hdfs操作
首先我们要知道公司集群的部署情况,这个在我们之前的课程中是有所介绍的,每个集群都是存在操作机的
集群中的机器负责集群的运行但是操作集群我们需要提供一个客户端的机器op机器
1.op机器的配置
我们需要在op的机器上进行配置参数,将hdfs的配置文件原封不动的放入到op机器中一份,这样我们就可以使用op机器直接连接hdfs的集群了
#使用root用户解压hadoop到/usr/local下面
tar -zxvf /public/software/bigdata/hadoop-3.1.4.tar.gz -C /usr/local
# 进入op机器,并且创建hadoop用户
useradd hadoop
passwd hadoop
#输入密码,如123456
#删除原来的软连接
#使用root用户创建软连接
rm -rf /usr/local/hadoop
ln -s /usr/local/hadoop-3.1.4/ /usr/local/hadoop
#删除hadoop的配置文件,将配置好的配置文件放入配置文件夹中
rm -rf /usr/local/hadoop/etc/hadoop
tar -zxvf /public/config/hadoop_conf.tar.gz -C /usr/local/hadoop/etc/
# 修改hadoop文件夹的权限给hadoop用户使用
chown hadoop:hadoop -R /usr/local/hadoop-3.1.4/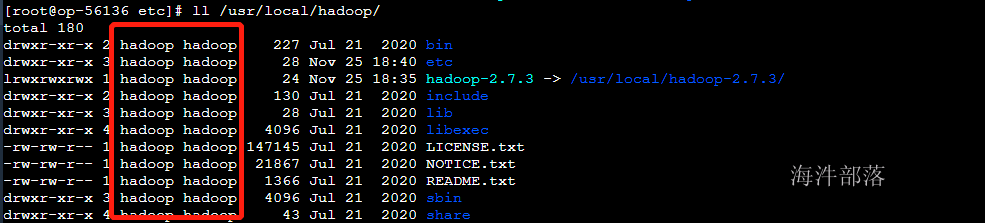
# 切换用户,配置环境变量
su - hadoop
vim ~/.bash_profile
#增加如下配置
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME=/usr/java/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
# source配置文件生效
source ~/.bash_profile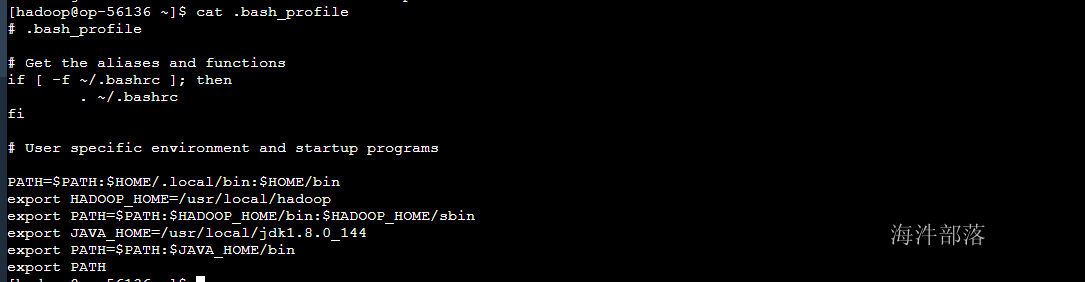
#检验是否配置成功
hadoop version
#查看java的版本
java -version
这个时候我们可以使用op机器操作hdfs的集群了
# 测试集群操作
hadoop fs -ls /
2.hdfs的使用命令
2.1 列出文件列表 ls
查看hdfs根目录
# 标准写法
hadoop fs -ls hdfs://ns1/
# 简写(推荐)
hadoop fs -ls /data
# -h:文件大小显示为最大单位,更加人性化
hadoop fs -ls -h /data
# -R:递归显示
hadoop fs -ls -R / 
2.2 上传文件/目录 put
从主机本地系统到集群HDFS系统。
1)上传新文件
#创建本地文件
echo 12345678 >> ~/a.txt
#标准写法:put 左面:是本地,右面是hdfs集群
hadoop fs -put ~/a.txt hdfs://ns1/
#简写:右面默认找hdfs (推荐)
hadoop fs -put ~/a.txt /
#当上传时要对文件进行重名
hadoop fs -put ~/a.txt /b.txt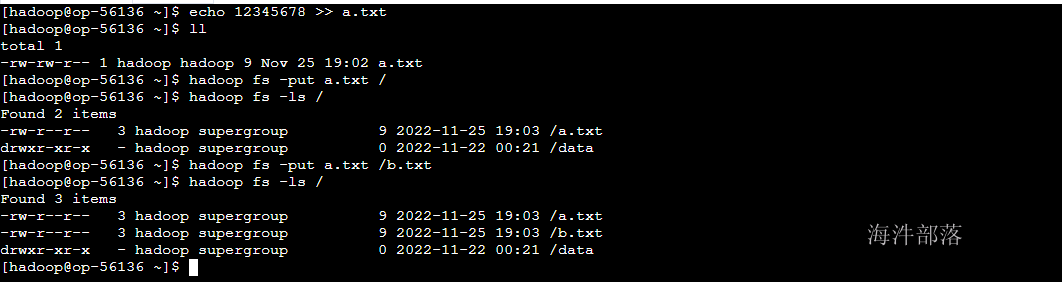
2)上传多个文件
#在本地创建多个文件
echo 'hello' >> b.txt
echo 'world' >> c.txt
#一次上传多个文件到HDFS路径
hadoop fs -put a.txt b.txt c.txt /data 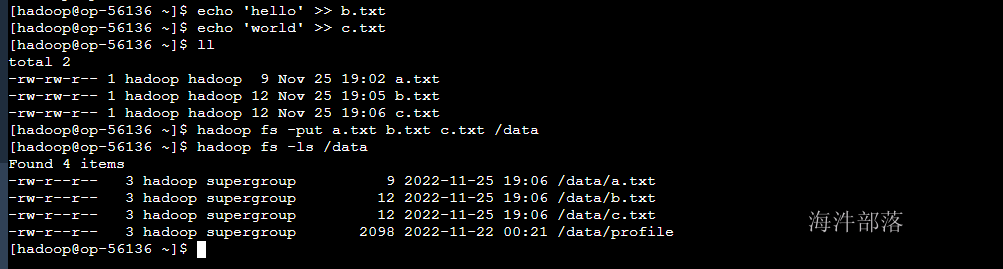
3)上传目录
#创建本地文件夹和文件夹中的文件
mkdir tmp
cd tmp
touch aa.txt
touch bb.txt
#上传并重命名目录
hadoop fs -put tmp / 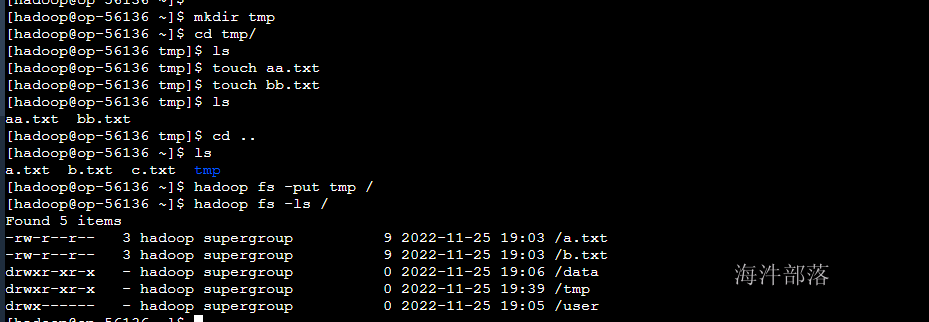
4)覆盖上传
#当上传时,hdfs存在同样的文件名时,会报文件已存在错误。
#可通过 -f 强制上传,并替换旧文件
hadoop fs -put -f a.txt /
2.3 下载文件/目录 get
从集群HDFS到本地文件系统,默认左面是hdfs,右面是linux本地
# 删除本地文件
rm -rf a.txt
#1)下载hdfs文件到本地目录
hadoop fs -get /a.txt ./
#2)下载hdfs文件到本地目录并重命名
hadoop fs -get /a.txt ./aaa.txt
2.4 拷贝文件/目录 cp
1)从本地到HDFS,同put,【此种方式推荐用put】
如果是本地文件,要以绝对路径表示,本地路径需要加file:
# 创建新的文件
touch dd.txt
# 上传本地文件使用file:开头
hadoop fs -cp file:/home/hadoop/dd.txt /
# 查看上传
hadoop fs -ls /
2)从HDFS到HDFS
# 简写
hadoop fs -cp /dd.txt /tmp
# 查询
hadoop fs -ls /tmp
2.5 移动文件 mv
#移动
hadoop fs -mv /b.txt /tmp
#查询
hadoop fs -ls /
2.6 删除文件/目录 rm
执行-rm 命令后,默认是把文件移动到 user/hadoop/.Trash/Current 下,会根据配置文件配置的清理周期定期清理。
#删除文件
hadoop fs -rm /a.txt
因为开启了垃圾箱,文件会直接放入到垃圾箱中,我们可以去查看删除的文件

#匹配模式删除所有文件
hadoop fs -ls /data
hadoop fs -rm /data/*.txt
3)递归删除全部文件和目录
#强制删除,并且递归删除文件夹中的内容
# rm只能删除文件
hadoop fs -ls /tmp
hadoop fs -rmr /tmp
hadoop fs -rm -r /tmp
4)删除之后不放到回收站
hadoop fs -rm -skipTrash /dd.txt
2.7 读取文件 cat
查看文件内容,如果文件超过一屏幕,那不建议用
hadoop fs -cat /data/profile
2.8 读取文件尾部 tail
查看尾部1K字节
hadoop fs -tail /data/profile 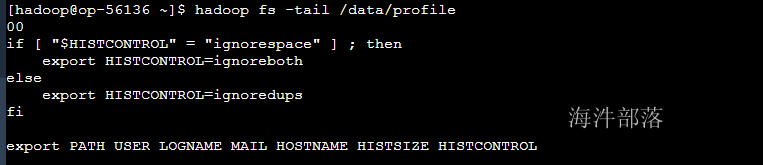
2.9 创建空文件 touchz
hadoop fs - touchz /aa.txt
2.10 追加写入文件 appendToFile
#本地创建文件 note.txt
touch note.txt
#写入hello
echo 'hello' >> note.txt
#本地创建文件 new.txt
touch new.txt
#写入world
echo 'world' >> new.txt
#将note.txt上传到hdfs中
hadoop fs -put note.txt /
#将new.txt的内容追加到node.txt中
hadoop fs -appendToFile new.txt /note.txt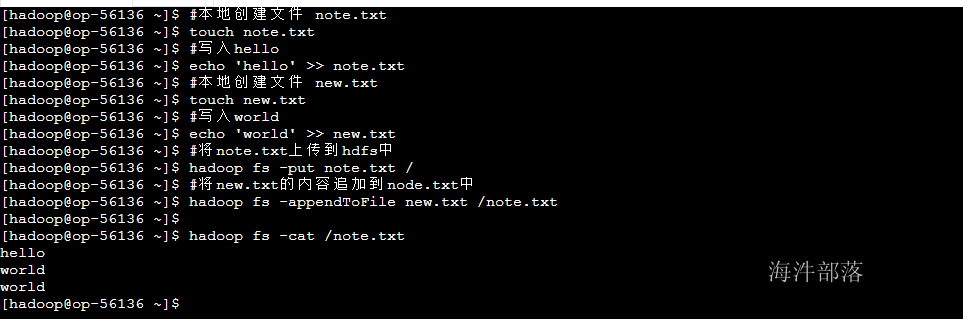
2.11 创建目录 mkdir
#可以同时创建多个目录
hadoop fs -mkdir /tmp1 /tmp2
#同时创建父级目录
hadoop fs -mkdir -p /dir1/dir2/dir3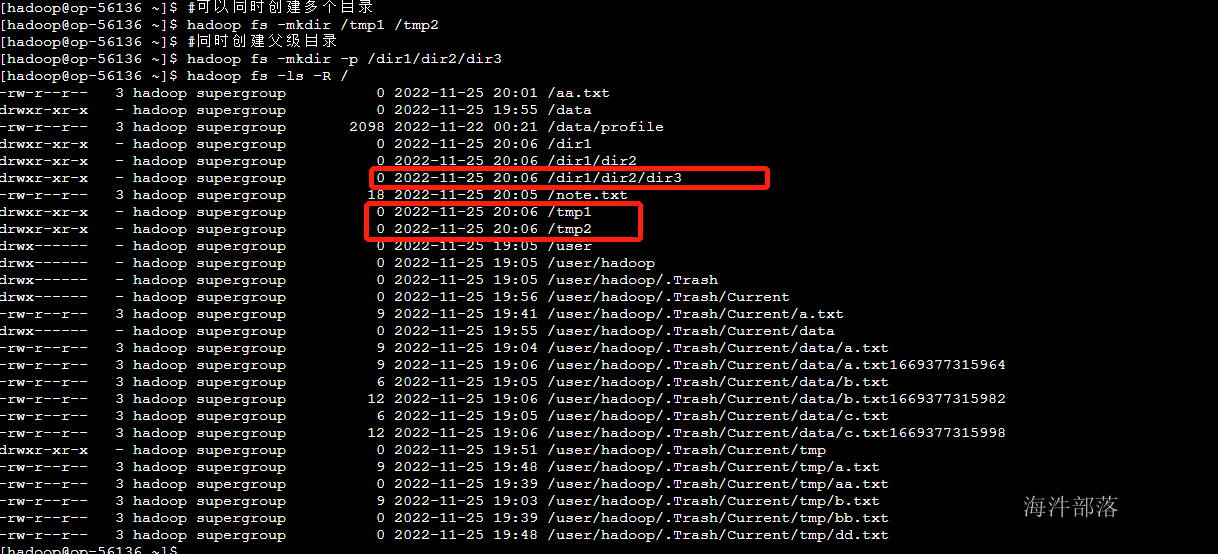
2.12 改变文件副本数 setrep

#-R 递归改变目录下所有文件的副本数。
#-w 等待副本数调整完毕后返回。可理解为加了这个参数就是阻塞式的了。
hadoop fs -setrep -R -w 2 /aa.txt

如果想修改默认备份数,修改配置hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
<description>文件复本数</description>
</property>2.12 获取逻辑空间文件/目录大小 du
#显示HDFS根目录中各文件和文件夹大小
hadoop fs - du /
#以最大单位显示HDFS根目录中各文件和文件夹大小
hadoop fs -du -h /
#仅显示HDFS根目录大小。即各文件和文件夹大小之和
hadoop fs -du -s -h /
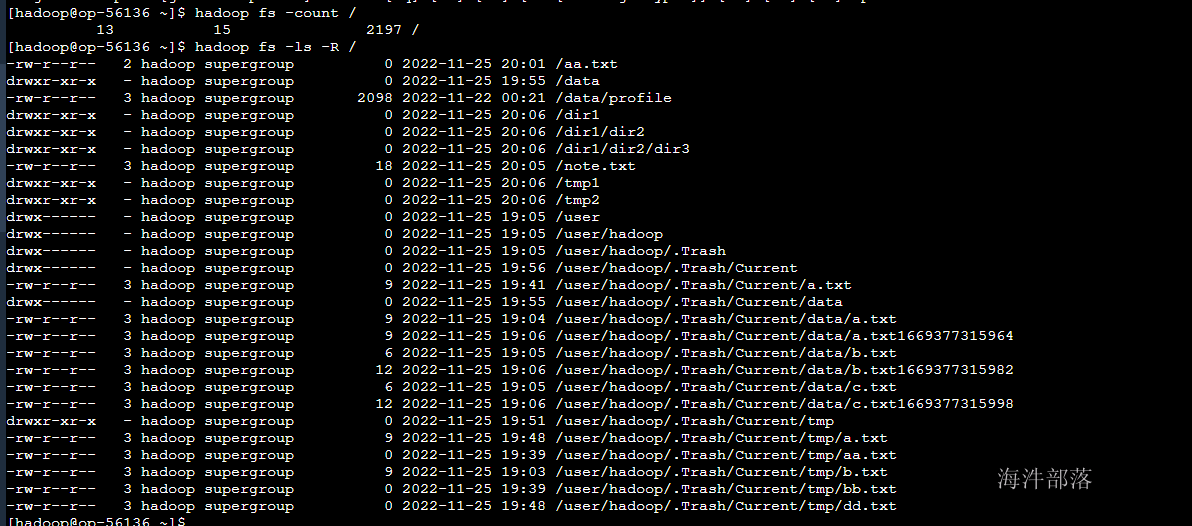
2.13 获取HDFS目录的物理空间信息 count
hadoop fs -count / #显示HDFS根目录在物理空间的信息查询结果:
第一个数值表示/下的目录的个数(包括其本身);
第二个数值表是当前目录下文件的个数;
第三个数值表示该目录下文件所占的空间大小,这个大小是不计算副本的个数的。
3.管理工具hadoop dfsadmin
hdfs dfsadmin
例如:hadoop dfsadmin -report
dfsadmin命令详解
1) -report:
查看文件系统的基本信息和统计信息。
2)-safemode :
安全模式命令。安全模式是NameNode的一种状态,在这种状态下,NameNode不接受对元数据的更改(只读);不复制或删除块。NameNode在启动时自动进入安全模式,当配置块的最小百分数满足最小副本数的条件时,会自动离开安全模式。enter是进入,leave是离开。
#进入安全模式
hdfs dfsadmin -safemode enter
#离开安全模式
hdfs dfsadmin -safemode leave
#获取安全模式信息
hdfs dfsadmin -safemode get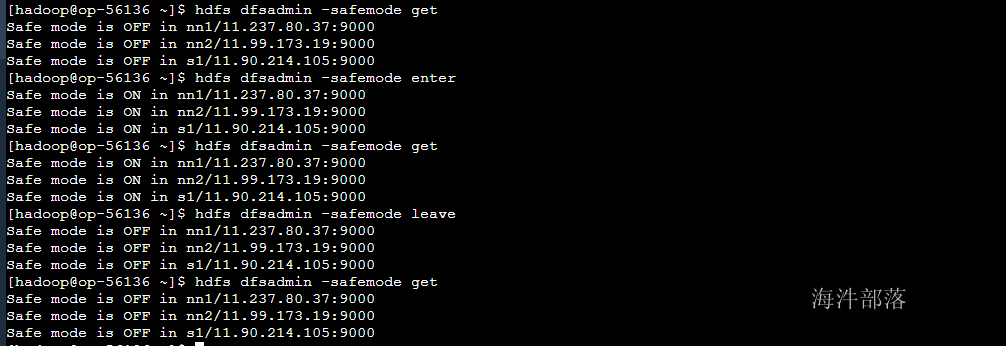
在安全模式情况下不允许任何hdfs的修改操作的

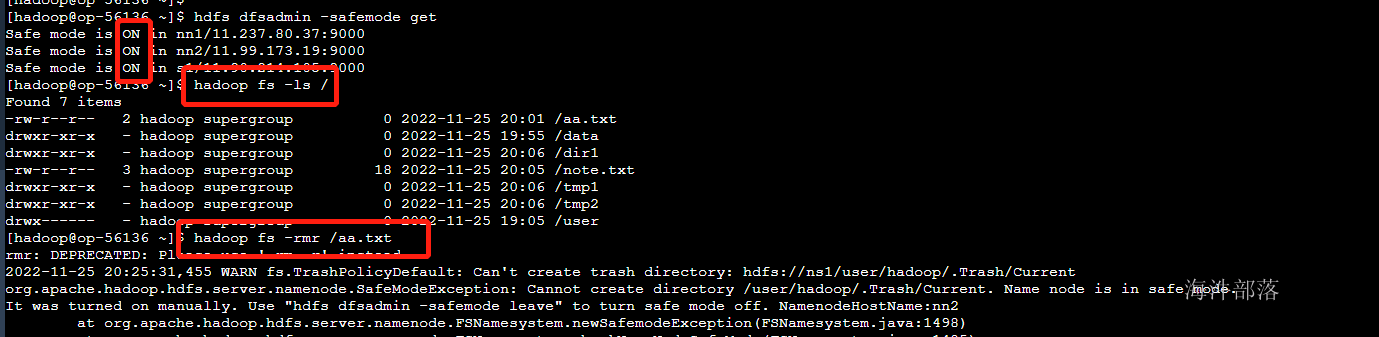
安全模式下可以查询元数据信息,但是不能对文件做任何的修改
4.动态增加datanode节点
hdfs是节点存储数据的空间是有限的,如果存储不够那么我们可以动态增加datanode的机器节点
增加节点的第一步我们需要启动一个新的linux虚拟机
选择新的节点进行连接
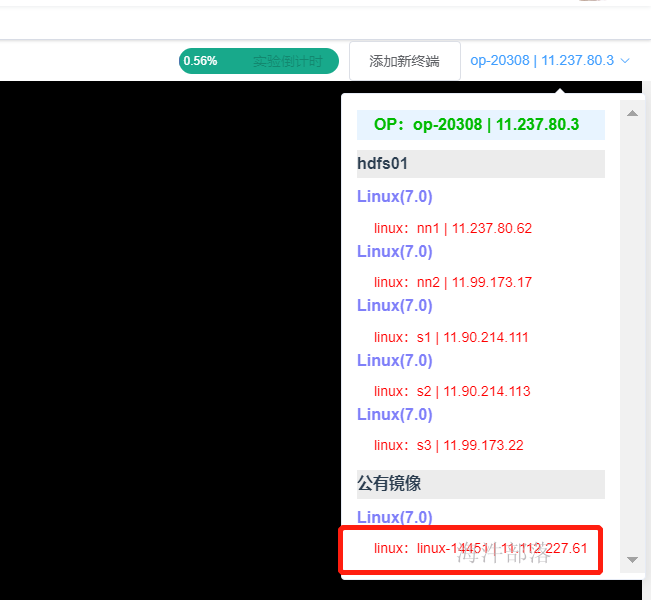
增加hadoop用户并且设置密码
useradd hadoop
passwd hadooop
#密码输入123456安装java环境
rpm -ivh /public/software/java/jdk-8u144-linux-x64.rpm解压hadoop并且修改hadoop的文件权限是hadoop用户
tar -zxvf /public/software/bigdata/hadoop-3.1.4.tar.gz -C /usr/local/
chown hadoop:hadoop -R /usr/local/hadoop-3.1.4创建hadoop软连接
ln -s /usr/local/hadoop-3.1.4/ /usr/local/hadoop修改环境变量
#增加如下环境信息到 /etc/profile中
vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME=/usr/java/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
#让环境变量生效
source /etc/profile配置完毕检验配置效果
hadoop version
java -version
创建/data文件夹,并且修改权限是hadoop用户
mkdir /data
chown hadoop:hadoop /data
解压配置文件到hadoop的配置目录中
# 删除原带配置文件
rm -rf /usr/local/hadoop/etc/hadoop/
# 解压新的配置文件到hadoop配置
tar -zxvf /public/config/hadoop_conf.tar.gz -C /usr/local/hadoop/etc/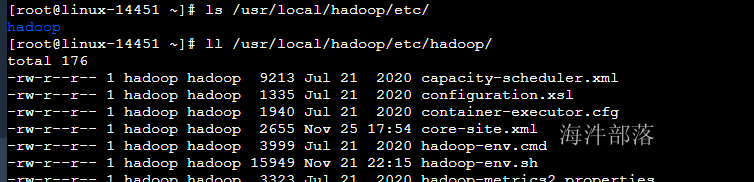
配置从节点host和hostname
#修改新增节点的hostname和host变为s4
vim /etc/hosts
vim /etc/hostname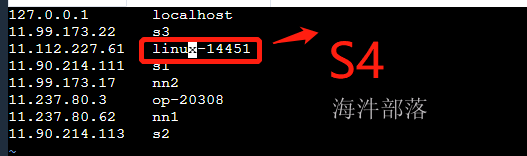

修改其他节点的hosts映射,增加s4
vim /etc/hosts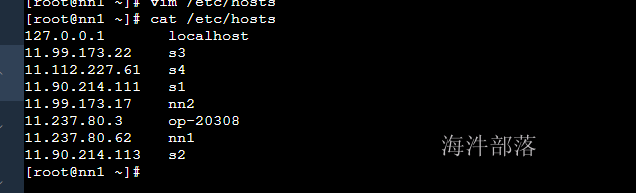
给s4节点的hadoop用户配置免密登录信息
#登录到 nn1节点
scp -r ~/.ssh s4:/home/hadoop
#输入用户名和密码进行操作在每一个机器的workers文件增加一个s4的信息
#所有节点执行
echo s4 >> /usr/local/hadoop/etc/hadoop/workers 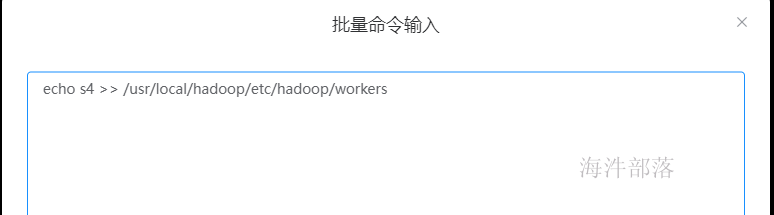
新增的s4节点启动datanode
#切换hadoop用户启动datanode
su - hadoop
hdfs --daemon start datanode
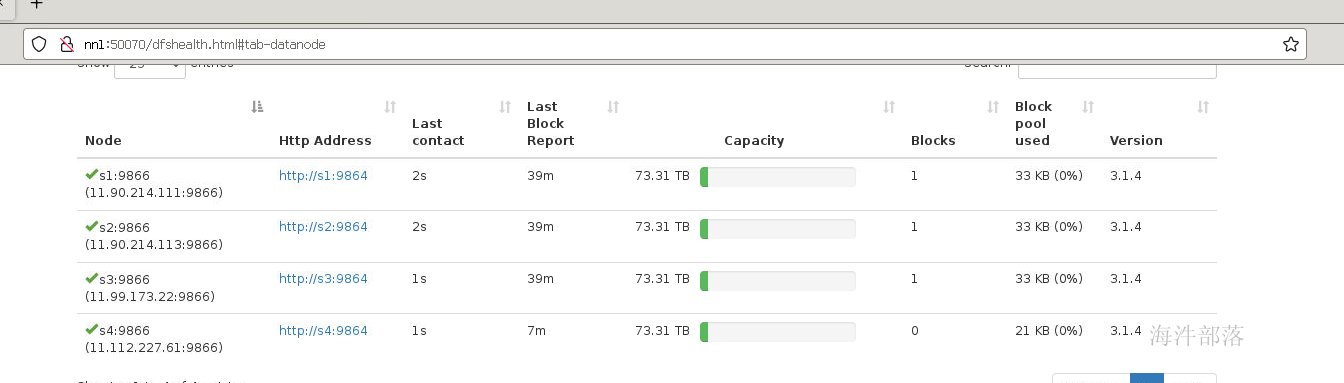
执行刷新节点命令
#切换到nn1机器
hdfs dfsadmin -refreshNodes
可以看到s4节点已经存在了
5.动态删除节点
为了保证能够识别新创建的节点s4我们关闭环境,重新启动实验
先生成镜像然后重新启动
动态删除节点是需要修改hdfs-site.xml中的信息的
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/excludes</value>
</property>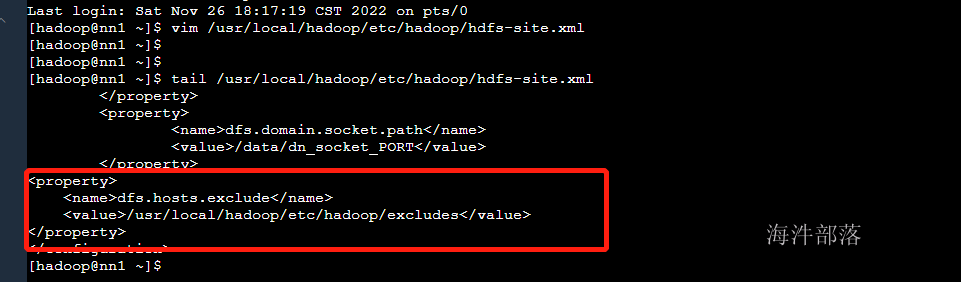
增加配置文件
echo 's4' >> /usr/local/hadoop/etc/hadoop/excludes
将配置文件分发到各个机器节点中
scp_all.sh /usr/local/hadoop/etc/hadoop/excludes /usr/local/hadoop/etc/hadoop/excludes
scp_all.sh /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hadoop/etc/hadoop/为了演示效果,我们将zookeeper的包上传到hdfs中
#在s4节点上面上传
su - hadoop
hadoop fs -put /public/software/bigdata/zookeeper-3.4.8.tar.gz /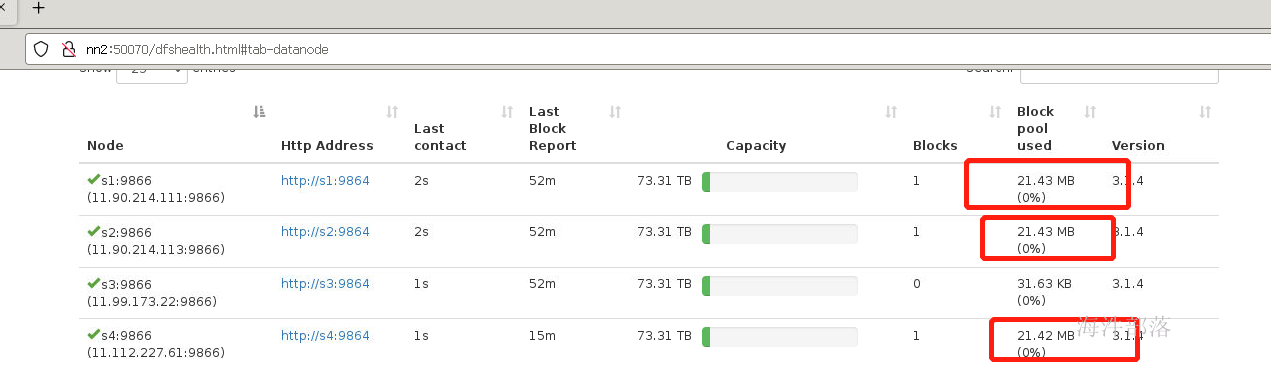
这个时候s1 s2 s4节点上面是存在数据的,我们将s4节点动态删除,那么s4的数据会自动备份到s3节点
#在nn1节点输入
hdfs dfsadmin -refreshNodes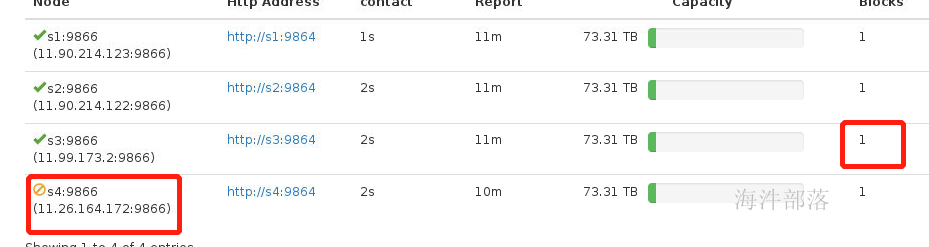
后续我们删除 workers中的s4节点,那么下次就不会启动它了

6.hdfs的负载均衡的实现
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,例如:当集群内新增、删除节点,或者某个节点机器内硬盘存储达到饱和值。当数据不平衡时,Map任务可能会分配到没有存储数据的机器,这将导致网络带宽的消耗,也无法很好的进行本地计算。
当HDFS负载不均衡时,需要对HDFS进行数据的负载均衡调整,即对各节点机器上数据的存储分布进行调整。从而,让数据均匀的分布在各个DataNode上,均衡IO性能,防止热点的发生。进行数据的负载均衡调整,必须要满足如下原则:
- 数据平衡不能导致数据块减少,数据块备份丢失
- 管理员可以中止数据平衡进程
- 每次移动的数据量以及占用的网络资源,必须是可控的
- 数据均衡过程,不能影响namenode的正常工作
在Hadoop中,包含一个 start-balancer.sh 脚本,通过运行这个工具,启动HDFS数据均衡服务。该工具可以做到热插拔,即无须重启计算机和 Hadoop 服务。
启动命令为:‘start-balancer.sh –threshold`
影响Balancer的参数:
- -threshold
- 默认设置:10,参数取值范围:1-100
- 参数含义:datanode间磁盘使用率相差阈值。理论上,该参数设置的越小,整个集群就越平衡。
#启动数据均衡,默认阈值为 10%
start-balancer.sh
#启动数据均衡,阈值 5%
start-balancer.sh -threshold 5
#停止数据均衡
stop-balancer.sh<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>104857600</value>
<description>根据每秒字节数指定每个数据节点可用于平衡的最大带宽,设置为100M</description>
</property>为了演示效果,我们先长传文件
# 关闭集群
stop-dfs.sh
# 重新启动集群
start-dfs.sh
# 在集群中上传hadoop的安装包
hdfs dfs -put /public/software/bigdata/hadoop-3.1.4.tar.gz /
# 复制多分文件
hdfs dfs -cp /hadoop-3.1.4.tar.gz /hadoop-3.1.4.tar.gz1
hdfs dfs -cp /hadoop-3.1.4.tar.gz /hadoop-3.1.4.tar.gz2
hdfs dfs -cp /hadoop-3.1.4.tar.gz /hadoop-3.1.4.tar.gz3
hdfs dfs -cp /hadoop-3.1.4.tar.gz /hadoop-3.1.4.tar.gz4
hdfs dfs -cp /hadoop-3.1.4.tar.gz /hadoop-3.1.4.tar.gz5
hdfs dfs -cp /hadoop-3.1.4.tar.gz /hadoop-3.1.4.tar.gz6
hdfs dfs -cp /hadoop-3.1.4.tar.gz /hadoop-3.1.4.tar.gz7
hdfs dfs -cp /hadoop-3.1.4.tar.gz /hadoop-3.1.4.tar.gz8
hdfs dfs -cp /hadoop-3.1.4.tar.gz /hadoop-3.1.4.tar.gz9
hdfs dfs -cp /hadoop-3.1.4.tar.gz /hadoop-3.1.4.tar.gz10
#然后赋值翻倍数据
hdfs dfs -mkdir /dir1
hdfs dfs -cp /hadoop* /dir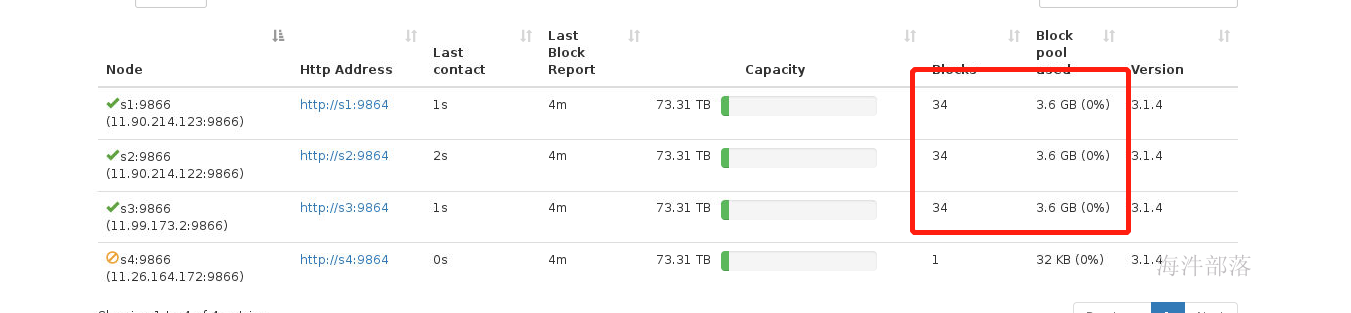
现在将第四台机器加入进来
#vim /usr/local/hadoop/etc/hadoop/excludes
删除ip
#在workers中增加s4节点
#分发配置文件
scp_all.sh /usr/local/hadoop/etc/hadoop/excludes /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/workers /usr/local/hadoop/etc/hadoop/
#刷新集群
hdfs dfsadmin -refreshNodes
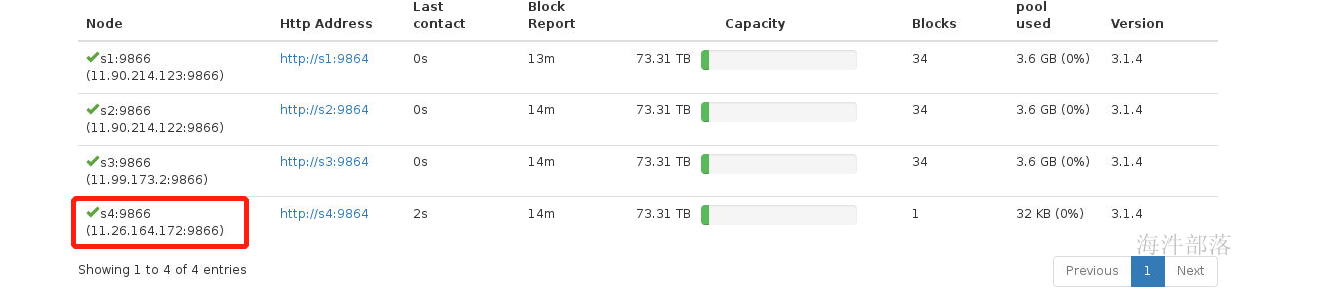
s4节点恢复正常
这个时候s1 s2 s3压力过大 我们让s4分摊压力
#首先为了保证数据足够大到hdfs不均衡我们修改hdfs-site.xml中的配置
<property>
<name>dfs.datanode.du.reserved</name>
<value>80264348827648</value>
<description>每个存储卷保留用作其他用途的磁盘大小</description>
</property>
#每个节点预留内存是73T,剩余300多G
#执行balance功能
start-balancer.sh -threshold 1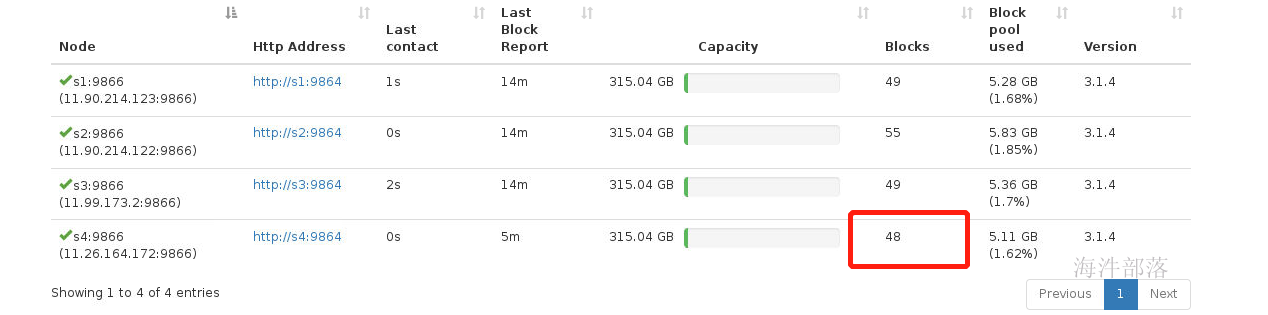
可以看到节点数据变多了,数据变得更加均衡了
7.元数据解析
在之前的课程中我们知道了元数据是hdfs的数据保存文件信息,这个数据会存在到内存中一份,并且防止内存在宕机或者关机的时候消失,那么也会存在数据到磁盘中一份,磁盘中的文件包含fsimage和edits日志文件
fsimage中存放的信息是整个hdfs中的数据的所有描述,比如文件的存储位置和inode的节点信息
edits日志文件中存储的数据是每一次的修改操作记录
namenode在运行的时候会在内存中存在一个全量的元数据信息,其中存储的数据的一个block在内存中占有150B的大小存储
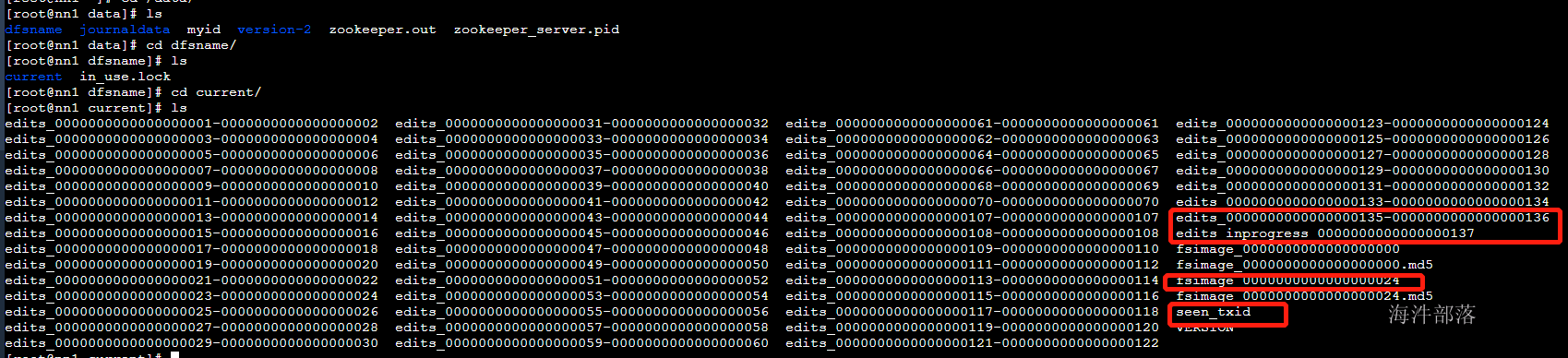
其中seen_txid记录的是最后一次修改的操作记录
在启动hdfs的时候namenode会自己合并fsimage+edits放入到内存中
我们可以查看元数据信息

hdfs中给我们提供了如下两个查看edits日志文件和fsimage的数据的工具
#现在我们上传/etc/passwd到hdfs的 /data目录中
hdfs dfs -put /etc/passwd /data
# 然后我们查看操作日志
# hdfs oev 解析操作日志文件并且输入到相应的目录中 -i 输入 -o 输出 -p 默认就是xml
hdfs oev -i edits_0000000000000000138-0000000000000000145 -o ~/edits.txt<RECORD>
<OPCODE>OP_CLOSE</OPCODE>
<DATA>
<TXID>143</TXID>
<LENGTH>0</LENGTH>
<INODEID>0</INODEID>
<PATH>/data/passwd._COPYING_</PATH>
<REPLICATION>3</REPLICATION>
<MTIME>1669538591721</MTIME>
<ATIME>1669538584064</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME/>
<CLIENT_MACHINE/>
<OVERWRITE>false</OVERWRITE>
<BLOCK>
<BLOCK_ID>1073741826</BLOCK_ID>
<NUM_BYTES>815</NUM_BYTES>
<GENSTAMP>1002</GENSTAMP>
</BLOCK>
<PERMISSION_STATUS>
<USERNAME>hadoop</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>420</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_RENAME_OLD</OPCODE>
<DATA>
<TXID>144</TXID>
<LENGTH>0</LENGTH>
<SRC>/data/passwd._COPYING_</SRC>
<DST>/data/passwd</DST>
<TIMESTAMP>1669538591733</TIMESTAMP>
<RPC_CLIENTID>7d0e7cc4-4fed-4cce-a55f-5a439ff91d33</RPC_CLIENTID>
<RPC_CALLID>8</RPC_CALLID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_END_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>145</TXID>
</DATA>
</RECORD>可以看到hadoop用户上传了passwd数据
查看fsimage中的元数据
#首先我们手动触发合并元数据
hdfs dfsadmin -saveNamespace
#然后将fsimage数据导出到文本中
hdfs oiv -i fsimage_0000000000000000024 -o ~/fs.txt -p xml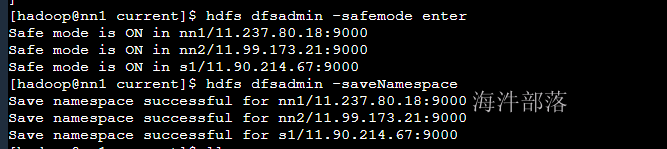
然后将数据放入到格式化的工具中进行格式化显示
# 查看元数据信息
cat ~/fs.txt<INodeSection>
<lastInodeId>16388</lastInodeId>
<numInodes>4</numInodes>
<inode>
<id>16385</id>
<type>DIRECTORY</type>
<name></name>
<mtime>1669047640777</mtime>
<permission>hadoop:supergroup:0755</permission>
<nsquota>9223372036854775807</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16386</id>
<type>DIRECTORY</type>
<name>data</name>
<mtime>1669538591733</mtime>
<permission>hadoop:supergroup:0755</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16387</id>
<type>FILE</type>
<name>profile</name>
<replication>3</replication>
<mtime>1669047669107</mtime>
<atime>1669540329171</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>hadoop:supergroup:0644</permission>
<blocks>
<block>
<id>1073741825</id>
<genstamp>1001</genstamp>
<numBytes>2098</numBytes>
</block>
</blocks>
<storagePolicyId>0</storagePolicyId>
</inode>
<inode>
<id>16388</id>
<type>FILE</type>
<name>passwd</name>
<replication>3</replication>
<mtime>1669538591721</mtime>
<atime>1669538584064</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>hadoop:supergroup:0644</permission>
<blocks>
<block>
<id>1073741826</id>
<genstamp>1002</genstamp>
<numBytes>815</numBytes>
</block>
</blocks>
<storagePolicyId>0</storagePolicyId>
</inode>
</INodeSection>
<INodeReferenceSection></INodeReferenceSection>
<SnapshotSection>
<snapshotCounter>0</snapshotCounter>
<numSnapshots>0</numSnapshots>
</SnapshotSection>
<INodeDirectorySection>
<directory>
<parent>16385</parent>
<child>16386</child>
</directory>
<directory>
<parent>16386</parent>
<child>16388</child>
<child>16387</child>
</directory>
</INodeDirectorySection>
可以看到inode中的元数据信息和hdfs中的数据一样
其中hdfs的元数据信息中并没有包含块的信息,这些信息要在datanode启动后进行上报的
在namenode下次合并的元数据的时候根据seen_id的值和上次合并的元数据的fsimage的编号进行判断
还有那些edits日志文件没有合并
元数据的合并触发条件
1.namenode启动的时候
2.手动直接触发
3.到达一定条件会触发自动合并过程
#自动合并的配置信息如下
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property >
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property>- 每隔一小时执行一次(定时执行)
- 一分钟检查一次操作次数,当操作次数达到1百万时,执行一次(定量执行)
8.hdfs的api读写文件
打开远程桌面,打开idea创建maven项目
引入配置文件
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>引入hdfs的配置信息到项目的src/main/resources中
打开目录然后引入/public/config中的内容,然后解压
最后我们只要这两个配置文件
打开我们的项目大家可以发现配置文件已经存在了
1.读取hdfs中的文件
package com.hainiu.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.util.Scanner;
public class TestHdfs {
public static void main(String[] args) throws Exception{
//创建链接
FileSystem fs = FileSystem.get(new Configuration());
//打开文件的读取流
FSDataInputStream in = fs.open(new Path("/data/profile"));
//使用scanner的扫描器,读取每一行的内容
Scanner sc = new Scanner(in);
while(sc.hasNext()){
String line = sc.nextLine();
System.out.println(line);
}
//关闭流
in.close();
//关闭链接
sc.close();
}
}2.创建文件,并且写入内容
#创建一个写入文件的目录
#在nn1节点 使用hadoop用户
hadoop fs -mkdir /test
hadoop fs -chmod 777 /testpackage com.hainiu.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.PrintWriter;
import java.util.Scanner;
public class TestHdfs {
public static void main(String[] args) throws Exception{
//创建链接
FileSystem fs = FileSystem.get(new Configuration());
//创建文件,并且打开流
FSDataOutputStream out = fs.create(new Path("/test/test.txt"));
//创建写出工具
PrintWriter pw = new PrintWriter(out, true);
for(int i=0;i<100;i++){
pw.write("this is hainiu");
}
pw.close();
out.close();
fs.close();
}
}3.追加写入文件
package com.hainiu.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.PrintWriter;
import java.util.Scanner;
public class TestHdfs {
public static void main(String[] args) throws Exception{
//创建链接
FileSystem fs = FileSystem.get(new Configuration());
//创建文件,并且打开流
FSDataOutputStream out = fs.append(new Path("/test/test.txt"));
//创建写出工具
PrintWriter pw = new PrintWriter(out, true);
for(int i=0;i<100;i++){
pw.write("this is hainiu");
}
pw.close();
out.close();
fs.close();
}
}4.查询子文件
package com.hainiu.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
public class TestHdfs {
public static void main(String[] args) throws Exception{
FileSystem fs = FileSystem.get(new Configuration());
FileStatus[] list = fs.listStatus(new Path("/"));
for (FileStatus s : list) {
System.out.println(s.getPath());
}
fs.close();
}
}9.hdfs的读写数据的流程
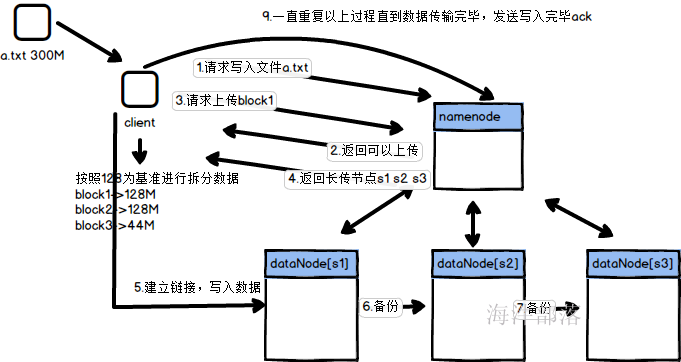
1.上传文件,客户端先进行文件的切分
2.请求namenode上传数据
3.namenode返回确认消息,是否可以上传
4.请求上传第一个块
5.namenode返回可以上传的datanode列表
6.找到其中一个datanode进行数据发送
7.datanode相互之间发送做数据的备份
8.不断重复以上过程
9.当全部数据都写入完毕发送ack给namenode节点
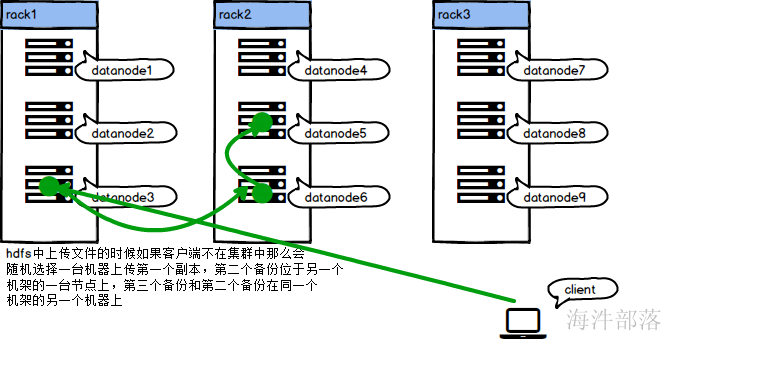
客户端在集群中的时候
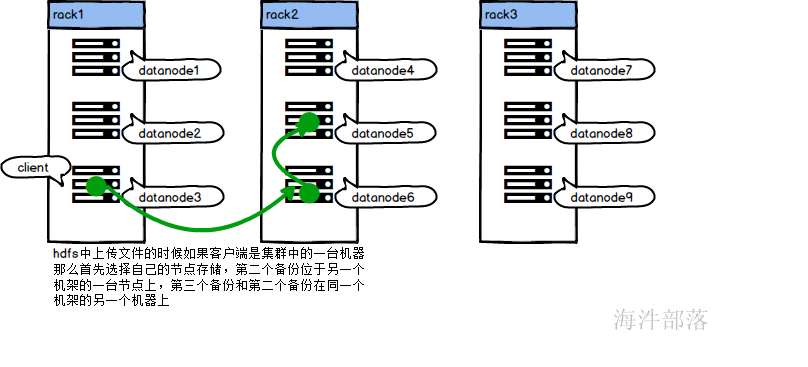
客户端不在集群中的时候
10.机架感知策略
那么我们怎么确定机器是否在一个机架上呢
默认情况下,Hadoop机架感知是没有启用的,需要在NameNode机器的hadoop-site.xml里配置一个选项,例如:
<property>
<name>topology.script.file.name</name>
<value>tp.py</value>
</property>其中:
这个配置选项的 value 指定为一个可执行程序,通常为一个脚本,该脚本接受一个参数,输出一个值。
接受的参数通常为 datanode 机器的 ip 地址,而输出的值通常为该ip地址对应的 datanode 所在的rackID,例如”/rack1”。
Namenode 启动时,会判断该配置选项是否为空,如果非空,则表示已经启用机架感知的配置,此时 namenode 会根据配置寻找该脚本,并在接收到每一个 datanode 的 heartbeat 时,将该 datanode 的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode 所属的机架,保存到内存的一个map中。
至于脚本的编写,就需要将真实的网络拓朴和机架信息了解清楚后,通过该脚本能够将机器的ip地址正确的映射到相应的机架上去。
当没有配置机架信息时,所有的datanode,hadoop都默认在同一个名为 “/default-rack”机架下。
# 编辑to.py文件,因为官网没有指出到底是根据ip还是hostname进行判断机架
# 所以我们都配置 如下在tp.py中
#!/usr/bin/python
#-*-coding:UTF-8 -*-
import sys
rack = {
"nn1":"hainiu_rack",
"nn2":"hainiu_rack",
"s1":"hainiu_rack",
"s2":"hainiu_rack",
"s3":"hainiu_rack",
"11.99.173.32":"hainiu_rack",
"11.90.214.112":"hainiu_rack",
"11.237.80.15":"hainiu_rack",
"11.90.214.71":"hainiu_rack",
"11.99.173.29":"hainiu_rack"
}
if __name__=="__main__":
print "/" + rack.get(sys.argv[1],"rack0")以上的内容根据/etc/hosts中的内容配置
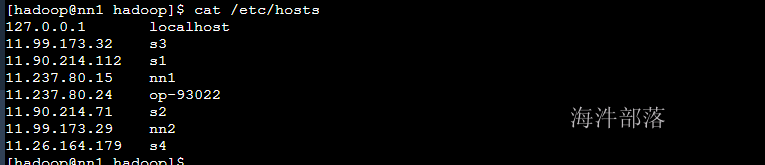
这个时候在集群需要得到机器的远近的时候就可以通过传入ip或者hostname进行判断
#输入命令打印机架感知
hdfs dfsadmin -printTopology
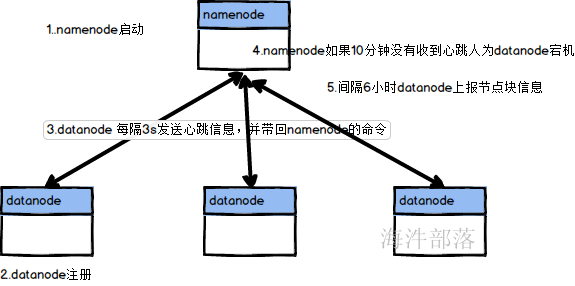
11.datanode的运行机制
首先我们找到datanode存储数据的位置
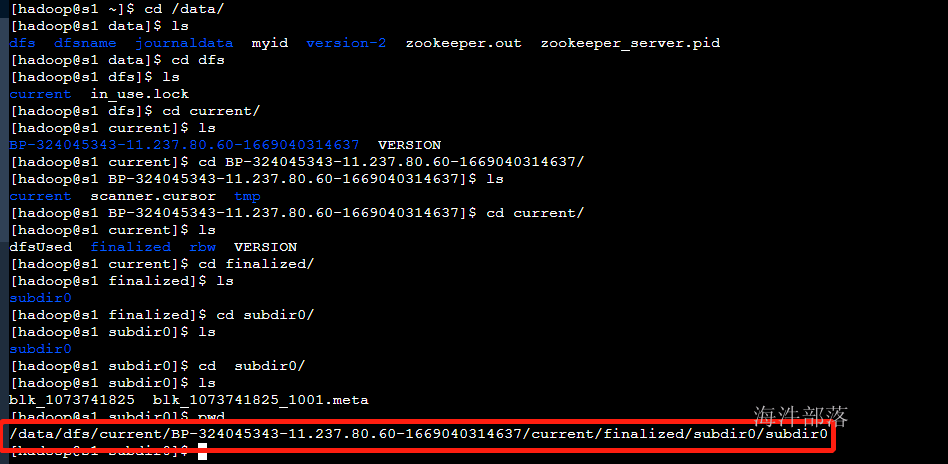
路径是比较深的
那么我们会看到在存储数据的时候,存在两个文件
#存储文件
blk_1073741825
#这个blk的信息[大小 创建时间 校验和]
blk_1073741825_1001.meta运行机制
datanode是怎么保证数据完整性的呢?
如上面所说datanode中存储的数据是有校验和数据的,datanode在读取block信息的时候首先要对block的数据做加密,和原带的meta中的校验和进行比对,得出数据的完整性

