MapReducer之Mapper
1.背景
1)海量数据在单机上处理因为硬件资源限制,无法胜任;
2)将单机版程序扩展到集群来分布式运行,极大增加程序的复杂度和开发难度;
3)引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将 分布式计算中的复杂性交由框架来处理;
Hadoop设计的初衷是使得Hadoop作用在低成本的硬件上
hdfs:分布式存储;
mapreduce:分布式计算;
yarn:管理集群计算资源;
通过Hadoop集群进而达到能存储和计算大数据。
2.原理
mapreduce的核心思想:化大为小,分而治之。
mapreduce 的主要组成部分:Mapper 和 Reducer。
Mapper: 负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。
Reducer: 负责对map阶段的结果进行汇总
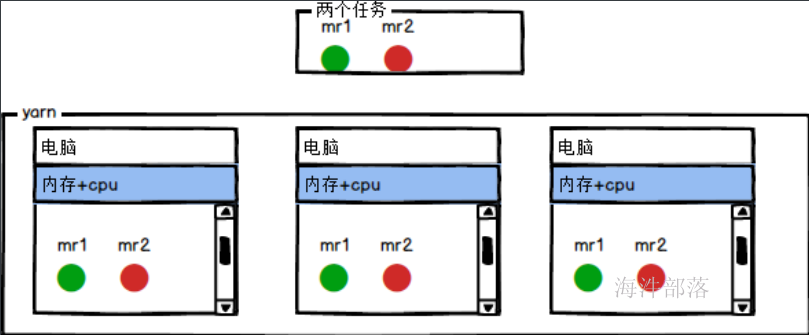
mr就是一段代码,用户定义的逻辑代码,执行在yarn上面进行文件计算和处理的逻辑应用
其实mapper和reducer都是单独的一段计算逻辑代码
只不过运行的并行度不同,并且执行的逻辑不同而已
mapper这段逻辑是分布式计算的整体,但是结果存在多个reducer负责合并规约
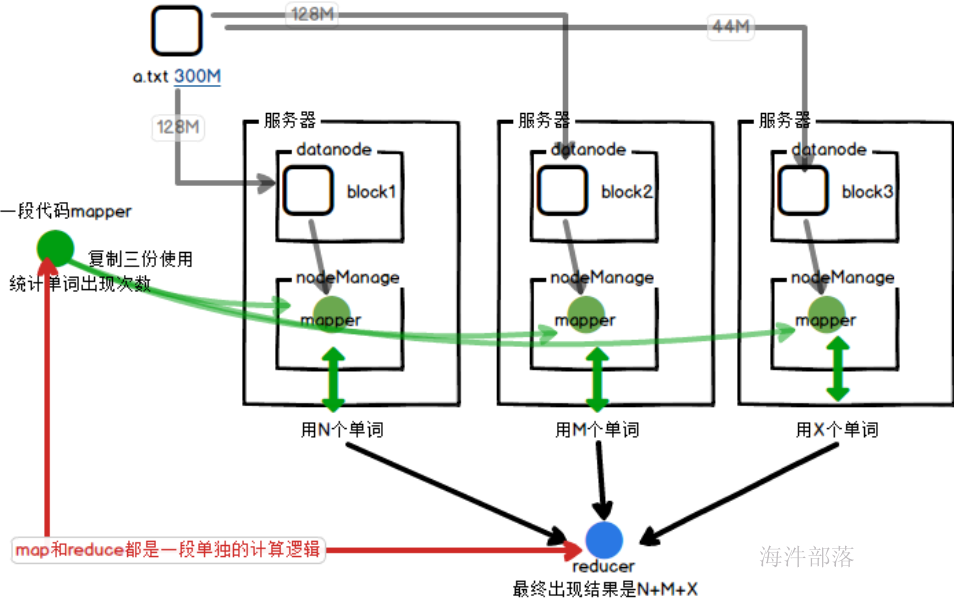
为了达成分布式计算和本地化计算的方式,每个拆分完毕的block块都会对应一个单独的mapper任务,将任务分发到计算节点进行执行,返回计算结果,节省了远程拉取的io通信
移动计算比移动数据本身更划算
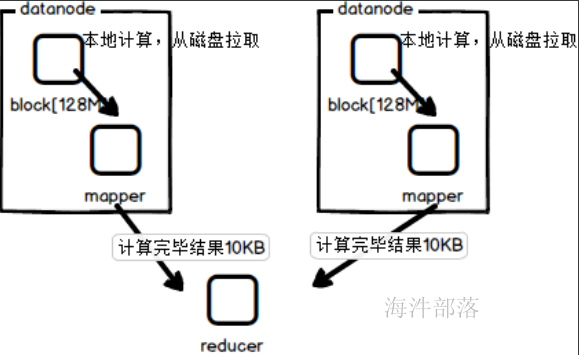
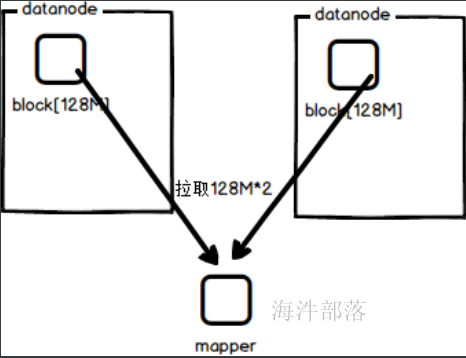
如果是远程拉取数据的话,那么需要多个任务分别拉取其中的数据到本地,这样远程数据传输是比较耗费资源的,所以将mapper任务分发到各个存储数据的节点进行计算,最终将计算的结果返回,这样是效率最高的做法
不仅仅实现了多节点的分布式计算,而且实现了计算本地化
那么reducer的原理是什么呢?
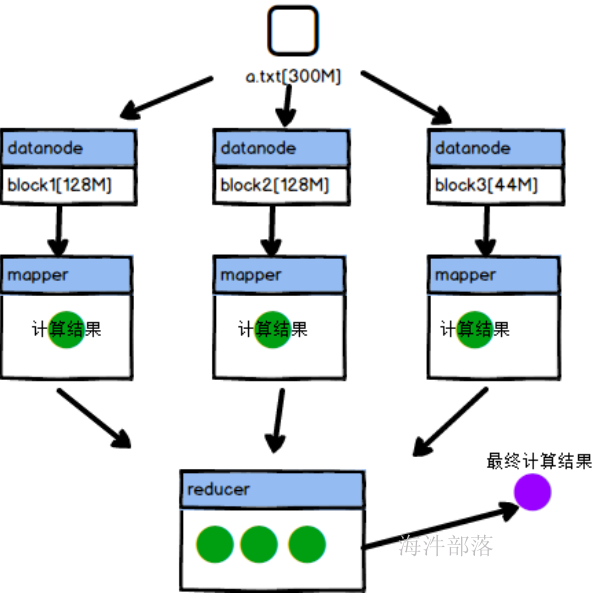
mapper端的数据放入到自己本地,然后启动reducer程序拉取数据进行整体计算。得到统一最终结果
3.mr任务和yarn的集成
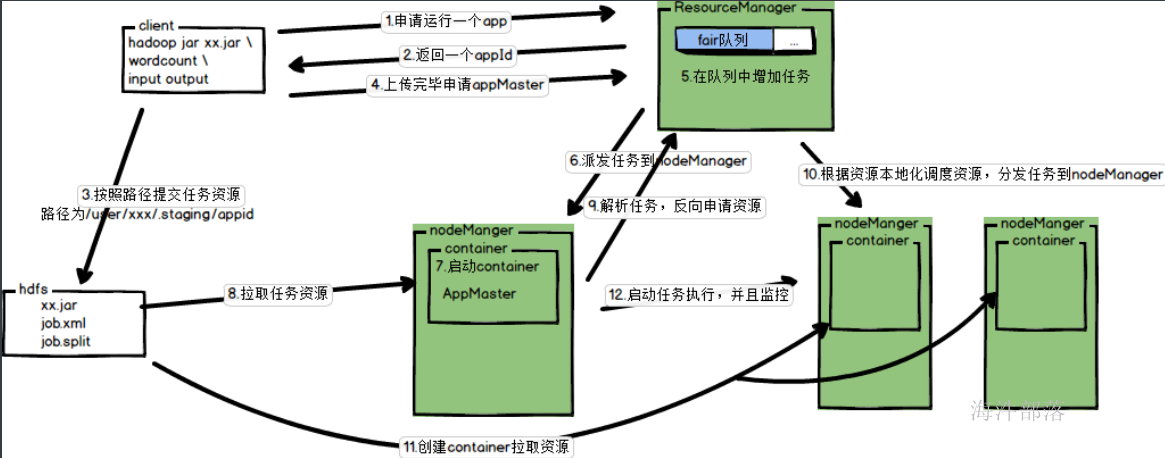
其中container中执行的任务就是mr任务
其中mapper任务尽量在数据所在的机器本地执行,但是reducer任务是随便找一个机器进行执行任务,所有的数据要从mapper端的结果数据中进来拉取
4.mapper的结构
因为mapreduce是一个集群架构。那么如果在集群中执行的话,集群要识别这是一个mr任务
我们首先要遵循这个规则,然后对于架构中的代码逻辑进行进一步的实现才可以
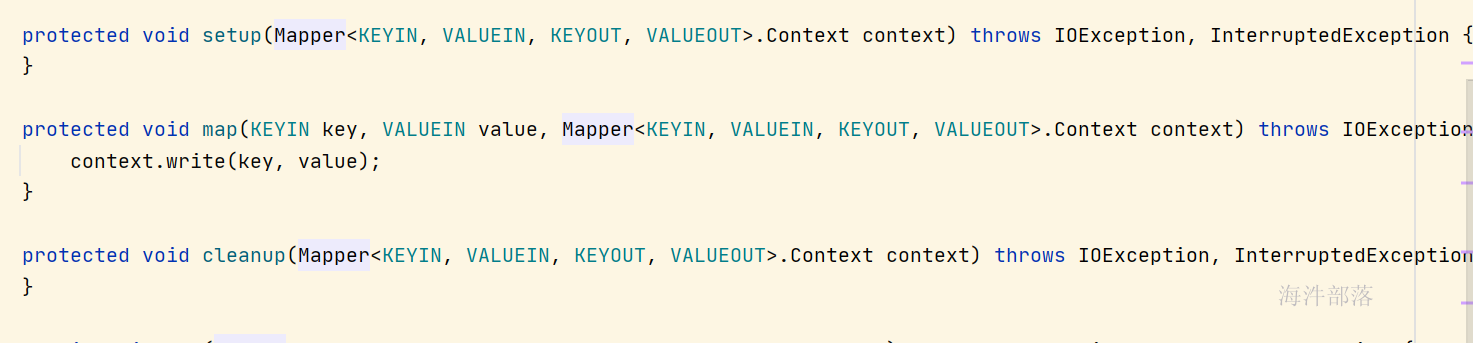
setup方法,在执行操作之前先执行setup方法,只执行一次
map方法,开始读取数据以后,来一条数据执行一次,具体的执行逻辑在这个方法中进行设定,然后处理一条输出一条数据,如果是有reducer就将数据准备,最后交给reducer,如果没有reducer就直接输出到外部文件中
cleanup方法在整个逻辑全部都执行完毕最后执行,只执行一次
我们的主要职责就是对三个方法进行逻辑代码的实现,然后代码会被集群中进行分布式执行
5.数据的输入
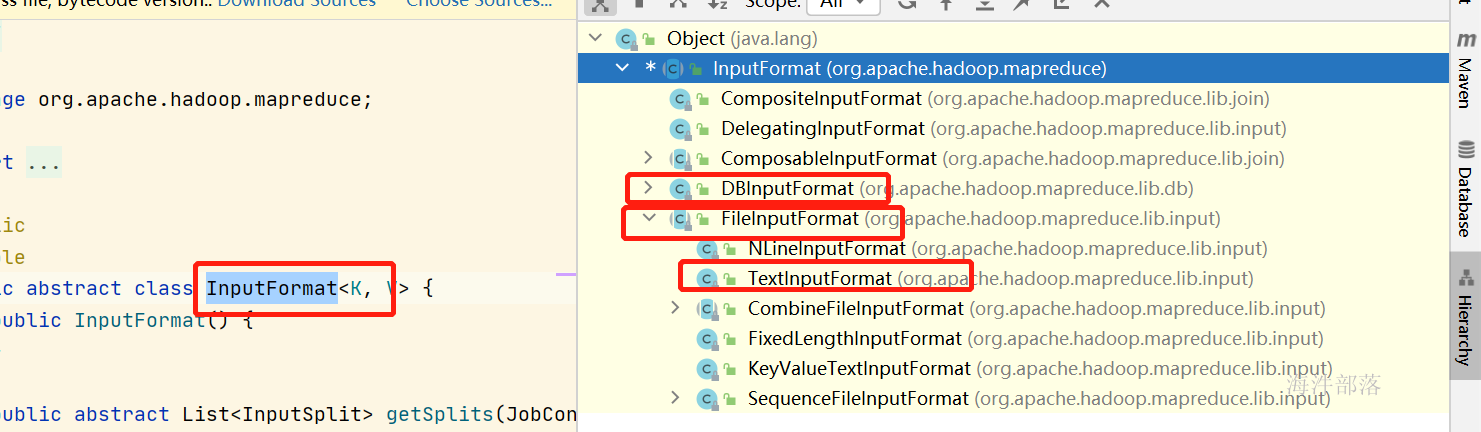
在进入到mapper之前我们需要用到一个读取器进行数据的读入,InputFormat就是数据读取器
与上面我们说的结构很类似,只要读取数据必须使用InputFormat,但是这个是一个抽象类,是一种规范,具体读取不同的文件我们需要进行不同的实现
DBInputFormat是读取数据数据的实现类
FileInputFormat是读取文件的实现
其中在文件读取器下面还有一个TextInputFormat是读取文本文件的实现TextInputFormat 是我们使用最多的读取器,因为输入的文件大多是文本的
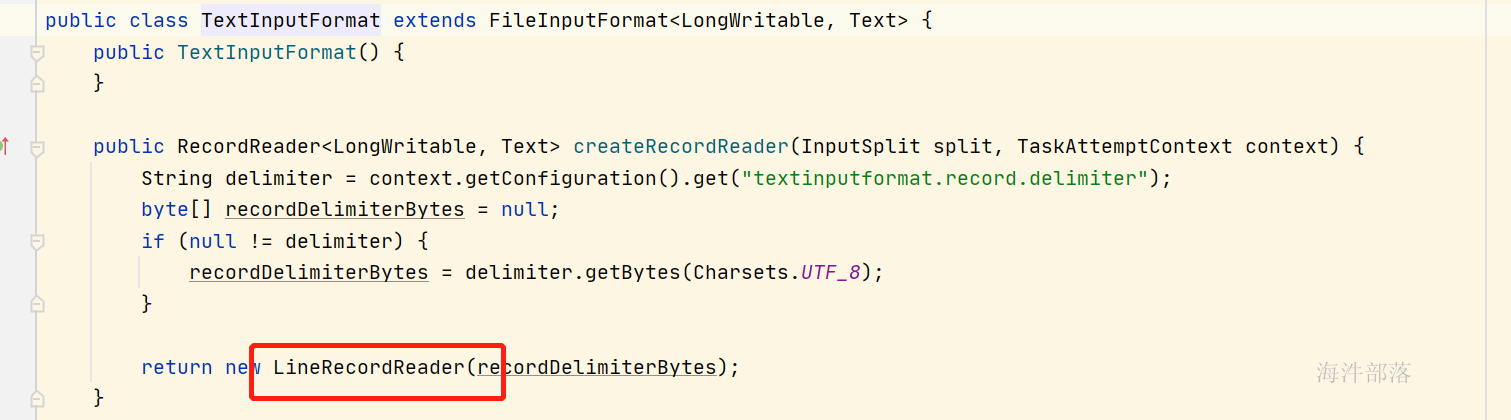
TextInputFormat是一个读取数据的实现类,其中它自身存在一个读取工具LineRecordReader,可以实现文本数据的读取
这个读取器会按照行为单位进行数据的读取,一行读取一次
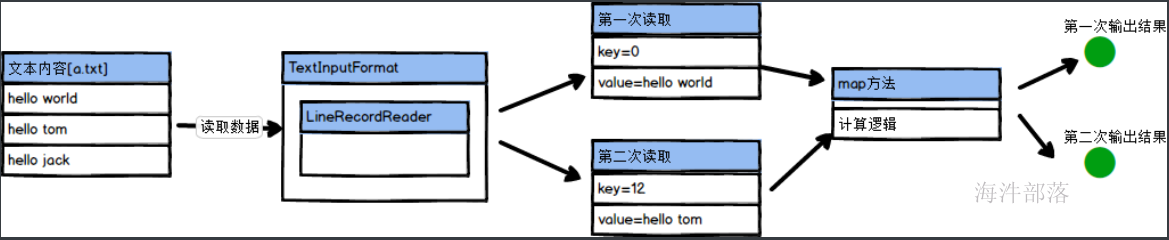
LineRecordReader每次读取数据都会记录一下,读取的数据的真正内容和文本的偏移量信息,以保证第二次读取数据的位置,其中key就是偏移量,value就是读取数据的信息,每次都去都是按照换行键进行分割
6.Mapper端的代码
首先准备环境
运行试验环境准备远程桌面
创建新的远程项目
引入依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>开发代码
开发的mapper类必须要继承mapper的公共父类才可以
其中mapper的类中是需要设定泛型的
public static class TMapper extends Mapper<LongWritable,Text, Text, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}这段代码中我们看到Mapper的前两个泛型是LongWritable和Text,这两个泛型就是输入的值的泛型,对于mapper来说我们可以知道,它输入的数据是需要读取器进行读取的,读取器是TextInputFormat中的LineRecordReader,读取的数据key是当前读取的偏移量信息,value当前这一行的内容,分为两个部分传递进来进行处理,后面两个是输入的类型,我们分别设定的是Text和NullWritable
这里我们要解释以下,输入的泛型如果有reducer那么就传递给reducer不然会直接写出到文件中,也是按照两个部分写出的,在文本中是以\t进行分割的
比如代码中的案例我们没有做任何的数据处理直接将数据输出出去的,因为LongWritable是程序需要进行断点计数的,我们不做任何的修改和使用,直接将内容输入,但是输出的部分只有一个值,那么我们另一个部分用NullWritable进行替代
那么我们为什么不用最基本的Long类型和string类型呢,下面会做解释
map中的代码逻辑我们可以自己选择性设定,按照真正的项目需求设定,下面设定代码的执行方式
public static void main(String[] args) throws Exception{
//创建job对象
Job job = Job.getInstance();
//设定执行类
job.setJarByClass(Test01.class);
//设定mapper的类,输出的k和v
job.setMapperClass(TMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//增加输入路径
TextInputFormat.addInputPath(job,new Path("data/a.txt"));
//设定任务只有mapper
job.setNumReduceTasks(0);
//设定输出路径
TextOutputFormat.setOutputPath(job,new Path("data/res"));
//提交代码并且让代码指定过程中输入执行过程
job.waitForCompletion(true);
}在resources文件夹中加入
log4j.properties
log4j.rootLogger=info,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c %M(): %m%n在项目根目录下创建data文件夹,并在其中创建a.txt文件
hello world hello tom
hello world hello tom
hello world hello tom
hello world hello tom
hello world hello tom
hello world hello tom
hello world hello tom代码的本地运行
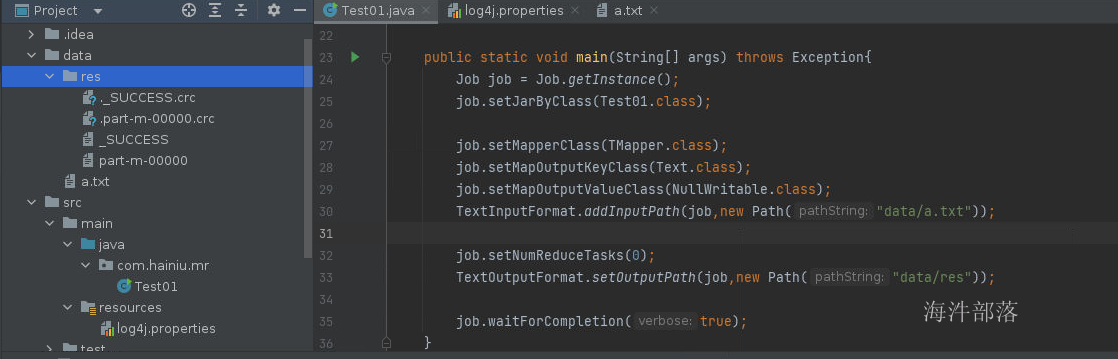
点击代码执行后的结果如下,会生成res文件夹
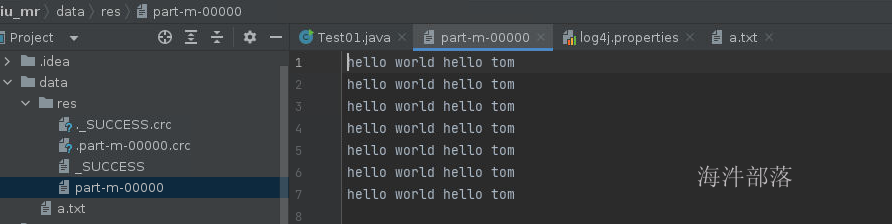
其中结果会原生不动打印出来,因为我们在map方法中没有做任何的逻辑设定
结果的数据命名是part-m-00000,这个意思是mapper端输出的数据,不存在reducer端逻辑
其中crc结尾的文件是校验和文件
用于保证输出的结果的正确性的,完整不缺失
总结:
mapper或者reducer代码就是一段业务逻辑而已,符合我们的逻辑需求,只不过在执行的时候会按照集群进行分布式计算和执行,按照hdfs的存储规则进行分布式计算,一个block块所对应的位置进行数据本地化计算
下面我们将a.txt进行复制为b.txt
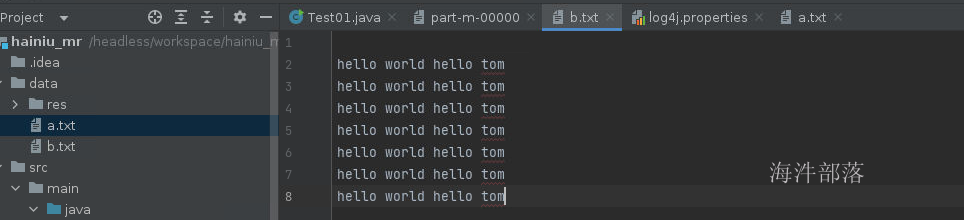
增加输入文件,并且将输入路径改名res1
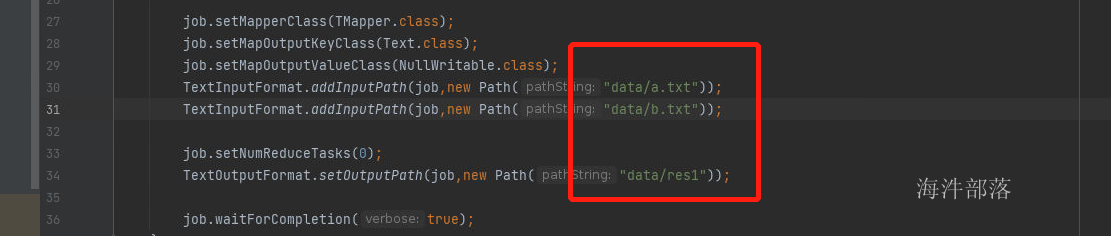
mr代码的输出路径必须不能存在
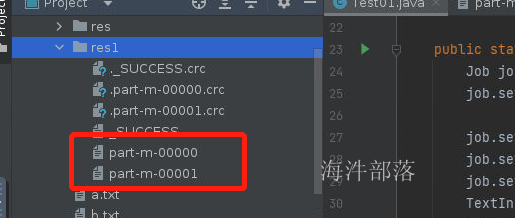
这个时候我们会发现输出的文件结果是两个内容了,因为一个文件对应一个block块,每个block单独启动一个应用计算,所以输出结果也会变多
7.mapper端的文件输入
如上所示,mr的代码主要的功能实现原理就是分布式计算,并且实现本地化计算,这样计算的性能会有很多根本上的提升,分布式计算保证多人并行,本地化计算减少数据的传输,保证数据本地计算完毕最后输出结果,所以一个block对应一个mr任务。当然这个只是我们理论上的一个结论,但是真正的数据输入真实如上所说吗?
通过前一部分的讲解我们知道mr的输入类是TextInputFormat主要是为读取文本数据的,它的父类是FileInputFormat主要是进行文件准备工作的,先有文件才会有文件的内容读取工具
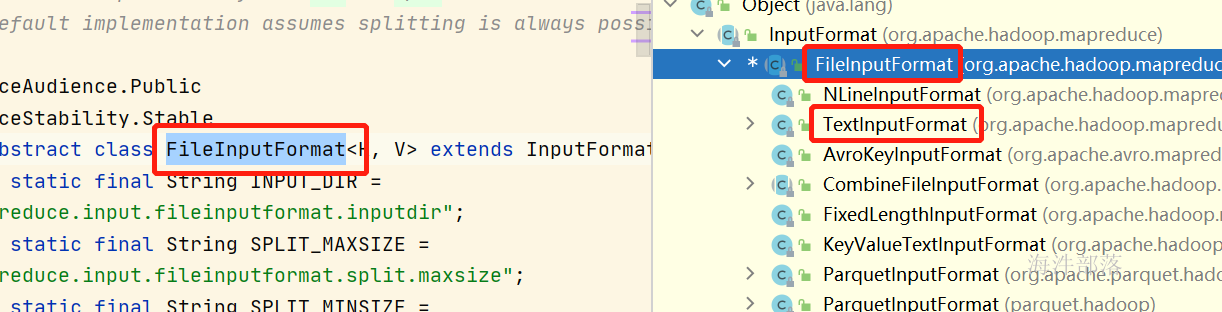
现在我们去看一下FileInputFormat是如何准备数据的
在这个类中最重要的一个方法就是getSplits
这个方法是按照分片大小进行文件的任务生成
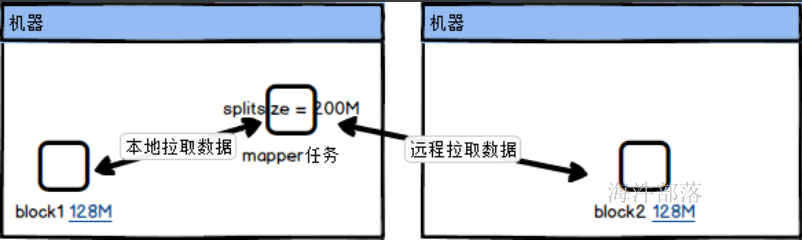
这个方法中非常重要的两个参数就是blocksize和splitsize,分别是存在的块大小和输入分片大小,其中blocksize就是真正存储的文件块有多大,比如blocksize=128M,而splitsize是切片大小,也就是一个mapper任务的输入文件是多大,比如splitsize=200M,那么证明一个mapper任务处理的数据需要从两个block中进行取值,所以一般这两个值都是相同的,不然就会出现远程io通信传输数据的问题
进行文件准备的代码如下
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
//获取最小值,最小值默认是1
long maxSize = getMaxSplitSize(job);
//获取配置最大切片大小
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
boolean ignoreDirs = !getInputDirRecursive(job)
&& job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);
for (FileStatus file: files) {
if (ignoreDirs && file.isDirectory()) {
continue;
}
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
//判断传入输入文件是否可以切分
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
//根据切片和block大小进行比对,谁小以谁为主,默认配置都是128M,所以切片也是128M
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
//如果剩余数据大于1.1*128M 那么还会继续切分,不然就合成一块
//文件可以切分,每次切分128M作为一个block块
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
//每次切分完毕减少大小
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
//按照128M切分完毕以后剩余的单独成一块
}
} else { // not splitable
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
//文件不能切分,那么整体作为一块传入
}
} else {
//Create empty hosts array for zero length files
//如果传入文件大小为空那么直接创建空文件
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}根据以上的切分逻辑我们可得知,切分的大小是128M为一块,但是少于12.8M的部分就不会单独切分成块,主要的原因就是,少量的数据根本不需要启动应用,与其启动应用进行处理,不如直接拉取过来处理,这样虽然走远程IO但是对于性能更有保障
加入测试文件 data/a.txt,文件大小6.02KB
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom
hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom hello tom测试代码
package com.hainiu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class TestSplit {
public static class SMapper extends Mapper<LongWritable,Text, Text, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
//创建job对象
Configuration conf = new Configuration();
conf.setInt("mapreduce.input.fileinputformat.split.maxsize",1024*5);
Job job = Job.getInstance(conf);
//设定执行类
job.setJarByClass(TestSplit.class);
//设定mapper的类,输出的k和v
job.setMapperClass(SMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//增加输入路径
TextInputFormat.addInputPath(job,new Path("data/a.txt"));
//设定任务只有mapper
job.setNumReduceTasks(0);
//设定输出路径
TextOutputFormat.setOutputPath(job,new Path("data/res"));
//提交代码并且让代码指定过程中输入执行过程
job.waitForCompletion(true);
}
}conf.setInt("mapreduce.input.fileinputformat.split.maxsize",1024*5);
设置切片大小,如果是6KB那么剩余0.2KB不足0.1部分,是不可以单独成块的

设置5KB剩余大小是大于0.1的所以单独成块

8.mapreduce中的数据类型
简单mr程序我们已经知道怎么开发了,现在我们看一下mr中奇奇怪怪的数据类型
比如:Text LongWritable
这要从序列化开始
首先我们看什么是序列化
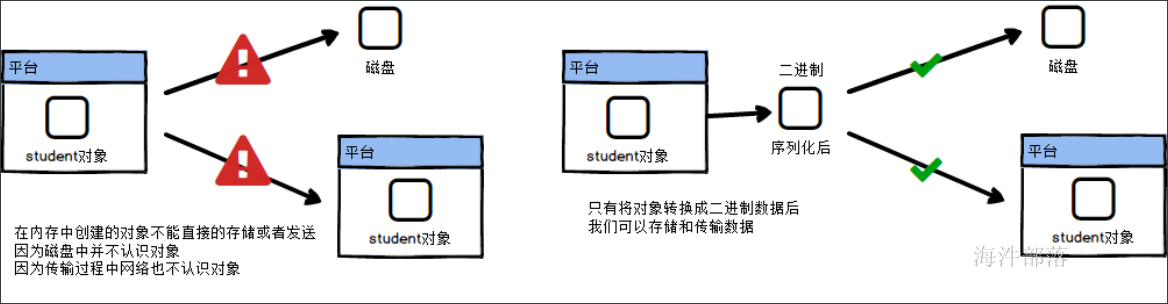
那么java中是如何实现序列化的呢
class Student implement Serializable在java中只需要实现Serializable接口就可以直接序列化数据
我们可以使用java的序列化方式进行一个对象的存储,看一下这个对象再序列化后的样子
package com.hainiu.mr;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class TestSeria01 {
public static void main(String[] args) throws Exception{
Student stu = new Student("hainiu", 5);
FileOutputStream os = new FileOutputStream("data/student1.txt");
ObjectOutputStream oos = new ObjectOutputStream(os);
oos.writeObject(stu);
}
public static class Student implements Serializable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
}
}我们会发现这个数据在序列化后的情况

数据很长占用空间很大
这个时候hadoop提出了自己的序列化方式,因为在大数据的情况下序列化如果性能比较低的情况下是没有办法保证数据传输的效率的,并且数据也会爆炸增长
package com.hainiu.mr;
import org.apache.hadoop.io.Writable;
import java.io.*;
public class TestSeria02{
public static void main(String[] args) throws Exception{
Student stu = new Student("hainiu", 5);
FileOutputStream os = new FileOutputStream("data/student2.txt");
DataOutputStream dos = new DataOutputStream(os);
stu.write(dos);
}
public static class Student implements Writable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.name);
dataOutput.writeInt(this.age);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.name = dataInput.readUTF();
this.age = dataInput.readInt();
}
}
}
我们可以看到这个数据序列化的大小要减少很多,所以hadoop在几乎所有常见类型上面都实现了自己的序列化方式。并且必须使用hadoop的序列化方式
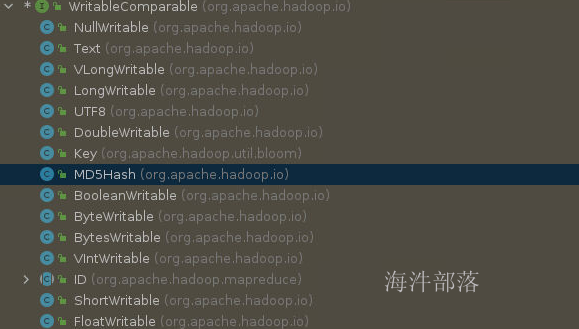
我们可以看到好多实现了writable接口的类
所以我们在代码中看到的类型Text是String类型的包装类实现类Writable的序列化方式,以及LongWritable
//所有的封装的类使用都符合以下规则
//创建的时候
Text v1=new Text("123")
LongWritabe v2 = new LongWritabe(0)
//直接new或者set进去
Text t = new Text()
t.set("hello")
//获取值的方式
v2.get()
v1.toString()
//其中两个对象的使用稍微特殊,我们需要分别取记
//Text中的数据获取是 toString方式获取
//NullWritable的创建方式是 NullWritable.get() 9.mapper端逻辑[清洗]
比如在我们以后大数据进行数据分析和挖掘之前,我们所采集到的数据不一定都是完整清晰的数据,有的时候我们可以对数据的合法性进行清洗

清洗数据非常简单,只是对数据进行规则性处理或者是判断然后输入就可以了,这样为后续处理做准备工作
首先创建data/log.txt
1,zhangsan,20,beijing,13888888888
2,lisi,30,shanxi,13888888877
3,wangwu,,1389990011
4,zhaosi,30,172000将数据不全的清洗删除,将电话号进行校验
package com.hainiu.mr;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class CleanData {
public static class CMapper extends Mapper<LongWritable,Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] strs = line.split(",");
if(strs.length != 5){
return;
}
if( StringUtils.isEmpty(strs[0]) ||
StringUtils.isEmpty(strs[1]) ||
StringUtils.isEmpty(strs[2]) ||
StringUtils.isEmpty(strs[3]) ||
StringUtils.isEmpty(strs[4]) ){
return;
}
if(strs[4].length() != 11){
return;
}
context.write(value,NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(CleanData.class);
job.setMapperClass(CMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
TextInputFormat.addInputPath(job,new Path("data/log.txt"));
job.setNumReduceTasks(0);
TextOutputFormat.setOutputPath(job,new Path("data/res2"));
job.waitForCompletion(true);
}
}
10.mapper端逻辑[去重]
可以实现单个mapper的数据去重处理,实现数据的去重过滤
这个时候我们就需要使用到特殊的数据结构set,在一个map中出现的数据只有128M,所以使用set在内存中去重就可以了,利用set集合的特性,如果重复的数据是加入不到set中的
在data文件夹下面创建 visit.txt输入如下内容
beijing
beijing
beijing
shanghai
shanghai
shanghai
tokyo
tokyo
tokyo
guangdong
guangdong
guangdong
guangdong
guangdongpackage com.hainiu.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
public class Distinct {
public static class DMapper extends Mapper<LongWritable, Text,Text, NullWritable>{
Set<String> set = new HashSet<>();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
String city = value.toString();
if(set.add(city)){
context.write(value,NullWritable.get());
}
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(Distinct.class);
job.setMapperClass(DMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
TextInputFormat.addInputPath(job,new Path("data/visit.txt"));
job.setNumReduceTasks(0);
TextOutputFormat.setOutputPath(job,new Path("data/res3"));
job.waitForCompletion(true);
}
}
去重完毕的结果展示
以上两个案例都是对于数据的简单处理,我们可以根据案例看到map的处理逻辑就是接受到每一个数据然后进行简单的逻辑判断然后输出到外部,在编程过程中和java的普通逻辑代码是没有任何区别的
以上是mapper的简单使用
11.mapper端逻辑[最值]
一般我们在大数据的场景中我们计算的结果都是聚合类的问题
比如每天的整体收入总额,每个城市的销售信息,每个性别的出生率等等,都是聚合后的数据
针对当前的聚合需求我们做一个简单的逻辑分析
1.计算的时候,map方法处理数据是一条为一次计算的
2.所以我们需要声明一个用于聚合的值
3.因为map是单条数据处理的,那么我们就要知道什么时候才能够计算完毕
这个时候我们引申出来两个方法
setup方法,这个方法在执行逻辑操作计算每个数据之前先执行一次,一般我们作为声明或者预先初始化对象来使用
cleanup方法,这个方法是计算完毕所有的结果后执行这个方法,用于收尾,一般我们使用这个方法作为判断是否计算完毕所有的数据
比如求出最大值
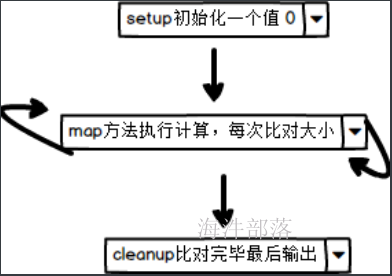
下面代码实现mapper端求出最大值最小值和和已经平均值
在data文件夹下面创建 salary.txt
1,zhangsan,20000
2,lisi,30000
3,zhaosi,45000
4,wangwu,50000
5,guangkun,35000
6,liuneng,34000这个案例中我们不仅仅使用到了cleanup方法,我们输出的结果也需要kv两个部分输出了,因为key输出的是标识,value输出的是值
初始化值如果比如最大值,那么初始化值是Integer最小值,如果是最小值那么初始化值是Integer最大值,计算的逻辑就是不断的进行比对和替换
context进行数据输出,也不是只能输出一个数据
package com.hainiu.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class Aggregate {
public static class AMapper extends Mapper<LongWritable, Text,Text,Text>{
String maxName = null;
String minName = null;
Integer maxSalary = Integer.MIN_VALUE;
Integer minSalary = Integer.MAX_VALUE;
Integer count = 0;
Integer sum = 0;
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(",");
String name = strs[1];
Integer currentSalary = Integer.valueOf(strs[2]);
sum += currentSalary;
count += 1;
if(currentSalary > maxSalary){
maxSalary = currentSalary;
maxName = name;
}
if(currentSalary < minSalary){
minName = name;
minSalary = currentSalary;
}
}
@Override
protected void cleanup(Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
context.write(new Text("最大值"),new Text(maxName +" " + maxSalary));
context.write(new Text("最小值"),new Text(minName +" " + minSalary));
Double avg = sum * 1.0 /count;
context.write(new Text("平均值"),new Text(avg.toString()));
context.write(new Text("总和"),new Text(sum.toString()));
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(Aggregate.class);
job.setMapperClass(AMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
TextInputFormat.addInputPath(job,new Path("data/salary.txt"));
job.setNumReduceTasks(0);
TextOutputFormat.setOutputPath(job,new Path("data/res4"));
job.waitForCompletion(true);
}
}
12.mapper端逻辑[join]
在真正的处理逻辑计算的时候,很多数据都是仅仅是来自于一个表的结果,我们需要将多个表的数据join到一起变成一个整体的数据结果集,然后对于结果集进行处理
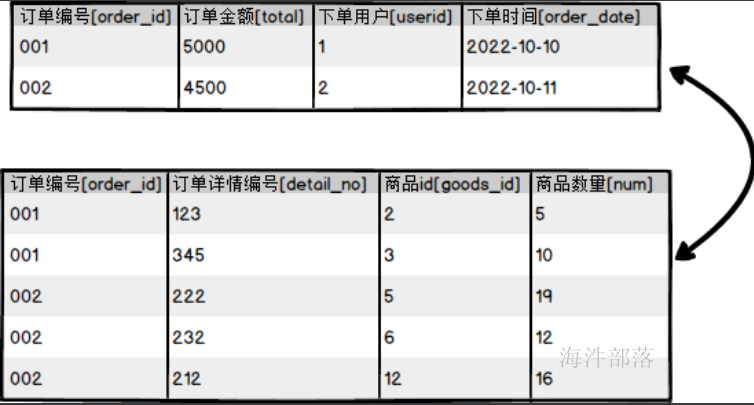
但是这个时候我们要考虑到数据在不同的文件中,我们需要将多个文件的数据进行联合使用,但是对于map来说,一个文件对应一个map,这样每个map处理单独的数据不能够联合到一起,这个时候我们就需要将一个文件放入到内存中,另一个文件使用map进行处理,然后和内存中的数据进行联合关联计算
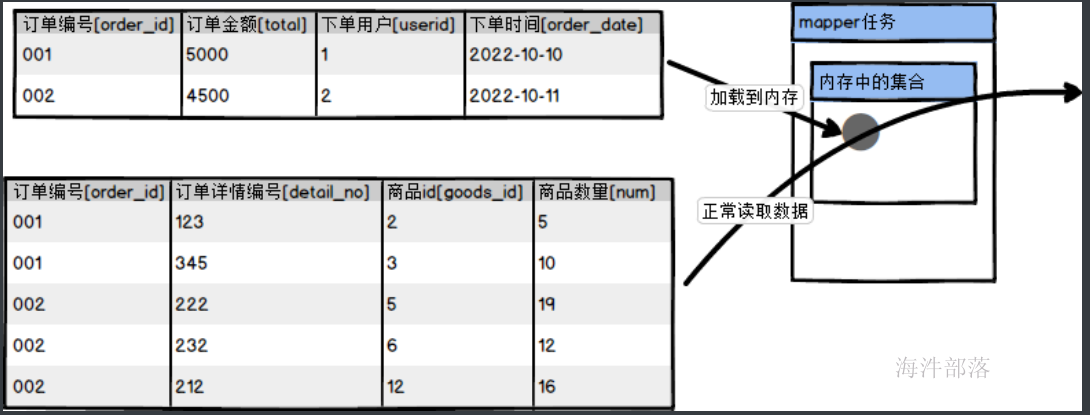
逻辑分析
1.在执行数据计算前就要将文件加载到内存中,这个时候需要使用setup方法,但是加载的是小文件
2.另一个文件正常读取处理在map方法中计算,每一条数据都要从内存中读取已经缓存的数据进行计算
3.输出的最终结果是联合后的内容,那么我们直接用key或者value输出就可以了
4.为了方便内存中的数据和map读取进来的数据很好的做join,在内存中存储的数据按照map进行存储
首先准备两个文件
data下面创建order.txt
001,5000,1,2022-10-10
002,4500,2,2022-10-11data下面创建detail.txt
001,123,2,5
001,345,3,10
002,222,5,19
002,232,6,12
002,212,12,16代码实现
package com.hainiu.mr;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
public class Join {
public static class JMapper extends Mapper<LongWritable,Text, Text, NullWritable>{
Map<String,String> map = new HashMap<String,String>();
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
LocalFileSystem fs = FileSystem.getLocal(context.getConfiguration());
FSDataInputStream in = fs.open(new Path("data/order.txt"));
Scanner sc = new Scanner(in);
while(sc.hasNext()){
String line = sc.nextLine();
String[] strs = line.split(",");
map.put(strs[0],strs[1]+","+strs[2]+","+strs[3]);
}
sc.close();
in.close();
fs.close();
context.write(new Text("orderId,total,userId,order_date,detail_no,goods_id,num"),NullWritable.get());
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(",");
String orderId = strs[0];
String detailInfo = strs[1]+","+strs[2]+","+strs[3];
String orderInfo = map.get(orderId);
context.write(new Text(orderId+","+orderInfo+","+detailInfo),NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(Join.class);
job.setMapperClass(JMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
TextInputFormat.addInputPath(job,new Path("data/detail.txt"));
job.setNumReduceTasks(0);
TextOutputFormat.setOutputPath(job,new Path("data/res5"));
job.waitForCompletion(true);
}
}
13.分布式缓存
Hadoop存的文件分发到各个执行任务的子节点的机器中,这样各个节点就可以自动读取本地文件系统上的数据进行处理
job.addCacheFile(uri);//setup方法中读取数据
context.getCacheFiles()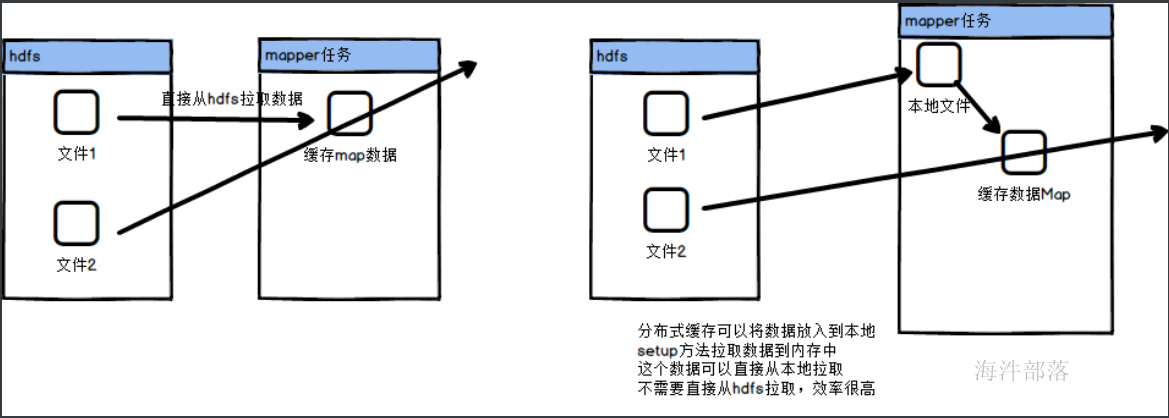
这样我们就可以将代码进行重构,现在order.txt文件放入到分布式缓存中,那么使用的时候读取可以直接从本地文件中读取,增加读取文件的效率
package com.hainiu.mr;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
public class Join2 {
public static class JMapper extends Mapper<LongWritable,Text, Text, NullWritable>{
Map<String,String> map = new HashMap<String,String>();
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
LocalFileSystem fs = FileSystem.getLocal(context.getConfiguration());
URI[] cacheFiles = context.getCacheFiles();
FSDataInputStream in = fs.open(new Path("order.txt"));
Scanner sc = new Scanner(in);
while(sc.hasNext()){
String line = sc.nextLine();
String[] strs = line.split(",");
map.put(strs[0],strs[1]+","+strs[2]+","+strs[3]);
}
sc.close();
in.close();
fs.close();
context.write(new Text("orderId,total,userId,order_date,detail_no,goods_id,num"),NullWritable.get());
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(",");
String orderId = strs[0];
String detailInfo = strs[1]+","+strs[2]+","+strs[3];
String orderInfo = map.get(orderId);
context.write(new Text(orderId+","+orderInfo+","+detailInfo),NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(Join2.class);
job.setMapperClass(JMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.addCacheFile(new URI("data/order.txt#order.txt"));
TextInputFormat.addInputPath(job,new Path("data/detail.txt"));
job.setNumReduceTasks(0);
TextOutputFormat.setOutputPath(job,new Path("data/res6"));
job.waitForCompletion(true);
}
}读取数据
FSDataInputStream in = fs.open(new Path("order.txt"));增加分布式缓存信息
job.addCacheFile(new URI("data/order.txt#order.txt"));后面的地址是本地文件路径,框架会自己在本地以软连接的形式产生这样一个文件
14.map端的压缩
map的结果输出到hdfs中或者是给下游的reducer供给数据的时候可以设定压缩数据,这样可以节省hdfs的数据存储大小也可以增加reducer拉取数据的效率
这个时候我们可以通过以下几个方式对mapper端的结果进行设定
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);直接在输出器上进行设定
Configuration conf = new Configuration();
conf.set(FileOutputFormat.COMPRESS, "true");
conf.set(FileOutputFormat.COMPRESS_CODEC, GzipCodec.class.getName());在conf上面进行设定
Configuration conf = new Configuration();
conf.set(FileOutputFormat.COMPRESS, "true");
conf.set(FileOutputFormat.COMPRESS_CODEC, GzipCodec.class.getName());一定要在conf对象使用之前设定,不然是无效的,或者设置完毕再取出以后设定
Job job = Job.getInstance(conf);
conf.set(FileOutputFormat.COMPRESS, "true");
conf.set(FileOutputFormat.COMPRESS_CODEC, GzipCodec.class.getName());这种设定是无效的
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(Join2.class);
job.setMapperClass(JMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.addCacheFile(new URI("data/order.txt#order.txt"));
TextInputFormat.addInputPath(job,new Path("data/detail.txt"));
job.setNumReduceTasks(0);
TextOutputFormat.setOutputPath(job,new Path("data/res6"));
TextOutputFormat.setCompressOutput(job, true);
TextOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
job.waitForCompletion(true);
}
15.计数器
mapreducer的框架在map和reducer中都预置了一个计数器功能,能够在计算的时候统计不同的任务中的不同指标数量,这个和计算逻辑无关,但是可以在周边起到一个辅助性的功能
而且在一个任务中可以出现很多不同的计数器,不一定是一个计数器
最终所有的计数器都会在结果中以日志的形式输出
比如我们对不合法数据过滤清洗的时候增加计数器
context.getCounter("user group","invalid_num")增加计数器
Counter counter = counters.findCounter("user group", "invalid_num");
System.out.println(counter.getValue());获取计数器
代码实现
package com.hainiu.mr;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Counters;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class CleanData {
public static class CMapper extends Mapper<LongWritable,Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
Counter counter = context.getCounter("user group", "invalid_num");
String line = value.toString();
String[] strs = line.split(",");
if(strs.length != 5){
counter.increment(1);
return;
}
if( StringUtils.isEmpty(strs[0]) ||
StringUtils.isEmpty(strs[1]) ||
StringUtils.isEmpty(strs[2]) ||
StringUtils.isEmpty(strs[3]) ||
StringUtils.isEmpty(strs[4]) ){
counter.increment(1);
return;
}
if(strs[4].length() != 11){
counter.increment(1);
return;
}
context.write(value,NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(CleanData.class);
job.setMapperClass(CMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
TextInputFormat.addInputPath(job,new Path("data/log.txt"));
job.setNumReduceTasks(0);
TextOutputFormat.setOutputPath(job,new Path("data/res2"));
job.waitForCompletion(true);
Counters counters = job.getCounters();
Counter counter = counters.findCounter("user group", "invalid_num");
System.out.println("不合法条数: "+counter.getValue());
}
}
最终打印结果会出现累加器的实现
16.多目录输出
在任务运行的时候我们有时候需要将数据进行分类输出到不同的文件中,比如采集的数据来自于多个数据源,但是我们处理的时候不能全部都处理,需要将输出进行拆分清洗,这个时候就可以使用MultipleOutPuts
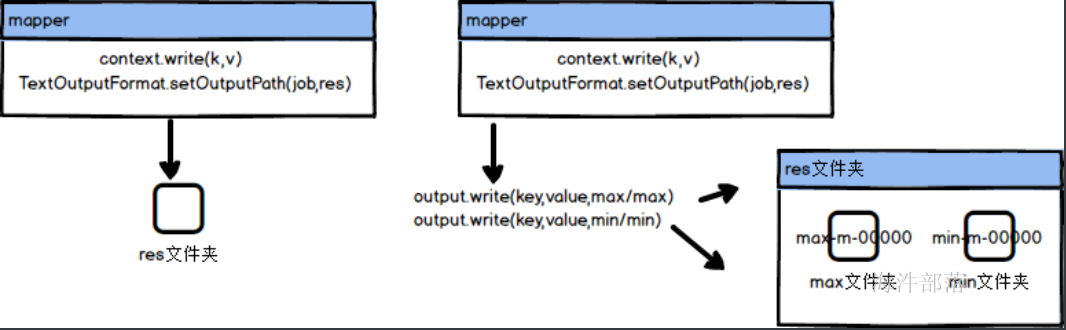
//MultipleOutPuts输出数据的时候可以指定多个文件夹,并且给每个文件起名,输出到不同的文件中
MultipleOutPuts output = new MultipleOutPuts(context);
//一般我们都在setup中进行初始化创建,并且准备对象
out.write(key,value,子文件夹/文件名);
//与输出文件夹是配合使用的,比如我们设定输出的文件夹是res
//TextOutputFormat.setOutputPath(job,"res")
//那么最终的结果就是在这个文件夹中生成子文件夹然后继续输出文件
// res/子文件夹/文件名下面我们在data文件夹下面创建visit.txt
13811110001 移动
13811110002 联通
13811110003 联通
13811110004 移动
13811110005 联通
13811110006 联通
13811110007 移动
13811110008 联通
13811110009 移动
13811110010 联通
13811110011 移动代码逻辑如下
package com.hainiu.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class MuitlOutPutTest {
public static class MultiMapper extends Mapper<LongWritable, Text, NullWritable,Text> {
MultipleOutputs<NullWritable, Text> output = null;
@Override
protected void setup(Mapper<LongWritable, Text, NullWritable, Text>.Context context) throws IOException, InterruptedException {
//初始化多文件输出对象
output = new MultipleOutputs<NullWritable, Text>(context);
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, Text>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] strs = line.split(" ");
String tel = strs[0];
String type = strs[1];
if(type.equals("联通")){
//设定子路径
output.write(NullWritable.get(),value,"联通/lt");
}else{
output.write(NullWritable.get(),value,"移动/yd");
}
}
@Override
protected void cleanup(Mapper<LongWritable, Text, NullWritable, Text>.Context context) throws IOException, InterruptedException {
output.close();
}
}·
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(MuitlOutPutTest.class);
job.setMapperClass(MultiMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
TextInputFormat.addInputPath(job,new Path("data/visist.txt"));
job.setNumReduceTasks(0);
TextOutputFormat.setOutputPath(job,new Path("data/res"));
job.waitForCompletion(true);
}
}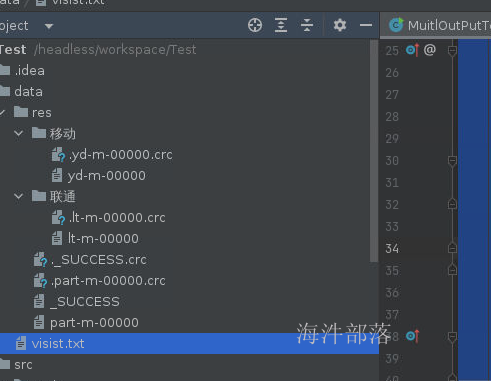
我们可以看到结果已经在多目录中生成

