Mapreducer之reducer
1.reducer的功能
经过以上部分的讲解和使用,我们已经知道了mapper的功能和使用场景,但是reducer部分还没有接触,现在我们针对reducer部分进行使用和练习
mapreducer主要是分为两个部分,mapper和reducer部分,其中mapper主要负责单个文件的处理任务,而reducer主要是对多个mapper的输出结果做总体的聚合操作
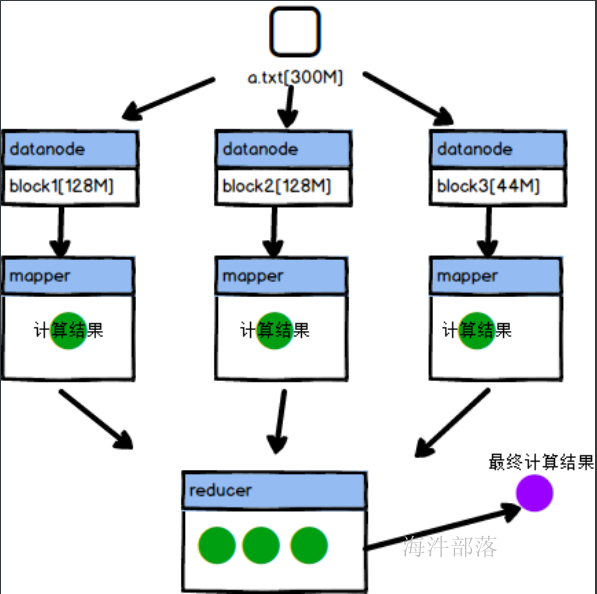
现在针对于reducer我们使用一个大数据中非常经典的wordcount案例进行分析
比如我们需要对一个300M的a.txt中的数据进行分析,得出总体文件中每个单词的出现次数
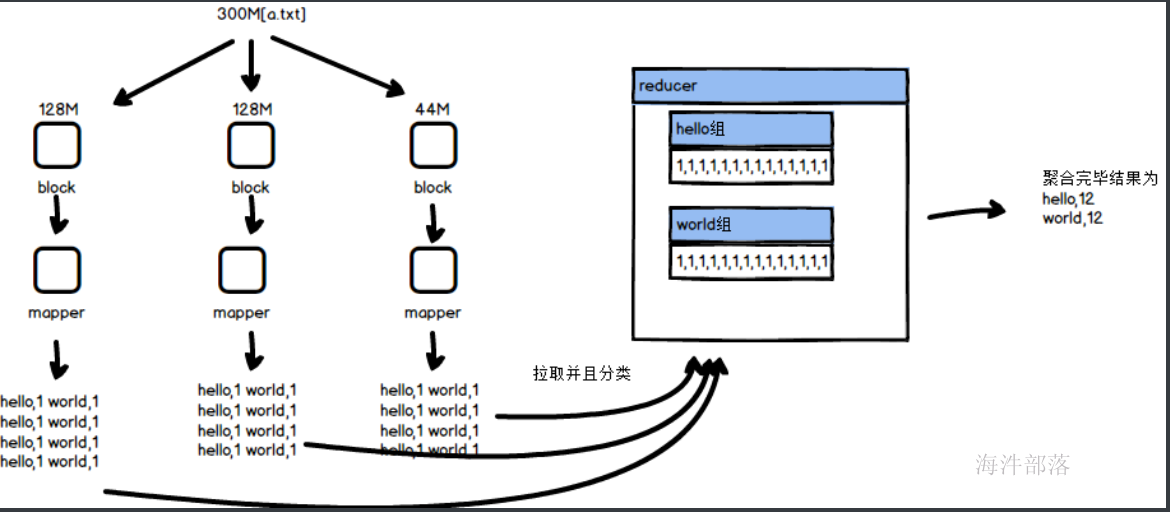
mapper端将数据进行分布式处理,然后将数据保存到自己的本地,reducer端去拉取数据然后存储数据到自己的本地,在拉取数据的过程中会按照map端输出的数据按照k进行分组,将所有的value部分放到一起,这个过程是自动的,我们需要做的就是怎么将已经存在并且分类后的数据进行合并规约
比如:hello,[1,1,1,1,1,1,1,1,1,1,1,1] 进行聚合得出最终结果为hello,12
2.reducer代码之wordcount
与mapper端一样,首先要写出一个reducer程序,我们需要定义一个reducer类,它必须继承自己的父类reducer才可以
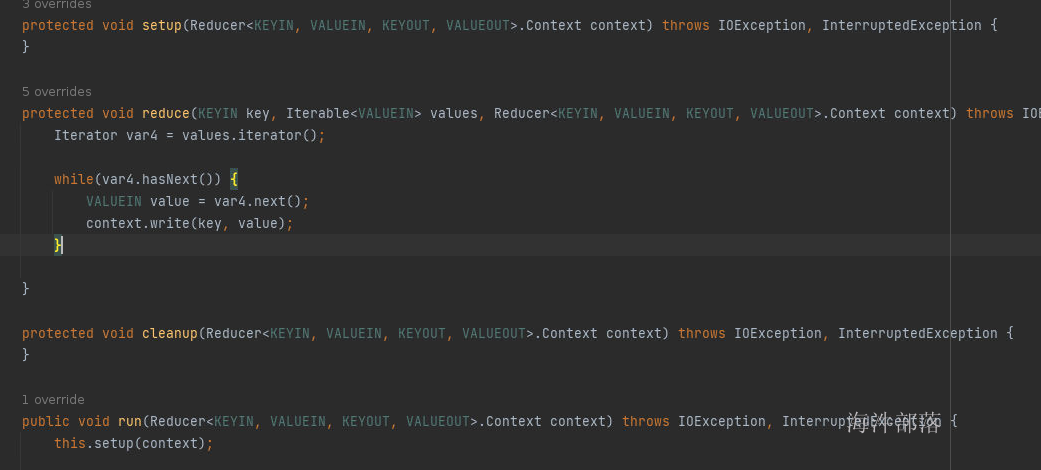
其中reducer的类也存在和mapper相同的三个方法
- setup方法在开始执行reducer任务之前执行
- reduce方法是真正的处理方法,但是和mapper不同,reduce方法是按照整合完毕的数据进行处理的,比如我们传递进来的hello,[1,1,1,1,1,1]这个数据会调用一次reduce方法,也就是存在几个key就会调用几个reduce方法,我们也可以看到reduce方法的参数默认就是key和values,其中key对应的是hello,而values对应的就是全部的分组完毕的value
- cleanup方法是最后调用的方法,等所有的reduce方法都执行完毕再执行cleanup方法
wordcount的单词统计整体逻辑如上图,mapper端负责处理每一个文件,将其中每个单词进行输出,并且给单词上面增加量词1,map端将数据处理完毕会存储到自己的本地,reducer端会拉取数据然后在拉取过程中进行数据的分类处理,分类完毕的数据变为 hello,[1,1,1,1,1],然后我们编写reducer的逻辑对数据进行合并
首先在data文件夹下面创建一个word.txt文件并且输入如下内容
hello world hello tom hello jack
hello world hello tom hello jack
hello world hello tom hello jack
hello world hello tom hello jack
hello world hello tom hello jack
hello world hello tom hello jack然后创建类键入下列代码
package com.hainiu.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class WordCount {
public static class WCMapper extends Mapper<LongWritable, Text,Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);//声明输出结果,其中每个单词的出现次数都记为1
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
//将文件的数据按照空格进行拆分
for (String str : strs) {
k.set(str);
context.write(k,v);
}
}
}
//map端输出的结果是hello,1
//在reducer端拉取数据的过程中会进行自动的分类处理,变成为hello[1,1,1,1,1]
public static class WCReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//其中key是hello,value为[1,1,1,1,1]
//不需要修改key的值,直接将所有的value进行求和就可以了
int sum = 0;
for (IntWritable value : values) {
sum ++;
}
v.set(sum);
context.write(key,v);
//所以最终结果输出的是hello 18
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(WordCount.class);
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
TextInputFormat.addInputPath(job,new Path("data/word.txt"));
//因为增加了reduce的处理部分
//所以我们需要设定reduce的类和输出的数据类型
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
TextOutputFormat.setOutputPath(job,new Path("data/res"));
job.waitForCompletion(true);
}
}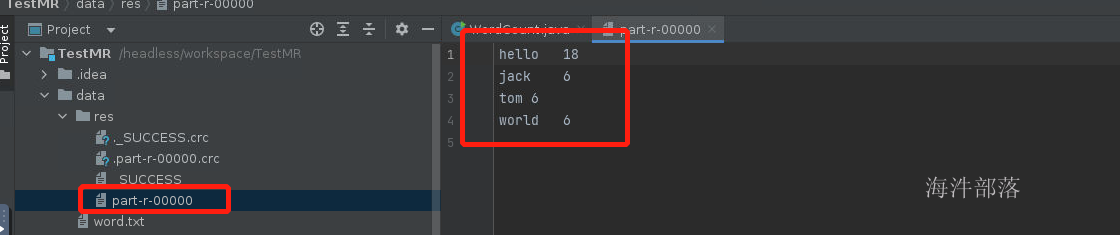
可以看到最终结果出现所有单词的出现次数,其中一个reducer输出的结果对应的是一个文件,其中文件的名称我们发现已经变成了part-r-00000,其中r代表的是reducer计算完毕的结果
如上所示reducer主要是进行mapper端的数据的合并得出最终结果的
那么在map和reducer之间数据发生了什么操作呢?带着这个疑问我们去探究以下问题
首先我们要了解一个概念叫做shuffle
shuffle就是map端数据的输出到reducer端中间的这个过程就是shuffle过程,这个过程中要经历非常复杂的过程,这个过程我们分为以下几个步骤进行讲解
3.combiner
我们知道mapreduce的框架中,mapper端的任务是进行单个文件进行处理,最后reduce进行整体的合并规约,map端的数据写出到本地然后拉取到reduce端进行合并处理的,这个过程中需要进行远程的传输和发送
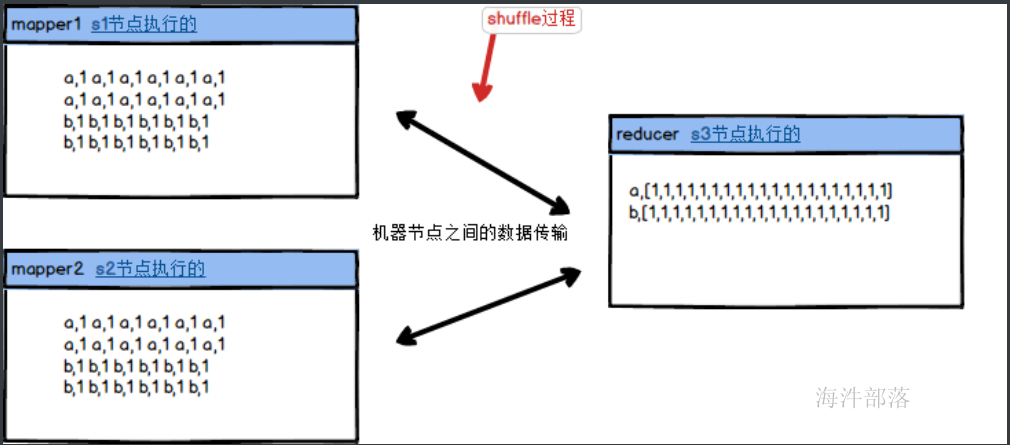
根据上图的描述数据会全部都从map端复制到reduce端,这个数据量是十分巨大的,我们可以在mapper端先进行聚合然后在分发给reducer端进行聚合处理,这样的效率会更高,那么这个在map端先进行聚合的逻辑叫做combiner,它是和reducer一样的聚合逻辑,只不过是在map端先聚合完毕再拉取到reduce端的
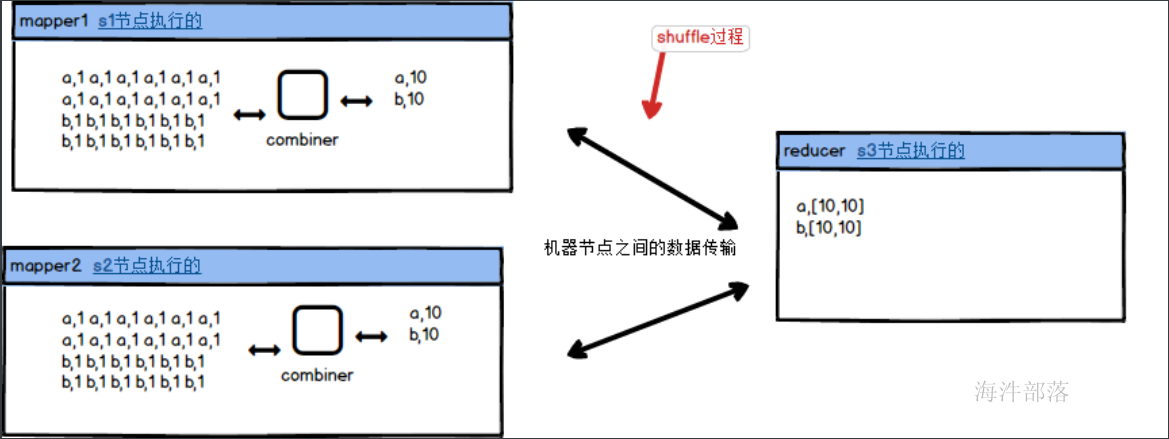
combiner可以任务是map端的一个组件可以进行reducer一样的逻辑聚合,先聚合完毕以后将数据输出到map的文件中,可以大大减少reducer端拉取数据的数据量大小,这个过程也叫作mapper端的reducer
combiner的代码开发如下:
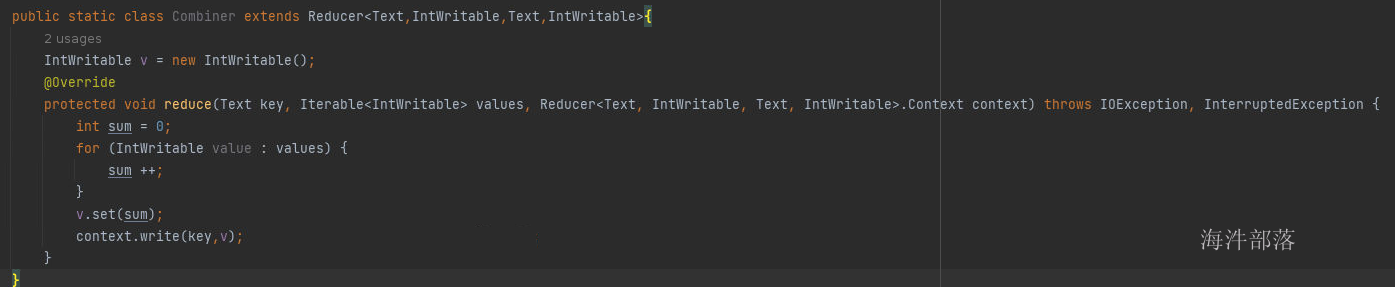
代码逻辑和reducer的逻辑完全一致
设定combiner逻辑代码
job.setCombinerClass(Combiner.class);整体代码如下:
package com.hainiu.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class WordCount {
public static class WCMapper extends Mapper<LongWritable, Text,Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
for (String str : strs) {
k.set(str);
context.write(k,v);
}
}
}
public static class Combiner extends Reducer<Text,IntWritable,Text,IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum ++;
}
v.set(sum);
context.write(key,v);
}
}
public static class WCReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum ++;
}
v.set(sum);
context.write(key,v);
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(WordCount.class);
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
TextInputFormat.addInputPath(job,new Path("data/word.txt"));
job.setCombinerClass(Combiner.class);
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
TextOutputFormat.setOutputPath(job,new Path("data/res"));
job.waitForCompletion(true);
}
}
结果没有任何变化
但是我们可以看到执行日志中的数据量发生了变化
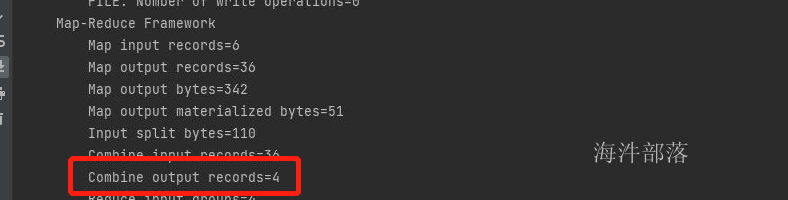
因为我们的数据是hello world hello tom hello jack
一个map的数据会先聚合然后在整体输出文件,所有的单词都会先进行聚合到一个结果进行输出,所以有四种key那么输出的条数相应的也应该是四个

我们发现flush是写出数据,done是完成写出,那么combiner一定在中间执行的,中间的方法是sortAndSpill
所以我们去这个方法中找寻combiner的调用

判断是否存在combiner,如果不存在那么就直接写出数据,如果存在就先进行合并数据

我们看到这个combine方法是一个抽象方法,找到他的实现类

选择new的实现类

我们发现调用的方法就是reducer,所以combiner其实就是map端的reducer
4.分区器
首先我们应该知道map的个数是按照文件的block的数量进行适配的,一般我们会按照128M进行数据切片和block的大小是完全适配的,最后一个block块的大小是按照1.1的比例进行划分的,也是符合12.8和140.8之间会单独形成一个切片,然后根据切片数量形成mapper端的task任务的数量
但是reducer的数量在默认不设置的情况下,默认是1个,我们也可以人为设置reducer的个数
因为有的时候数据量太大一个reducer没有办法处理全部的数据进行计算,因为一个reduce会将结果数据输出一个单独的文件中,有时候我们可能会遇见将数据分类输出的问题,所以可能会涉及到多个reduce协同工作
这个时候我们就需要一个专业的管理工具,分区器,它是规定数据从mapper端如何去往相应的reducer端的一个逻辑分类器
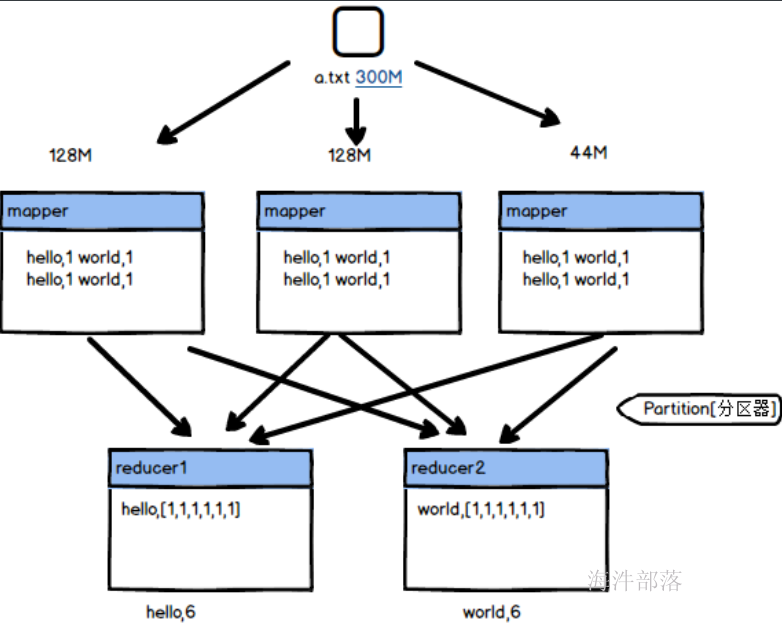
现在我们将上面的wordcount的reducer的任务个数设定为2
job.setNumReduceTasks(2)
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(WordCount.class);
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
TextInputFormat.addInputPath(job,new Path("data/word.txt"));
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
TextOutputFormat.setOutputPath(job,new Path("data/res"));
job.setNumReduceTasks(2);
job.waitForCompletion(true);
}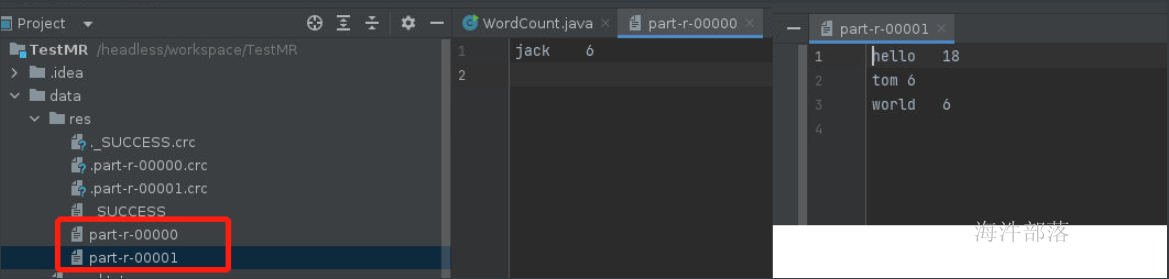
这样可以看到产生的数据计算结果为2,得出的文件中,分别将数据做了不同的分类,其中jack在part-r-00000文件中,hello tom world在part-r-00001文件中
针对于以上的数据分类我们并没有做任何的操作和逻辑的指定,这个分类是如何实现的呢?系统会自带一个默认的HashPartitioner的分区器,在job对象上面存在一个getPartitionerClass()的方法,我们没有任何的设定,但是可以获取一下

public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(WordCount.class);
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
TextInputFormat.addInputPath(job,new Path("data/word.txt"));
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
TextOutputFormat.setOutputPath(job,new Path("data/res"));
job.setNumReduceTasks(2);
System.out.println(job.getPartitionerClass());
job.waitForCompletion(true);
}
默认分区器显示为HashPartitioner,那么它的分区规则是什么呢?
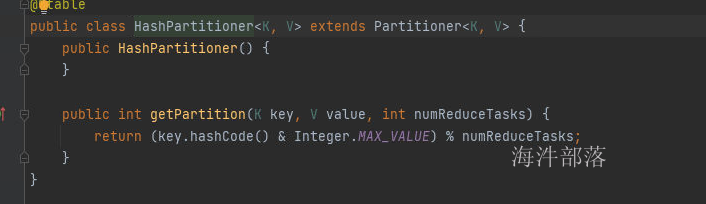
点开这个类以后我们发现其中存在一个getPartition方法,他会获取到map端输出的key和value的数据,然后根据相应的规则,返回分区的编号,其中numReducerTasks是我们设定reducer的任务个数,默认是1个,其实hash分区器的功能就是按照key的hashcode值和numReduceTask进行取余得到分区编号,比如我们的分区个数是两个,那么一个key的hashcode值和2进行取余得出就是0或者1,将数据按照这个规则分发到不同的分区
key.hashCode() & Integer.MAX_VALUE;
//这个操作就是将数据的二进制去除负号,得到hashcode正数的值,防止出现异常这个时候我们做一个验证,是否如规则所说
package com.hainiu.mr;
public class TestHashCode {
public static void main(String[] args) {
System.out.println("hello".hashCode());
System.out.println("world".hashCode());
System.out.println("jack".hashCode());
System.out.println("tom".hashCode());
}
}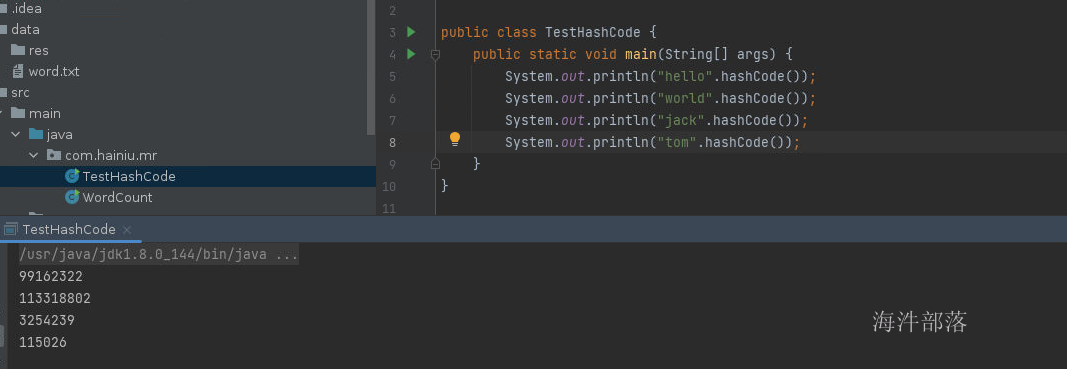
这个时候可以看到只有jack的hashcode值是奇数,其他的都是偶数,与我们刚才看到的计算规则一致
现在我们可以根据分区器实现数据的统计计算和数据分类输出
创建一个data/teacher.txt的文件
https://www.java.hainiu.com/xiniu
https://www.java.hainiu.com/xiniu
https://www.java.hainiu.com/xiniu
https://www.java.hainiu.com/xiniu
https://www.java.hainiu.com/xiniu
https://www.java.hainiu.com/xiniu
https://www.java.hainiu.com/hongniu
https://www.java.hainiu.com/hongniu
https://www.java.hainiu.com/hongniu
https://www.java.hainiu.com/hongniu
https://www.spark.hainiu.com/yeniu
https://www.spark.hainiu.com/yeniu
https://www.spark.hainiu.com/yeniu
https://www.spark.hainiu.com/yeniu
https://www.spark.hainiu.com/yeniu
https://www.spark.hainiu.com/yeniu
https://www.spark.hainiu.com/qingniu
https://www.spark.hainiu.com/qingniu
https://www.spark.hainiu.com/qingniu
https://www.spark.hainiu.com/qingniu
https://www.spark.hainiu.com/qingniu现在我们实现每个老师的访问量计算,以及按照不同的专业进行划分数据存储,这个时候我们就要自定义分区器,分区器的实现我们可以根据HashPartitioner的实现原理进行设计
public class MyPartitioner extends Partitioner<Text,IntWritable>然后根据获取的key进行拆分,得出不同的专业返回不同的分区编号
代码如下
package com.hainiu.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
import java.net.URL;
public class TeacherMR {
public static class TMapper extends Mapper<LongWritable,Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
URL url = new URL(value.toString());
//将数据转换为java自带的URL对象,能够方便获取其中的专业和老师数据
String host = url.getHost(); //获取的值为www.java.hainiu.com
String teacher = url.getPath();//获取的值为/yeniu
String subject = host.split("\\.")[1];
//切分完毕获取下标为1的数据就是专业
k.set(subject+teacher);
//输入结果和wordcount类似,spark/yeniu,1
context.write(k,v);
}
}
public static class TReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0 ;
for (IntWritable value : values) {
sum ++;
}
v.set(sum);
context.write(key,v);
}
}
public static class MyPartitioner extends Partitioner<Text,IntWritable>{
//自定义分区器逻辑,获取key的数据 spark/yeniu,6
//其中将key拆分完毕得到专业,根据专业导出分区编号
@Override
public int getPartition(Text text, IntWritable intWritable, int i) {
String[] strs = text.toString().split("/");
if(strs[0].equals("java"))
return 0;
else
return 1;
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(TeacherMR.class);
job.setMapperClass(TMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
TextInputFormat.addInputPath(job,new Path("data/teacher.txt"));
job.setReducerClass(TReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
TextOutputFormat.setOutputPath(job,new Path("data/res"));
job.setNumReduceTasks(2);
//设定分区器的类型为自定义分区器
job.setPartitionerClass(MyPartitioner.class);
job.waitForCompletion(true);
}
}
得出结果如下,数据按照专业已经分类实现

综上所述,我们得出在map和reducer之间是存在分区器的,它用于管理map端的数据根据什么逻辑进行数据的划分和分流
5.排序
数据在经由map端的数据流转以后到达reducer端,这个数据在流转的过程中会经过排序的过程,这个过程中会按照key的排序规则进行正向升序排列,然后传输到reducer端,这个过程是shuffle的非常重要的一个过程,它的原理如下图所示:
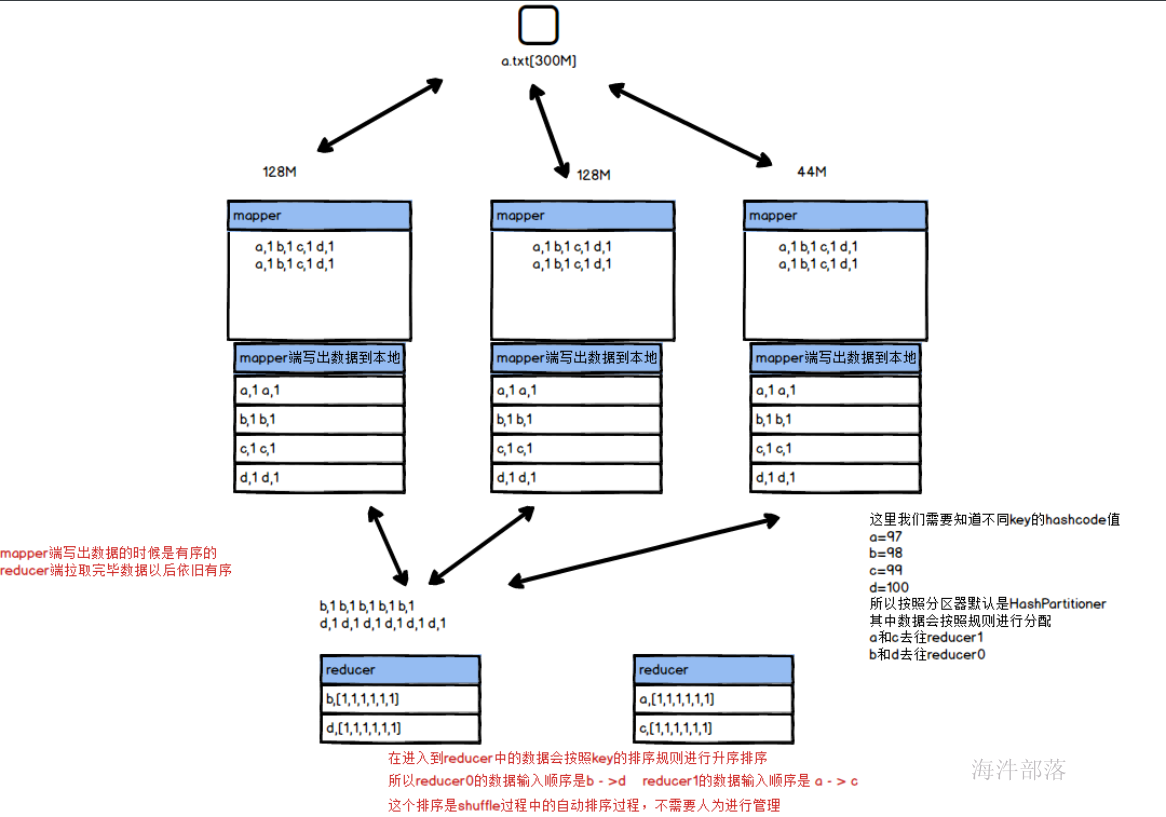
这个过程我们可以在上文的wordcount的案例得到结果,比如我们可以看到执行完毕的存储结果是
这里可以看出key是字符串,而字符串的排序规则是字典顺序,也就是按照字母a-z A-Z进行排序的,而数据中的元素分别为hello jack tom world 这几个单词的顺序为 h<j<t<w 所以输出顺序如上图所示
下面我们可以利用mr的shuffle过程中的排序规则对数据进行排序处理,完全不需要人为干扰,我们可以借力打力
思路:
将需要排序的数据放入到key中,然后系统会按照key进行自动排序,比如下面的数据,我们可以将分区当成key放入到mr中进行计算,自动可以进行排序处理,得出最终的结果是存在顺序的
首先创建 score.txt 用户存储学生信息
lisi 95
zhangsan 100
wangwu 97
zhaosi 96代码如下
package com.hainiu.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class TestSort {
public static class SMapper extends Mapper<LongWritable, Text, IntWritable,Text> {
Text v = new Text();
IntWritable k = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IntWritable, Text>.Context context) throws IOException, InterruptedException {
//拆分完毕数据将分数当成是key,name作为value值进行输出
String[] strs = value.toString().split(" ");
String name = strs[0];
int score = Integer.valueOf(strs[1]);
v.set(name);
k.set(score);
context.write(k,v);
}
}
public static class SReducer extends Reducer<IntWritable,Text,Text,IntWritable>{
@Override
protected void reduce(IntWritable key, Iterable<Text> values, Reducer<IntWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//reducer端按照key进行合并value到一起,但是因为分数都是单一的
//我们可以得出value值中只有一个元素,所以不用遍历可以直接取值
Text name = values.iterator().next();
context.write(name,key);
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(TestSort.class);
job.setMapperClass(SMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
TextInputFormat.addInputPath(job,new Path("data/score.txt"));
job.setReducerClass(SReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
TextOutputFormat.setOutputPath(job,new Path("data/res"));
job.waitForCompletion(true);
}
}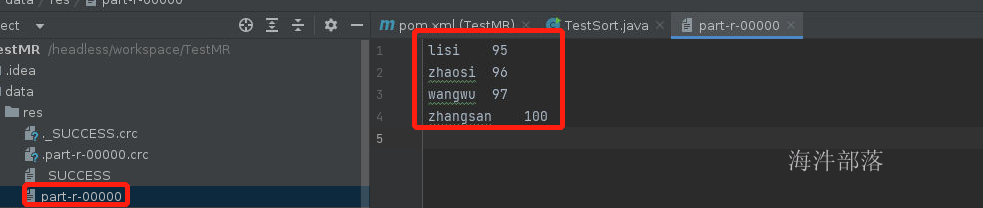
可以看到元素已经排序完毕了,但是默认是按照数值的升序进行排序的,因为int类型的数据是按照数字进行升序排序的,这个时候我们如果想要进行降序排序的话怎么实现呢???
6.指定key的排序规则
带着上面的问题,我们可以指定默认系统是按照key的排序规则进行升序排序的,如果我们想要人为干扰一下排序规则应该怎么做呢?
job.setSortComparatorClass();job中是可以设定排序规则干扰器的
这个时候我们引出一个新的比较器的类
WritableComparator这个类可以允许我们对已经存在的key的比较规则进行重新设定
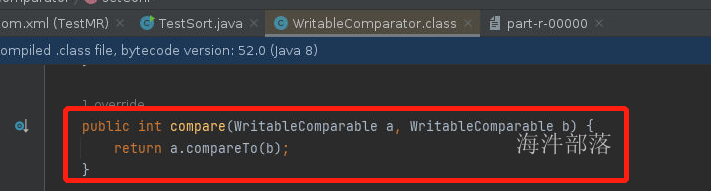
打开这个类我们会发现它的实现方式就是在shuffle过程中完全依赖key的原生比较规则进行比较的,那么我们可以使用一个子类继承这个类,并且实现shuffle过程中比较方式的重新定义
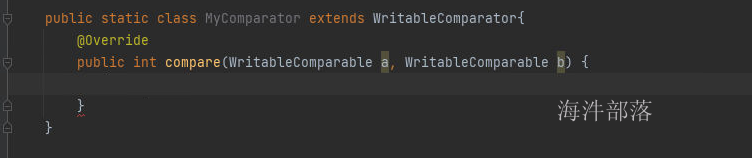
在这里我们可以实现类的重新定义和比较,其中a和b都是key的元素,因为在上一个案例中我们知道key的类型是IntWritable,所以这里我们可以直接转换这个类型,然后根据值进行重新定义比较就可以了
这里需要告知系统key的类型为IntWritable类型
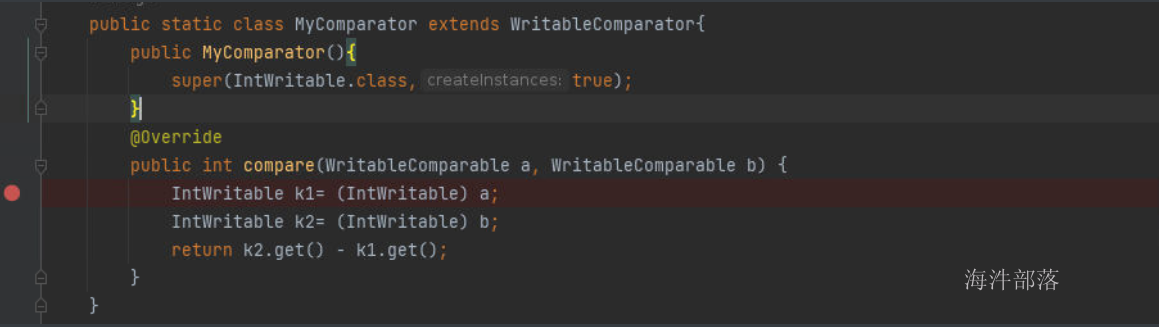
并且设定比较器在job中

全量代码为:
package com.hainiu.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class TestSort {
public static class SMapper extends Mapper<LongWritable, Text, IntWritable,Text> {
Text v = new Text();
IntWritable k = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IntWritable, Text>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
String name = strs[0];
int score = Integer.valueOf(strs[1]);
v.set(name);
k.set(score);
context.write(k,v);
}
}
public static class SReducer extends Reducer<IntWritable,Text,Text,IntWritable>{
@Override
protected void reduce(IntWritable key, Iterable<Text> values, Reducer<IntWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
Text name = values.iterator().next();
context.write(name,key);
}
}
public static class MyComparator extends WritableComparator{
public MyComparator(){
super(IntWritable.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
IntWritable k1= (IntWritable) a;
IntWritable k2= (IntWritable) b;
return k2.get() - k1.get();
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(TestSort.class);
job.setMapperClass(SMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
TextInputFormat.addInputPath(job,new Path("data/score.txt"));
job.setReducerClass(SReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
TextOutputFormat.setOutputPath(job,new Path("data/res"));
job.setSortComparatorClass(MyComparator.class);
job.waitForCompletion(true);
}
}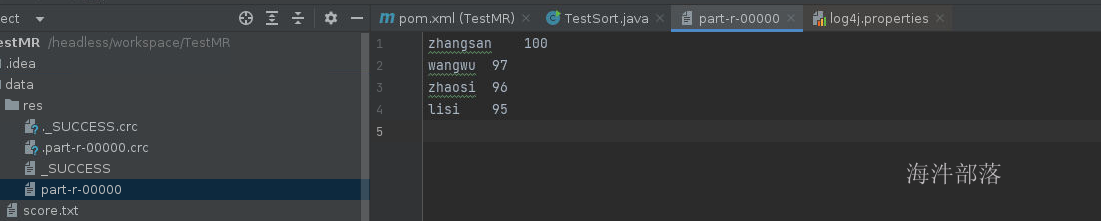
这里我们可以看见数据已经倒序排序了
7.自定义排序规则
上面案例中我们可以知道数据的排序默认是按照key的排序规则实现的,同时我们可以更改shuffle过程不要使用key的排序规则,使用我们人为设定的,但是如果我们自己设定了key的排序规则默认就是倒序就不用更改shuffle的过程了
这个时候我们需要使用一个类WritableComparable
因为key要排序所以,这个key的类型必须要实现Comparable才可以进行比较,同时因为数据要经历shuffle的过程,这个时候要从mapper中输出存储到文件,并且远程拉取到reducer端,那么这个数据也必须要经过序列化,所以必须实现writable接口才可以,那么这两个接口的统一实现方式就是WritableComparable

自定义类型比较的思路:
将所有的数据都放入到一个类型中,这个类型我们自己定义,并且在类型中指定类的比较器规则就可以了,但是这个类必须继承WritableComparable,然后重新定义其中的序列化方法和比较器方法,然后将数据进行封装当成key,系统就会按照比较规则进行比较数据的顺序了
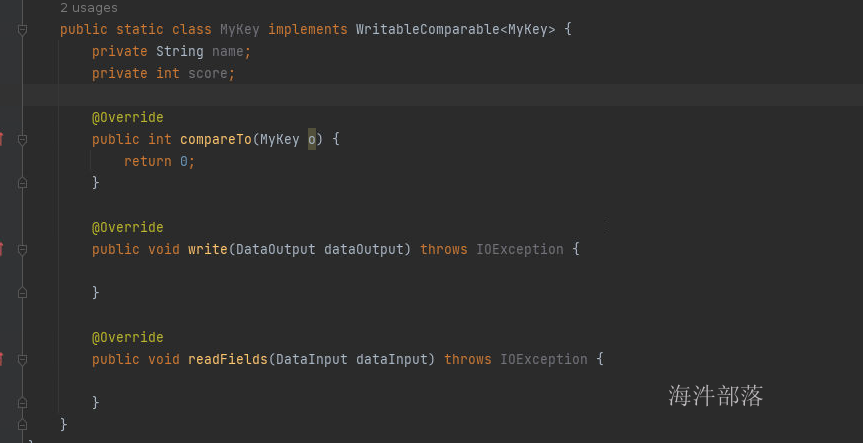
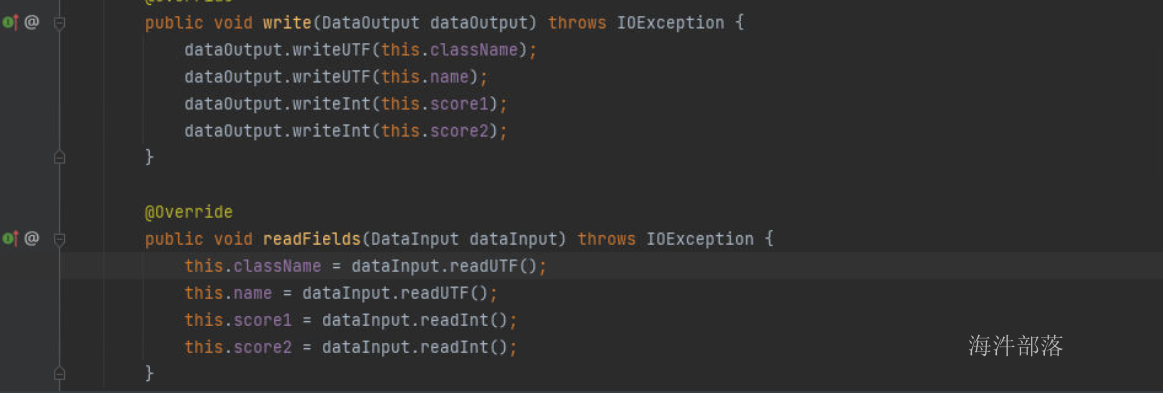
compareTo是比较方式,write和readFields是序列化和反序列化的方法
全量代码如下:
package com.hainiu.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Objects;
public class TestSort2 {
public static class MyKey implements WritableComparable<MyKey> {
private String name;
private int score;
public MyKey() {
}
public MyKey(String name, int score) {
this.name = name;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public int compareTo(MyKey o) {
return o.score - this.score;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.name);
dataOutput.writeInt(this.score);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.name = dataInput.readUTF();
this.score = dataInput.readInt();
}
}
public static class SMapper extends Mapper<LongWritable, Text,MyKey, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, MyKey, NullWritable>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
MyKey k = new MyKey(strs[0], Integer.valueOf(strs[1]));
context.write(k,NullWritable.get());
}
}
public static class SReducer extends Reducer<MyKey,NullWritable,Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable();
@Override
protected void reduce(MyKey key, Iterable<NullWritable> values, Reducer<MyKey, NullWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String name = key.getName();
int score = key.getScore();
k.set(name);
v.set(score);
context.write(k,v);
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(TestSort2.class);
job.setMapperClass(SMapper.class);
job.setMapOutputKeyClass(MyKey.class);
job.setMapOutputValueClass(NullWritable.class);
TextInputFormat.addInputPath(job,new Path("data/score.txt"));
job.setReducerClass(SReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
TextOutputFormat.setOutputPath(job,new Path("data/res"));
job.waitForCompletion(true);
}
}
最终得出结果已经排序完毕,这个是按照自定义的key的比较器类型进行比较的,主要思路就是自定类并且设定类的比较器规则
8.多条件排序
正如以上的思路,我们定义一个类型以后设定它的比较器规则以后系统会自动按照这个规则进行比较,那么我们在比较器中就可以定义多条件的比较规则实现,比如下面的数据,我们可以实现多条件排序
在data文件夹下面创建score2.txt
zhangsan 100 98
lisi 100 97
wangwu 98 95
zhaosi 98 93
liuneng 99 92
guangkun 99 91我们可以先按照第一列值进行排序,如果第一列值相同可以按照第二列进行排序,这个就是比较出名的二次排序的实现,其中二次排序说的就是按照条件进行两次排序

全部代码如下:
package com.hainiu.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class TestSort3 {
public static class MyKey implements WritableComparable<MyKey> {
private String name;
private int score1;
private int score2;
public MyKey() {
}
public MyKey(String name, int score1, int score2) {
this.name = name;
this.score1 = score1;
this.score2 = score2;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore1() {
return score1;
}
public void setScore1(int score1) {
this.score1 = score1;
}
public int getScore2() {
return score2;
}
public void setScore2(int score2) {
this.score2 = score2;
}
@Override
public int compareTo(MyKey o) {
if(o.score1 == this.score1){
return o.score2 - this.score2;
}else{
return o.score1 - this.score1;
}
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.name);
dataOutput.writeInt(this.score1);
dataOutput.writeInt(this.score2);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.name = dataInput.readUTF();
this.score1 = dataInput.readInt();
this.score2 = dataInput.readInt();
}
}
public static class SMapper extends Mapper<LongWritable, Text,MyKey, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, MyKey, NullWritable>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
MyKey k = new MyKey(strs[0], Integer.valueOf(strs[1]),Integer.valueOf(strs[2]));
context.write(k,NullWritable.get());
}
}
public static class SReducer extends Reducer<MyKey,NullWritable,Text, Text>{
Text k = new Text();
Text v = new Text();
@Override
protected void reduce(MyKey key, Iterable<NullWritable> values, Reducer<MyKey, NullWritable, Text, Text>.Context context) throws IOException, InterruptedException {
String name = key.getName();
int score1 = key.getScore1();
int score2 = key.getScore2();
k.set(name);
v.set(score1+" "+score2);
context.write(k,v);
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(TestSort3.class);
job.setMapperClass(SMapper.class);
job.setMapOutputKeyClass(MyKey.class);
job.setMapOutputValueClass(NullWritable.class);
TextInputFormat.addInputPath(job,new Path("data/score2.txt"));
job.setReducerClass(SReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
TextOutputFormat.setOutputPath(job,new Path("data/res"));
job.waitForCompletion(true);
}
}输出结果为:

9.分区器加排序实现整体排序
在开发的场景中有的时候我们会遇见这样的一个问题,比如上面的分数数据,我们想要实现整体的排序,并且实现多个类别的数据进行分类计算和存储,那么我们应该怎么做呢?
在data下面创建score3.txt
class1 zhangsan 100 98
class2 lisi 100 97
class1 wangwu 98 95
class2 zhaosi 98 93
class1 liuneng 99 92
class2 guangkun 99 91将以下数据进行按照原来规则排序,但是我们要求数据按照班级分到不同的文件中存储,那么我们就需要多个reducer进行计算,这样才能实现多个reducer排序和分类,那么我们不仅仅需要多个reducer还需要自己设定分区器的逻辑,实现分区器的规则定义
思路:
1.定义分区器按照班级进行分类
2.定义排序规则规则实现自定义排序
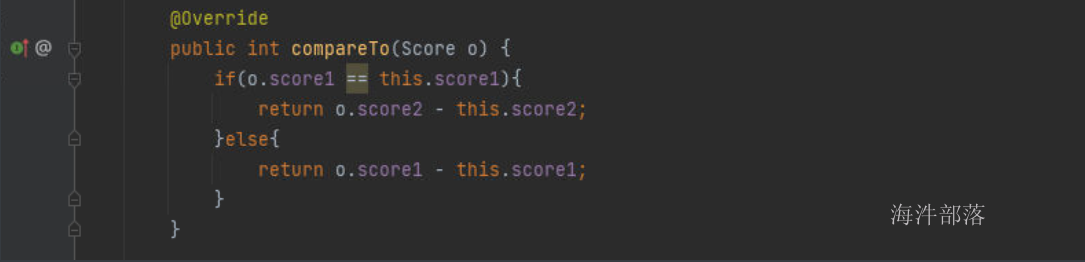
定义序列化和比较规则
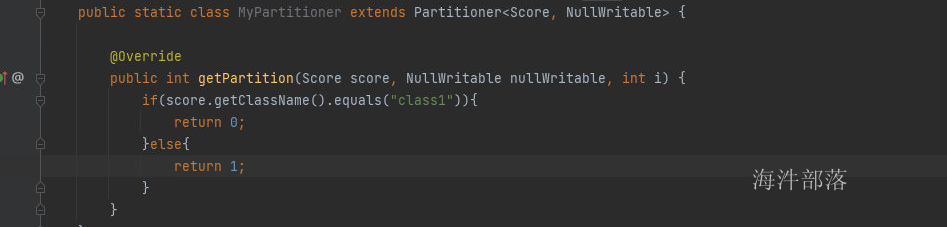
定义分区器逻辑
整体代码实现:
package com.hainiu.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class TestSort3 {
public static class Score implements WritableComparable<Score> {
private String className;
private String name;
private Integer score1;
private Integer score2;
@Override
public String toString() {
return className+"->"+name+"->"+score1+"->"+score2;
}
public String getClassName() {
return className;
}
public void setClassName(String className) {
this.className = className;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getScore1() {
return score1;
}
public void setScore1(Integer score1) {
this.score1 = score1;
}
public Integer getScore2() {
return score2;
}
public void setScore2(Integer score2) {
this.score2 = score2;
}
public Score() {
}
public Score(String className, String name, Integer score1, Integer score2) {
this.className = className;
this.name = name;
this.score1 = score1;
this.score2 = score2;
}
@Override
public int compareTo(Score o) {
if(o.score1 == this.score1){
return o.score2 - this.score2;
}else{
return o.score1 - this.score1;
}
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.className);
dataOutput.writeUTF(this.name);
dataOutput.writeInt(this.score1);
dataOutput.writeInt(this.score2);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.className = dataInput.readUTF();
this.name = dataInput.readUTF();
this.score1 = dataInput.readInt();
this.score2 = dataInput.readInt();
}
}
public static class MyPartitioner extends Partitioner<Score, NullWritable> {
@Override
public int getPartition(Score score, NullWritable nullWritable, int i) {
if(score.getClassName().equals("class1")){
return 0;
}else{
return 1;
}
}
}
public static class SMapper extends Mapper<LongWritable, Text,Score,NullWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Score, NullWritable>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
String className = strs[0];
String name = strs[1];
int score1 = Integer.valueOf(strs[2]);
int score2 = Integer.valueOf(strs[3]);
context.write(new Score(className,name,score1,score2),NullWritable.get());
}
}
public static class SReducer extends Reducer<Score,NullWritable,Score,NullWritable>{
@Override
protected void reduce(Score key, Iterable<NullWritable> values, Reducer<Score, NullWritable, Score, NullWritable>.Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(TestSort3.class);
job.setMapperClass(SMapper.class);
job.setMapOutputKeyClass(Score.class);
job.setMapOutputValueClass(NullWritable.class);
TextInputFormat.addInputPath(job,new Path("data/score3.txt"));
job.setReducerClass(SReducer.class);
job.setOutputKeyClass(Score.class);
job.setOutputValueClass(NullWritable.class);
TextOutputFormat.setOutputPath(job,new Path("data/res"));
job.setNumReduceTasks(2);
job.setPartitionerClass(MyPartitioner.class);
job.waitForCompletion(true);
}
}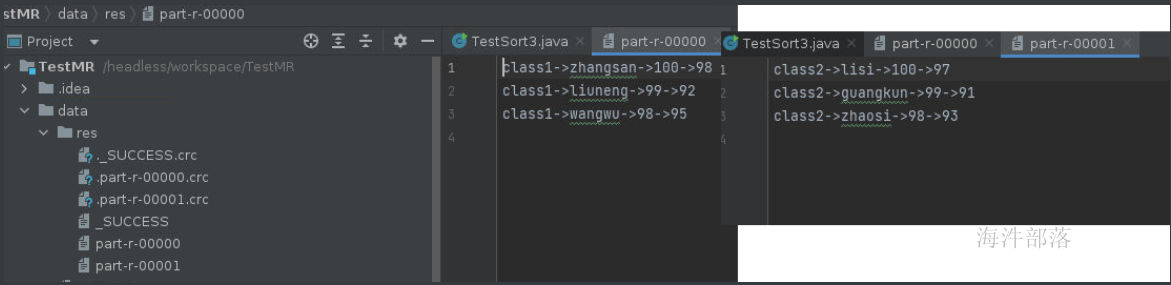
得出排序结果,已经按照班级分类,并且带有顺序
10.分组
通过以上的讲解我们知道map端的数据在到达reducer端中间的过程叫做shuffle,在这个过程中数据会按照key进行分组,合并到一起然后传输到reducer端,这个过程是自动进行分类的,如下图所示
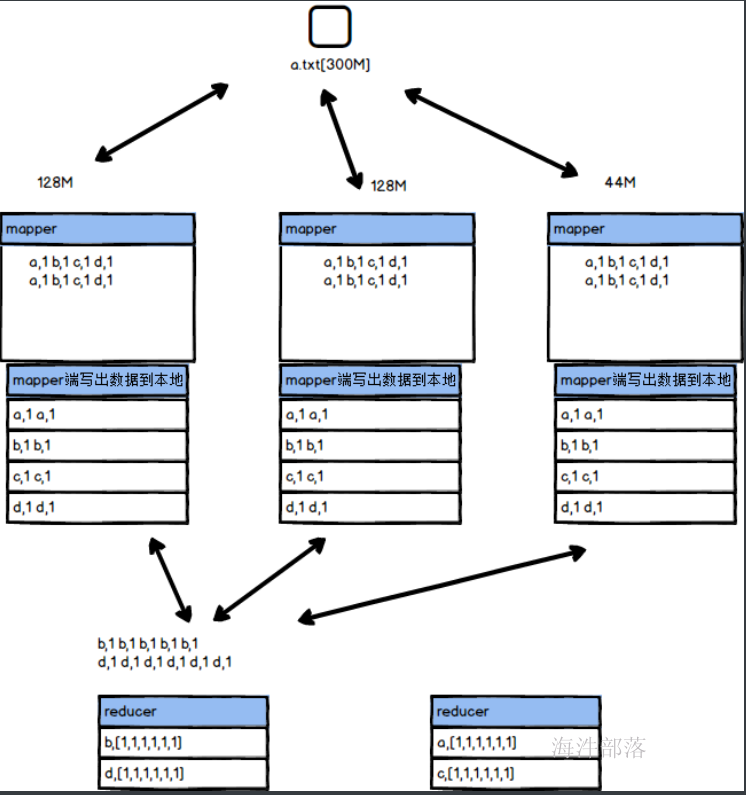
数据在shuffle的传输过程中,首先数据在mapper写出数据到本地的时候经过缓存是有顺序的,其次数据在reducer端拉取过来数据的时候也是先排序的,所以数据在进入到reducer端之前就是存在顺序的
那么分组和排序是有什么必然联系吗????
带着这个问题我们可以做以下分析,其实shuffle的过程并没有做任何的分组操作,它是根据排序会将key相同的数据按顺序相近排序放到一起,所以分组就是将相同的key排列在一起的数据进行截取就是分组,这样就比较简单,不要单独处理进行分组
比如:
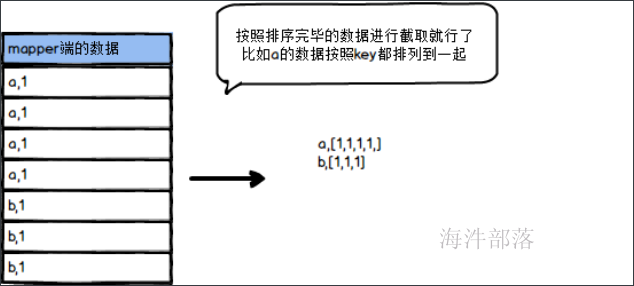
将数据分组处理,合并在一起作为整体的输入,因为reduce的本质工作就是分组处理,所以输入已经处理完毕,可以直接进行计算,节省了分组分类的操作流程
使用分组的流程我们可以实现以下操作
首先在data文件夹下面创建
score4.txt
class1 user1 87
class2 user2 98
class3 user3 93
class1 user4 99
class2 user5 91
class3 user6 92
class1 user7 65
class2 user8 97
class3 user9 83score5.txt
class1 user10 82
class2 user11 76
class3 user12 85
class1 user12 80
class2 user14 100
class3 user15 95我们的需求为求解出来班级分数的最大值,最小值,平均值
思路: 多个文件实现整体的计算,必须使用reducer将数据聚合到一起进行计算,将相同的数据作为key发送到reduce端进行分类处理,相同的数据会聚合到一起,比如上面的哪里我们将班级作为key进行输出,在reduce端所有的分数数据都会聚合到一起,然后整体进行处理
全量代码如下:
package com.hainiu.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class TestMaxMinAvg {
public static class TMapper extends Mapper<LongWritable, Text,Text,Text>{
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
String className = strs[0];
String name_and_score = strs[1]+" "+strs[2];
k.set(className);
v.set(name_and_score);
context.write(k,v);
}
}
public static class TReducer extends Reducer<Text,Text,Text, NullWritable>{
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
String className = key.toString();
String maxName = null;
Integer max = Integer.MIN_VALUE;
String minName = null;
Integer min = Integer.MAX_VALUE;
Integer sum = 0;
Integer count = 0;
for (Text value : values) {
String[] strs = value.toString().split(" ");
String username = strs[0];
Integer score = Integer.valueOf(strs[1]);
sum += score;
count += 1;
if(score>max){
max=score;
maxName = username;
}
if(score<min){
min = score;
minName = username;
}
}
context.write(new Text(className+"最大值为:"+maxName+" "+max),NullWritable.get());
context.write(new Text(className+"最小值为:"+minName+" "+min),NullWritable.get());
context.write(new Text(className+"平均值为:"+(sum*1.0/count)),NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(TestMaxMinAvg.class);
job.setMapperClass(TMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
TextInputFormat.addInputPath(job,new Path("data/score4.txt"));
TextInputFormat.addInputPath(job,new Path("data/score5.txt"));
job.setReducerClass(TReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
TextOutputFormat.setOutputPath(job,new Path("data/res"));
job.waitForCompletion(true);
}
}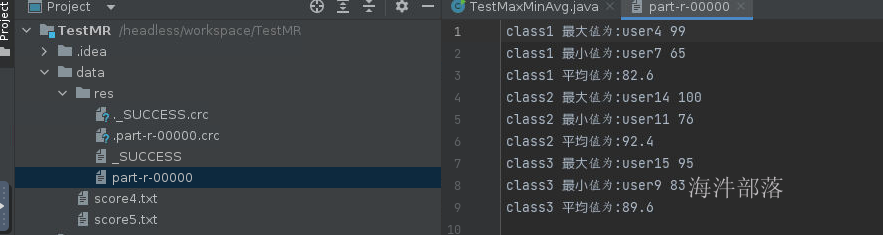
我们可以得到最终的结果如图
combiner实现topN的优化
以上是通过reducer实现的代码求解topN,但是这个压力全部都给到reducer了,我们可以在mapper端增加一个combiner进行预合并求出每个班级的最大值最小值和平均值然后进行二次合并求出,这个时候combiner的输出结果key是非常重要的,因为要在reducer端进行整体的合并
整体代码如下:
package com.hainiu.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class ReducerTopWithCombiner {
public static class TMapper extends Mapper<LongWritable, Text,Text,Text>{
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
String class_name = strs[0];
String name = strs[1];
String score = strs[2];
k.set(class_name);
v.set(name+" "+score);
context.write(k,v);
}
}
public static class Combiner extends Reducer<Text,Text,Text,Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String class_name = key.toString();
int count = 0;
int sum = 0;
String max_name = null;
int max = Integer.MIN_VALUE;
String min_name = null;
int min = Integer.MAX_VALUE;
for (Text value : values) {
String[] strs = value.toString().split(" ");
String name = strs[0];
int score = Integer.valueOf(strs[1]);
count ++;
sum += score;
if(score > max){
max = score;
max_name = name;
}
if(score<min){
min = score;
min_name = name;
}
}
context.write(new Text(class_name+":max"),new Text(max_name+" "+max));
context.write(new Text(class_name+":min"),new Text(min_name+" "+min));
context.write(new Text(class_name+":sum_count"),new Text(sum+"_"+count));
}
}
public static class TReducer extends Reducer<Text,Text,Text,Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String className = key.toString().split(":")[0];
if(key.toString().contains("sum_count")){
int count = 0;
int sum = 0;
for (Text value : values) {
String[] strs = value.toString().split("_");
int current_sum = Integer.valueOf(strs[0]);
int current_count = Integer.valueOf(strs[1]);
count += current_count;
sum += current_sum;
}
context.write(new Text(className+":??"),new Text(sum+""));
double avg = sum*1.0/count;
context.write(new Text(className+":???"),new Text(avg+""));
}
if(key.toString().contains("max")){
String max_name = null;
Integer max = Integer.MIN_VALUE;
for (Text value : values) {
String[] strs = value.toString().split(" ");
String name = strs[0];
int number = Integer.valueOf(strs[1]);
if(number>max){
max = number;
max_name = name;
}
}
context.write(new Text(className+":???"),new Text(max_name+" "+max));
}
if(key.toString().contains("min")){
String min_name = null;
Integer min = Integer.MAX_VALUE;
for (Text value : values) {
String[] strs = value.toString().split(" ");
String name = strs[0];
int number = Integer.valueOf(strs[1]);
if(number<min){
min = number;
min_name = name;
}
}
context.write(new Text(className+":???"),new Text(min_name+" "+min));
}
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(ReducerTopWithCombiner.class);
job.setMapperClass(TMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(TReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setCombinerClass(Combiner.class);
TextInputFormat.addInputPath(job,new Path("data/score4.txt"));
TextInputFormat.addInputPath(job,new Path("data/score5.txt"));
job.setNumReduceTasks(2);
FileSystem fs = FileSystem.getLocal(conf);
Path out = new Path("data/res");
if(fs.exists(out))
fs.delete(out,true);
TextOutputFormat.setOutputPath(job,out);
job.waitForCompletion(true);
}
}
11.利用分组实现reducer端join
多个文件中有多个种类的数据,这些数据可以使用reduce端的进行数据的合并联合在一起,思路就是多个map的数据输出,如果两个文件中比如按照id进行关联到一起,那么我们可以在两个map端都将这个id作为key进行输出,他们就可以直接关联到一起了,因为分组就是将key相同的数据放到一个组中
我们使用上面map端实现join的数据进行join关联操作
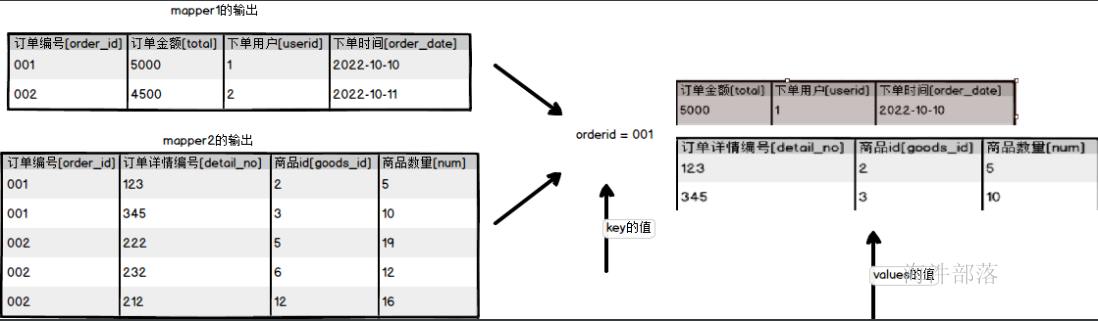
首先准备两个文件
data下面创建order.txt
001,5000,1,2022-10-10
002,4500,2,2022-10-11data下面创建detail.txt
001,123,2,5
001,345,3,10
002,222,5,19
002,232,6,12
002,212,12,16以上思路我们就可以直接将相同key的数据在reducer端使用分组的原理合并在一起了,但是问题是我们在reducer端没有办法知道数据究竟来自于哪个文件,后续的处理逻辑不是特别清晰,所以我们在map端输出的时候就要加上文件的标识,后续可以根据标识进行文件的逻辑计算,这段逻辑在map端的setup方法中执行,在执行逻辑之前就获取到文件的名称
整体代码如下:
package com.hainiu.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class ReduceJoin {
public static class JMapper extends Mapper<LongWritable,Text, Text,Text>{
String mark = null;
@Override
protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
InputSplit inputSplit = context.getInputSplit();
FileSplit split = (FileSplit) inputSplit;
//获取数据切片,这样可以获取路径中的文件名
Path path = split.getPath();
String name = path.getName();
if(name.contains("order")){
mark = "o_";
//分别做不同的标识
}else{
mark = "d_";
}
}
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(",");
k.set(strs[0]);
//不管是哪个文件都将order_id当成是key进行输出
v.set(mark+strs[1]+"\t"+strs[2]+"\t"+strs[3]);
context.write(k,v);
}
}
public static class JReducer extends Reducer<Text,Text,Text,Text>{
@Override
protected void setup(Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
context.write(new Text("order_id"), new Text("total\tserid\tsorder_date\tsdetail_no\tsgoods_id num"));
//使用setup方法预先输出列的名称信息
}
Text v = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String order_info = null; //因为订单信息只有一个
List<String> detail_info = new ArrayList<String>();
//订单详情数据存储很多,使用集合装入
for (Text value : values) {
String line = value.toString();
if(line.startsWith("o_"))
//分别根据不同的标识放入到不同的位置
order_info = line.substring(2);
else
//将标识删除
detail_info.add(line.substring(2));
}
for (String s : detail_info) {
v.set(order_info +"\t"+s);
//按照文件的类型进行顺序拼接
context.write(key,v);
}
}
}
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setJarByClass(ReduceJoin.class);
job.setMapperClass(JMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
TextInputFormat.addInputPath(job,new Path("data/order.txt"));
TextInputFormat.addInputPath(job,new Path("data/detail.txt"));
job.setReducerClass(JReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
TextOutputFormat.setOutputPath(job,new Path("data/res"));
job.waitForCompletion(true);
}
}
结果可以看到相同key的数据完美的join到了一起,并且可以根据数据类别进行排序输出
12.shuffle的整体流程
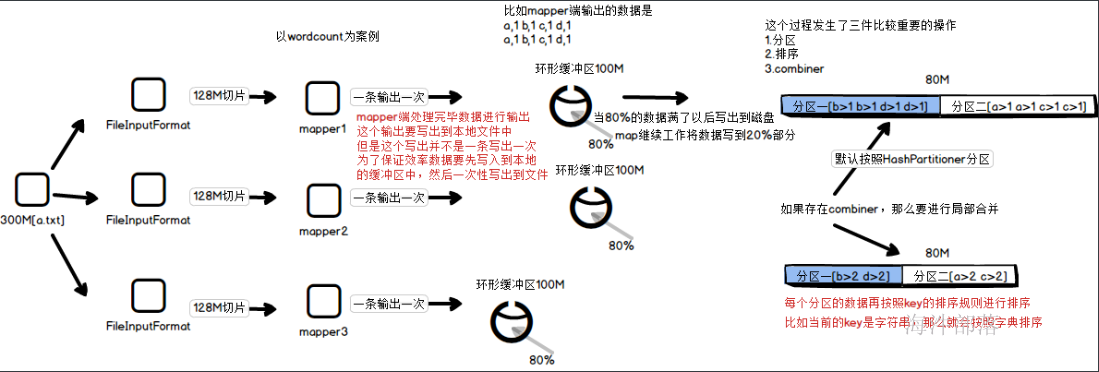
到这里是shuffle的第一个部分,shuffle的溢写阶段就完成了
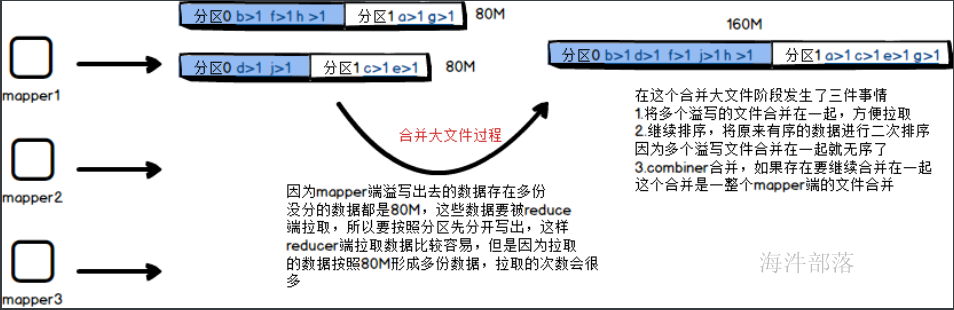
第二个阶段合并大文件阶段
到此为止数据会放入到本地磁盘等待reducer端拉取数据
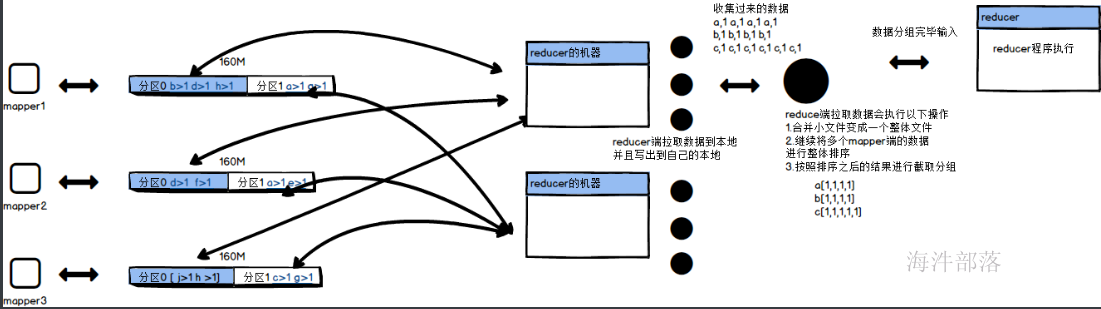
这个部分为reduce部分
shuffle的过程分为三个比较重要的阶段
1.溢写阶段
map端的数据是一条一条写出的,但是不能一条一条的将数据直接写出到缓存文件中,这个过程太慢,为了考虑到性能,也为了在写出的时候可以对内容进行二次的加工和操作,会将数据写出到缓存区中然后一次性写出到文件中,缓存区的大小为100M,其中我们只能使用到80%的部分,将数据写出到缓存区中以后,在写出到文件之前我们会先进行在内存中的分区和排序,就如上图所展示的,先进行按照分区器规则排序,然后按照key的排序规则进行比较后写出文件到磁盘中,每个文件的大小是80M,在这个过程中如果存在combiner的合并操作会进行合并,然后写出,这样会大大的减少溢写的文件2.合并大文件阶段
对于map端写出的数据最终要汇总到reducer端进行合并规约,这个文件要远程的拉取过来,map端一旦满足80M就会将数据写出到本地的中间文件中,但是reducer端拉取的数据太多了,因为存在多个map端,map端又会多次写出数据到本地,这个时候reducer要拉取的数据就会很多,为了增加reducer拉取数据的效率,会将溢写出来的小文件进行合并,先在map端将多个80M的部分合并成一个部分,这个时候相应分区中的数据会合并在一起,然后进行重新排序,让数据在原本有序的基础上进行快速排序,生成一个大的文件方便拉取,所以这个时候会发生三个事情,合并大文件,继续排序,有combiner的话会继续进行map端数据的combiner3.reducer端拉取数据
map端的任务全部都运行完毕,reducer端开始拉取数据过来进行计算合并规约,这个拉取的过程和map端溢写数据的过程很像,它首先将数据放入到自己的内存中,然后在写出数据到自己的本地,这个过程会拉取所有map端的文件过来,这个时候小文件也会很多,我们会将多个写出到本地的数据进行合并到一起,这个时候会合并的成一个文件,并且reducer端会继续进行排序,因为每个map虽然有序,但是合并到一起要重新进行排序,最后会按照key将数据放入到一个组中,然后输入数据给reducer端进行计算处理以上就是将所有的原理进行整体的合并总结,也是是完整的shuffle流程


