hadoop01_大数据-hadoop-环境准备
1 大数据概述
1.1 什么是大数据(bigdata)?
大数据本身是一个抽象的概念。
从一般意义上讲,大数据是指无法在有限时间内用常规软件工具对其进行获取、存储、管理和处理的数据集合。
大数据具备 Volume、Velocity、Variety 和 Value 四个特征,简称“4V”,即数据体量巨大、数据速度快、数据类型繁多和数据价值密度低,商业价值高特征。
如下图所示。下面分别对每个特征作简要描述。
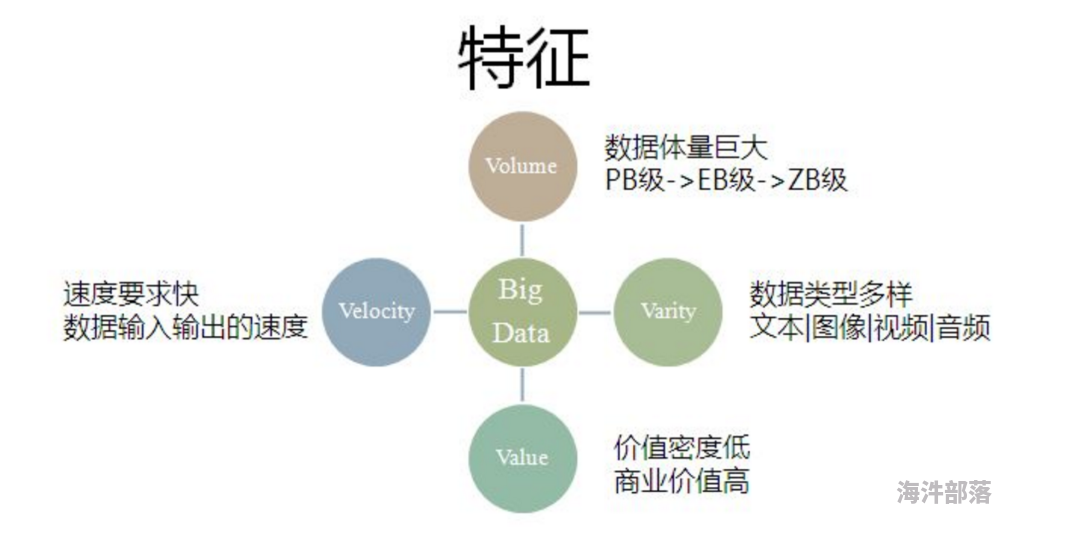
1.2 大数据产生
1)运营式系统阶段
将业务数据存入数据库,用数据库来管理业务数据。如:交易记录、入库记录等。
这个阶段的最主要特点是,数据的产生往往伴随着一定的运营活动;而且数据的产生方式是被动的。
2)用户原创内容阶段
随着互联网和移动终端的兴起,用户会通过社交App来主动发朋友圈、发微博、通过电商App购买商品等,而且还特别便捷,这会产生大量的数据。数据产生方式是主动的。
3)感知式系统阶段
随着技术的发展,移动端利用传感器来记录用户的日常行为、企业利用传感器来获取运行数据,进而监控机器的运行情况。这些设备会源源不断地产生新数据,这种数据的产生方式是自动的。
简单来说,数据产生经历了被动、主动和自动三个阶段。这些被动、主动和自动的数据共同构成了大数据的数据来源,但其中自动式的数据才是大数据产生的最根本原因。
1.3 大数据的作用?
现在正是大数据的时代,大数据在许多各行各业也发挥着越来越多的作用。
比如:
1)电商、零售行业,通过对用户购买行为的分析,细分市场、精准营销。
2)企业通过大数据技术,来分析生产的各个环节,提高生产效率。
3)通过数据采集技术,抓取互联网上的信息,并提取,比如:新闻采集。
随着互联网+的兴起,产生的数据会越来越多,数据的作用会越来大。
以后是得数据者得天下,各大互联网企业也在争抢数据来源。而且国家也开始重视大数据,防止数据外泄威胁国家安全,国家出台很多政策。
1.4 大数据的数据处理流程
第一阶段 : 数据抽取与集成
将不同数据源、不同类型的数据统一格式,存储到分布式文件系统中。
没有大数据技术前:存储到MySQL、oracle这种关系型数据库(单机瓶颈)。
有大数据技术后:存储到如hdfs分布式文件系统中(可多机存储和分析)。
第二阶段 : 数据分析
数据分析是整个大数据处理流程的核心。
数据分析包括 普通统计分析、算法分析(数据挖掘),通过分析数据产生价值。
数据分析通常有两种:
离线处理分析:
对一段时间内海量的离线数据进行统一的处理,对应的处理框架有 MapReduce、Spark。
数据有范围,对时间性要求不高。
实时处理分析:
对运动中的数据进行处理,即在接收数据的同时就对其进行处理,对应的处理框架有Storm、Spark Streaming、Flink。
数据没有范围(随着时间的流逝数据在产生),对时间性要求高。
随着处理框架的完善,也可以用SQL来对数据进行统计分析,如hiveSQL, sparkSQL。
第三阶段 : 数据解释
数据分析是大数据处理的核心,但是用户往往更关心对结果的解释。
通过数据可视化,将分析的结果形象的展现在数据大屏上,使用户更易于理解和接受。
1.5 大数据处理技术
对大数据技术的基本概念进行简单介绍,包括分布式计算、服务器集群和 Google 的 3 个大数据技术。
1.5.1 分布式计算
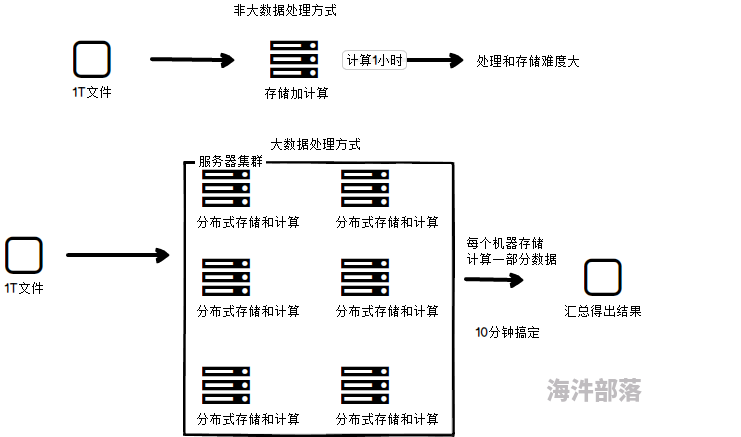
随着数据越来越大,单机存储和计算能力遇到瓶颈。
需要多机存储和计算(分布式计算)。
分布式计算:
是把一个大计算任务拆分成多个小计算任务分布到若干台机器上去计算,然后再进行结果汇总。 目的在于分析计算海量的数据。
尽管分散系统内的单个计算机的计算能力不强,但是由于每个计算机只计算一部分数据,而且是多台计算机同时计算,所以就分散系统而言,处理数据的速度会远高于单个计算机。
1.5.2 服务器集群
服务器集群是一种提升服务器整体计算能力的解决方案。它是由互相连接在一起的服务器群组成的一个并行式或分布式系统。
通俗解释:
服务器集群 由多台 机器 组成在一起
提供各种服务,比如存储的服务(hdfs)、分布式计算的服务(mapreduce)等
由于服务器集群中的服务器运行同一个计算任务,因此,从外部看,这群服务器表现为一台虚拟的服务器,对外提供统一的服务。
尽管单台服务器的运算能力有限,但是将成百上千的服务器组成服务器集群后,整个系统就具备了强大的运算能力,可以支持大数据分析的运算负荷。
Google、Amazon, 阿里巴巴的计算中心里的服务器集群都达到了 5000 台服务器的规模。
1.5.3 大数据的技术基础
2003—2004 年间,Google 发表了 MapReduce、GFS(Google File System)和 BigTable 3 篇技术论文,提出了一套全新的分布式计算理论。
MapReduce --> Mapredue****分布式计算框架
GFS --> HDFS分布式文件系统
BigTable --> Hbase列式存储数据库
Google 的分布式计算模型相比于传统的分布式计算模型有 3 大优势:
- 简化了传统的分布式计算理论,降低了技术实现的难度,可以进行实际的应用。
- 可以应用在廉价的计算设备上,只需增加计算设备的数量就可以提升整体的计算能力,应用成本十分低廉。
- 被应用在 Google 的计算中心,取得了很好的效果,有了实际应用的价值。
后来,各家互联网公司开始利用 Google 的分布式计算模型搭建自己的分布式计算系统,Google 的这 3 篇论文也就成为大数据时代的技术核心。 当时 Google 采用分布式计算理论也是为了利用廉价的资源,使其发挥出更大的效用。
Google 的成功使人们开始效仿,从而产生了开源系统 Hadoop。
2 hadoop概述
2.1 Hadoop简介
Hadoop项目是以可靠、可扩展和分布式计算为目的而发展而来的开源软件。
Hadoop 是Apache的顶级项目。
Hadoop设计的初衷:可以作用在低成本的硬件上。
Hadoop 采用 MapReduce 分布式计算框架,根据 GFS 原理开发了 HDFS(分布式文件系统),并根据 BigTable 原理开发了 HBase 数据存储系统。
Hadoop 是一个基础框架,允许用简单的编程模型在计算机集群上对大型数据集进行分布式处理。
2.2 hadoop的历史起源
创始人: Doug Cutting 和 Mike Cafarella


hadoop logo hadoop之父 Doug Cutting
Doug Cutting 看到他儿子在牙牙学语时,抱着黄色小象,亲昵的叫 hadoop,他灵光一闪,就把这技术命名为 Hadoop,而且还用了黄色小象作为标示 Logo,不过,事实上的小象瘦瘦长长,不像 Logo 上呈现的那么圆胖。“我儿子现在 17 岁了,所以就把小象给我了,有活动时就带着小象出席,没活动时,小象就丢在家里放袜子的抽屉里。” 历史起源:
2002开始,两位创始人开发开源搜索引擎解决方案: Nutch
2004年受Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发,NDFS( Nutch Distributed File System )引入Nutch
2006年 在Yahoo!工作的Doug Cutting将这套大数据处理软件命名为Hadoop

2.3 hadoop核心组件和框架演变
用于解决两个核心问题:存储和计算
核心组件
1)Hadoop Common:****一组分布式文件系统和通用I/O的组件与接口(序列化、Java RPC和持久化数据结构)。
2)Hadoop Distributed FileSystem(Hadoop分布式文件系统HDFS)-->解决存储问题
分布式存储, 有备份, 可扩展
3)Hadoop MapReduce(分布式计算框架)--> 解决计算问题****
分布式计算:多台机器同时计算一部分,得到部分结果,再将部分结果汇总,得到总体的结果
可扩展,程序员只需专注业务开发
4)Hadoop YARN(分布式资源管理器)--> 解决资源管理问题****
MapReduce任务计算的时候,运行在yarn上,yarn提供资源管理。
yarn主要管理的是 CPU 和 内存。
2.4 Hadoop 生态圈
Hadoop 生态圈包括以下主要组件。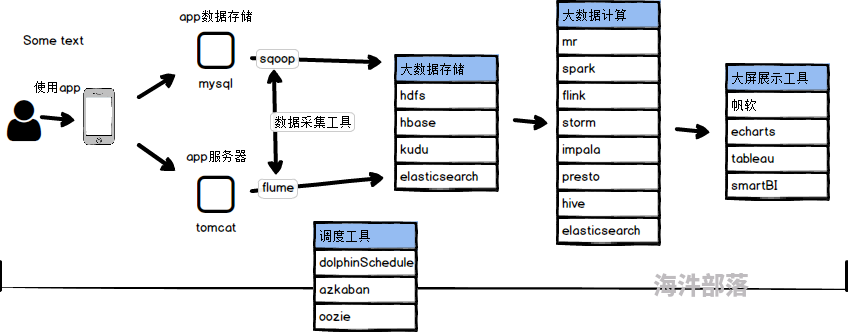
1)HDFS(Hadoop分布式文件系统)
HDFS是一种数据分布式保存机制,数据被保存在计算机集群上。数据写入一次,读取多次。HDFS 为HBase等工具提供了基础。
2)MapReduce(分布式计算框架)
MapReduce是一种分布式计算模型,用以进行大数据量的计算,是一种离线计算框架。
这个 MapReduce 的计算过程简而言之,就是将大数据集分解为成若干个小数据集,每个(或若干个)数据集分别由集群中的一个结点(一般就是一台主机)进行处理并生成中间结果,然后将每个结点的中间结果进行合并, 形成最终结果。
3)HBASE(分布式列存数据库)
HBase是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。HBase使用Zookeeper进行管理,确保所有组件都正常运行。
4)Sqoop(数据ETL/同步工具)
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之间传输数据。
5)flume(分布式日志收集系统)
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。
6)Zookeeper(分布式协作服务)
Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
作用:解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
7)Hive(数据仓库)
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析。
HQL用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。
8)Spark(内存计算模型)
Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。
9)azkaban(工作流调度器)
azkabani可以把多个Map/Reduce作业组合到一个逻辑工作单元中,从而完成更大型的任务。
10)Hadoop YARN(分布式资源管理器)****
YARN是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的。
其核心思想:
将MR1中JobTracker的资源管理和作业调用两个功能分开,分别由ResourceManager和ApplicationMaster进程来实现。
1)ResourceManager:负责整个集群的资源管理和调度
2)ApplicationMaster:负责应用程序相关事务,比如任务调度、任务监控和容错等
2.5 Hadoop 发行版本
Apache(先学这个)
- 企业实际使用并不多。最原始(基础)版本。这是学习hadoop的基础。我们就是用的最原始的这个版本
cloudera --> CDH版(后学这个)
- 对hadoop的升级,打包,开发了很多框架。flume、hue、impala都是这个公司开发
- 2008 年成立的 Cloudera 是最早将 Hadoop 商用的公司,为合作伙伴提 供 Hadoop 的商用解决方案,主要是包括支持,咨询服务,培训。
- 2009年Hadoop的创始人 Doug Cutting也加盟 Cloudera公司。Cloudera 产品主要 为 CDH,Cloudera Manager,Cloudera Support
- CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全 性,稳定性上有所增强。
- Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署 好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即 是对Hadoop的技术支持。
- Cloudera 的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大 数据的Impala项目。
Hortonworks --> HDP+Ambari
- 2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建
- 公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工 程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop 80%的代码。
- 雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
- Hortonworks 的主打产品是Hortonworks Data Platform (HDP),也同样是100%开 源的产品,HDP除常见的项目外还包含了Ambari,一款开源的安装和管理系统
- HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook 开源的Hive中
。Hortonworks的Stinger开创性地极大地优化了Hive项目。Hortonworks为入门提 供了一个非常好的,易于使用的沙盒。* Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能 够在包括Windows Server和Windows Azure在内的Microsoft Windows平台上本地 运行。 - 定价以集群为基础,每10个节点每年为12500美元。
3 服务器集群搭建
3.1 集群方式
本地模式:windows伪集群,本地开发。(自己电脑)
集群部署:完全分布式。(海牛实验室)
公司环境 : 完全分布式,需要 用户名和密码登录
3.2 部署环境
伪集群 --> windows环境下
集群 --> 海牛实验室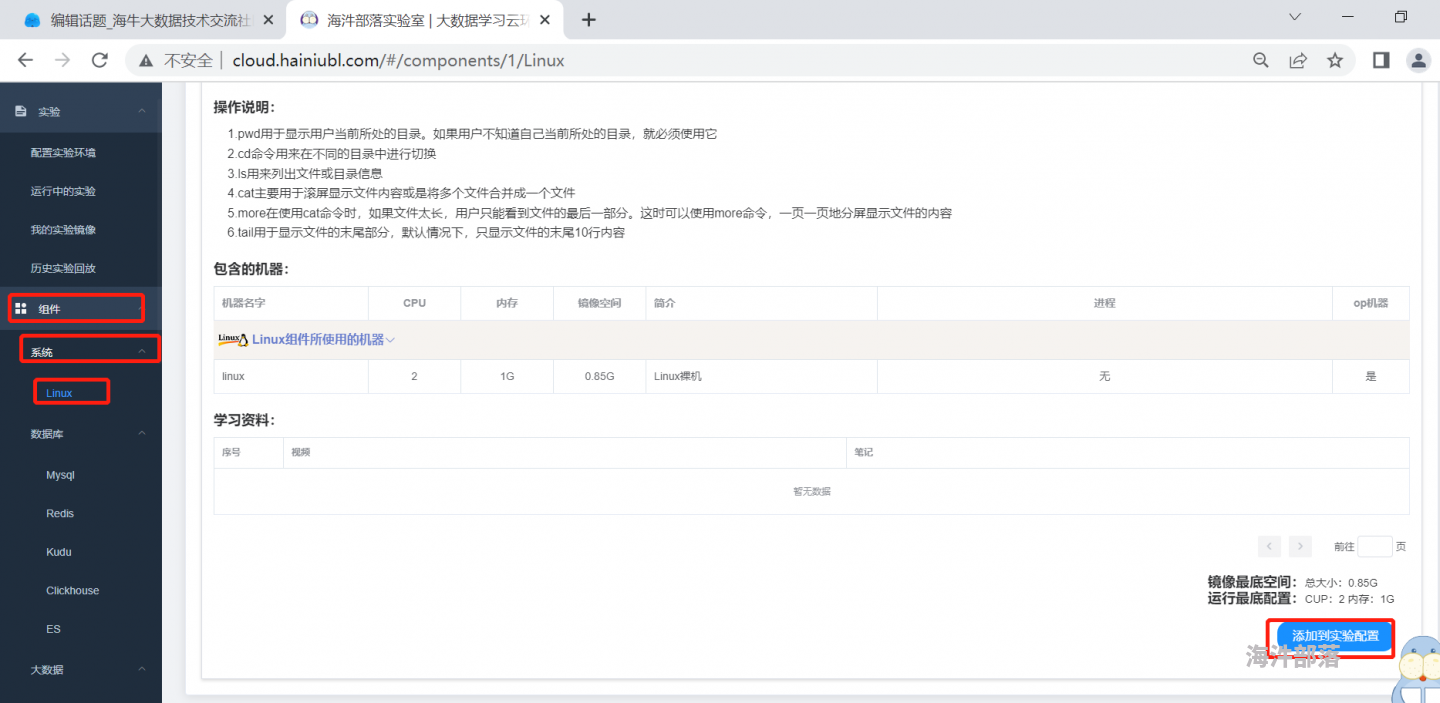
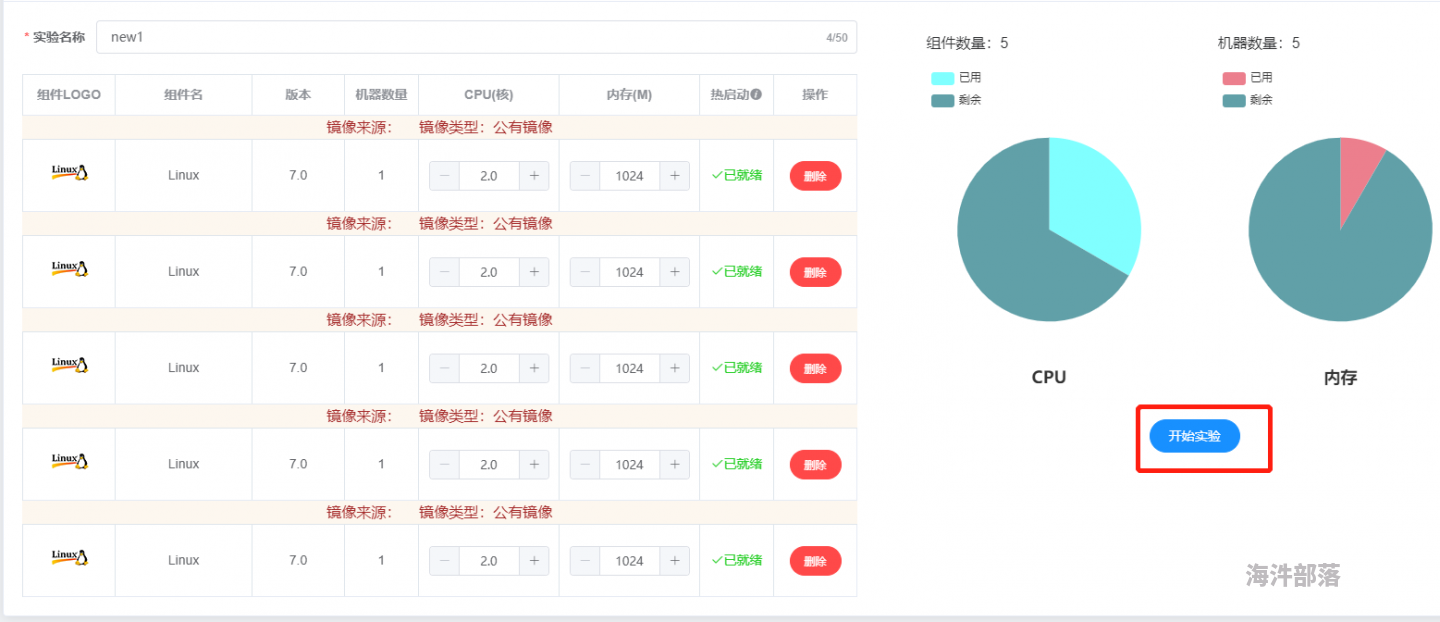
3.3 软件准备
海牛实验室集群
下载 64位JDK(7/8) RPM安装包
下载 hadoop3.x 安装包 我们使用的hadoop版本是 3.1.4
3.4 部署计划
电脑的组成
-
集群的组成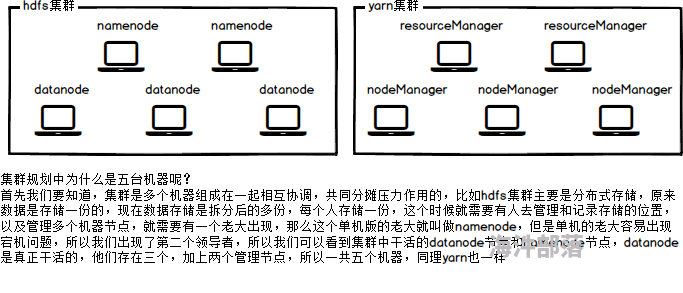
集群部署规划,5台服务器:
一个主节点:nn1
一个从节点:nn2
三个工作节点:s1、s2、s3
注意:
计算机名 --> 不要修改了,后面安装的所有组件都涉及主机名称。
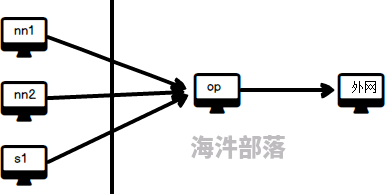
nn1 机器作为操作机。
在企业里还应有操作机(跳板机)防止服务器中毒,用跳板机联网做炮灰
我们机房里的服务器就是这么设置的
内部集群 ---->操作机op (vpn) --------> 外网(电脑搞个vpn)
3.5 初始化环境
3.5.1 配置阿里云 yum 源
1)下载 repo 文件
文件下载地址: http://mirrors.aliyun.com/repo/Centos-7.repo
2)用 rz 将下载的 Centos-7.repo 文件上传到Linux系统的某个目录下
3)备份并替换系统的repo文件
cp Centos-7.repo /etc/yum.repos.d/
cd /etc/yum.repos.d/
mv CentOS-Base.repo CentOS-Base.repo.bak
mv Centos-7.repo CentOS-Base.repo
远程发送这个已经修改完毕的配置到各个机器上面
scp 本地的目标文件 用户@ip:目标文件中4)执行yum源更新命令
yum clean all
#服务器的包信息下载到本地电脑缓存起来
yum makecache
yum update -y配置完毕。
3.5.2 安装常用软件
yum install -y openssh-server vim gcc gcc-c++ glibc-headers bzip2-devel lzo-devel curl wget openssh-clients zlib-devel autoconf automake cmake libtool openssl-devel fuse-devel snappy-devel telnet unzip zip net-tools.x86_64 firewalld systemd ntp unrar bzip2 3.5.3 安装JDK
1 JDK 下载地址
进入 /public/software目录中查询软件2)安装JDK
rpm -ivh jdk-8u144-linux-x64.rpm
/usr/java-ivh:安装时显示安装进度
3 配置JDK 环境变量
1)修改系统环境变量文件 /etc/profile,****在文件尾部追加以下内容
使用批量命令进行执行
echo 'export JAVA_HOME=/usr/java/jdk1.8.0_144' >> /etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile
source /etc/profile
java -versionexport
设置或显示环境变量。
一个变量创建时,它不会自动地为在它之后创建的shell进程所知。而命令export 可以向后面的shell传递变量的值。


执行完毕没有结果,因为第一个脚本声明的变量第二个脚本没法执行
加上export以后,变量可以向下传递
2) 使修改生效,并配置JDK
#使修改生效
source /etc/profile
#查看系统变量值
echo $PATH
#检查JDK 配置情况
java -version3.5.4 修改主机名
vim /etc/hostname
#修改完后用hostname可查看当前主机名
hostname
vim /etc/hosts
修改第一台机器的ip映射文件,然后分发都各个不同的机器上面
scp /etc/hosts root@s3:/etc/hosts3.5.5 创建hadoop 用户并设置密码
#创建hadoop用户
useradd hadoop
#给hadoop用户设置密码: 12345678
passwd hadoop3.5.6 禁止非 wheel 组用户切换到root,配置免密切换root
通常情况下,一般用户通过执行“su -”命令、输入正确的root密码,可以登录为root用户来对系统进行管理员级别的配置。
但是,为了更进一步加强系统的安全性,有必要建立一个管理员的组,只允许这个组的用户来执行 “su -” 命令登录为 root 用户,而让其他组的用户即使执行 “su -” 、输入了正确的 root 密码,也无法登录为 root 用户。在UNIX和Linux下,这个组的名称通常为 “wheel” 。
1)修改/etc/pam.d/su配置
su 时要求 这个用户必须加入到wheel组,否则权限不足
修改/etc/pam.d/su文件,将“#auth\t\trequired\tpam_wheel.so”,替换成“auth\t\trequired\tpam_wheel.so”
修改/etc/pam.d/su文件,将字符串“#auth\t\tsufficient\tpam_wheel.so”替换成“auth\t\tsufficient\tpam_wheel.so”
sed -i 's/#auth\t\trequired\tpam_wheel.so/auth\t\trequired\tpam_wheel.so/g' '/etc/pam.d/su'
sed -i 's/#auth\t\tsufficient\tpam_wheel.so/auth\t\tsufficient\tpam_wheel.so/g' '/etc/pam.d/su' 命令说明:
修改某个文件,并替换文件里的内容,命令格式:
sed -i 's/要被取代的字串/新的字串/g' '文件名'-i :直接修改读取的文件内容,而不是输出到终端。
2)修改/etc/login.defs文件
只有wheel组可以su 到root
cp /etc/login.defs /etc/login.defs_back 先备份一个
# 把“SU_WHEEL_ONLY yes”字符串追加到/etc/login.defs文件底部
echo "SU_WHEEL_ONLY yes" >> /etc/login.defs tail /etc/login.defs 从文件底部查看

3) 添加用户到管理员,禁止普通用户su 到 root
#把hadoop用户加到wheel组里
gpasswd -a hadoop wheel
#查看wheel组里是否有hadoop用户
cat /etc/group | grep wheel4)用vuser1 用户验证一下,由于vuser1 没有在wheel 组里,所以没有 su - root 权限。
useradd vuser1
su - vuser1
su - 是直接切换到root用户
海牛实验室的root用户的密码默认是hainiu
5)验证免密码切换到 root 用户
3.5.7 给hadoop用户,配置SSH密钥
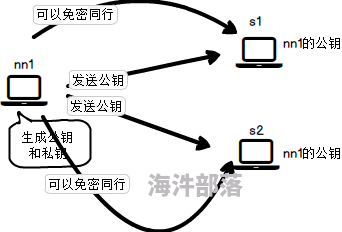
配置SSH密钥的目的:使得多台机器间可以免密登录。
实现原理:
使用ssh-keygen在nn1 上生成private和public密钥,将生成的public密钥拷贝到远程机器s1 上后,就可以使用ssh命令无需密码登录到另外一台机器s1上。如果想互相登录,则要把公钥私钥都拷贝到远程机器s1 上。
#切换到hadoop用户
su – hadoop
#创建.ssh目录
mkdir ~/.ssh
#生成ssh公私钥
ssh-keygen -t rsa -f ~/.ssh/id_rsa -P ''
#输出公钥文件内容并且重新输入到~/.ssh/authorized_keys文件中
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
#给~/.ssh文件加上700权限
chmod 700 ~/.ssh
#给~/.ssh/authorized_keys加上600权限
chmod 600 ~/.ssh/authorized_keys
然后将配置的信息发送到每一个机器上面
scp -r /home/hadoop/.ssh hadoop@s1:/home/hadoop4 hadoop多服务器批量操作
4.1 如何获取当前执行脚本的路径
用`dirname \$0`。
这个命令写在脚本文件里才有作用,他返回这个脚本文件放置的目录,这样就可以知道一些和脚本一起部署的文件的位置了,只要知道相对位置就可以根据这个目录来定位,而可以不用关心绝对位置。这样脚本的可移植性就提高了,扔到任何一台服务器,(如果是部署脚本)都可以执行。
#! /bin/bash
#获取脚本的当前位置
cd `dirname $0`
#输出脚本位置
echo `pwd`
4.2 命令说明及使用
4.2.1 scp 命令
scp 就是secure copy,一个在linux下用来进行远程拷贝文件的命令。
格式:
scp 文件名 登录用户名@目标机器IP或主机名:目标目录示例:
scp /home/hadoop/f1 hadoop@s1:/home/hadoop/
4.2.2 ssh 命令
1)指定用户登录其他机器
ssh 登录用户名@目标ip或主机名示例:
ssh hadoop@s1
2)指定用户登录其他机器执行某些命令
ssh 登录用户名@目标ip或主机名 命令示例:
ssh hadoop@s1 ls
4.2.3 eval命令
如何动态执行拼接的SSH 命令, 通过 eval 命令
eval命令会计算(evalue)它的参数,这些参数作为表达式计算后重新组合为一个字符串,然后作为一个命令被执行。
eval最常见的用法是将动态生成的命令行计算并执行。
示例:
name=hadoop
cmd="echo hello $name\! "
eval $cmd4.3 批量脚本说明及使用
ips :用于存放要操作的主机列表,用回车或空格隔开
scp_all.sh :用hadoop用户拷贝当前机器的文件到其他操作机(多机分发脚本)
ssh_all.sh :用hadoop 用户可登陆其他操作机执行相应操作(多机操作脚本)
exe.sh : 执行su 命令,与ssh_root.sh 配套使用
ssh_root.sh : 用hadoop 用户登录其他操作机,并su 到 root 用户,以root 用户执行相应操作,与exe.sh 配套使用(root权限多机操作脚本)
4.3.1 ips
ips :用于存放要操作的主机列表,用回车或空格隔开
nn1
nn2
s1
s2
s34.3.2 ssh_all.sh
用hadoop 用户可登陆其他操作机执行相应操作
#! /bin/bash
# 进入到当前脚本所在目录
cd `dirname $0`
# 获取当前脚本所在目录
dir_path=`pwd`
#echo $dir_path
# 读ips文件得到数组(里面是一堆主机名)
ip_arr=(`cat $dir_path/ips`)
# 遍历数组里的主机名
for ip in ${ip_arr[*]}
do
# 拼接ssh命令: ssh hadoop@nn1 ls
cmd_="ssh hadoop@${ip} \"$*\""
echo $cmd_
# 通过eval命令 执行 拼接的ssh 命令
if eval ${cmd_} ; then
echo "OK"
else
echo "FAIL"
fi
done4.3.3 scp_all.sh
用hadoop用户拷贝当前机器的文件到其他操作机
#! /bin/bash
# 进入到当前脚本所在目录
cd `dirname $0`
# 获取当前脚本所在目录
dir_path=`pwd`
#echo $dir_path
# 读ips文件得到数组(里面是一堆主机名)
ip_arr=(`cat $dir_path/ips`)
# 源
source_=$1
# 目标
target=$2
# 遍历数组里的主机名
for ip in ${ip_arr[*]}
do
# 拼接scp命令: scp 源 hadoop@nn1:目标
cmd_="scp ${source_} hadoop@${ip}:${target}"
echo $cmd_
# 通过eval命令 执行 拼接的scp 命令
if eval ${cmd_} ; then
echo "OK"
else
echo "FAIL"
fi
done4.3.4 exe.sh
执行su 命令,与ssh_root.sh 配套使用
cmd=$*
su - << EOF
$cmd
EOF
4.3.5 ssh_root.sh
用hadoop 用户登录其他操作机,并su 到 root 用户,以root 用户执行相应操作,与exe.sh 配套使用
#! /bin/bash
# 进入到当前脚本所在目录
cd `dirname $0`
# 获取当前脚本所在目录
dir_path=`pwd`
#echo $dir_path
# 读ips文件得到数组(里面是一堆主机名)
ip_arr=(`cat $dir_path/ips`)
# 遍历数组里的主机名
for ip in ${ip_arr[*]}
do
# 拼接ssh命令: ssh hadoop@nn1 ls
cmd_="ssh -t hadoop@${ip} ~/exe.sh \"$*\""
echo $cmd_
# 通过eval命令 执行 拼接的ssh 命令
if eval ${cmd_} ; then
echo "OK"
else
echo "FAIL"
fi
done4.4 批量脚本的使用
**首先切换到hadoop用户
**
1)将批量脚本上传到机器上
把hadoop_op.zip文件用 rz 命令上传到 nn1机器上
hadoop_op只放在nn1.hadoop机器上
exe.sh 要分发到每台机器的hadoop 用户家bin目录下
2)解压批量脚本,并修改批量脚本权限
一般先切换到当前使用用户的home/bin目录下
cd/cd \~
unzip hadoop_op.zip
cd hadoop_op
# 给每个脚本+执行权
chmod a+x ./*.sh
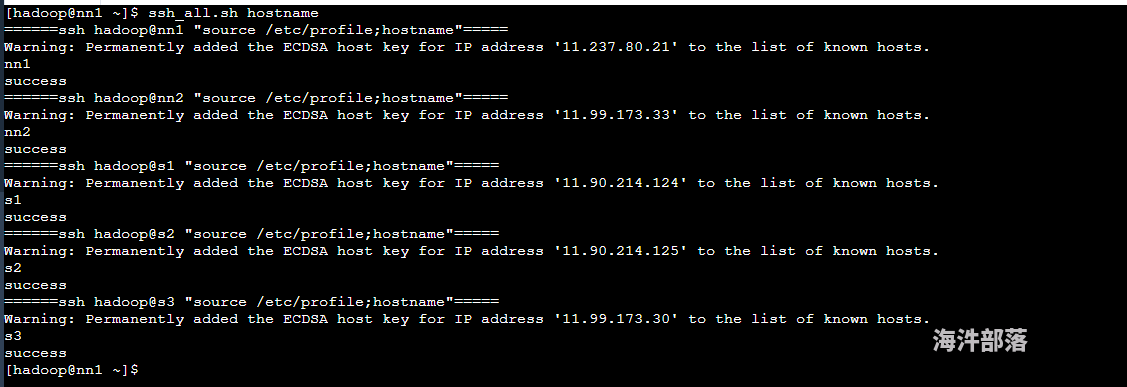
3)测试批量操作(ssh_all.sh, hadoop用户权限)
./ssh_all.sh hostname
4)测试批量分发文件(scp_all.sh, hadoop用户权限**)**

5)测试root权限批量操作****(ssh_root.sh, root 用户权限)
**执行 ssh_root.sh 前要将exe.sh文件分发到每个机器的hadoop用户家目录bin下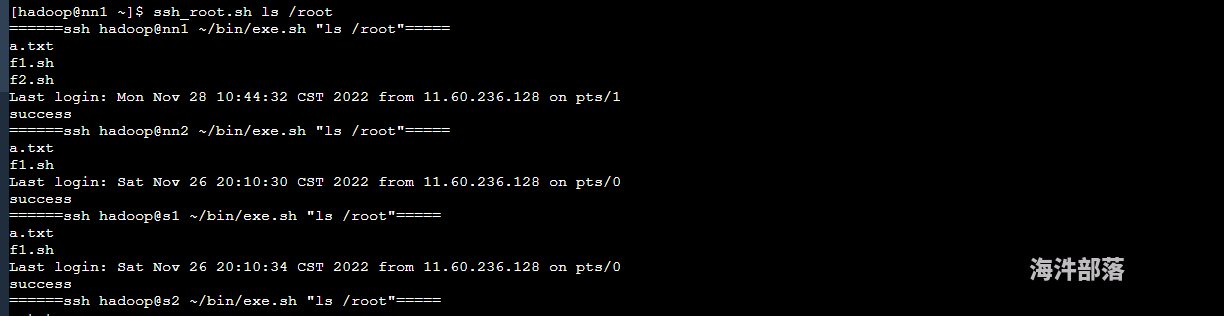
Hadoop用户没权限
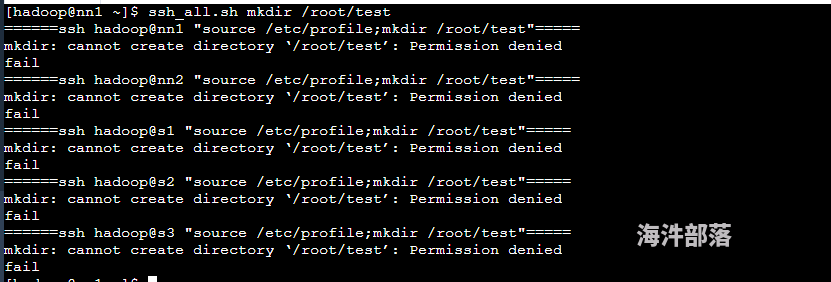
**
思考题:
假如nn1 上的/root 目录下有个f1文件,如何将f1文件分发到5台机器的/root/op/ 目录下?
要求:不允许单机操作直接拷贝,利用多机操作、多机分发脚本来完成。
#1)hadoop:创建5台的/root/op/ 目录
[hadoop@nn1 hadoop_op]$ ./ssh_root.sh mkdir -p /root/op
# 2)root:cp /root/f1 /home/hadoop
[hadoop@nn1 hadoop_op]$ su - root
上一次登录:六 7月 17 10:07:11 CST 2021
[root@nn1 ~]# cp f1 /home/hadoop
[root@nn1 ~]# ll /home/hadoop | grep f1
-rw-r--r-- 1 root root 0 7月 17 10:08 f1
# 3)Hadoop:分发到5台机器的/home/hadoop
[hadoop@nn1 hadoop_op]$ ./scp_all.sh ~/f1 /home/hadoop
# 4)Hadoop:将每台的/home/hadoop/f1 mv 到 /root/op 目录下
[hadoop@nn1 hadoop_op]$ ./ssh_root.sh mv ~/f1 /root/op
# 查看
[hadoop@nn1 hadoop_op]$ ./ssh_root.sh ls /root/op 操作镜像位置,各位小伙伴可以直接通过连接找到我的镜像
直接将镜像添加到自己的实验中就可以直接启动了
http://cloud.hainiubl.com/#/privateImageDetail?id=2655&imageType=private

