hdfs的原理和安装
1.hdfs的介绍
hadoop的三个重要组成部分
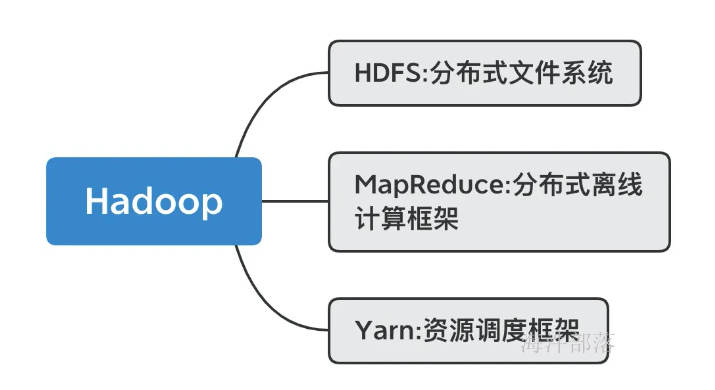
本篇课件主要针对于hdfs进行讲解
1.1技术背景:
话说远古时期,技术发展迅速,各大派别争先恐后发展,人类步入了it时代,人们开始知道什么是电脑了,但是电脑的性能不需多言,并且磁盘的存储能力垃圾到极致,从而人类对于存储有了更进一步的认知和需要

随着技术的发展磁盘越来越小,存储越来越快,性能越来越高,但是铁杵也终归低档不住这千军万马的磨练

天道轮回,苍天饶过谁,它炸了,炸的那么彻底!!!!

公司黄了,苦心经营多年的社团一时间烟消云散,员工流离失所,到底是造化弄人还是命该如此

1.2 磁盘阵列
鲁迅说过:一切杀不死你的,都会让你变得更强!!!

人们开始探索之旅,磁盘阵列应运而生
在单机时代,如果把数据一块磁盘一块磁盘的写,有如下问题:
1)单块磁盘写,磁盘读写速度上不去,读写慢;
2)数据写入单块磁盘,一旦磁盘故障导致数据丢失;
在这种情况下,RAID技术就应运而生了。
RAID ( Redundant Array of Independent Disks )即独立磁盘冗余阵列,简称为「磁盘阵列」,其实就是用多个独立的磁盘组成在一起形成一个大的磁盘系统,从而实现比单块磁盘更好的存储性能和更高的可靠性。
根据 RAID 算法的不同,RAID 有很多种。下面主要介绍 RAID0、RAID1、RAID10
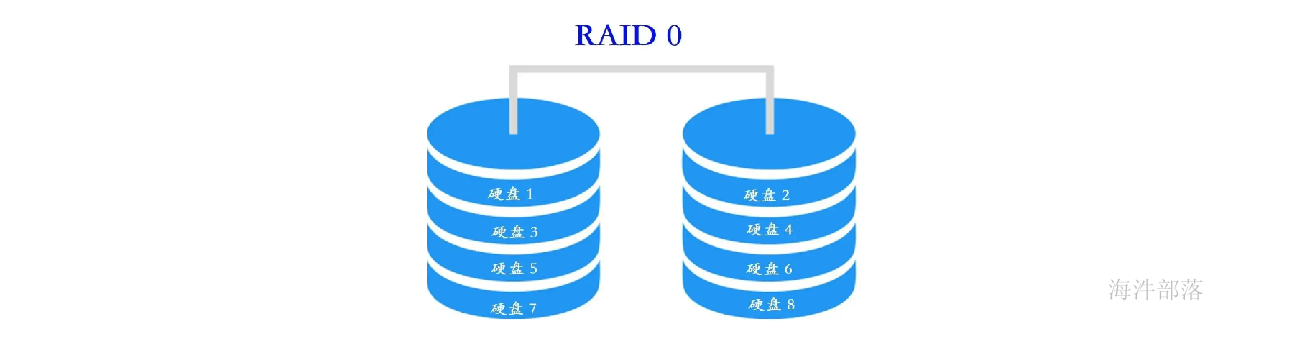
1.2.1RAID0
RAID0 是一种非常简单的的方式,它将多块磁盘组合在一起形成一个大容量的存储。
假设阵列中有N块磁盘,当写数据时,会将数据分为N份,然后分别写入N块 磁盘中。因此,RAID0将提供非常优秀的读写性能。
优点:
并行写入读取快,空间利用率高。
如果你要读取/写入 2G 的数据,在普通硬盘上,要以单盘的速度读取/写入 2G 的数据。
如果在 4 盘 RAID0 阵列中,每个盘只需读取/写入 500MB 的数据,四个盘可以并行读取/写入,因此理论的读写速度将是单块硬盘的4倍。
缺点:
只要阵列中有一块硬盘坏掉,由于这块硬盘保存着所有数据(每个文件)的某一部分,因此所有数据都将无法读取,整个阵列中的数据将宣告报废。
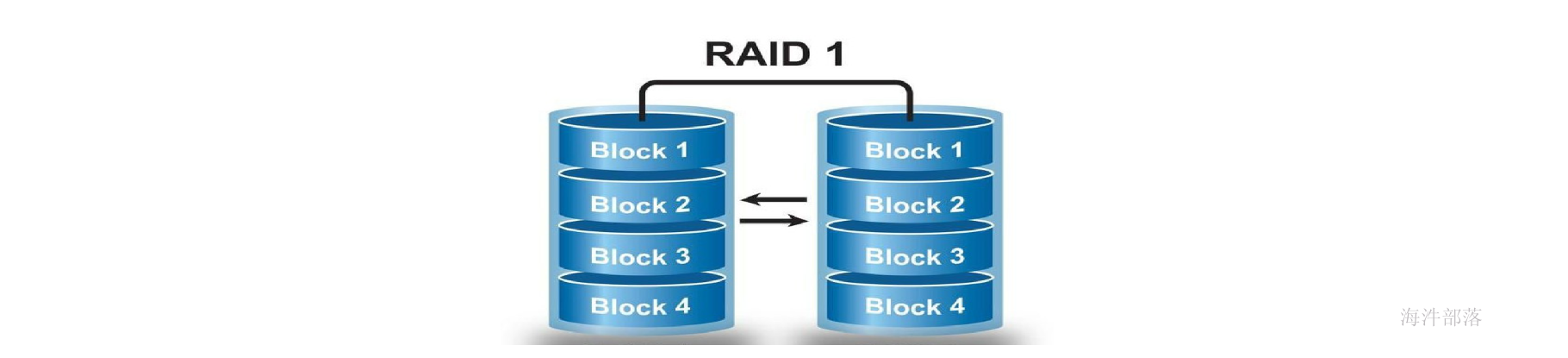
1.2.2 RAID1
RAID1 是磁盘阵列中单位成本最高的一种方式。因为它的原理是在往磁盘写数据的时候,将同一份数据无差别的写两份到磁盘,分别写到工作磁盘和镜像磁盘,那么它的实际空间使用率只有50%了,两块磁盘当做一块用,这是一种比较昂贵的方案。
优点:
数据写入两个磁盘,通过冗余存储实现容错。
缺点:
空间利用率低,读写速度慢。
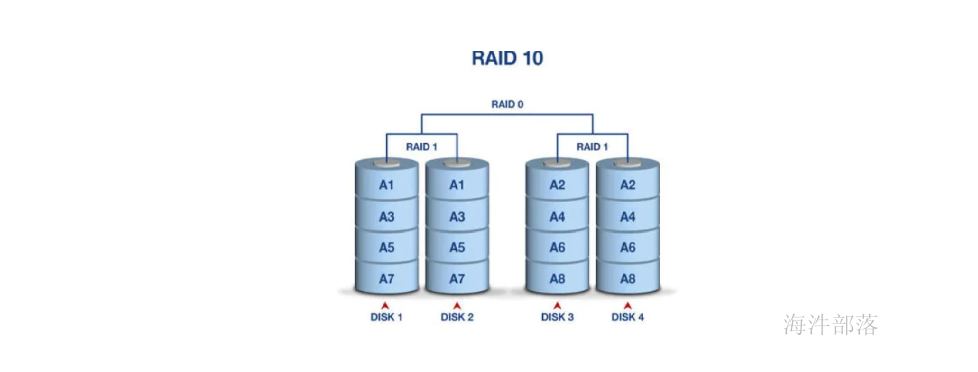
1.2.3 RAID10
RAID10其实就是RAID1与RAID0的一个合体。
先将磁盘阵列组成 RAID1, 再将多个RAID1 组成 RAID0。
读写数据时,可以将数据分N块,并行写入,而且每块数据都有备份。
这样既可以通过冗余存储容错,也可以提高读写的效率。
2.hdfs的介绍
软件raid
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统,用来解决存储问题。
HDFS 可以使用低成本的硬件来搭建。
HDFS 可以对海量的数据进行分布式存储。
HDFS 实现软件RAID10。
2.1 hdfs中数据存储的分析
2.1.1数据的备份
首先我们应该知道hdfs的存储是基于RAID的方式实现出来的,那么它充分的理解了鸡蛋不能放入到一个篮子中
因为一个篮子太小了,我们是集群的

其次我们不能一个鸡蛋只放一次,这样稳定性不高,因为可能出现单节点损毁问题
所以分布式存储的稳定性的保证一定要是多副本的

现在已经保证了数据的稳定性,但是我们这么存储是有问题的
2.1.2 数据的拆分存储
我们都知道hadoop的三个组成部分比较重要的还有mapreduce的计算框架,那么我们看一下数据的计算过程

因为计算也是分布式的,那么如果你的数据放的是一个整体,那么只有一个机器在干活。其他机器都在闲着,并且一个机器的处理能力是有限的,并且读取数据的压力都给在一个hdfs的机器上面是效率非常低下的

2.1.3 hdfs存储数据的方案
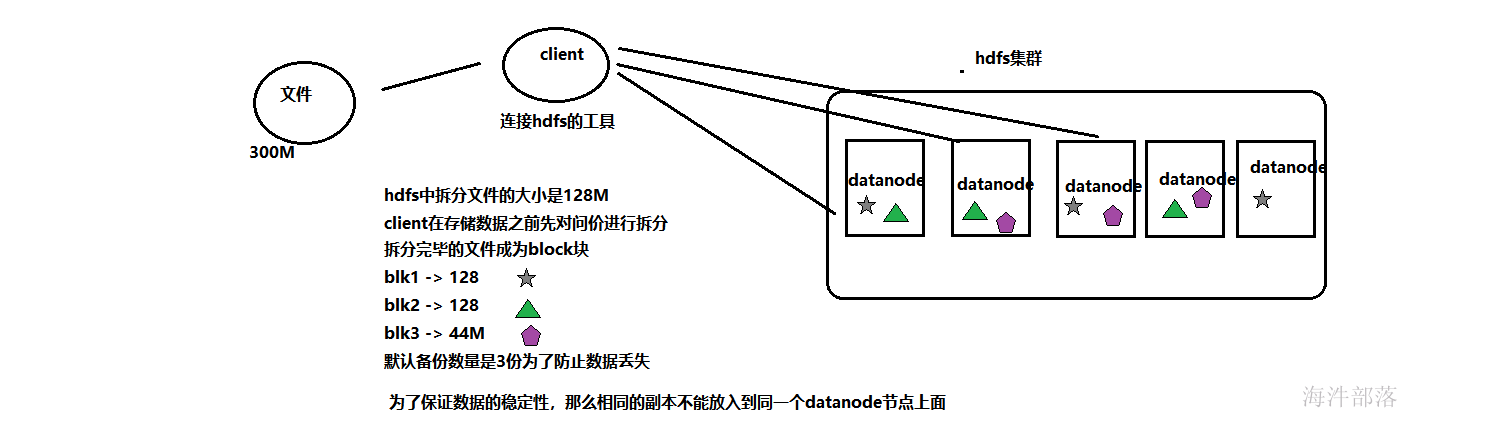
存储完毕的数据我们需要读取数据,下次想从hdfs中读取一个数据的整体,只需要在任意存放数据的节点上面找到不同的block返回,然后组装在一起就可以拿到我们想要的文件,并且多个机器分摊压力,这样速度和稳定性都能保证

在公司的正常集群中,节点非常多,存储的位置相对分散,没有办法指定点位数据的存放位置,并且存储数据的时候要存哪里,哪个机器的存储性能比较低下,哪个机器出现故障,都没有办法进行监控,所以整个集群需要一个主节点,namenode主节点诞生了
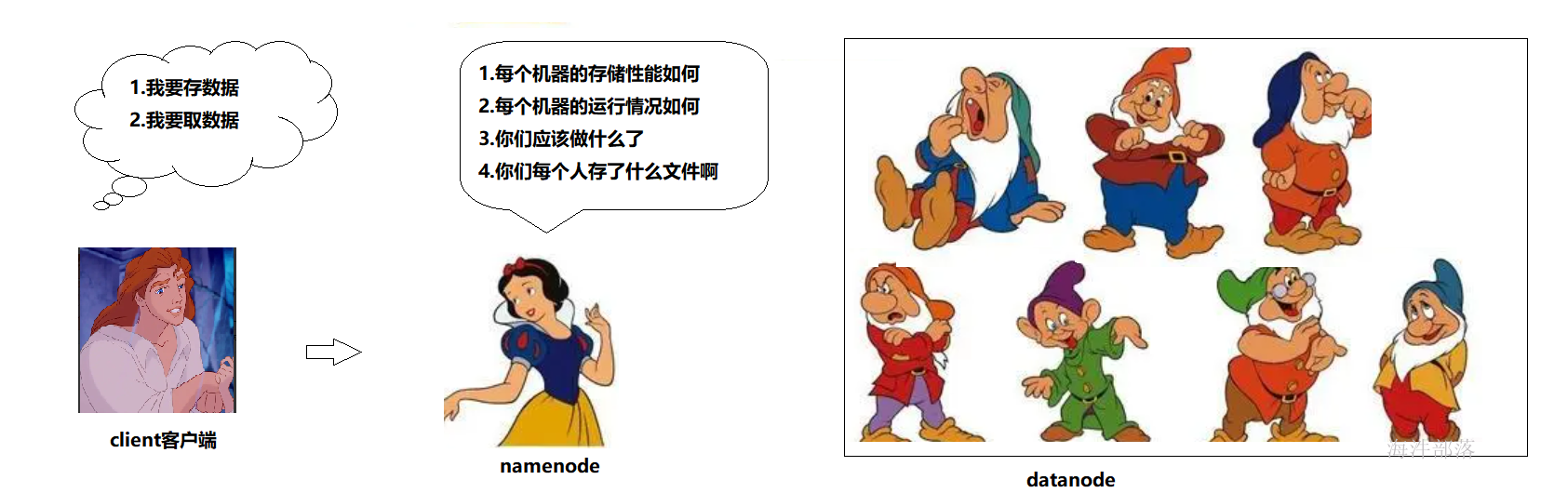
nameNode:
是大领导。管理数据块映射;处理客户端的读写请求。一般有一个active状态的namenode,有一个standby状态的namenode,其中,active状态的NameNode负责所有的客户端操作,standby状态的NameNode处于从属地位,维护着数据状态,随时准备切换。
dataNode:
干活的。负责存储client发来的数据块block;执行数据块的读写操作。
3. namenode的主从与搭建

主节点是单机的,那么在集群运行过程中可能会出现宕机或者异常情况,那么主从节点会出现单点故障
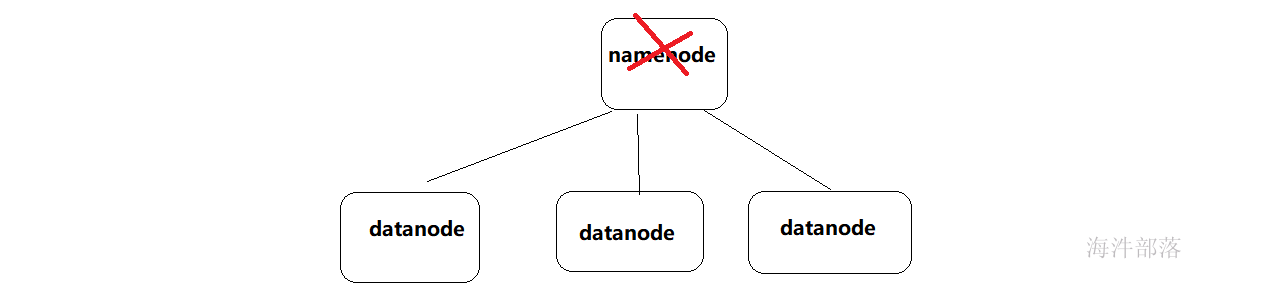
所以hdfs中namenode都是多个,一个节点是active状态,一个standby状态
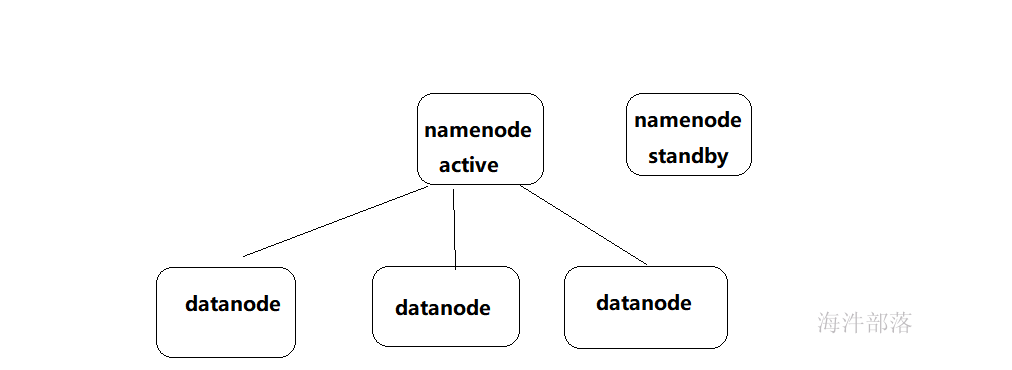
这种叫做主从热备,两个namenode可以相互进行切换,一个宕机以后另一个会马上从事服务
3.1 namenode的搭建和配置
这里我们开始安装操作
3.1.1环境准备
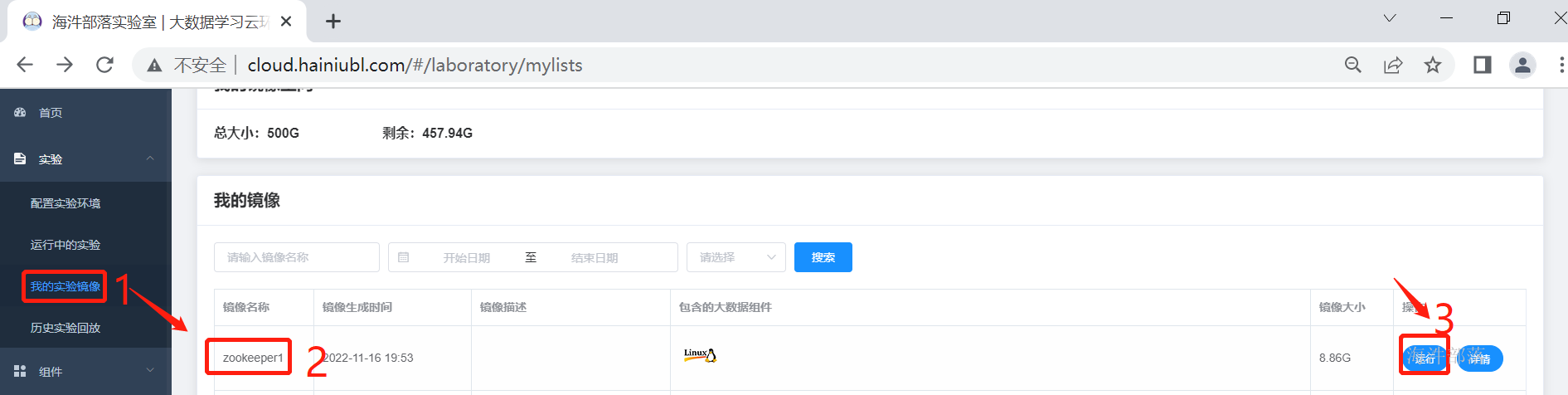
将上次搭建的zookeeper的镜像启动,作为基础镜像使用
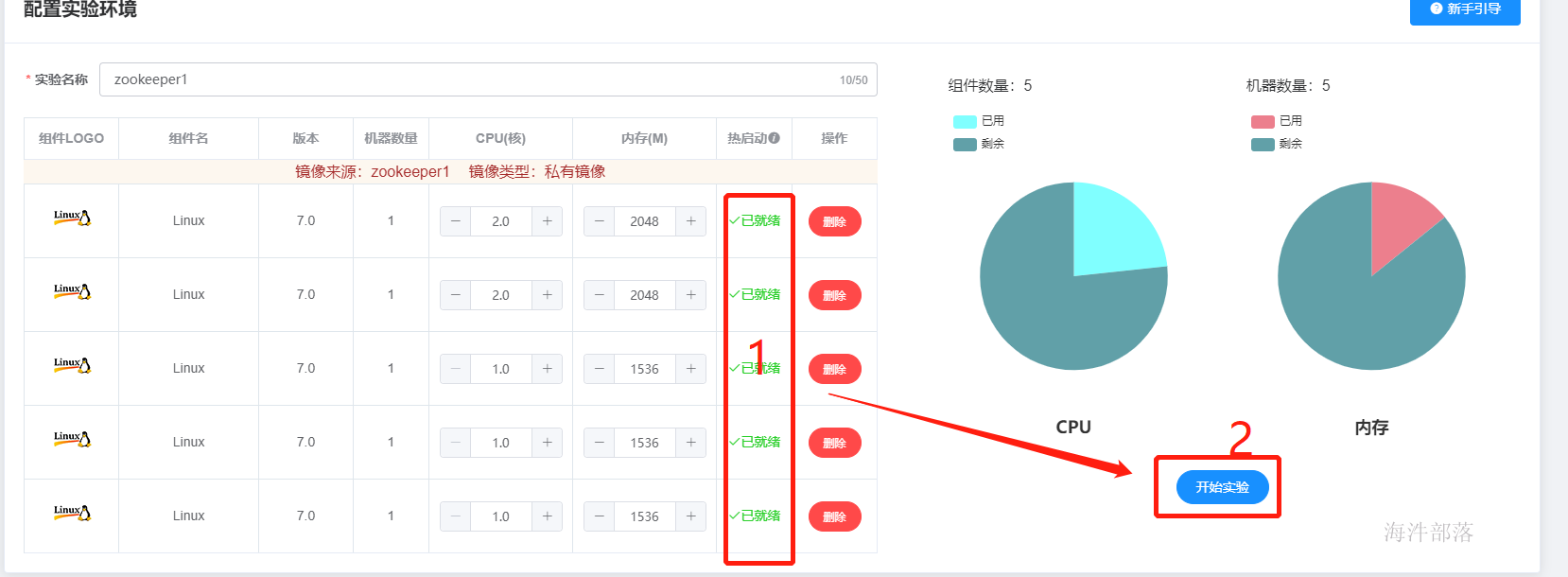
等待所有的镜像准备完毕我们点击开始试验
3.1.2 安装操作

点击服务器列表选择nn1节点,并且切换到hadoop用户
#切换用户
su - hadoop
#解压hadoop到 /usr/local目录中
ssh_root.sh tar -zxvf /public/software/bigdata/hadoop-3.1.4.tar.gz -C /usr/local/#查询解压完毕的安装包
ssh_root.sh ls /usr/local/hadoop-3.1.4/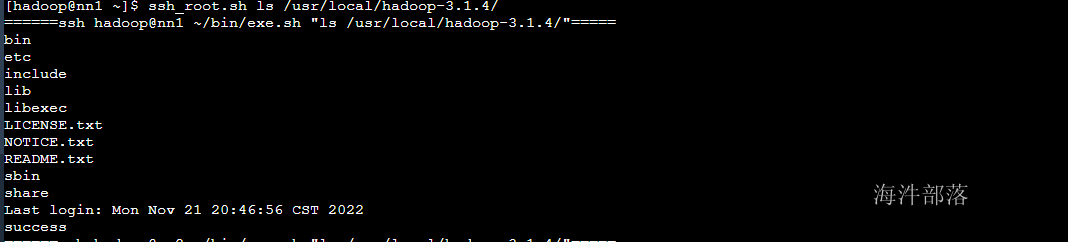
#修改安装包的用户权限归属为hadoop用户,因为以后我们都使用hadoop用户安装和使用
ssh_root.sh chown hadoop:hadoop -R /usr/local/hadoop-3.1.4/
#创建软连接,使用起来更方便
ssh_root.sh ln -s /usr/local/hadoop-3.1.4/ /usr/local/hadoop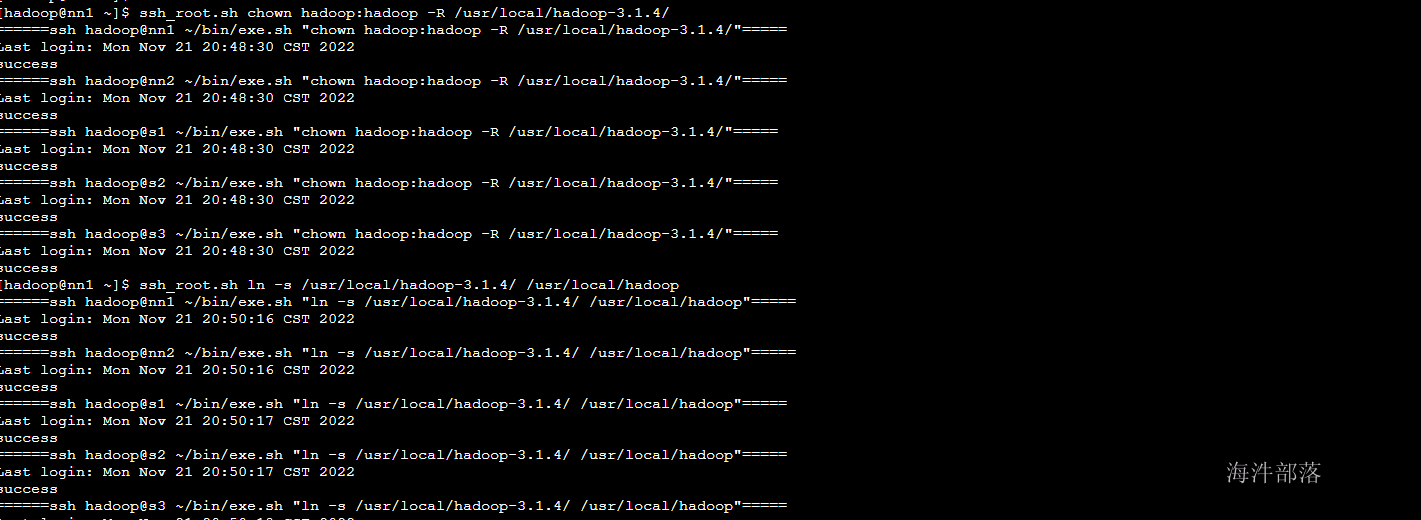
查看解压的hadoop包中都有什么
ls /usr/local/hadoop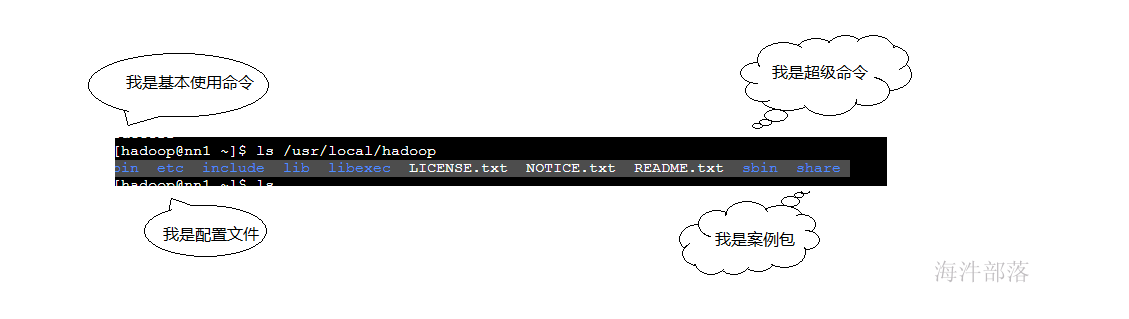
# 配置环境变量
echo 'export HADOOP_HOME=/usr/local/hadoop' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile
#分发所有机器上
scp_all.sh /etc/profile /etc/profile
#让环境起作用
# 在批量命令中执行 source /etc/profile
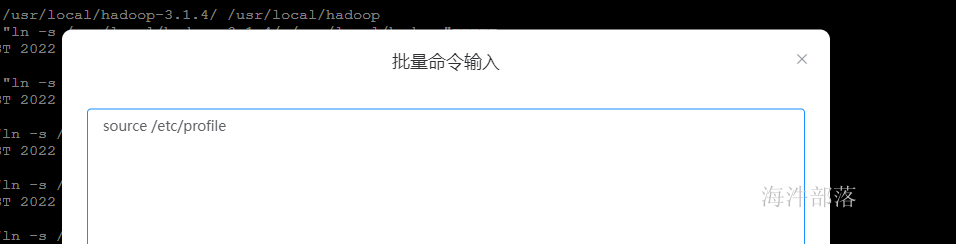
查看配置信息
ssh_all.sh hadoop version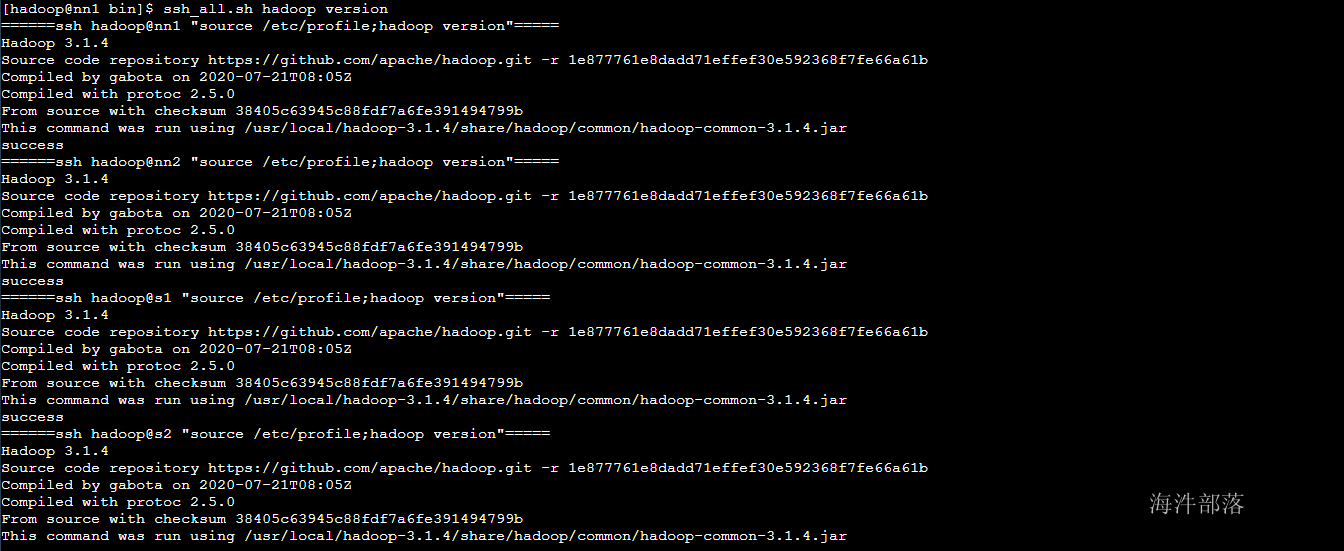
3.1.3 配置文件修改
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
<description>默认文件服务的协议和NS逻辑名称,和hdfs-site.xml里的对应此配置替代了1.0里的fs.default.name</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/tmp</value>
<description>数据存储目录</description>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>hadoop</value>
<description>hdfs dfsadmin –refreshSuperUserGroupsConfiguration,yarn rmadmin –refreshSuperUserGroupsConfiguration使用这两个命令不用重启就能刷新</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>localhost</value>
<description>本地代理</description>
</property> hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/dfsname</value>
<description>namenode本地文件存放地址</description>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
<description>提供服务的NS逻辑名称,与core-site.xml里的对应</description>
</property>
<!--主要的-->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2,nn3</value>
<description>列出该逻辑名称下的NameNode逻辑名称</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>nn1:9000</value>
<description>指定NameNode的RPC位置</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>nn1:50070</value>
<description>指定NameNode的Web Server位置</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>nn2:9000</value>
<description>指定NameNode的RPC位置</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>nn2:50070</value>
<description>指定NameNode的Web Server位置</description>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn3</name>
<value>s1:9000</value>
<description>指定NameNode的RPC位置</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.http-address.ns1.nn3</name>
<value>s1:50070</value>
<description>指定NameNode的Web Server位置</description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>77</value>
<description>namenode的工作线程数</description>
</property>hadoop-env.sh
#hadoop的环境中识别机器的环境
source /etc/profile
# The maximum amount of heap to use, in MB. Default is 1000.
# java虚拟机使用的最大内存
export HADOOP_HEAPSIZE=2563.2 journalnode
3.2.1 journalnode的作用
通过以上的讲解大家知道namenode的主要作用是管理datanode节点,并且可以存储元数据信息,那么namenode在运行的过程中,元数据信息是记录在内存中的

但是在namenode宕机或者是挂机以后会出现元数据丢失的问题,所以namenode元数据存储会分为两份,一份实时存储到内存中的,一份是以文件的形式存储到硬盘上面的
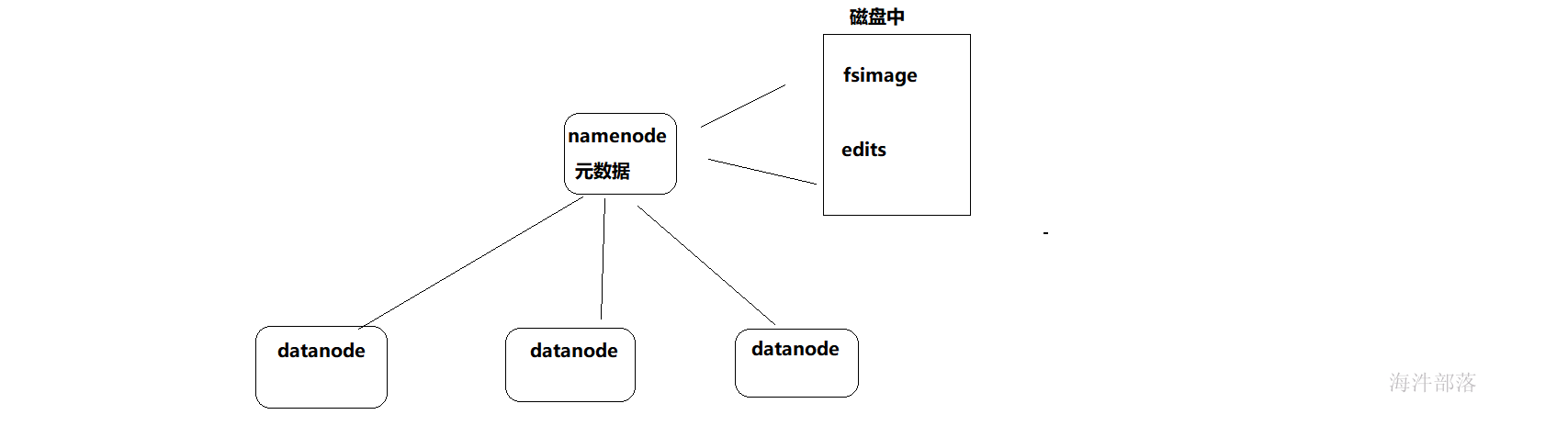
那么问题来了,为什么存储两个文件呢
fsimage保存了最新的元数据检查点,在HDFS启动时加载fsimage的信息,包含了整个HDFS文件系统的所有目录和文件的信息。
对于文件来说包括了数据块描述信息、修改时间、访问时间等。
对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。
editlog主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。
Fsimage,editlog主要用于在集群启动时将集群的状态恢复到关闭前的状态。
为了达到这个目的,集群启动时将Fsimage、editlog加载到内存中,进行合并,合并后恢复完成。
所以,fsimage主要是由edits日志文件合并成的,fsimage为了让启动速度更快,而edits日志文件是为了防止数据丢失,namenode启动的时候直接加载fsimage,然后重播edits日志文件,那么edits日志文件重播的越多那么越慢,所以合并edits和fsimage是至关重要的环节,每隔一段时间应该让数据合并在一起,默认间隔时间是一个小时,合并的工作交给standby的namenode去做
那么新的问题来了,standby的namenode是如何合并两个文件的呢,首先要保证standby的namenode要有这个数据才可以合并,那么两个namenode之间是如何同步数据的呢,带着这个问题我们找到 journalnode
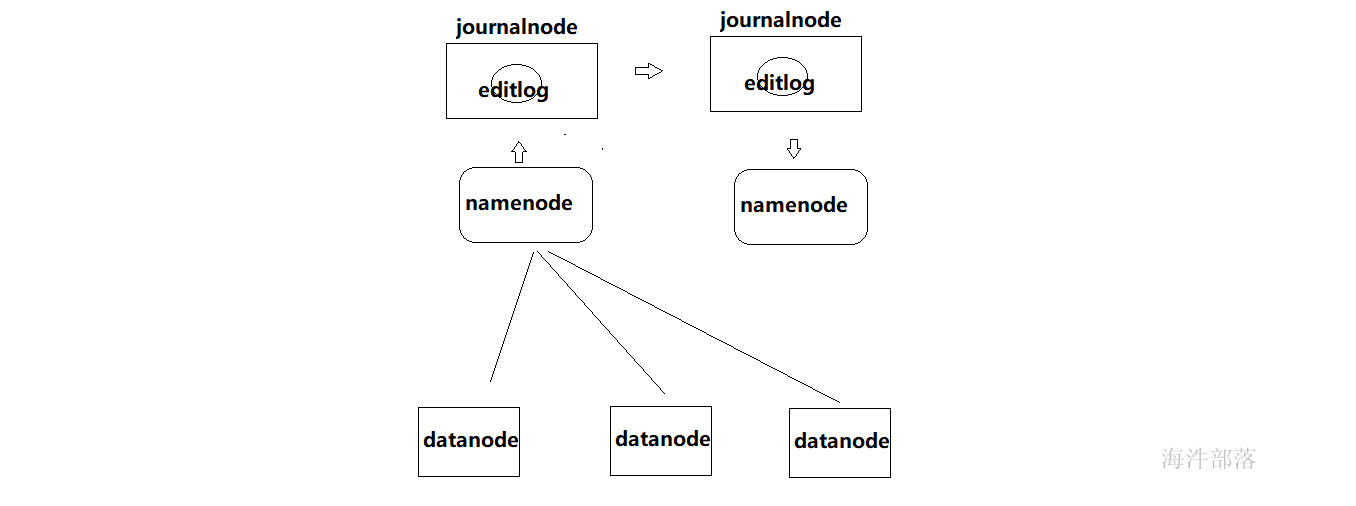
journalnode是hdfs中一个单独的进程,主要是辅助namenode的作用,主节点的namenode负责写出edits日志文件放入到journalnode中进行托管,这样另一个机器也存在相同的edit日志文件
3.2.2 namenode的合并数据过程
fsimage与editlog合并过程
其实这个合并过程是一个很耗I/O与CPU的操作,并且在进行合并的过程中肯定也会有其他应用继续访问和修改hdfs文件。所以,这个过程一般不是在单一的NameNode节点上进行从。如果HDFS没有做HA的话,checkpoint由SecondNameNode进程(一般SecondNameNode单独起在另一台机器上)来进行。在HA模式下,checkpoint则由StandBy状态的NameNode来进行。
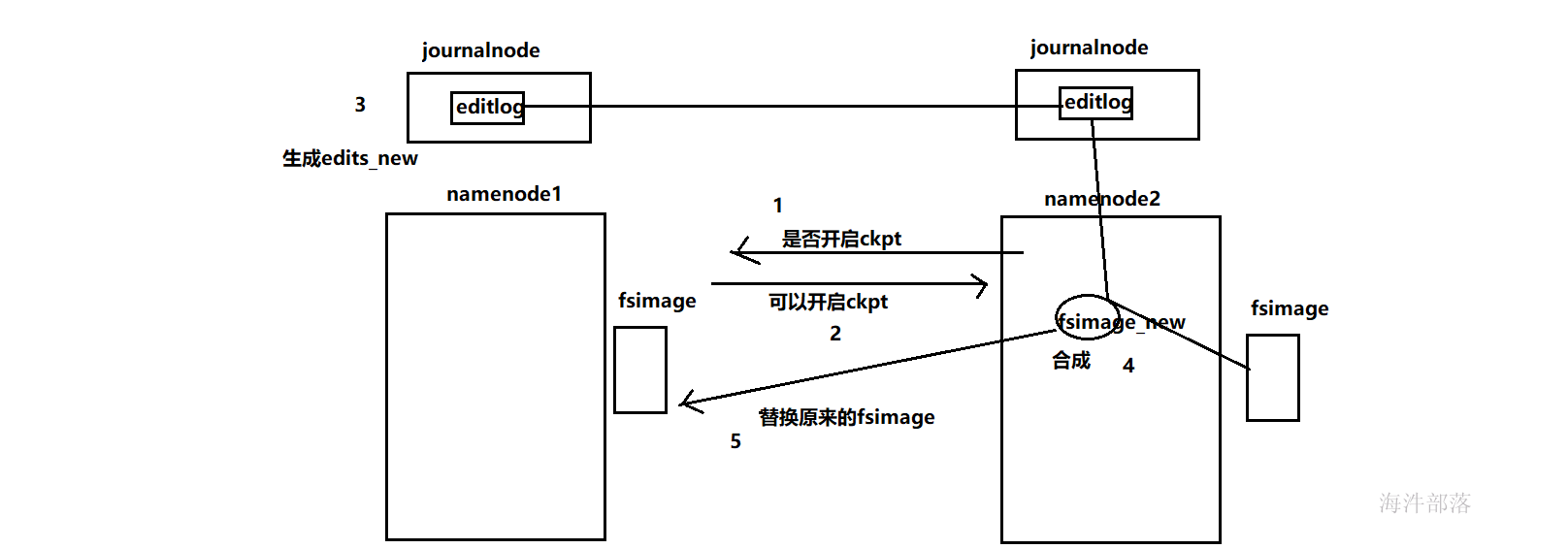
合并过程:
1.SNN合并自身的edits和fsimage
2.合并edits和fsimage文件,产生一个新的fsimage.ckpt
3.发送给NN,并去掉后缀.ckpt(自身也会留存一份)
4.当拉取走edits时,会创建一个edits.new,来存储合并这段时间的操作日志
5.得到fsimage后,去掉edits.new的.new后缀,得到一个edits和一个fsimage
触发条件在core-site.xml中配置
注意这个现在不要配置
<property>
<name> dfs.namenode.checkpoint.period</name>
<value>3600</value>
<description>
两次连续的 checkpoint 之间的时间间隔。默认 1 小时
</description>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>最大的没有执行 checkpoint 事务的数量,满足将强制执行紧急 checkpoint,即使尚未达到检查点周期。默认设置为 100 万。
</description>
</property>
在HA模式下checkpoint过程由StandBy NameNode来进行,以下简称为SBNN,Active NameNode简称为ANN。
HA模式下的edit log文件会同时写入多个JournalNodes节点的dfs.journalnode.edits.dir路径下,JournalNodes的个数为大于1的奇数,类似于Zookeeper的节点数,当有不超过一半的JournalNodes出现故障时,仍然能保证集群的稳定运行。
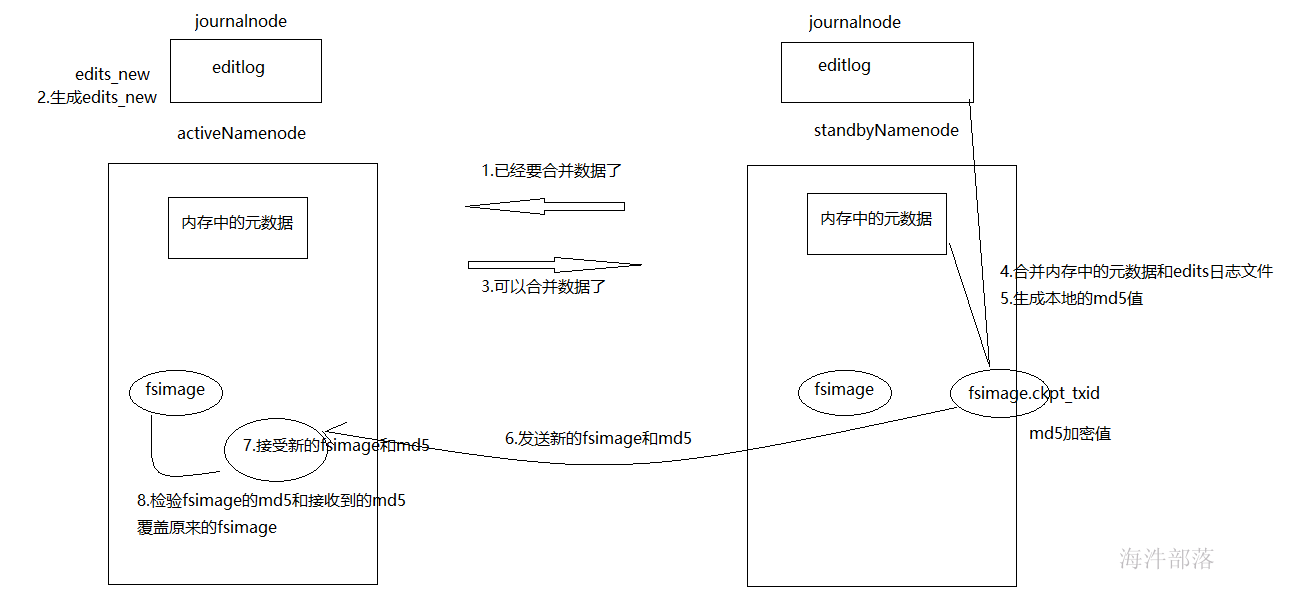
-
SBNN检查是否达到checkpoint条件:离上一次checkpoint操作是否已经有一个小时,或者HDFS已经进行了100万次操作。
-
SBNN检查达到checkpoint条件后,将该元数据以fsimage.ckpt_txid格式保存到SBNN的磁盘上,并且随之生成一个MD5文件。然后将该fsimage.ckpt_txid文件重命名为fsimage_txid。
-
然后SBNN通过HTTP联系ANN。
-
ANN通过HTTP从SBNN获取最新的fsimage_txid文件并保存为fsimage.ckpt_txid,然后也生成一个MD5,将这个MD5与SBNN的MD5文件进行比较,确认ANN已经正确获取到了SBNN最新的fsimage文件。然后将fsimage.ckpt_txid文件重命名为fsimage_txit。
通过上面一系列的操作,SBNN上最新的FSImage文件就成功同步到了ANN上。
3.2.3 journalnode的配置
hdfs-site.xml中增加如下配置
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://nn1:8485;nn2:8485;s1:8485/ns1</value>
<description>指定用于HA存放edits的共享存储,通常是namenode的所在机器</description>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/journaldata/</value>
<description>journaldata服务存放文件的地址</description>
</property>
<property>
<name>ipc.client.connect.max.retries</name>
<value>10</value>
<description>namenode和journalnode的链接重试次数10次</description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
<description>重试的间隔时间10s</description>
</property>3.3 启动namenode和journalnode的启动
#首先分发以上配偶的文件到三个机器中
scp_all.sh /usr/local/hadoop/etc/hadoop/core-site.xml /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/hadoop-env.sh /usr/local/hadoop/etc/hadoop/#启动三个机器的journalnode
#nn1 nn2 s1
su - hadoop
hdfs --daemon start journalnode
#也可以使用hadoop2.x版本命令
hadoop-daemon.sh start journalnode
#查看三台机器的启动情况
查看journalnode的文件创建
ls /data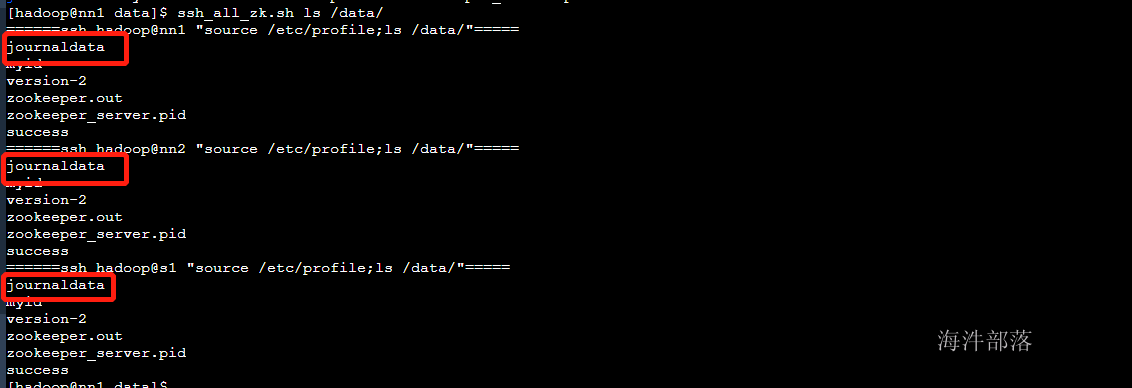
#在第一台机器上面进行数据的格式化
hdfs namenode -format
#查看namenode的fsimage的文件创建
ls /data/dfsname/current/
#查看journalnode中日志文件的创建
ls /data/journaldata/ns1/
#现在第一台机器启动namenode
hdfs --daemon start namenode
现在已经可以查看namenode的信息了
打开浏览器然后输入nn1:50070
恭喜你第一步完成了
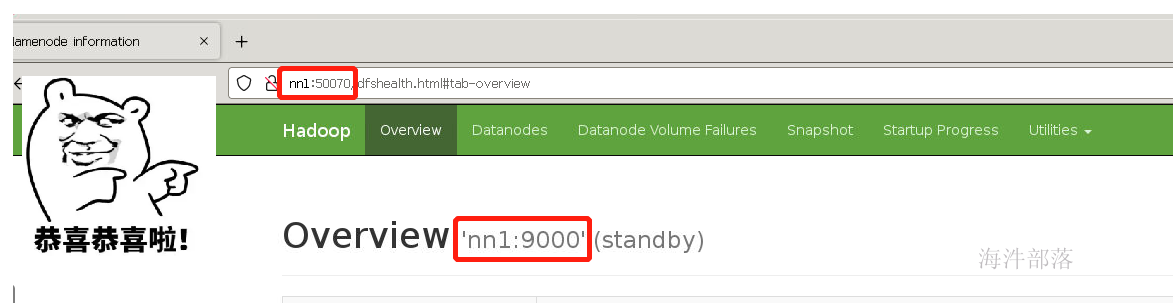
其他的nn2和s1机器上的namenode要同步第一台机器的元数据信息
#nn2和s1同步第一台机器的元数据
#分别在两个机器输入以下命令
#记得切换用于呦
su - hadoop
hdfs namenode -bootstrapStandby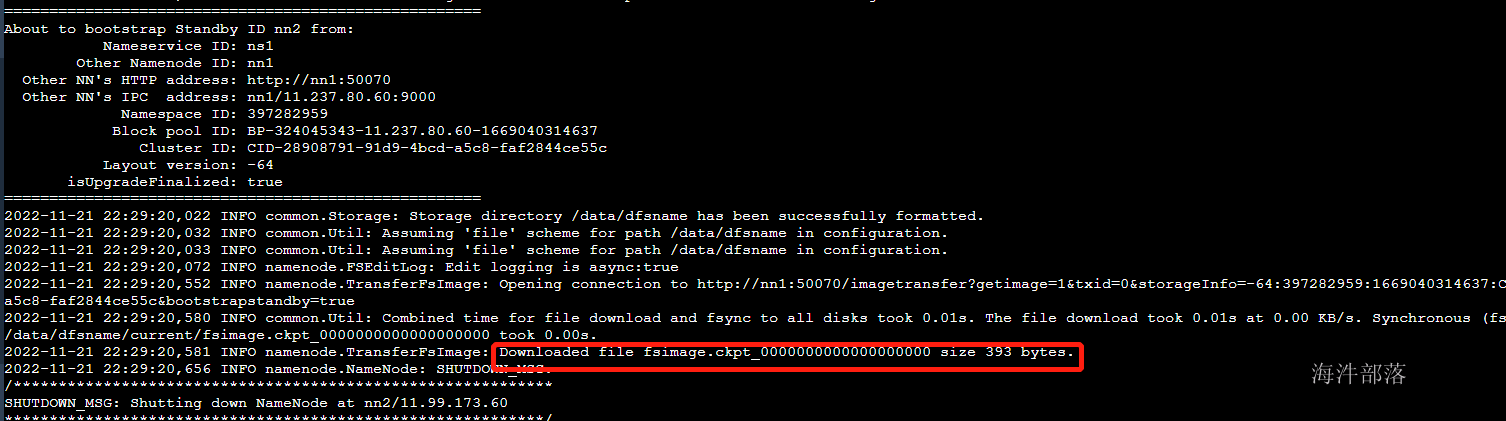
到此三个namenode的数据都准备完毕啦!!!
#启动nn2和s1机器的namenode
hdfs --daemon start namenode
三个机器的namenode全部启动已经准备完毕
4.zkfc的选举
4.1 zkfc的引入
现在我们已经搭建完毕了所有的namenode了,小伙伴们阶段性的胜利了

现在三个机器都是standby状态的,没有一个是真正意义上的领导者

那么我们需要选举一个话事人
我们可以手动切换主从
#手动切换nn1的节点是主节点
hdfs haadmin -transitionToActive nn1
#查看节点状态
hdfs haadmin -getServiceState nn1
但是我们总不能一直人为监控这个节点的状态,实现主从热切换,防止集群宕机对外不能提供服务
这个时候引入一个新的组件zkfc
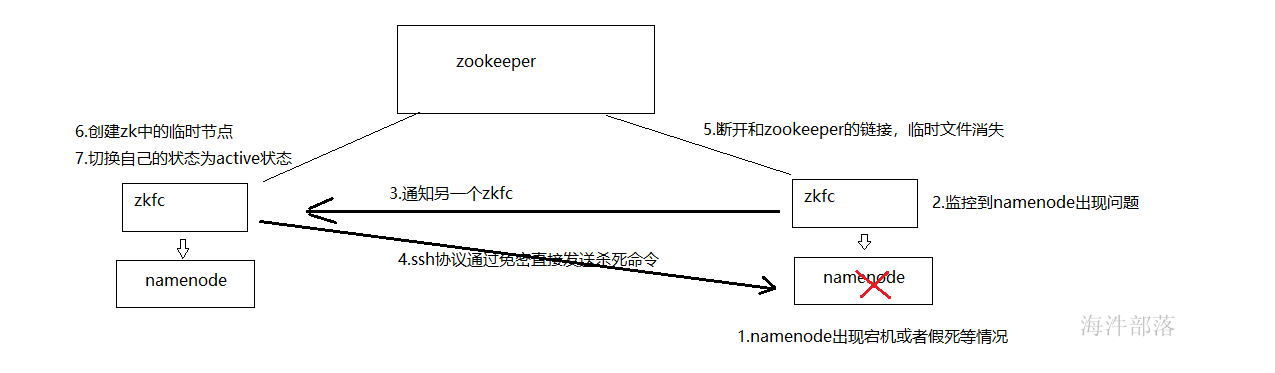
ZKFC(是一个进程,和NN在同一个物理节点上)有两只手,分别拽着NN和Zookeeper。(监控NameNode健康状态,并向Zookeeper注册NameNode);集群一启动,2个NN谁是Active?谁又是Standby呢?
2个zkfc先判断自己的NN是否健康,如果健康,2个zkfc会向zoopkeeper集群抢着创建一个节点,结果就是只有1个会最终创建成功,从而决定active地位和standby位置。如果ZKFC1抢到了节点,ZKFC2没有抢到,ZKFC2也会监控watch这个节点。
如果ZKFC1的Active NN异常退出,ZKFC1最先知道,就访问ZK,ZK就会把曾经创建的节点删掉。删除节点就是一个事件,谁监控这个节点,就会调用callback回调,ZKFC2就会把自己的地位上升到active,但在此之前要先确认ZKFC1的节点是否真的挂掉?这就引入了第三只手的概念。ZKFC2通过ssh远程连接NN1尝试对方降级,判断对方是否挂了。确认真的不健康,才会真的 上升地位之active。所以ZKFC2的步骤是:
1.创建新节点。
2.第三只手把对方降级。
3.把自己升级
那如果NN都没毛病,ZKFC挂掉了呢?Zoopkeeper有一个客户端session机制,集群启动之后,2个ZKFC除了监控自己的NN,还要和Zoopkeeper建立一个tcp长连接,并各自获取自己的session。只要一方的session失效,Zoopkeeper 就会删除该方创建的节点,同时另一方创建节点,上升地位。
4.2 zkfc安装
core-site.xml中添加一下内容
<property>
<name>ha.zookeeper.quorum</name>
<value>nn1:2181,nn2:2181,s1:2181</value>
<description>HA使用的zookeeper地址</description>
</property>hdfs-site.xml增加如下配置
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<description>指定HA做隔离的方法,缺省是ssh,可设为shell,稍后详述</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
<description>杀死命令脚本的免密配置秘钥</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>指定客户端用于HA切换的代理类,不同的NS可以用不同的代理类以上示例为Hadoop 2.0自带的缺省代理类</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.auto-ha</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>#分发脚本配置到各个节点
scp_all.sh /usr/local/hadoop/etc/hadoop/core-site.xml /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hadoop/etc/hadoop/
#启动zookeeper
ssh_all_zk.sh /opt/zookeeper/bin/zkServer.sh start
#查看zookeeper
ssh_all_zk.sh /opt/zookeeper/bin/zkServer.sh status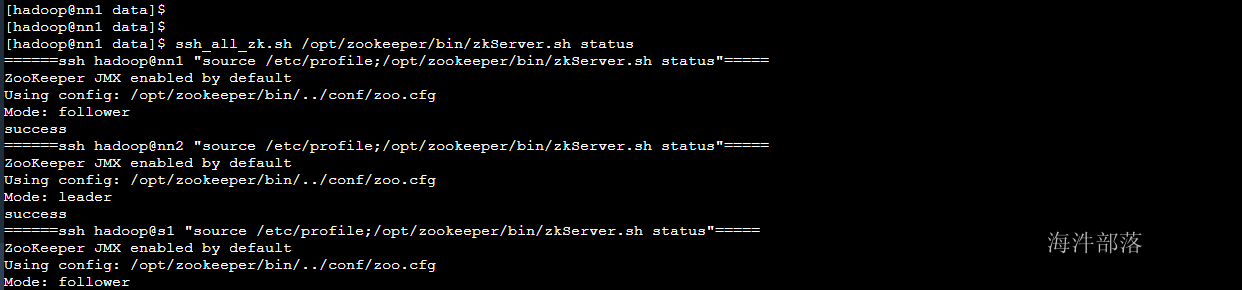
#在zookeeper中初始化zkfc的使用节点的创建
#在nn1节点执行
hdfs zkfc -formatZK
分别在不同的机器启动zkfc
#nn1 nn2 s1启动zkfc
hdfs --daemon start zkfc
#三个机器分别重启namenode
ssh_all_zk.sh hdfs --daemon stop namenode
ssh_all_zk.sh hdfs --daemon start namenode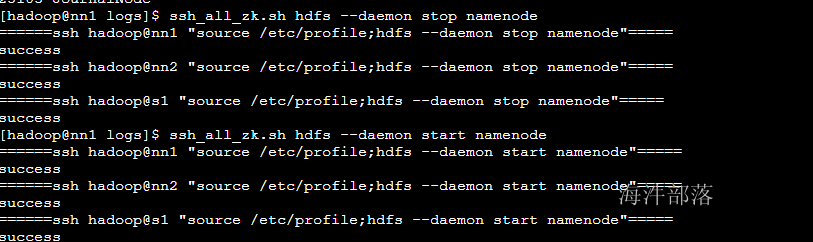
查看三个节点的状态,其中nn1自动选举为nn1
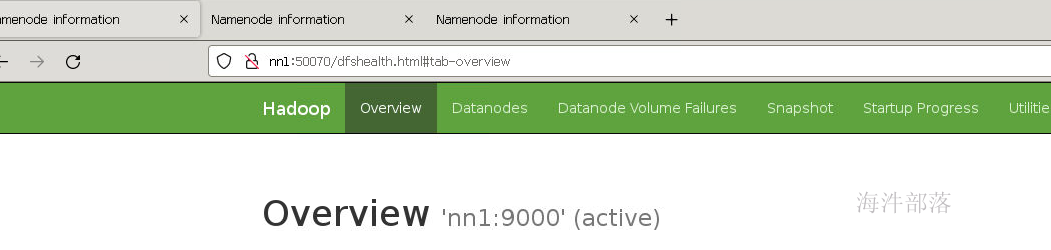
现在去查看zookeeper中的节点创建

在hadoop-ha的znode中会创建独享锁的路径
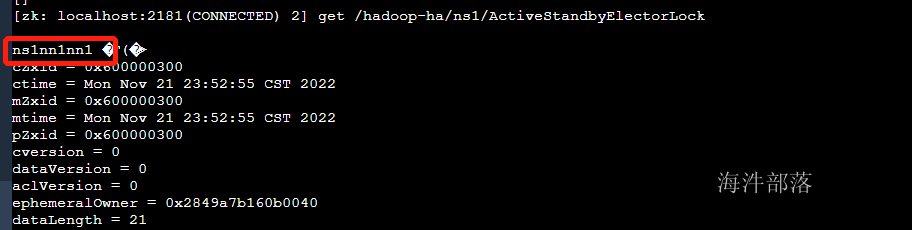
主节点的信息已经存储完毕
现在演示整个集群的自动故障切换
#第一个机器上关闭namenode
hdfs --daemon stop namenode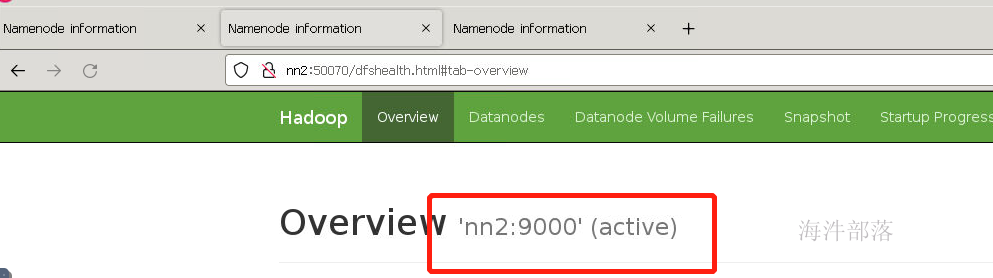
nn2已经切换完毕,现在去zookeeper中查看信息
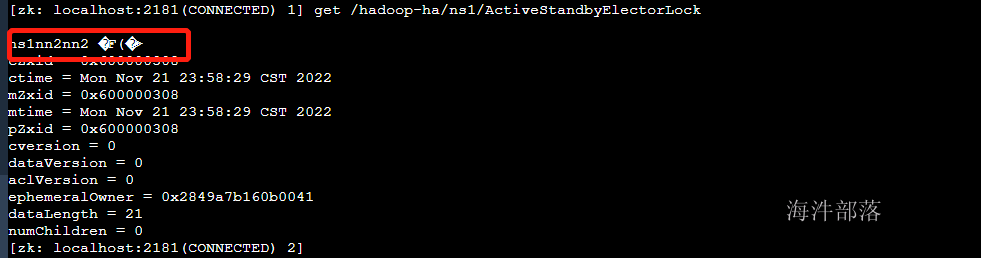
已经切换完毕为nn2
5.datanode
5.1 datanode的介绍
现在我们已经安装完毕namenode的所有进程,可以查看hdfs的监控页面
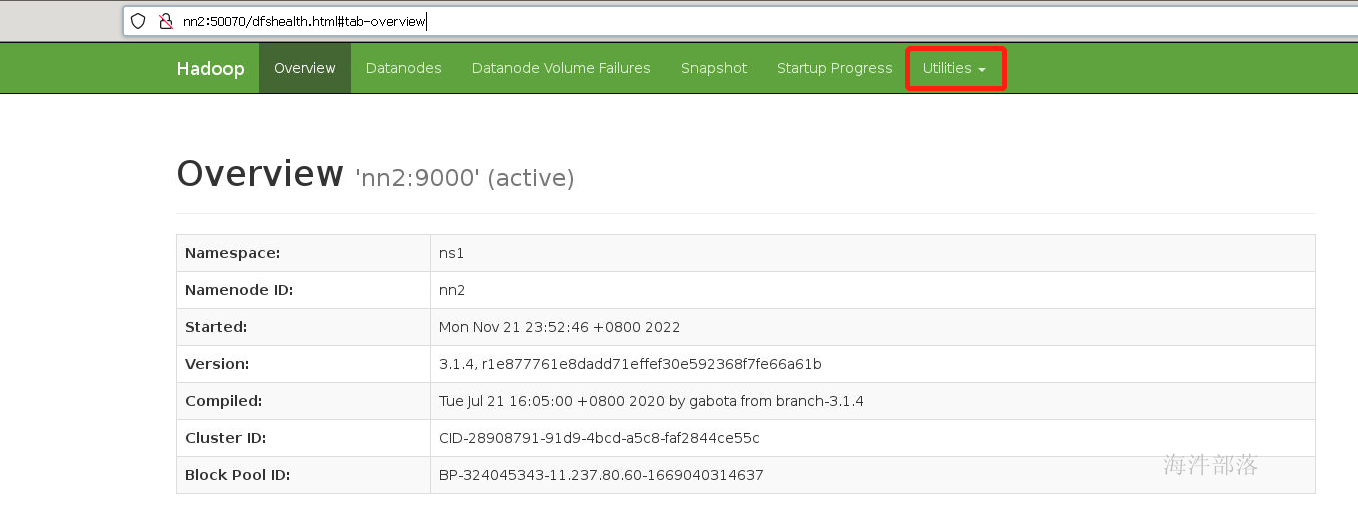
点击图中位置可以查看hdfs中的文件内容


里面没有任何数据
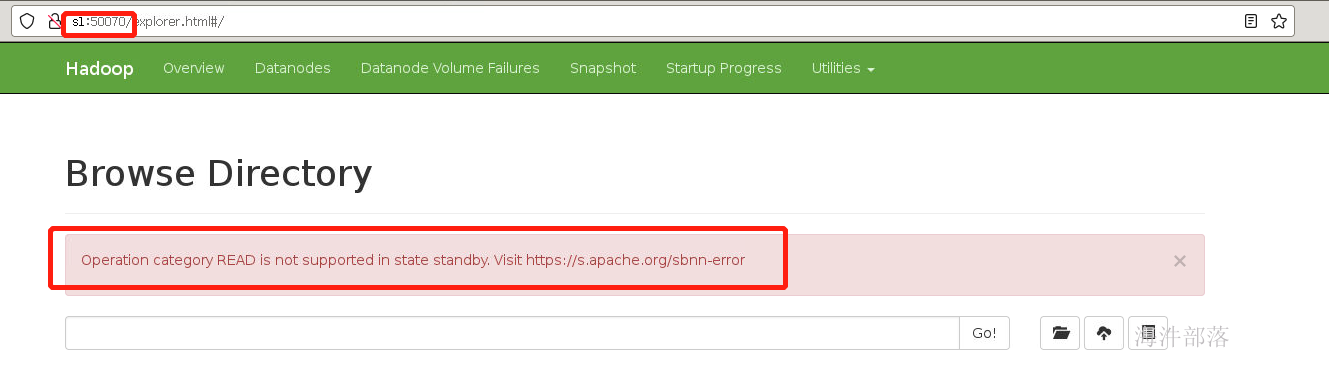
standby节点中是不提供读取数据支持的
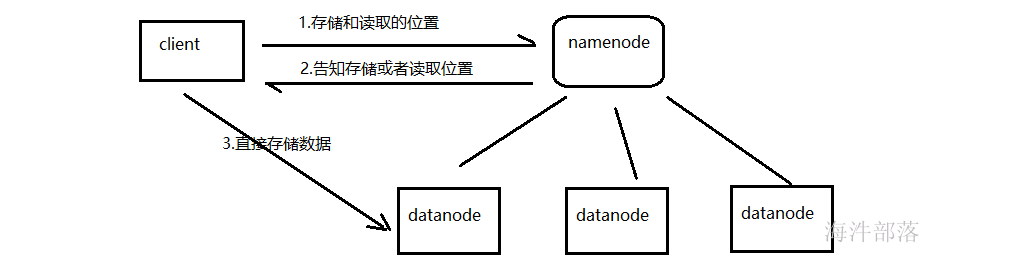
存储数据是需要datanode提供支持的
datanode是真正存储数据block块的从节点
5.2 datanode的安装
hdfs-site.xml 中的配置
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dfs</value>
<description>datanode本地文件存放地址</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>文件复本数</description>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>true</value>
</property>workers中的配置
s1
s2
s3#分发配置文件到各个节点中
scp_all.sh /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/workers /usr/local/hadoop/etc/hadoop/
#防止datanode启动权限不足,修改每个节点的data文件夹的权限
ssh_root.sh chown hadoop:hadoop -R /data
#启动各个节点的datanode
hdfs --workers --daemon start datanode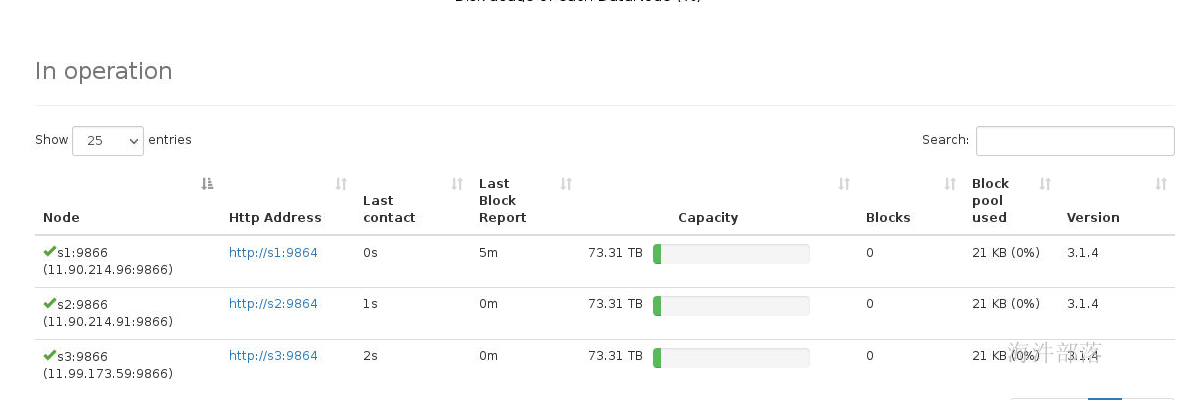
查看每个节点的启动情况
使用命令进行测试
#相当于把linux系统中创建文件夹
hdfs dfs -mkdir /data
#上传文件做测试
hdfs dfs -put /etc/profile /data

可以看到每个节点中的数据增加了2KB大小
到此为止整个hdfs的安装全部都结束了,我们可以看一下每个节点上面的所有进程
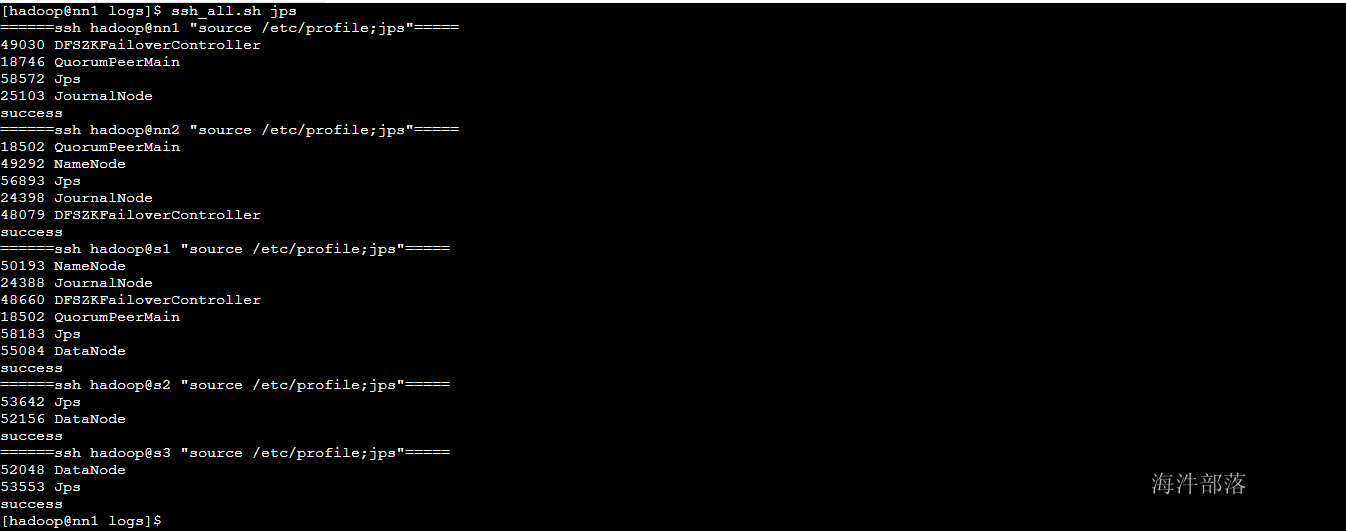
安装完毕后续我们的启动和关闭命令是
start-dfs.sh
stop-dfs.sh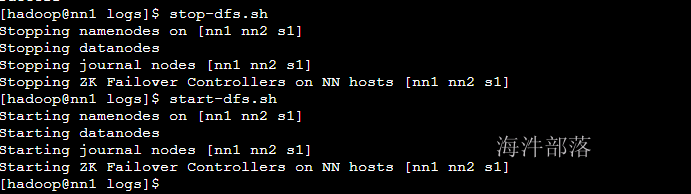
6.hdfs的高级配置
core-site.xml中进行配置
#开启本地库对压缩的支持
<property>
<name>io.native.lib.available</name>
<value>true</value>
<description>开启本地库支持</description>
</property>#支持的压缩格式
<property>
<name>io.compression.codecs</name> <value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec</value>
<description>相应编码的操作类</description>
</property>#SequenceFiles在读写中可以使用的缓存大小
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>SequenceFiles在读写中可以使用的缓存大小</description>
</property># 设置mr输入到hdfs中的数据的压缩是按照块压缩
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name>
<value>BLOCK</value>
</property>
# 出入到hdfs中的文件是按照块为一个整体进行压缩
<property>
<name>io.seqfile.compressioin.type</name>
<value>BLOCK</value>
</property># 客户端连接超时时间
<property>
<name>ipc.client.connection.maxidletime</name>
<value>60000</value>
</property>hdfs-site.xml中的配置
# hdfs开启支持文件追加操作
#关闭文件系统权限
#开启垃圾箱,删除的文件不会消失会移除到垃圾箱中
<property>
<name>dfs.support.append</name>
<value>true</value>
<description>是否支持追加</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>是否开启目录权限</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>2880</value>
<description>回收周期</description>
</property># datanode在读写本地文件的时候设置最大机器文件打开数
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>8192</value>
<description>相当于linux下的打开文件最大数量,文档中无此参数,当出现DataXceiver报错的时候,需要调大。默认256</description>
</property># 在hdfs多个节点中数据均衡的时候能够用到的最大系统带宽,防止占用太多带宽
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>104857600</value>
</property># 设置每个机器的磁盘要预留两个G的数据,不能全部都给hdfs使用
# 设置存储的datanode机器的选择策略,优先以机器剩余磁盘存储两个G以上
<property>
<name>dfs.datanode.du.reserved</name>
<value>2147483648</value>
<description>每个存储卷保留用作其他用途的磁盘大小</description>
</property>
<property>
<name>dfs.datanode.fsdataset.volume.choosing.policy</name>
<value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value>
<description>存储卷选择策略</description>
</property>
<property>
<name>dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold</name>
<value>2147483648</value>
<description>允许的卷剩余空间差值,2G</description>
</property># 设置客户端读取数据
# 如果读取数据的客户端和datanode在同一个机器上那么可以直接从本地读取数据,不需要走远程IO
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/data/dn_socket_PORT</value>
</property>#复制以上内容到core-site.xml和hdfs-site.xml中
#将这个文件分发到不同的机器中
scp_all.sh /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/core-site.xml /usr/local/hadoop/etc/hadoop/
#重启集群
stop-dfs.sh
start-dfs.sh
