spark-sql
20.1 SparkSQL的发展历程
20.1.1 Hive and Shark
SparkSQL的前身是Shark,是给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,它是运行在Hadoop上的SQL-on-hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,运行效率低。为了提高SQL-on-Hadoop的效率,shark 应运而生。它修改了下图所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升。
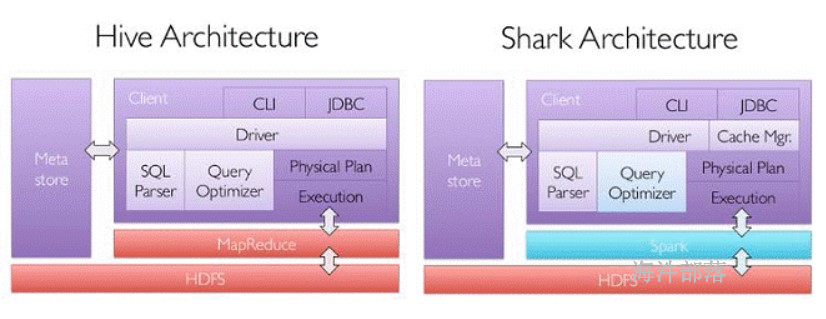
随着Spark的发展,对于野心勃勃的Spark团队来说,Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),制约了Spark各个组件的相互集成,所以提出了SparkSQL项目。
SparkSQL抛弃原有Shark的代码,摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
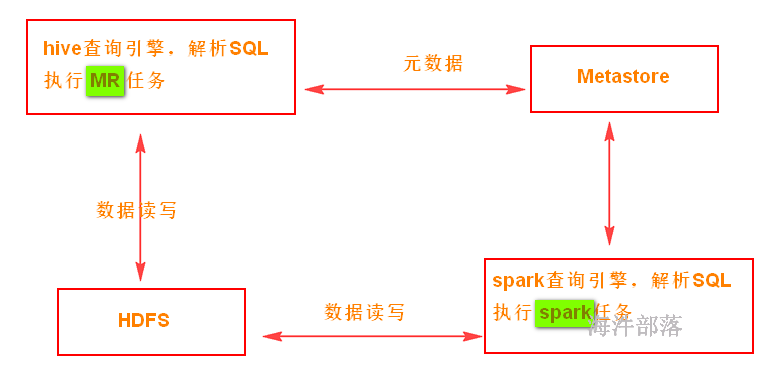
hive与spark-sql的对比
20.2 实验室集群配置
1)安装hive
#以nn1机器为例
#切换用户为root,安装的目录是/usr/local
tar -zxvf /public/software/bigdata/apache-hive-3.1.3-bin.tar.gz -C /usr/local/
#修改权限
chown hadoop:hadoop -R /usr/local/apache-hive-3.1.3-bin/
#创建软连接
ln -s /usr/local/apache-hive-3.1.3-bin/ /usr/local/hive
# 配置环境变量 /etc/profile
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
# 基础准备工作完毕2) 安装mysql
wget https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm
安装mysql 源
rpm -ivh mysql57-community-release-el7-11.noarch.rpm
修改阿里云的镜像为原生镜像
rm -rf CentOS-Base.repo
mv CentOS-Base.repo.back CentOS-Base.repo
检查mysql源是否安装成功
yum repolist enabled | grep "mysql.*-community.*"
用 yum 命令安装mysql
yum -y install mysql-community-server
出现问题
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
重新执行安装
查看MYSQL配置文件加载顺序:
mysqld --help --verbose|grep -A1 -B1 cnf
修改/etc/my.cnf 配置文件内的文件目录
datadir=/data/mysql/data
sql_mode=STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
log-error=/data/mysql/log/mysqld.log
创建mysql 文件目录
[root@localhost jar]# mkdir -p /data/mysql/data
[root@localhost jar]# mkdir -p /data/mysql/log
生成首次登录随机密码
mysqld --initialize
修改mysql 文件目录所有者为 mysql 用户
chown -R mysql:mysql /data/mysql
systemctl start mysqld.service
如果systemctl不能使用,我们需要进行替换
文件在/public/software/other/systemctl
cp /public/software/other/systemctl /usr/bin/systemctl
如果说启动mysql后使用
ps -ef|grep mysql
如果没有任何进程
chmod 777 -R /data/mysql
systemctl start mysqld.service
用生成的随机密码登录mysql
随机密码的位置 /data/mysql/log/mysqld.log
mysql -uroot -p'/FJThgDrD6Il'
修改ROOT用户密码
set password=PASSWORD('123456'); 3)创建用户和数据库
mysql -uroot -p'123456'
--创建hive用户
CREATE USER 'hive'@'%' IDENTIFIED BY '12345678';
--在mysql中创建hive_meta数据库
create database hive_meta default charset utf8 collate utf8_general_ci;
--给hive用户增加hive_meta数据库权限
grant all privileges on hive_meta.* to 'hive'@'%' identified by '12345678';
--更新
flush privileges;
拷贝mysql驱动jar 到/usr/local/hive/lib/
cp /public/software/other/mysql-connector-java-5.1.35.jar /usr/local/hive/lib/
删除冲突jar包
rm -f /usr/local/hive/lib/log4j-slf4j-impl-2.4.1.jar
创建文件夹
su - hadoop
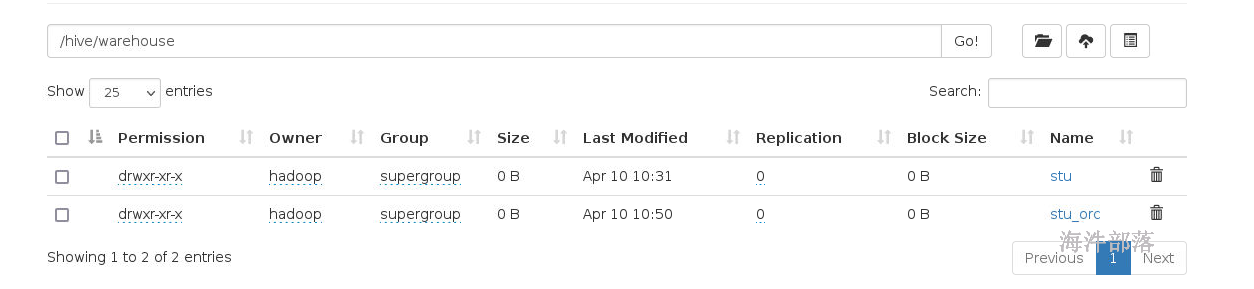
hadoop fs -mkdir -p /hive/warehouse
hadoop fs -chmod -R 777 /hive
hadoop fs -ls /hive
初始化元数据仓库
schematool -dbType mysql -initSchema
初始化的时候出现jar包冲突,对比换成版本比较高的
hive中guava.jar位置/hive/lib/
hadoop中guava.jar位置/hadoop/share/hadoop/common/lib/
命令如下
rm -rf /usr/local/hive/lib/guava-19.0.jar
cp /usr/local/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/hive/lib/4) 修改后的hive-site.xml 内容
/usr/local/hive/conf/
<configuration>
<!-- 数据库 start -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://nn1:3306/hive_meta</value>
<description>mysql连接</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>mysql驱动</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>数据库使用用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>12345678</value>
<description>数据库密码</description>
</property>
<!-- 数据库 end -->
<!-- HDFS start -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive使用的HDFS目录</description>
</property>
<!-- HDFS end -->
<!-- metastore start 在客户端使用时,mysql连接和metastore同时出现在配置文件中,客户端会选择使用metastore -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://nn1:9083</value>
</property>
<!-- metastore end -->
<!-- hiveserver start -->
<property>
<name>hive.server2.authentication</name>
<value>NONE</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>nn1</value>
<description>hive开启的thriftServer地址</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>hive开启的thriftServer端口</description>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>true</value>
</property>
<!-- hiveserver end -->
<!-- 其它 start -->
<property>
<name>datanucleus.autoCreateSchema</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoStartMechanism</name>
<value>SchemaTable</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!-- 其它 end -->
</configuration>
到此为止hive安装完毕
#启动元数据服务
nohup hive --service metastore >> /tmp/hive.log 2>&1 &配置spark的hive-site.xml
<configuration>
<!-- HDFS start -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive使用的HDFS目录</description>
</property>
<!-- HDFS end -->
<!-- metastore start 在客户端使用时,mysql连接和metastore同时出现在配置文件中,客户端会选择使用metastore -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>校验metastore版本信息是否与sparkjar 版本一致;true:校验;false:不校验</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://nn1:9083</value>
</property>
<!-- metastore end -->
<!-- hiveserver start -->
<property>
<name>hive.server2.thrift.min.worker.threads</name>
<value>5</value>
<description>Minimum number of Thrift worker threads</description>
</property>
<property>
<name>hive.server2.thrift.max.worker.threads</name>
<value>500</value>
<description>Maximum number of Thrift worker threads</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>nn1</value>
<description>hive开启的thriftServer地址</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>20000</value>
<description>开启spark的thriftServer端口</description>
</property>
<!-- hiveserver end -->
</configuration>其中:
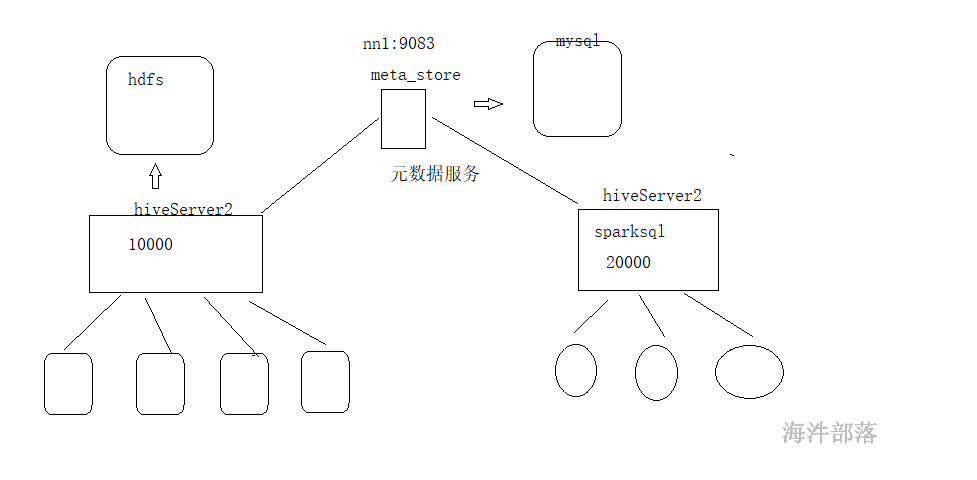
hive.metastore.schema.verification,用于校验 metastore版本信息是否与spark jar 版本一致;true:校验;false:不校验;
hive 有个hiveserver2服务,端口是10000;而spark 用的hiveserver2服务,配置的端口是20000,不冲突。
2)spark-env.sh
使得spark 能与hadoop关联。

3)减少spark sql 日志输出,修改spark conf 目录下的 log4j.properties

20.3 spark-sql shell(自己玩)
20.3.1 启动spark-SQL shell 步骤
# 启动yarn集群
#启动hive服务
nohup hive --service metastore > /dev/null 2>&1 &
#执行sparkSQL
spark-sql –master yarn –queue root.hainiu –num-executors 2 –executor-memory 1G --executor-cores 2这种方式每个人一个driver彼此之间的数据无法共享;
启动任务后,发现还没跑 任务,就已经占用了 资源,因为现在还没有机制能计算出跑SQL任务会用多少内存。而hive是只有跑任务才去算占用多少资源。

20.3.2 运行sparkSQL
写hive命令即可。
-- 查看数据库
show databases;
create database hainiu;
-- 进入数据库
use hainiu;
--创建表
create table student(id int,name string,age int)
row format delimited fields terminated by ' ';1)查询统计student表记录数
select count(1) from student;
执行带有shuffle 的SQL,会产生200 partition。
select count(1),id from student group by id;
可以通过 set spark.sql.shuffle.partitions=20; 进行设置partition的个数,这样可以减少shuffle的次数。
set spark.sql.shuffle.partitions=20;
select count(1),id from student group by id;
20.3.3 通过bin/spark-sql –help可以查看CLI命令参数
spark-sql –help
spark-shell -h 查看帮助
20.4 spark thriftserver(共享玩)
ThriftServer是一个JDBC/ODBC接口,用户可以通过JDBC/ODBC连接ThriftServer来访问SparkSQL的数据。ThriftServer在启动的时候,会启动了一个SparkSQL的应用程序,而通过JDBC/ODBC连接进来的客户端共同分享这个SparkSQL应用程序的资源,也就是说不同的用户之间可以共享数据;ThriftServer启动时还开启一个侦听器,等待JDBC客户端的连接和提交查询。所以,在配置ThriftServer的时候,至少要配置ThriftServer的主机名和端口,如果要使用Hive数据的话,还要提供Hive Metastore的uris。
这种方式所有人可以通过driver连接,彼此之间的数据可以共享。
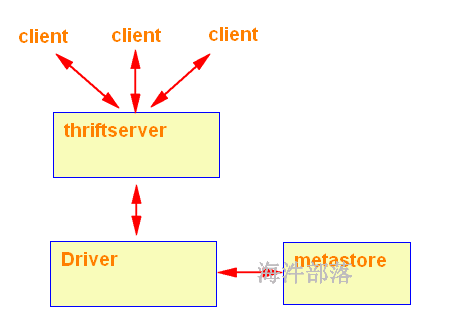
20.4.1 启动spark thriftserver
#启动yarn集群
#启动hive服务
nohup hive --service metastore > /dev/null 2>&1 &
#启动thriftserver服务
/usr/local/spark/sbin/start-thriftserver.sh --master yarn --queue hainiu在 op.hadoop 机器启动thriftserver 服务
集群只要启动一个即可,如果报端口被占用,说明有人已经启动过。
20.4.2 使用spark的beeline 连接 thriftserver
beeline 分为hive 和 spark的。
hive 的 beeline :/usr/local/hive/bin/beeline
spark 的 beeline : /usr/local/spark/bin/beeline
在op.hadoop上启动beelie, 连接 nn1 的thriftserver 服务
/usr/local/spark/bin/beeline
!connect jdbc:hive2://nn1:20000

yarn页面看见启动了sparkSQL任务

20.4.3 在thriftsever 上跑 sparkSQL
select count(1),id from student group by id;
首先准备数据
vim /home/hadoop/a.txt
2 lisi 30
3 wangwu 40
4 zhaosi 43
5 liuneng 44
6 guangkun 45
7 dajiao 46
8 daguo 47插入数据
load data local inpath '/home/hadoop/a.txt' into table student;cache table 表名;
uncache table student;
cache table 数据集别名 as 查询SQL
cache table cnt_table as select id,count(1) from student group by id;
去除缓存
uncache table tablename;内存缓存

uncache

20.5 spark-webUI
怎么合理的运用并行化,比如要处理的数据最终生成的partition是30个,那你的job设置的资源就应该是10到15个cores。为什么呢?因为官方推荐的设置是(2\~3)*cores = parttions,这样设置的主要原因是executor不会太闲置或者太繁忙。
模拟数据
# linux中存在python环境的
# 进入到nn1机器中
python
with open("/tmp/abc.txt","a") as f:
for i in range(100000):
f.write("%s,hainiu_%s,%s\n" % (i,i,i))
退出python
exit()
然后加载数据到sparksql的表中
create table stu(id int,name string, age int)
row format delimited fields terminated by ',';
--加载数据
load data local inpath '/tmp/abc.txt' into table stu;
多次load数据

如何判断任务并行化是否合理?
先看你的RDD会有多少个task,也就是有多少个partition

因为读取的数据个数10个文件,对应存在10个block块,分区就是10个
单独统计每个文件的元素的个数,然后整体统计所有的元素的个数
再看你的任务总cores资源是多少

job运行11个task,提供的CPU核数2个, 相对比较合理,但CPU核有空转的。
如何知道自己使用的RDD到底会使用多大的存储空间?
直接缓存表方式:
如果表数据是txt格式,可以根据表对应hdfs的大小来设定。
如果表数据是orc格式文件,那缓存的大小 = 对应hdfs的大小 * 3。


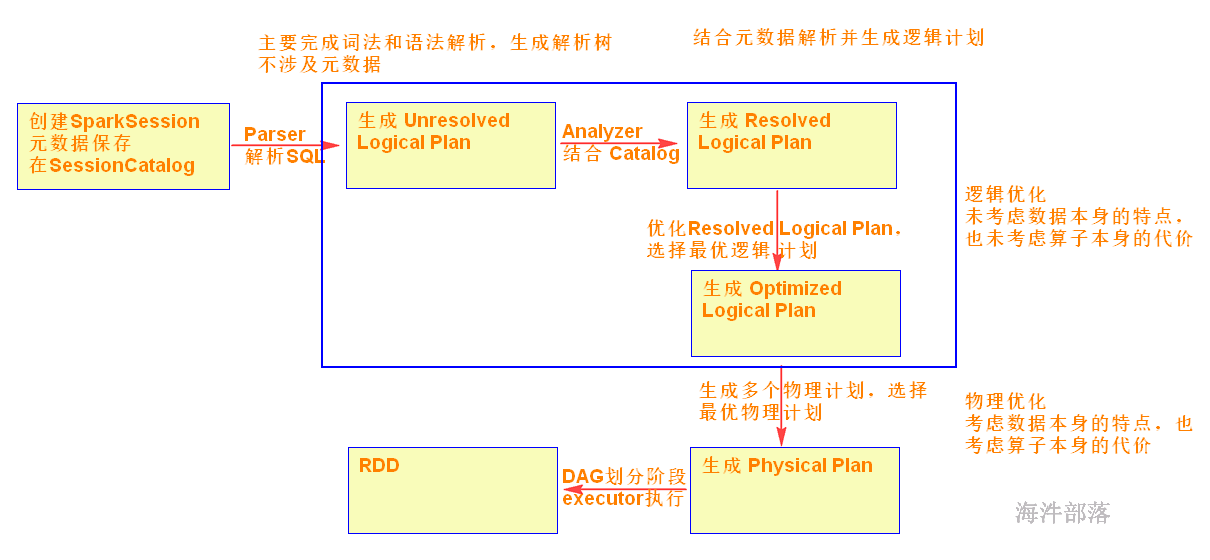
20.6 spark-sql执行过程
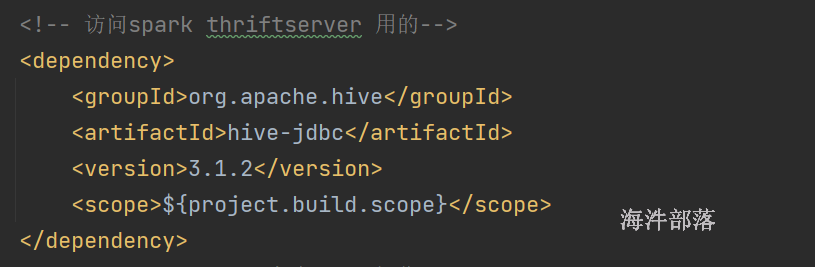
20.7 通过JDBC连接thriftserver
pom里添加spark的hive-jdbc,之前已经添加过
使用JDBC访问spark-sql server 程序:
package com.hainiu.spark
import org.apache.hive.jdbc.HiveDriver
import java.sql.{DriverManager, ResultSet}
object TestBeeline {
def main(args: Array[String]): Unit = {
//scala jdbc -> sql -->sparksql
classOf[HiveDriver]
val con = DriverManager.getConnection("jdbc:hive2://nn1:20000","hadoop",null)
val prp = con.prepareStatement("select count(1) as cnt from stu")
val set: ResultSet = prp.executeQuery()
while(set.next()){
val cnt = set.getLong("cnt")
println("stu表的总条数是 :"+cnt)
}
con.close()
}
}
结果:

20.8 spark-sql 编程
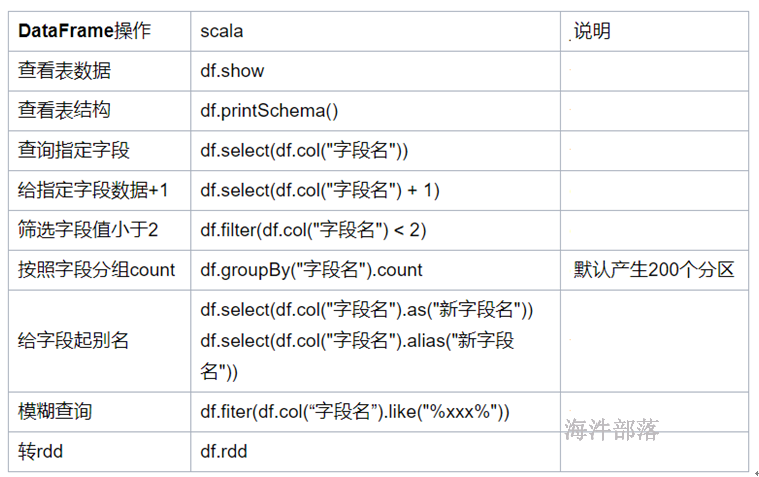
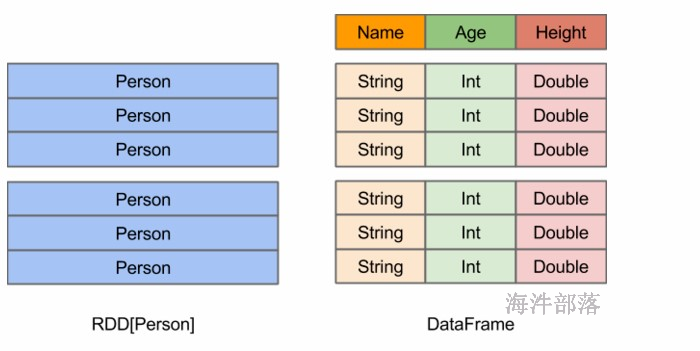
20.8.1 dataFrame对象
DataFrame:
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这样的数据集可以用SQL查询。
创建方式
准备数据
1 zhangsan 20 male
2 lisi 30 female
3 wangwu 35 male
4 zhaosi 40 femaletoDF方式
package com.hainiu.spark
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}
object TestSparkSql{
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test sql")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val sqlSc = new SQLContext(sc)
//环境对象包装
import sqlSc.implicits._
//引入环境信息
val rdd = sc.textFile("data/a.txt")
.map(t => {
val strs = t.split(" ")
(strs(0).toInt, strs(1), strs(2).toInt)
})
//增加字段信息
val df = rdd.toDF("id", "name", "age")
df.show() //展示表数据
df.printSchema() //展示表格字段信息
}
}使用类定义schema
object TestSparkSql{
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test sql")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val sqlSc = new SQLContext(sc)
import sqlSc.implicits._
val rdd = sc.textFile("data/a.txt")
.map(t => {
val strs = t.split(" ")
Student(strs(0).toInt, strs(1), strs(2).toInt)
})
// val df = rdd.toDF("id", "name", "age")
val df = rdd.toDF()
df.show() //打印数据,以表格的形式打印数据
df.printSchema() //打印表的结构信息
}
}
case class Student(id:Int,name:String,age:Int)createDataFrame方式
这种方式需要将rdd和schema信息进行合并,得出一个新的DataFrame对象
package com.hainiu.spark
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
object TestSparkSqlWithCreate {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test create")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val sqlSc = new SQLContext(sc)
val rdd = sc.textFile("data/a.txt")
.map(t => {
val strs = t.split(" ")
Row(strs(0).toInt, strs(1), strs(2).toInt)
})
// rdd + schema
val schema = StructType(
Array(
StructField("id",IntegerType),
StructField("name",StringType),
StructField("age",IntegerType)
)
)
val df = sqlSc.createDataFrame(rdd, schema)
df.show()
df.printSchema()
}
}20.8.2 sparksql的查询方式
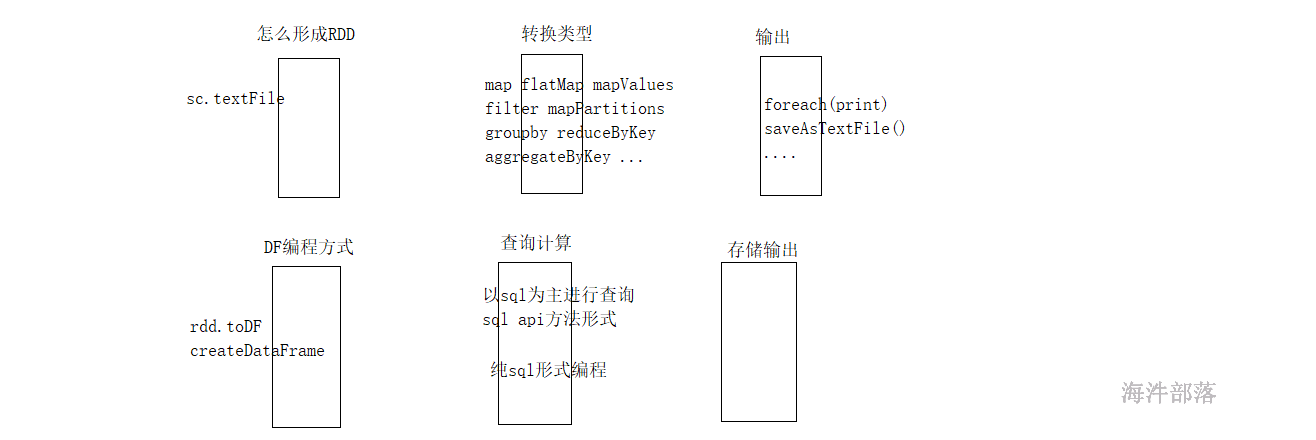
第二个部分关于df的查询
第一种sql api的方式查询
- 使用的方式方法的形式编程
- 但是思想还是sql形式
- 和rdd编程特别相似的一种写法
object TestSql {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test sql")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val sqlSc = new SQLContext(sc)
import sqlSc.implicits._
val rdd = sc.textFile("data/a.txt")
.map(t => {
val strs = t.split(" ")
(strs(0).toInt, strs(1), strs(2).toInt,strs(3))
})
val df = rdd.toDF("id", "name", "age","gender")
//select * from student where age >20
//df.where("age >20")
//分组聚合
//df.groupby("gender").sum("age")
//几个问题
//聚合函数不能增加别名 聚合函数不能多次聚合 orderby不识别desc
// df.groupBy("gender").agg(count("id").as("id"),sum("age").as("age")).orderBy($"age".desc)
//字段标识可以是字符串,也可以是字段对象
//df.orderBy($"age".desc)
//df.orderBy(col("age").desc)
//df.orderBy(df("age").desc)
//增加字段对象可以实现高端操作
//df.select($"age".+(1))
//join问题
//val df1 = sc.makeRDD(Array(
// (1,100,98),
// (2,100,95),
// (3,90,92),
//(4,90,93)
//)).toDF("id","chinese","math")
//df.join(df1,"id") //字段相同
//df.join(df1,df("id")===df1("id"))
//窗口函数
//普通函数 聚合函数 窗口函数 sum|count|rowkey over (partition by gender order by age desc)
//按照条件分割完毕进行数据截取
//班级的前两名 每个性别年龄最高的前两个
//select *,row_number() over (partition by gender order by age desc) rn from table
import sqlSc.implicits._
import org.apache.spark.sql.functions._
df.withColumn("rn",row_number().over(Window.partitionBy("gender").orderBy($"age".desc)))
.where("rn = 1")
.show()
}
}第二种纯sql形式的查询
- 首先注册表
- 然后使用sql查询
- 最终得出的还是dataFrame的对象
- 其中和rdd的编程没有任何的区别,只不过现在使用sql形式进行处理了而已
package com.hainiu.spark
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
object TestSparkSqlWithCreate {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test create")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val sqlSc = new SQLContext(sc)
val rdd = sc.textFile("data/a.txt")
.map(t => {
val strs = t.split(" ")
Row(strs(0).toInt, strs(1), strs(2).toInt,strs(3))
})
// rdd + schema
val schema = StructType(
Array(
StructField("id",IntegerType),
StructField("name",StringType),
StructField("age",IntegerType),
StructField("gender",StringType),
)
)
val df = sqlSc.createDataFrame(rdd, schema)
//sql形式查询
//select col from table
df.createTempView("student")
val df1 = sqlSc.sql(
"""
|select count(1) cnt,gender from student group by gender
|""".stripMargin)
df1.createTempView("student1")
val df2 = sqlSc.sql(
"""
|select * from student1 where cnt>1
|""".stripMargin)
df2.show()
df2.printSchema()
}
}函数查询练习
#电影推荐的练习
#首先将数据从 /public/data/movie_data中将数据复制到idea的data文件夹中
# movie中的数据是
# mid name type
# ratings中的数据是
# userid mid score time整体代码如下:
package com.hainiu.spark
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.expressions.Window
import org.apache.spark.{SparkConf, SparkContext}
object TestMovieWithSql {
def main(args: Array[String]): Unit = {
//??movie???
//1.id middle=name last=type
val conf = new SparkConf()
conf.setAppName("movie")
conf.setMaster("local[*]")
conf.set("spark.shuffle.partitions","20")
val sc = new SparkContext(conf)
val sqlSc = new SQLContext(sc)
import sqlSc.implicits._
//deal data
val df = sc.textFile("data/movies.txt")
.flatMap(t => {
val strs = t.split(",")
val mid = strs(0)
val types = strs.reverse.head
val name = strs.tail.reverse.tail.reverse.mkString(" ")
types.split("\\|").map((mid, name, _))
}).toDF("mid", "mname", "type")
df.limit(1).show()
val df1 = sc.textFile("data/ratings.txt")
.map(t=>{
val strs = t.split(",")
(strs(0),strs(1),strs(2).toDouble)
}).toDF("userid","mid","score")
df1.limit(1).show()
import org.apache.spark.sql.functions._
df.join(df1,"mid").groupBy("userid","type")
.agg(count("userid").as("cnt"))
.withColumn("rn",row_number().over(Window.partitionBy("userid").orderBy($"cnt".desc)))
.where("rn = 1")
.show()
// df.createTempView("movie")
// df1.createTempView("ratings")
// import org.apache.spark.sql.functions._
//
//
// sqlSc.sql(
// """
// |select userid,type,cnt
// |from
// |(select *,row_number() over (partition by userid order by cnt desc) rn
// |from
// |(select count(*) cnt,userid,type
// |from
// |(select userid,type
// |from
// |movie m join ratings r
// |on m.mid = r.mid)t
// |group by userid,type)t1)t2
// |where rn = 1
// |""".stripMargin)
// .show(200,false)
}
}作业题
每个用户最喜欢哪个类型的电影
每个类型中最受欢迎的前三个电影?
然后给用户推荐 val df11 = df.join(df1, "mid").groupBy("userid", "type")
.agg(count("userid").as("cnt"))
.withColumn("rn", row_number().over(Window.partitionBy("userid").orderBy($"cnt".desc)))
.where("rn = 1")
.select("userid", "type")
val df22 = df.join(df1, "mid").groupBy("type", "mname")
.agg(avg("score").as("avg"))
.withColumn("rn", row_number().over(Window.partitionBy("type").orderBy($"avg".desc)))
.where("rn<4")
.select("type", "mname")
df11.join(df22,"type")
.show()修改idea的内存参数
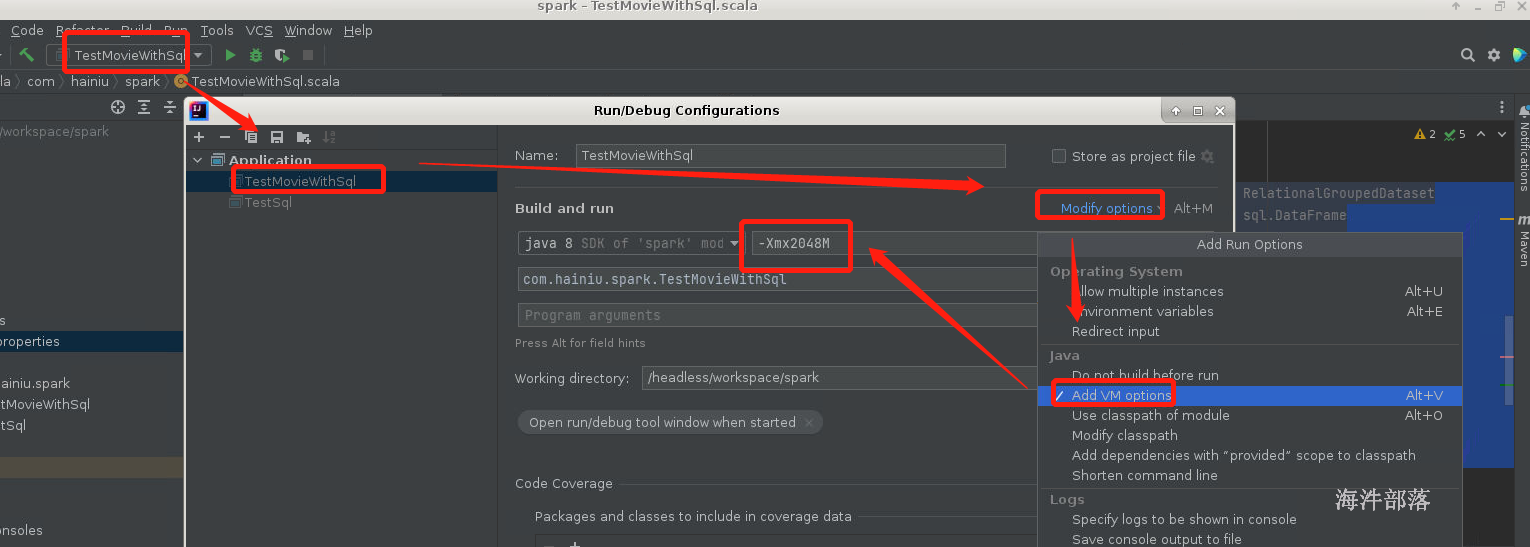
设定jvm的最大内存 -Xmx2048M
20.8.3 sparksql读写数据
我们使用sparksql进行编程,编程的过程我们需要创建dataframe对象,这个对象的创建方式我们是先创建RDD然后再转换rdd变成为DataFrame对象
但是sparksql给大家提供了多种便捷读取数据的方式
//原始读取数据方式
sc.textFile().toRDD
sqlSc.createDataFrame(rdd,schema)
//更便捷的使用方式
sqlSc.read.text|orc|parquet|jdbc|csv|json
df.write.text|orc|parquet|jdbc|csv|jsonwrite存储数据的时候也是文件夹的,而且文件夹不能存在
csv是一个介于文本和excel之间的一种格式,如果是文本打开用逗号分隔的
text文本普通文本,但是这个文本必须只能保存一列内容
以上两个文本都是只有内容的,没有列的
json是一种字符串结构,本质就是字符串,但是存在kv,例子 {"name":"zhangsan","age":20}
多平台解析方便,带有格式信息
orc格式一个列式存储格式,hive专有的
parquet列式存储,顶级项目
以上都是列式存储问题,优点(1.列式存储,检索效率高,防止冗余查询 2.带有汇总信息,查询特别快 3.带有轻量级索引,可以跳过大部分数据进行检索),他们都是二进制文件,带有格式信息
jdbc 方式,它是一种协议,只要符合jdbc规范的服务都可以连接,mysql,oracle,hive,sparksql
整体代码:
package com.hainiu.spark
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.expressions.Window
import org.apache.spark.{SparkConf, SparkContext}
import java.util.Properties
object TestMovieWithSql {
def main(args: Array[String]): Unit = {
//??movie???
//1.id middle=name last=type
val conf = new SparkConf()
conf.setAppName("movie")
conf.setMaster("local[*]")
conf.set("spark.shuffle.partitions","20")
val sc = new SparkContext(conf)
val sqlSc = new SQLContext(sc)
import sqlSc.implicits._
//deal data
val df = sc.textFile("data/movies.txt")
.flatMap(t => {
val strs = t.split(",")
val mid = strs(0)
val types = strs.reverse.head
val name = strs.tail.reverse.tail.reverse.mkString(" ")
types.split("\\|").map((mid, name, _))
}).toDF("mid", "mname", "type")
df.limit(1).show()
val df1 = sc.textFile("data/ratings.txt")
.map(t=>{
val strs = t.split(",")
(strs(0),strs(1),strs(2).toDouble)
}).toDF("userid","mid","score")
df1.limit(1).show()
import org.apache.spark.sql.functions._
val df11 = df.join(df1, "mid").groupBy("userid", "type")
.agg(count("userid").as("cnt"))
.withColumn("rn", row_number().over(Window.partitionBy("userid").orderBy($"cnt".desc)))
.where("rn = 1")
.select("userid", "type")
val df22 = df.join(df1, "mid").groupBy("type", "mname")
.agg(avg("score").as("avg"))
.withColumn("rn", row_number().over(Window.partitionBy("type").orderBy($"avg".desc)))
.where("rn<4")
.select("type", "mname")
val df33 = df11.join(df22, "type")
//spark3.1.2?? spark2.x
// df33.write.csv()
df33.write
.format("csv")
.save("data/csv")
// df33.write.
// csv("data/csv")
// df33.write.json("data/json")
// df33.write.parquet("data/parquet")
// df33.write.orc("data/orc")
// val pro = new Properties()
// pro.put("user","root")
// pro.put("password","hainiu")
// df33.write.jdbc("jdbc:mysql://11.99.173.24:3306/hainiu","movie",pro)
}
}为了简化存储的计算方式
package com.hainiu.spark
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}
object TestSink {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test sink")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val sqlSc = new SQLContext(sc)
import sqlSc.implicits._
import org.apache.spark.sql.functions._
val df = sc.textFile("data/a.txt")
.map(t=>{
val strs = t.split(" ")
(strs(0),strs(1),strs(2),strs(3))
}).toDF("id","name","age","gender")
.withColumn("all",concat_ws(" ",$"id",$"name",$"age",$"gender"))
.select("all")
// df.write.csv("data/csv")
// df.write.format("org.apache.spark.sql.execution.datasources.v2.csv.CSVDataSourceV2")
// .save("data/csv")
// df.write.parquet("data/parquet")
// df.write.format("org.apache.spark.sql.execution.datasources.v2.parquet.ParquetDataSourceV2")
// .save("data/parquet")
// df.write.format("org.apache.spark.sql.execution.datasources.v2.json.JsonDataSourceV2")
// .save("data/json")
df.write.format("org.apache.spark.sql.execution.datasources.v2.text.TextDataSourceV2")
.save("data/text")
}
}读取数据代码:
package com.hainiu.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SQLContext
import java.util.Properties
object TestReadData {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("movie")
conf.setMaster("local[*]")
conf.set("spark.shuffle.partitions", "20")
val sc = new SparkContext(conf)
val sqlSc = new SQLContext(sc)
// sqlSc.read.text("data/text").show()
// sqlSc.read.csv("data/csv").show()
//
// sqlSc.read.parquet("data/parquet").show()
// sqlSc.read.json("data/json").show()
sqlSc.read.format("org.apache.spark.sql.execution.datasources.v2.text.TextDataSourceV2").load("data/text").show()
sqlSc.read.format("org.apache.spark.sql.execution.datasources.v2.csv.CSVDataSourceV2").load("data/csv").show()
sqlSc.read.format("org.apache.spark.sql.execution.datasources.v2.json.JsonDataSourceV2").load("data/json").show()
sqlSc.read.format("org.apache.spark.sql.execution.datasources.v2.parquet.ParquetDataSourceV2").load("data/parquet").show()
sqlSc.read.orc("data/orc").show()
val pro = new Properties()
pro.put("user","root")
pro.put("password","hainiu")
sqlSc.read.jdbc("jdbc:mysql://11.99.173.24:3306/hainiu","movie",pro).show()
}
}20.8.4 读取hive数据
hive作为sparksql中的一个数据源,可以直接操作hive
准备工作
将hive-site.xml,core-site.xml,hdfs-site.xml放入到src/main/resources
直接在nn1机器远程发送配置文件到远程桌面的机器中
所有机器的root用户的密码是hainiu
scp /usr/local/hive/conf/hive-site.xml root@11.99.173.36:/headless/workspace/spark/src/main/resources
scp /usr/local/hadoop/etc/hadoop/hdfs-site.xml root@11.99.173.36:/headless/workspace/spark/src/main/resources
scp /usr/local/hadoop/etc/hadoop/core-site.xml root@11.99.173.36:/headless/workspace/spark/src/main/resources
读取代码;
首先修改hdfs的权限
hdfs dfs -chmod -R 777 /
#如果遇见内存不足我们换机器执行package com.hainiu.spark
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext}
object TestHive {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("movie")
conf.setMaster("local[*]")
conf.set("spark.shuffle.partitions", "20")
val sc = new SparkContext(conf)
//sparksql -->sqlSc
//hive -->hiveSc(sqlSc)
val hsc = new HiveContext(sc)
hsc.sql(
"""
|create table stu(id int,name string,age int)
|row format delimited fields terminated by ','
|""".stripMargin)
hsc.sql(
"""
|insert into stu(id,name,age)
|values(1,'zhangsan',20)
|""".stripMargin)
hsc.sql(
"""
|select * from stu
|""".stripMargin).show()
}
}
hdfs中的文件
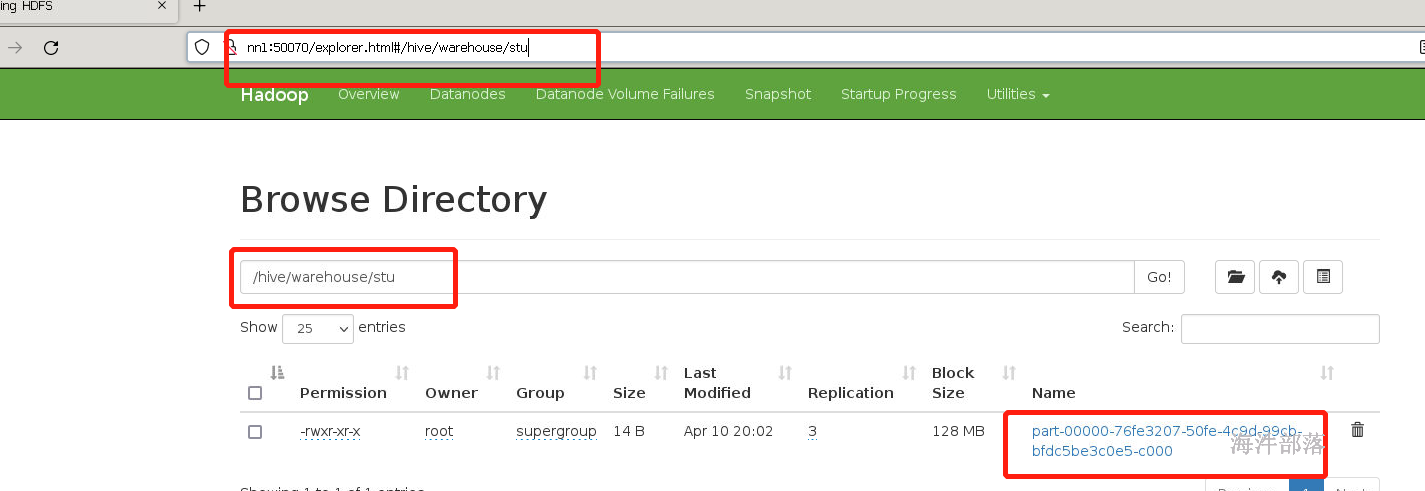
20.8.5 sparksession
之前使用的操作对象有三个
- sparkContext主要是为了rdd编程而产生的一个操作对象
- sqlContext主要是为了sparksql的编程而产生的
- hiveContext主要是操作hive的对象
归一化的对象
sparkSession对象融合了sc,sqlSc,hsc三种为一个整体
package com.hainiu.spark
import org.apache.spark.sql.SparkSession
object TestSession {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder()
.enableHiveSupport() //hive
.master("local[*]").appName("test").getOrCreate()
//session --> sc.sqlsc.hivesc
//sparkContext
val sc = session.sparkContext
session //sqlSc
import session.implicits._
val df = sc.textFile("file:///headless/workspace/spark/data/a.txt")
.map(t => {
val strs = t.split(" ")
(strs(0), strs(1), strs(2), strs(3))
}).toDF("id", "name", "age", "gender")
df.show()
df.createTempView("student")
session.sql("select * from student").show()
session.sql(
"""
|select count(1) from stu
|""".stripMargin)
.show()
}
}20.8.6 dataset
dataset是dataFrame的升级版对象,dataframe是一个传统的sql编程对象,如果要想使用dataframe进行灵活开发的比较复杂的
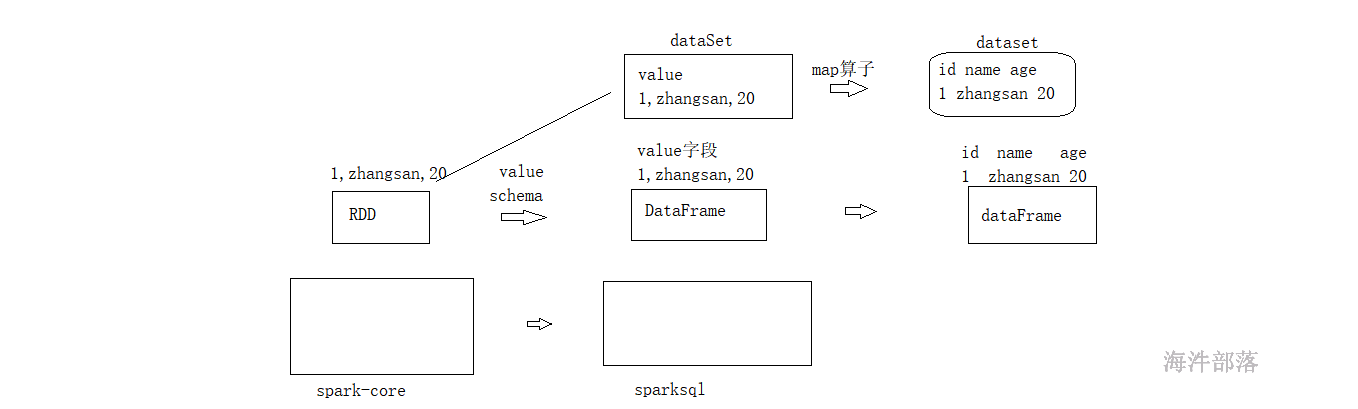
dataset和dataFrame是一个类别的对象,都是可以进行sql查询数据的,并且可以支持rdd上面的方法
当我们需要对一个表对象进行二次处理的话建议大家转换为dataset而不是dataframe
package com.hainiu.spark
import org.apache.spark.sql.{Dataset, SparkSession}
object TestDSAndDF {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("test").getOrCreate()
import session.implicits._
val ds: Dataset[String] = session.read.textFile("file:///headless/workspace/spark/data/a.txt")
ds.map(t=>{
val strs = t.split(" ")
(strs(0), strs(1), strs(2), strs(3))
})
// val df = session.read.format("org.apache.spark.sql.execution.datasources.v2.text.TextDataSourceV2")
// .load("file:///headless/workspace/spark/data/a.txt")
//
// val ds: Dataset[(String, String, String, String)] = df.map(row => {
// val line = row.getAs[String]("value")
// val strs = line.split(" ")
// (strs(0), strs(1), strs(2), strs(3))
// })
}
}20.9 RDD、DataFrame、Dataset
20.9.1 概念
RDD:
弹性分布式数据集;
DataFrame:
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这样的数据集可以用SQL查询。
DataFrame 是 DataSet[Row]
DataSet:
Dataset是一个强类型的特定领域的对象,Dataset也被称为DataFrame的类型化视图,这种DataFrame是Row类型的Dataset,即Dataset[Row]。

20.9.2 三者之间的转换
RDD、DataFrame、Dataset三者有许多共性,有各自适用的场景常常需要在三者之间转换;
val ds: Dataset[String] = session.read.textFile("file:///headless/workspace/spark/data/a.txt")
ds.map(t=>{
val strs = t.split(" ")
(strs(0), strs(1), strs(2), strs(3))
})
val df1 = ds.toDF("id","name","age","gender")
val df: Dataset[Row] = session.read.format("org.apache.spark.sql.execution.datasources.v2.text.TextDataSourceV2")
.load("file:///headless/workspace/spark/data/a.txt")
val rdd = session.sparkContext.textFile("file:///headless/workspace/spark/data/a.txt")
rdd.toDS()
rdd.toDF()
df.rdd
ds.rdd20.10 spark-sql的UDF
20.10.1 udf
数据库中的系统函数
oracle mysql impala hive sparksql flinksql
udf 一进一出,函数接受的是一行中的一个或者多个字段值,返回一个值
udaf聚合函数,多行作为参数输出的结果是一个
udtf拆分函数,单行进来输出的结果是多行
首先自定义udf
准备数据
1 zhangsan 20000 10000
2 lisi 21000 20000
3 wangwu 22000 21000定义udf统计每个人的年终总收入情况
程序:
package com.hainiu.spark
import org.apache.spark.sql.{SparkSession}
object TestUDF {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("testUDF").getOrCreate()
import session.implicits._
val df = session.sparkContext.textFile("file:///headless/workspace/spark/data/salary.txt")
.map(t => {
val strs = t.split(" ")
(strs(0), strs(1), strs(2).toInt, strs(3).toInt)
}).toDF("id", "name", "salary", "bonus")
session.udf.register("all_income",(sal:Int,bonus:Int)=>{
sal*12 + bonus
})
import org.apache.spark.sql.functions
df.withColumn("all",functions.callUDF("all_income",$"salary",$"bonus"))
.select("id","name","all")
.show()
//
// df.createTempView("salary")
// session.sql(
// """
// |select id,name,all_income(salary,bonus) all from salary
// |""".stripMargin)
// .show()
}
}

20.10.2 udaf 聚合函数
多进一出的函数
系统自带的聚合函数 count avg sum max min
以学生信息为主进行统计,所有人员的年龄的总和
或者每个性别的年龄的平均值
求和的整体代码:
package com.hainiu.spark
import org.apache.spark.sql.{Encoder, Encoders, SparkSession, functions}
import org.apache.spark.sql.expressions.{Aggregator, UserDefinedFunction}
object TestUDAF {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().appName("test udaf").master("local[*]").getOrCreate()
import session.implicits._
val df = session.sparkContext.textFile("file:///headless/workspace/spark/data/a.txt")
.map(t => {
val strs = t.split(" ")
(strs(0), strs(1), strs(2).toInt, strs(3))
}).toDF("id", "name", "age", "gender")
//avg(age)
import org.apache.spark.sql.functions._
// val df1 = df.agg(avg("age"))
// val df2 = df.groupBy("gender").avg("age")
//sum(age)
import org.apache.spark.sql.functions._
// df.agg(Mysum($"age")).show()
val mysum = functions.udaf(MySum)
df.agg(mysum($"age")).show
// session.udf.register("mysum",functions.udaf(sum))
//
// df.createTempView("student")
// session.sql(
// """
// |select mysum(age) from student
// |""".stripMargin)
// .show()
}
}
object MySum extends Aggregator[Int,Int,Int]{
//初始化
override def zero: Int = 0
//聚合逻辑
override def reduce(b: Int, a: Int): Int = a+b
//整体聚合
override def merge(b1: Int, b2: Int): Int = b1+b2
//最终返回值
override def finish(reduction: Int): Int = reduction
//累加值的类型
override def bufferEncoder: Encoder[Int] = Encoders.scalaInt
//输出结果的类型
override def outputEncoder: Encoder[Int] = Encoders.scalaInt
}求平均值的整体代码:
package com.hainiu.spark
import org.apache.spark.sql.{Encoder, Encoders, SparkSession, functions}
import org.apache.spark.sql.expressions.{Aggregator, UserDefinedFunction}
object TestUDAF {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().appName("test udaf").master("local[*]").getOrCreate()
import session.implicits._
val df = session.sparkContext.textFile("file:///headless/workspace/spark/data/a.txt")
.map(t => {
val strs = t.split(" ")
(strs(0), strs(1), strs(2).toInt, strs(3))
}).toDF("id", "name", "age", "gender")
//select avg(age)
val myavg = functions.udaf(MyAvg)
df.agg(myavg($"age")).show()
}
}
case class AggragateVo(var cnt:Int,var sum:Int)
object MyAvg extends Aggregator[Int,AggragateVo,Double]{
override def zero: AggragateVo = AggragateVo(0,0)
override def reduce(b: AggragateVo, a: Int): AggragateVo = {
b.cnt += 1
b.sum += a
b
}
override def merge(b1: AggragateVo, b2: AggragateVo): AggragateVo = {
b1.cnt += b2.cnt
b1.sum += b2.sum
b1
}
override def finish(reduction: AggragateVo): Double = {
reduction.sum.toDouble /reduction.cnt
}
override def bufferEncoder: Encoder[AggragateVo] = Encoders.product
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}20.10.3 udtf
拆分函数,进入的是一行内容出现的结果是多行内容
spark中不能定义拆分函数
但是可以使用hive中的udtf=>explode
首先准备文件
m.txt
1,wujiandao,liangchaowei|chenguanxi|liudehua
2,fenggou,chenguanxi|liudehua
3,dushen,zhourunfa|liudehua
4,shanghaitan,zhourunfa|liangchaoweipackage com.hainiu.spark
import org.apache.spark.sql.SparkSession
object TestUDTF {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().appName("test udtf").master("local[*]").getOrCreate()
import session.implicits._
val df = session.sparkContext.textFile("file:///headless/workspace/spark/data/m.txt")
.map(t => {
val strs = t.split(",")
(strs(0), strs(1), strs(2))
}).toDF("id", "name", "actors")
//explode map array
df.createTempView("movies")
session.sql(
"""
|select id,name,actor from movies lateral view explode(split(actors,'\\|')) t as actor
|""".stripMargin)
.createTempView("movies1")
session.sql(
"""
|select count(1),actor from movies1 group by actor
|""".stripMargin)
.show()
}
}


