5.zookeeper的使用命令
3.1 ZooKeeper服务命令
1)启动ZK服务: sh bin/zkServer.sh start
2)查看ZK服务状态: sh bin/zkServer.sh status
3)停止ZK服务: sh bin/zkServer.sh stop
4)重启ZK服务: sh bin/zkServer.sh restart
#查看每个机器ZK运行的状态
./ssh_all_zookeeper.sh /usr/local/zookeeper/bin/zkServer.sh status
#整体停止服务
./ssh_all_zookeeper.sh /usr/local/zookeeper/bin/zkServer.sh stop 3.2 zk客户端命令
- 1. 显示根节点下的子节点: ls /
- 2. 显示根目录下的子节点和说明信息: ls2
- 3. 创建znode,并设置初始内容
创建永久节点:create /zk "节点内容"
创建临时节点:create -e /zk/app "节点内容"
创建时序节点:create -s /zk/app/s1 "节点内容"
- 4. 获取节点内容: get /zk
- 5. 修改节点内容: set /zk "zkbak" 对 zk 所关联的字符串进行设置
- 6. 删除节点(此种方式该节点下不能有子节点): delete /zk
- 7. 删除节点和所有子节点:rmr /zk
- 7. 退出客户端: quit
- 8. 帮助命令: help
#启动zkclient,并连接zookeeper集群
/usr/local/zookeeper/bin/zkCli.sh -server nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181nn1机器客户端登录
cZxid:创建节点时的事务id
pZxid:子节点列表最后一次被修改的事务id
cversion:节点版本号
dataCersion:数据版本号
aclVerson:acl权限版本号
如何查看是临时节点还是永久节点?
当get 节点信息时,其中有一个字段是ephemeralOwner意思是这个节点的临时拥有者。
当ephemeralOwner 值不为0时,表明这个节点是临时节点,值为会话id。
当ephemeralOwner 值为0时,表明这个节点是永久节点。.
[zk: nn1.hadoop:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: nn1.hadoop:2181(CONNECTED) 1] ls2 /
[zookeeper]
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
[zk: nn1.hadoop:2181(CONNECTED) 2] get /
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
# 创建永久节点
[zk: nn1.hadoop:2181(CONNECTED) 3] create /hainiu "hainiu bigdata"
Created /hainiu
[zk: nn1.hadoop:2181(CONNECTED) 4] ls /
[hainiu, zookeeper]
[zk: nn1.hadoop:2181(CONNECTED) 5] ls /hainiu
[]
[zk: nn1.hadoop:2181(CONNECTED) 6] get /hainiu
hainiu bigdata
cZxid = 0x300000002
ctime = Sat Jul 17 16:04:50 CST 2021
mZxid = 0x300000002
mtime = Sat Jul 17 16:04:50 CST 2021
pZxid = 0x300000002
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0 # 为0:永久, 非0:临时
dataLength = 14
numChildren = 0
[zk: nn1.hadoop:2181(CONNECTED) 7] set /hainiu "hainiu bigdata base"
cZxid = 0x300000002
ctime = Sat Jul 17 16:04:50 CST 2021
mZxid = 0x300000003
mtime = Sat Jul 17 16:06:05 CST 2021
pZxid = 0x300000002
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 19
numChildren = 0
[zk: nn1.hadoop:2181(CONNECTED) 8] get /hainiu
hainiu bigdata base
cZxid = 0x300000002
ctime = Sat Jul 17 16:04:50 CST 2021
mZxid = 0x300000003
mtime = Sat Jul 17 16:06:05 CST 2021
pZxid = 0x300000002
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 19
numChildren = 0
[zk: nn1.hadoop:2181(CONNECTED) 9] ls /
[hainiu, zookeeper]
# 创建临时节点
[zk: nn1.hadoop:2181(CONNECTED) 10] create -e /hainiu/c33 "class33"
Created /hainiu/c33
# 在nn2上查看
[zk: nn2.hadoop(CONNECTED) 3] get /hainiu/c33
class33
cZxid = 0x300000005
ctime = Sat Jul 17 16:08:37 CST 2021
mZxid = 0x300000005
mtime = Sat Jul 17 16:08:37 CST 2021
pZxid = 0x300000005
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x17ab3790f740000 # 临时节点
dataLength = 7
numChildren = 0
# 把nn1 的session关掉
[zk: nn1.hadoop:2181(CONNECTED) 11] quit
# 退出后,发现 /hainiu/c33 节点消失了
# 测试时序节点
[zk: nn1.hadoop:2181(CONNECTED) 0] ls /
[hainiu, zookeeper]
[zk: nn1.hadoop:2181(CONNECTED) 1] ls /hainiu
[]
[zk: nn1.hadoop:2181(CONNECTED) 2] create -s /hainiu/class "c1"
Created /hainiu/class0000000001
[zk: nn1.hadoop:2181(CONNECTED) 3] create -s /hainiu/class "c2"
Created /hainiu/class0000000002
[zk: nn1.hadoop:2181(CONNECTED) 4] create -s /hainiu/class "c3"
Created /hainiu/class0000000003
[zk: nn1.hadoop:2181(CONNECTED) 5] create -s /hainiu/class "c4"
Created /hainiu/class0000000004
[zk: nn1.hadoop:2181(CONNECTED) 6] ls /hainiu
[class0000000003, class0000000002, class0000000001, class0000000004]
[zk: nn1.hadoop:2181(CONNECTED) 7] get /hainiu/class000000000
class0000000003 class0000000002 class0000000001 class0000000004
[zk: nn1.hadoop:2181(CONNECTED) 7] get /hainiu/class0000000001
c1
cZxid = 0x300000008
ctime = Sat Jul 17 16:10:57 CST 2021
mZxid = 0x300000008
mtime = Sat Jul 17 16:10:57 CST 2021
pZxid = 0x300000008
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 2
numChildren = 0
[zk: nn1.hadoop:2181(CONNECTED) 8]
# 测试删除
[zk: nn1.hadoop:2181(CONNECTED) 8] ls /hainiu
[class0000000003, class0000000002, class0000000001, class0000000004]
[zk: nn1.hadoop:2181(CONNECTED) 9] create /app "app"
Created /app
[zk: nn1.hadoop:2181(CONNECTED) 10] ls /
[app, hainiu, zookeeper]
[zk: nn1.hadoop:2181(CONNECTED) 11] delete /app
[zk: nn1.hadoop:2181(CONNECTED) 12] ls /
[hainiu, zookeeper]
[zk: nn1.hadoop:2181(CONNECTED) 13]
[zk: nn1.hadoop:2181(CONNECTED) 13] delete /hainiu
Node not empty: /hainiu
[zk: nn1.hadoop:2181(CONNECTED) 14] rmr /hainiu
[zk: nn1.hadoop:2181(CONNECTED) 15] ls /
[zookeeper]3.3 zookeeper的读写数据流程
1)写操作
写入数据的指定leader写入
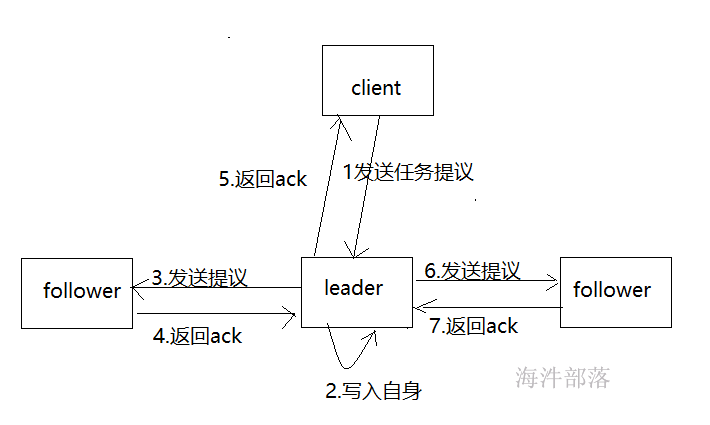
写入数据请求follower的情况
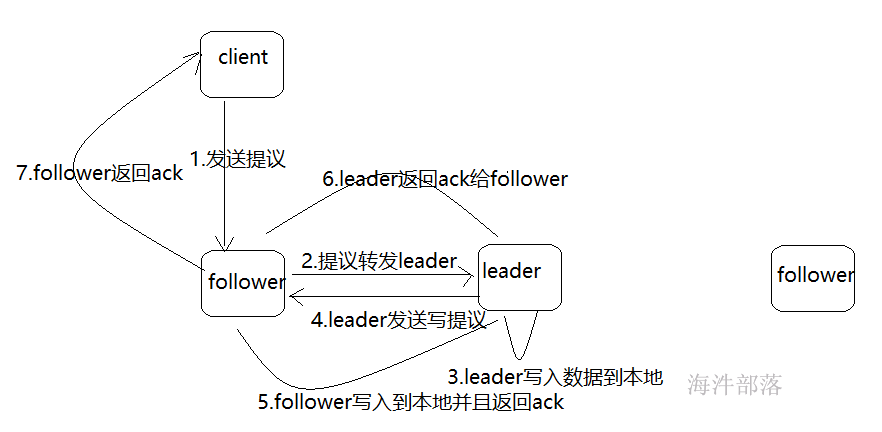
2)读操作
1)在Client向Follwer 或 Observer 发出一个读的请求;
2)Follwer 或 Observer 把请求结果返回给Client;
6.zookeeper的使用场景
6.1 zookeeper的特点
最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的特性;
可靠性:具有简单、健壮、良好的性能,如果消息被某一台服务器接受,那么它将被所有的服务器接受;
实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。 但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口;
等待无关(wait-free):慢的或者失效的client,不得干预快速的client的请求,使得每个client都能有效的等待;
原子性:更新只能成功或者失败,没有中间状态;
顺序性:按照客户端发送请求的顺序更新数据;
6.2 zookeeper的使用场景
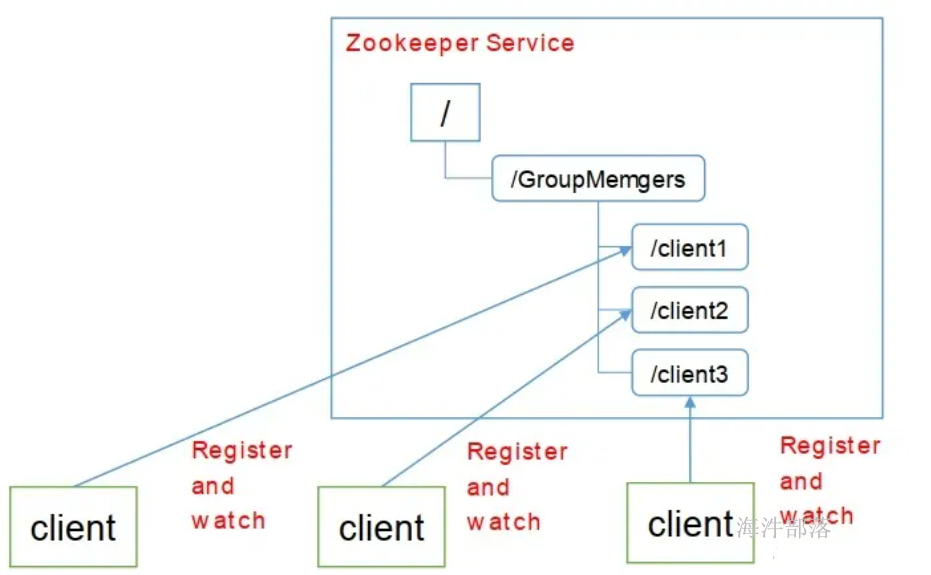
6.2.1 集群管理
每个加入集群的机器都创建一个节点,写入自己的状态。监控父节点的用户会收到通知,进行相应的处理。离开时session失效,节点删除,监控父节点的用户同样会收到通知。
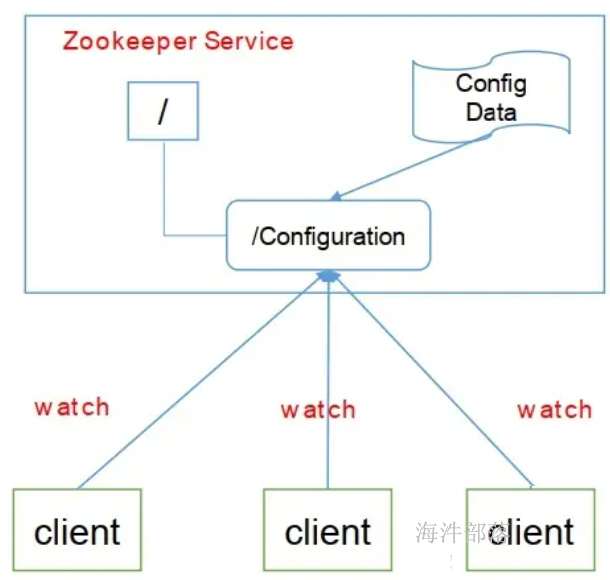
6.2.2 数据发布与订阅
发布与订阅即所谓的配置管理,顾名思义就是将数据发布到ZK节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。
应用配置集中到znode上,应用启动时主动获取,并在znode上注册一个watcher,每次配置更新都会通知到应用。
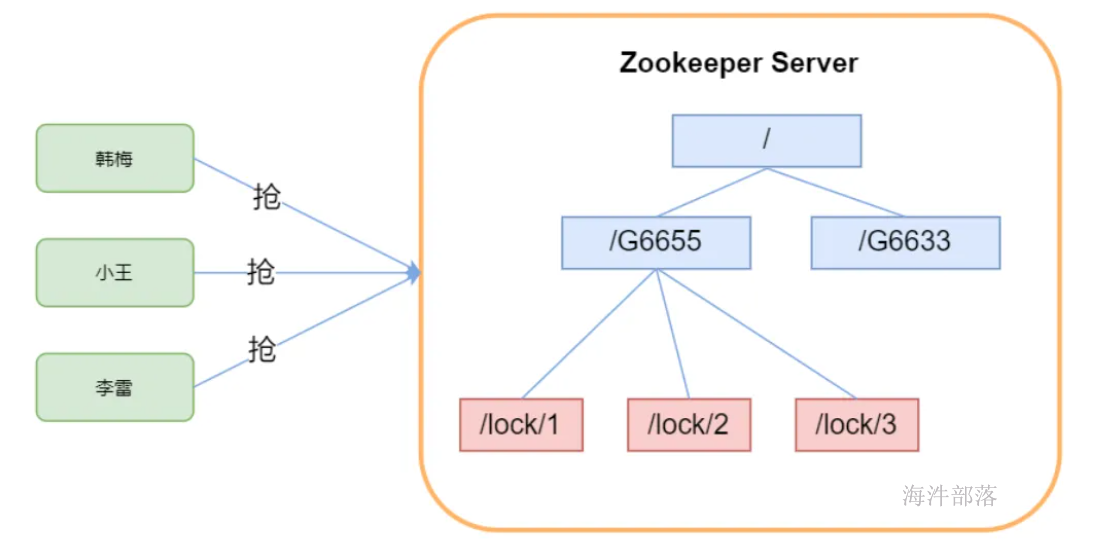
6.2.3 分布式锁
Zookeeper能保证数据的强一致性,用户任何时候都可以相信集群中每个节点的数据都是相同的。
锁的两种体现方式:
1)独占锁(多人抢椅子坐,谁坐在椅子上,谁就获取锁;离开椅子释放锁)
一个用户创建一个znode作为锁,另一个用户检测该znode,如果存在,代表别的用户已经锁住,如果不存在,则可以创建一个znode,代表拥有一个锁。
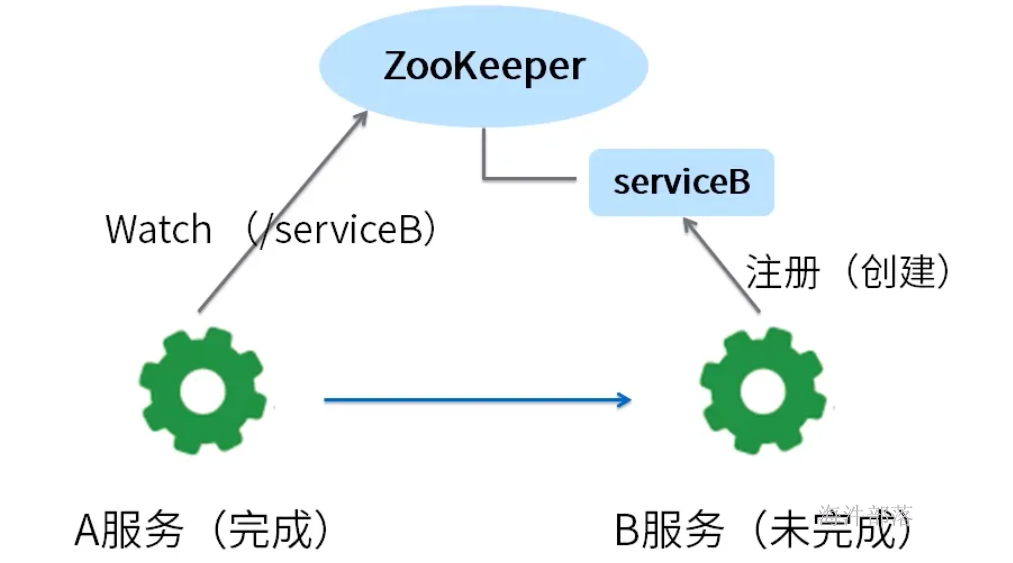
2)时序锁(看谁先创建,谁先创建,谁就获取锁)
有一个znode作为父节点,其底下是带有编号的子节点,所有要获取锁的用户,需要在父节点下创建带有编号的子节点,编号最小的会持有锁;当最小编号的节点被删除后,锁被释放,再重新找最小编号的节点来持有锁,这样保证了全局有序。
7. zookeeper的简单api和使用实现
7.1 环境搭建
pom文件的依赖
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.8</version>
</dependency>log4j的配置
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n 7.2简单api的实现
创建连接
val zk = new ZooKeeper("nn1.hadoop:2181",5000,new Watcher {
override def process(watchedEvent: WatchedEvent): Unit = {}
})节点操作
//创建节点
zk.create("/class_45","xiaobo_gande".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT)
//删除节点
zk.delete("/class_45",-1)
//设置值
zk.setData("/class_45","wangsai".getBytes(),-1)
//获取值
val data = zk.getData("/class_45",false,new Stat())
println(new String(data))
for(i<-1 to 10){
//创建子节点
zk.create(s"/class_45/child_${i}",s"littlesai_${i}".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT)
}
//获取子节点
val children: util.List[String] = zk.getChildren("/class_45",false)
import scala.collection.JavaConversions._
for(c<-children){
val data = zk.getData(s"/class_45/${c}",false,new Stat())
println(new String(data))
}7.3 服务注册代码场景实现
监控服务端
public class MonitorServer {
private static final String path = "/servers";
private static ZooKeeper zk = null;
//创建zk连接
public static void init() throws IOException {
zk = new ZooKeeper("nn1.hadoop:2181", 5000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
try {
monitorServers();
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
public static void main(String[] args) throws Exception {
init();
monitorServers();
Thread.sleep(Long.MAX_VALUE);
}
public static void monitorServers() throws Exception {
List<String> childs = zk.getChildren(path, true);
for (String child : childs) {
byte[] data = zk.getData(path + "/" + child, false, null);
System.out.println("当前在线服务器有:"+new String(data));
}
}
}监控客户端
public class RegisterClient {
private static ZooKeeper zk =null;
private static final String path = "/servers";
private static final String name = "s3";
public static void init() throws IOException {
zk = new ZooKeeper("nn1.hadoop:2181", 5000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
}
});
}
public static void main(String[] args) throws Exception {
init();
String path = zk.create(RegisterClient.path + "/" + name, name.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println(path+"注册成功!!!");
Thread.sleep(Long.MAX_VALUE);
}
}7.4独享锁的实现机制
public class RegisterClient {
private static ZooKeeper zk =null;
private static final String path = "/servers";
private static final String name = "lock";
public static void init() throws IOException {
zk = new ZooKeeper("nn1.hadoop:2181", 5000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
try {
if(watchedEvent.getType().equals(Event.EventType.NodeDeleted))
regist();
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
public static void regist() throws KeeperException, InterruptedException {
try {
String lock = zk.create(path + "/" + name, "nn1".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println("竞争到独享锁,做自己的事情!!!");
}catch (KeeperException.NodeExistsException e){
zk.exists(path+"/"+name,true);
System.out.println("没有竞争到锁,等待锁!!!!");
}catch (Exception e){
System.out.println("独享锁出错");
e.printStackTrace();
System.exit(1);
}
}
public static void main(String[] args) throws Exception {
init();
regist();
Thread.sleep(Long.MAX_VALUE);
}
}7.5 共享锁的代码实现
public class DistributeShareLock {
private static ZooKeeper zk = null;
private String self_lock = null;
private static final String lock_path = "/servers/lock";
private static final String lock_prefix = "/servers";
public void init() throws IOException {
zk = new ZooKeeper("nn1.hadoop:2181", 5000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
try {
getLock();
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
public void work() throws InterruptedException {
System.out.println("当前获取到共享锁!!!做自己的事情!!!");
Thread.sleep(10000);
System.exit(1);
}
public void init_mylock() throws KeeperException, InterruptedException {
self_lock = zk.create(lock_path, "my_lock".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}
public void getLock() throws KeeperException, InterruptedException {
List<String> children = zk.getChildren(lock_prefix, false);
if(children.size() == 1){
//如果只有一个那么肯定是自己
work();
}else if(children.size() == 0){
System.out.println("锁出现异常!!!");
System.exit(1);
}else{
Collections.sort(children);
String my_lock_path = self_lock.substring(lock_prefix.length()+1);
int index = children.indexOf(my_lock_path);
if(index == 0){
//自己是最小的
work();
}else{
zk.exists(lock_prefix+"/"+children.get(index-1),true);
//如果不是最小的那么监控比自己小的
}
}
}
public static void main(String[] args) throws Exception {
DistributeShareLock l1 = new DistributeShareLock();
l1.init();
l1.init_mylock();
l1.getLock();
Thread.sleep(Long.MAX_VALUE);
}
}8 ZAB协议和数据恢复
8.1 paxos协议
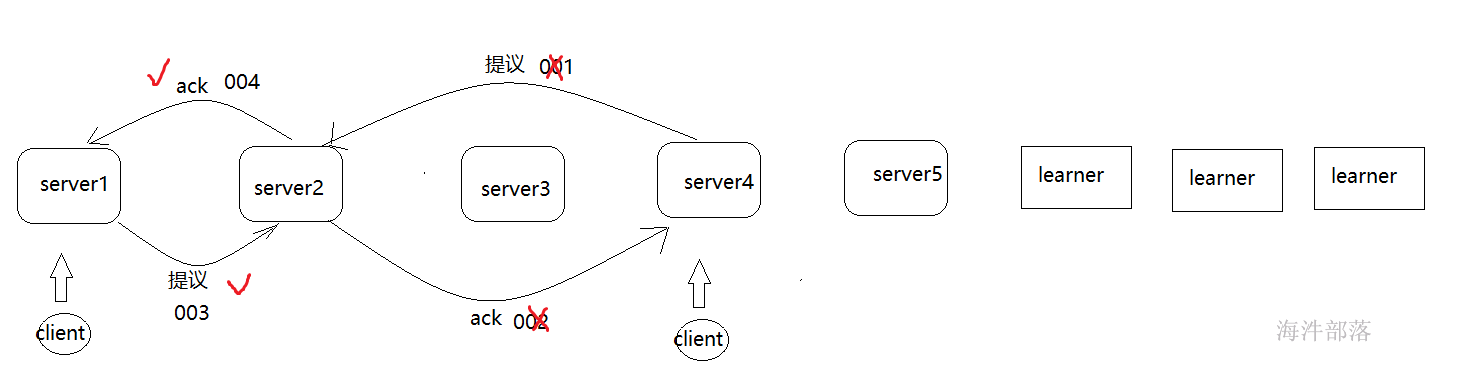
paxos协议分为三个阶段
- 提议者发送提议到各个接受者部分,接受者给出反馈
- 真正提出操作提议,接受者接受并且产生动作
- 将所有的提议结果发送给不同的learner
paxos算法的缺陷问题
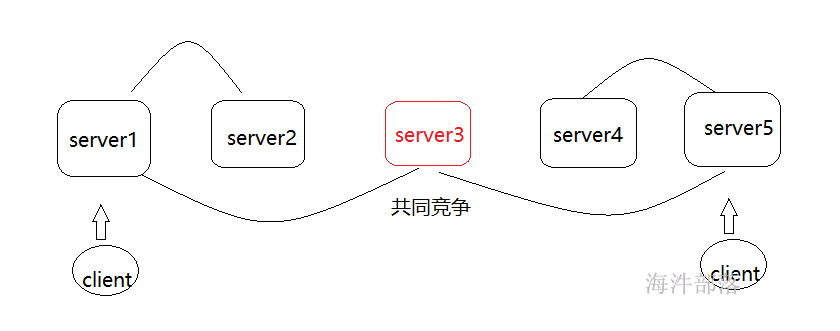
如果server1和server5共同竞争server3作为提议的决定者,那么server3会造成两个提议端的摇摆不定的问题
8.2 ZAB协议的出现
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的数据一致性。实现这个机制的协议叫做Zab协议。
Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。
恢复模式:
当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,恢复模式不接受客户端请求,当领导者被选举出来,且过半的Follower完成了和leader的状态同步以后,恢复模式就结束了。剩下未同步完成的机器会继续同步,直到同步完成并加入集群后该节点的服务才可用。
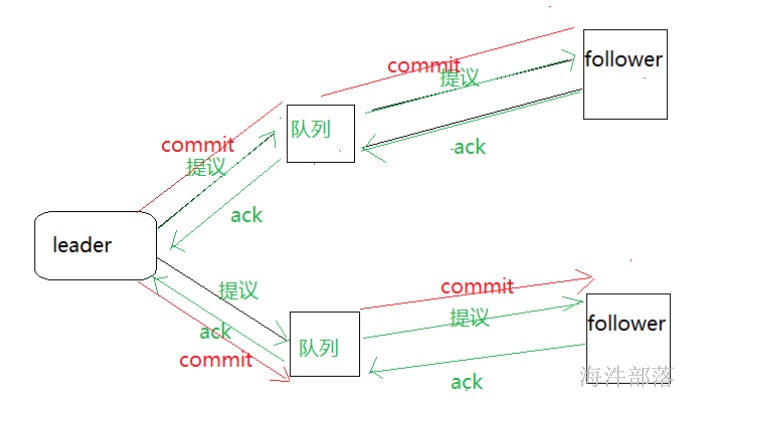
失败恢复的两种情况
1.leader发送完毕提议就宕机了
2.leader接受完毕ack,但是没有commit提交就宕机了
zab协议的条件
1.所有commit的提议必须被执行
2.没有被commit的执行的必须全部丢掉
选举leader的要求
1.首先是zxid最大的,可以防止数据丢失
2.这个leader不能存在未完成的提议
leader选举完毕后的动作
1.扫清障碍,保证所有的提议都被执行了
2.将落后的follower进行数据同步,并且加入到follower的队伍中
广播模式:
当集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进人消息广播模式了。这时候当一个Server加入ZooKeeper服务中,它会在恢复模式下启动,发现Leader,并和Leader进行状态同步。待到同步结束,它也参与消息广播。ZooKeeper的广播状态一直到Leader崩溃了或者Leader失去了大部分的Followers支持。
8.3 为什么zookeeper最好是奇数台?
首先需要明确zookeeper选举的规则:leader选举,要求 可用节点数量 > 总节点数量/2 。注意 是 > , 不是 ≥。
1)防止在脑裂的情况下集群不可用
脑裂:集群的脑裂通常是发生通信不可达的在节点之间情况下,集群会分裂成不同的小集群,小集群各自选出自己的master节点,导致原有的集群出现多个master节点的情况,这就是脑裂。
集群有奇数台机器,由于网络原因导致脑裂,一端机器多,一端机器少,多数端机器数量 > 集群总机器数/2,集群可用。
集群有4台机器,由于网络原因导致脑裂,有可能出现两端的机器数一样,两端都不 > 集群总机器数/2,集群不可用。
2)在容错能力相同的情况下,奇数台更节省资源
leader选举,要求 可用节点数量 > 总节点数量/2 。注意 是 > , 不是 ≥。
举两个例子:
(1) 假如zookeeper集群1,有3个节点,3/2=1.5 , 即zookeeper想要正常对外提供服务(即leader选举成功),至少需要2个节点是正常的。换句话说,3个节点的zookeeper集群,允许有一个节点宕机。
(2) 假如zookeeper集群2,有4个节点,4/2=2 , 即zookeeper想要正常对外提供服务(即leader选举成功),至少需要3个节点是正常的。换句话说,4个节点的zookeeper集群,也允许有一个节点宕机。
那么问题就来了, 集群1与集群2都有 允许1个节点宕机 的容错能力,但是集群2比集群1多了1个节点。在相同容错能力的情况下,本着节约资源的原则,zookeeper集群的节点数维持奇数个更好一些。

