1 kerberos部署
1.1 kerberos概述
Kerberos是一个用于鉴定身份(authentication)的协议, 它采取对称密钥加密(symmetric-key cryptography),密钥不会在网络上传输。在Kerberos中,未加密的密码(unencrypted password)不会在网络上传输,因此攻击者无法通过嗅探网络来偷取用户的密码。
在cdh大数据平台中充当这秘钥的角色,cdh平台中组件会集成kerberos服务,意味着一旦开启,在请求访问组件服务时必须先通过kerberos秘钥认证。
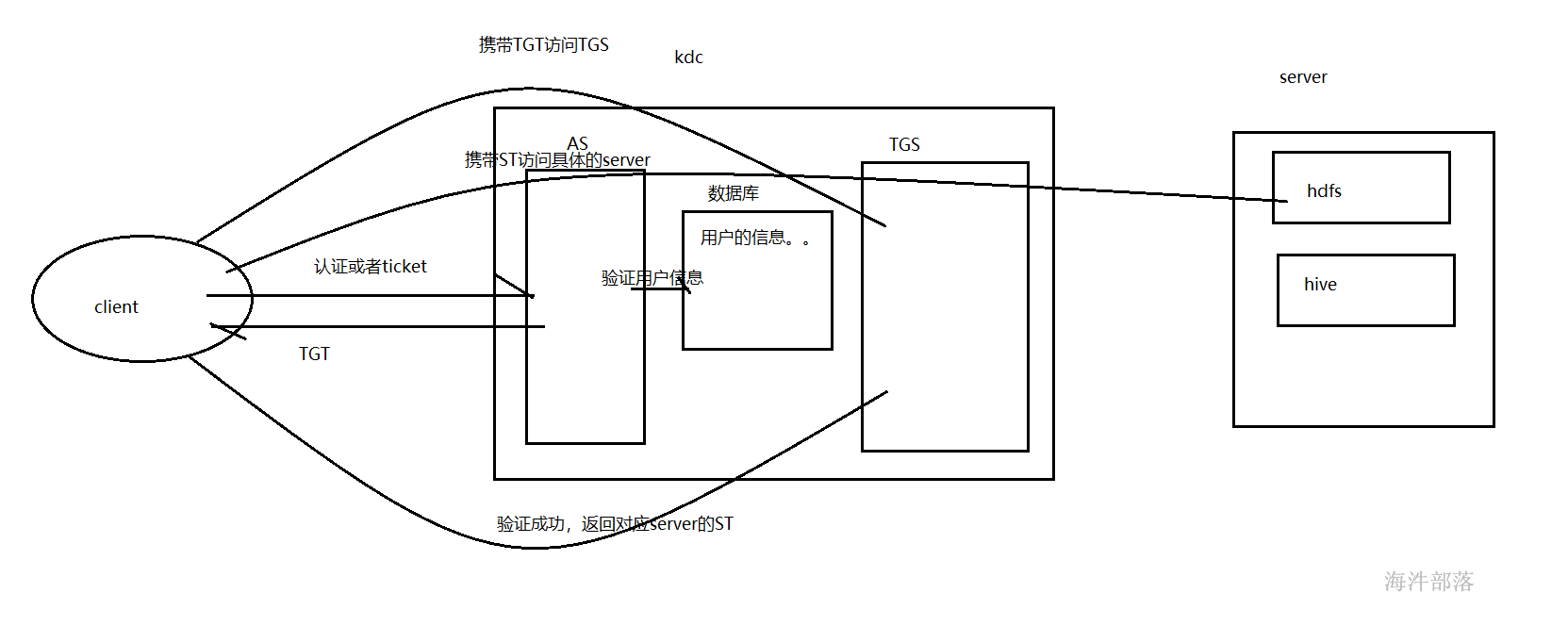
在keberos Authentication中,Kerberos有三个实体:Client、Server和 KDC(包含 AS 和 TGS)。
KDC(key distribution center):密钥发放中心。
AS(authentication service):认证服务,索取身份信息,发放 TGT。
TGS(ticket granting service):票据授权服务,索取TGT,发放ST。
TGT(ticket granting ticket):票据授权票据,由KDC的AS发放,有有效期。有了这个票据,可以申请多个server的票据。
ST(server ticket):服务票据,由KDC的TGS发放,访问任何的server都需要一张有效的ST。
1.2 kerberos部署
worker-1:kerberos server端
worker-[1-3]:kerberos cilent端
选择服务端:选择worker1节点作为kerberos服务端
#worker-1安装
yum -y install krb5-server krb5-auth-dialog krb5-workstation
#worker-[1-3] 安装
yum -y install krb5-libs krb5-auth-dialog krb5-workstation
#所有节点安装sasl工具,impala启用kerberos时需要sasl工具,如已安装请忽略
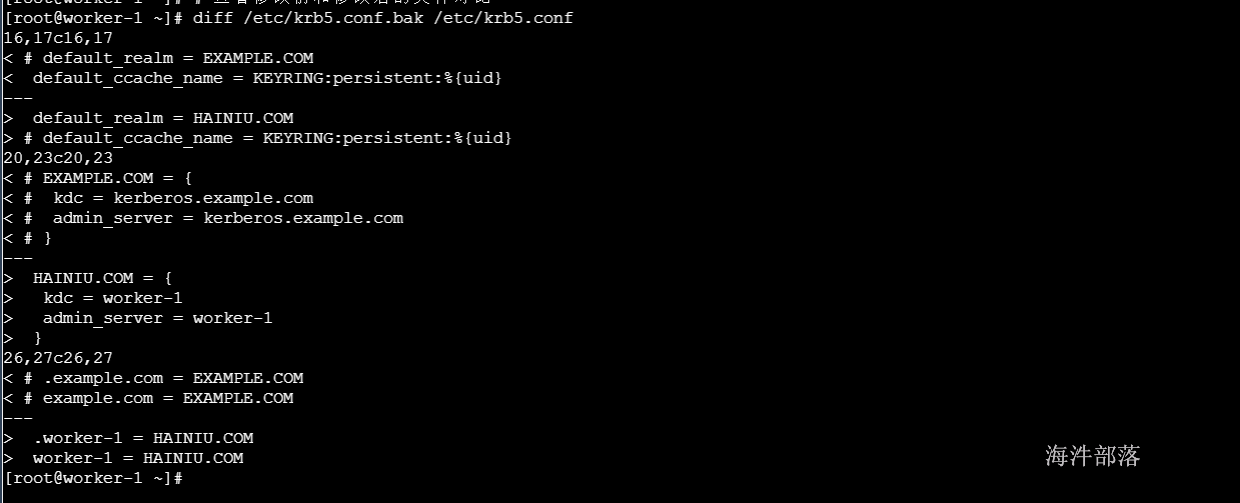
yum -y install cyrus-sasl-plain cyrus-sasl-devel cyrus-sasl-gssapi cyrus-sasl-md5/etc/krb5.conf存在于每一个Kerberos节点上,所以在master节点上编辑好该文件后需要覆盖到集群上的所有节点上。主要是domain, kdc服务器和admin_server服务器的地址。
修改/etc/krb5.conf文件,这里要修改的几个关键点,kerberos.example.com和example.com替换为kerberos服务端的hostname,EXAMPLE.COM替换为自己公司的域名
#注释掉如下行,打开会引起错误:[Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)]
# default_ccache_name = KEYRING:persistent:%{uid}
cp -n /etc/krb5.conf /etc/krb5.conf.bak && \
sed -i 's/#//g' /etc/krb5.conf && \
sed -i 's/EXAMPLE.COM/HAINIU.COM/g' /etc/krb5.conf && \
sed -i 's/kerberos.example.com/worker-1/g' /etc/krb5.conf && \
sed -i 's/example.com/worker-1/g' /etc/krb5.conf && \
sed -i 's/ default_ccache_name/# default_ccache_name/g' /etc/krb5.conf && \
sed -i 's/ Configuration/# Configuration/g' /etc/krb5.conf
# 查看修改前和修改后的文件对比
diff /etc/krb5.conf.bak /etc/krb5.conf修改后查看:
default_realm:设置 Kerberos 应用程序的默认领域,必须跟要配置的realm的名称一致。如果有多个领域,只需向 [realms] 节添加其他的领域。
ticket_lifetime:表明凭证生效的时限,一般为 24 小时。
renew_lifetime : 表明凭证最长可以被延期的时限,一般为一个礼拜。当凭证过期之后,对安全认证的服务的后续访问则会失败。
[realms]:列举使用的 realm。
修改/var/kerberos/krb5kdc/kdc.conf文件,修改EXAMPLE.COM为自己公司的域名。
cp -n /var/kerberos/krb5kdc/kdc.conf /var/kerberos/krb5kdc/kdc.conf.bak && \
sed -i 's/EXAMPLE.COM/HAINIU.COM/g' /var/kerberos/krb5kdc/kdc.conf
diff /var/kerberos/krb5kdc/kdc.conf.bak /var/kerberos/krb5kdc/kdc.conf
#并在文件中添加一下内容
max_renewable_life = 7d 0h 0m 0s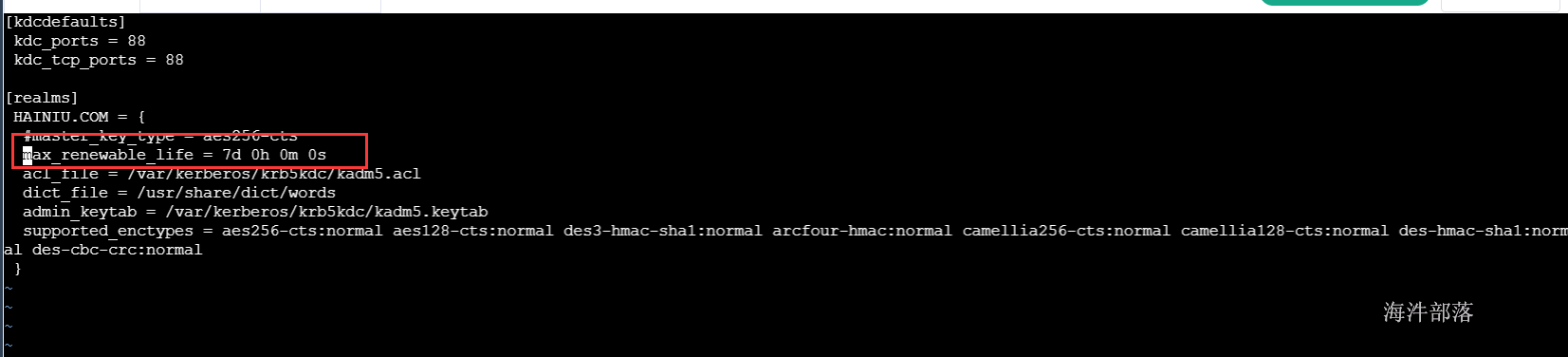
修改/var/kerberos/krb5kdc/kadm5.acl文件,修改EXAMPLE.COM为自己公司的域名。
principal的名字的第二部分是admin,那么该principal就拥有管理员权限。例如后面我们要建立的cloudera-scm/admin@HAINIU.COM 就拥有管理员权限,因为它的名字以/admin结尾。
cp -n /var/kerberos/krb5kdc/kadm5.acl /var/kerberos/krb5kdc/kadm5.acl.bak && \
sed -i 's/EXAMPLE.COM/HAINIU.COM/g' /var/kerberos/krb5kdc/kadm5.acl
diff /var/kerberos/krb5kdc/kadm5.acl.bak /var/kerberos/krb5kdc/kadm5.acl1.3 配置kerberos服务
在worker-1节点上,生成kerberos数据库,设置密码为:12345678
/usr/sbin/kdb5_util create -s为cdh创建cloudera-scm/admin用户,设置密码为:12345678
# 开启kerberos管理界面
kadmin.local
# 添加认证主体, 主体名: cloudera-scm/admin 密码: 12345678
addprinc cloudera-scm/admin
12345678
12345678
# 退出kerberos管理界面
exit会在 /var/kerberos/krb5kdc/ 生成一个数据库文件principal
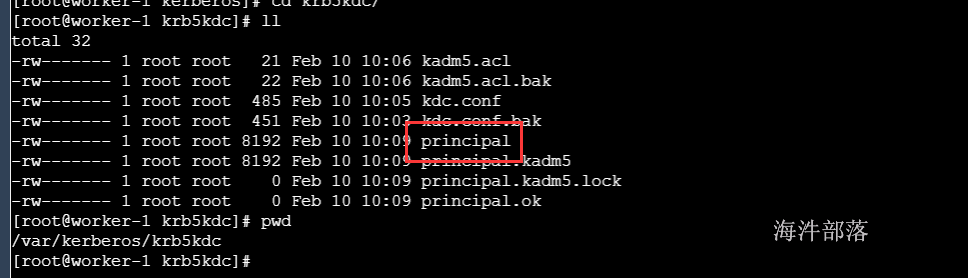
修改krbtgt/HAINIU.COM@HAINIU.COM的Maximum renewable life参数为90天(其默认值为0天),解决在CDH启用kerberos时,Hue角色Kerberos Ticket Renewer启动异常问题
kadmin.local
modprinc -maxrenewlife 90day krbtgt/HAINIU.COM@HAINIU.COM
getprinc krbtgt/HAINIU.COM@HAINIU.COM
exit1.4 启动kerberos服务
#在worker0-1上启动kerberos服务
systemctl start krb5kdc
systemctl start kadmin
systemctl status krb5kdc
systemctl status kadmin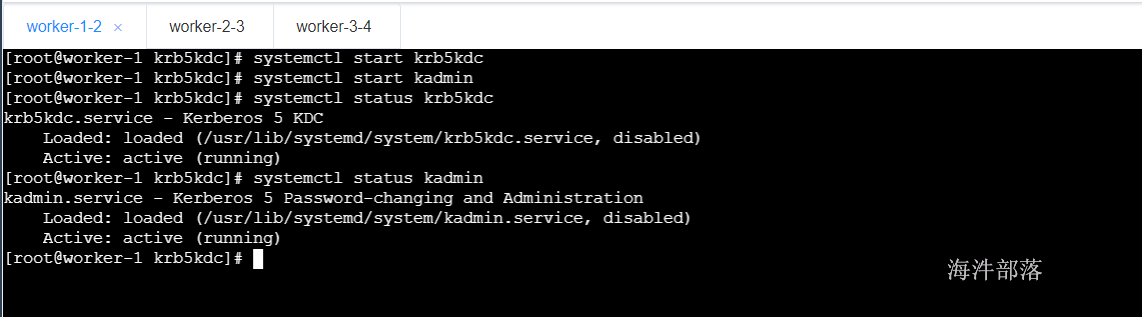
1.5 kerberos客户端安装
多节点时执行,单节点不需要执行
#从节点安装kerberos客户端软件
yum -y install krb5-libs krb5-workstation
#从主节点复制配置文件到从节点
scp /etc/krb5.conf root@worker-2:/etc/krb5.conf
scp /etc/krb5.conf root@worker-3:/etc/krb5.conf
ssh root@worker-2 cat /etc/krb5.conf
ssh root@worker-3 cat /etc/krb5.conf1.6 kerberos认证测试
#客户端执行
#获取票据
kinit cloudera-scm/admin
12345678
#查看票据
klist
#销毁票据
kdestroy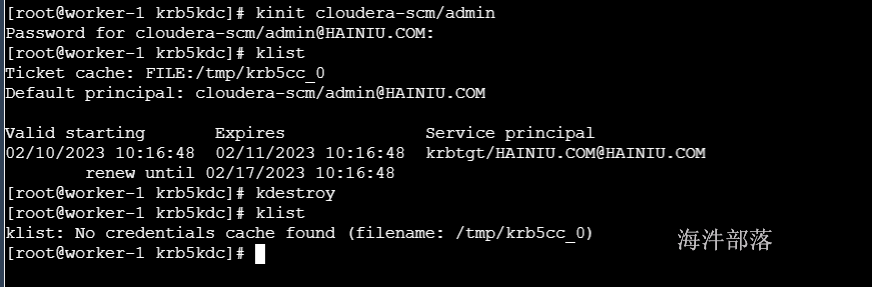
1.7 CDH集成kerberos
集群启用kerberos,进入cm界面,在集群右边选择下拉选项,选择启用kerberos。或者在cm界面,点击管理,点击安全,选择启用kerberos。
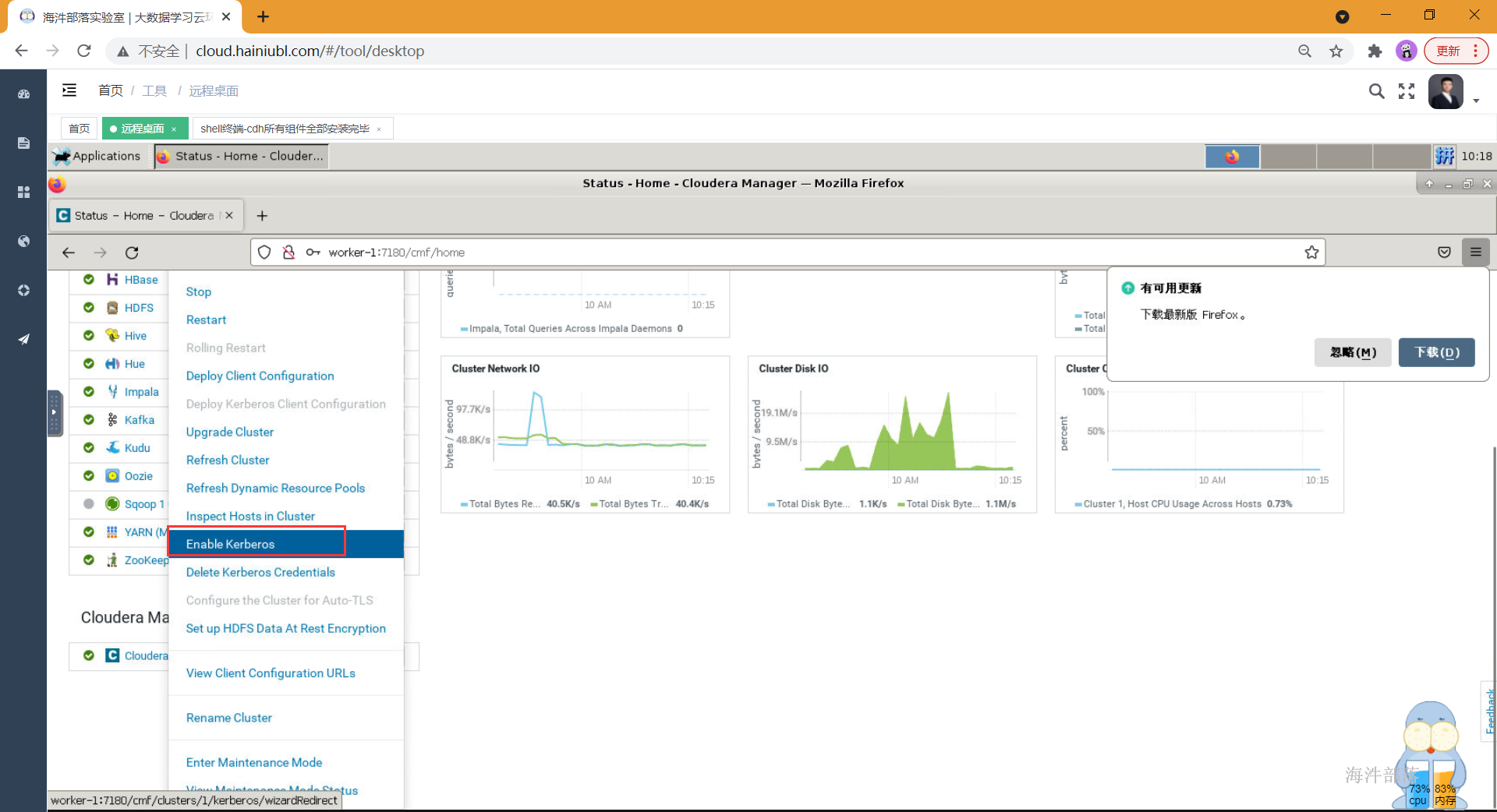
然后按照如下操作进行
- 页面1,检查提示
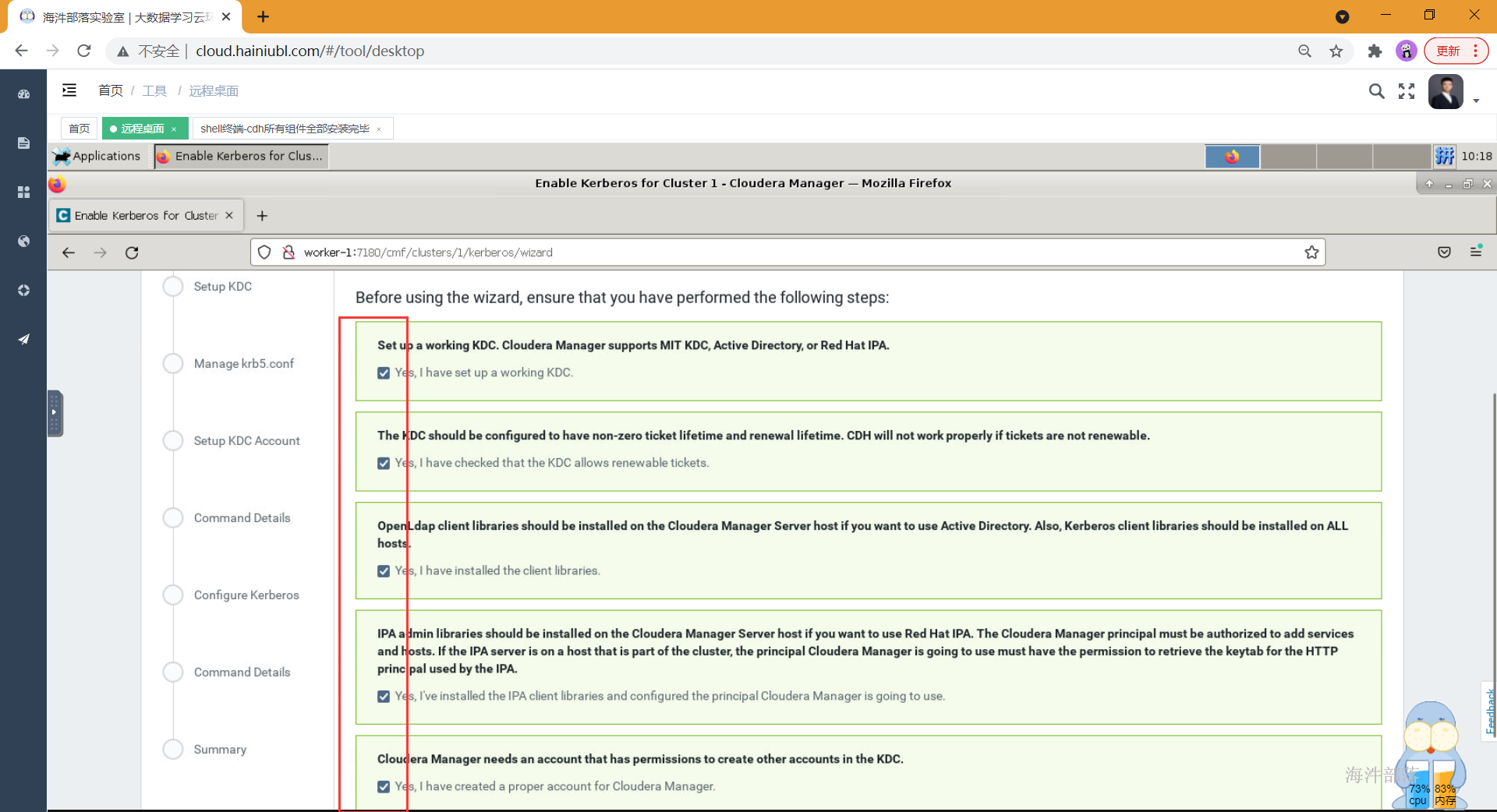
-
页面2,配置kerberos服务端信息
KDC Type: MIT KDC
Kerberos Security Realm: HAINIU.COM
KDC Server Host: worker-1
KDC Admin Server Host: worker-1
Kerberos Encryption Types: rc4-hmac
Maximum Renewable Life for Principals: 5
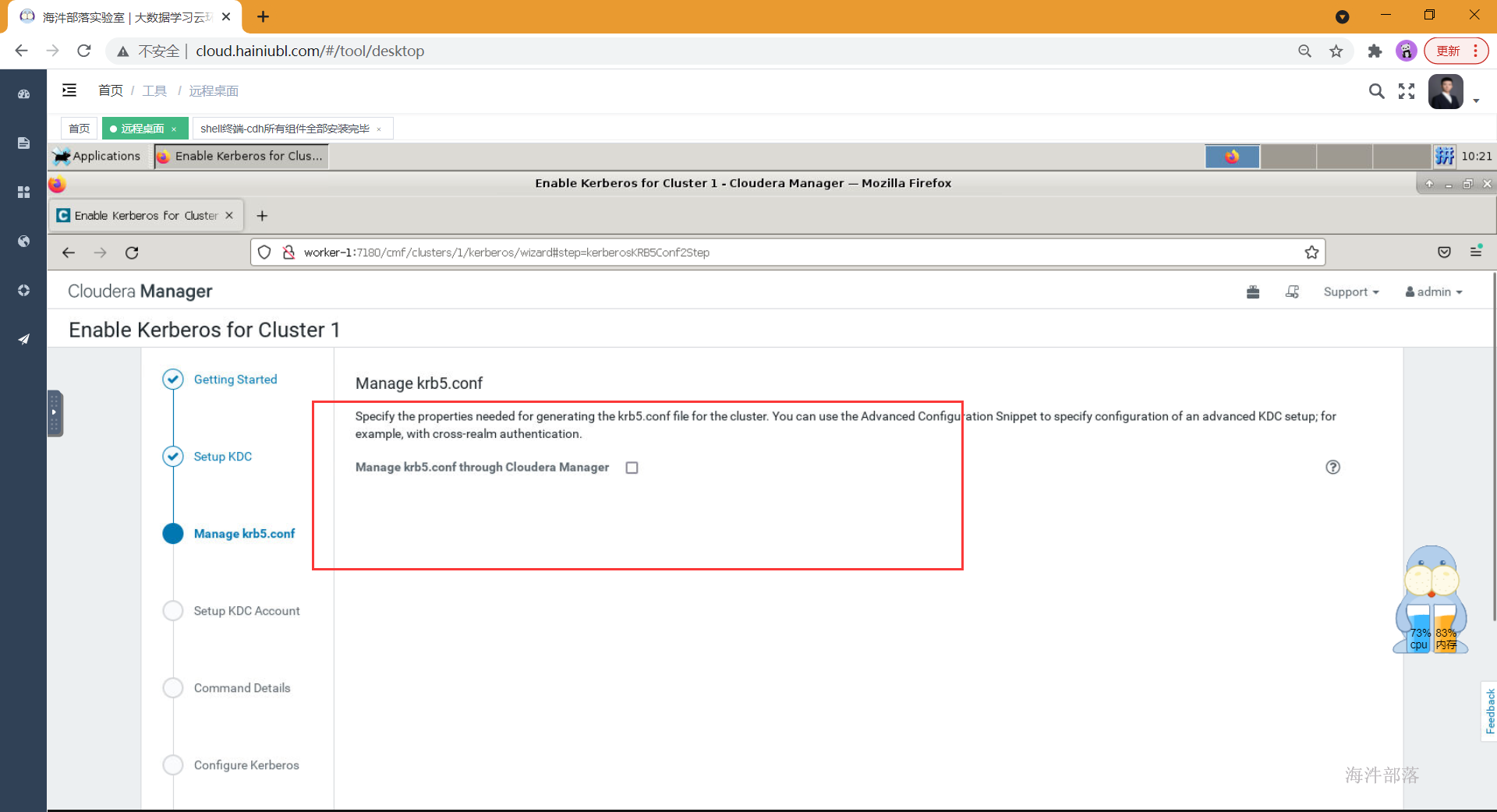
- 页面3,不要勾选该项(Manage krb5.conf through Cloudera Manager),直接继续
-
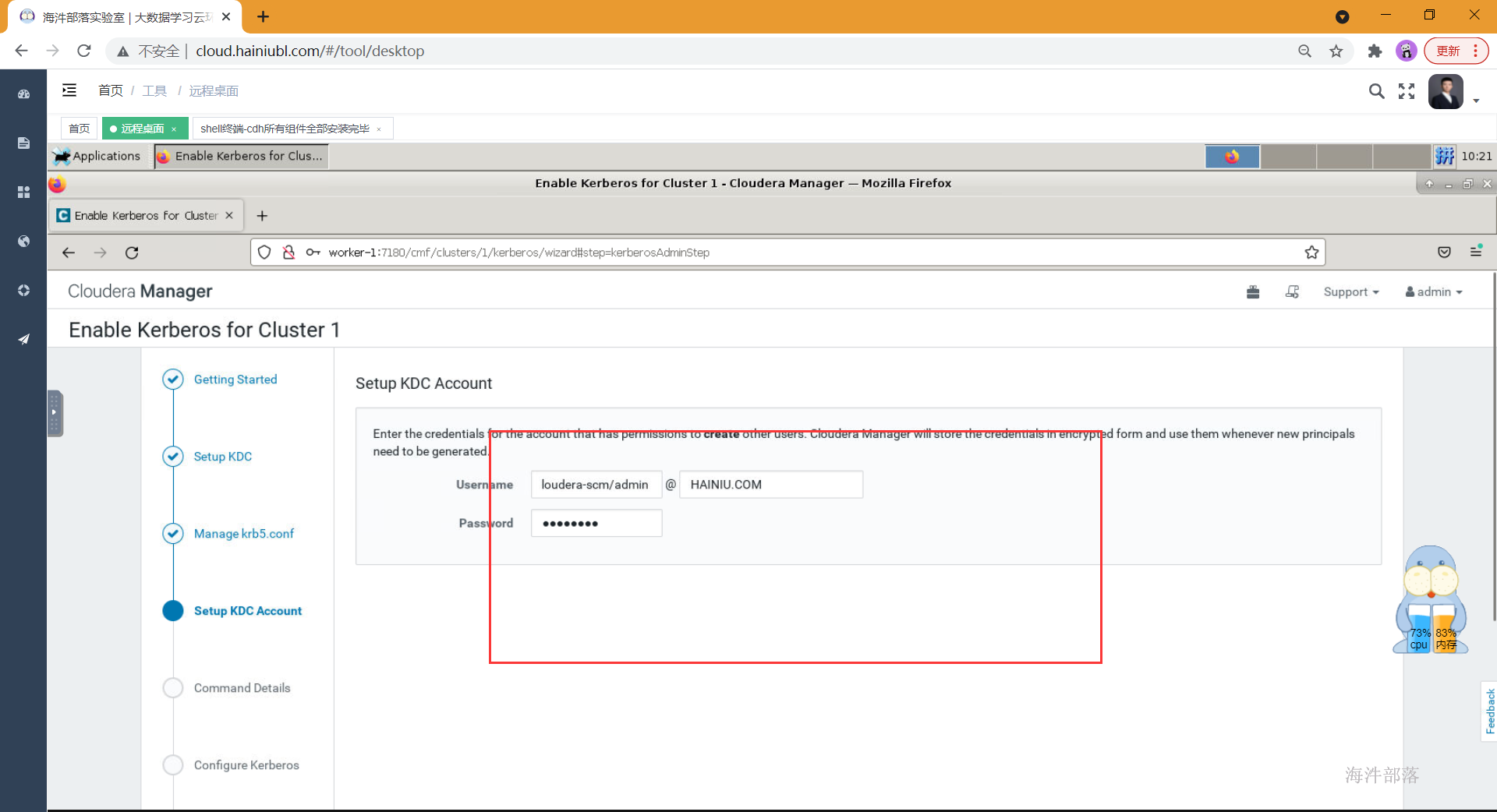
页面4,cloudera-scm/admin账号、密码
cloudera-scm/admin
12345678
-
页面5,页面6 Continue
-
页面7,确认HDFS特权端口,并选择重启集群(此过程需要十几分钟)
- 重启集群的时候报错,datanode启动失败
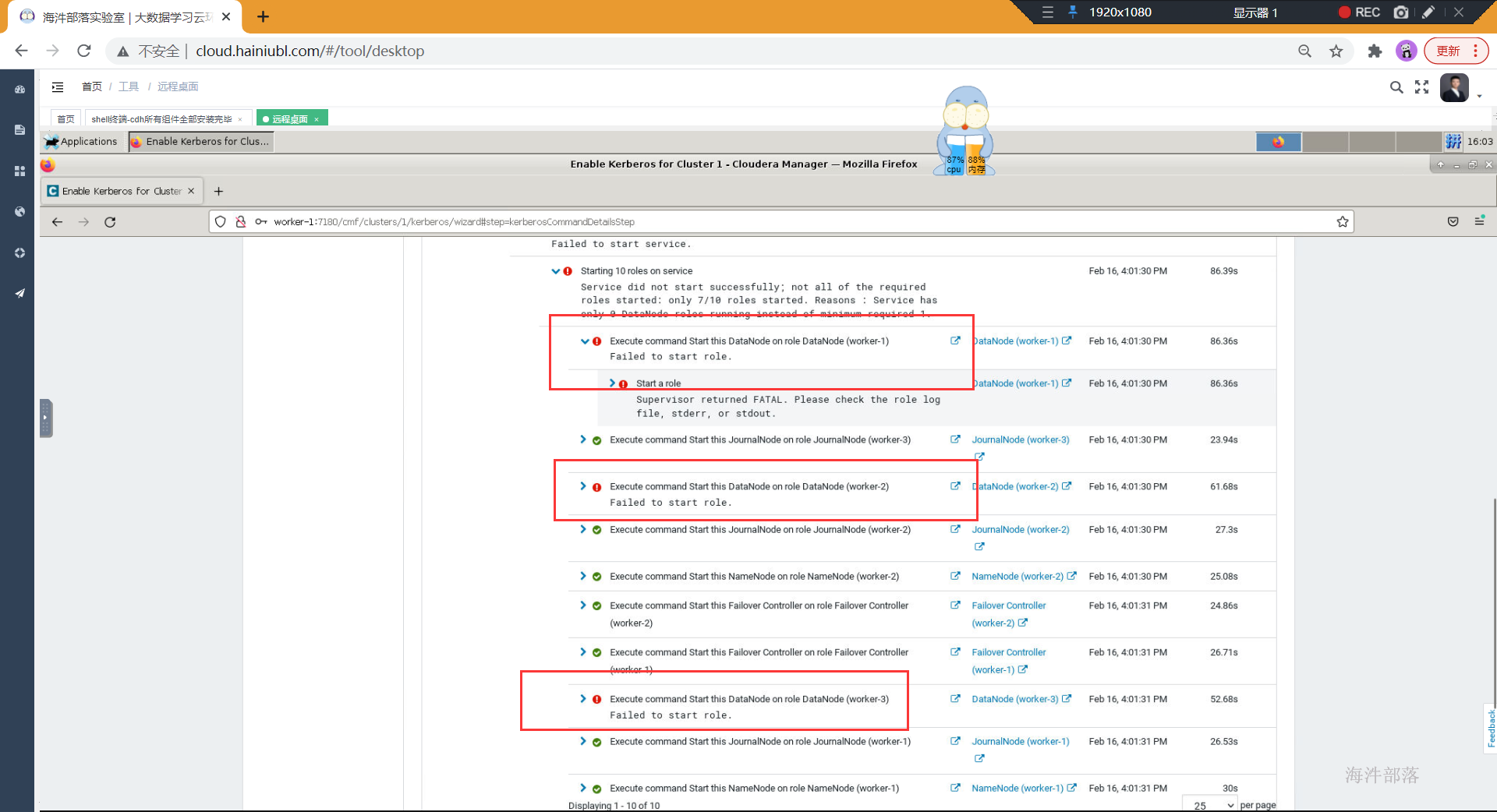
原因就是:
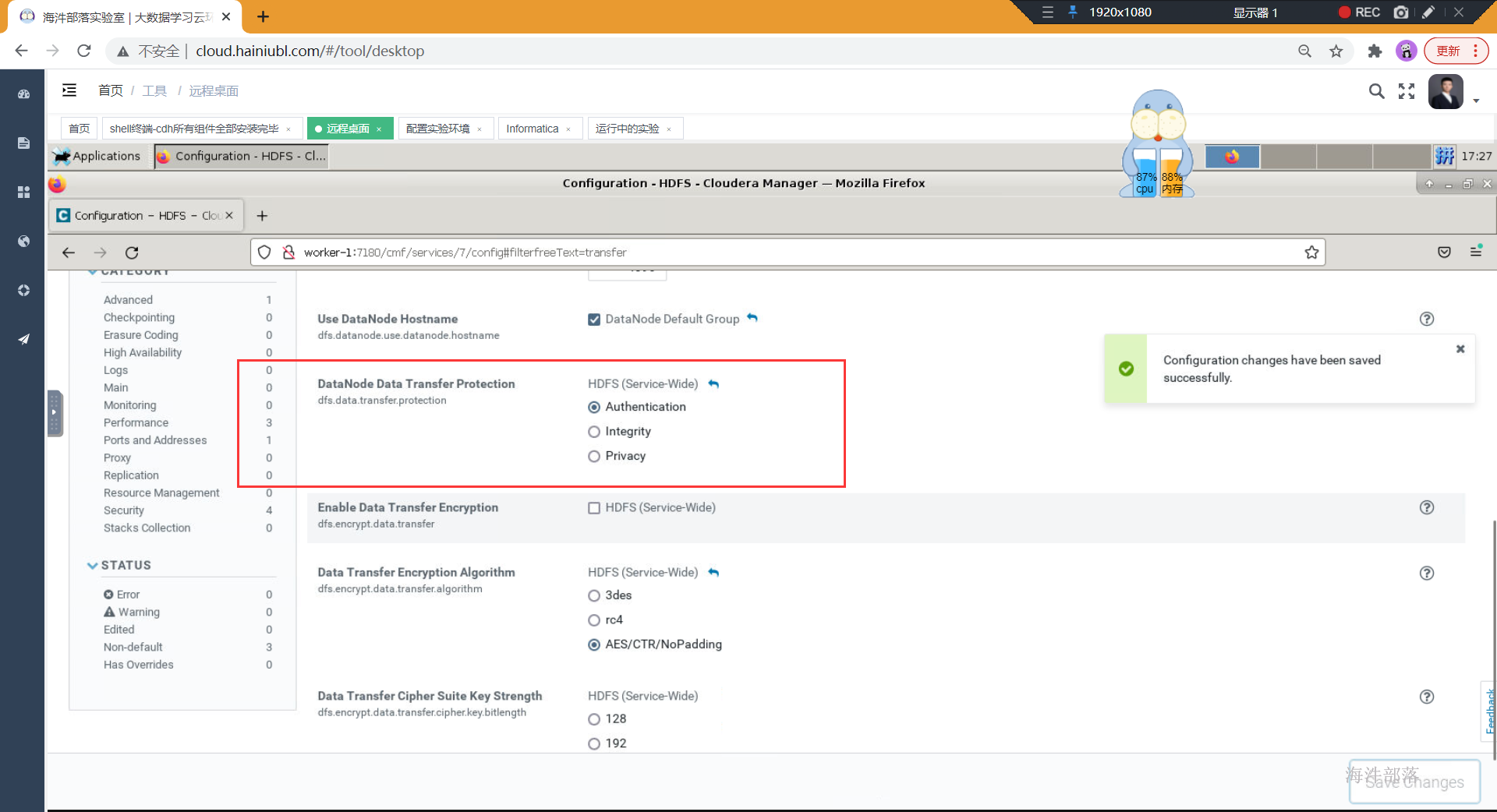
由于datanode数据传输走的不是rpc,而是http。所以datanode无法使用kerberos的方式进行认证。为了解决这个问题,有两种方式的配置,来实现datanode数据传输的安全性
- JSVC
JSVC方式启动datanode节点的时候,需要编译安装jsvc,通过JSVC工具,让datanode能够使用特权端口(这两个特权端口dfs.datanode.address和 dfs.datanode.http.address(小于1024))启动, 但是如果没有办法获取root权限,则没有办法启动datanode,巧了,我们云服务器不具备完整的root权限,所以采用第二种方式启动。
- TLS/SSL
TLS/SSL这种方式主要来实现数据的安全传输的,将特权端口配置成大于1024,并开启TLS,就可以绕开获取root权限,即可启动datanode了
#所有机器创建目录
mkdir /opt/security
#密码统一:12345678
#在每一台服务器生成ca证书 先生成一个的CA证书,然后通过这个私有的CA证书给的其它证书签名,通过将私有CA的证书安装到各机器的信任区里,实现一个各机器间的TLS/SSL通信
openssl req -new -x509 -keyout hn_private.key -out ca_cert -days 9999 -subj '/C=CN/ST=beijing/L=beijing/O=bigdata/OU=bigdata/CN=localhost'
#生成自己的公私秘钥对 密码统一:12345678
keytool -keystore keystore -alias localhost -validity 9999 -genkey -keyalg RSA -keysize 2048 -dname "CN=localhost, OU=bigdata, O=bigdata, L=beijing, ST=beijing, C=CN"
#将上述的CA公钥证书导入本机的信任区truststore
keytool -keystore truststore -alias CARoot -import -file ca_cert
#将上述的CA公钥导入本机的keystore中
keytool -keystore keystore -alias CARoot -import -file ca_cert
#将本机的公钥证书导出
keytool -certreq -alias localhost -keystore keystore -file local_cert
#用CA私钥,对本机的公钥证书进行签名
openssl x509 -req -CA ca_cert -CAkey hn_private.key -in local_cert -out local_cert_signed -days 9999 -CAcreateserial
#将签名后的证书导入的自己的Keystore
keytool -keystore keystore -alias localhost -import -file local_cert_signed
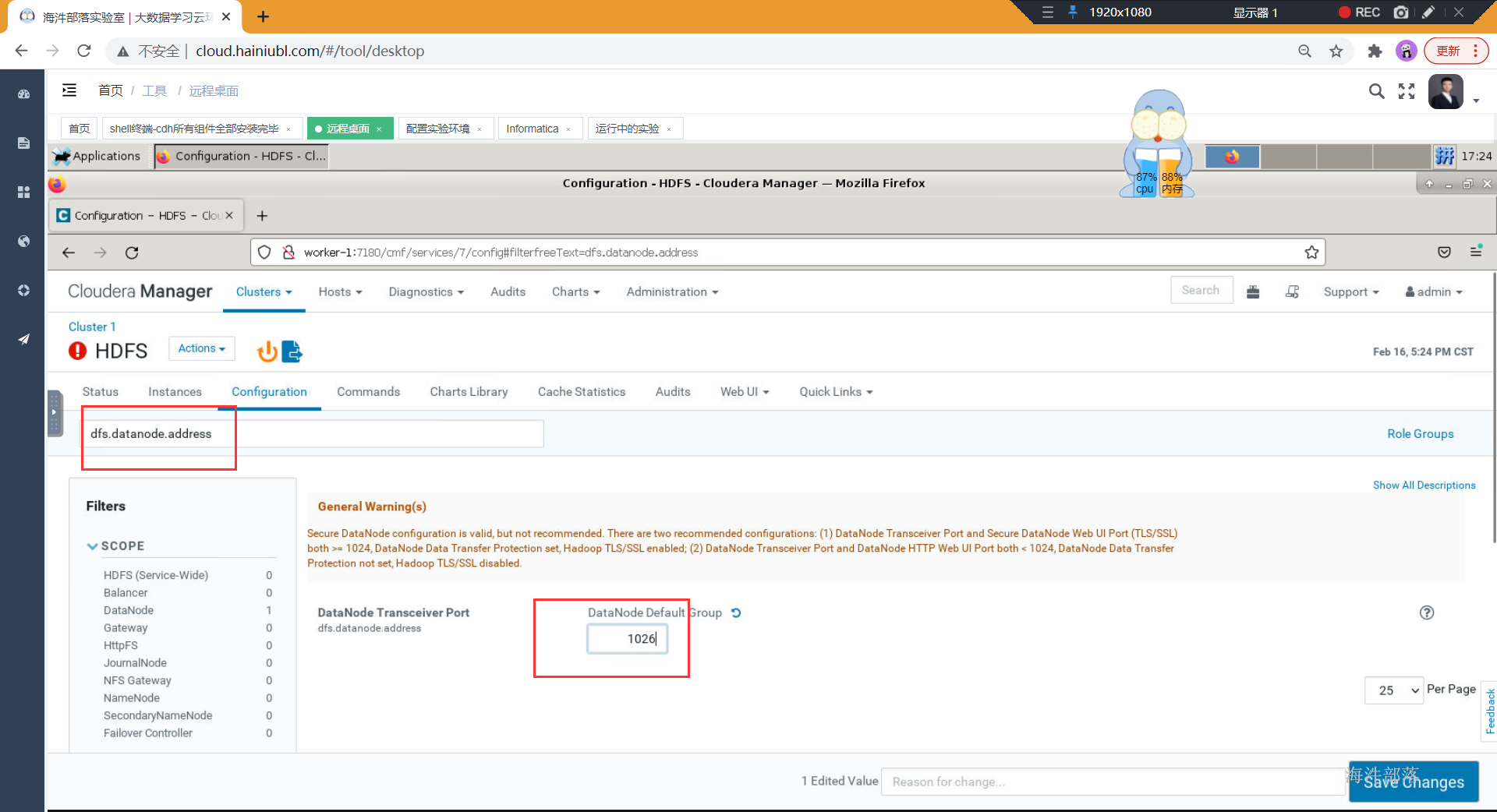
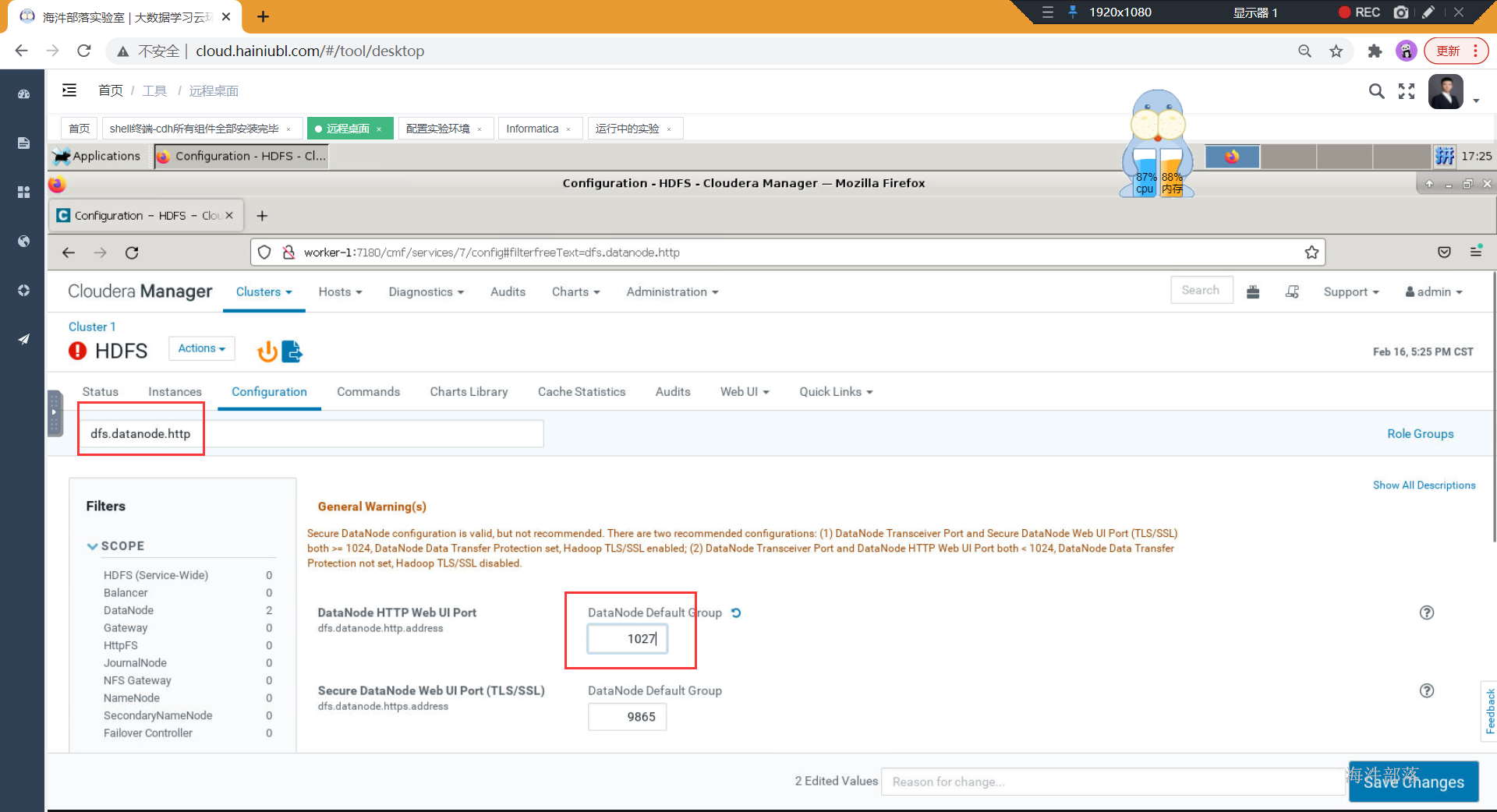
接着打开hdfs的configuration
修改以下内容:
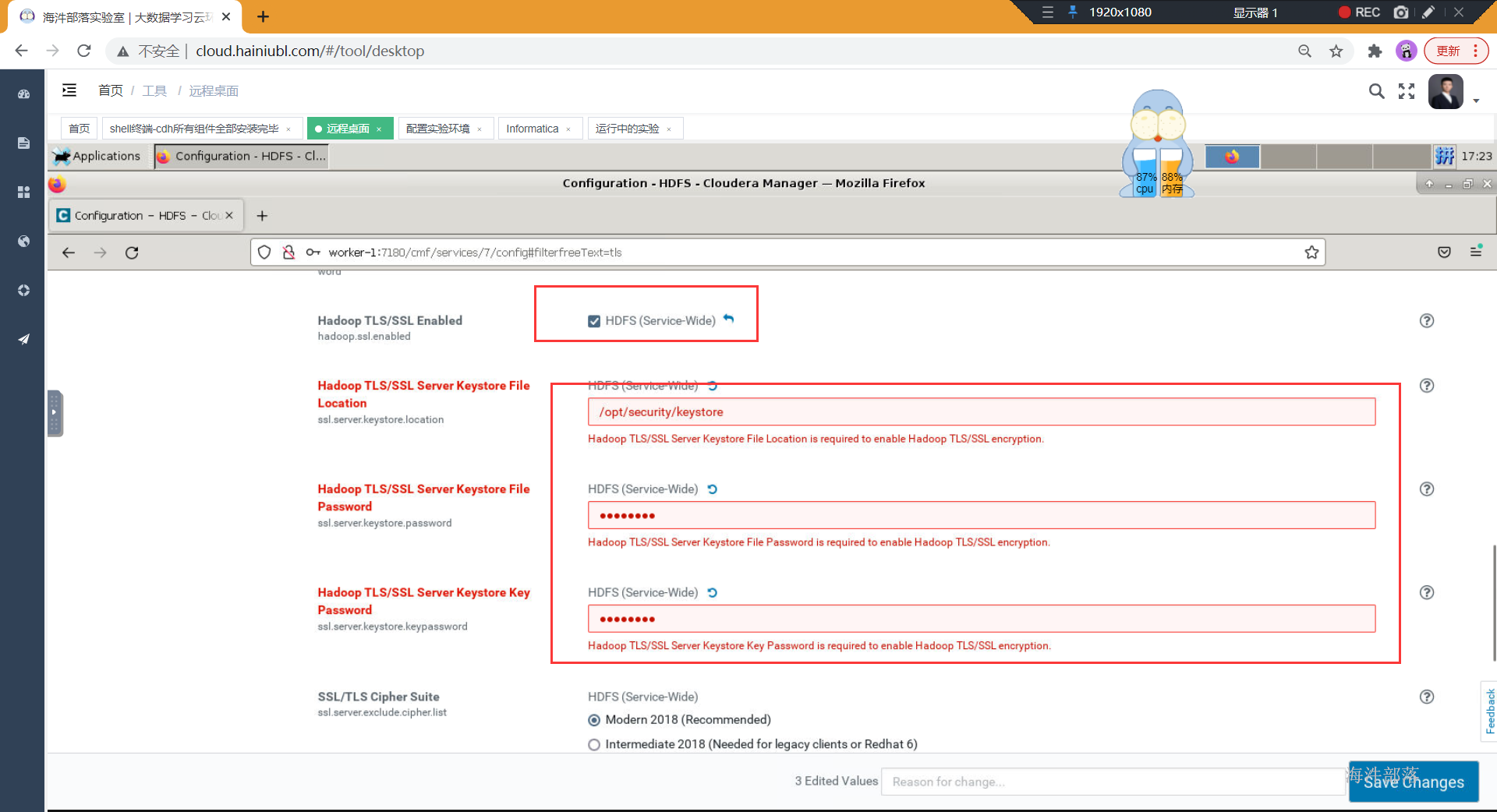
弹出警告:特权端口必须设置成大于1024
修改yarn的配置页面修改一下内容
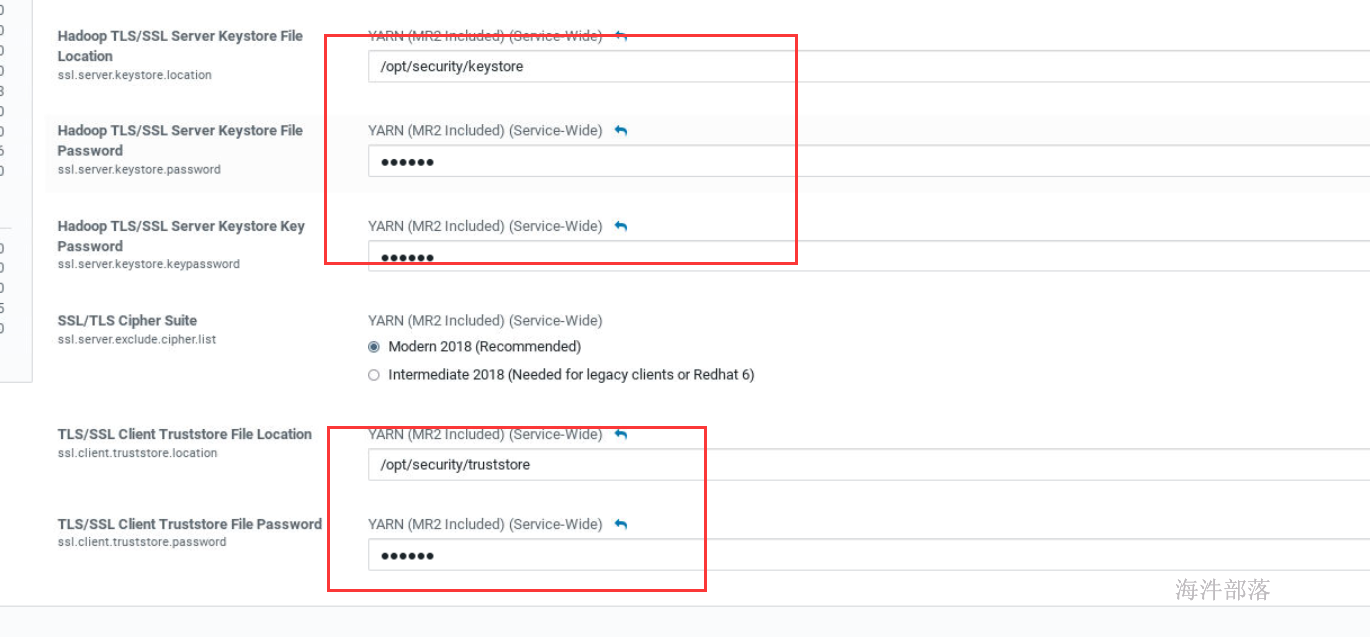
重新启动即可
远程桌面配置kerberos认证
当我们安装好kerberos之后,想要访问namenode页面,发现没有认证不让访问。
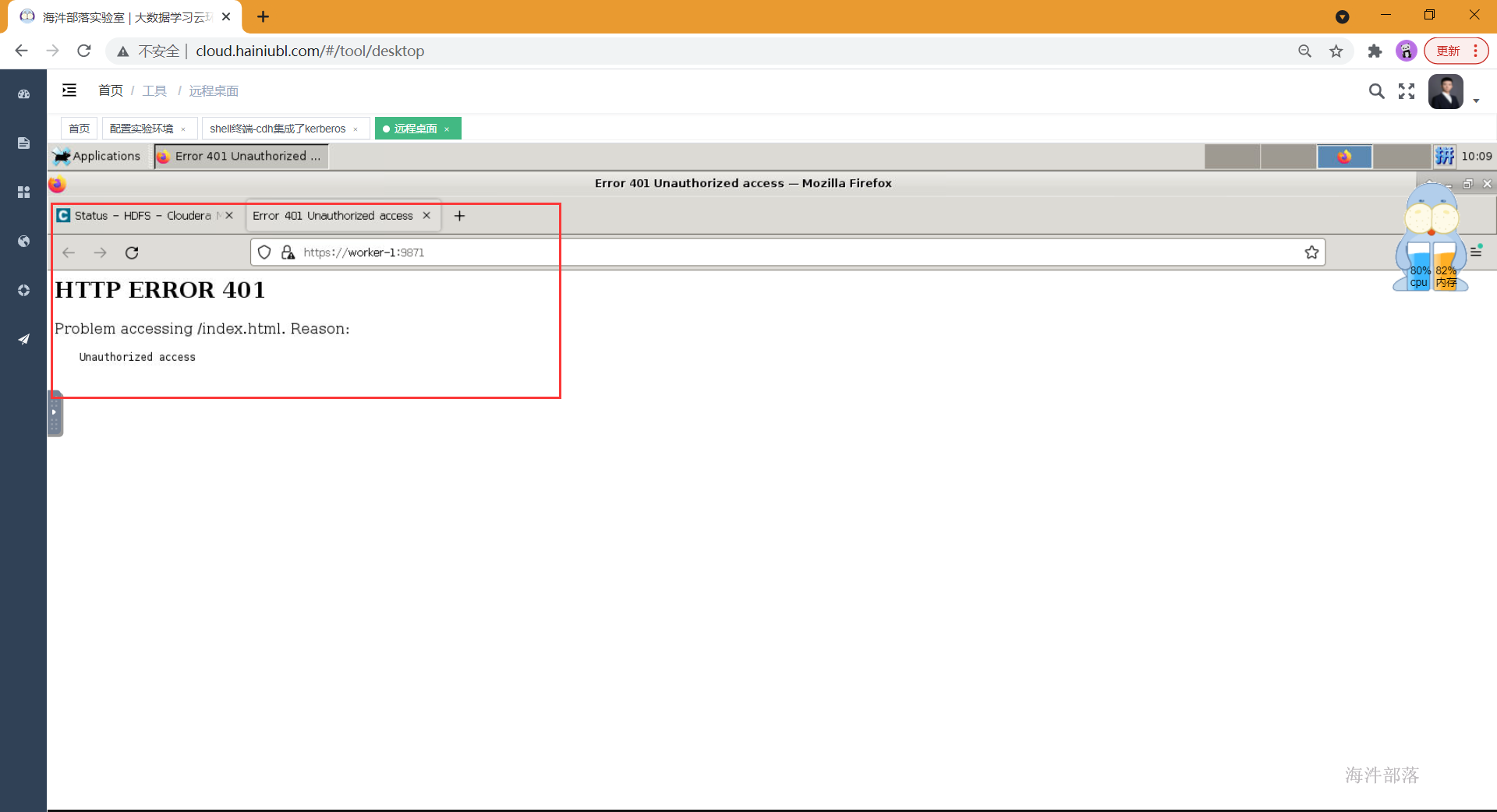
配置远程桌面添加kerberos认证
- 远程桌面安装kerberos客户端
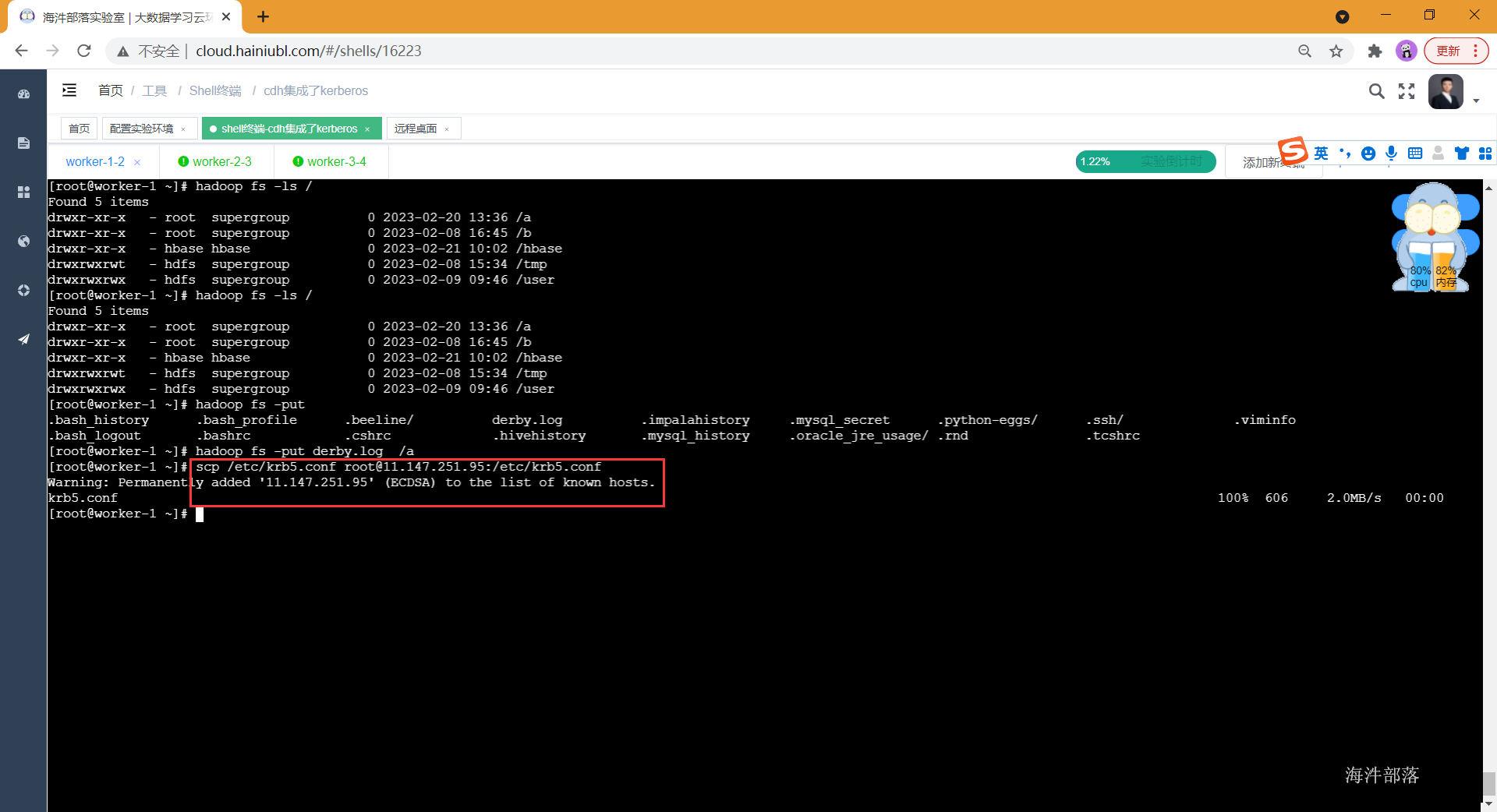
- 将krb5.conf传递到远程桌面所在服务器
- 火狐浏览器配置
火狐浏览器地址栏输入"about:config"
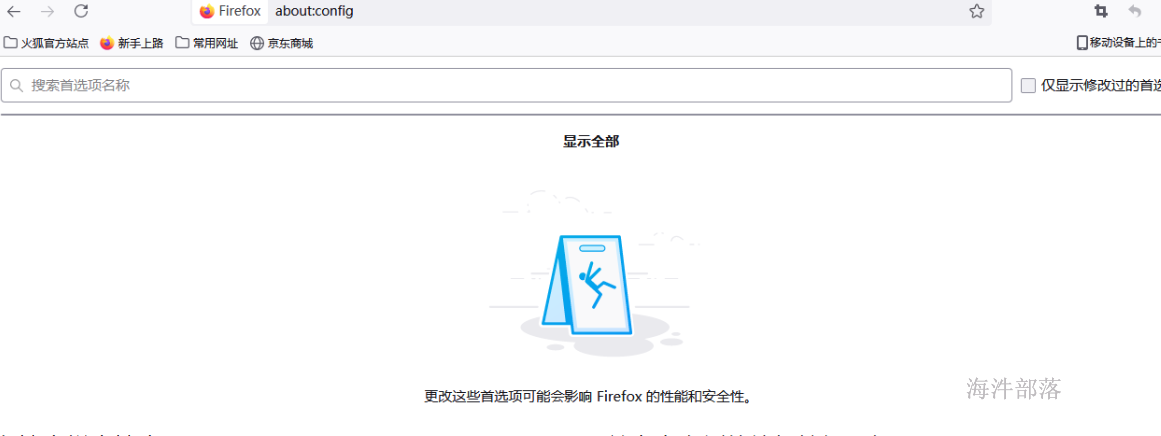
在搜索栏中搜索"network.negotiate-auth.trusted-uris",并点击右侧的编辑按钮,如下:
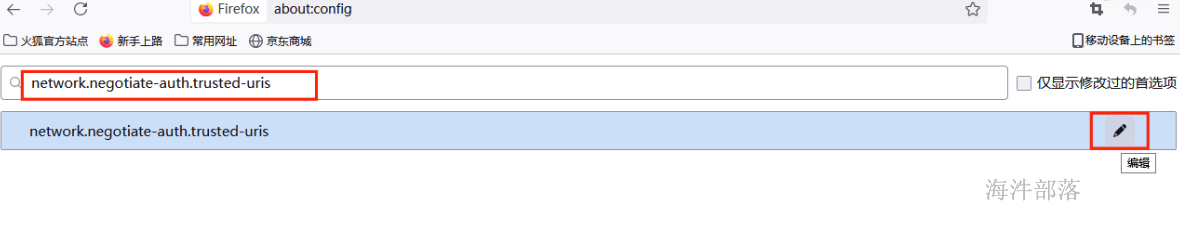
输入要访问节点的hostname,多个hostname使用","分割,如下:

搜索栏中再次搜索"network.auth.use-sspi",并修改为false。

1.8 kerberos使用
- 进入管理界面
kadmin.local- 创建principal(认证主体)
使用管理员创建认证主体,即principal,principal由主体名@域名组成,域名一般都设置为公司的域名。
# 语法格式:
# addprinc -pw 密码 主体名@域名
# 创建hdfs认证主体
addprinc -pw hdfs hdfs@HAINIU.COM
# 创建hive 认证主体
addprinc -pw hive hive@HAINIU.COM
# 创建hbase 认证主体
addprinc -pw hbase hbase@HAINIU.COM
- 生成keytab凭证
给主体principal生成keytab凭证,用于后面的kinit认证操作,此处的参数-norandkey意义为不随机生成密码,沿用创建主体时的密码,这样就可以即能使用keytab认证也能使用密码认证了。
# 语法格式:
# xst -norandkey -k 主体文件生成位置 主体名
# 生成hdfs的keytab
xst -norandkey -k /data/hdfs.keytab hdfs
# 生成hive的keytab
xst -norandkey -k /data/hive.keytab hive
# 生成hbase的keytab
xst -norandkey -k /data/hbase.keytab hbase
exit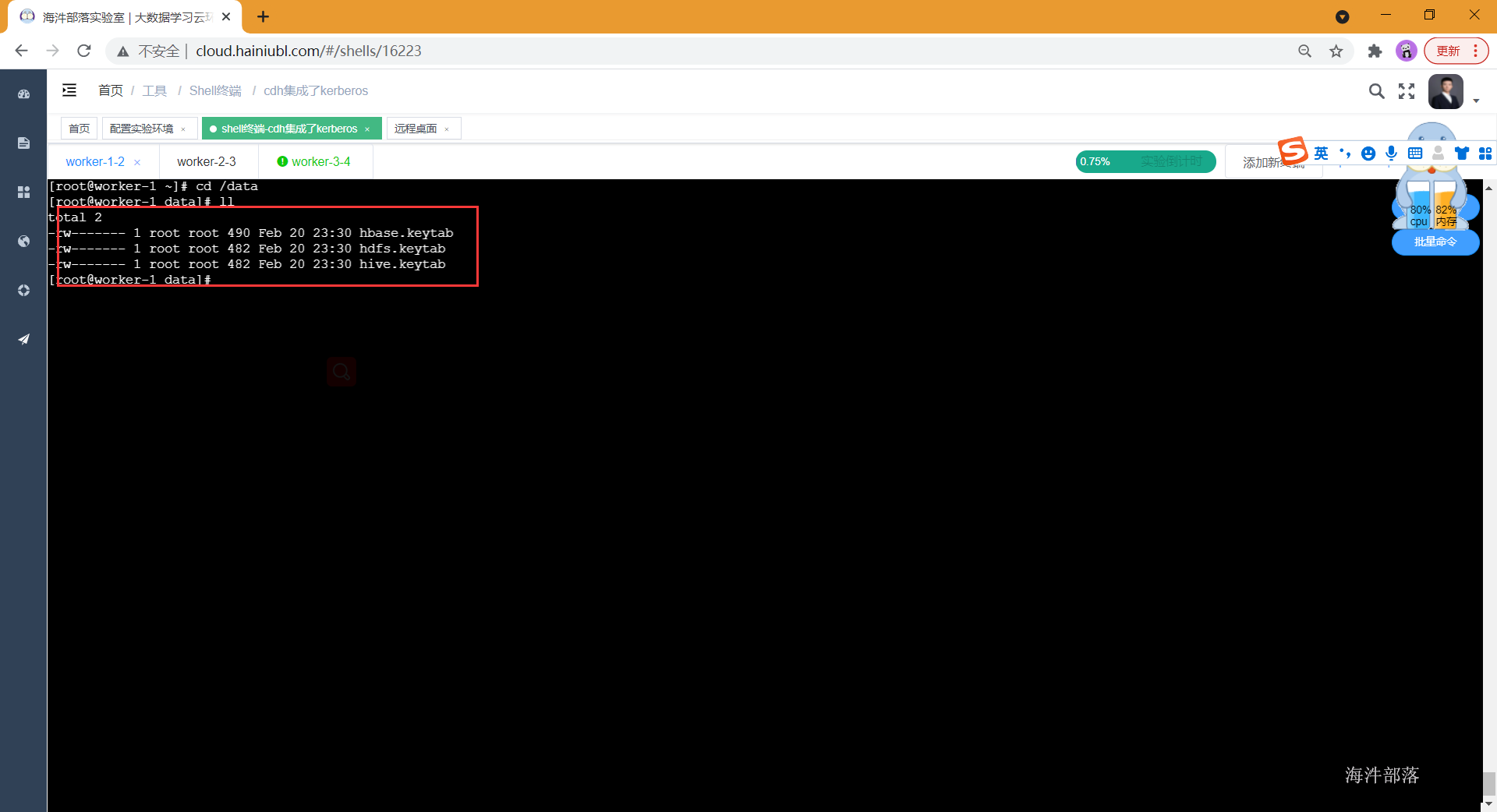
- kerberos认证的两种方式
进行安全认证,共有两种方式,如下:
1)主体加密码的方式认证
此种方式适合测试用。
# 用主体加密码的方式认证
kinit hdfs
# 输入密码,即创建主体principal时-pw设置的密码
password
# 查看当前票据
klist
# 销毁当前票据
kdestroy2)使用keytab认证
此种方式适合生产环境用,比如在脚本中加入认证。
# 使用keytab认证 参数kt意义为keytab文件路径 后面接要认证的主体名,keytab文件要和主体名一致
kinit -kt /data/hdfs.keytab hdfs
# 查看当前票据
klist- 验证hadoop操作
通过安全认证后再操作Hadoop集群,验证是否可以正常使用Hadoop命令。
hadoop fs -ls /- 认证的一些操作
# 查看票据
klist
# 销毁票据
kdestroy
# 删除主体(该操作需要管理员用户才能执行,需要进入kadmin.local界面下操作)
kadmin.local
delprinc '主体名'
6. 启用kerberos认证环境下连接hive
在kerberos认证环境下连接hive,通过两种认证方式的任何一种认证都可以。连接时可以直接使用hive的client端连接,或者使用beeline的方式连接,由于hive集成sentry以后不能用hive client方式执行权限管理,所以推荐用beeline 连接方式。
# 先认证
kinit -kt /data/xxxx.keytab xxxx或者kinit xxxx 输入密码
# 后通过beeline连接hive, 在内部通过 !q 退出beeline
# hiveserver2服务地址: jdbc:hive2://worker-3:10000
# worker-3@HAINIU.COM 中的 worker-3 是对应的是hive server端主体名
beeline -u "jdbc:hive2://worker-3:10000/;principal=hive/worker-3@HAINIU.COM"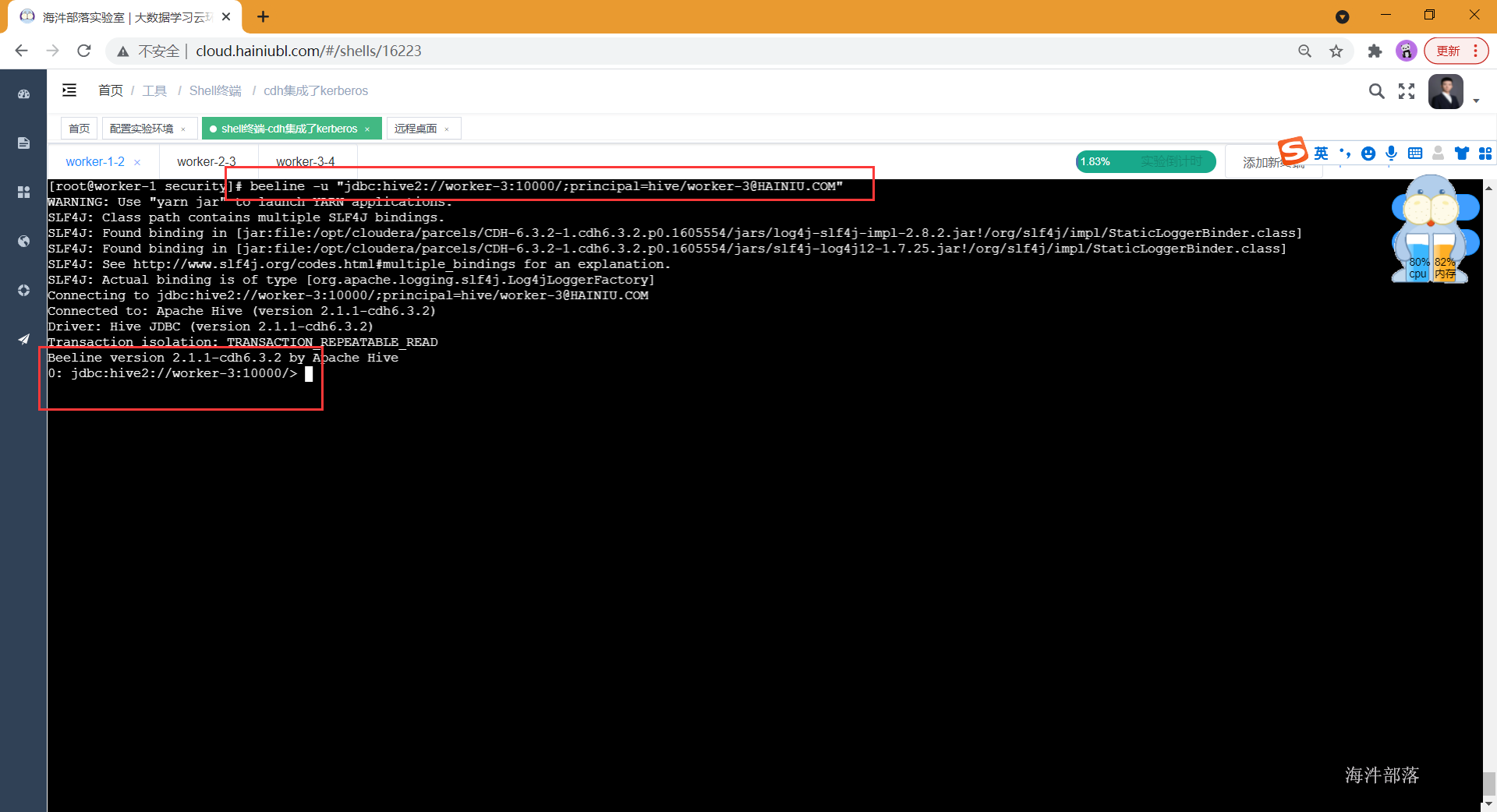
2 sentry 部署
2.1 sentry概述
sentry是Cloudera公司开源开源组件,后贡献给Apache,提供数据支持细粒度权限控制,支持hive、impala、hbase等
2.2 cdh添加sentry服务
sentry也是Cloudera公司开源给Apache的,直接在cm页面配置即可。
-
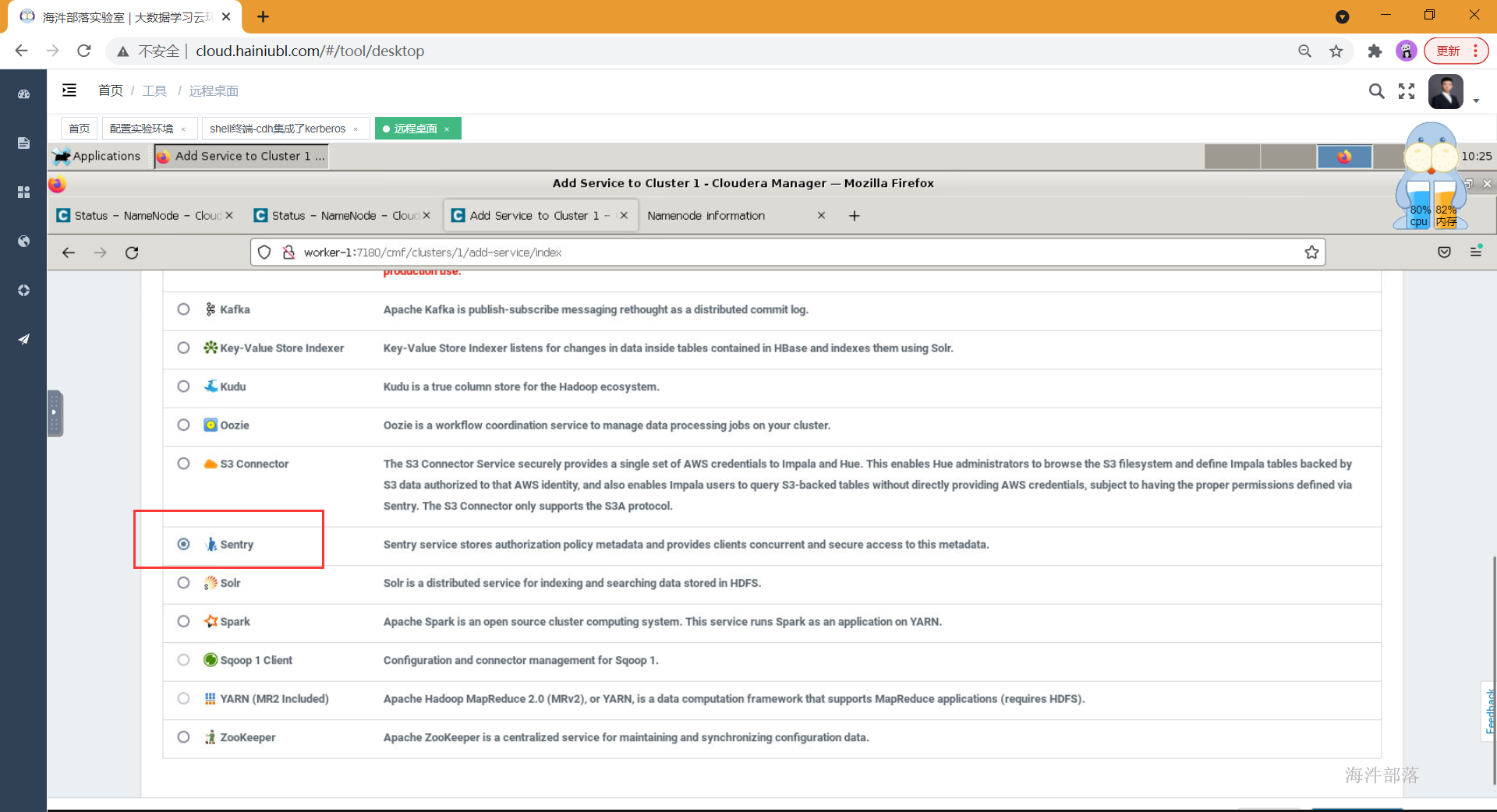
添加服务
依次点击Cloudera Manager -> Cluster 1 -> Add Service -> Sentry
-
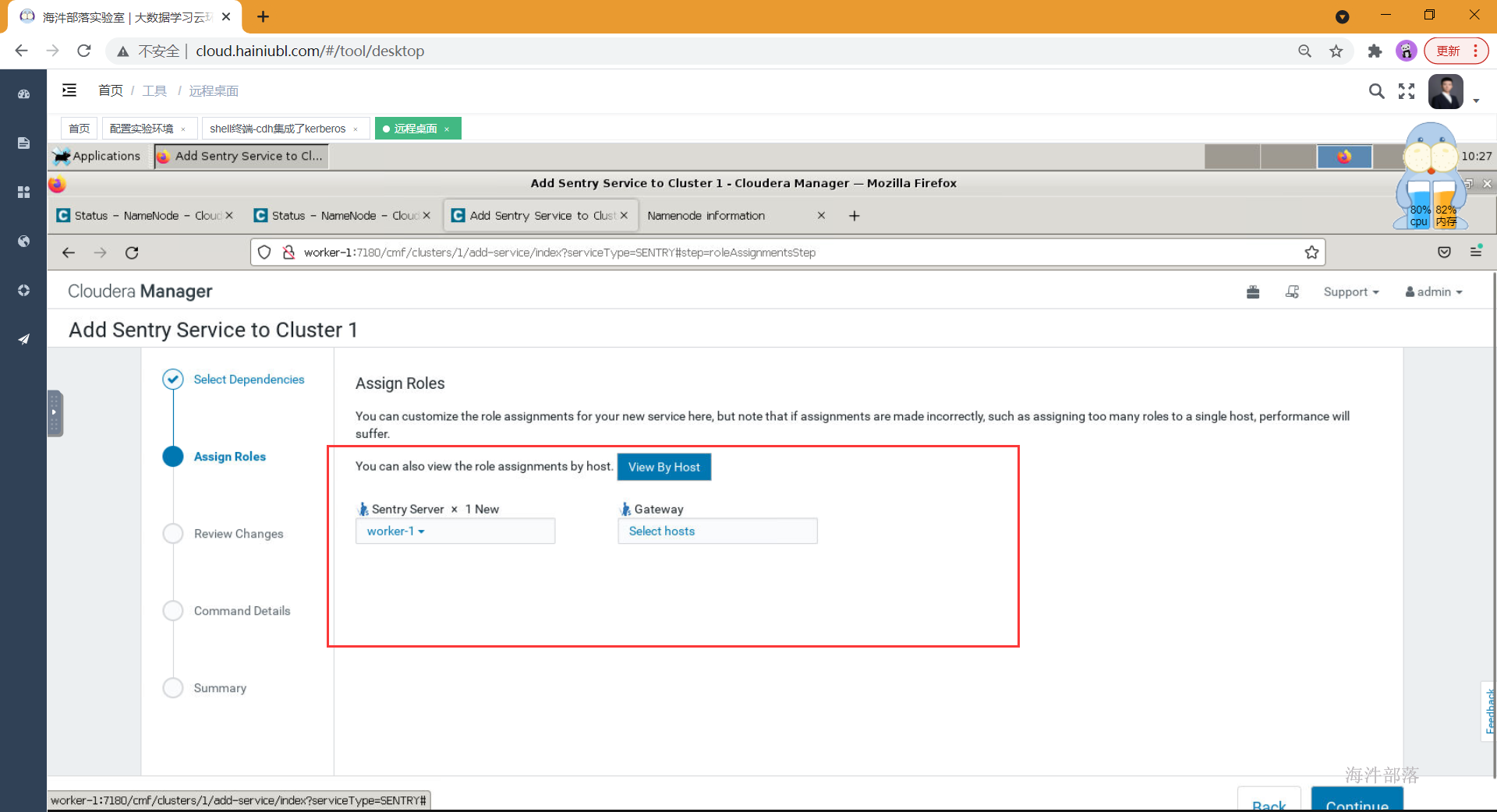
节点选择
选择Sentry Server所在服务器,Gatway可以不选。
-
填写元库信息
填写元数据库信息: sentry sentry sentrydemima,这个元库信息是在cdh部署时cm元库创建时的信息。
安装时如果由于缺少mysql jdbc驱动报错,请复制jdbc驱动到以下目录
cp /tmp/cloudera/mysql-connector-java-5.1.35.jar /opt/cloudera/parcels/CDH/lib/sentry/lib/
如上,服务添加完成。
2.3 hive集成sentry
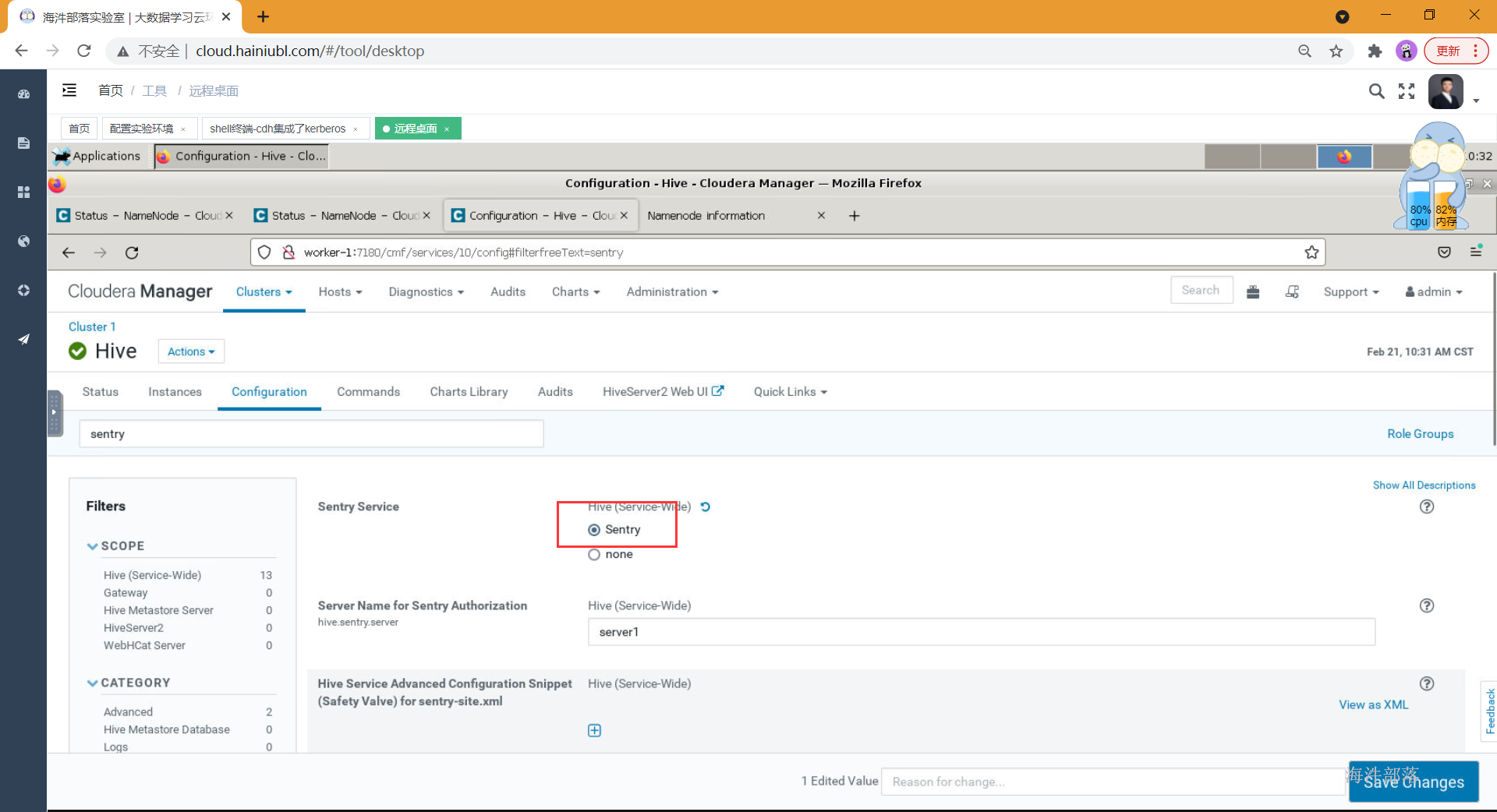
1)开启hive的sentry权限管理
依次点击Clusters -> Hive -> Configuration -> 搜索: sentry,选择hive组件,点击配置,搜索senty,然后Sentry Service [勾选] Sentry。
2)关闭所有HiveServer2的Impersonation
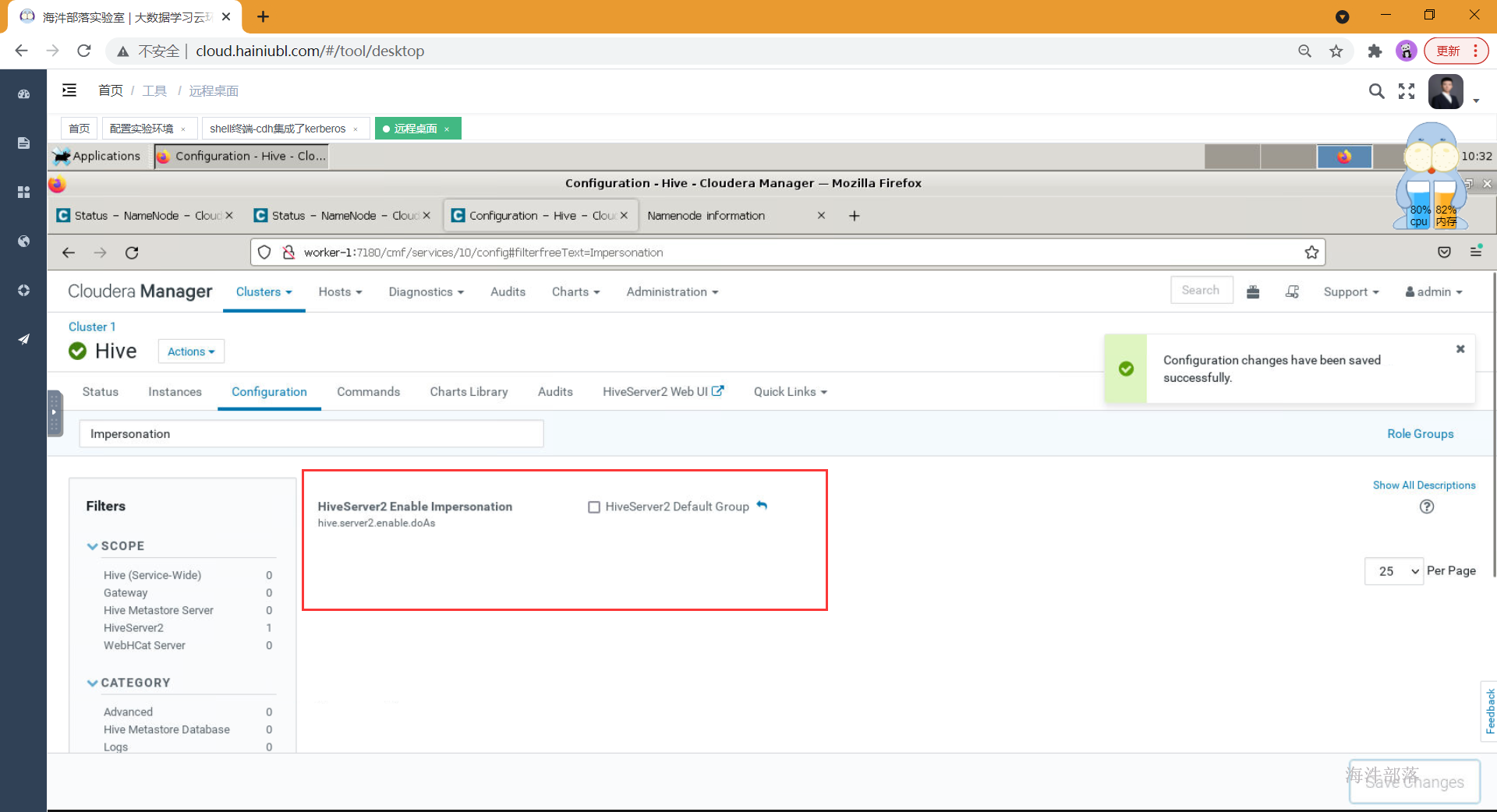
在hive的配置项中搜索:Impersonation,[去除勾选] HiveServer2
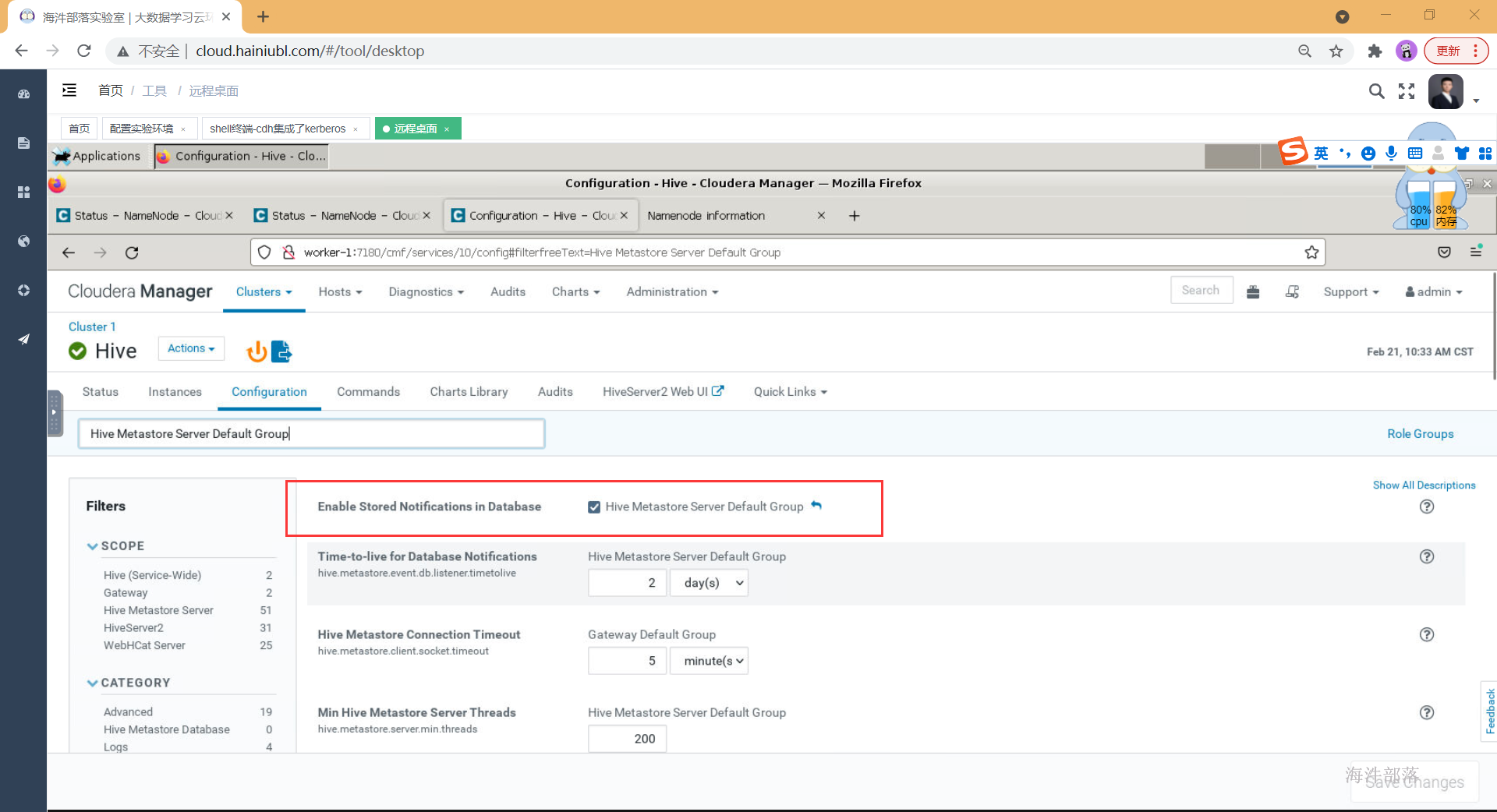
3)启用数据库存储通知
在hive配置中搜索:Hive Metastore Server Default Group,然后[勾选] Hive Metastore Server Default Group
4)保存并重启hive服务
2.4 impala集成sentry
点击impala组件,点击配置,在搜索栏中搜多:Sentry,然后Sentry Service [勾选] Sentry
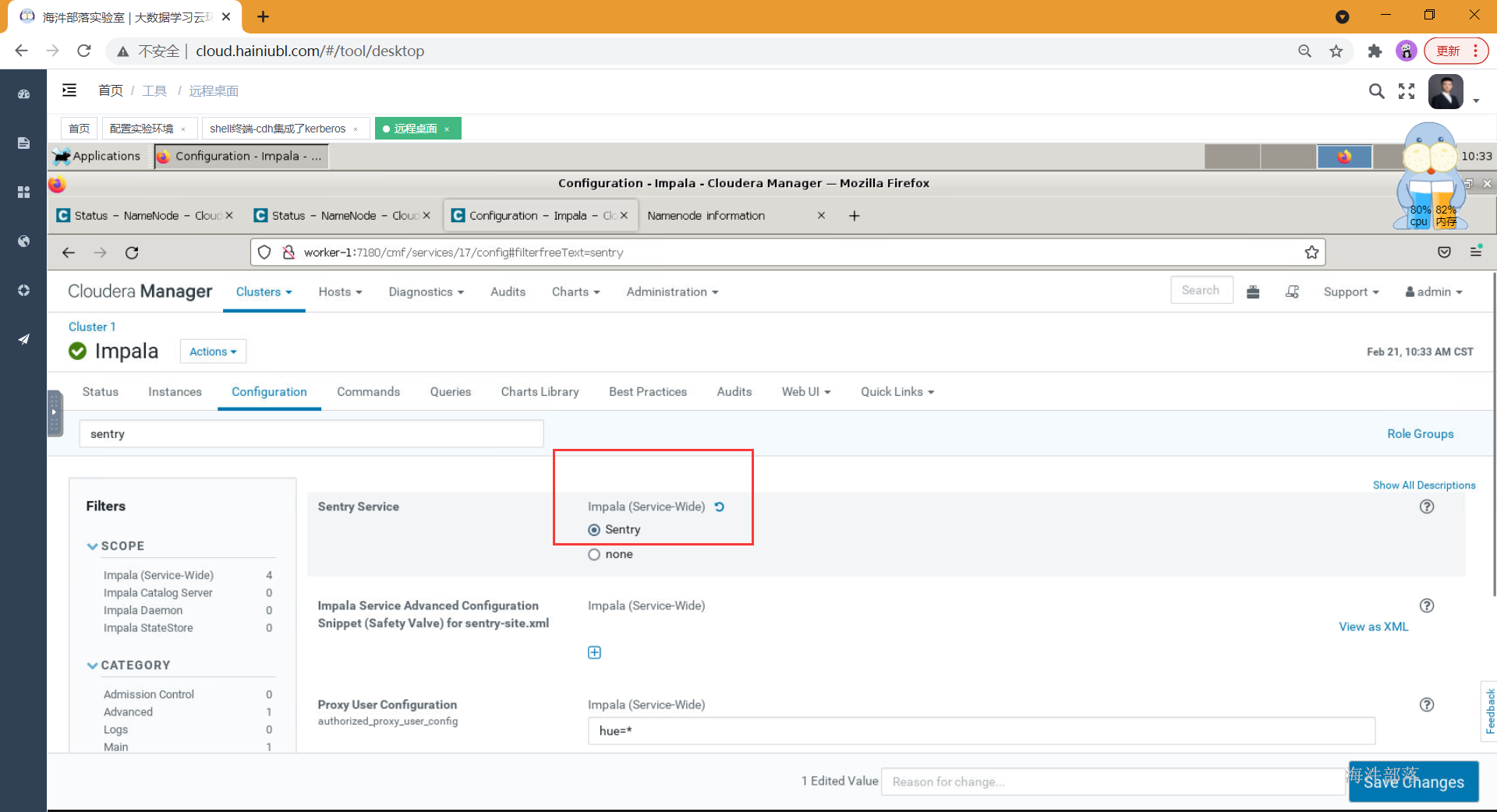
保存并重启Impala服务
2.5 hue集成sentry
点击hue服务,点击配置,在搜索栏中搜索:Sentry,然后Sentry Service [勾选] Sentry
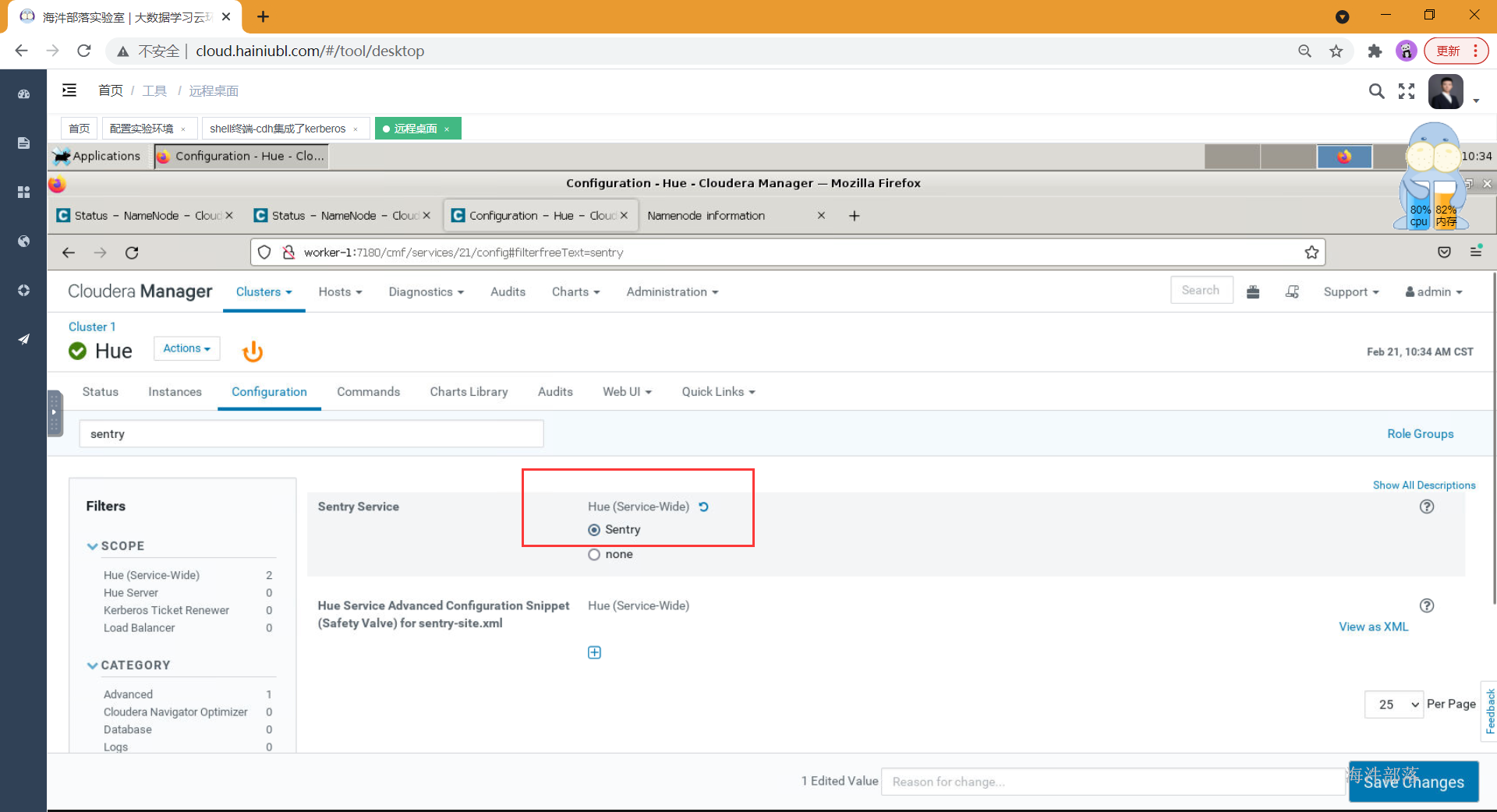
保存并重启Hue服务
2.6 hdfs集成sentry
点击hdfs组件,点击配置,在搜索框中搜索:"启用访问控制列表"或者"dfs.namenode.acls.enabled",然后[勾选] HDFS (Service-Wide);
在搜索框中搜索:"acl",然后[勾选] HDFS (Service-Wide)
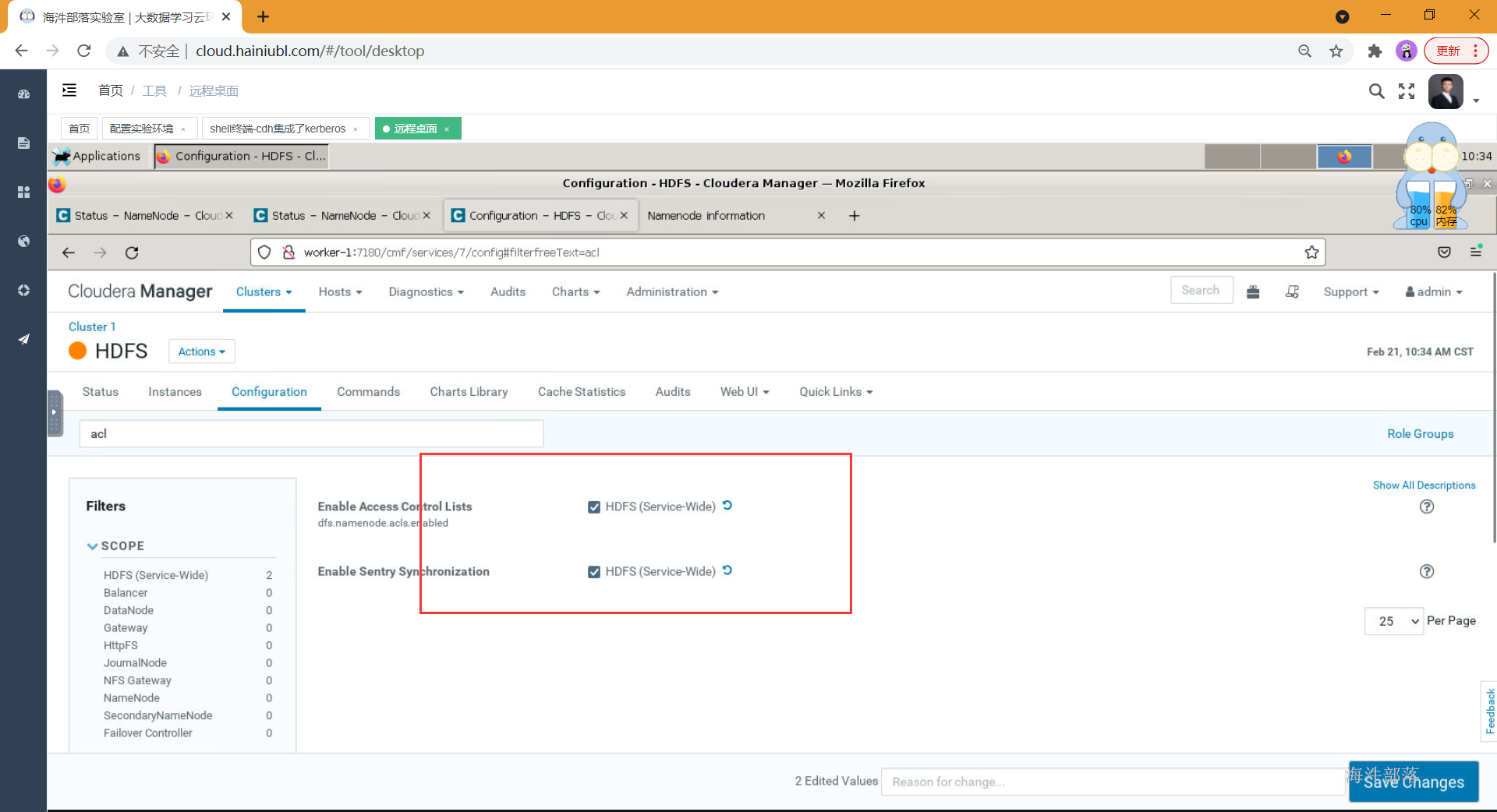
保存并重启HDFS服务
2.7 Sentry测试
2.7.1 sentry权限管理-hive
kerberos 认证环境下连接hive
- 通过kerberos认证连接hive
kinit -kt /data/hive.keytab hive- 使用kerberos认证方式登录hive
使用beeline的方式连接hive,第一个worker-1为hiveserver2所在节点的域名,第二个worker-1为hive的server服务器对用主体的域名,不要混淆。
beeline -u "jdbc:hive2://worker-3:10000/;principal=hive/worker-3@HAINIU.COM"2.7.2 sentry操作
sentry在hive中只能对用户组进行授权。
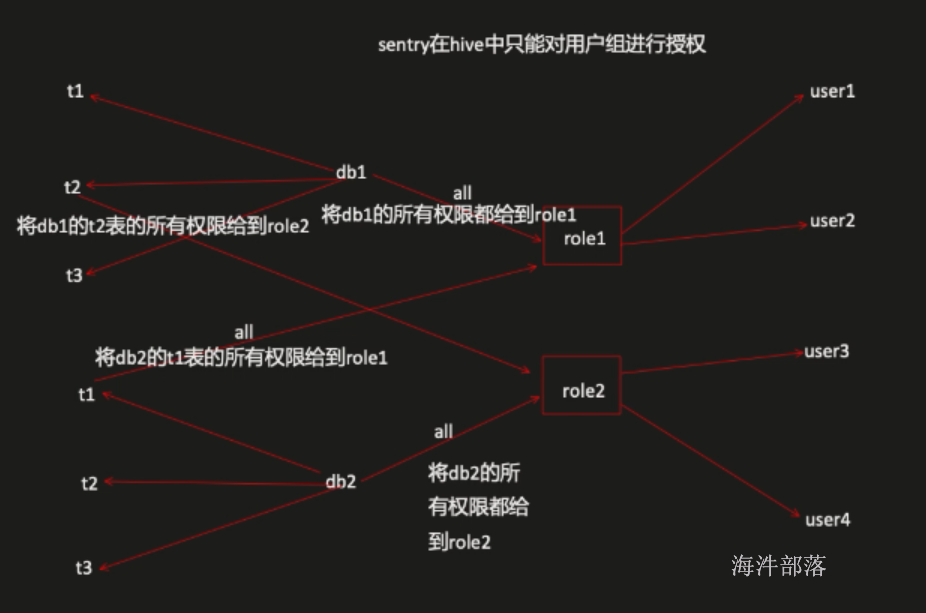
sentry一些常用操作,如下:
-- 创建角色
create role user1_role;
-- 查看角色列表
show roles;
-- 给角色赋予数据库权限
grant all on database db1 to role user1_role;
-- 给角色赋予表权限
grant select on table db2.test2 to role user1_role;
-- 给角色赋予表中的某一列的权限
grant select(id) on table db2.test2 to role user1_role;
-- 授权角色给用户组
grant role user1_role to group user1;
-- 查看角色权限
show grant role user1_role on database db1;
show grant role user1_role on table test1;
-- 查看某个组都授权了哪些角色
show role grant group hainiu;
-- 删除角色
drop role user1_role;
-- 权限收回
revoke select on table db2.test2 from role user1_role;
revoke all on database db2 from role user2_role;
2.7.2.1 准备测试用的库和表
开启sentry后的hive客户端不能授权,要用beeline。
1)创建超级管理员角色,并赋予hive
-- 认证
kinit hive
-- 连接hive
beeline -u "jdbc:hive2://worker-3:10000/;principal=hive/worker-3@HAINIU.COM"
-- 创建超级角色
create role admin_role;
-- 给超级角色赋予server级别的所有权限
grant all on server server1 to role admin_role;
-- 其中: server1 是在sentry-site.xml 中配置
<property>
<name>sentry.hive.server</name>
<value>server1</value>
</property>
-- 给hive 赋予超级角色
grant role admin_role to group hive;
-- 查看hive的权限情况
show role grant group hive;
-- 注意:
-- 可以将超级角色赋给linux其它用户组,这样其他用户组也有了超级权限。
-- 如果只有sentry,每个用户如果用超级管理员登录,就没有权限
-- 必须要kerberos 和 sentry 配套使用。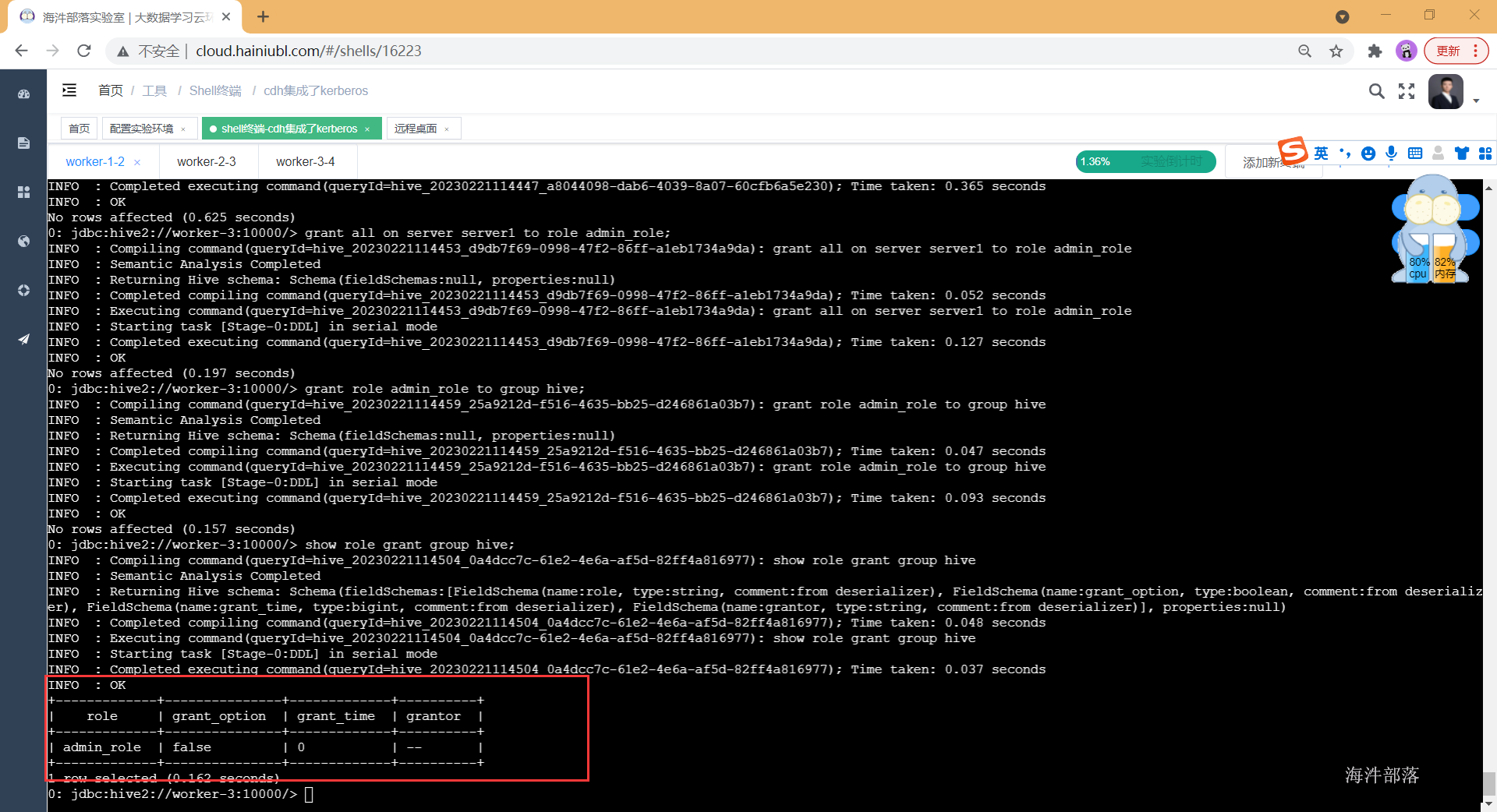
2)继续创建测试用的库和表
-- 创建db1库
create database db1;
-- 创建db2库
create database db2;
-- 在db2库中创建test1表
create table db2.test1(id string, name string);
-- 在db2库中创建test2表
create table db2.test2(id string, name string);2.7.2.2库、表、列权限测试
1)创建test1 用户并创建test1认证主体, 连接hive发现没有查看其它库的权限
useradd test1
passwd test1
# 进入kerberos管理界面
kadmin.local
# 创建 user1 认证主体
addprinc -pw test1 test1@HAINIU.COM
# 退出kerberos管理界面
exit
su - test1
#user主体进行认证
kinit test1
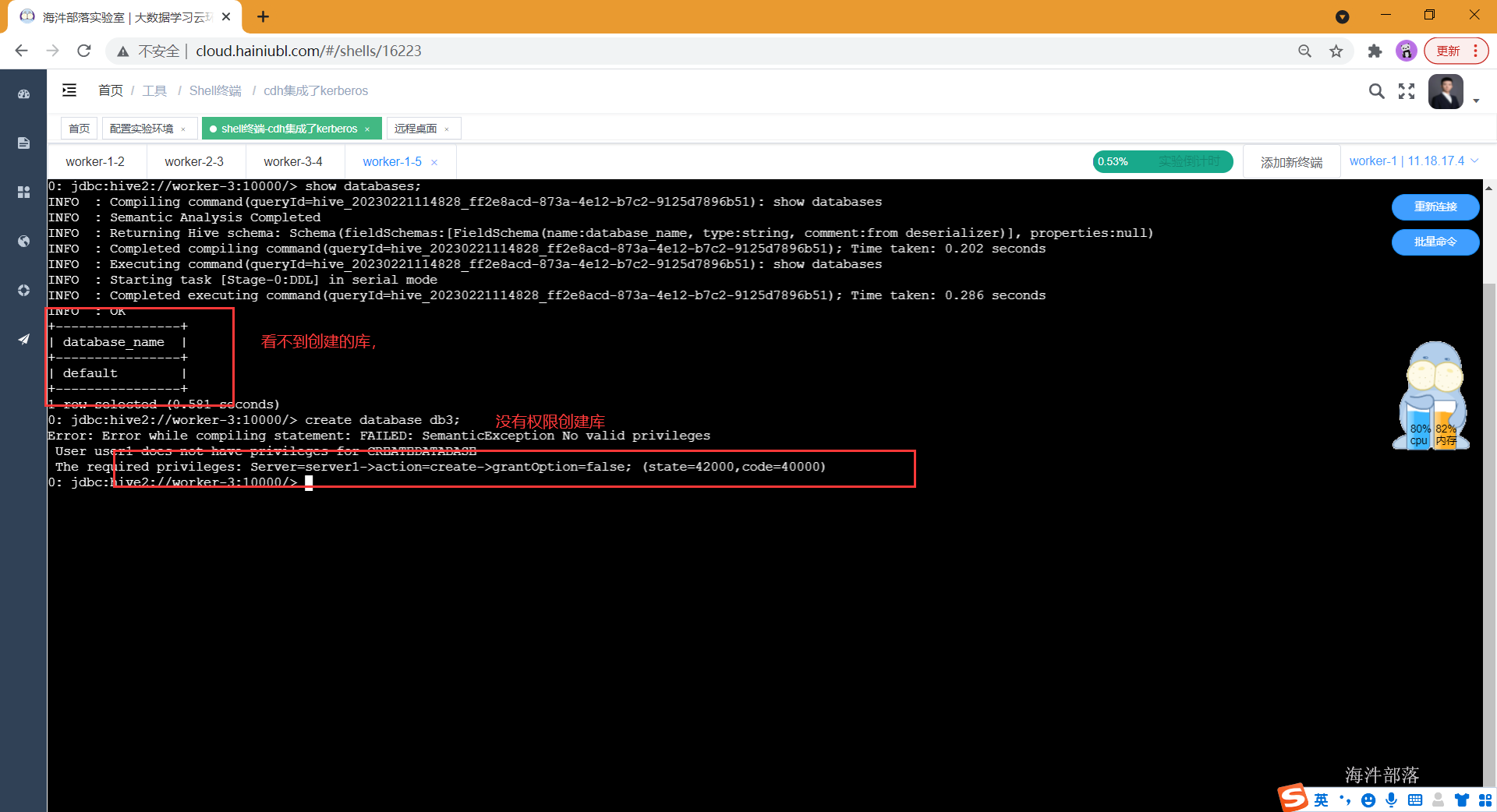
# 通过beeline连接hive
beeline -u "jdbc:hive2://worker-3:10000/;principal=hive/worker-3@HAINIU.COM"
# 发现user1用户没有权限操作hive
show databases;
create database db3;
2)用带有超级角色的hive用户创建test1_role角色
-- 创建角色 user1_role
create role test1_role;
-- 给角色赋予数据库权限
grant all on database db1 to role test1_role;
-- 查看角色权限
show grant role test1_role on database db1;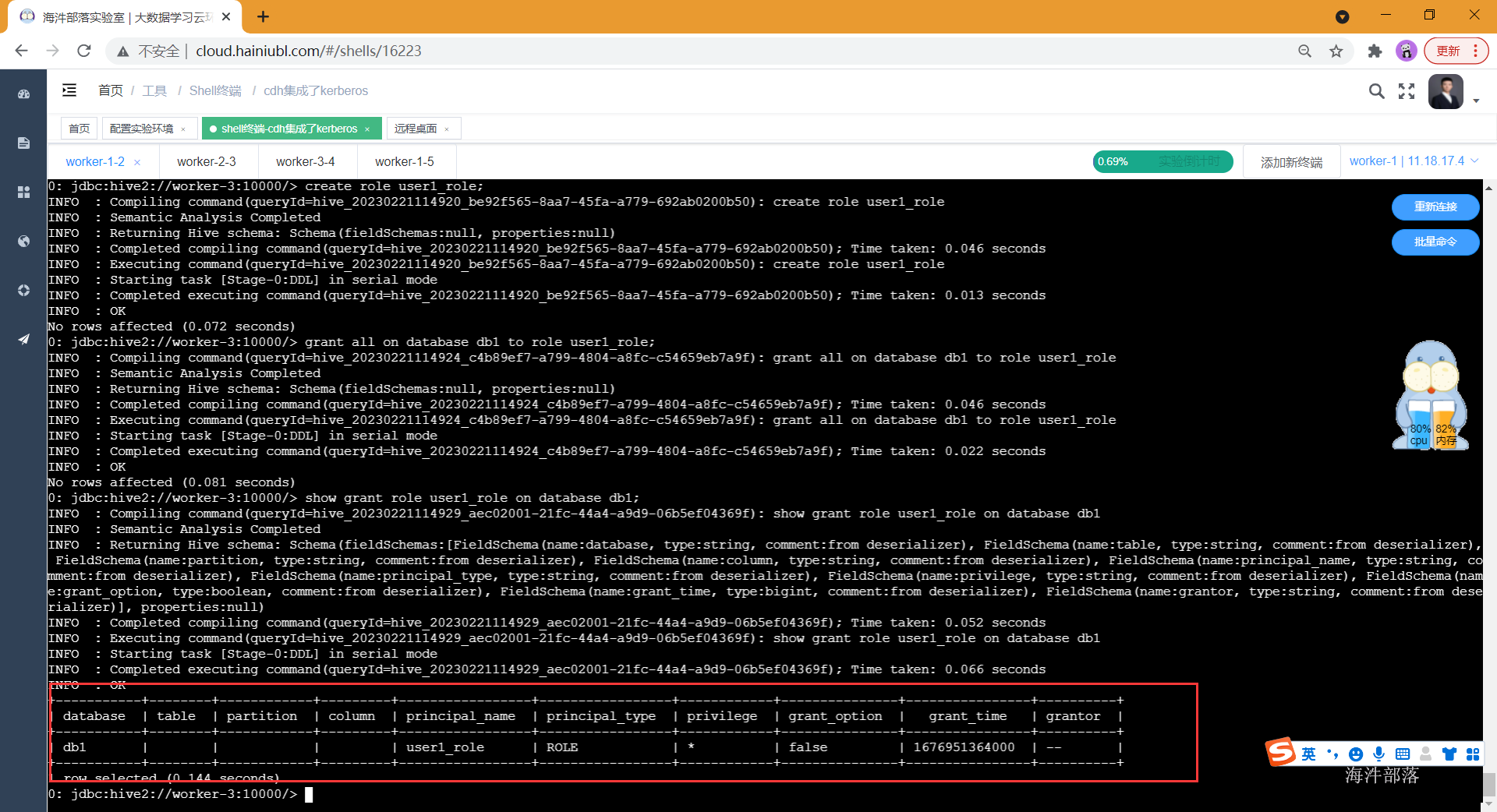
3) 给test1_role角色赋予库的权限
-- 给 user1 加入 user1_role角色,此时:该角色有db1库的所有权限
grant role test1_role to group test1;
-- 查看某个组都授权了哪些角色
show role grant group test1;
-- 用user1操作 user1有了操作db1库的所有权限
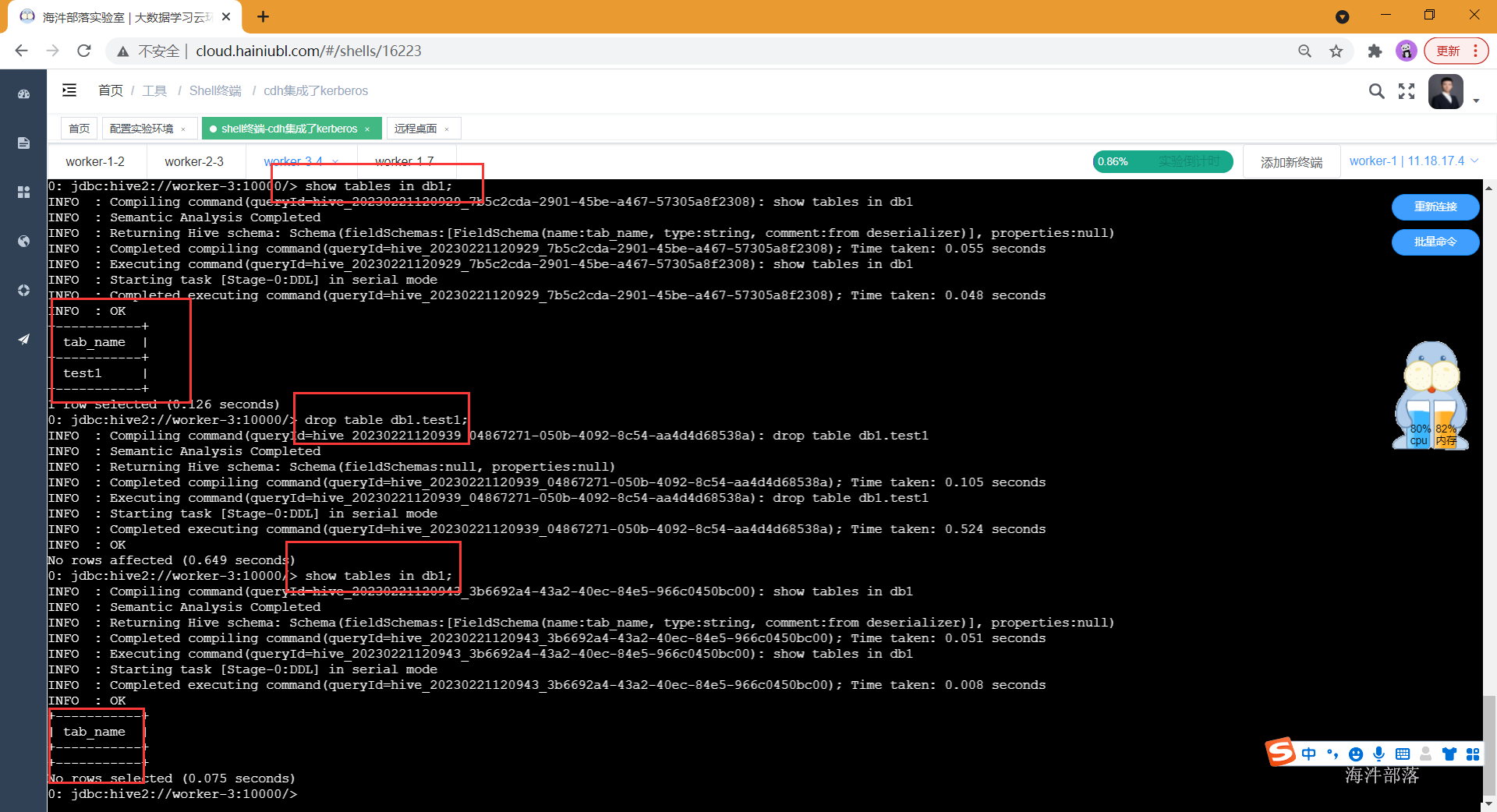
create table db1.test1(id int);
show tables in db1;
drop table db1.test1;
show tables in db1;
4) 给test1_role角色赋予表的权限
-- 给角色赋予表权限
-- 给 user1_role角色赋予db2.test1表的select权限,此时:该角色有db1库的所有权限、db2.test1的select权限
grant select on table db2.test1 to role test1_role;
-- 查看角色权限
show grant role test1_role on table db2.test1;
-- user1 又增加了能查询 db2.test1表的权限
select * from db2.test1;
如果想要插入数据则报错,没有插入权限

grant insert on table db2.test1 to role test1_role;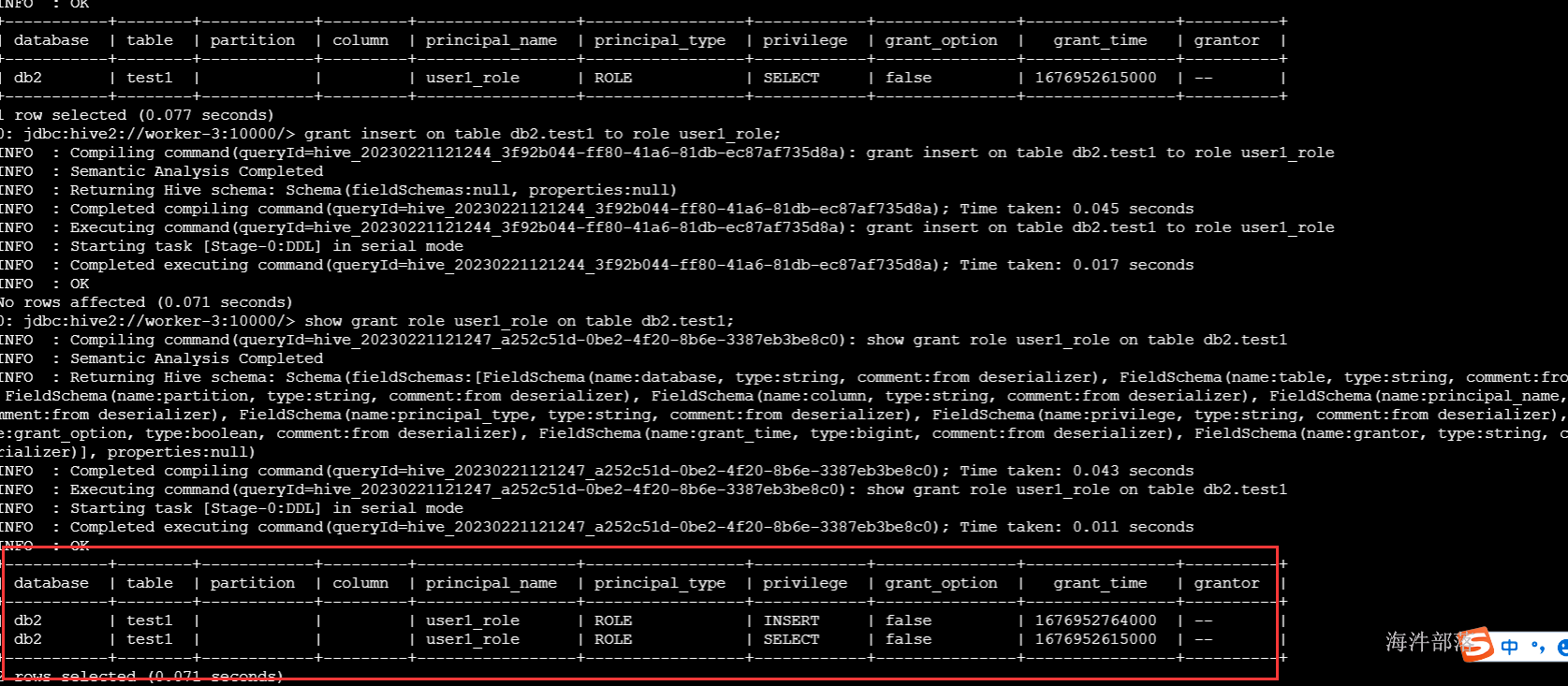
正常执行job任务插入数据
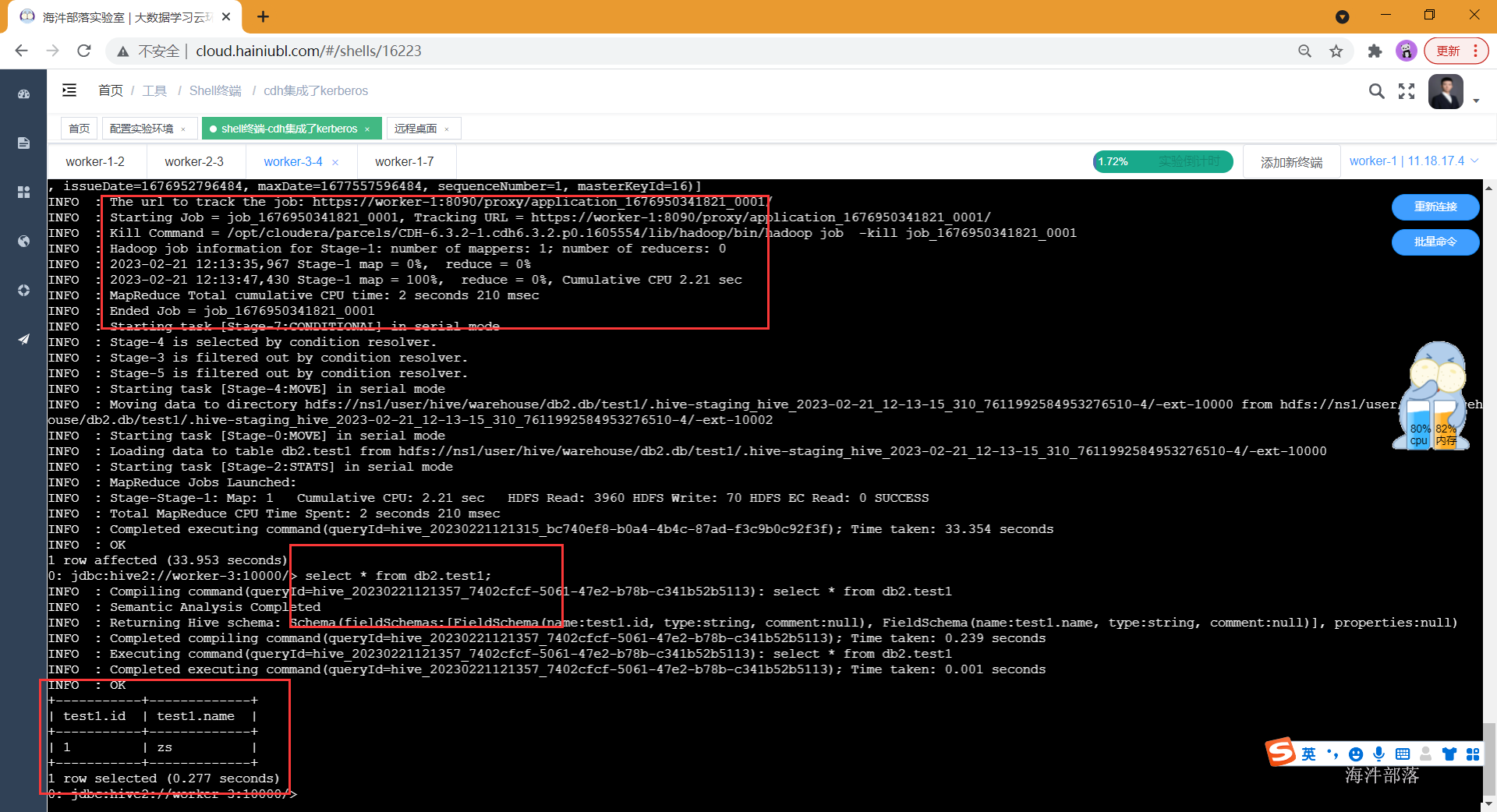
5)给test1_role角色赋予表字段的权限
-- 给角色赋予表字段的权限
-- 给 user1_role角色赋予db2.test2表id字段的查询权限
-- 此时:该角色有db1库的所有权限、db2.test1的select权限、db2.test2的id字段的查询权限
grant select(id) on table db2.test2 to role test1_role;
-- 查看角色权限
show grant role test1_role on table db2.test2;
-- 能查询
select id from db2.test2;
-- 不能查询
select name from db2.test2;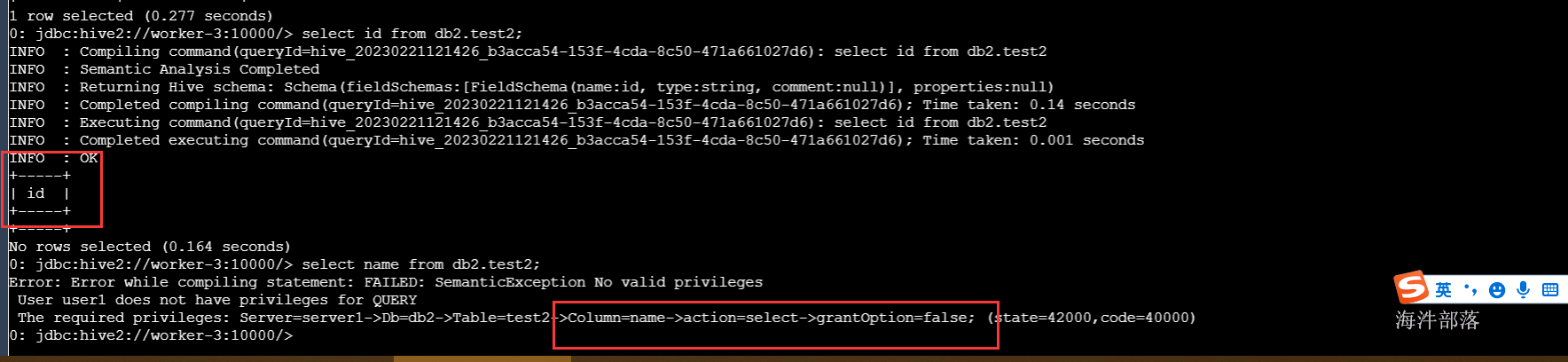
6)收回test1_role角色中db2.test1 的select权限
-- 权限收回
revoke select on table db2.test1 from role test1_role;
-- 查看角色权限
show grant role test1_role on table db2.test1;
-- 查询 db2.test2 的 id字段不报错
select id from db2.test2;
-- 查询 db2.test1 报错
select * from db2.test1;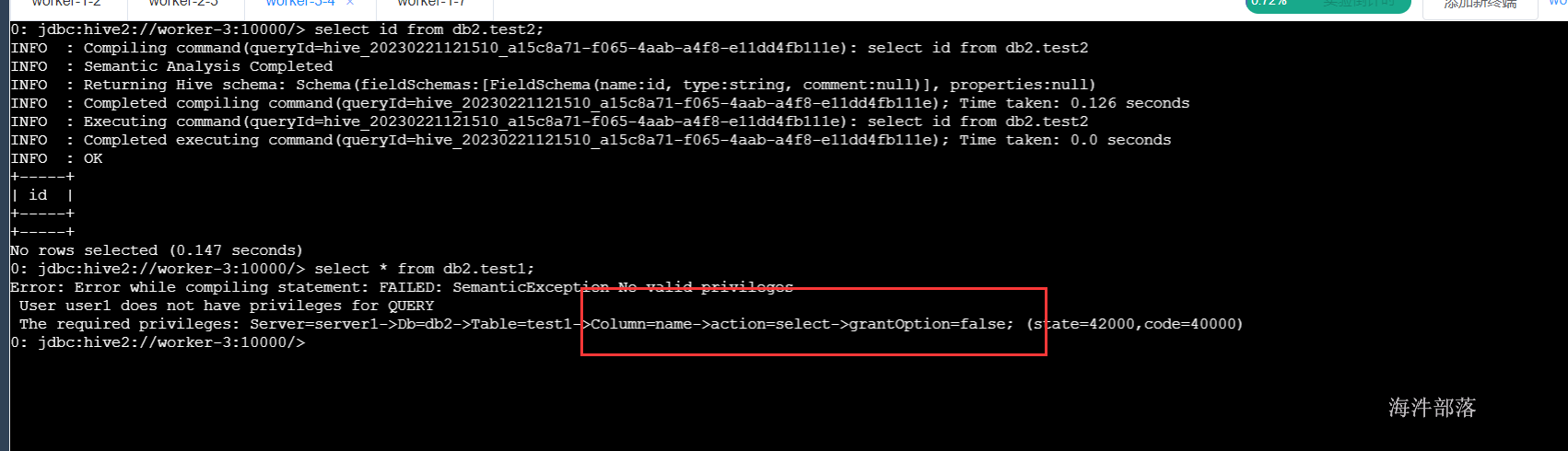
7)收回user1_role角色中db2 的all权限
revoke all on database db1 from role test1_role;
-- 查看角色权限
show grant role test1_role on database db1;
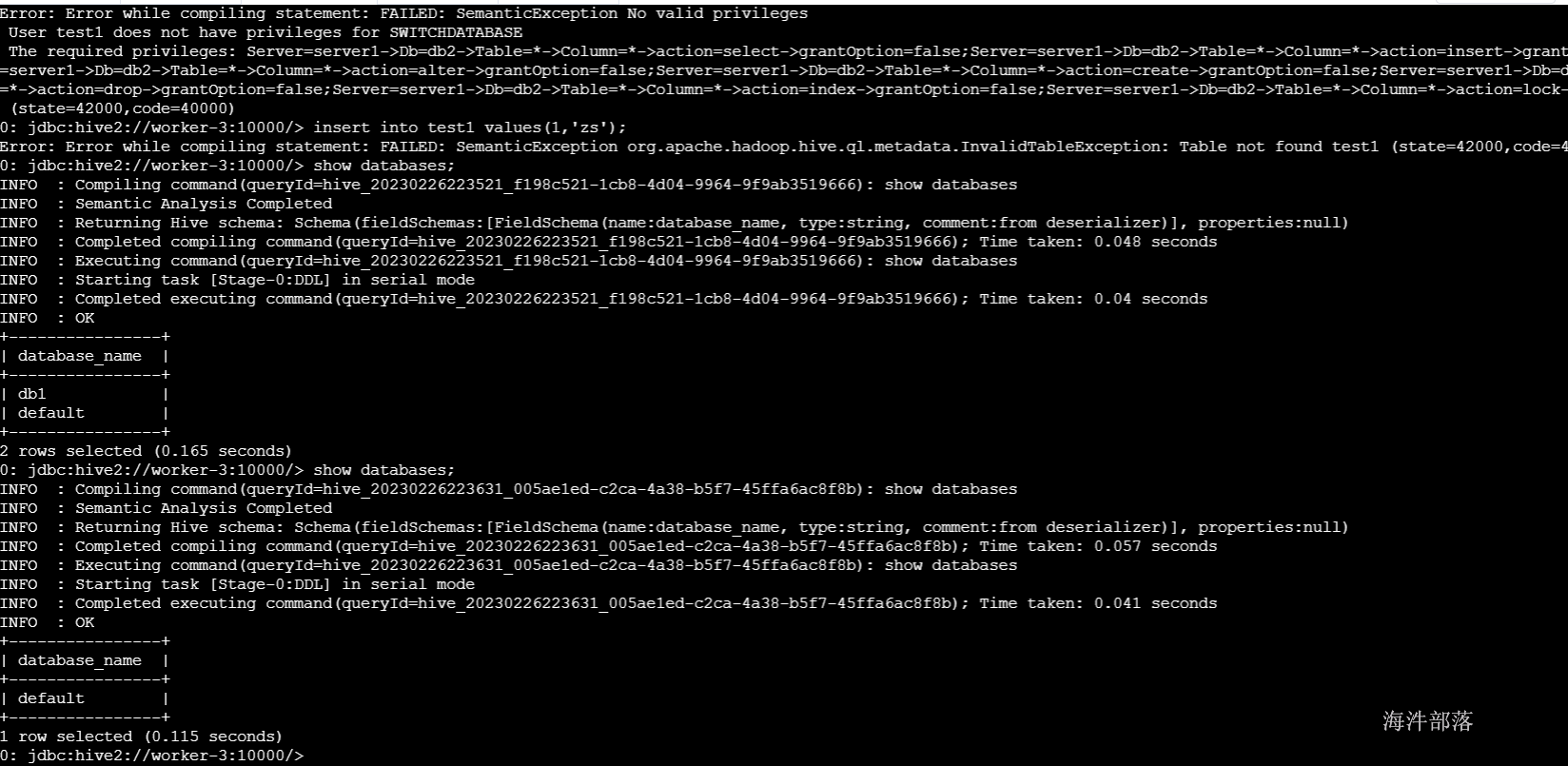
8)删除角色
-- 删除角色
drop role test1_role;
-- 查看role列表
show roles;2.8 sentry权限管理-hbase
2.8.1 Hbase ACLs的访问级别
HBase ACLs的访问分为5个级别:
Read(R) : 可以读取给定范围内数据的权限
Write(W) : 可以在给定范围内写数据
Executor(X) : 可以在指定表执行Endpoints类型的协处理
Create(C) : 可以在给定范围内创建和删除表(包括非该用户创建的表)
Admin(A) : 可以执行集群操作,如平衡数据等
2.8.2 hbase权限操作
2.8.2.1 使用普通用户测试
使用 test1用户登录 hbase,此时test1没有任何权限
# 安全认证
kinit -kt /data/test1.keytab test1
# 登陆hbase
hbase shell
# 查看当前登陆用户
whoami
# 查看命名空间(什么也没有)
list_namespace
# 创建表(不能创建)
create 'testacl','cf'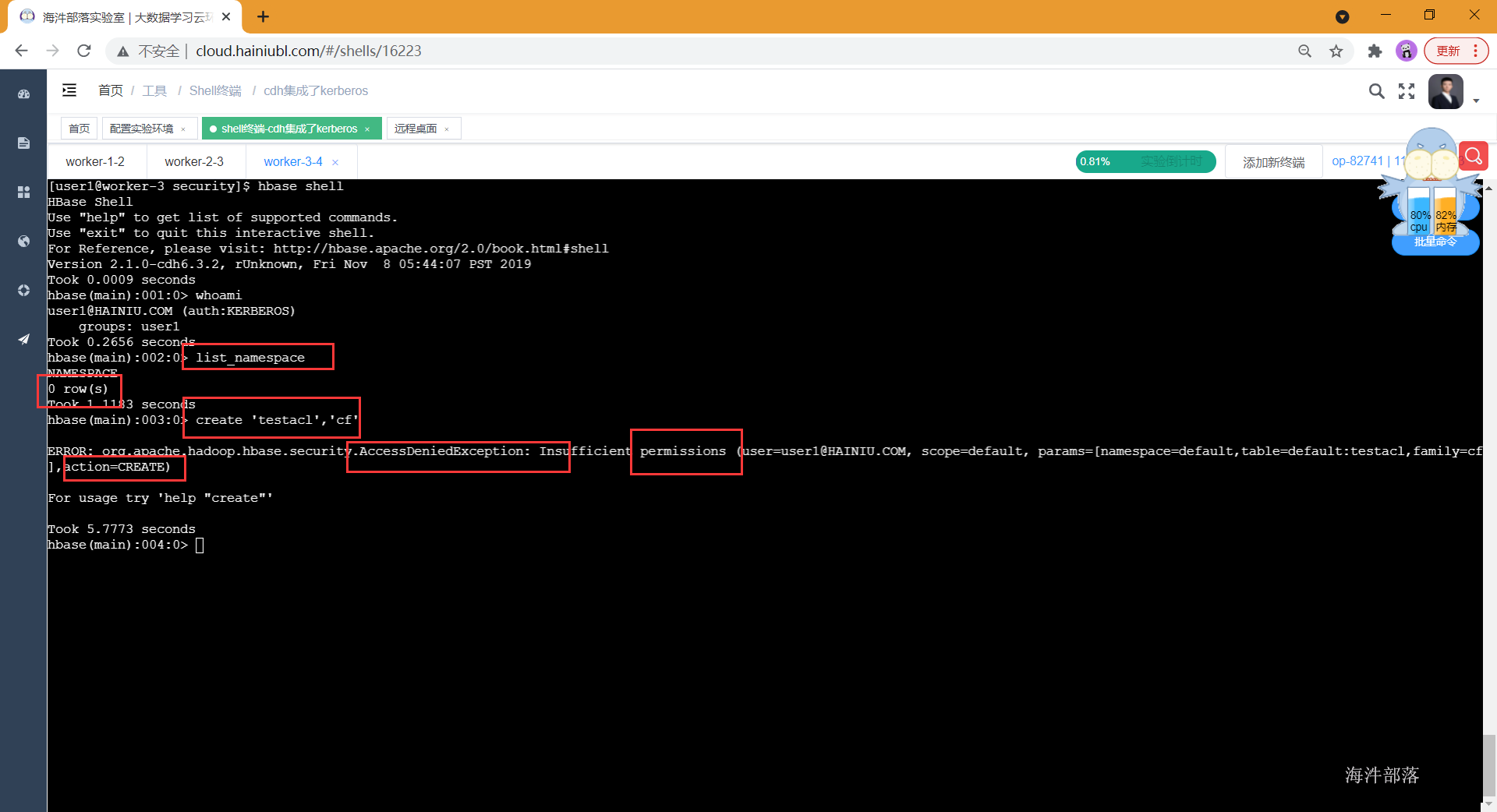
开启sentry后因为没有给test1用户授权所以该用户没有任何权限,list为空,也没有创建表的权限。
2.8.2.3 使用超级管理员测试
在cdh中hbase的超级管理员配置的为hbase用户,所以我们使用hbase用户做安全认证,然后进入hbase shell进行测试。
# 使用hbase用户进行认证,hbase的keytab生成需要kerberos管理员用户在kadmin.local中生成。
kinit -kt /data/hbase.keytab hbase
hbase shell
# 查看当前操作用户
whoami
# 查看命名空间列表
list_namespace
# 建表
create 'testacl','cf'
# 删表
disable 'testacl'
drop 'testacl'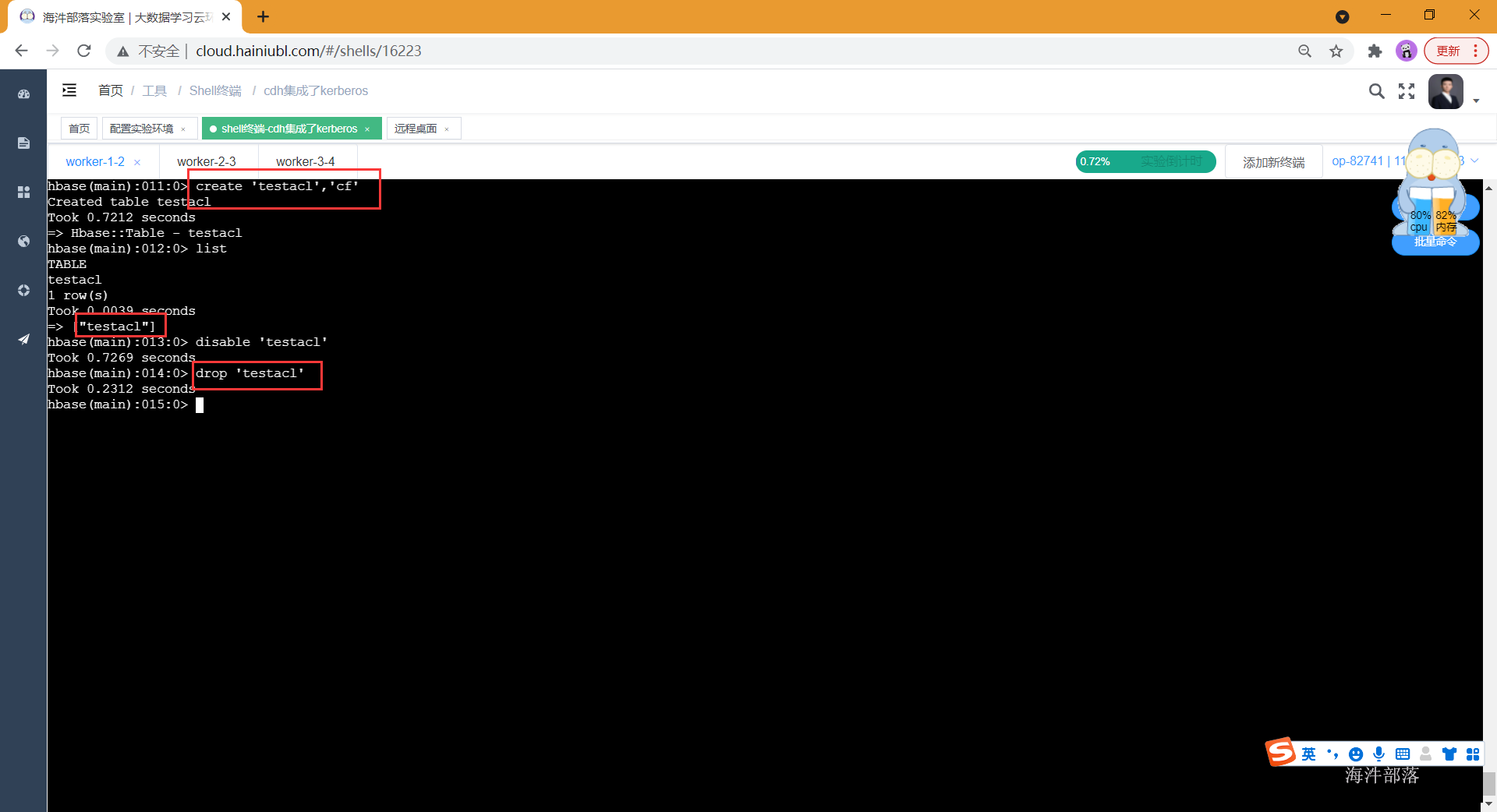
可以发现超级用户是可以操作的,但是这不符合我们多租户设计的愿景
2.8.2.4 使用超级用户给普通用户授管理员权限
使用超级用户给普通用户授权,语法如下:
# ---【注意:这是语法,别执行】----------------
# CA权限 = RWXCA
# 给【user1用户组】赋予CA权限
grant '@test2', 'CA'
# 给【user1用户】赋予CA权限
grant 'test2', 'CA'
# user_permission是查看当前所有用户及组权限
user_permission '.*'
# 查看当前表的所有用户及组权限
user_permission '命名空间:表名'给user1用户组赋予CA全局权限
# 给user1用户组赋予CA全局权限
grant 'test2', 'CA'
# 通过user_permission ‘.*’查看当前HBase所有的授权;
user_permission '.*'
赋权限后查看:

当为用户或用户组拥有CA权限时,用户和用户组创建表时会默认的为当前操作用户添加该表的RWXCA权限

注意:
拥有Admin(A)权限的用户,可以为其它用户进行任何级别授权,在使用HBase授权时需要慎用;
在CDH中HBase支持Global、NameSpace、Table、ColumnFamily范围授权,无法支持Row级别授权;
2.8.2.5 命名空间acl授权
给test3用户组赋予xinniu命名空间 CA权限
1)创建 test3用户并创建test3认证主体,连接hbase
useradd test3
passwd test3
# 进入kerberos管理界面
kadmin.local
# 创建 user1 认证主体
addprinc -pw test3 test3@HAINIU.COM
# 退出kerberos管理界面
exit
su - test3
hbase shell
2)给test3用户组赋予xinniu命名空间 CA权限
# 用超级用户创建xinniu命名空间
create_namespace 'xinniu'
# 给test2用户赋予xinniu命名空间 CA权限
grant 'test3','RWXCA','@xinniu'
3)用test3操作xinniu命名空间
# 在xinniu命名空间下建表、查询都可以
create 'xinniu:testacl', 'cf'
scan 'xinniu:testacl'
# 但在default命名空间操作,就报错了
create 'testacl1', 'cf'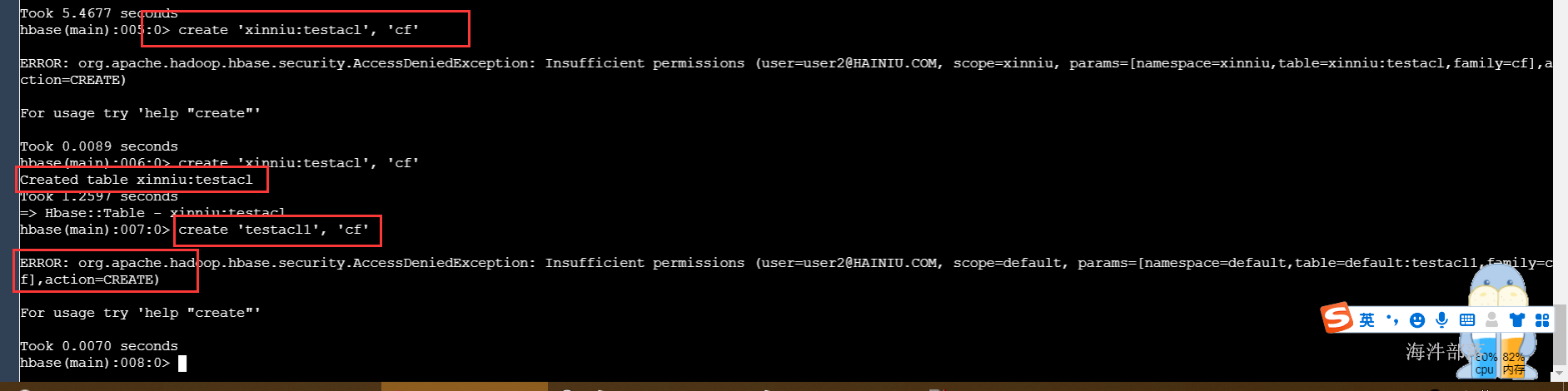
2.8.2.6 表acl授权
1)使用超级管理员用户,创建一个新的命名空间,并且创建两张表,同时插入数据
# 创建命名空间 xinniu1
create_namespace 'xinniu1'
# 创建表 xinniu1:tableacl
create 'xinniu1:tableacl','cf'
put 'xinniu1:tableacl','x0002','cf:datadate','20210518'
# 创建表 xinniu1:tableacl1
create 'xinniu1:tableacl1','cf'
put 'xinniu1:tableacl1','x0002','cf:datadate','20210518'2)给 test3用户 赋予 xinniu1:tableacl 表的所有权限
grant 'test3','RWXCA','xinniu1:tableacl'3)使用test3用户进行测试
# 查看 xinniu1命名空间下的表,发现只能看到 tableacl表
list_namespace_tables 'xinniu1'
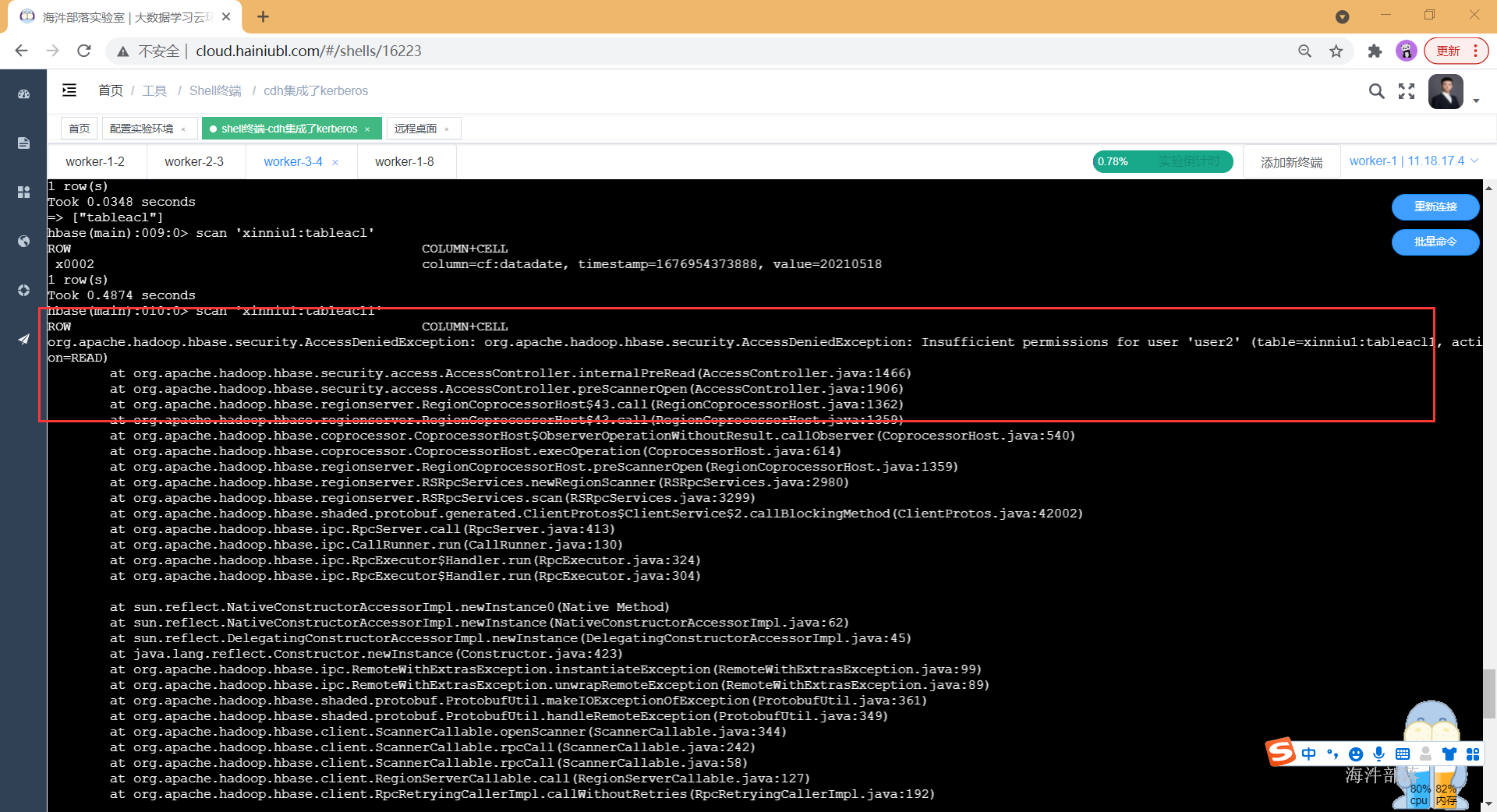
# 也只能查询tableacl表
scan 'xinniu1:tableacl'
# 由于查询tableacl1表没有权限,所以权限错误
scan 'xinniu1:tableacl1'由于查询tableacl1表没有权限,所以权限错误
2.8.2.7 列族acl授权
1)使用管理员创建 xinniu1:tableacl2表 并添加数据
# 创建多列族表
create 'xinniu1:tableacl2', 'cf1', 'cf2'
# 添加数据
put 'xinniu1:tableacl2', 'X0001', 'cf1:name', 'n1'
put 'xinniu1:tableacl2', 'X0001', 'cf2:datadate', '20210518'
put 'xinniu1:tableacl2', 'X0002', 'cf1:name', 'n2'
put 'xinniu1:tableacl2', 'X0002', 'cf2:datadate', '20210518'
2)使用管理员给 test3用户 赋予 xinniu:tableacl1 表 cf1列族赋予 RW权限
grant 'test3','RW','xinniu1:tableacl2','cf1'3)使用test3用户进行测试
# 查看xinniu1命名空间的表列表里有 tableacl2
list_namespace_tables 'xinniu1'
# 但查询的时候,只能查询出cf1列族
scan 'xinniu1:tableacl2'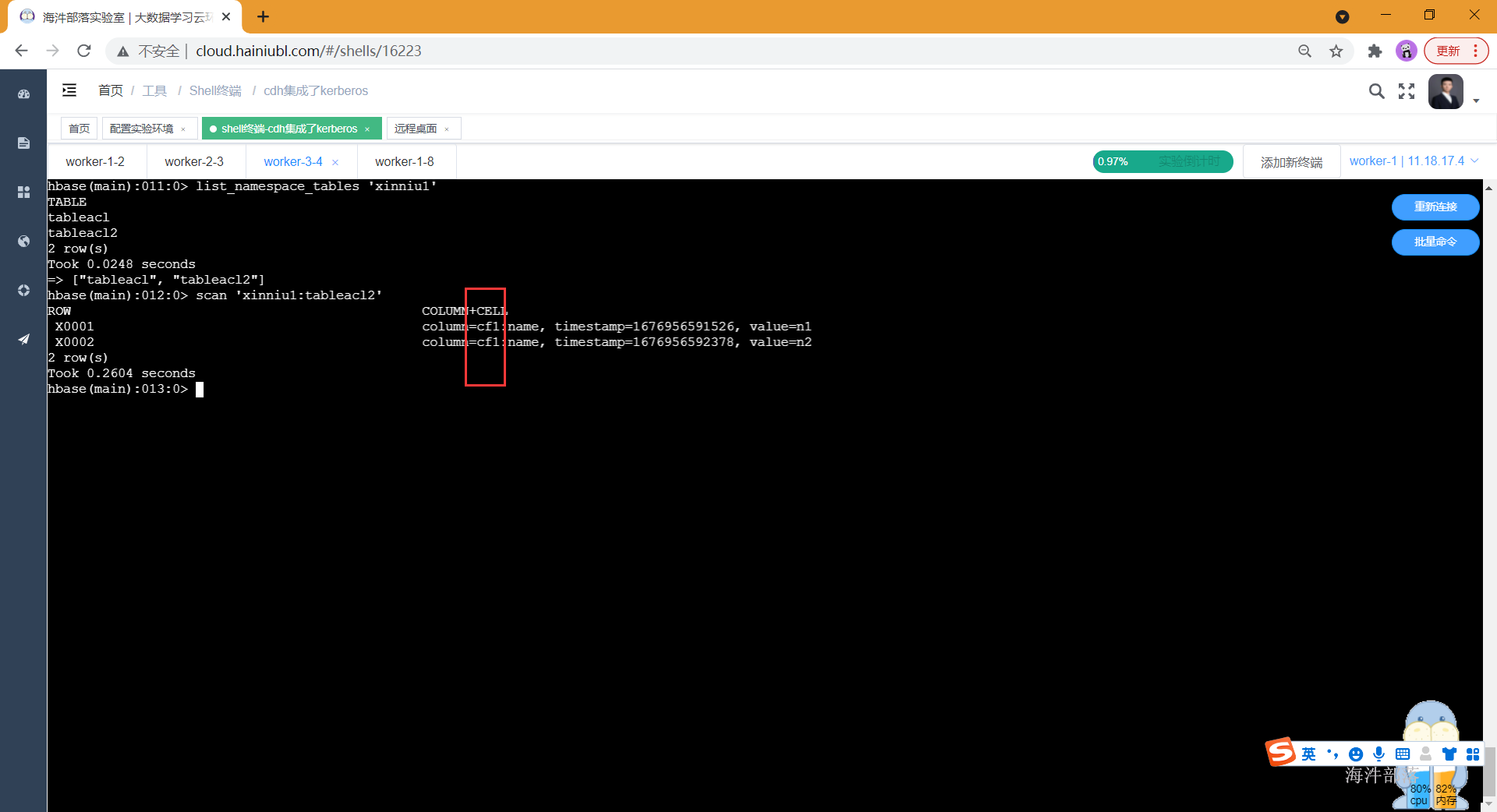
2.8.2.8 权限收回
1)收回 表的权限
# ***管理员操作***
# 收回 test3 用户的 赋予 xinniu1:tableacl2 表的所有权限
revoke 'test3', 'xinniu1:tableacl2', 'cf1'
# ***test3***
# 查看xinniu1命名空间的表列表里没有 tableacl2
list_namespace_tables 'xinniu1'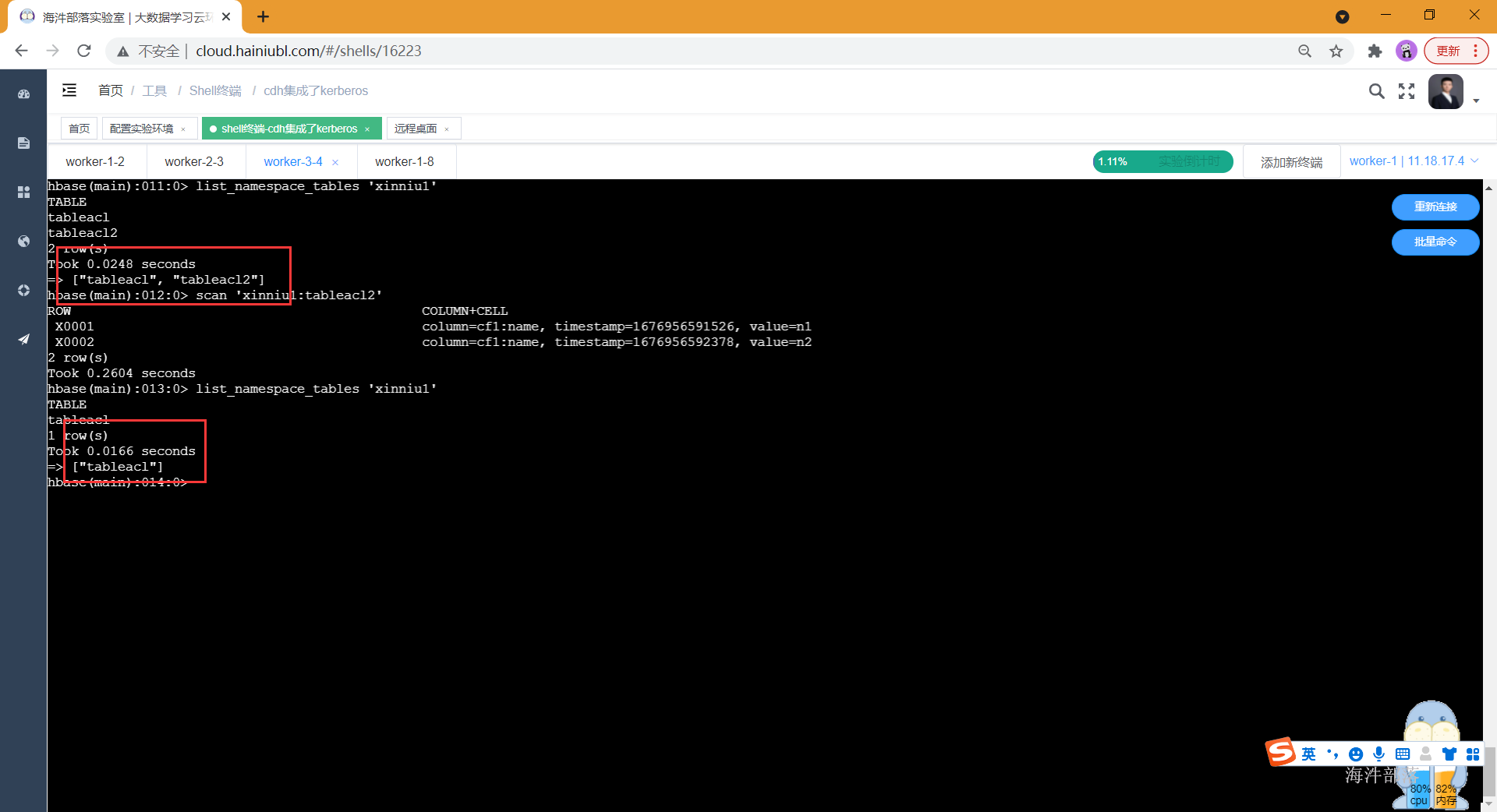
2)收回命名空间权限
要先收下收回命名空间下表的权限
# ***管理员操作***
# 收回 test3 用户的 赋予 xinniu:testacl 表的所有权限
revoke 'test3', 'xinniu:testacl'
user_permission '.*'



