spark-shuffle和共享变量 12 共享变量
Spark两种共享变量:广播变量(broadcast variable)与累加器(accumulator)。
累加器用来对信息进行聚合,相当于mapreduce中的counter;而广播变量用来高效分发较大的对象,相当于semijoin中的DistributedCache 。
共享变量出现的原因:
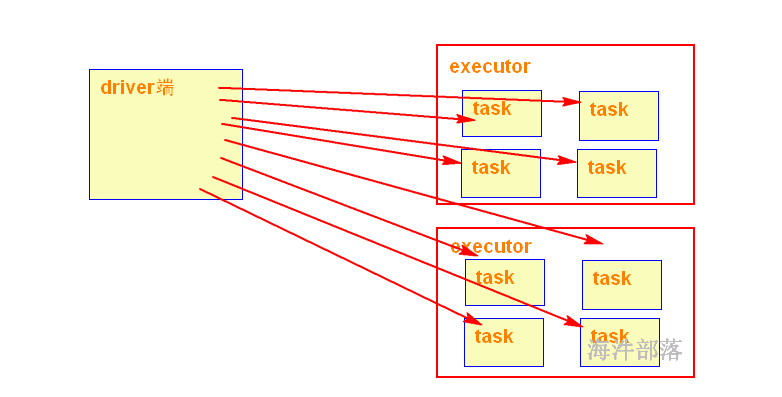
我们传递给Spark的函数,如map(),或者filter()的判断条件函数,能够利用定义在函数之外的变量,但是集群中的每一个task都会得到变量的一个副本,并且task在对变量进行的更新不会被返回给driver。
package com.hainiu.spark
import org.apache.spark.{SparkConf, SparkContext}
object TestAcc {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test acc")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(Array(1, 2, 3, 4, 5, 6, 7, 8, 9),3)
val count = rdd.map(t=> 1).reduce(_+_)
println(count)
// val acc = sc.longAccumulator("count")
//
// rdd.foreach(t=>{
// acc.add(1)
// })
//
// println(acc.value)
// println(rdd.count())
}
}
原因总结:
对于executor端,driver端的变量是外部变量。
excutor端修改了变量count,根本不会让driver端跟着修改。如果想在driver端得到executor端修改的变量,需要用累加器实现。
当在Executor端用到了Driver变量,不使用广播变量,在每个Executor中有多少个task就有多少个Driver端变量副本。如果这个变量中的数据很大的话,会产生很高的传输负载,导致执行效率降低,也可能会造成内存溢出。需要广播变量提高运行效率。
累加器
累加器可以很简便地对各个worker返回给driver的值进行聚合。累加器最常见的用途之一就是对一个job执行期间发生的事件进行计数。
用法:
var acc: LongAccumulator = sc.longAccumulator // 创建累加器
acc.add(1) // 累加器累加
acc.value // 获取累加器的值
累加器的简单使用
package com.hainiu.spark
import org.apache.spark.{SparkConf, SparkContext}
object WordCountWithAcc {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test acc")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val acc = sc.longAccumulator("bad word")
sc.textFile("data/a.txt")
.flatMap(_.split(" "))
.filter(t=>{
if(t.equals("shit")){
acc.add(1)
false
}else
true
}).map((_,1))
.reduceByKey(_+_)
.foreach(println)
println("invalid words:"+acc.value)
}
}广播变量
ip案例
ip转换工具
public class IpUtils {
public static Long ip2Long(String ip) {
String fragments[] = ip.split("[.]");
Long ipNum = 0L;
for(int i=0;i<fragments.length;i++) {
ipNum = Long.parseLong(fragments[i]) | ipNum << 8L;
}
return ipNum;
}
}ip案例代码
package com.hainiu.spark
import org.apache.spark.{SparkConf, SparkContext}
object IpTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ip")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val accessRDD = sc.textFile("data/access.log")
.map(t=>{
val strs = t.split("\\|")
IpUtils.ip2Long(strs(1))
})
val ipArr:Array[(Long,Long,String)] = sc.textFile("data/ip.txt").map(t=>{
val strs = t.split("\\|")
(strs(2).toLong,strs(3).toLong,strs(6)+strs(7))
}).collect()
// accessRDD.map(ip=>{
// ipRDD.filter(t=>{
// ip>= t._1 && ip<= t._2
// })
// }).foreach(println)
accessRDD.map(ip=>{
ipArr.find(t=>{
t._1<= ip && t._2>=ip
}) match {
case Some(v) => (v._3,1)
case None => ("unknow",1)
}
//option
}).reduceByKey(_+_)
.foreach(println)
}
}
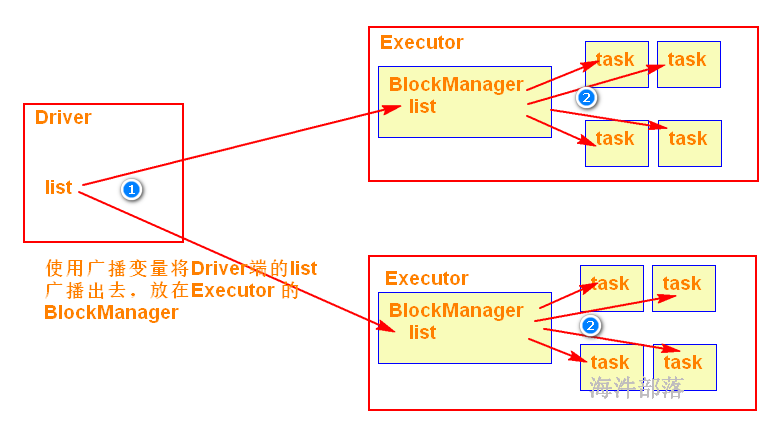
使用广播变量可以使程序高效地将一个很大的只读数据发送到executor节点,会将广播变量放到executor的BlockManager中,而且对每个executor节点只需要传输一次,该executor节点的多个task可以共用这一个。
用法:
val broad: Broadcast[List[Int]] = sc.broadcast(list) // 把driver端的变量用广播变量包装
broad.value // 从广播变量获取包装的数据,用于计算
package com.hainiu.spark
import org.apache.spark.{SparkConf, SparkContext}
object IpTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ip")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val accessRDD = sc.textFile("data/access.log")
.map(t=>{
val strs = t.split("\\|")
IpUtils.ip2Long(strs(1))
})
val ipArr:Array[(Long,Long,String)] = sc.textFile("data/ip.txt").map(t=>{
val strs = t.split("\\|")
(strs(2).toLong,strs(3).toLong,strs(6)+strs(7))
}).collect()
val bs = sc.broadcast(ipArr)
// accessRDD.map(ip=>{
// ipRDD.filter(t=>{
// ip>= t._1 && ip<= t._2
// })
// }).foreach(println)
accessRDD.map(ip=>{
bs.value.find(t=>{
t._1<= ip && t._2>=ip
}) match {
case Some(v) => (v._3,1)
case None => ("unknow",1)
}
//option
}).reduceByKey(_+_)
.foreach(println)
}
}二分法查找代码
def binarySearch(ip:Long,arr:Array[(Long,Long,String)]):String = {
var start = 0
var end = arr.length - 1
while(start<=end){
val middle = (start+end)/2
val lowip = arr(middle)._1
val highip = arr(middle)._2
val address = arr(middle)._3
if(ip<=highip && ip>=lowip)
return address
else if(ip<lowip)
end = middle -1
else
start = middle+1
}
"unknow"
}累加器实现运行时间的统计
val start = System.currentTimeMillis()
val res = (binarySearch(ip,bs.value),1)
// val res = bs.value.find(t=>{
// t._1<= ip && t._2>=ip
// }) match {
// case Some(v) => (v._3,1)
// case None => ("unknow",1)
// }
val end = System.currentTimeMillis()
acc.add(end-start)13 BlockManager分析
BlockManager是Spark的分布式存储系统,与我们平常说的分布式存储系统是有区别的,区别就是这个分布式存储系统只会管理Block块数据,它运行在所有节点上。
BlockManager的结构是Maser-Slave架构,Master就是Driver上的BlockManagerMaster,Slave就是每个Executor上的BlockManager。BlockManagerMaster负责接受Executor上的BlockManager的注册以及管理BlockManager的元数据信息。
运行图:
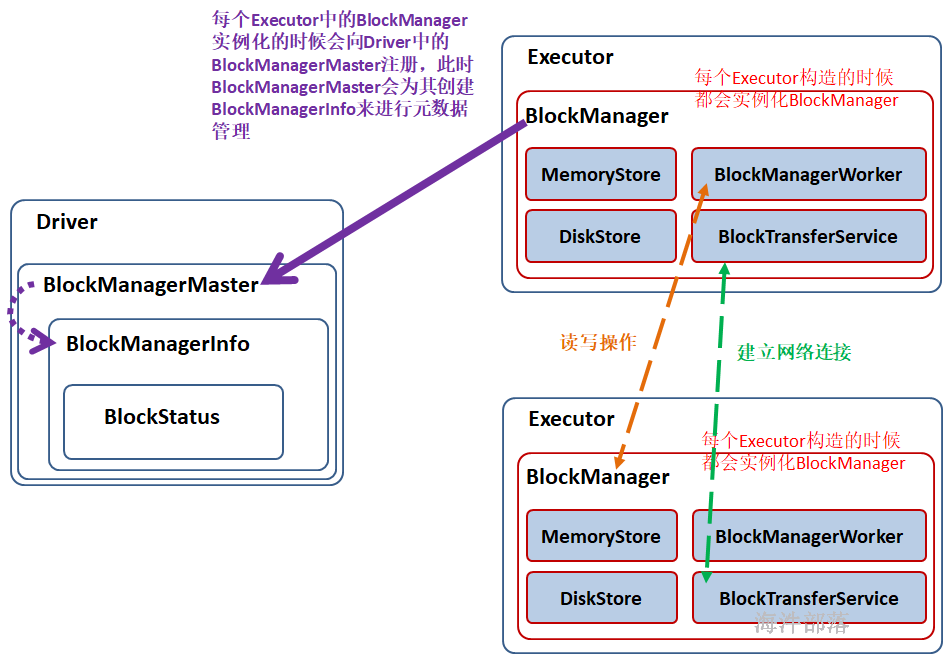
1)在 Application 启动的时候会在 SparkEnv 中注册 BlockMangerMaster。
BlockManagerMaster:对整个集群的 Block 数据进行管理;
2)每个启动一个 Executor 都会实例化 BlockManagerSlave 并通过远程通信的方式注册给 BlockMangerMaster;
3)BlockManagerSlave由 4部分组成:
MemoryStore:负责对内存上的数据进行存储和读写;
DiskStore:负责对磁盘上的数据进行存储和读写;
BlockTransferService:负责与远程其他Executor 的BlockManager建立网络连接;
BlockManagerWorker:负责对远程其他Executor的BlockManager的数据进行读写;
4)当Executor 的BlockManager 执行了增删改操作,那就必须将 block 的 blockStatus 上报给Driver端的BlockManagerMaster,BlockManagerMaster 内部的BlockManagerMasterEndPoint 内维护了 元数据信息的映射。通过Map、Set结构,很容易维护 增加、更新、删除元数据,进而达到维护元数据的功能。
// 维护 BlockManagerId 与 BlockManagerInfo 的关系
// 而BlockManagerInfo内部维护 JHashMap[BlockId, BlockStatus] 的映射关系
private val blockManagerInfo = new mutable.HashMap[BlockManagerId, BlockManagerInfo]
// 维护 executorID 与 BlockManagerId 的关系
private val blockManagerIdByExecutor = new mutable.HashMap[String, BlockManagerId]
// 维护 BlockId 与 HashSet[BlockManagerId] 的关系, 因为数据块可能有副本
private val blockLocations = new JHashMap[BlockId, mutable.HashSet[BlockManagerId]]JHashMap[BlockId, mutable.HashSet[BlockManagerId]]
HashMap[executorID, BlockManagerId]
HashMap[BlockManagerId, BlockManagerInfo]
JHashMap[BlockId, BlockStatus]
14 spark 的shuffle
shuffle
对spark任务划分阶段,遇到宽依赖会断开,所以在stage 与 stage 之间会产生shuffle,大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO、序列化、网络数据传输等操作。
负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager,也即shuffle管理器。而随着Spark的版本的发展,ShuffleManager也在不断迭代。
ShuffleManager 大概有两个: HashShuffleManager 和 SortShuffleManager。
历史:
在spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager;
在spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager;
在spark 2.0以后,抛弃了 HashShuffleManager。
14.1 HashShuffleManager
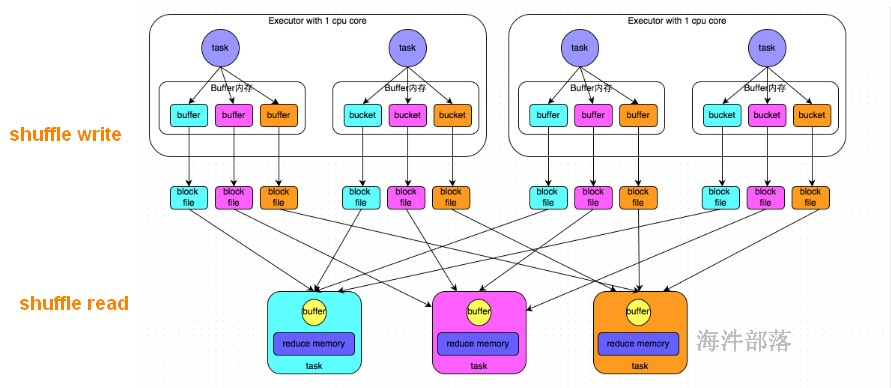
上游 stage 有 2个 Executor,每个Executor 有 2 个 task。
下游 stage 有 3个task。
shuffle write阶段:
将相当于mapreduce的shuffle write,按照key的hash 分桶,写出中间文件。上游的每个task写自己的文件。
写出中间文件个数 = maptask的个数 * reducetask的个数
上图写出的中间文件个数 = 4 * 3 = 12
假设上游 stage 有 10 个Executor,每个 Executor有 5 个task,下游stage 有 4 个task,写出的中间文件数 = (10 * 5) * 4 = 200 个,由此可见,shuffle write操作所产生的磁盘文件的数量是极其惊人的。
shuffle read 阶段:
就相当于mapreduce 的 shuffle read, 每个reducetask 拉取自己的数据。
由于shuffle write的过程中,task给下游stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
弊端:
shuffle write阶段占用大量的内存空间,会导致频繁的GC,容易导致OOM;也会产生大量的小文件,写入过程中会产生大量的磁盘IO,性能受到影响。适合小数据集的处理。
14.2 HashShuffleManager 优化
开启consolidate机制。
设置参数:spark.shuffle.consolidateFiles。该参数默认值为false,将其设置为true即可开启优化机制。
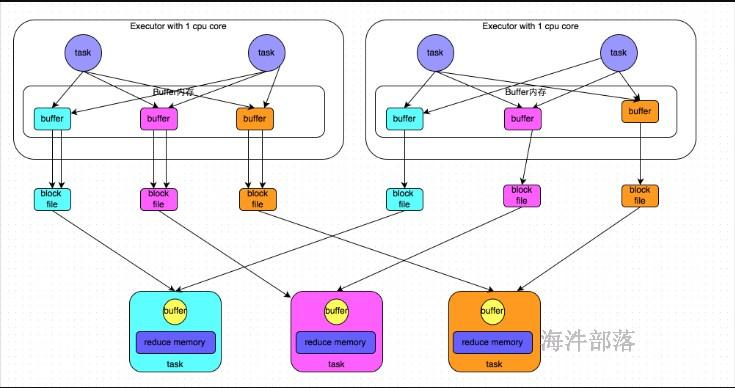
假设:每个Executor只有1个CPU core,也就是说,无论这个Executor上分配多少个task线程,同一时间都只能执行一个task线程。
上游 stage 有 2个 Executor,每个Executor 有 2 个 task,每个Executor只有1个CPU core。
下游 stage 有 3个task。
shuffle write阶段:
开启consolidate机制后,允许上游的多个task写入同一个文件,这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
写出中间文件个数 = 上游的CPU核数 * 下游task的个数
上图写出的中间文件个数 = 2 * 3 = 6
假设上游 stage 有 10 个Executor,每个Executor只有1个CPU core,每个 Executor有 5 个task,下游stage 有 4 个task,写出的中间文件数 = 10 * 4 = 40个
shuffle read 阶段:
就相当于mapreduce 的 shuffle read, 每个reducetask 拉取自己的数据。
由每个reducetask只要从上游stage的所在节点上,拉取属于自己的那一个磁盘文件即可。
弊端:
优化后的HashShuffleManager,虽然比优化前减少了很多小文件,但在处理大量数据时,还是会产生很多的小文件。
14.3 SortShuffleManager
Spark在引入Sort-Based Shuffle以前,比较适用于中小规模的大数据处理。为了让Spark在更大规模的集群上更高性能处理更大规模的数据,于是就引入了SortShuffleManager。
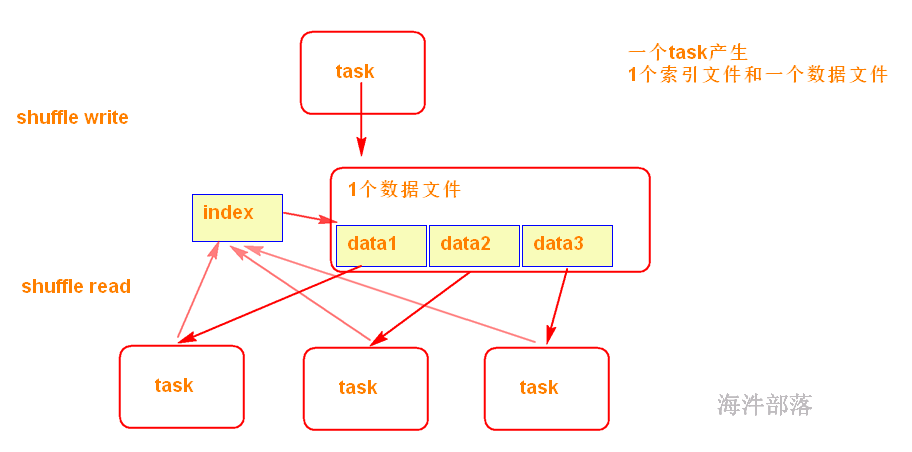
SortShuffleManager不会为每个Reducer中的Task生成一个单独的文件,相反,会把上游中每个mapTask所有的输出数据Data只写到一个文件中。并使用了Index文件存储具体 mapTask 输出数据在该文件的位置。
因此 上游 中的每一个mapTask中产生两个文件:Data文件 和 Index 文件,其中Data文件是存储当前Task的Shuffle输出的,而Index文件中存储了data文件中的数据通过partitioner的分类索引。
写出文件数 = maptask的个数 * 2 (index 和 data )
可见,SortShuffle 的产生的中间文件的多少与 上个stage 的 maptask 数量有关。
shuffle read 阶段:
下游的Stage中的Task就是根据这个Index文件获取自己所要抓取的上游Stage中的mapShuffleMapTask产生的数据的;
14.4 bypass机制
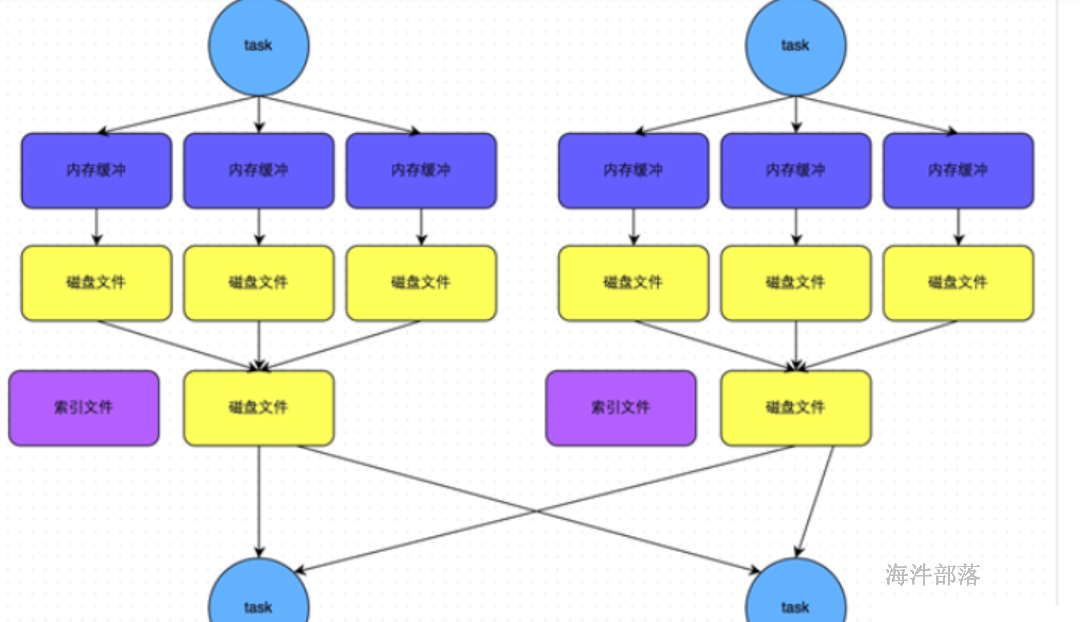
此时task会为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
bypass机制与普通SortShuffleManager运行机制的不同在于:
第一,磁盘写机制不同;
第二,不会进行排序。
也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
触发bypass机制的条件:
shuffle map task的数量小于spark.shuffle.sort.bypassMergeThreshold参数的值(默认200)或者不是聚合类的shuffle算子(比如groupByKey)
14.5 shuffle 总结
回顾整个Shuffle的历史,Shuffle产生的临时文件的数量的变化以此为:
Hash Shuffle:M*R;
Consolidate 方式的Hash Shuffle:C*R;
Sort Shuffle:2*M;
其中:M:上游stage的task数量,R:下游stage的task数量,C:上游stage运行task的CPU核数
14.6 验证理论
由于spark2.0以后 HashShuffle已经不存在,要验证HashShuffle 需要spark1.5的 环境。
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>在spark1.5环境下,运行HashShuffle 需要在代码中设置SparkConf 的参数
spark.shuffle.manager ,值设置成hash。
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object HashShuffleTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("HashShuffleTest").setMaster("local[2]")
conf.set("spark.shuffle.manager", "hash")
conf.set("spark.shuffle.consolidateFiles", "true")
val sc = new SparkContext(conf)
// sc.setLogLevel("DEBUG")
val outPath = "/tmp/spark/output/wordcount"
val hadoopConf = new Configuration()
val fs: FileSystem = FileSystem.get(hadoopConf)
val path = new Path(outPath)
if (fs.exists(path)) {
fs.delete(path, true)
}
val line: RDD[String] = sc.textFile("/tmp/spark/input",2)
println(line.partitions.length)
val sort: RDD[(String, Int)] = line.flatMap(_.split(" ")).map((_,1)).reduceByKey((a,b) => a+b,4)
sort.saveAsTextFile(outPath)
//打印rdd的debug信息可以方便的查看rdd的依赖,从而可以看到那一步产生shuffle
println(sort.toDebugString)
}
}CPU核数 = 2
上游task数 = 5
下游task数 = 4
产生中间文件数 = 5 * 4 = 20
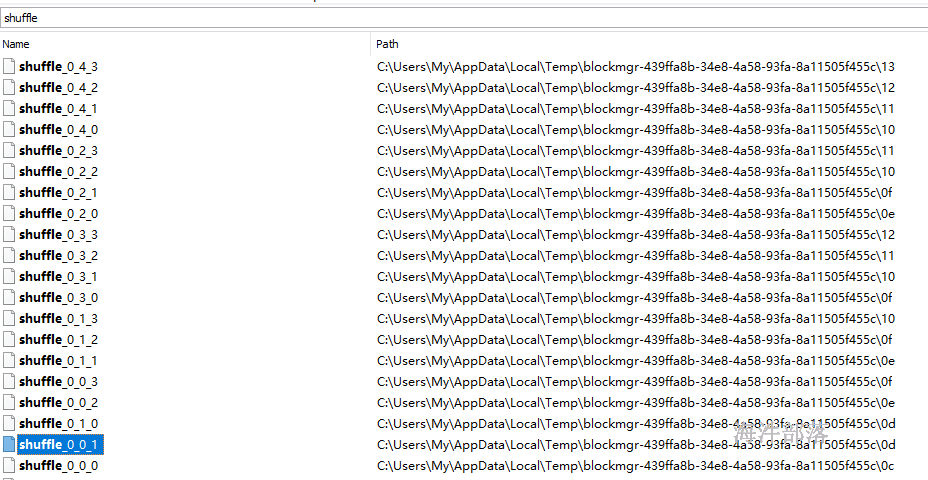
增加Consolidate后的HashShuffle,需要增加参数
spark.shuffle.consolidateFiles,设置成true

上游task数 = 5
下游task数 = 4
产生中间文件数 = 2 * 4 = 8
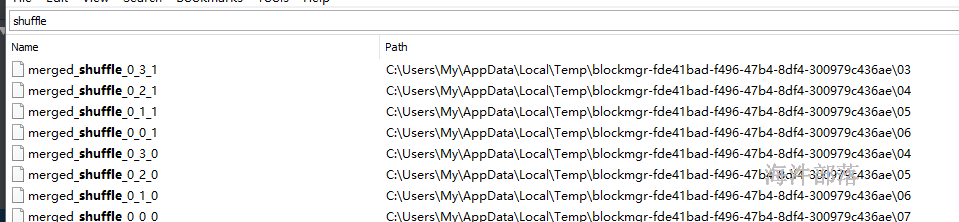
SortShuffle 测试,在spark1.5环境下,默认用SortShuffle
只需要把之前的两个参数注释掉即可
CPU核数 = 2
上游task数 = 5
下游task数 = 4
产生中间文件数 = 2 * 5 = 10
按照分数进行排序,先按照第一列然后按照第二列进行排序
zhangsan 100 86
lisi 98 95
wangwu 100 92
zhaosi 98 83整体代码如下:
package com.hainiu.spark
package com.hainiu.spark
import org.apache.spark.{SparkConf, SparkContext}
object SecondarySort {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test secondary")
conf.setMaster("local[1]")
val sc = new SparkContext(conf)
sc.textFile("data/score.txt")
.map(t=>{
val strs = t.split(" ")
(strs(0),strs(1).toInt,strs(2).toInt)
}).sortBy(t=>new MyScore(t._1,t._2,t._3))
.foreach(println)
}
}
class MyScore(val name:String,val chinese:Int,val math:Int) extends Ordered[MyScore] with Serializable {
override def compare(that: MyScore): Int = {
if(this.chinese == that.chinese){
that.math - this.math
}else{
that.chinese - this.chinese
}
}
override def toString: String = s"name=${name} chinese = ${chinese} math = ${math}"
}
结果如下:

16 spark mapjoin
16.1 spark使用的pom
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.scope>compile</project.build.scope>
<!-- scope关键字是jar包的一个作用域,provided编译时候可以使用,运行和打包不行
runtime编译时候可以使用,运行可以使用,打包不行
compile编译,运行,打包-->
<spark.version>3.1.2</spark.version>
<!-- <project.build.scope>provided</project.build.scope>-->
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- spark 操作 hbase用到的-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- <dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-cli</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
</exclusion>
</exclusions>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<!-- sparkSQL编程-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- sparkSQL-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.35</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.spark-project.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<scope>compile</scope>
<version>1.2.1.spark2</version>
</dependency>
<!-- 访问spark thriftserver 用的-->
<!-- <dependency>-->
<!-- <groupId>org.apache.hive</groupId>-->
<!-- <artifactId>hive-jdbc</artifactId>-->
<!-- <exclusions>-->
<!-- <exclusion>-->
<!-- <groupId>org.apache.hive</groupId>-->
<!-- <artifactId>hive-exec</artifactId>-->
<!-- </exclusion>-->
<!-- </exclusions>-->
<!-- <version>3.1.2</version>-->
<!-- <scope>${project.build.scope}</scope>-->
<!-- </dependency>-->
<!-- sparkStreaming直连kafka操作-->
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>0.10.2.2</version>
<scope>${project.build.scope}</scope>
<exclusions>
<exclusion>
<artifactId>kafka-clients</artifactId>
<groupId>org.apache.kafka</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- sparkStreaming操作-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop</artifactId>
<version>5.6.11</version>
<exclusions>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>pentaho-aggdesigner-algorithm</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
</exclusion>
<exclusion>
<groupId>cascading</groupId>
<artifactId>cascading-hadoop</artifactId>
</exclusion>
<exclusion>
<groupId>cascading</groupId>
<artifactId>cascading-local</artifactId>
</exclusion>
</exclusions>
<!-- -Xms256m -Xmx512m -Xss10m
-->
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.9.2</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>JsoupXpath</artifactId>
<version>0.3.2</version>
<scope>compile</scope>
</dependency>
</dependencies>
<build>
<resources>
<resource>
<directory>src/resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptors>
<descriptor>src/resources/assembly.xml</descriptor>
</descriptors>
<archive>
<manifest>
<mainClass>com.hainiu.spark.day03.Start</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.12</version>
<configuration>
<skip>true</skip>
<forkMode>once</forkMode>
<excludes>
<exclude>**/**</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>16.2 mapjoin所用工具及数据
使用之前封装的orc工具读取hive的orc格式文件;

数据集
使用累加类统计数据的join情况
输出10条join之后的数据结果,并将数据输出到ORC文件中
orc工具类
import org.apache.hadoop.hive.ql.io.orc.OrcSerde;
import org.apache.hadoop.hive.ql.io.orc.OrcStruct;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfoUtils;
import org.apache.hadoop.io.Writable;
import java.util.ArrayList;
import java.util.List;
/**
* orcUtil工具类, 读写orc文件
* 应用步骤:<br/>
* 读orc:<br/>
* setOrcTypeReadSchema()<br/>
* getOrcData()<br/>
*
* 写orc:<br/>
* setOrcTypeWriteSchema()<br/>
* addAttr()<br/>
* serialize()<br/>
*
* @Date 2019年6月5日
*/
public class OrcUtil {
/**
* 读取orc文件的inspector对象
*/
StructObjectInspector inspectorR = null;
/**
* 写orc文件的inspector对象
*/
StructObjectInspector inspectorW = null;
/**
* 存储一行的数据
*/
List<Object> realRow = null;
/**
* orc文件序列化对象
*/
OrcSerde serde = null;
/**
* 设置读orc的inspector对象
*/
public void setOrcTypeReadSchema(String schema){
// 根据orc文件的结构,获取对应的typeinfo对象
TypeInfo typeinfo = TypeInfoUtils.getTypeInfoFromTypeString(schema);
// 通过typeinfo对象获取具体的inspector对象
inspectorR = (StructObjectInspector) OrcStruct.createObjectInspector(typeinfo);
}
/**
* 设置写orc的inspector对象
*/
public void setOrcTypeWriteSchema(String schema){
// 根据orc文件的结构,获取对应的typeinfo对象
TypeInfo typeinfo = TypeInfoUtils.getTypeInfoFromTypeString(schema);
// 根据typeinfo 获取写orc文件的inspector对象
inspectorW = (StructObjectInspector) TypeInfoUtils.getStandardJavaObjectInspectorFromTypeInfo(typeinfo);
}
/**
* 获取指定orc格式文件字段的值
* @param orcStruct orc文件数据
* @param filedName 字段名称
* @return 指定字段的值
*/
public String getOrcData(OrcStruct orcStruct, String filedName){
// 根据字段名称,获取对应的 StructField对象
StructField fieldRef = inspectorR.getStructFieldRef(filedName);
// 通过 对应的 StructField对象,从orcData 里面,取出 对应字段的值
Object obj = inspectorR.getStructFieldData(orcStruct, fieldRef);
String filedData = null;
if (obj != null) {
filedData = String.valueOf(obj);
filedData = "".equals(filedData) || "null".equals(filedData) ? null : filedData;
}
return filedData;
}
/**
* 写orc时,添加要写入orc文件的字段可变数组
* @param objs 可变数组
* @return
*/
public OrcUtil addAttr(Object... objs){
if(realRow == null){
realRow = new ArrayList<Object>();
}
for(Object obj : objs){
realRow.add(obj);
}
return this;
}
/**
* 将 这一行的数据 序列化成 orc文件格式
*/
public Writable serialize() {
// 每次new新的
serde = new OrcSerde();
Writable w = serde.serialize(realRow, inspectorW);
// 序列化后重新创建接收数据的列表对象
realRow = new ArrayList<Object>();
return w;
}
}16.3 scala 版本实现上面的功能
package com.hainiu.sparkcore
import com.hainiu.util.{OrcFormat, OrcUtil}
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hive.ql.io.orc.{CompressionKind, OrcNewInputFormat, OrcNewOutputFormat, OrcStruct}
import org.apache.hadoop.io.compress.SnappyCodec
import org.apache.hadoop.io.{NullWritable, Writable}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
import scala.io.Source
object MapJoin {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("mapjoin")
val sc: SparkContext = new SparkContext(conf)
// 读取hdfs上的orc文件,并转换成相应的pairRDD
val inputPath:String = "/tmp/spark/mapjoin_input"
// path: String,
// fClass: Class[F],
// kClass: Class[K],
// vClass: Class[V],
// conf: Configuration = hadoopConfiguration
val orcPairRdd: RDD[(NullWritable, OrcStruct)] = sc.newAPIHadoopFile(inputPath,
classOf[OrcNewInputFormat],
classOf[NullWritable],
classOf[OrcStruct])
// 加载字典文件到内存,并加载到广播变量里
val dictPath:String = "/tmp/spark/country_dict.dat"
// "CN\t中国"
val list: List[String] = Source.fromFile(dictPath).getLines().toList
val tuples: List[(String, String)] = list.map(f => {
val arr: Array[String] = f.split("\t")
(arr(0), arr(1))
})
val map: Map[String, String] = tuples.toMap
val broad: Broadcast[Map[String, String]] = sc.broadcast(map)
// 定义累加器统计join上的
val matchAcc: LongAccumulator = sc.longAccumulator
// 定义累加器统计join不上的
val notMatchAcc: LongAccumulator = sc.longAccumulator
// (NullWritable, OrcStruct) --> (NullWritable, Writable)
val orcWriteRdd: RDD[(NullWritable, Writable)] = orcPairRdd.mapPartitionsWithIndex((index, it) => {
// 创建 OrcUtil对象
val orcUtil: OrcUtil = new OrcUtil
// 根据schema获取读的inspector
orcUtil.setOrcTypeReadSchema(OrcFormat.SCHEMA)
// 根据schema获取写的inspector
orcUtil.setOrcTypeWriteSchema("struct<code:string,name:string>")
// 提取广播变量里的数据
val map2: Map[String, String] = broad.value
val orcList = new ListBuffer[(NullWritable, Writable)]
it.foreach(f => {
val countryCode: String = orcUtil.getOrcData(f._2, "country")
val option: Option[String] = map2.get(countryCode)
if (option == None) {
notMatchAcc.add(1L)
} else {
matchAcc.add(1L)
// 获取join的国家名称
val countryName: String = option.get
// 将国家码和国家名称添加到 orcList
orcUtil.addAttr(countryCode, countryName)
val w: Writable = orcUtil.serialize()
orcList += ((NullWritable.get(), w))
}
})
orcList.iterator
})
// 写入orc文件
val outputPath:String = "/tmp/spark/mapjoin_output"
import com.hainiu.util.MyPredef.string2HdfsUtil
outputPath.deleteHdfs
val hadoopConf: Configuration = new Configuration()
hadoopConf.set(CompressionKind.SNAPPY.name(), classOf[SnappyCodec].getName);
// 执行 saveAsNewAPIHadoopFile的rdd必须符合能写入该文件类型的rdd
// path: String,
// keyClass: Class[_],
// valueClass: Class[_],
// outputFormatClass: Class[_ <: NewOutputFormat[_, _]],
// conf: Configuration = self.context.hadoopConfiguration
orcWriteRdd.saveAsNewAPIHadoopFile(outputPath,
classOf[NullWritable],
classOf[Writable],
classOf[OrcNewOutputFormat])
println(s"matchAcc:${matchAcc.value}")
println(s"notMatchAcc:${notMatchAcc.value}")
}
}
源码:
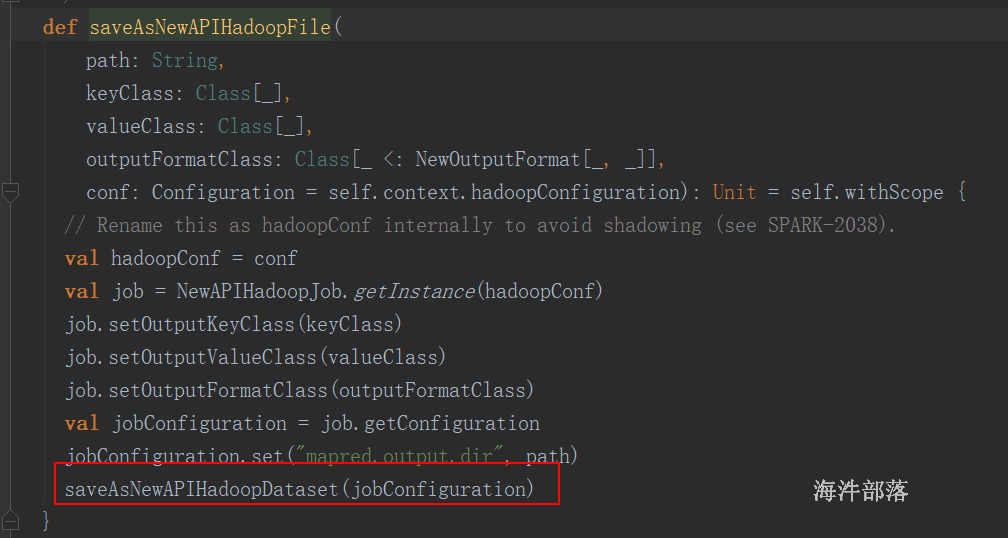
def saveAsNewAPIHadoopDataset(conf: Configuration): Unit = self.withScope {
// Rename this as hadoopConf internally to avoid shadowing (see SPARK-2038).
val hadoopConf = conf
val job = NewAPIHadoopJob.getInstance(hadoopConf)
val formatter = new SimpleDateFormat("yyyyMMddHHmmss", Locale.US)
val jobtrackerID = formatter.format(new Date())
val stageId = self.id
val jobConfiguration = job.getConfiguration
val wrappedConf = new SerializableConfiguration(jobConfiguration)
// OutputFOrmatClass
val outfmt = job.getOutputFormatClass
val jobFormat = outfmt.newInstance
if (isOutputSpecValidationEnabled) {
// FileOutputFormat ignores the filesystem parameter
jobFormat.checkOutputSpecs(job)
}
val writeShard = (context: TaskContext, iter: Iterator[(K, V)]) => {
// iter: 一个分区的数据
val config = wrappedConf.value
/* "reduce task" <split #> <attempt # = spark task #> */
val attemptId = new TaskAttemptID(jobtrackerID, stageId, TaskType.REDUCE, context.partitionId,
context.attemptNumber)
val hadoopContext = new TaskAttemptContextImpl(config, attemptId)
// 创建outputFormat实例,本次具体实例就是OrcNewOutputFormat对象
val format = outfmt.newInstance
format match {
case c: Configurable => c.setConf(config)
case _ => ()
}
val committer = format.getOutputCommitter(hadoopContext)
committer.setupTask(hadoopContext)
val outputMetricsAndBytesWrittenCallback: Option[(OutputMetrics, () => Long)] =
initHadoopOutputMetrics(context)
// 获取到能写入orc文件的具体RecordWriter, 本例是 OrcRecordWriter
// 一个分区创建一个RecordWriter对象
val writer = format.getRecordWriter(hadoopContext).asInstanceOf[NewRecordWriter[K, V]]
require(writer != null, "Unable to obtain RecordWriter")
var recordsWritten = 0L
Utils.tryWithSafeFinallyAndFailureCallbacks {
while (iter.hasNext) {
val pair = iter.next()
// 写入式一行一行写入
// 调用对应RecordWriter对象的write方法
writer.write(pair._1, pair._2)
// Update bytes written metric every few records
maybeUpdateOutputMetrics(outputMetricsAndBytesWrittenCallback, recordsWritten)
recordsWritten += 1
}
}(finallyBlock = writer.close(hadoopContext))
committer.commitTask(hadoopContext)
outputMetricsAndBytesWrittenCallback.foreach { case (om, callback) =>
om.setBytesWritten(callback())
om.setRecordsWritten(recordsWritten)
}
1
} : Int
val jobAttemptId = new TaskAttemptID(jobtrackerID, stageId, TaskType.MAP, 0, 0)
val jobTaskContext = new TaskAttemptContextImpl(wrappedConf.value, jobAttemptId)
val jobCommitter = jobFormat.getOutputCommitter(jobTaskContext)
// When speculation is on and output committer class name contains "Direct", we should warn
// users that they may loss data if they are using a direct output committer.
val speculationEnabled = self.conf.getBoolean("spark.speculation", false)
val outputCommitterClass = jobCommitter.getClass.getSimpleName
if (speculationEnabled && outputCommitterClass.contains("Direct")) {
val warningMessage =
s"$outputCommitterClass may be an output committer that writes data directly to " +
"the final location. Because speculation is enabled, this output committer may " +
"cause data loss (see the case in SPARK-10063). If possible, please use an output " +
"committer that does not have this behavior (e.g. FileOutputCommitter)."
logWarning(warningMessage)
}
jobCommitter.setupJob(jobTaskContext)
// runJob 提交action操作,执行 writeShard 函数写入数据
self.context.runJob(self, writeShard)
jobCommitter.commitJob(jobTaskContext)
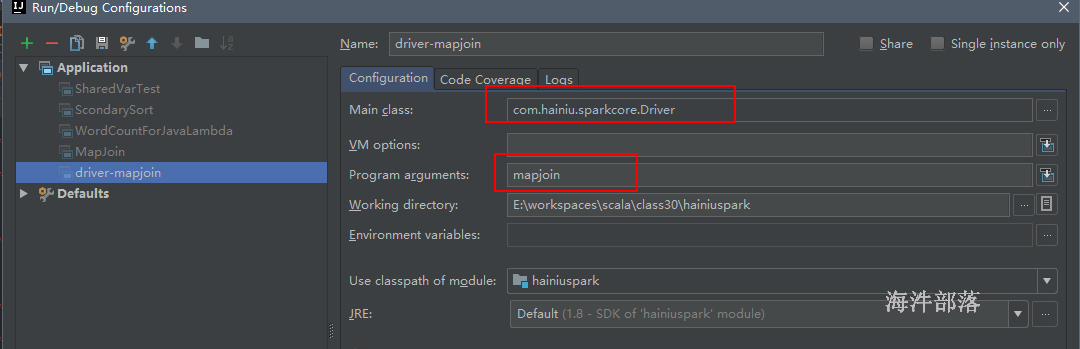
}16.4 定义Driver并运行mapjoin
可以像mapreduce那样 封装个 Driver,在启动参数中配置

package util
import rdd.MapJoin
import org.apache.hadoop.util.ProgramDriver
object Driver {
def main(args: Array[String]): Unit = {
val driver = new ProgramDriver
// MapJoin 需要有伴生类,classOf找的是伴生类
driver.addClass("mapjoin", classOf[MapJoin], "mapJoin任务")
driver.run(args)
}
}