spark序列化、GC和操作hbase 17 spark序列化使用
由于大多数Spark计算的内存性质,Spark程序可能会受到集群中任何资源(CPU,网络带宽或内存)的瓶颈。通常,如果内存资源足够,则瓶颈是网络带宽。
数据序列化,这对于良好的网络性能至关重要。
在Spark的架构中,在网络中传递的或者缓存在内存、硬盘中的对象需要进行序列化操作。比如:
1)分发给Executor上的Task
2)广播变量
3)Shuffle过程中的数据缓存
等操作,序列化起到了重要的作用,将对象序列化为慢速格式或占用大量字节的格式将大大减慢计算速度。通常,这是优化Spark应用程序的第一件事。
spark 序列化分两种:一种是Java 序列化; 另一种是 Kryo 序列化。
17.1 Java序列化
定义UserInfo类
public class UserInfo{
private String name = "hainiu"; // java实现了序列化
private int age = 10; // java实现了序列化
private Text addr = new Text("beijing"); // 没有实现java的 Serializable接口
public UserInfo() {
}
@Override
public String toString() {
return "UserInfo{" +
"name='" + name + '\'' +
", age=" + age +
", addr=" + addr +
'}';
}
}java实现序列化的一般方法:
1)让类实现Serializable接口
当使用Serializable方案的时候,你的对象必须继承Serializable接口,类中的属性如果有实例那也必须是继承Serializable 可序列化的;
package com.hainiu.sparkcore
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SerDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SerDemo")
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.parallelize(List("aa","aa","bb","aa"),2)
val broad: Broadcast[UserInfo] = sc.broadcast(new UserInfo)
val pairRdd: RDD[(String, UserInfo)] = rdd.map(f => {
val userInfo: UserInfo = broad.value
(f, userInfo)
})
// 因为groupByKey有shuffle,需要序列化
val groupRdd: RDD[(String, Iterable[UserInfo])] = pairRdd.groupByKey()
val arr: Array[(String, Iterable[UserInfo])] = groupRdd.collect()
for(t <- arr){
println(t)
}
}
}
2)static和transient修饰的属性不会被序列化,可以通过在属性上加 static 或 transient 修饰来解决序列化问题。
static修饰的是类的状态,而不是对象状态,所以不存在序列化问题;

这样导致数据丢失。
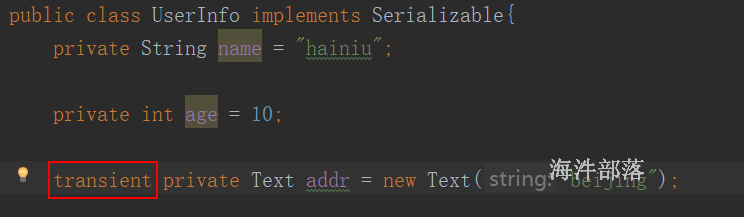
给addr 属性用 transient 修饰,导致反序列化后数据丢失

java 序列化弊端:
1)如果引入第三方类对象作为属性,如果对象没有实现序列化,那这个类也不能序列化;
2)用 transient 修饰 的属性,反序列化后数据丢失;
3)Java序列化很灵活(支持所有对象的序列化)但性能较差,同时序列化后占用的字节数也较多(包含了序列化版本号、类名等信息);

17.2 Kryo 序列化
由于java序列化性能问题,spark 引入了Kryo序列化机制。
Spark 也推荐用 Kryo序列化机制。Kryo序列化机制比Java序列化机制性能提高10倍左右,Spark之所以没有默认使用Kryo作为序列化类库,是因为它不支持所有对象的序列化,同时Kryo需要用户在使用前注册需要序列化的类型,不够方便。
1)开启序列化
spark 默认序列化方式 是 用java序列化

conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") // classOf[KryoSerializer].getName 一样效果2)配置序列化参数
当开启序列化后,需要配置 【spark.kryo.registrationRequired】属性为true,默认是false,如果是false,Kryo序列化时性能有所下降。

注册有两种方式:
第一种:
// 开启Kryo序列化
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 要求主动注册
conf.set("spark.kryo.registrationRequired", "true")
// 方案1:
val classes: Array[Class[_]] = Array[Class[_]](
classOf[UserInfo],
classOf[Text],
Class.forName("scala.reflect.ClassTag$GenericClassTag"),
classOf[Array[UserInfo]]
)
//将上面的类注册
conf.registerKryoClasses(classes)第二种:
封装一个自定义注册类,然后把自定义注册类注册给Kryo。
a)自定义注册类:
class MyRegistrator extends KryoRegistrator {
override def registerClasses(kryo: Kryo): Unit = {
kryo.register(classOf[UserInfo])
kryo.register(classOf[Text])
kryo.register(Class.forName("scala.reflect.ClassTag$GenericClassTag"))
kryo.register(classOf[Array[UserInfo]])
}
}b)配置自定义注册类
// 开启Kryo序列化
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 要求主动注册
conf.set("spark.kryo.registrationRequired", "true")
// 设置注册类
conf.set("spark.kryo.registrator",classOf[MyRegistrator].getName)代码:
package spark05
import com.esotericsoftware.kryo.Kryo
import java05.UserInfo
import org.apache.hadoop.io.Text
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.serializer.KryoRegistrator
import org.apache.spark.{SparkConf, SparkContext}
object SerDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SerDemo")
// 开启Kryo序列化
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 要求主动注册
conf.set("spark.kryo.registrationRequired", "true")
// 方案1:
// val classes: Array[Class[_]] = Array[Class[_]](
// classOf[UserInfo],
// classOf[Text],
// Class.forName("scala.reflect.ClassTag$GenericClassTag"),
// classOf[Array[UserInfo]]
// )
//将上面的类注册
// conf.registerKryoClasses(classes)
// 方案2
conf.set("spark.kryo.registrator",classOf[MyRegistrator].getName)
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.parallelize(List("aa","aa","bb","aa"),2)
val user = new UserInfo
val broad: Broadcast[UserInfo] = sc.broadcast(user)
val rdd2: RDD[(String, UserInfo)] = rdd.map(f => {
val user2: UserInfo = broad.value
(f, user2)
})
// 目的是让rdd产生shuffle
val arr: Array[(String, Iterable[UserInfo])] = rdd2.groupByKey().collect()
arr.foreach(println)
}
}
class MyRegistrator extends KryoRegistrator {
override def registerClasses(kryo: Kryo): Unit = {
kryo.register(classOf[UserInfo])
kryo.register(classOf[Text])
kryo.register(Class.forName("scala.reflect.ClassTag$GenericClassTag"))
kryo.register(classOf[Array[UserInfo]])
}
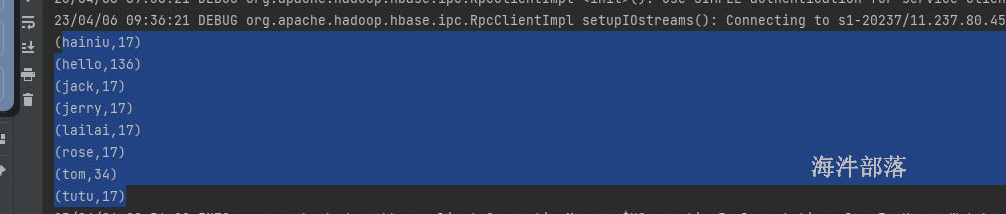
}运行结果:

18 GC对spark性能的影响分析
18.1 什么是GC
垃圾收集 Garbage Collection 通常被称为“GC”,回收没用的对象以释放空间。
GC 主要回收的是虚拟机堆内存的空间,因为new 的对象主要是在堆内存。
18.2 垃圾收集的算法
1)标记 -清除算法
“标记-清除”(Mark-Sweep)算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。之所以说它是最基础的收集算法,是因为后续的收集算法都是基于这种思路并对其缺点进行改进而得到的。
它的主要缺点有两个:一个是效率问题,标记和清除过程的效率都不高;另外一个是空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致,当程序在以后的运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
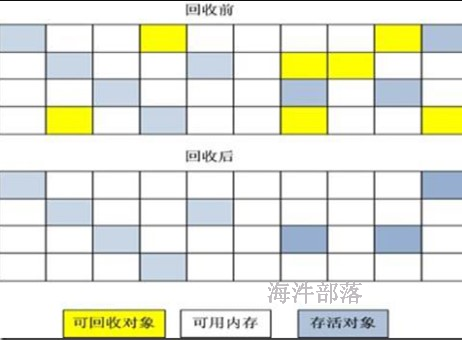
2)复制算法
“复制”(Copying)的收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
这样使得每次都是对其中的一块进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,缺点:这种算法持续复制长生存期的对象则导致效率降低。
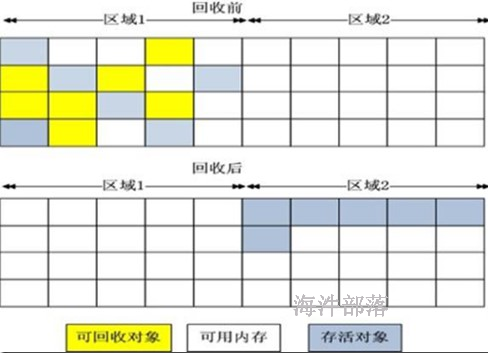
3)标记-整理算法
复制收集算法在对象存活率较高时就要执行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
根据老年代的特点,有人提出了另外一种“标记-整理”(Mark-Compact)算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存;
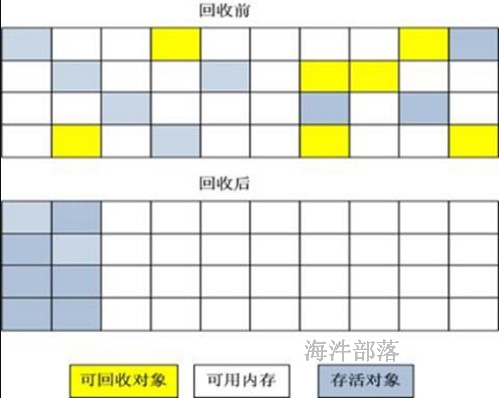
4)分代收集算法
GC分代的基本假设:绝大部分对象的生命周期都非常短暂,存活时间短。
“分代收集”(Generational Collection)算法,把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清理”或“标记-整理”算法来进行回收。

18.3 JVM的minor gc与full gc
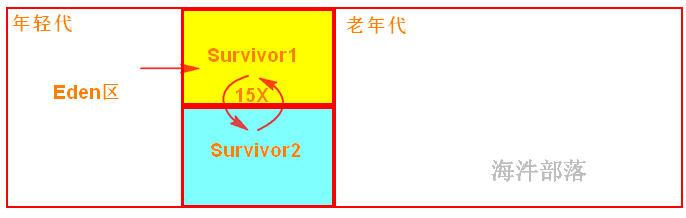
其中:
年轻代:存放岁数比较年轻的对象。分为 Eden区 和 Survivor区。
Eden区:开始对象分配的地方;
Survivor区:是经过minor gc 后存活对象的存储区域,一般这个区域要比Eden区小。分为两个区:from 和 to。
老年代:存放存活时间长的对象和年轻代存不下的对象,这个区域要比年轻代大的多。
1)对象分配
一般对象分配:当有新对象产生时,JVM会把对象分配到Eden区,Survivor区作为备用;
大对象分配:大对象是指需要连续空间的java对象,如很长的数组、字符串。这样的大对象不会分配在年轻代,直接进入老年代。
2)minor gc(年轻代 gc)
minor gc 是指 年轻代的垃圾收集动作。因为年轻代中的对象基本都是朝生夕死的(80%以上),所以Minor gc 会非常频繁,回收速度也比较快。
触发条件:Eden区满了。
操作方法:
1)第一次minor gc,通过复制算法,将Eden区存活的对象复制到 Survivor from 区,对象年龄设为1;
2)以后的minor gc,通过复制算法,将Eden区 和 Survivor from 区 存活的对象 复制到 Survivor to 区,然后 再将 to 区 变成新的 from 区,同时对象的年龄+1,一旦某个对象达到了指定的次数,就会把该对象移到老年代。
3)full gc(老年代 gc)
full gc 是指 老年代的垃圾收集动作。因为老年代中的对象大多是存活时间长的对象,老年代回收要用 标记整理或标记清除算法,回收速度很慢。
触发条件:老年代满了。
操作方法:
通过标记整理或标记清除算法,扫描老年代的每个对象,并回收不可达的对象。
18.4 频繁GC的影响及优化方法
1)频繁GC的影响
task运行期间动态创建的对象使用的Jvm堆内存的情况

当给spark任务分配的内存少了,会频繁发生minor gc,如果存活时间长的对象特别多,就会发生full gc。
当频繁的new对象时,导致很快进入老年代,这样也可能发生full gc。
频繁gc 会影响 工作任务线程的正常执行,从而降低spark 应用程序的性能。
2)优化方案
a)优化代码,避免频繁new 同一个对象,导致的频繁gc。
b)调节可用存储内存和执行内存的比例,以减少gc 发生的频率。
c)对应存储内存,可以考虑存储序列化后的对象,调节序列化级别为MEMORY_DISK_SER或MEMORY_ONLY_SER,这样占用内存空间小。
d)还可以使用Kryo序列化类库,进行序列化,因为kryo序列化方法可以进一步的降低RDD的parition的内存占用量。
19 spark 操作 hbase
spark没有读写hbase的api,如果想用spark操作hbase表,需要参考java和MapReduce操作hbase的api。
19.1 hbase配置
准备hbase环境
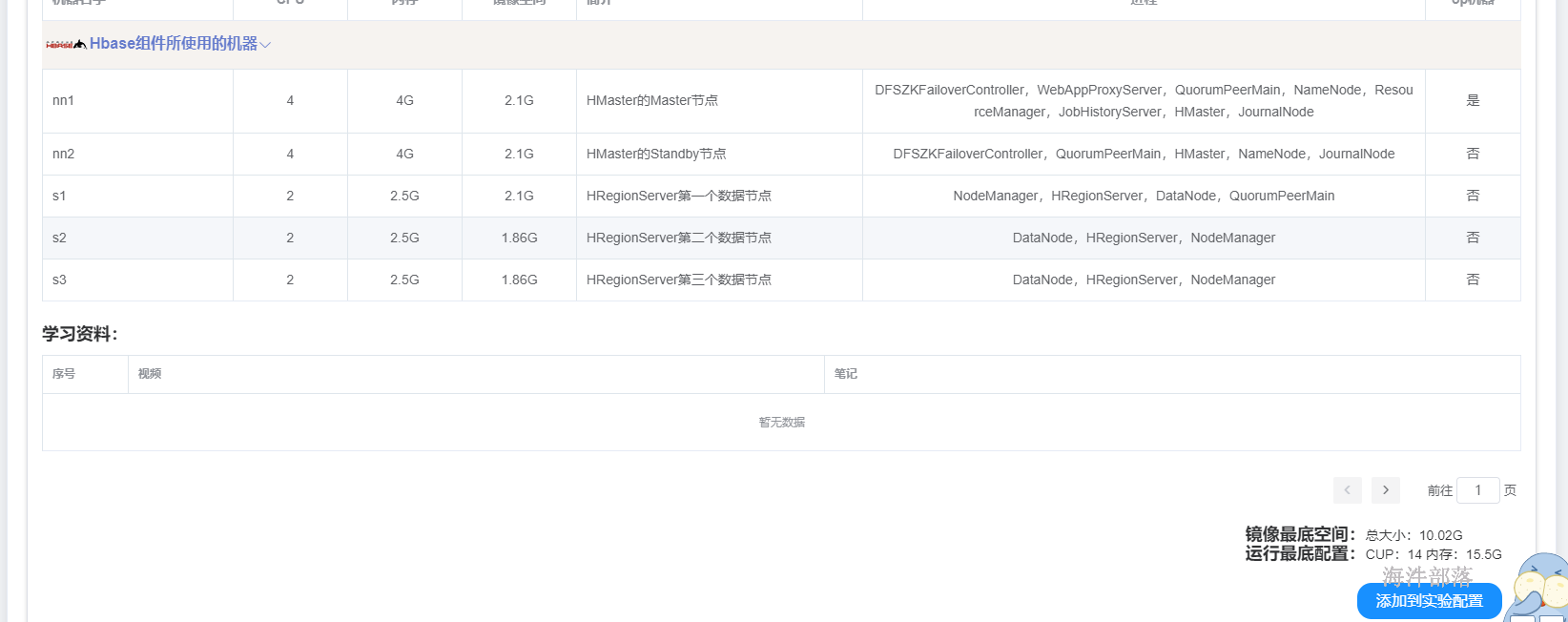
实验室中选择hbase添加到实验环境
1)pom
之前已经配置过,不需要配置
连接hbase的配置,可以是直接的代码配置还可以是配置文件设置
conf.set("hbase.zookeeper.quorum","zookeeper地址")可以去hbase集群的nn1机器中下载配置信息然后放入到项目本地
# 在opt文件夹下面 下载
hbase-site.xml
hdfs-site.xml
core-site.xml<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns1/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>nn1-20237,nn2-20237,s1-20237</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
</configuration>创建 hbase表
package com.hainiu.spark
import org.apache.hadoop.hbase.{HBaseConfiguration, NamespaceDescriptor, TableName}
import org.apache.hadoop.hbase.client.{ColumnFamilyDescriptorBuilder, ConnectionFactory, TableDescriptorBuilder}
import org.apache.hadoop.hbase.util.Bytes
/**
* 简单api
* configuration
* connectionFactory
* create delete truncate
* put scan delete
*/
object TestHbase {
def main(args: Array[String]): Unit = {
val conf = HBaseConfiguration.create()
// conf.set("hbase.zookeeper.quorum","11.106.67.56:2181")
val connection = ConnectionFactory.createConnection(conf)
val admin = connection.getAdmin
// val namedescriptor = NamespaceDescriptor.create("hainiu").build()
// admin.createNamespace(namedescriptor)
val cdesc = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info")).build()
val tabledesc = TableDescriptorBuilder.newBuilder(TableName.valueOf("hainiu:student1"))
.setColumnFamily(cdesc)
.build()
admin.createTable(tabledesc)
}
}操作数据
package com.hainiu.spark
import org.apache.hadoop.hbase.{HBaseConfiguration, NamespaceDescriptor, TableName}
import org.apache.hadoop.hbase.client.{ColumnFamilyDescriptorBuilder, ConnectionFactory, Put, ResultScanner, Scan, TableDescriptorBuilder}
import org.apache.hadoop.hbase.util.Bytes
import java.util
object TestPutData{
def main(args: Array[String]): Unit = {
val conf = HBaseConfiguration.create()
val con = ConnectionFactory.createConnection(conf)
val table = con.getTable(TableName.valueOf("hainiu:student"))
//put
val list = new util.ArrayList[Put]()
for(i<- 1 to 9999){
val put = new Put(Bytes.toBytes(s"rowkey_${i}"))
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(s"hainiu_${i}"))
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes(i))
list.add(put)
if(list.size() == 1000){
table.put(list)
list.clear()
}
}
if(list.size() > 0)
table.put(list)
con.close()
}
}
object TestScanData{
def main(args: Array[String]): Unit = {
val conf = HBaseConfiguration.create()
val con = ConnectionFactory.createConnection(conf)
val table = con.getTable(TableName.valueOf("hainiu:student"))
val scan = new Scan()
val scanner: ResultScanner = table.getScanner(scan)
val it = scanner.iterator()
while(it.hasNext){
val result = it.next()
val rowkey = result.getRow
val name = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name"))
val age = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age"))
println(Bytes.toString(rowkey),Bytes.toString(name),Bytes.toInt(age))
}
con.close()
}
}
19.2 table put
用表操作对象的put() 插入数据
准备数据
hello tom hello jack hello hainiu hello rose hello tom hello jerry hello tutu hello lailai
hello tom hello jack hello hainiu hello rose hello tom hello jerry hello tutu hello lailai
hello tom hello jack hello hainiu hello rose hello tom hello jerry hello tutu hello lailai#创建表
create 'hainiu:wordcount','info'程序:
package com.hainiu.spark
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{ConnectionFactory, Put}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount2Hbase {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("wordcount2Habse")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.textFile("file:///headless/workspace/spark/data/a.txt")
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
//foreach
rdd.foreachPartition(it=>{
val conf = HBaseConfiguration.create()
val con = ConnectionFactory.createConnection(conf)
val table = con.getTable(TableName.valueOf("hainiu:wordcount"))
it.foreach(t=>{
val put = new Put(Bytes.toBytes(t._1))
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("count"),Bytes.toBytes(t._2))
table.put(put)
})
con.close()
})
}
}

用表操作对象的put(list) 批量插入数据
package com.hainiu.sparkhbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, HTable, Put}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkHbaseTablePuts {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkHbaseTablePuts")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(20 until 30, 2)
// 一个分区创建一个hbase连接,批量写入,效率高
rdd.foreachPartition(it =>{
// 把每个Int 转成 Put对象
val puts: Iterator[Put] = it.map(f => {
// 创建Put对象
val put: Put = new Put(Bytes.toBytes(s"spark_puts_${f}"))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("count"), Bytes.toBytes(s"${f}"))
put
})
println("--创建hbase连接--")
val hbaseConf: Configuration = HBaseConfiguration.create()
var conn: Connection = null
var table: HTable = null
try{
// 创建hbase连接
conn = ConnectionFactory.createConnection(hbaseConf)
// 创建表操作对象
table = conn.getTable(TableName.valueOf("panniu:spark_user")).asInstanceOf[HTable]
// 通过隐式转换,将scala的List转成javaList
import scala.collection.convert.wrapAsJava.seqAsJavaList
// 一个分区的数据批量写入
table.put(puts.toList)
}catch {
case e:Exception => e.printStackTrace()
}finally {
table.close()
conn.close()
}
})
}
}
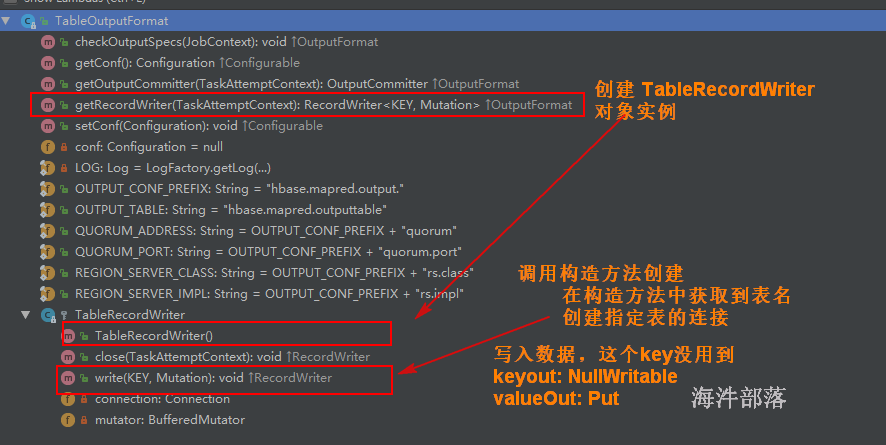
19.4 tableoutputformat put
用TableOutputFormat 来实现写入数据
package com.hainiu.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client.{ConnectionFactory, Put}
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.io.NullWritable
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.{SparkConf, SparkContext}
import java.util
object SparkWordCount2HbaseFormat {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("wordcount2Habse")
conf.setMaster("local[*]")
System.setProperty("hadoop.home.dir","/headless/hadoop-3.1.4")
val sc = new SparkContext(conf)
val rdd = sc.textFile("file:///headless/workspace/spark/data/a.txt")
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
//NUllWritable PUT
val rdd1 = rdd.map(t => {
val put = new Put(Bytes.toBytes(t._1))
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("count"), Bytes.toBytes(t._2))
(NullWritable.get(), put)
})
val hbaseConf: Configuration = HBaseConfiguration.create()
hbaseConf.set(TableOutputFormat.OUTPUT_TABLE, "hainiu:wordcount")
val job: Job = Job.getInstance(hbaseConf)
job.setOutputFormatClass(classOf[TableOutputFormat[NullWritable]])
job.setOutputKeyClass(classOf[NullWritable])
job.setOutputValueClass(classOf[Put])
rdd1.saveAsNewAPIHadoopDataset(job.getConfiguration)
println(1)
}
}
put: 一个元素创建一个连接,一条一条写入
puts: 一个分区创建一个连接,一个分区数据批量写入
write: 一个分区创建一个连接, 一个分区数据一条一条写入
效率高–> 低: puts —> write —-> put
19.5 tableoutputformat put partitions
package com.hainiu.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client.{ConnectionFactory, Put}
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.io.NullWritable
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.{SparkConf, SparkContext}
import java.util
object SparkWordCount2HbaseFormat {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("wordcount2Habse")
conf.setMaster("local[*]")
System.setProperty("hadoop.home.dir","/headless/hadoop-3.1.4")
val sc = new SparkContext(conf)
val rdd = sc.textFile("file:///headless/workspace/spark/data/a.txt")
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
//NUllWritable PUT
val rdd1 = rdd.map(t => {
val put = new Put(Bytes.toBytes(t._1))
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("count"), Bytes.toBytes(t._2))
(NullWritable.get(), put)
})
val hbaseConf: Configuration = HBaseConfiguration.create()
hbaseConf.set(TableOutputFormat.OUTPUT_TABLE, "hainiu:wordcount")
val job: Job = Job.getInstance(hbaseConf)
job.setOutputFormatClass(classOf[TableOutputFormat[NullWritable]])
job.setOutputKeyClass(classOf[NullWritable])
job.setOutputValueClass(classOf[Put])
rdd1.
coalesce(2).
saveAsNewAPIHadoopDataset(job.getConfiguration)
}
}

19.6 通过scan读取hbase表
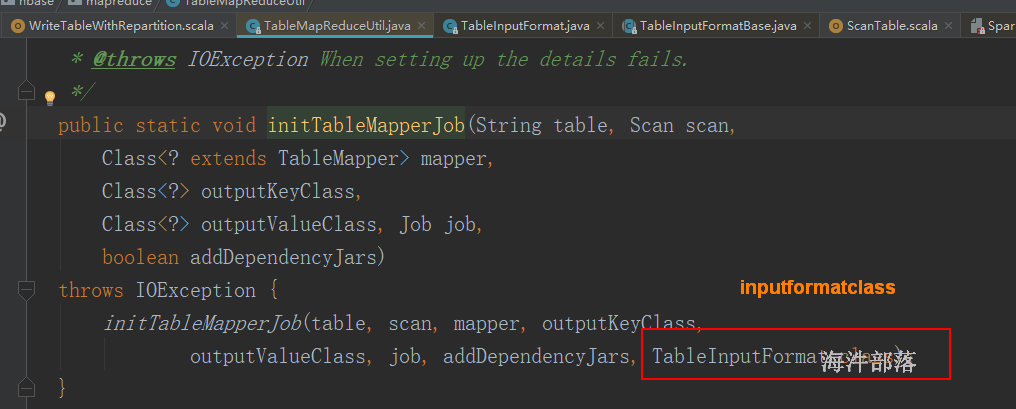
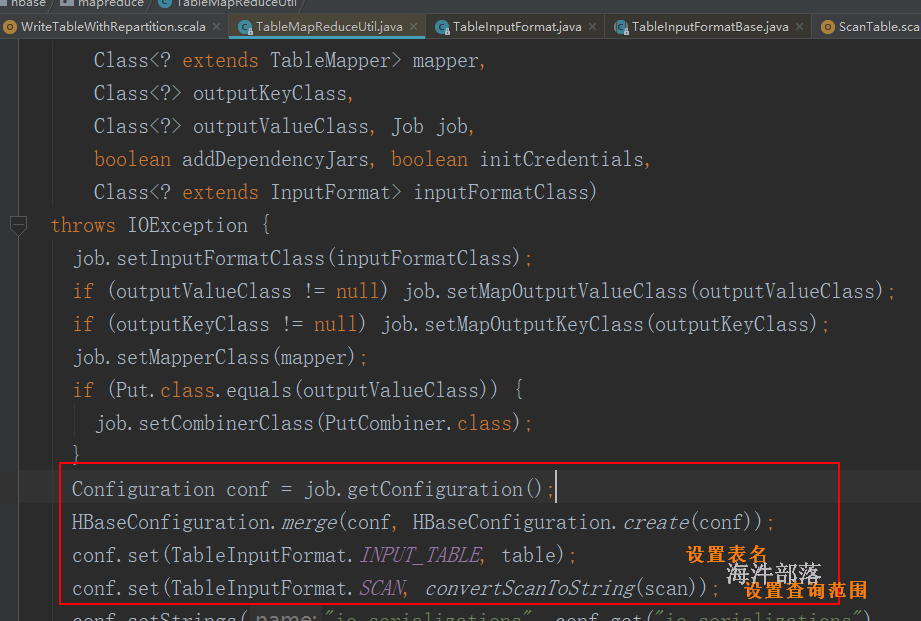
参考 TableMapReduceUtil.initTableMapperJob() 中参数的配置
package com.hainiu.spark
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{Result, Scan}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableMapReduceUtil}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.{SparkConf, SparkContext}
object ReadHbaseWithFormat {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test read")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
//tableMapReduceUtils
//ImmutableBytesWritable rowkey[key]
//result [value]
val scan = new Scan()
val config = HBaseConfiguration.create()
config.set(TableInputFormat.INPUT_TABLE,"hainiu:wordcount")
config.set(TableInputFormat.SCAN,TableMapReduceUtil.convertScanToString(scan))
sc.newAPIHadoopRDD(config,classOf[TableInputFormat],classOf[ImmutableBytesWritable],classOf[Result])
.map(t=>{
val rowkey = t._1.get()
val count = t._2.getValue(Bytes.toBytes("info"), Bytes.toBytes("count"))
(Bytes.toString(rowkey),Bytes.toInt(count))
}).foreach(println)
}
}结果: