1.zookeeper的介绍
ZooKeeper是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务,它提供了一项基本服务:分布式锁服务。分布式应用可以基于它实现更高级的服务,实现诸如同步服务、配置维护和集群管理或者命名的服务。
1.1 首先我们介绍一下集群的存在模式
1.主从集群

其中主节点的角色就是主,主节点消失了也只能从其他主节点中选出来,但是从节点就不能存在任何的选举可能
2.非主从集群

而在主从集群中就会出现单节点故障【比如皇帝挂了】
所以非主从集群中要存在两个主节点做热备份
1.2 zookeeper的作用
但是zookeeper为了让自身集群稳定自身也是集群形式的
1.3 zookeeper的集群形式
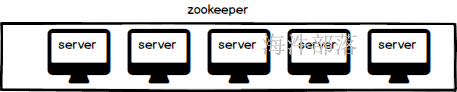
作为一个集群给其他集群做协调服务那么首先要保证自身也是稳定性较高的,自身的存在也是集群形式的
作为一个集群也是存在主点的,因为需要保证自身集群的可用和管理
那么真正的集群中zookeeper的服务节点的身份如下
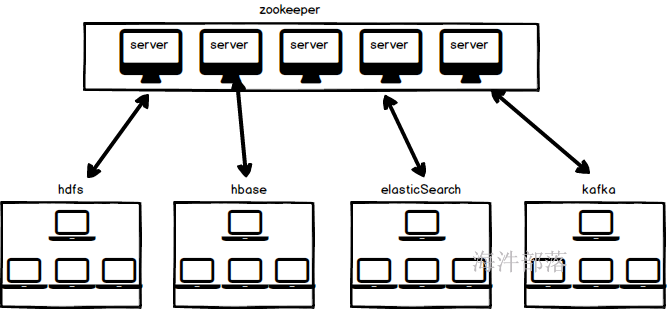
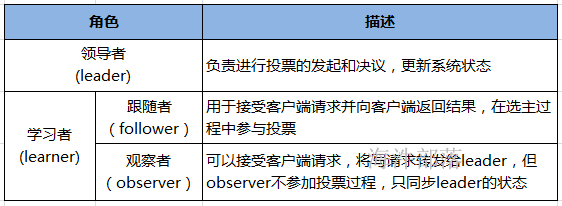
1.4 zookeeper中的角色
>> 领导者(leader),负责进行投票的发起和决议,更新系统状态(数据同步),发送心跳。
>> 学习者(learner),包括跟随者(follower)和观察者(observer)。
>> 跟随者(follower),用于接受客户端请求、向客户端返回结果,在选主过程中参与投票。
>> 观察者(Observer),可以接受客户端请求,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度。
如果Zookeeper集群的读取负载很高,或者客户端多到跨机房,可以设置一些observer服务器,以提高读取的吞吐量。
需要注意的是:
1)Leader和Follower构成Zookeeper集群的法定人数,也就是说,只有他们才能参与新Leader的选举以及响应Leader的提议。
2)observer不属于法定人数,即不参加选举也不响应提议。
1)leader失效后会在follower中重新选举新的leader
2)每个follower都和leader有连接,接受leader的数据更新操作
3)客户端可以连接到每个server,每个server的数据完全相同
4)每个节点的服务Server,记录事务日志和快照到持久存储
2.zookeeper的搭建
2.1 规划
nn1、nn2、s1。
其中:一个是leader,剩余的是Follower
2.2 制作 zookeeper 机器批量分布脚本
用之前的多机脚本拷贝一套zookeeper 多机操作脚本,然后修改成 zookeeper 用的多机操作脚本。
1)拷贝并修改带有ip的文件
#生成新的ip文件
cp ips ips_zk
#修改ips_zk文件 的主机名称只留下nn1、nn2、s1三台。
2)拷贝脚本
#复制三个zk的脚本
cp scp_all.sh scp_all_zk.sh
cp ssh_all.sh ssh_all_zk.sh
cp ssh_root.sh ssh_root_zk.sh3)修改脚本
#修改三个脚本的ip信息
vim scp_all_zk.sh
vim ssh_all_zk.sh
vim ssh_root_zk.sh
#修改其中的ips变为ips_zk
2.3 找到zookeeper的安装包
#找到每个安装zookeeper机器上的安装包
/public/software/bigdata/zookeeper-3.4.8.tar.gz2.4 在所有机器上把zookeeper的tar包解压到/usr/local目录下
ssh_root_zk.sh tar -zxvf /public/software/bigdata/zookeeper-3.4.8.tar.gz -C /usr/local/2.5 创建软链接
#在每台机器上给/usr/local/zookeeper-3.4.8创建zookeeper软链接
ssh_root_zk.sh ln -s /usr/local/zookeeper-3.4.8 /usr/local/zookeeper
#修改zookeeper的归属权限是hadoop用户
ssh_root_zk.sh chown hadoop:hadoop -R /usr/local/zookeeper-3.4.82.6 修改每个机器上的zookeeper 配置
2.6.1 zookeeper脚本所在目录——bin目录
2.6.2 zookeeper配置文件目录——conf目录
zookeeper的解压文件包含以下把内容
conf:配置文件包 bin:命令指定脚本 lib:依赖支持包
配置文件中的信息如下,我们需要修改的是zoo.cfg

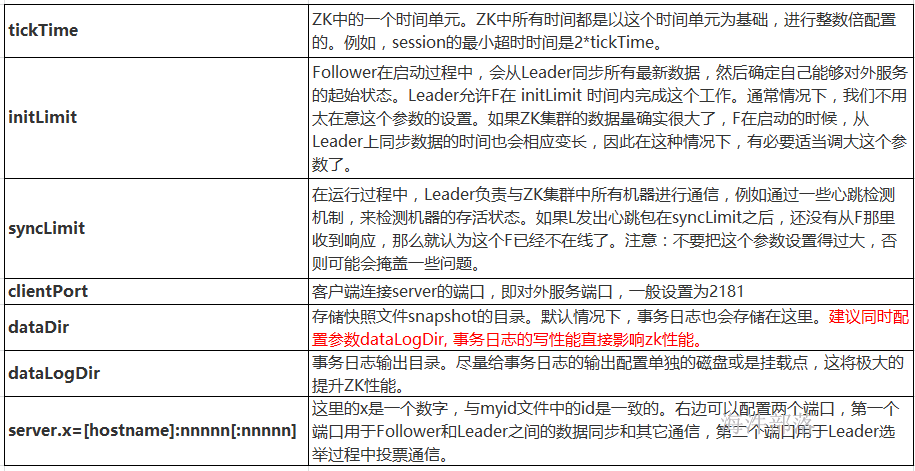
1)常用配置文件 conf/zoo.cfg,常用配置说明及示例
配置示例:
4)修改配置文件
#修改配置文件名称
mv /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
vim /usr/local/zookeeper/conf/zoo.cfg
#增加图上内容
server.1=nn1:2888:3888
server.2=nn2:2888:3888
server.3=s1:2888:3888
#其中1 2 3分别代表的节点编号 2888节点之间的通信端口 3888节点间的选举端口
dataDir=/data
#zookeeper运行时候的数据存储位置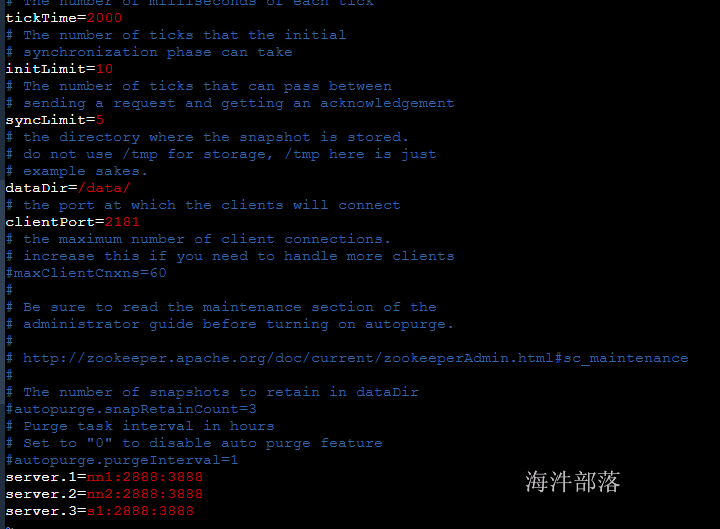
5)将zoo.cfg 配置批量拷贝到每台机器
#将zoo.cfg 配置文件批量拷贝到每台机器上
scp_all_zk.sh /usr/local/zookeeper/conf/zoo.cfg /usr/local/zookeeper/conf/
#检查是否拷贝成功
ssh_all_zk.sh ls /usr/local/zookeeper/conf/zoo.cfg 2.6.3 修改输出日志配置文件所在目录并分发配置
修改zookeeper/bin/zkEnv.sh 脚本,在脚本中给 ZOO_LOG_DIR 设置日志所在目录
修改后

#拷贝zkEnv.sh到每台机器的zookeeper的bin目录下
scp_all_zk.sh /usr/local/zookeeper/bin/zkEnv.sh /usr/local/zookeeper/bin/ 2.7 在每个机器上创建/data目录
#5个机器一起创建 /data目录,因为以后安装hadoop的时候也使用
ssh_root.sh mkdir /data
#修改五个机器的data目录是hadoop权限
ssh_root.sh chown hadoop:hadoop -R /data
#批量验证
ssh_root.sh "ls -l / | grep data"2.8 在新建的/data目录下生成myid文件(这个只能手动,不能使用批量脚本)
#在每个机器的/data目录下创建myid文件
ssh_all_zk.sh touch /data/myid 每台机器都需要单独执行
#第一台:
echo "1" > /data/myid
#第二台:
echo "2" > /data/myid
#第三台:
echo "3" > /data/myid
#查看
ssh_all_zk.sh cat /data/myid补充:
以下是实验室的机器文件系统目
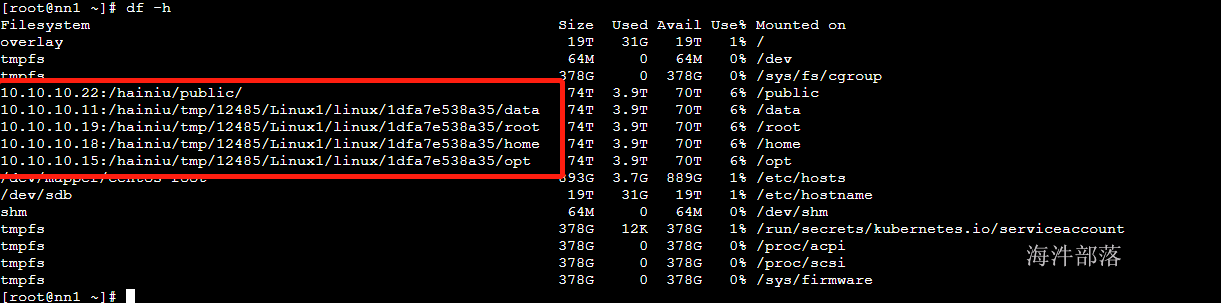
其中链接形式展示的目录都是挂载在海牛云盘上面的,所以存储数据在这里面机器的启动速度会比较快因为直接从云盘加载,本地不用装载数据,但是这个目录中的数据使用起来需要将云盘的数据放入到自己的本地所以比较慢,小伙伴们在使用的时候要注意!!!!
2.9 给5个机器设置好环境变量
env 查看当前shell环境下已有环境变量
1./etc/profile整个系统的
2.\~/.bash_profile当前用户的。
加载顺序是先加载系统,再加载自己的。
#在nn1 nn2 s1的机器上面执行以下操作
echo 'export ZOOKEEPER_HOME=/usr/local/zookeeper' >> /etc/profile
echo 'export PATH=$PATH:$ZOOKEEPER_HOME/bin' >> /etc/profile加到/etc/profile文件的底部,并且确认保存,注意使用root用户操作,再切换一个用户或者退出就会重新加载刚才的设置,再加env验证一下是否配置正确
#批量分发
scp_all_zk.sh /etc/profile /tmp
#曲线救国将数据从tmp目录提取出来放入到/etc目录下
ssh_root_zk.sh mv /tmp/profile /etc/profile
#批量验证
ssh_root_zk.sh tail /etc/profile
#批量source
ssh_root_zk.sh source /etc/profile查看每个机器的JAVA 版本
ssh_all.sh java -version 2.10 在每个机器上启动zookeeper服务并查看启动结果
2.10.1 在每个机器上启动zookeeper服务
#批量启动
ssh_all_zk.sh /usr/local/zookeeper/bin/zkServer.sh start
#批量查看java进程用jps
ssh_all_zk.sh jps
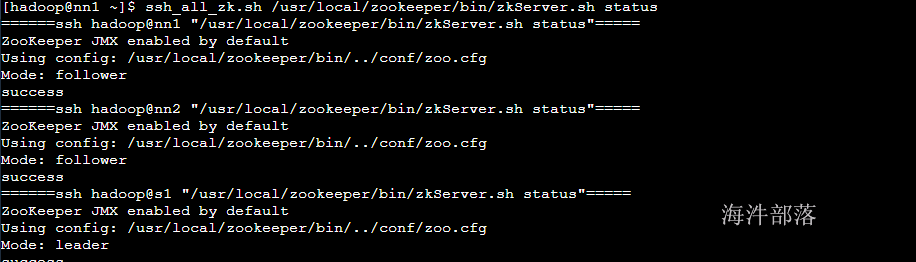
#查询各个zookeeper节点的状态
ssh_all_zk.sh /usr/local/zookeeper/bin/zkServer.sh status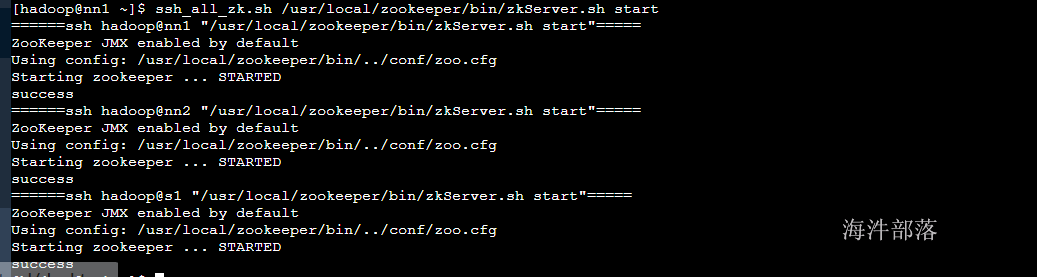
查看状态 status
补充问题:前台执行和后台执行
在linux或者是window电脑中执行一个程序可以是前台执行也可以是后台执行的,前台就像是我们玩游戏一样,后台就像是支撑系统运行的很多应用程序一样,我们虽然看不见但是却在后台默默执行着
对于zookeeper服务而言他的执行就是后台执行
那么在linux中怎么实现一个 程序的后台执行呢????
这要我们使用两个命令分别是nohup命令和&,其中nohup是后台一直执行,即使用户账户退出也可以一直执行,而&是让程序在后台执行
首先我们生命定义一个执行脚本
vim ~/f1.sh
#输入以下内容
#! /bin/bash
name='hainiu'
echo $name
sleep 20
echo 'end'
#增加执行权限
chmod +x ~/f1.sh
#执行脚本命令
~/f1.sh
程序前台执行处于卡死状态
#使用nohup执行
nohup ~/f1.sh &
发现程序处于后台执行过程中
默认执行输出文件内容位置nohup.out中
#所以程序运行我们要选择文件执行日志输出位置
#linux进程中2代表是错误输出结果 1代表是正常输出结果 2>&1
nohup ~/f1.sh >>test.log 2>&1 &
#后台执行并且输出到test.log中
#其中输出日志结果可以写出到 /dev/null中,这个位置是系统黑洞,什么都会消失
#所以如果不看重日志那么可以输出到这个位置
nohup ~/f1.sh >> /dev/null 2>&1 &2.10.2 查看ZK输出日志和进程信息
#日志输出文件
/data/zookeeper.out由于ZooKeeper集群启动的时候,每个结点都试图去连接集群中的其它结点,先启动的肯定连不上后面还没启动的,所以上面日志前面部分的异常是可以忽略的。通过后面部分可以看到,集群在选出一个Leader后,最后稳定了。
其他结点可能也出现类似问题,属于正常。
2.10.3 怎么查看系统进程输入日志文件位置
通过 JPS 查看进程ID
去查看进程ID文件,再到FD目录就能查看到当前进程所使用的管道信息

通过进程id查看linux服务运行日志
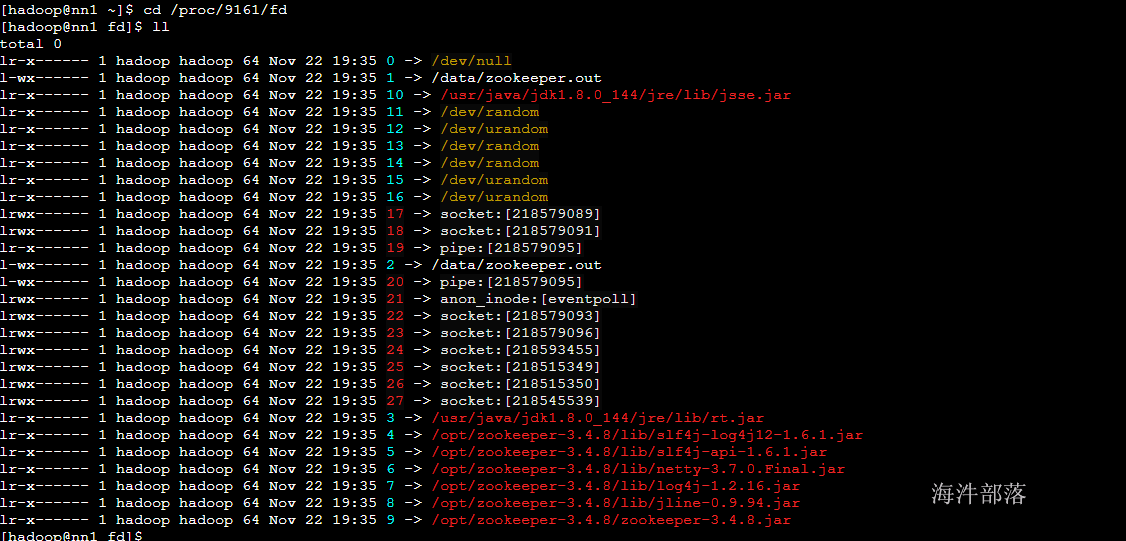
在此文件夹中可以看到所有的进程使用文件和连接信息,其中2代表错误日志输出位置 1代表正确日志输出位置
3.zookeeper的数据模型
1)ZooKeeper本质上是一个分布式的小文件存储系统;
2)Zookeeper表现为一个分层的文件系统目录树结构(不同于文件系统的是,节点可以有自己的数据,而文件系统中的目录节点只有子节点),每个节点可以存少量的数据(1M左右)。
3)每个节点称做一个ZNode。每个ZNode都可以通过其路径唯一标识。
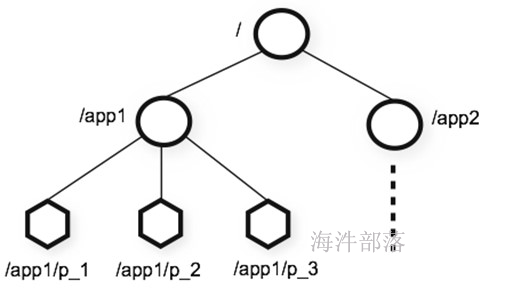
4)ZooKeeper中的每个节点存储的数据要被原子性的操作。也就是说读操作将获取与节点相关的所有数据,写操作也将替换掉节点的所有数据。
5)在zookeeper创建顺序节点(create -s ),节点路径后加编号,这个计数对于此节点的父节点来说是唯一的。
/app/
/s100000000001
/s100000000002

6)ZooKeeper中的节点有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。
① 临时节点:在客户端用create -e创建,该节点的生命周期依赖于创建它们的会话。一旦会话(Session)结束,临时节点将被自动删除,当然可以也可以手动删除。虽然每个临时的Znode都会绑定到一个客户端会话,但他们对所有的客户端还是可见的。另外,ZooKeeper的临时节点不允许拥有子节点。
② 永久节点:在客户端用create 创建,该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
7)客户端可以给节点设置watch,我们称之为监视器。当节点状态发生改变时(Znode的增、删、改)将会触发watch所对应的操作。当watch被触发时,ZooKeeper将会向客户端发送且仅发送一条通知。
4.zookeeper的选举
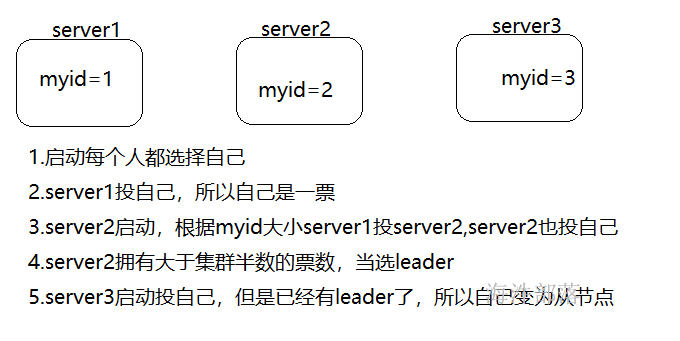
1.在集群初始化阶段,只有两台以上的 ZK 启动才会发生leader选举,过程如下:
2.集群恢复的时候
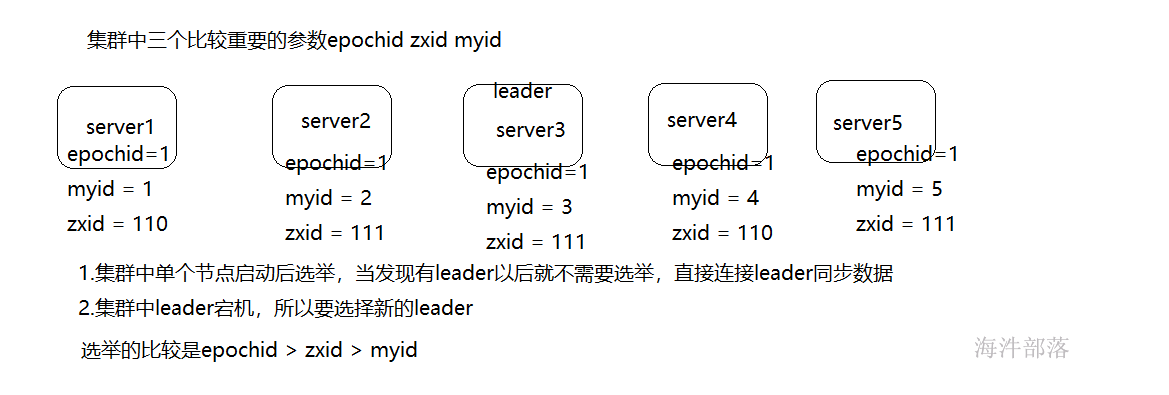
其中:
Looking :系统刚启动时或者Leader崩溃后正处于Leader选举状态;
Following :Follower节点所处的状态,Follower与Leader处于数据同步阶段;
Leading :Leader节点所处状态,当前集群中有一个Leader为主进程时的状态;

