Hbase安装和DDL
1.hbase的简述
在学习hbase之前同学们已经学习完毕了hdfs和yarn以及mr,hbase作为google的大数据三篇比较重要的论文之一,它的起源叫做bigtable,意思非常简单就是大表的意思,是一个分布式存储很多数据的大型表格系统,它是对于hdfs中的数据不能直观查询和随机读写的病痛的一个补充和完善
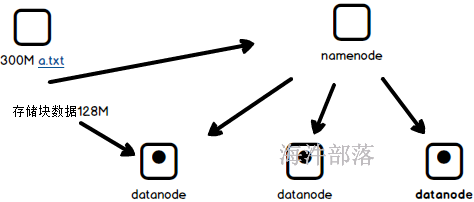
hdfs中的数据是整存整去的数据体,按照128M进行拆分然后分布式存储,我们之前学过这个组件,hdfs能够很好的保证数据的稳定性和读取存储的高性能,同时具有很强的可靠性,但是这个数据只能整体的存储和读取使用,如果我们存储一堆重要的文件信息,想要读取其中某一条数据,或者修改其中的一个值或者删除一行内容是完全做不到的,比如读取我们需要整体进行读取,然后过滤出来我们想要的数据,假如数据是1T大小,我们只想要一行内容也需要将1T全部读取出来然后进行过滤,这个是非常低性能的,完全不能保证在大数据场景中的实时效果,而且完全不支持修改数据,想要修改数据必须要将数据全部都读取出来然后修改整个数据然后在重新存储到hdfs中,所以hdfs中的数据更像是一个仓库,里面非常粗粒度不能保证灵活性,至此hbase出现了
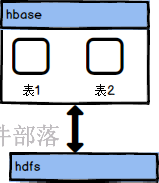
hbase并不提供数据存储,而是借助于hdfs进行数据存储,在这个基础之上实现了上层架构的一个管理和封装,它更像是一个给予内存的hdfs的管理组件,类比生活中更像是一个售卖柜台和一个商场的仓库的关系,柜台更加灵活的进行商品的售卖和购买,仓库中只是作为大量商品的存储,比较重量级和固定
2.hbase的原理
那么hbase是怎么进行hdfs上层管理的呢???
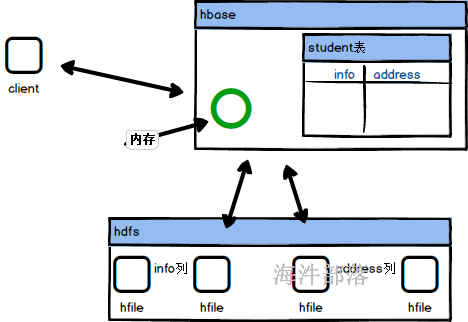
hbase首先是hdfs上层的一个管理层,hbase自身是带有元数据信息的,用来记录我们在hbase中创建了多少个表,并且每个表存在多少个列,这样就可以实现表格级别的使用和管理,并且会将表格的数据放入到hdfs中存储,为了方便查询和管理会按照表的列进行文件的存储和分类,比如info列就会存储到一个单独的hfile文件中,但是hbase中存储的数据会非常的多,那么一个列单独保存在一个hfile中,也是难管理和查询的,所以按照行级别进行数据的分割存储到不同的文件中,这样可以非常快速的检索出来数据,但是不能够解决掉数据的修改问题,因为底层是hdfs的存储,这样是没有办法灵活修改和变化的,这个时候hbase引入了一块内存区域,会将数据的修改和插入放入到内存中,一旦缓存区中的数据满了,那么就会将数据存储到hdfs中并且对数据进行修改和合并操作,能够保证灵活的数据修改,并且通过图中我们可以发现数据是按照列为一个整体进行存储的,所以查询效率会更高,大数据场景中存储的数据会存在很多列,那么我们只需要其中的两列就可以直接去相应的hfile中读取数据,不需要全部的hfile文件都扫描读取
从而实现灵活的数据随机读写
3.hbase的组成结构
hbase中的数据是存储到hdfs中的,但是hbase要管理hdfs中数据的元数据信息,并且对插入和修改的数据进行处理,在大数据场景中首先数据量会很大,而且表也会非常的多,那么hbase管理起来压力也会非常的大,所以hbase也是分布式的,多个机器共同分摊表数据的管理压力
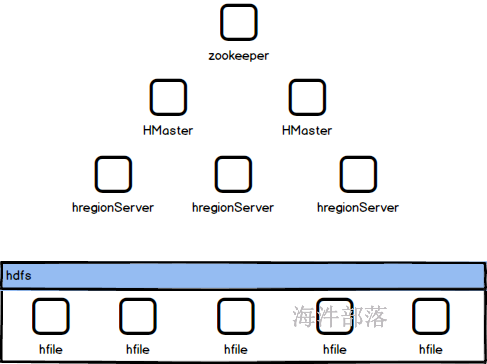
所以hbase中会存在很多个节点组件进行管理,首当其冲的就是hregionserver管理每个节点的数据,每个列的数据存储和hfile文件的管理,一般这些节点都会和hdfs的datanode节点部署到一起,hmaster主要是通过zookeeper对多个regionserver进行管理,并且管理整个集群中的元数据信息文件,为了防止hbase的Hmaster主节点的单机故障问题,使用zookeeper进行协调选举服务保证多个hmaster下的集群稳定问题
4.hbase的搭建
首先找到hdfs的基础镜像,里面包含了yarn和hdfs
http://cloud.hainiubl.com/?#/privateImageDetail?id=2959&imageType=private
五个节点 nn1 nn2 s1 s2 s3
nn1 [zk,namenode,resourceManager]
nn1 [zk,namenode,resourceManager]
s1 [zk,datanode,nodeManager]
s2 [datanode,nodeManager]
s3 [datanode,nodeManager]
但是在启动之前我们需要调节一下之前所设置的内存和核数的大小,原本的集群只能运行hdfs不能运行hbase,在这个基础上我们要进行调节
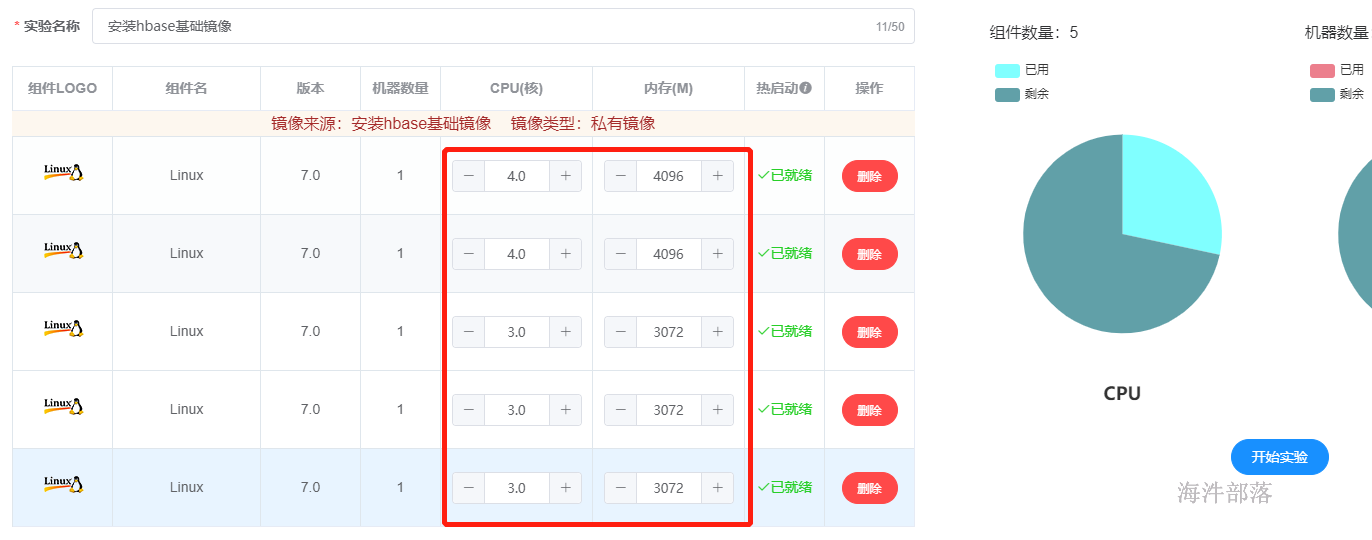
增加主节点的内存为4G核数为4,从节点的内存为3G核数为3
安装的步骤:
# 切换到hadoop用户
# 解压压缩包
ssh_root.sh tar -zxvf /public/software/bigdata/hbase-2.4.13-bin.tar.gz -C /usr/local/
#查看解压效果
ssh_all.sh ls /usr/local/|grep hbase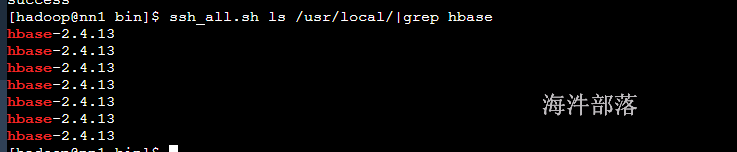
# 解压完毕我们需要设定权限和配置软连接
ssh_root.sh chown hadoop:hadoop -R /usr/local/hbase-2.4.13/
# 配置软连接
ssh_root.sh ln -s /usr/local/hbase-2.4.13/ /usr/local/hbase

解压完毕内容可以看到以上几个比较重要的包
- bin 执行脚本
- conf配置信息
- hbase-webapps 监控页面组件
- lib 支撑包
# 配置环境变量
# 在 /etc/profile中增加如下配置
echo 'export HBASE_HOME=/usr/local/hbase' >> /etc/profile
echo 'export PATH=$PATH:$HBASE_HOME/bin' >> /etc/profile
source /etc/profile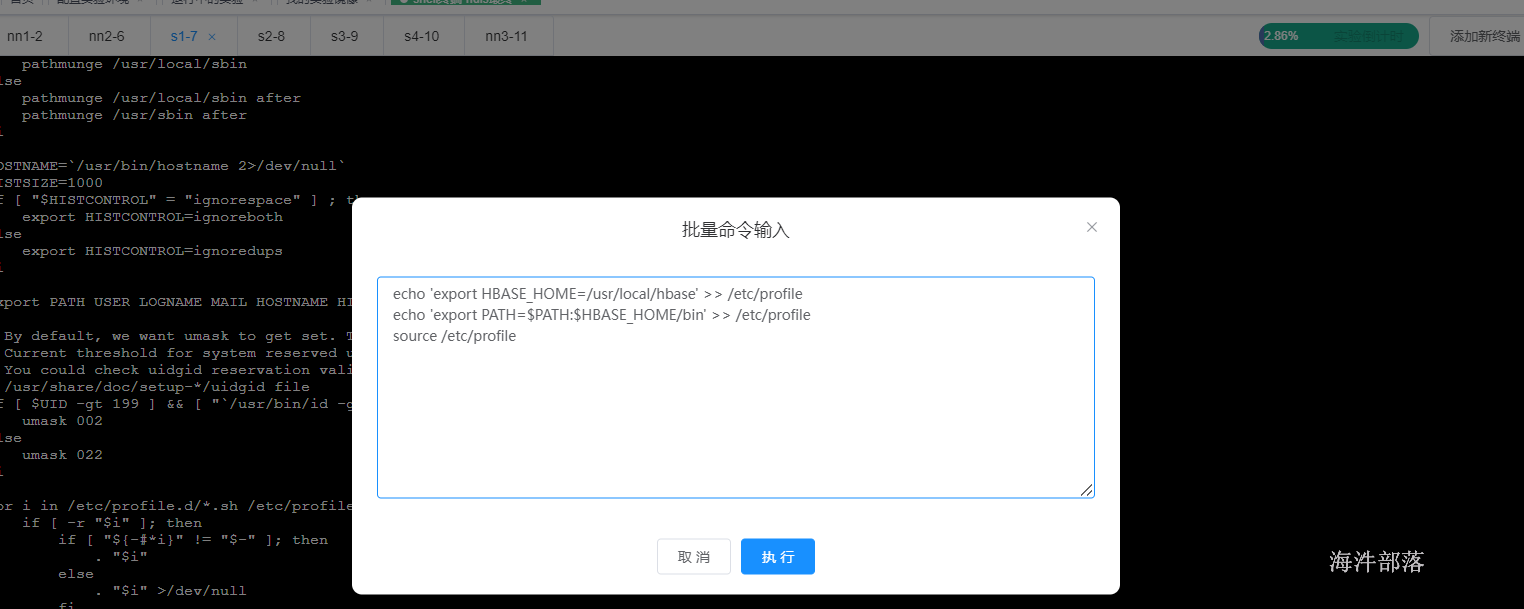
# 检验配置情况
ssh_all.sh hbase version
在hbase-env.sh中增加如下配置
# 关闭hbase自带zk,使用我们搭建的zookeeper集群
export HBASE_MANAGES_ZK=false
# 设定hbase的内存为1G
export HBASE_HEAPSIZE=1G
# 增加系统环境配置
source /etc/profile在hbase-site.xml中增加如下配置
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns1/hbase</value>
</property>
<!-- hbase在hdfs中的存储位置 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 开启hbase的全分布式 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<!-- zookeeper的端口号 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>nn1,nn2,s1</value>
</property>
<!-- zookeeper集群的主机名 -->
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<!-- hbase的临时文件存储路径 -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- 开启配置防止hmaster启动问题 -->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<!-- 监控页面端口 -->分发配置文件
scp_all.sh /usr/local/hbase/conf/hbase-env.sh /usr/local/hbase/conf/
scp_all.sh /usr/local/hbase/conf/hbase-site.xml /usr/local/hbase/conf/启动hbase
# 启动zookeeper
ssh_all_zk.sh /usr/local/zookeeper/bin/zkServer.sh start
# 启动hdfs
start-dfs.sh
# 启动hbase master 主节点
hbase-daemon.sh start master
# jps查看启动进程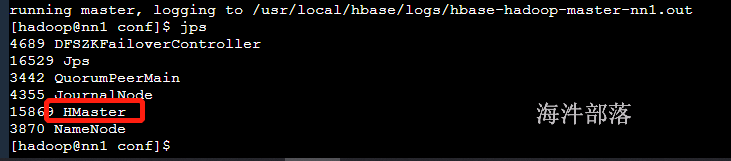
打开监控页面查看
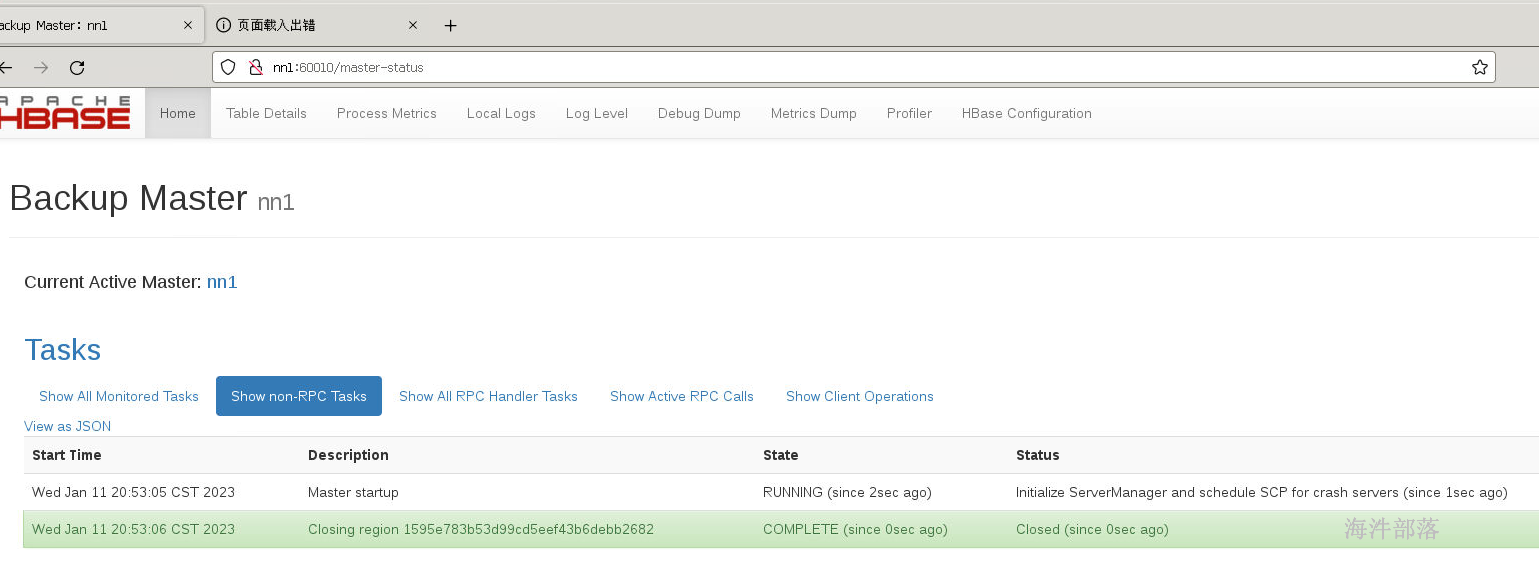
可以看到hbase的监控信息,但是只有一个master,这样会出现hbase的主从单点故障问题,为了解决这个问题我们需要再开启一个新的Hmaster服务在另一个节点上nn2
# nn2节点执行启动命令
hbase-daemon.sh start master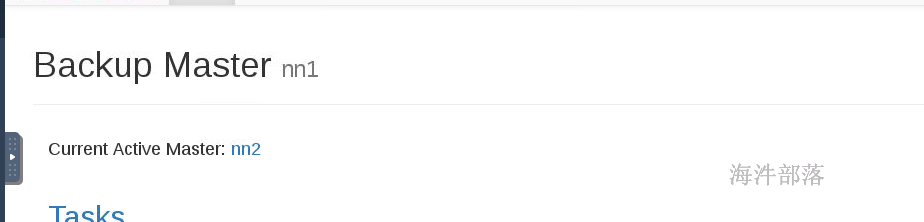
这个时候我们发现已经存在两个hmaster了,并且自动存在了主从
但是集群中没有任何的从节点,这个时候我们需要安装并且启动从节点
# 修改regionservers配置增加从节点信息
s1
s2
s3
# 分发数据到各个节点中
scp_all.sh /usr/local/hbase/conf/regionservers /usr/local/hbase/conf/
# 启动所有的从节点
hbase-daemons.sh start regionserver

我们发现所有的从节点已经启动,并且心跳也有显示
集群的群体启动和关闭命令如下:
# 启动命令
start-hbase.sh
# 关闭命令
stop-hbase.sh
# 但是第二个主节点要人为启动
# nn2节点执行
hbase-daemon.sh start master
hbase-daemon.sh stop master那么以上为止我们的hbase搭建就完毕了
5.hbase的表结构
在使用的时候hbase就是一个普通的表,但是hbase是一个列式存储的表结构,与我们常用的mysql等关系型数据库的存储方式不同,mysql中的所有列的数据是按照行级别进行存储的,查询数据要整个一行查询出来,不想要的字段也需要查询出来,hbase是列式存储的方式实现的,它的一个列的所有行都是存储为一份文件,在大数据场景中我们一般一个表的字段都会比较多,那么我们业务很多情况下是不需要查询出来所有的列的,所以列式存储会大大的减少数据查询带来的消耗问题,为我们的查询增加效率
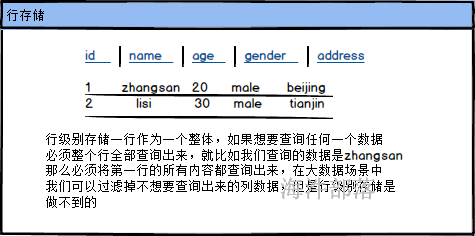
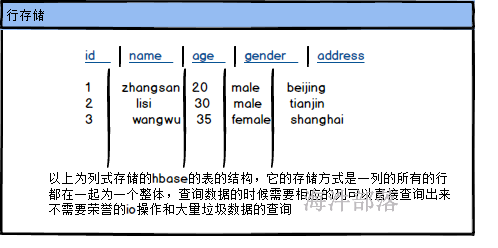
我们已经知道了hbase是列级别存储的,那么我们看具体的存储结构
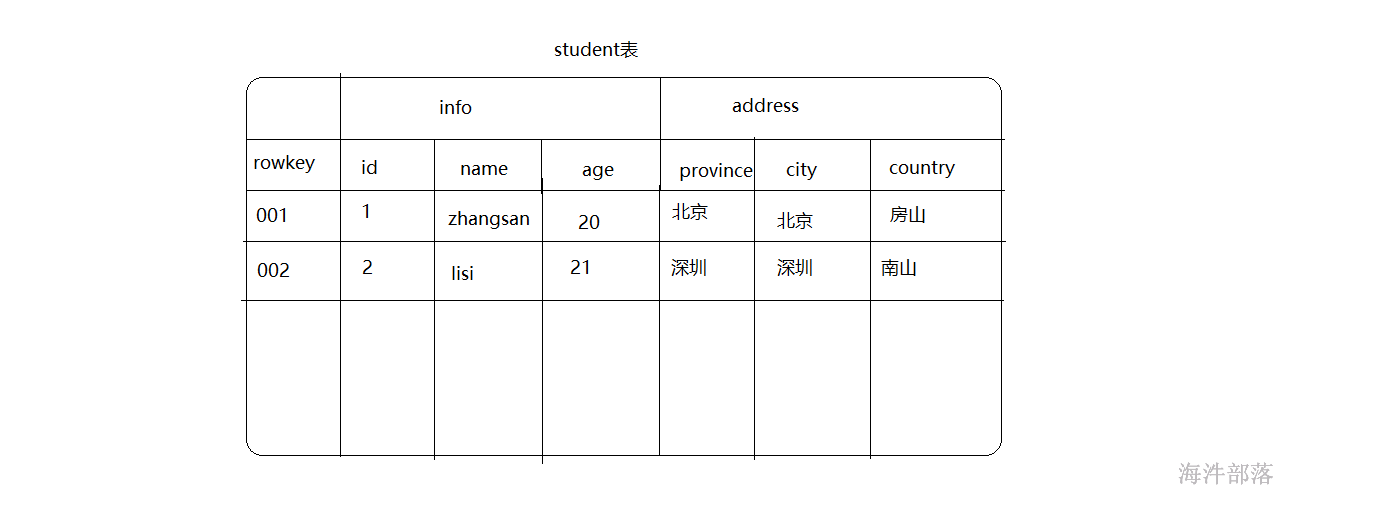
表中的数据结构rowkey是hbase表自带的主键,每个表中都会存在这样一个主键,它的格式为存储为Byte数组,什么样的数据都可以充当为rowkey进行存储,但是在存储的时候要转换为byte数组进行存储,并且数据是按照rowkey的字典顺序进行排序的
表中是存在列的,但是这个列以列族进行分类,比如info列族中存在三个列id,name,age 相应的列的存储数据类型也可以是任意的类型,但是都会以byte数组形式存储在hbase中
我们在使用hbase的表的时候,我们就按照上图的表格显示进行使用就可以了,但是实际的底层存储却不是我们所看到的样子
首先我们先要知道,hbase的表的数据操作分为两个类型,一个是put一个是delete,put是更新或者插入新的数据都使用这个命令它会自己覆盖数据,delete是删除数据,hbase的底层数据存储是hdfs,hdfs中的数据是不允许我们随意的进行操作和修改的,那么我们的所有操作都必须要先放入到自己的内存中然后在将数据写出到hdfs中,和hdfs中的数据进行合并处理,所以我们在hbase中真正存储的数据并不是按照表的样子进行存储的,底层是按照k-v类型存储到hbase中的,并且写出到hdfs中
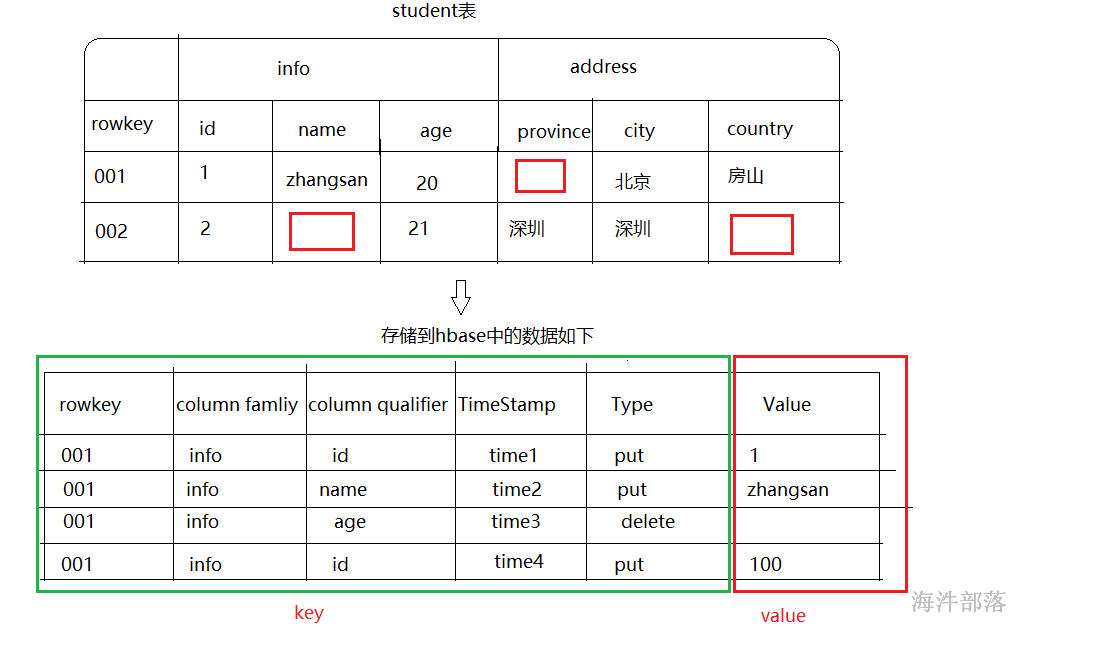
我们在上面的表中可以看到数据的存储是按照表格形式存储的,但是表格形式的存储在hbase的底层数据中并不是真正存在的,而是kv类型存储的,其中存储的数据包含以下几个部分,key的组成是[rowkey主键,列族,列,时间戳和操作类型],其中rowkey是唯一性的主键,每个数据都必须和主键相关联,列族和列组成了相对应的存储描述,时间戳用于做数据的修改保存,用于识别最新的数据是什么,而不像是关系型数据库它的每个操作都会直接写出到数据上,我们只能在上层操作,并且操作完毕以后将数据一下写出到hdfs中进行最终保存,所以时间戳是必备项,同于我们识别数据的版本,能够认识到数据的变化流程,找出最新的数据,type类型用户识别操作是什么,从而最后得出数据最新值,value是我们每次操作对应的值
而且因为数据在底层存储是按照kv类型进行存的,那么我们会发现在不同的行的数据可能字段并不相同,并不是像关系型数据库中,列是固定死的,从而我们发现hbase的数据存储中能够固定死的就只有列族信息
在我们操作和使用hbase之前,先要知道以下几个比较重要的关键词
namespace
命名空间:相当于是关系型数据中的数据库概念。在hbase中可以根据不同的业务声明不同的命名空间,一个命名空间中会存在多个表,类似于数据库表的分类层级
table
hbase数据库中的表,和关系型数据库的表相同,但是这个表中我们只需要声明列族即可,不需要指定相应的列字段,因为不同的行中的数据是按照kv进行存储的,可以动态变化
row
hbase表中的一行内容,一行中会存在一个唯一的rowkey,以及很多用列族和列字段标识的值,hbase的表是列式存储的,那么一行中的不同列族是位于多个文件中的,在查询一整行内容的时候可能会需要用到多个底层存储文件才能获取到
column family
列族:表中的列的固定部分,其中一个列族中会包含很多个列,每个列并不是真实存在的,只是存储数据时候的一个描述而已,更像是kv数据中的一个简单的描述值,一个列族会单独存储到一个文件中,这个列族中所有的列都是存在一个文件中的
column
列:在一个列中的下一级的描述关键字
timestamp
操作时间戳,用于在数据多次操作的时候记录每一次操作的时间,用于标识数据的版本
cell
单元格:一个由行和列进行定位的数据位置叫做单元格信息,其中包含一个确定的值,这个值其实只是kv存储的一个单独的value值,会根据上面的timestamp时间戳存在多个版本
6.hbase shell基础实操
6.1 查看hbase状态
# 进入hbase 命令行
hbase shell
status
6.2 查看版本号
version
6.3 命名空间操作
# 创建命名空间
create_namespace '命名空间名'
# 显示所有命名空间
list_namespace
# 删除命名空间
drop_namespace '命名空间名'
# 查看命名空间中的表有什么
list_namespace_tables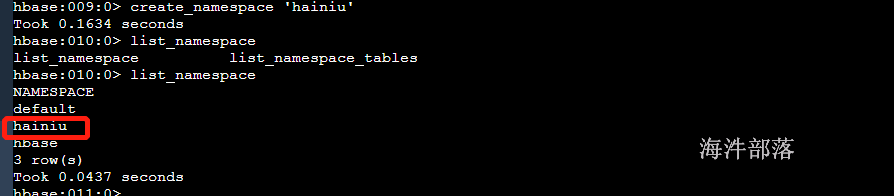
hainiu命名空间是自己创建的,默认都会在default中,其中hbase的这个命令空间是系统自己的

6.4 创建表
# 创建默认命名空间的表
create '表名称', '列族名称1','列族名称2','列族名称N'
# 创建带有命名空间的表
create '命名空间:表名称', '列族名称1','列族名称2','列族名称N'示例:
# 创建hainiu_table表,表里有三个列族
create 'hainiu:student','cf1','cf2','cf3'创建完之后有一个region是上线的
状态和该表region的位置:


在监控页面上存在一个已经创建好的表了,并且显示相应的列族信息
6.5 列出所有的表
# 查看所有的表
list
# 查询指定命名空间下的表
list_namespace_tables '命名空间'
只显示用户创建的表信息
6.6 获取表描述
# 默认命名空间
describe '表名'
# 指定命名空间
describe '命名空间:表名'
6.7 删除列族
# 删除hainiu_table 表的 cf3 列族
alter 'hainiu:student',{NAME=>'cf3',METHOD=>'delete'}
# 查看表结构
describe 'hainiu:student'
# 创建表
create 'hainiu:student1','cf1','cf2','cf3'
# 删除多个列族
alter 'hainiu:student1', {NAME => 'cf3', METHOD => 'delete'},{NAME => 'cf2', METHOD => 'delete'}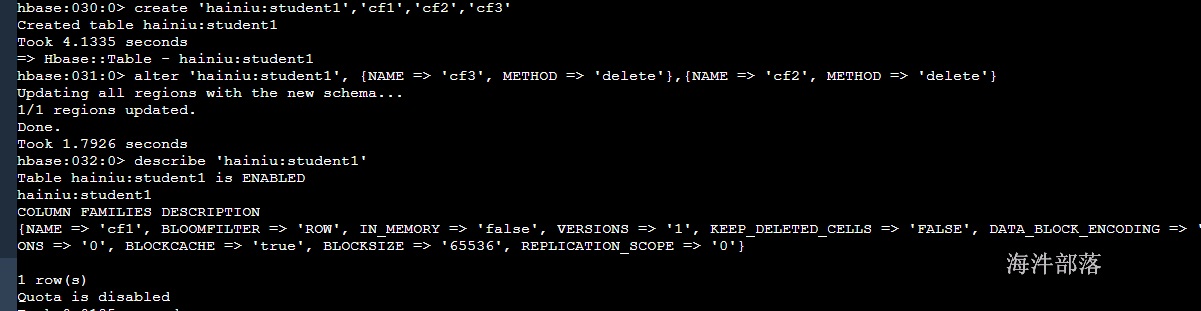
6.8 其他ddl操作
# 把表设置为disable(下线)
disable '表名'
# drop表
# 先把表下线,再drop表
disable '表名'
# 启动表
enable '表名'
drop '表名'
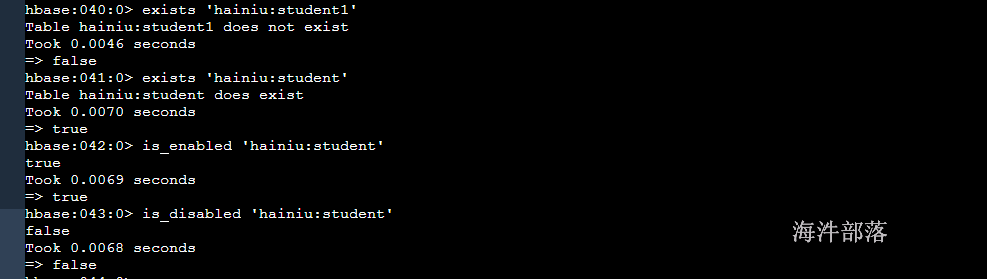
# 判断表是否存在
exists '表名'
# 判断表是否下线
is_disabled '表名'
# 判断表是否上线
is_enabled '表名'
删除表要先禁用表

判断表是否存在和启动