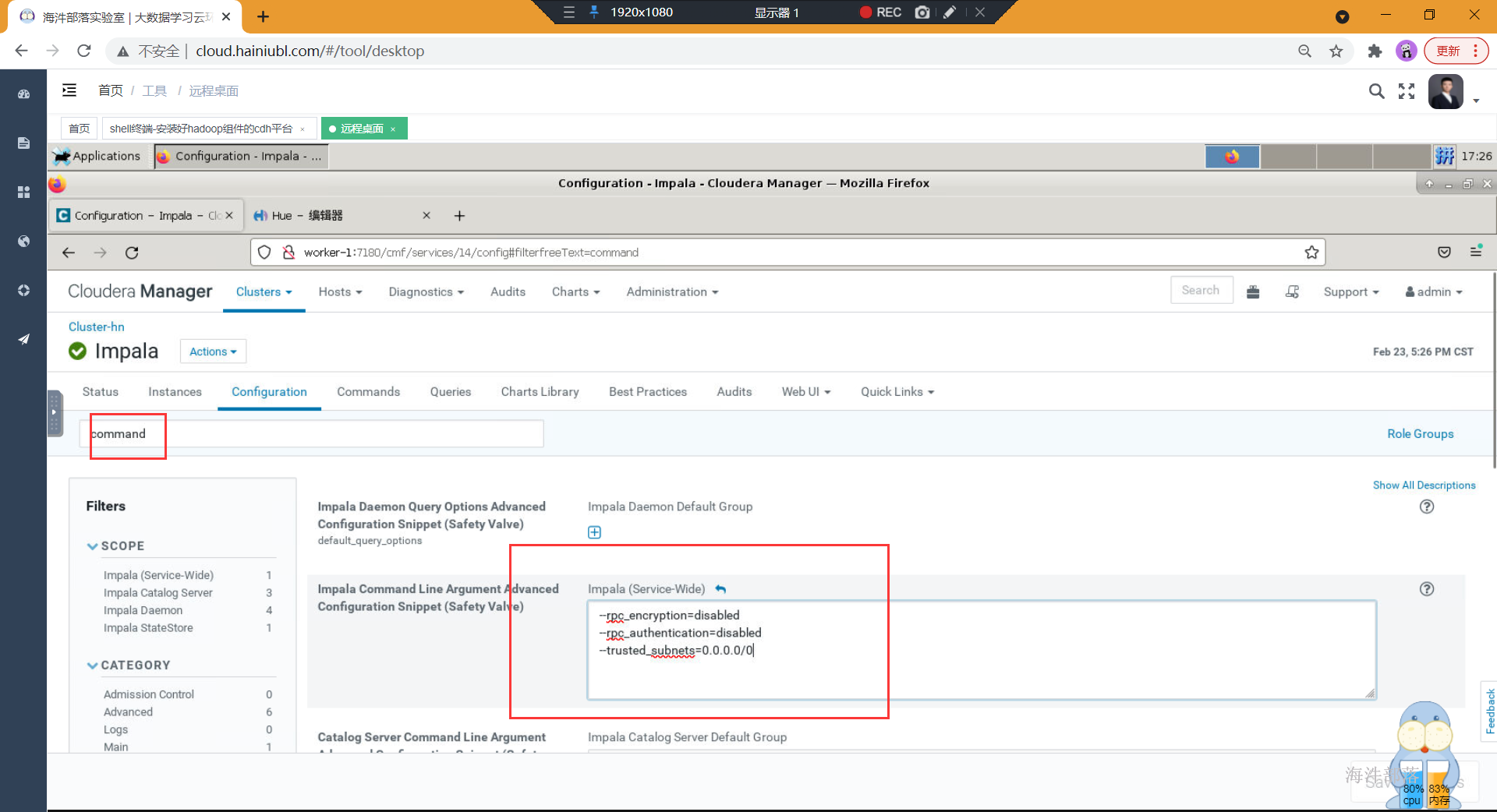
6 安装oozie
6.1 oozie概述
Oozie 是一个工作流调度系统用来管理 Hadoop 任务,将多个任务定义成工作流,定义好的工作流以DAG的方式按照指定的顺序运行我们的job任务
安装hue需要提前安装ooize
6.2 cdh集成oozie
- 选择组件并安装
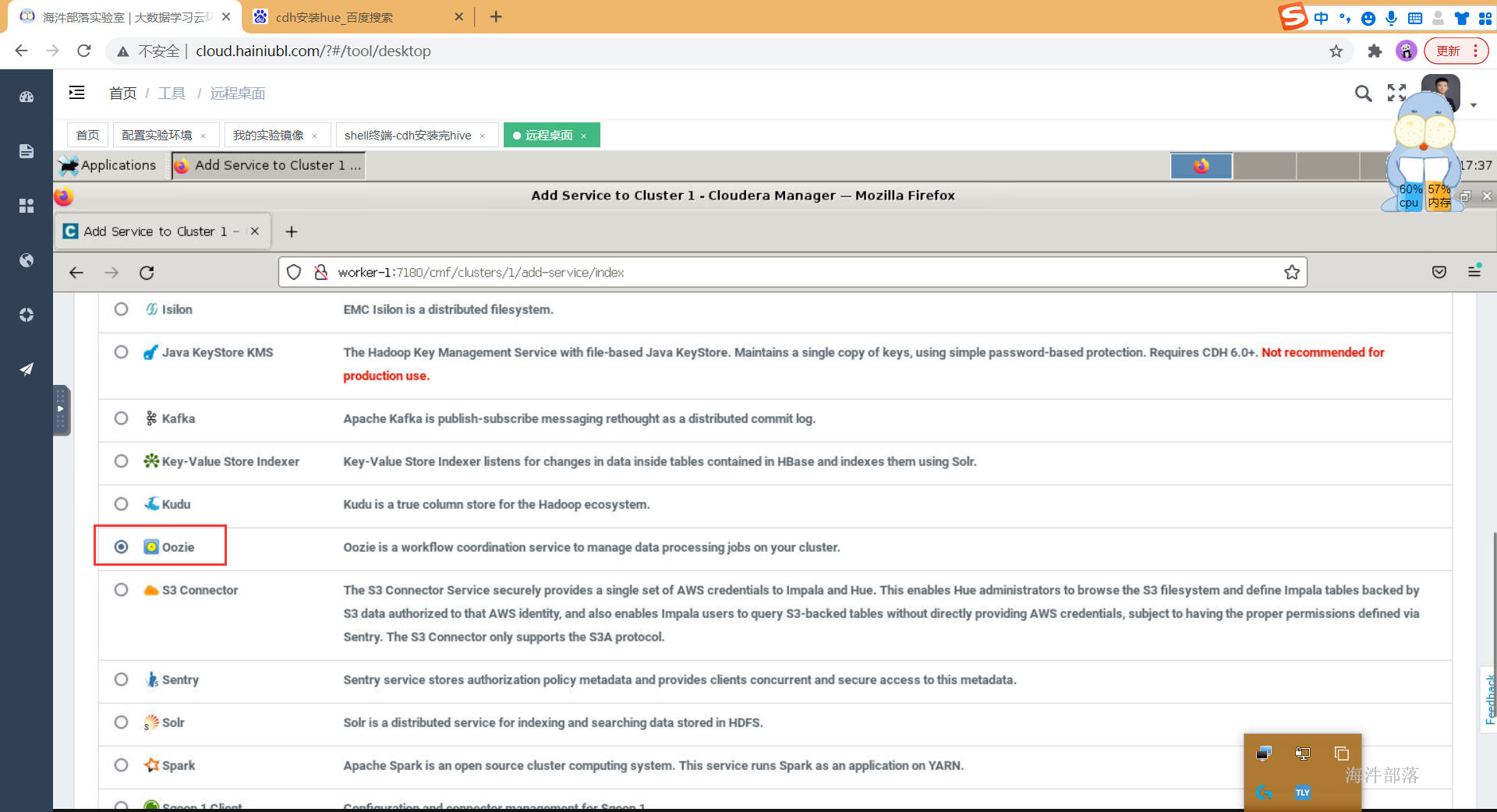
- 选择依赖
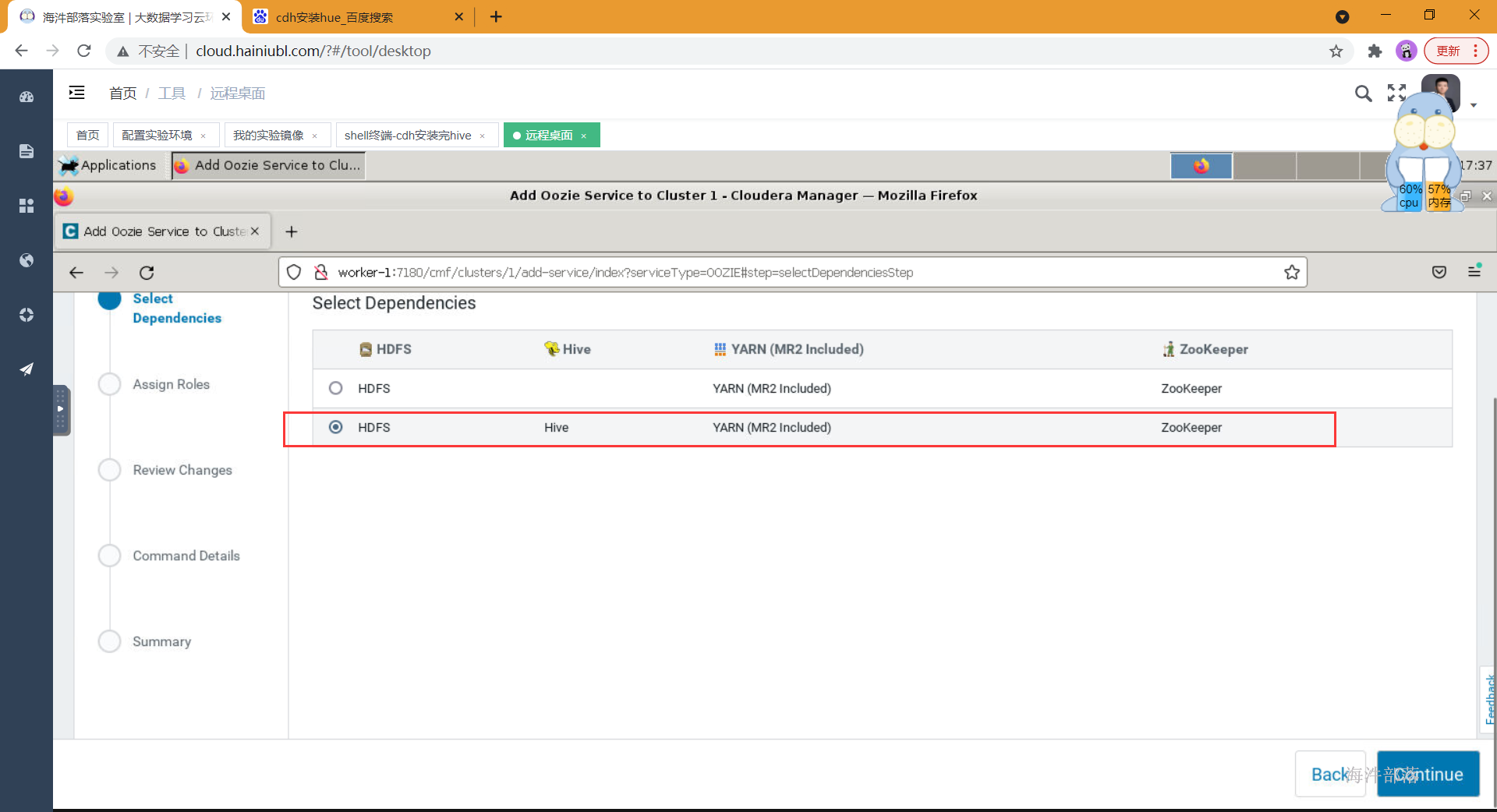
- 分配角色到节点
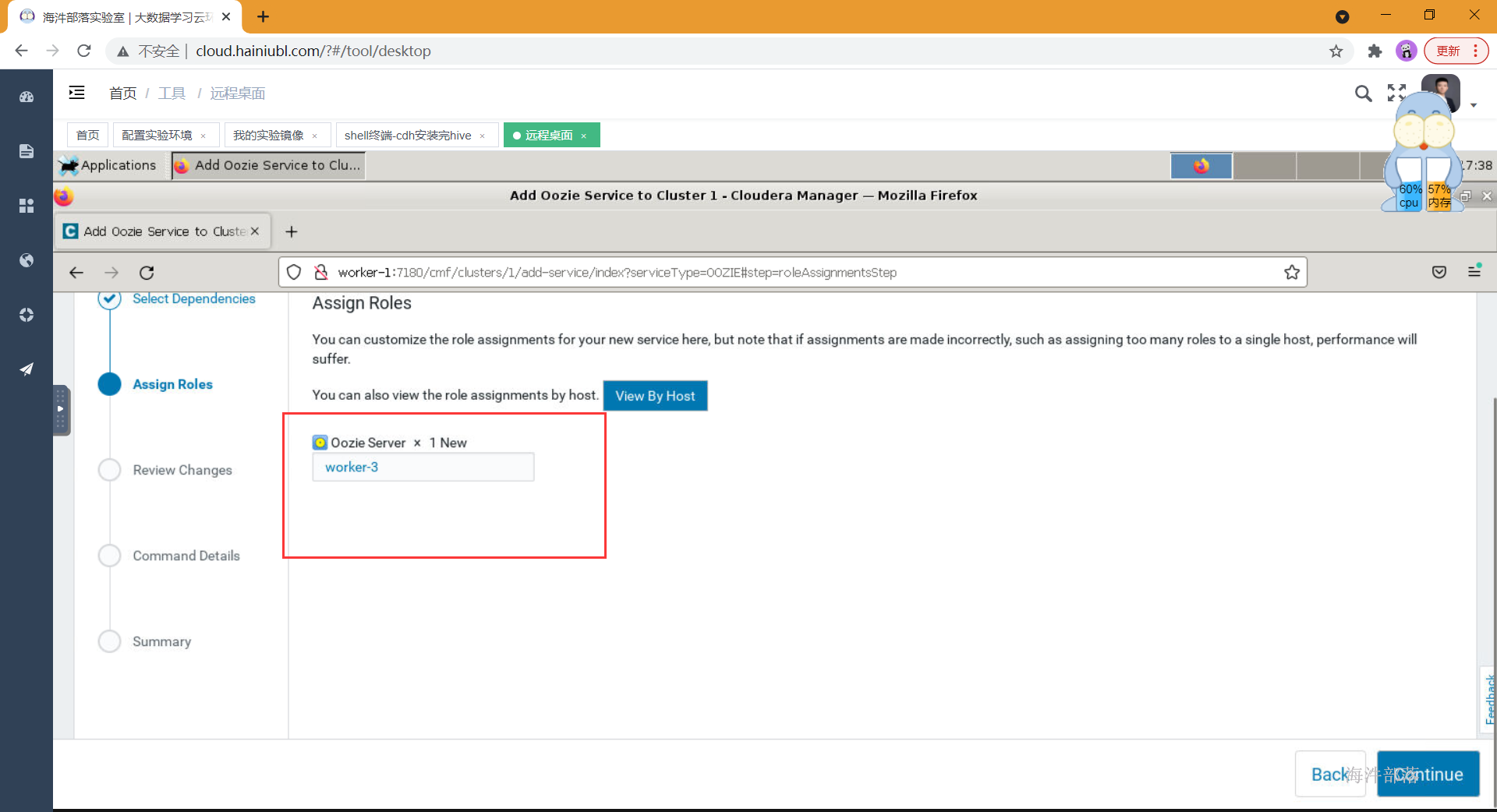
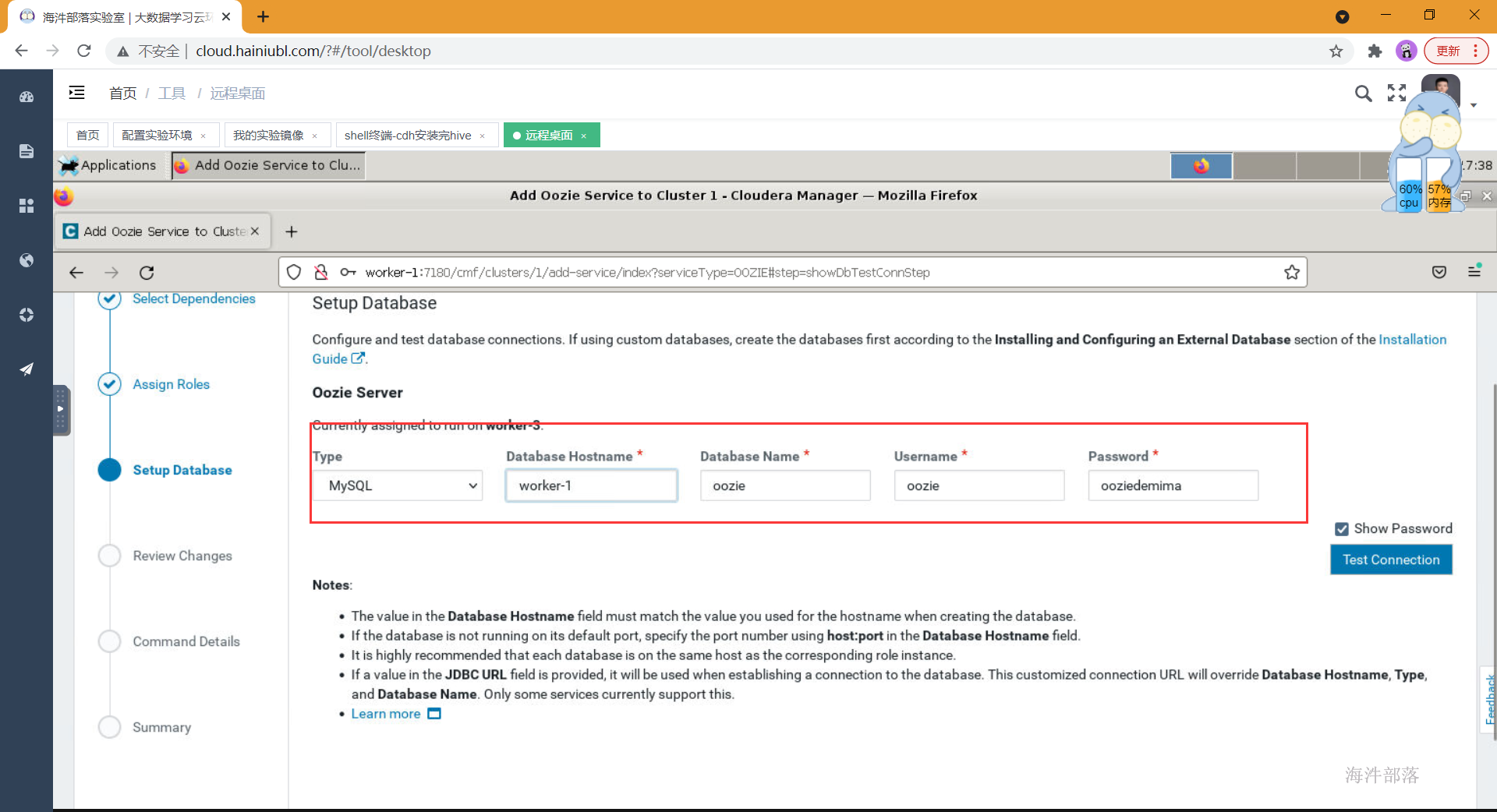
- 选择oozie对应的库和密码
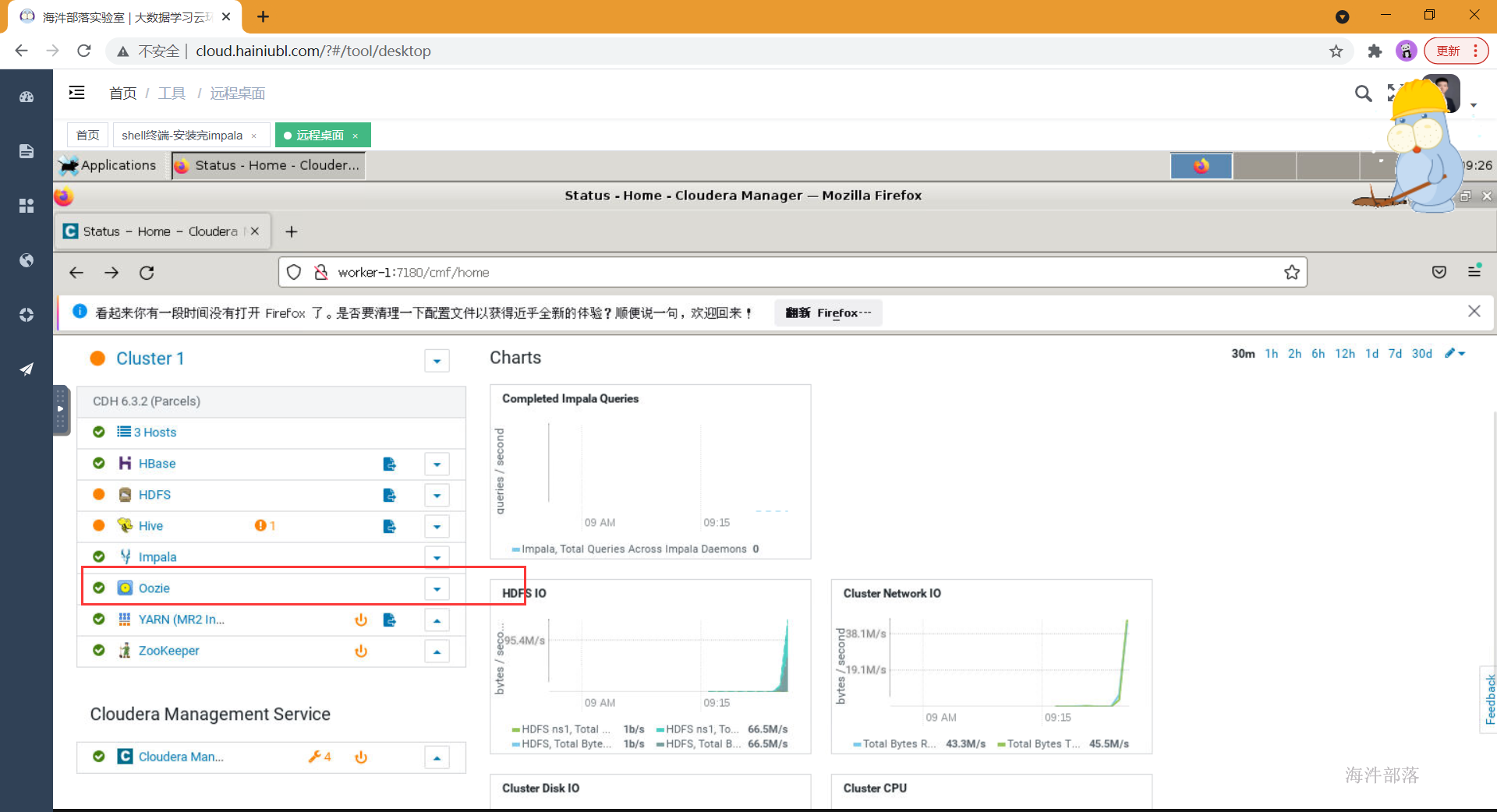
- 安装成功并启动
7 安装 hue
7.1 hue概述
Hue是一个能够与Apache Hadoop交互的Web应用程序。一个开源的Apache Hadoop UI
简单理解:hue提供了一个可视图的webui界面,通过sql编辑器可以对数据进行增删改查。
- SQL编辑器:支持Hive, Impala, MySQL, Oracle, PostgreSQL, SparkSQL, Solr SQL, Phoenix…
7.2 cdh集成hue
安装之前必须先安装好oozie
- 选择hue组件并添加
2.选择相应依赖
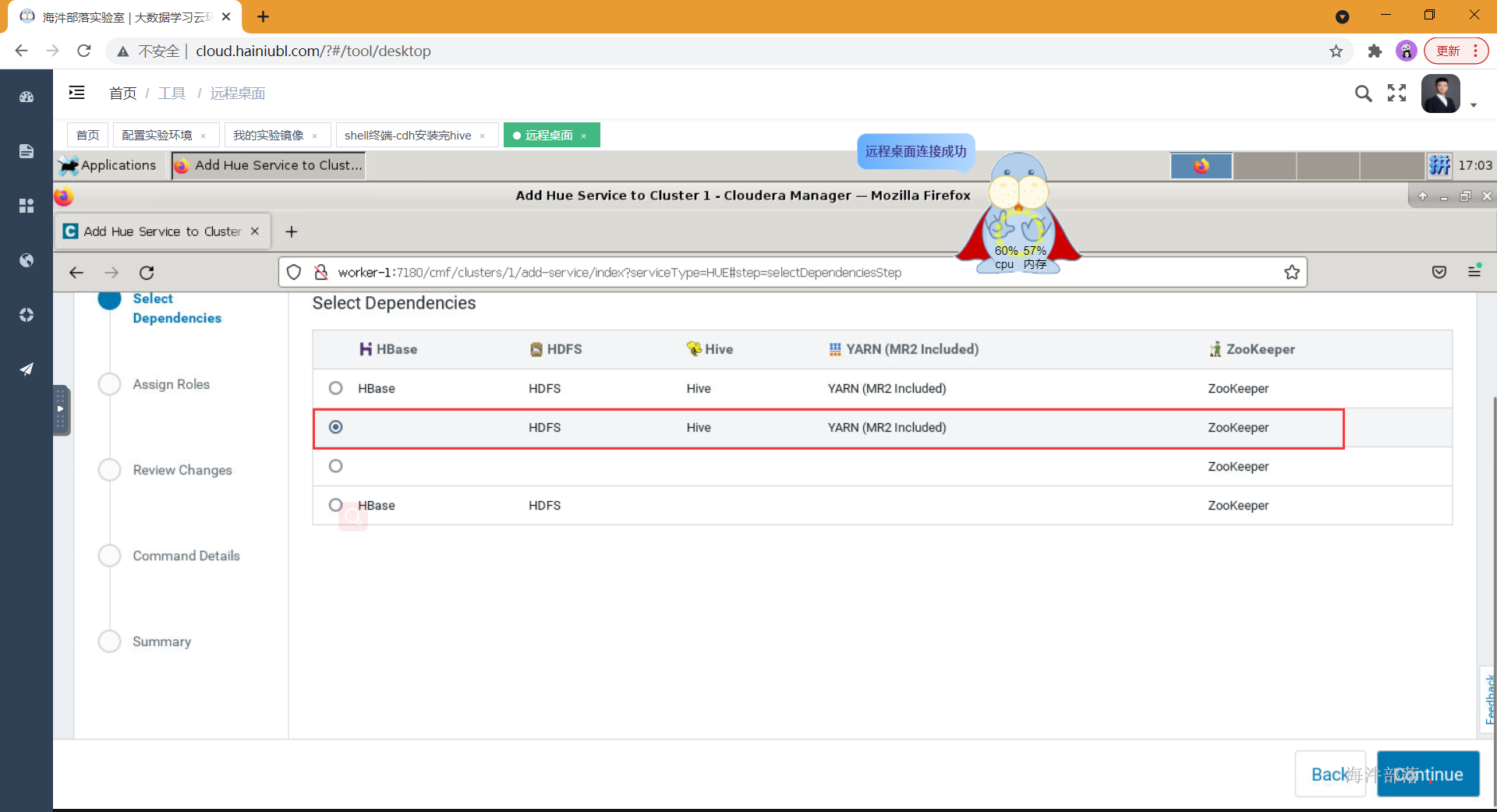
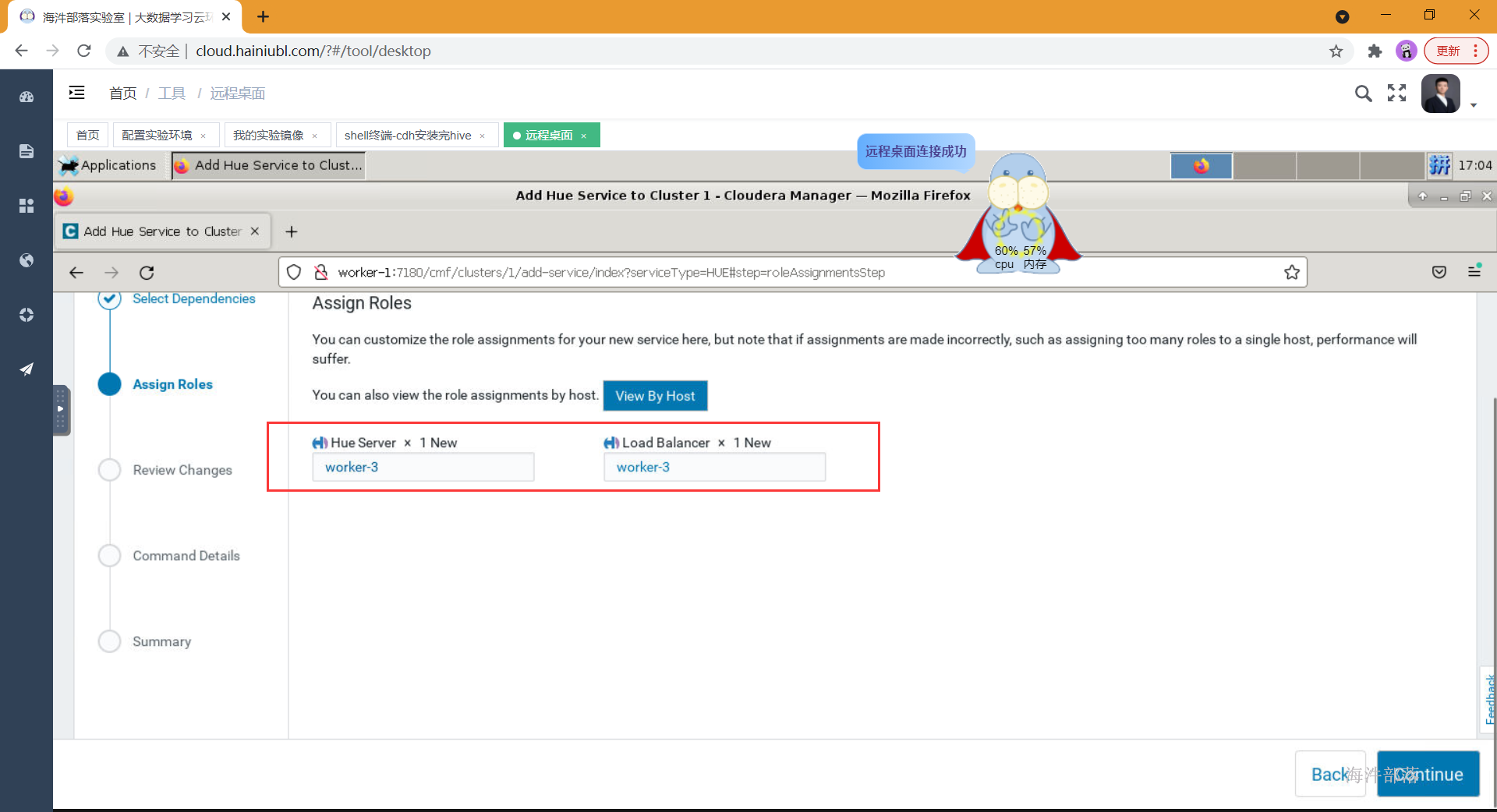
- 分配角色到对应节点
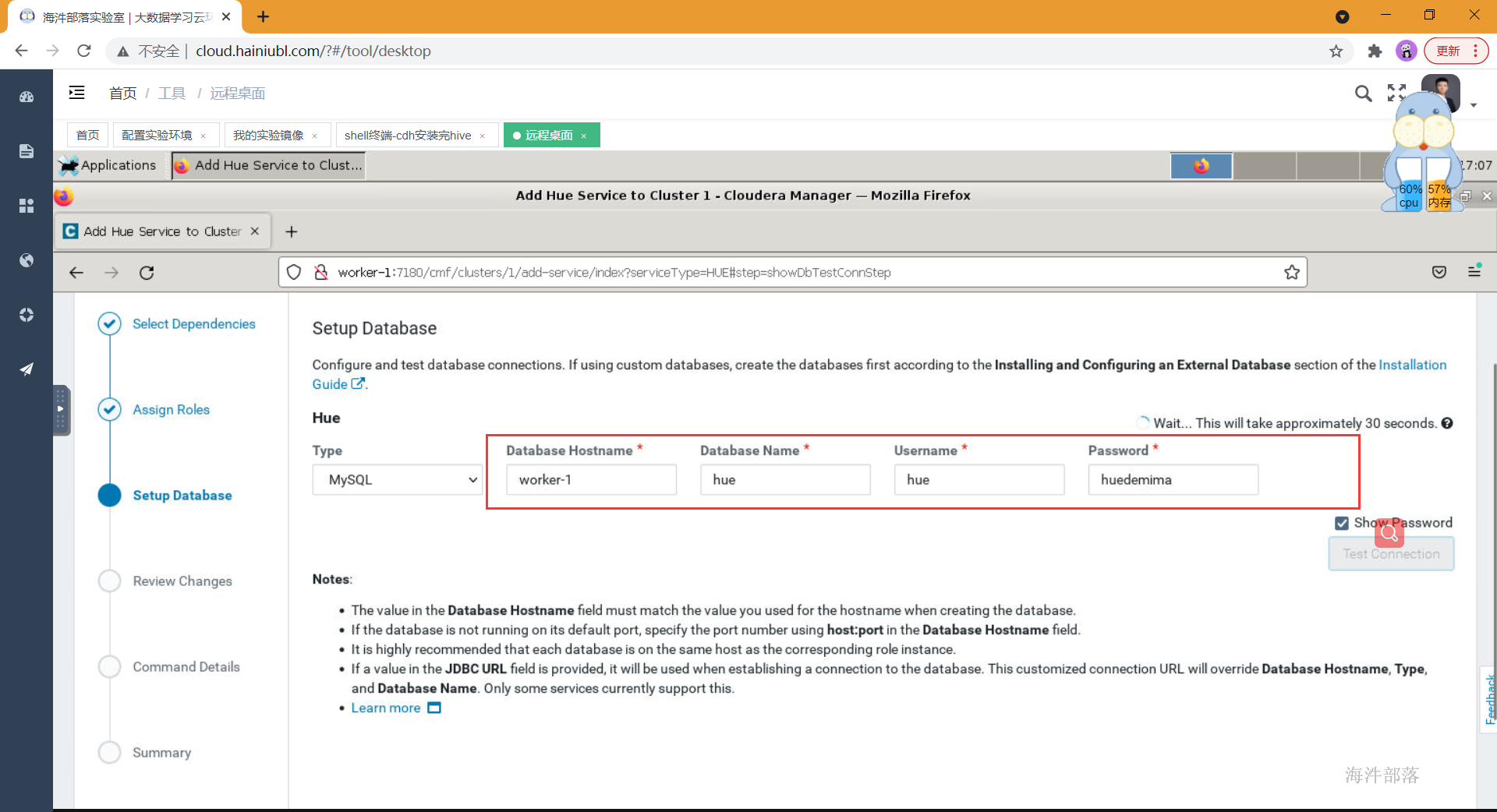
- 输入hue对应的数据库以及用户密码
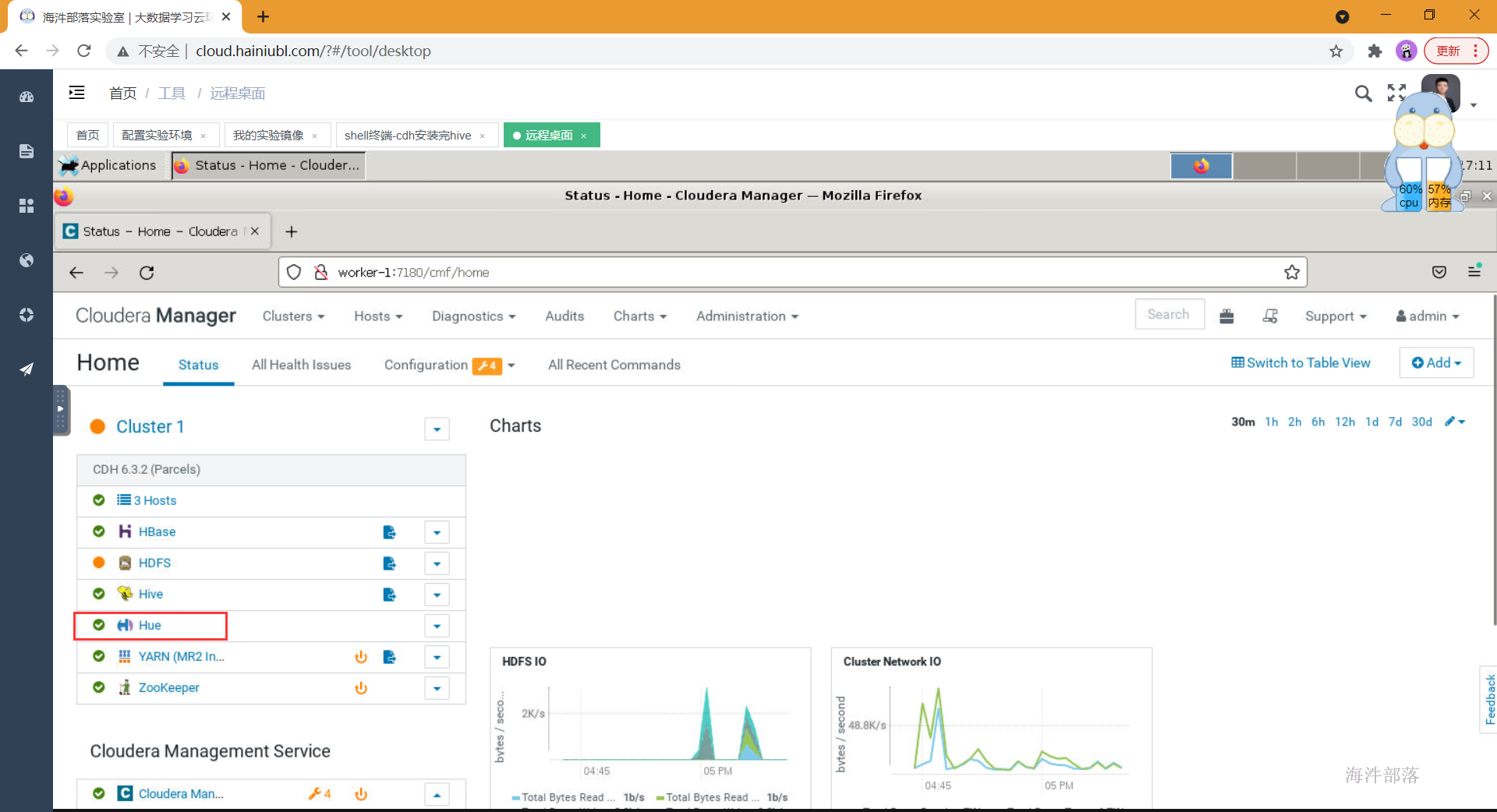
- 安装完启动hue
- 启动并测试
点击hue web UI
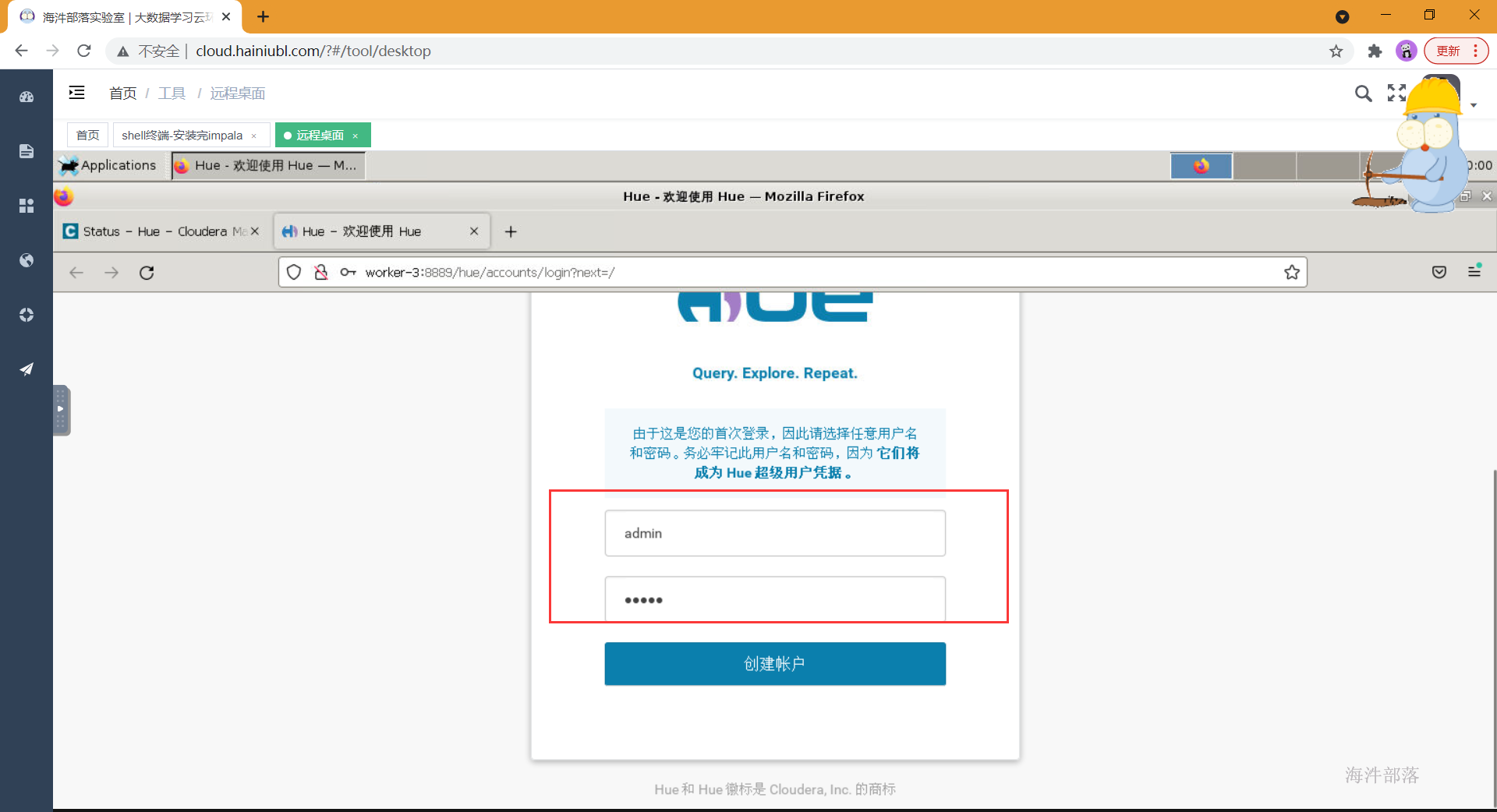
输入用户名密码,第一次输入的用户名为管理员
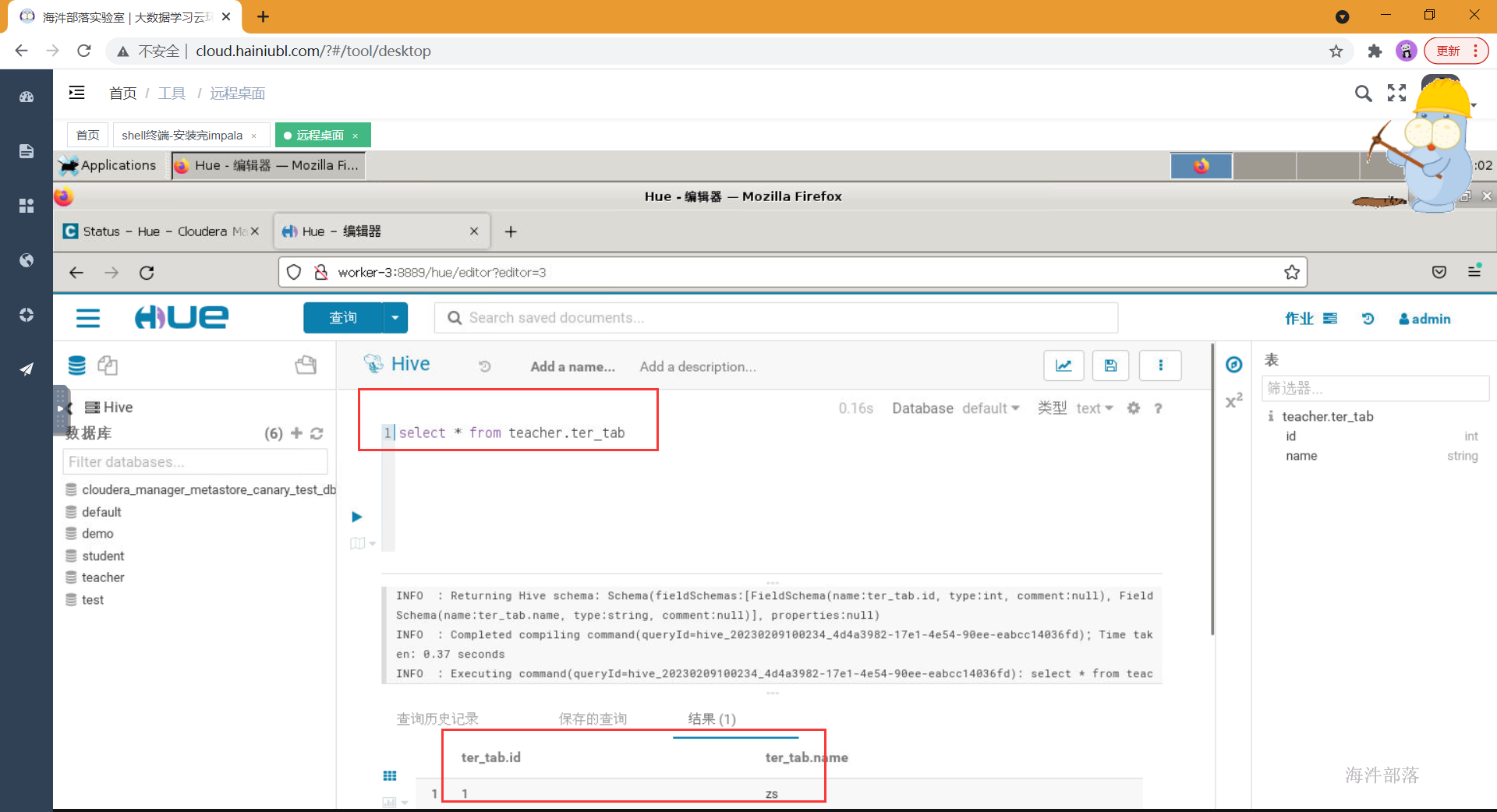
测试:
8 安装kudu
8.1 kudu概述
kudu 是Cloudera 开源给 Apache的,针对 Hadoop 平台而开发的列式存储管理器,kudu是介于hive与hbase中间的一个组件,解决了hive的随机读写问题,同时提高了hbase的吞吐量与组合查询效率。
8.2 cdh 集成kudu
- 选择组件并安装
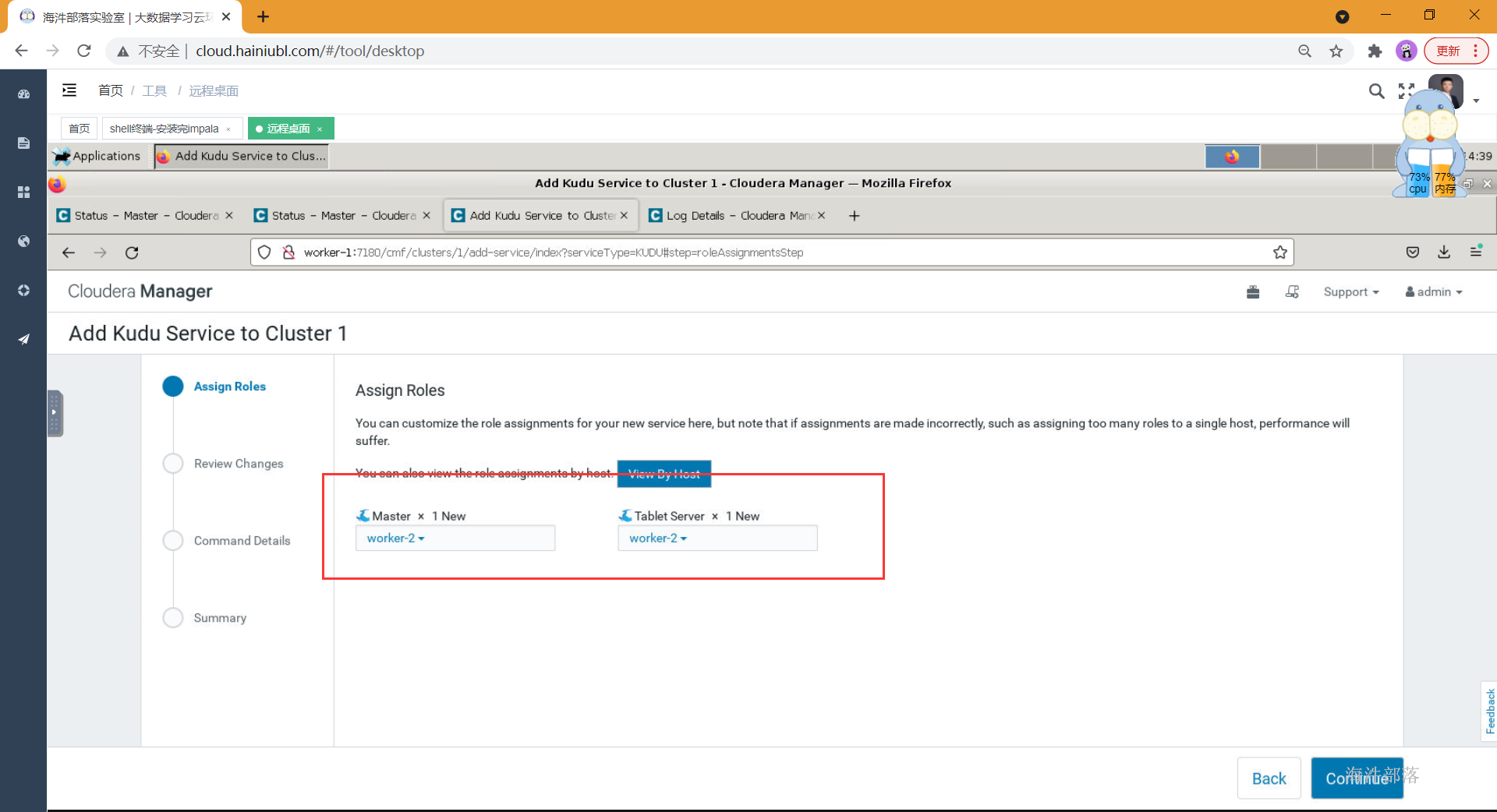
- 如上配置完元库信息并通过连接测试后,点击继续,进入服务详细配置界面,如果选择了安装kudu服务,则需要填写四个kudu的目录,如下,
#Kudu在安装时需要填写以下几项内容:
Kudu Master WAL Directory: /data/kudu_master/fs_wal_dir
Kudu Master Data Directories: /data/kudu_master/fs_data_dirs
Kudu Tablet Server WAL Directory: /data/kudu_tablet/fs_wal_dir
Kudu Tablet Server Data Directories: /data/kudu_tablet/fs_data_dirs 这四个目录,通常与hdfs的盘分离(官方也没有给出为什么,但是在生产中确实遇到过kudu与hdfs同盘导致服务不能启动的问题),我们在测试学习环境下可以设置在一起,如果要使用虚拟机分盘则需要再添加一块虚拟盘,挂载在指定目录下,专门给kudu使用。
生产环境下肯定是配置非常多的数据盘,在配置dfs目录的时候可以点击后面的+增加盘路径(如果所有盘都挂载到了一个目录下,那就不用增加了)
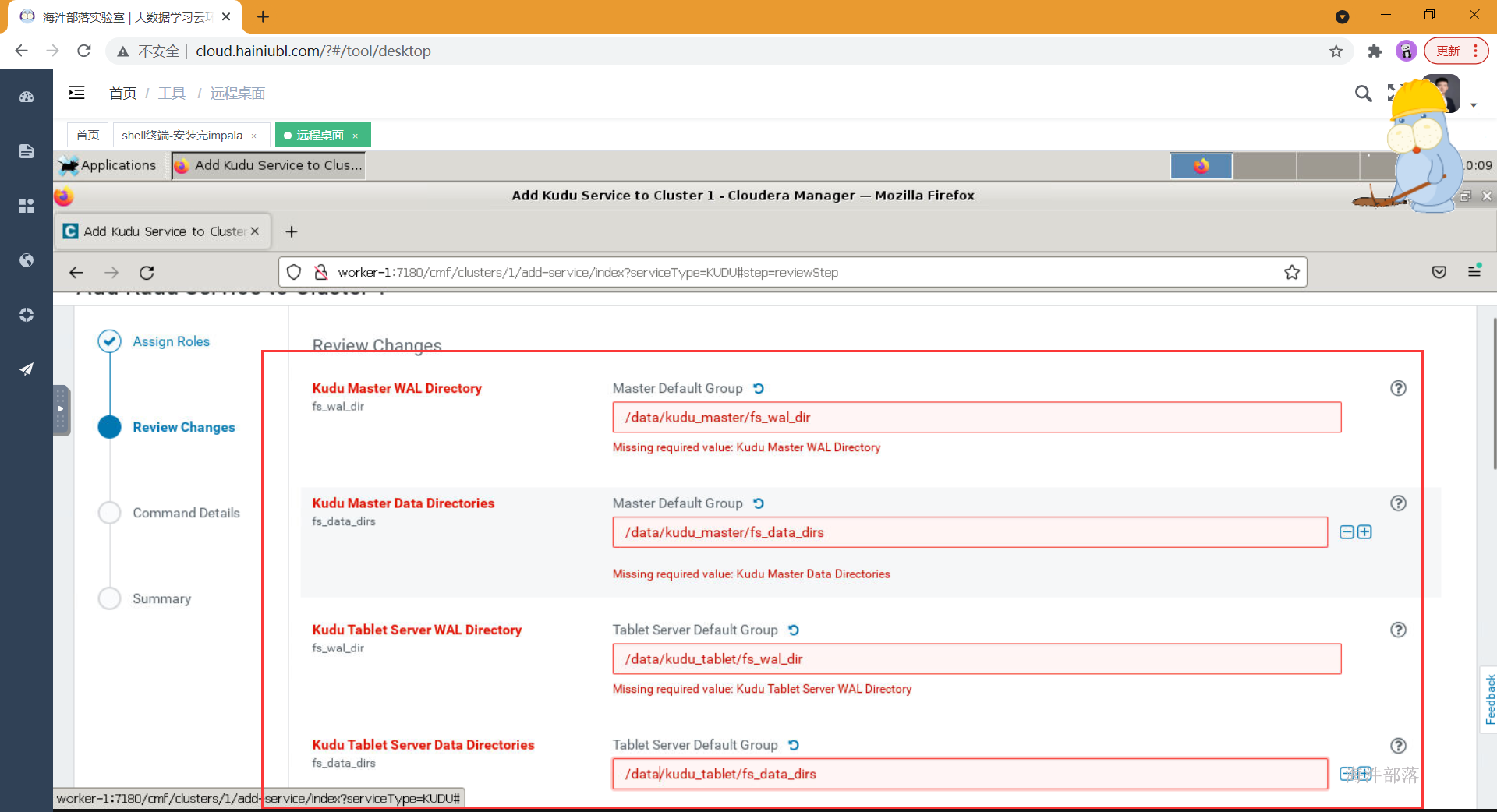
- 如上配置完成后点击继续,开始服务的安装,并在安装成功之后启动
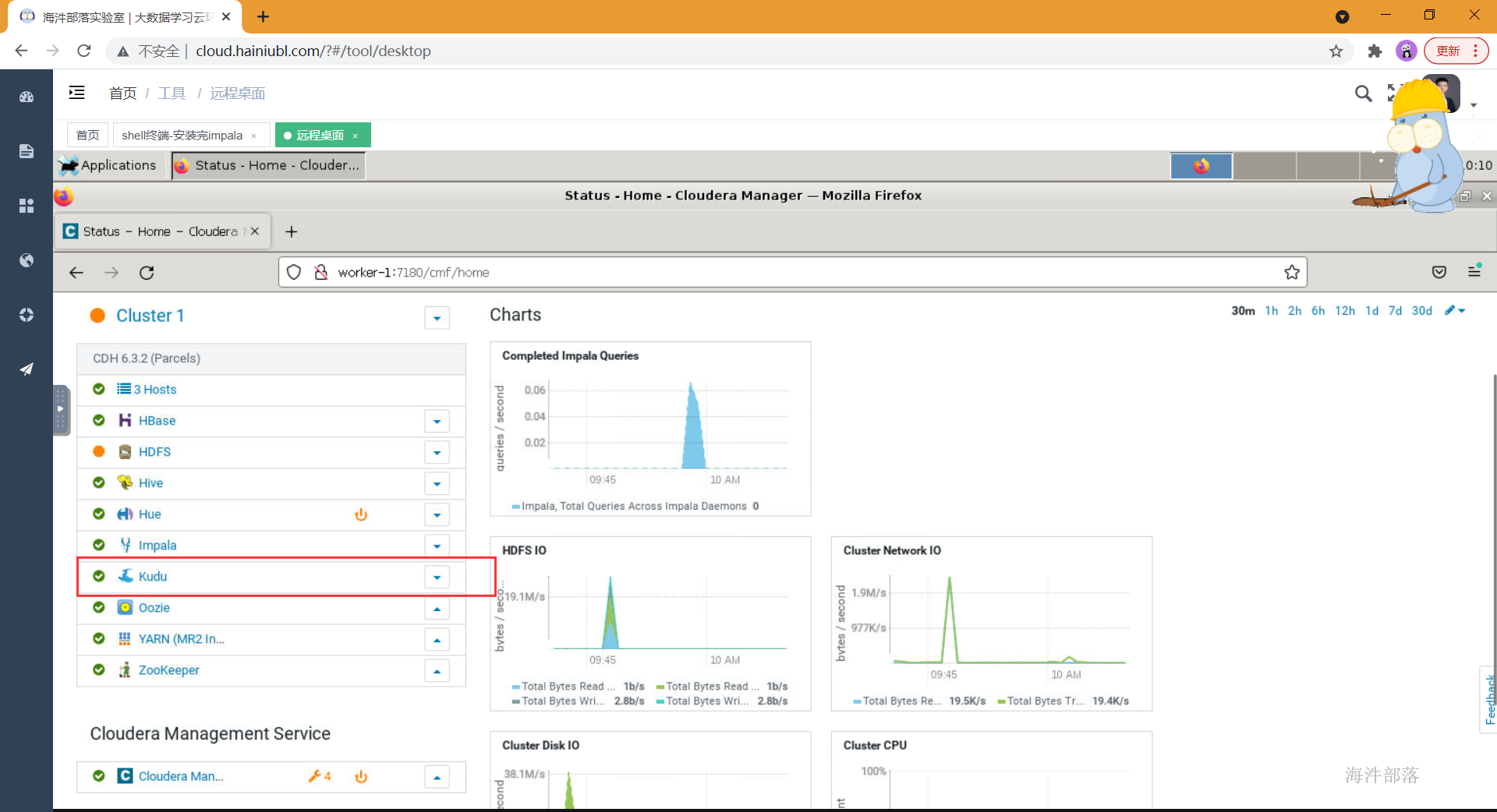
- impala 开启kudu服务
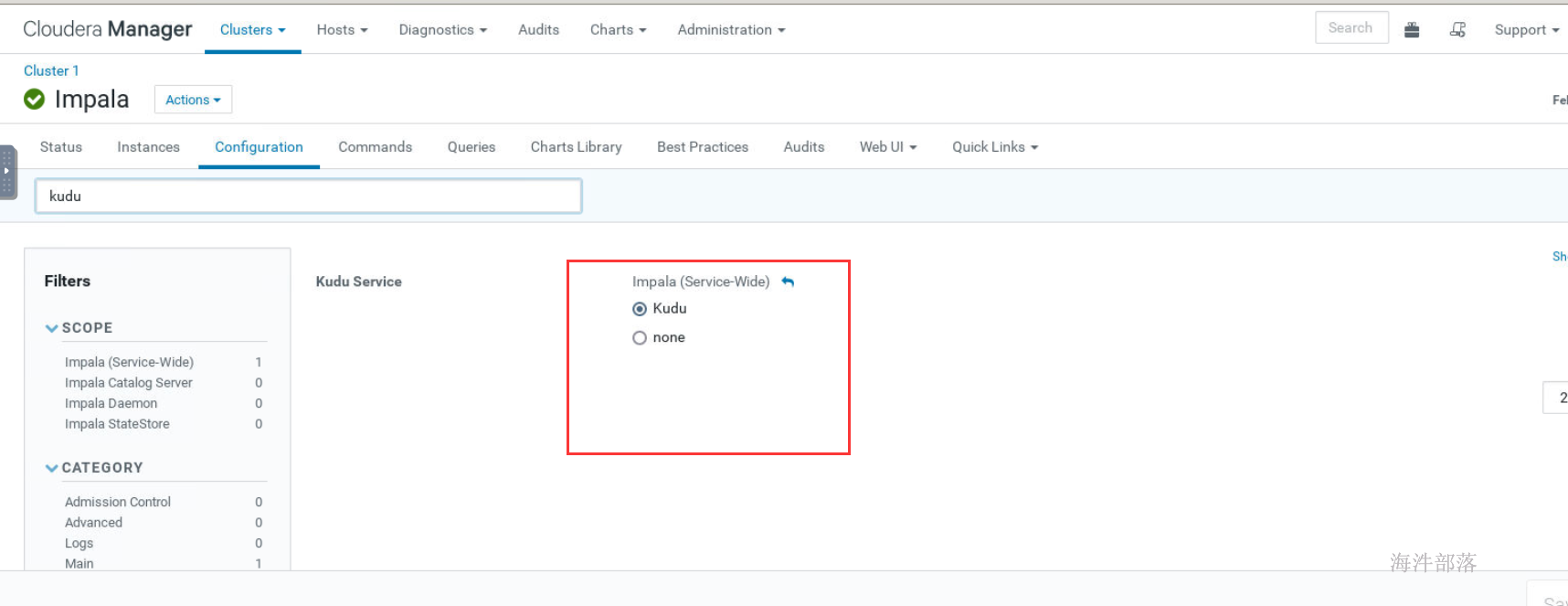
- 重启impala,并测试
#Kudu的使用需要配合impala来使用
#创建表
CREATE TABLE kudu_hash_t1
(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH(id) PARTITIONS 5
STORED AS KUDU
TBLPROPERTIES ('kudu.master_addresses'='worker-2');
如果在建表时卡着不动,需要增加额外的配置
--rpc_encryption=disabled
--rpc_authentication=disabled
--trusted_subnets=0.0.0.0/0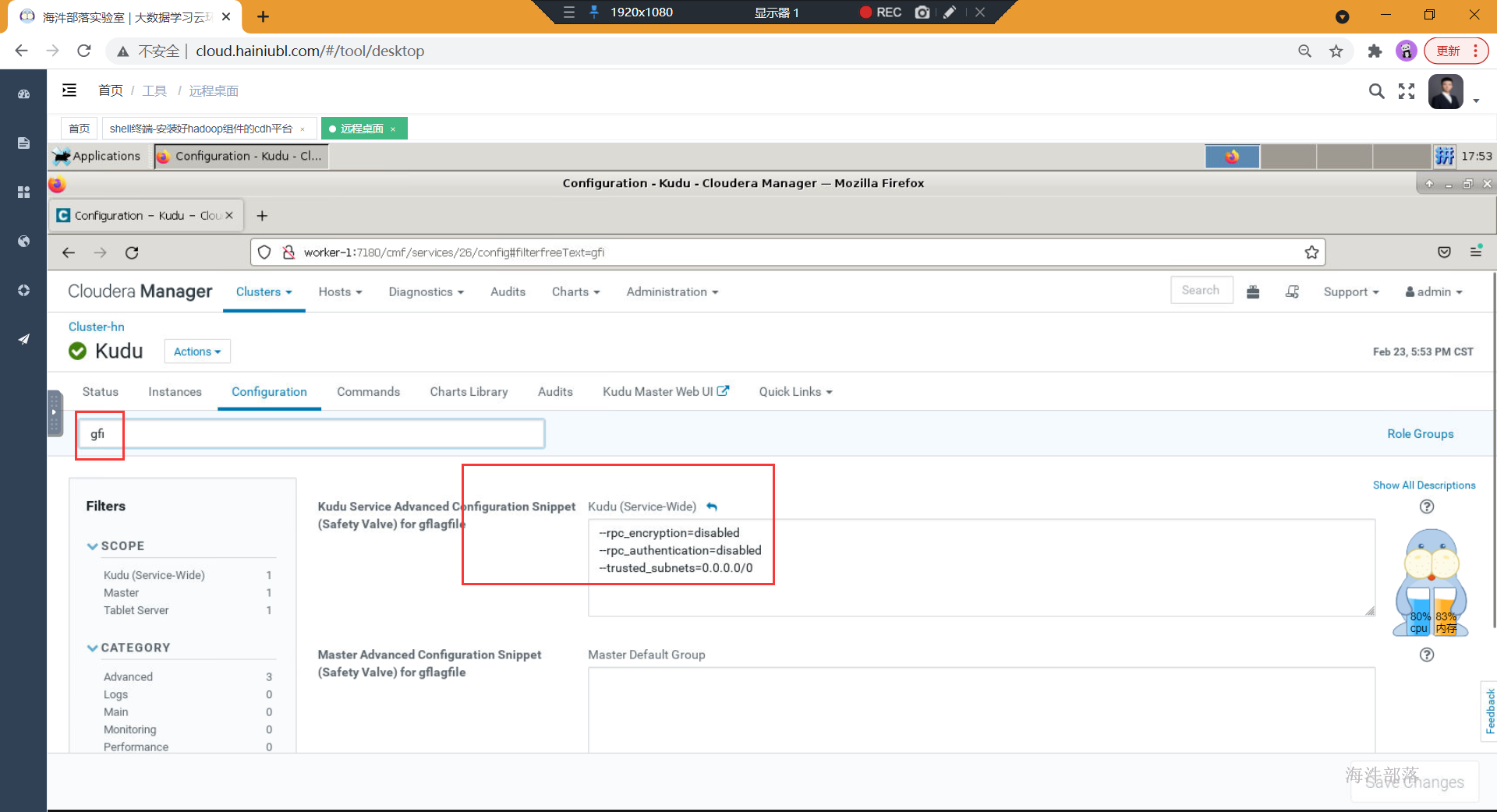
kudu表创建成功
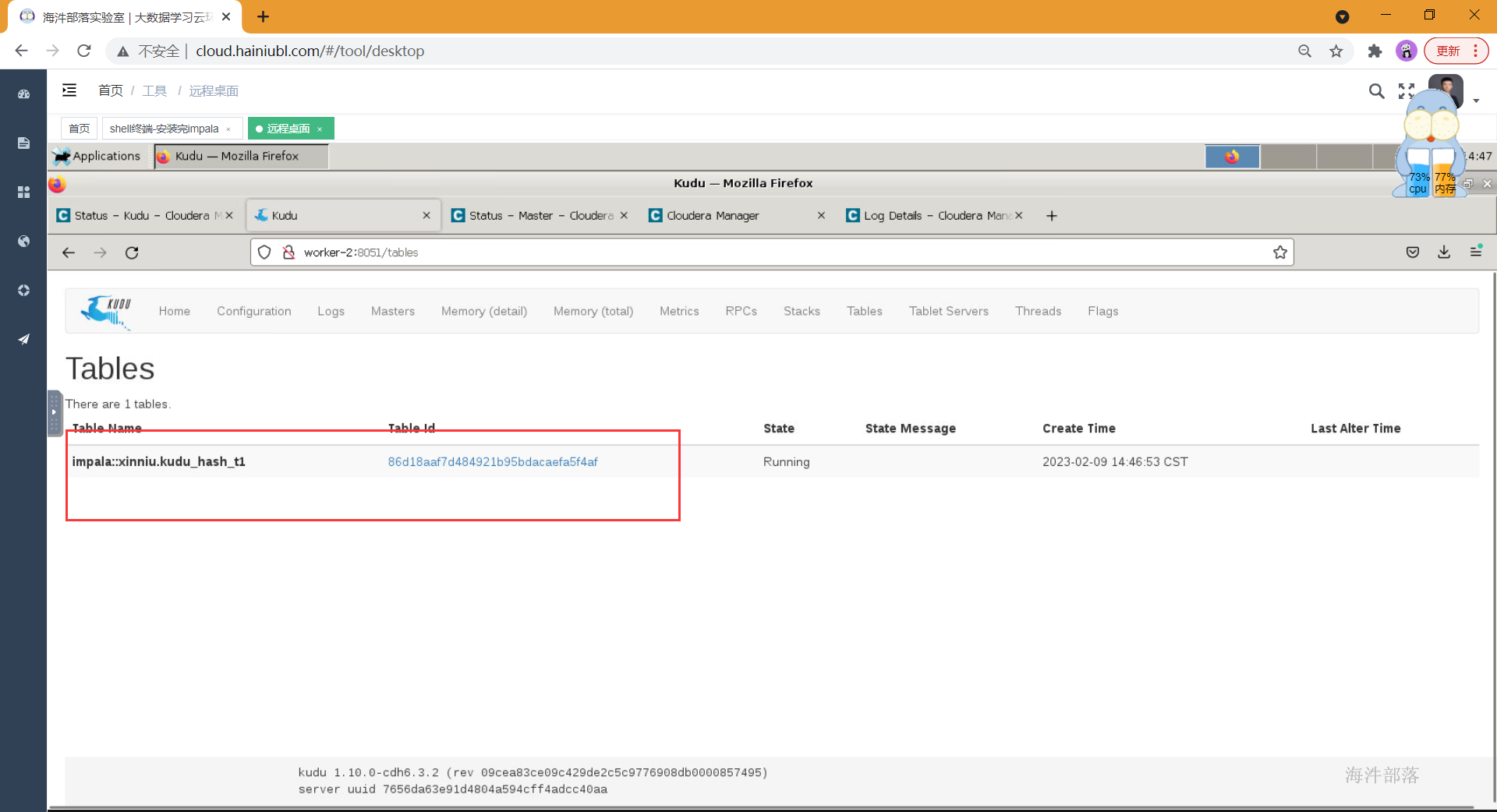
9 安装kafka
9.1 kafka概述
Kafka是由LinkedIn开发的一个分布式的消息系统。它是一款开源的、轻量级的、分布式、可分区和具有复制备份的(Replicated)、基于ZooKeeper的协调管理的分布式流平台的功能强大的消息系统。与传统的消息系统相比,KafKa能够很好的处理活跃的流数据,使得数据在各个子系统中高性能、低延迟地不停流转。
Kafka使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。
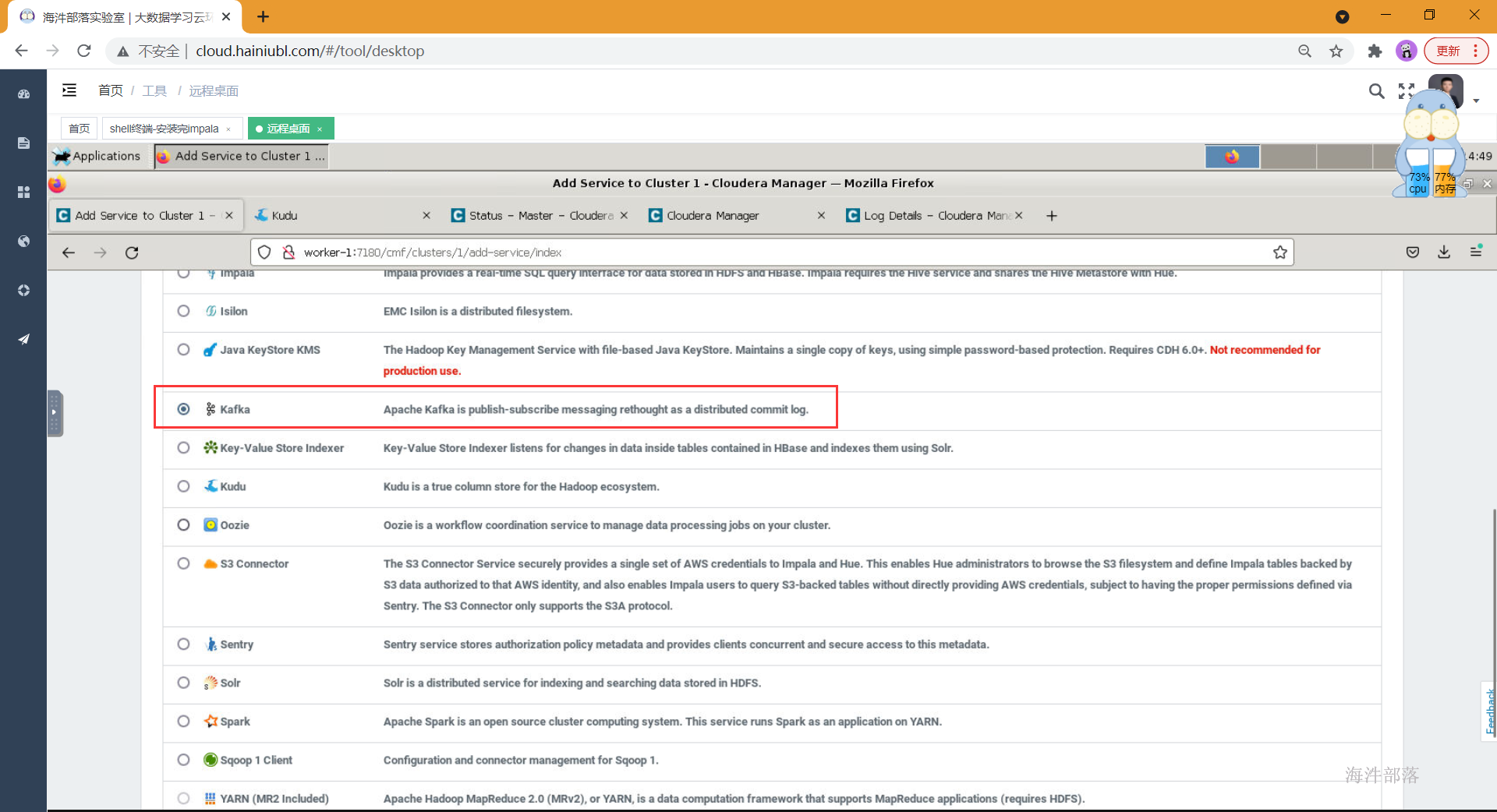
9.2 cdh集成kafka
- 选择组件
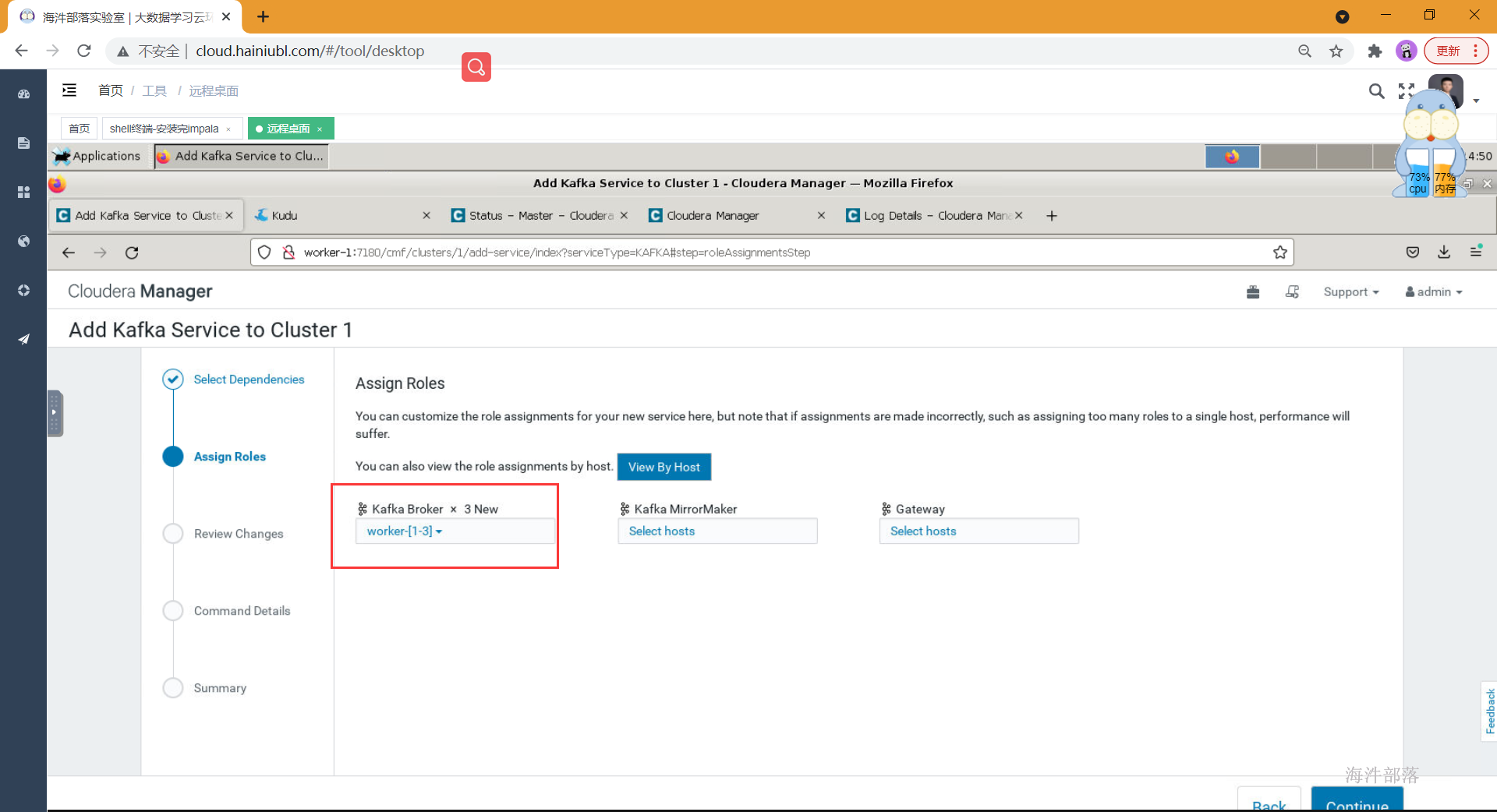
- 选择角色所在节点
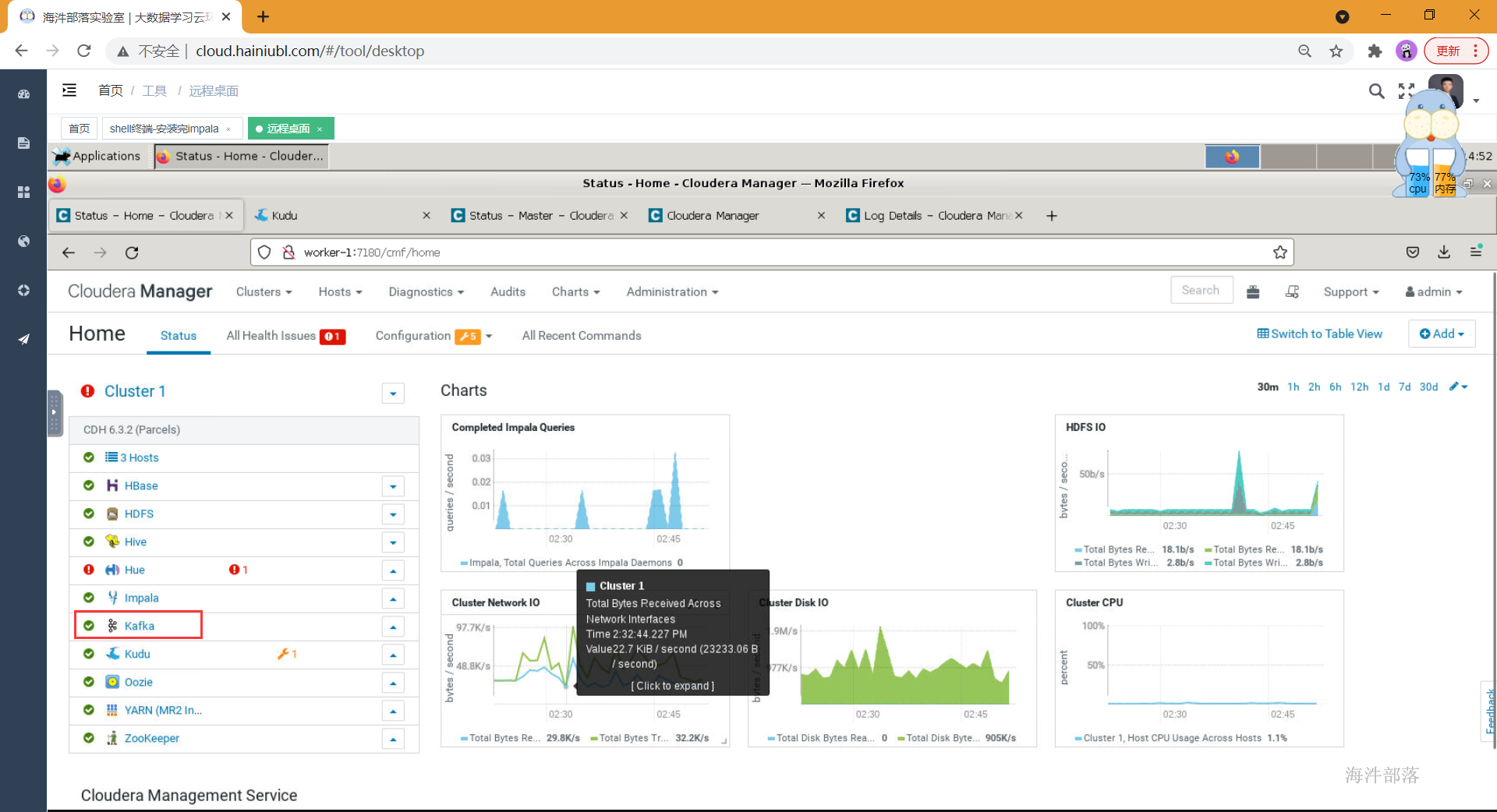
- 下一步进行安装
测试:
#创建一个demo的topic
kafka-topics --zookeeper worker-1:2181 --create --topic demo --replication-factor 1 --partitions 1
#查询所有topic
kafka-topics --list --zookeeper worker-1:2181
#启动消费者消费指定topic中的数据
kafka-console-consumer --bootstrap-server worker-1:9092 --topic demo
#启动生产者向指定topic生产数据
kafka-console-producer --broker-list worker-1:9092 --topic demo生产者生产数据:
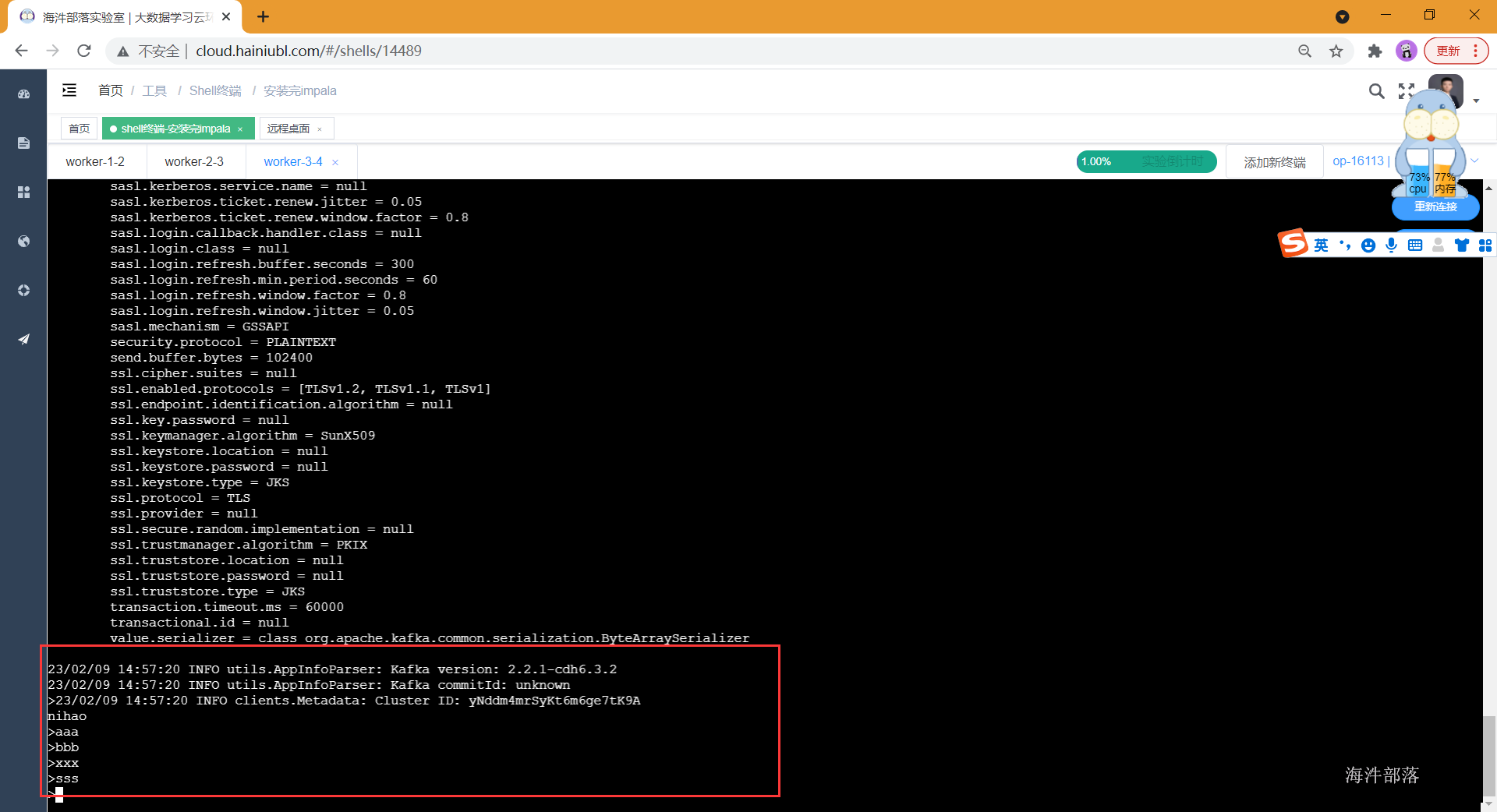
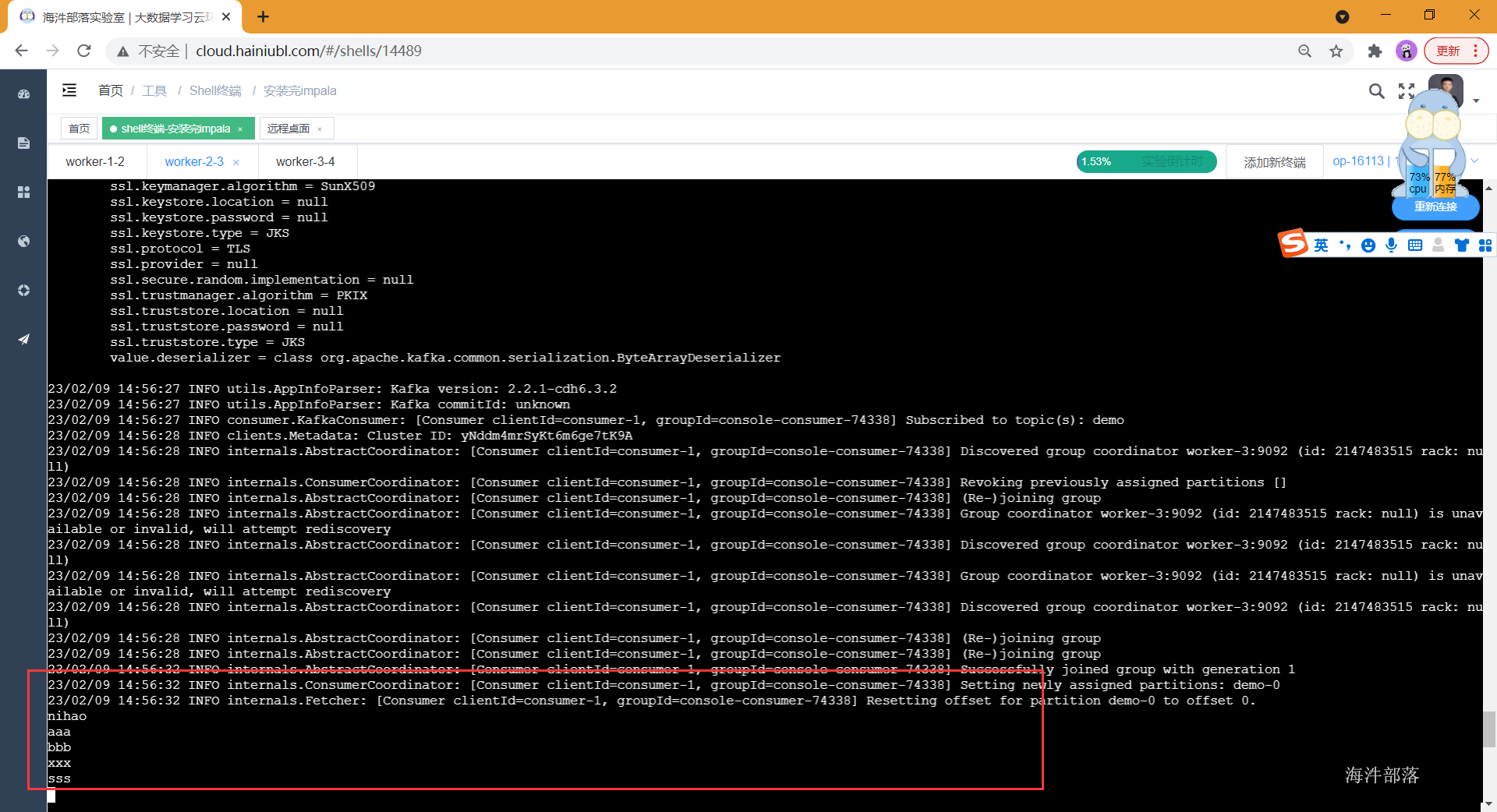
消费者消费数据:
10 安装flume
10.1 flume概述
flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到HDFS、Hbase,简单来说flume就是收集日志的。 flume 作为 cloudera(CDH版本的hadoop) 开发的实时日志收集系统,受到了业界的认可与广泛应用。
10.2 cdh 集成flume
- 选择组件添加
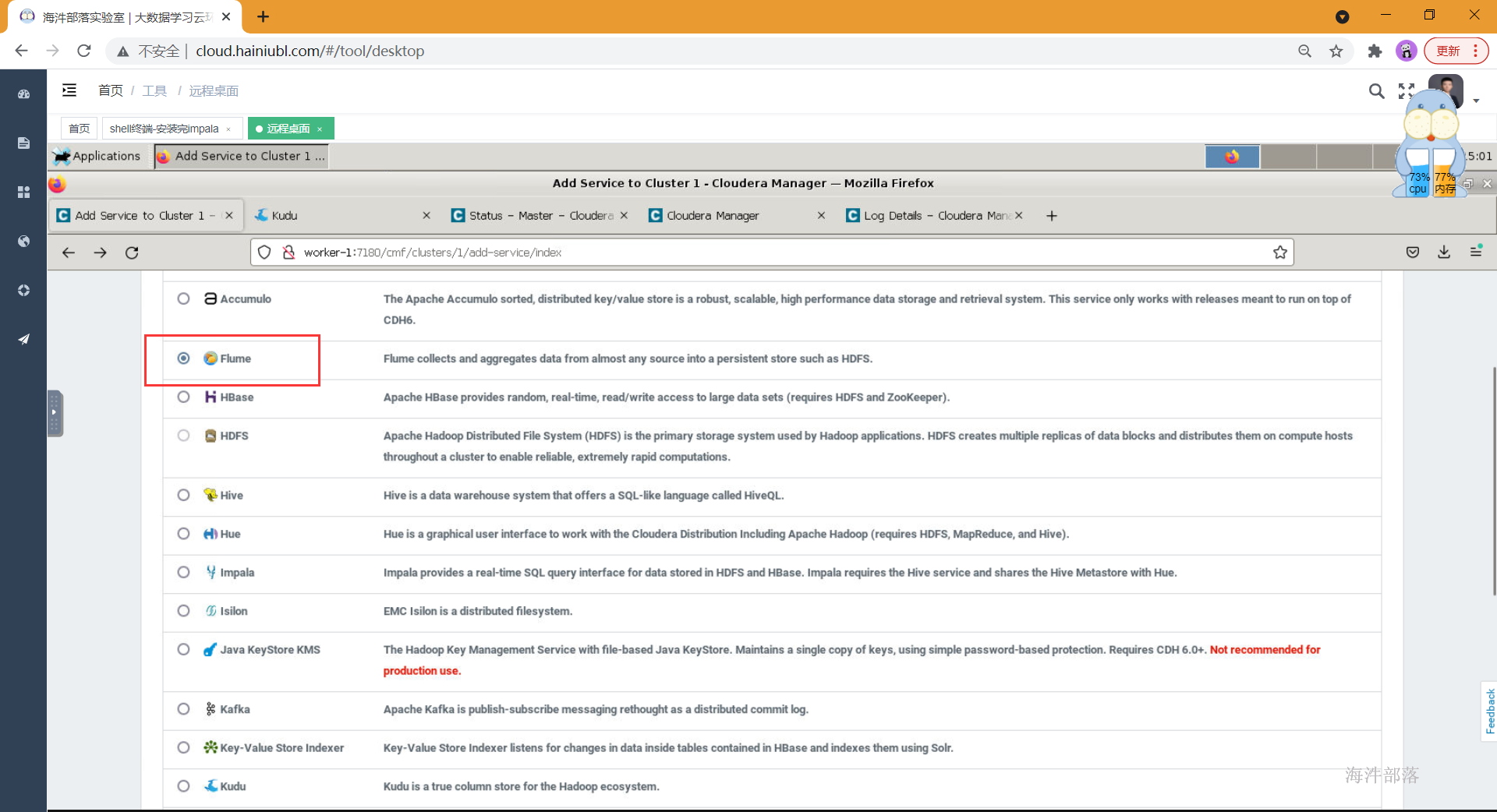
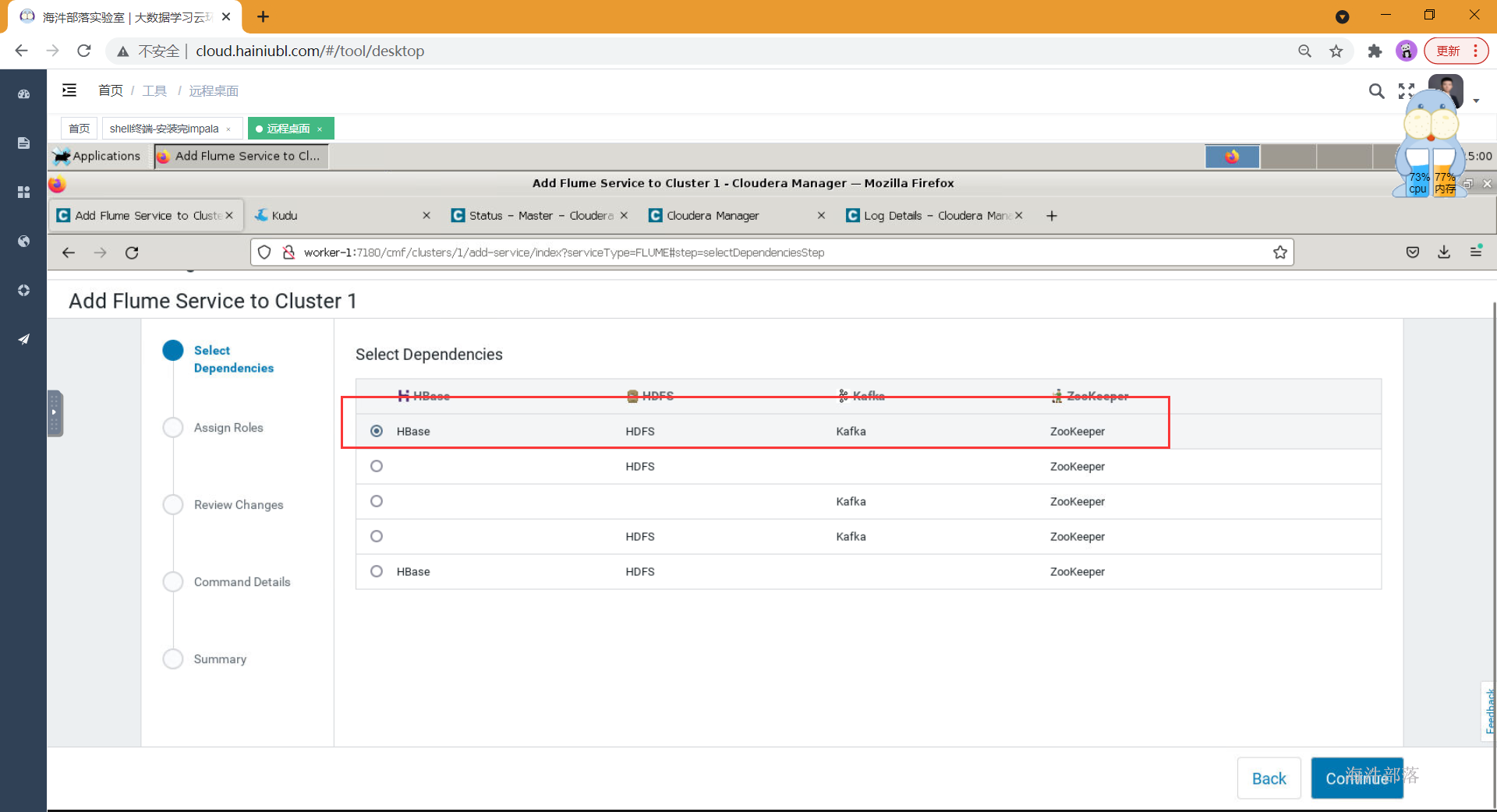
- 选择依赖
- 选择角色所在服务器
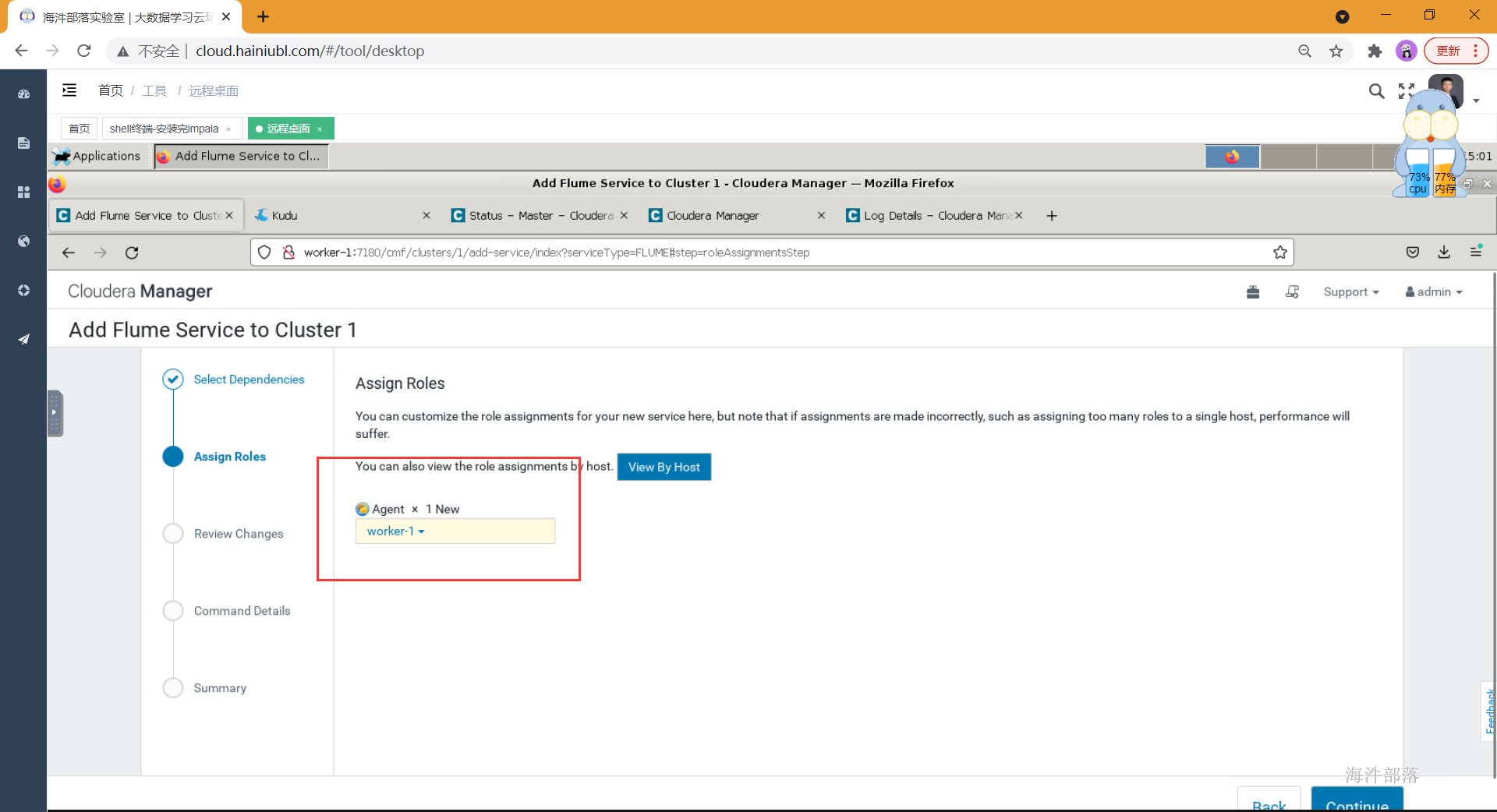
4.安装成功,不需要启动
11 安装sqoop
11.1 sqoop概述
Sqoop是Apache旗下的一款“hadoop和关系型数据库服务器之间传送数据”的工具。
导入数据:MySQL、Oracle导入数据到hadoop的hdfs、hive、hbase等数据存储系统。
导出数据:从hadoop的文件系统中导出数据到关系型数据库中。
11.2 cdh集成sqoop
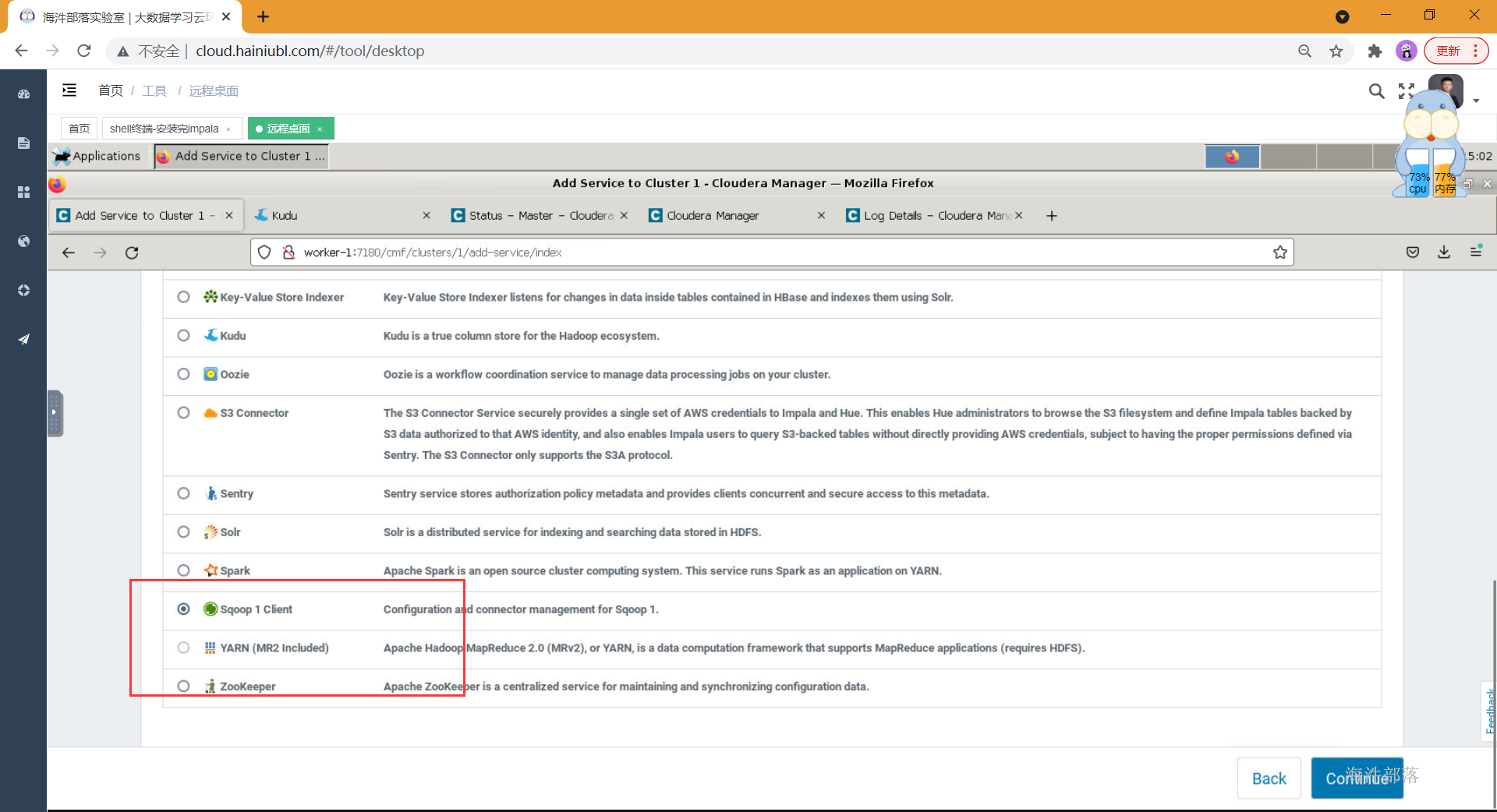
- 选择组件安装
- 选择角色所在节点
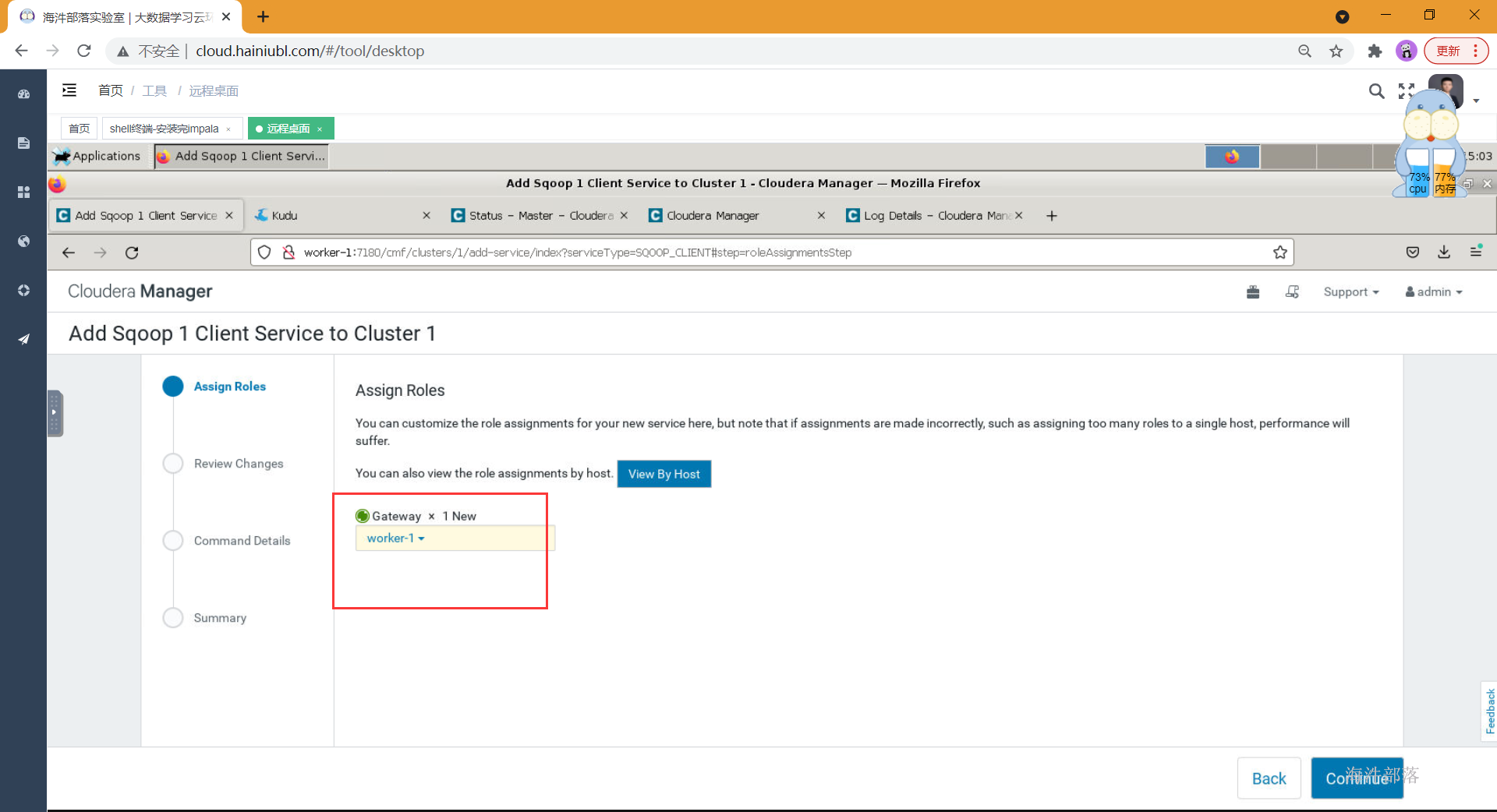
- 安装成功,不需要启动
12 镜像保存及重新运行镜像
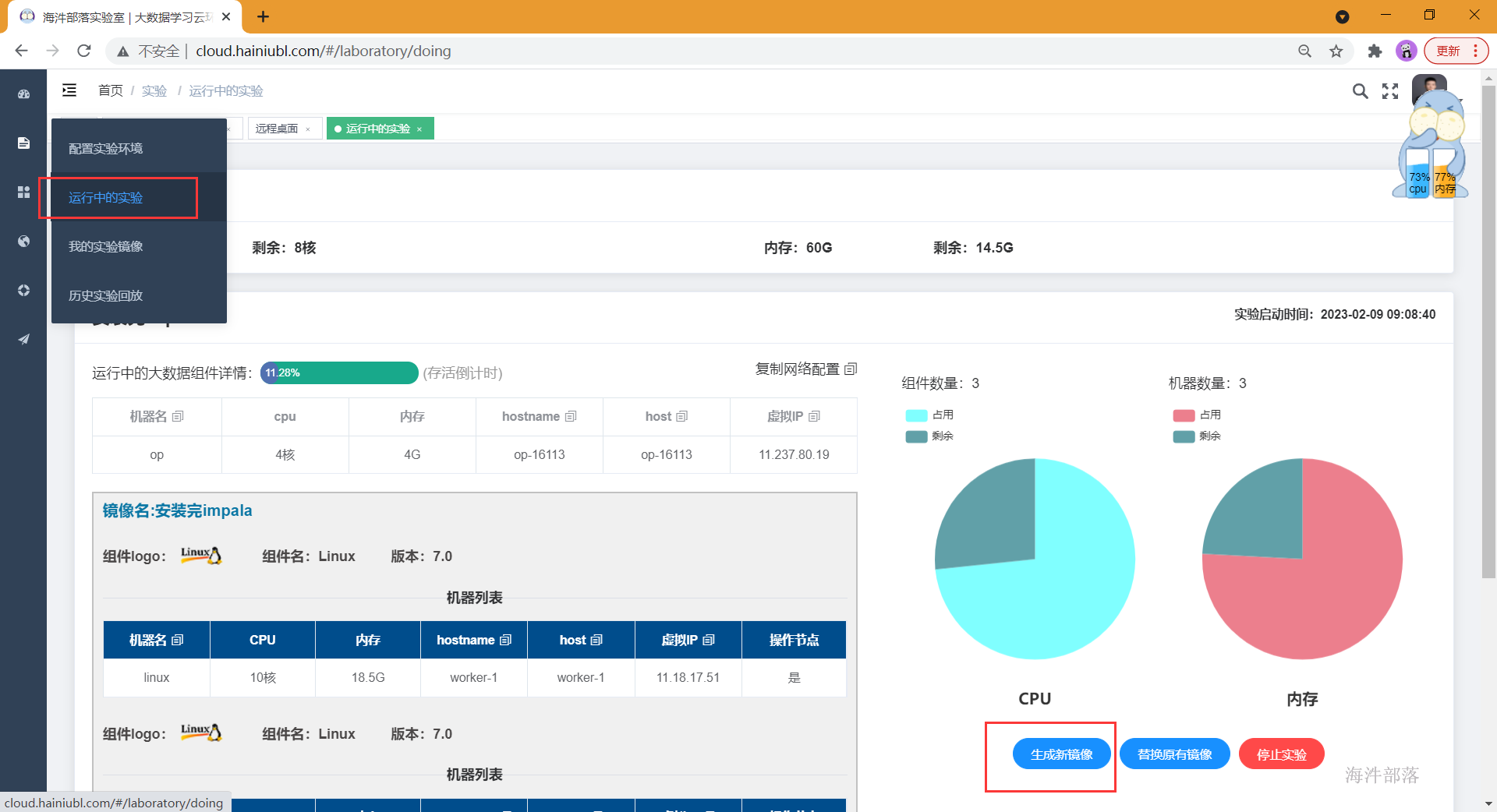
- 找到运行中的镜像,将安装好的组件打成新镜像,并给新的镜像起名
- 启动打好的镜像
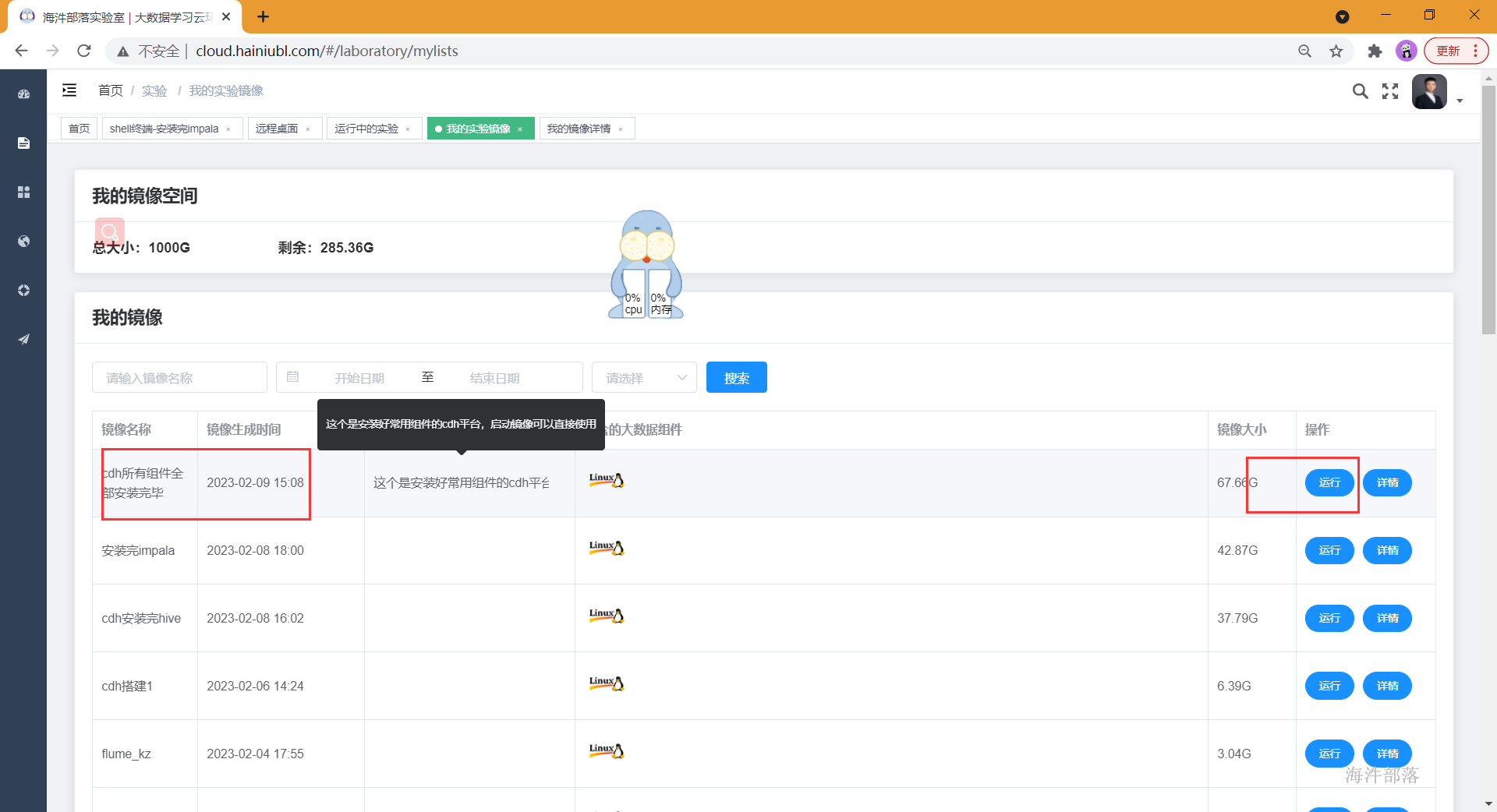
- 等到镜像热启动变成已就绪,就可以快速启动了!!
- 镜像启动成功需要按顺序启动一下所需服务
#1.在worker-1 上启动mysql
systemctl start mysqld
#2,在三台机器上启动httpd
systemctl start httpd
#3,在worker-1 上启动cm server
systemctl start cloudera-scm-server
#4,等待cm启动成功 在worker-1启动rpcbind
systemctl start rpcbind
#5,在三台节点启动supervisord
systemctl start supervisord
#6,在三台节点启动cm agent
systemctl start cloudera-scm-agent5.访问cm
http://worker-1:7180 输入admin/admin 进入
- 重启完镜像之后,需要重启所有组件,等待启动完成即可正常使用。