hbase的架构和读写流程
7.hbase的整体架构
hbase的region存储原理图
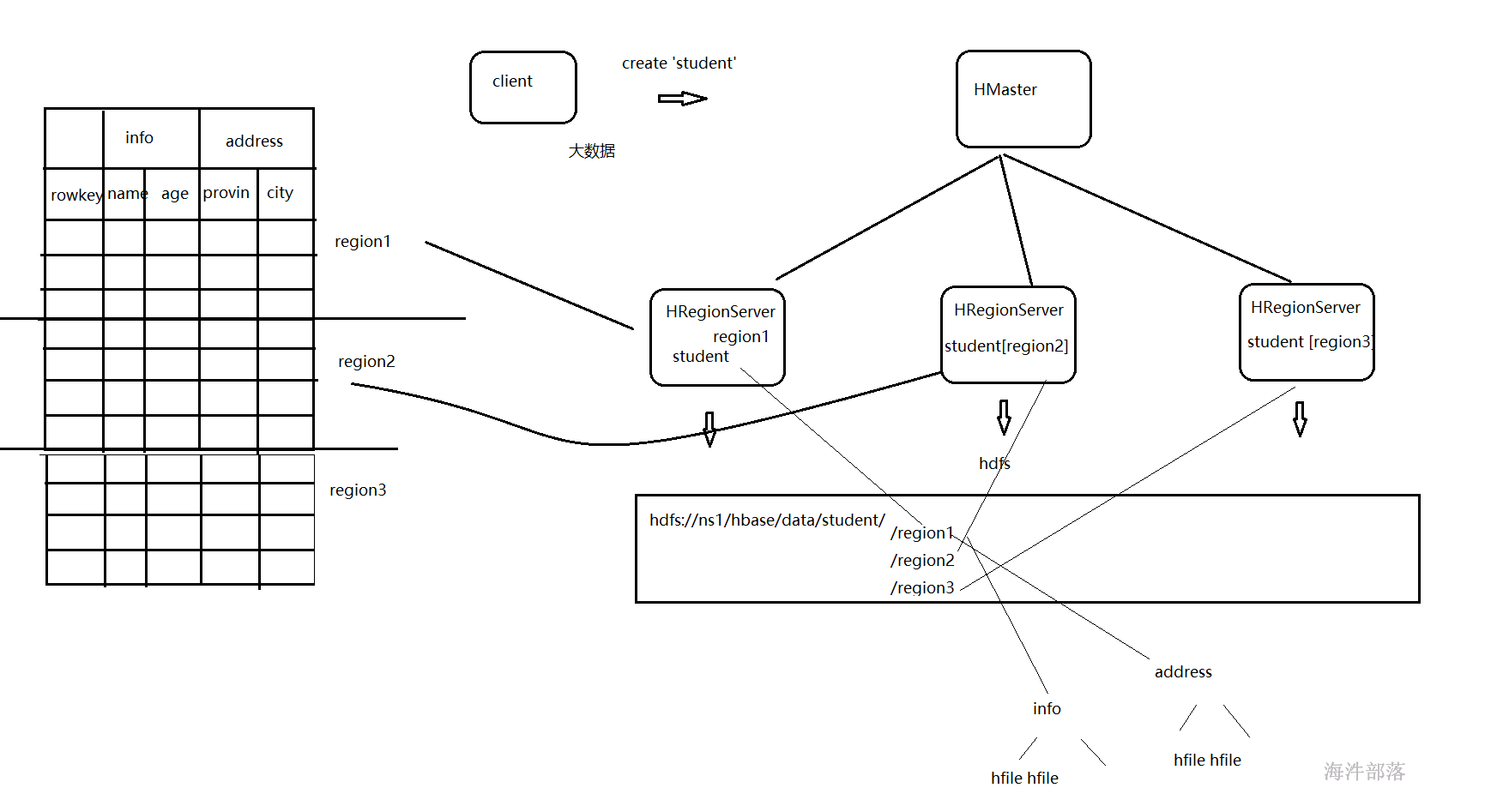
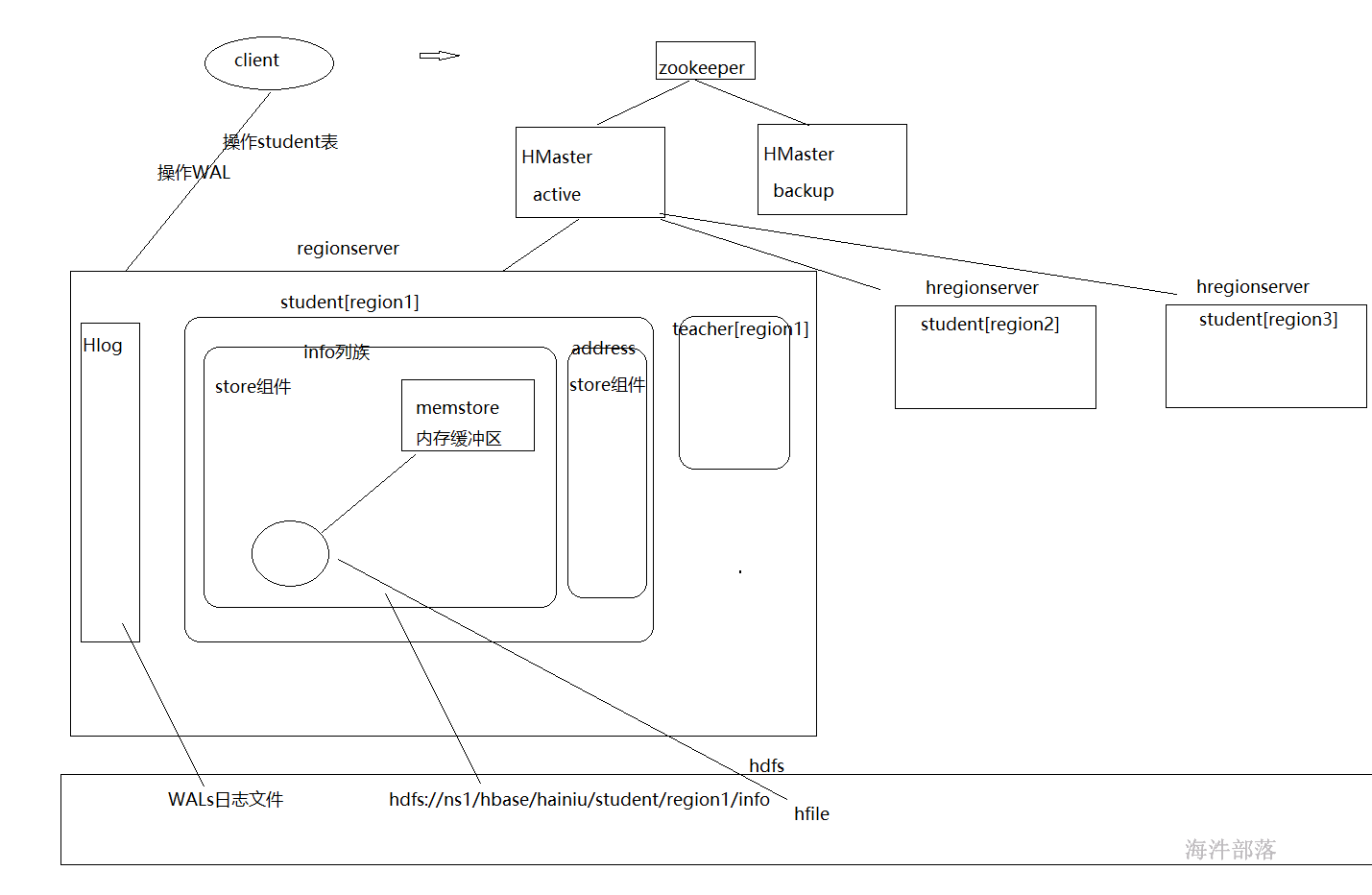
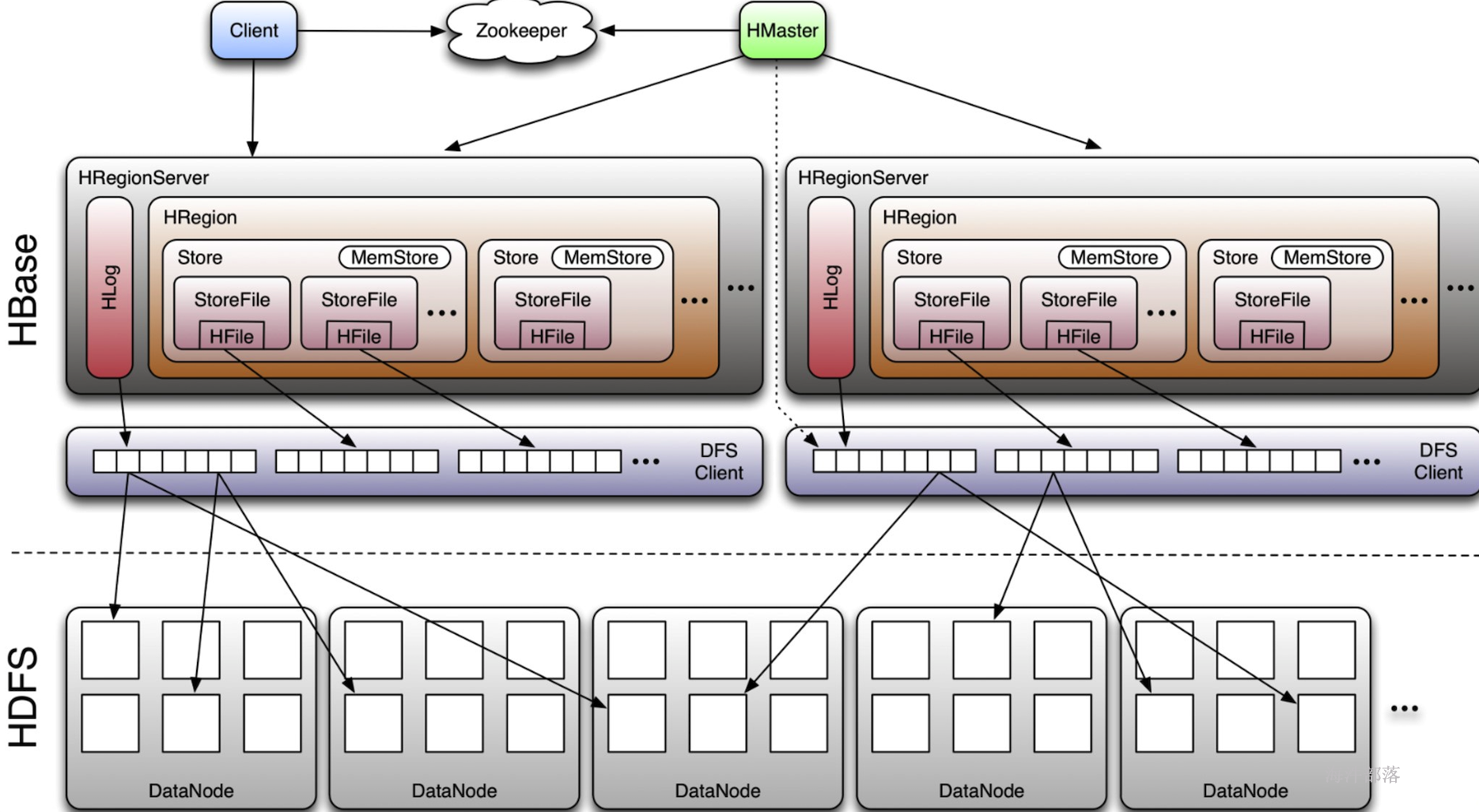
首先我们看到hbase的组成分为两个大的部分,分别是hmaster和hregionserver,主节点用于协调数据,regionserver用于真正的去管理表,其中regionserver存在多个,他们共同协调管理全有的表,负载均衡,共同分摊压力,其中一个表会由一个regionserver进行管理,这样压力都会集中在一个regionserver中,并且查询速度会比较慢,那么为了并行操作查询效率升高,一个表会分为多个部分分散在多个regionserver中进行管理,每个表会按照行进行拆分为多个region,一个region是一个表的横向切割的部分内容,所以一个表切割完毕以后会存在多个region部分,分别交给不同的regionserver进行管理,一个region会包含一个表所有的列信息,然后这些信息会按照列族进行存储,一个region中存在多少个列族就会有多少个Store,一个store中又会存在一个memstore进行缓存客户端对于这个列族的所有操作,这个memstore的缓存部分写满以后会以文件的形式写到本地磁盘中,这个文件叫做storeFile,最后这个storeFile会写出到hdfs中以HFile的形式进行存储
hbase的组件结构如下
HMaster
hmaster一般都是两台机器,使用zookeeper进行管理和协调
管理表操作,如:create、alter、drop;
管理HRegionServer的负载均衡,调整region分布;
region split后,负责新region重分布;
在HRegionServer停机后,负责失效的HRegionServer上region的迁移;
HRegionServer
真正干活的节点,一般会和datanode部署到一起
维护region,处理region的IO请求,如:put、get、scan、delete;
regionserver负责切分在运行过程中逐渐变大的region
Region
一个表会按照rowkey的范围进行行级别的分割,分割出来的一个部分就叫做region,它是表的一部分数据,可以分散到不同的regionserver中进行管理,是一个表的最小负载均衡的单位
每个region都会记录自己的startkey和endkey的范围
Store
每一个列族对应一个Store,一个Region里包含一个或者多个Store,>由此在设计cf时,尽量将同一系列的数据存在一个列族中,便于同一系列的数据都存在同一个region中。
Hlog
hbase WAL(write ahead log),在用户发起写请求时先向Hlog写一份,然后再将数据向memstore中写,Hlog数据是写磁盘,为了避免HRegionServer故障时memstore数据丢失,Hlog滚动更新,新数据会加入会对应冲抵掉较早的Hlog数据。
Memstore
hbase写缓存,在用户发起写请求时先写入hlog,然后再写入memstore中,当memstore写入达到flush阈值时,将memstore中的数据写到hdfs上(hfile),每个列族对应一个memstore,即一个HStore/Store中只有一个memstore。
storefile
当memstore写数据达到设定的阈值之后,会将数据溢写到hdfs,即storefile,内部存储hfile。storefile会进行合并,当storefile经过多次合并后变得已经达到指定规则的分裂阈值,则再进行region分裂。
8.hbase的写数据流程
在讲hbase的数据读写流程之前,我们先要进行普及一个事情就是zookeeper在hbase中的作用,zookeeper在整个hbase的集群中是一个协调者的身份存在的,能够协调多个hmaster实现主从的选举,维护整个集群的稳定性和高可靠性,除此之外zookeeper还用于记录hbase的元数据信息的情况
我们知道hbase的一个表为了多个机器并行进行管理和查询,将数据按照行进行拆分为多个region部分,多个region的数据会分散到不同的regionserver中进行管理,每个region会记录着所存储数据的startkey和endkey,那么我们在查询hbase的一条数据的时候就要知道去那个region中查询,并且知道这个region在什么位置,这个数据会被系统自动记录到hbase:meta的表中

这个表全部都是元数据信息,但是这个表也会存在很多region信息,我们应该去那个region中查询meta表的数据呢,这个时候meta表也需要自己的一个元数据表进行记录,这个表会放入到zookeeper中进行存储

在zookeeper中会存在meta-region-server的一个数据信息
我们看一下meta表的数据信息
# 进入hbase
hbase shell
# 查看表的数据
scan 'hbase:meta'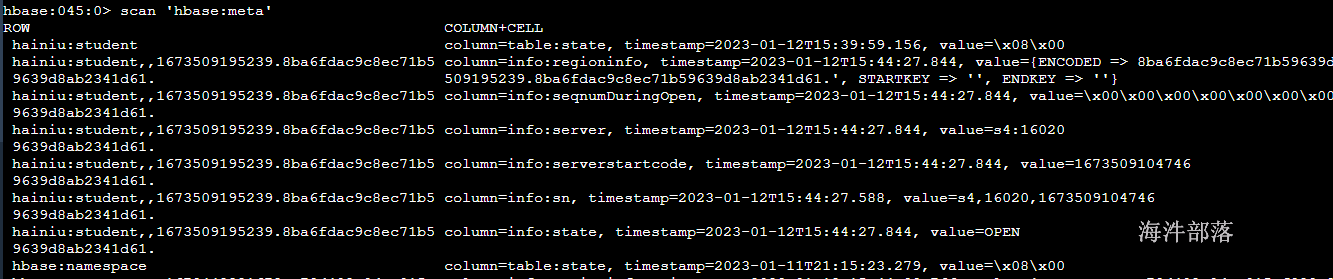
这个就是元数据的内容信息,其中内容如下:
hainiu:student,,1673509195239.8ba6fdac9c8ec71b5 column=info:state, timestamp=2023-01-12T15:44:27.844, value=OPEN meta表中的一个Rowkey就代表了一个region Rowkey主要由以下几部分组成:
TableName(业务表名)
StartRow(业务表Region区间的起始rowkey)
Timestamp(Region创建的时间戳)
EncodedName(上面3个字段的MD5 Hex值)4个字段拼接而成 也就是regionId
Rowkey:search_table,,1625037955174.f507364ab62a42cfe702c6b3dea8757c.
TableName: search_table为表名称。
StartRow: StartRow缺失
Timestamp: 1625037955174
EncodedName: 1625037955174.f507364ab62a42cfe702c6b3dea8757c.各个列的信息
info:regioninfo
value主要存储4个信息,即EncodedName、RegionName、Region的StartRow、Region的StopRow
{ENCODED => 8ba6fdac9c8ec71b59639d8ab2341d61, NAME => 'hainiu:student,,1673
9639d8ab2341d61. 509195239.8ba6fdac9c8ec71b59639d8ab2341d61.', STARTKEY => '', ENDKEY => ''} info:server
不同的region位于哪个regionserver上面
column=info:server, timestamp=2023-01-12T15:44:27.844, value=s4:16020 我们还需要知道一个文件WAL
同hdfs的edits日志文件一样,每个regionserver中都存在一个HLog文件,这个文件主要是hbase的操作日志文件,这个文件内的数据会记录的操作,防止集群损坏后恢复用的
文件在这个目录下 /hbase/WALs/
# 我们可以使用hbase的命令进行操作查看文件中的内容
hbase wal <hfile文件路径> -j 以json形式输出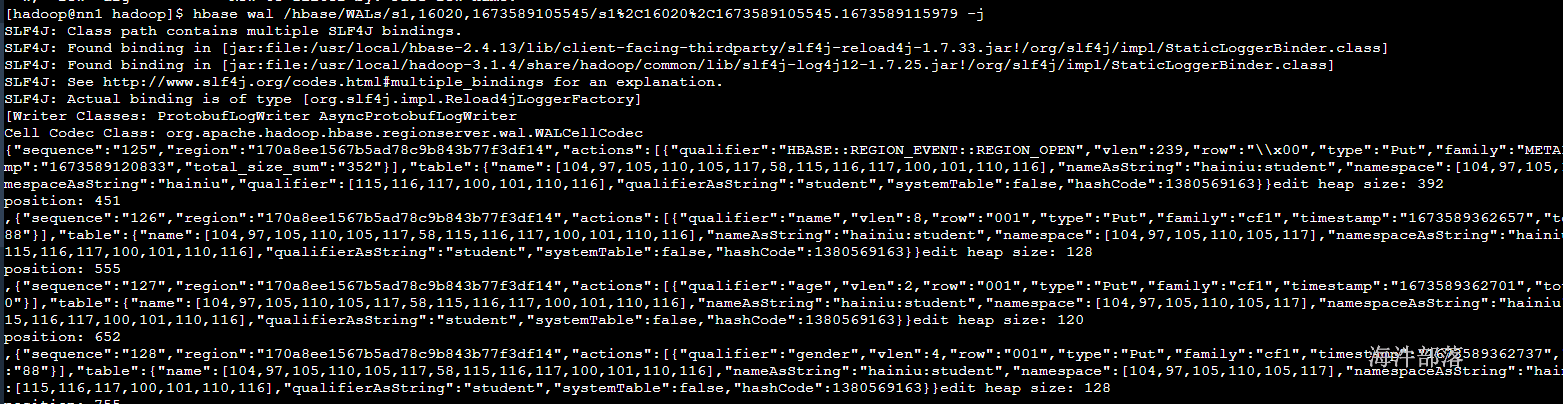
将文件放入到页面格式化可以直观查看内容

可以非常清晰的看到这个操作的所有记录,包括操作的数据库,命名空间,操作类型和操作序列信息
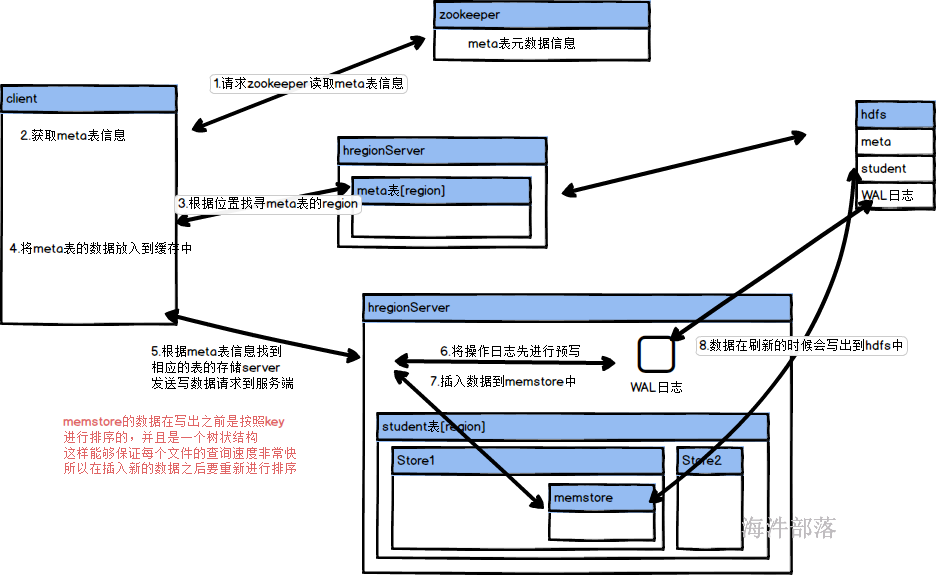
流程如下:
- 首先访问zookeeper获取meta表的信息
- 按照meta的信息去往相应的regionserver中查询对应的数据
- 返回数据后放入到自己的客户端缓存中进行保存,防止下次查询还需要继续检索
- 发送存储请求到regionserver
- 将发送请求的信息放入到WAL的预写日志中
- 然后将数据存储到memstore中进行缓存,并且按照key进行排序,保证数据是一个树状结构
- 然后返回客户端写完毕确认
- 一旦达成memstore的写出条件会写出内存中的数据到hdfs中
9.hbase插入数据
添加数据
# 创建连接
hbase shell
# 插入数据
put <table> <rowkey> <columnFamily:column> <value>
# 插入数据要按照rowkey指定不同的列进行插入
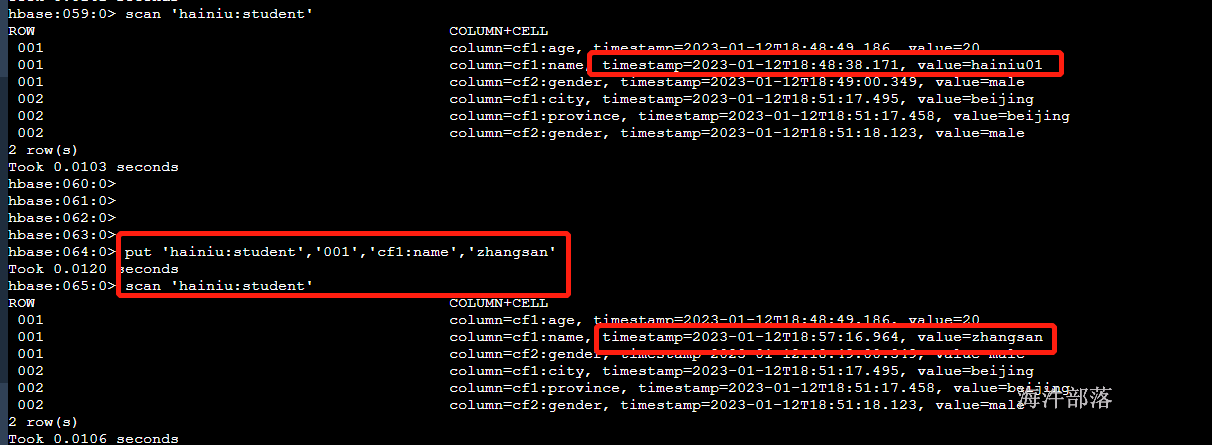
put 'hainiu:student','001','cf1:name','hainiu01'
put 'hainiu:student','001','cf1:age','20'
put 'hainiu:student','001','cf2:gender','male'
put 'hainiu:student','002','cf1:province','beijing'
put 'hainiu:student','002','cf1:city','beijing'
put 'hainiu:student','002','cf2:gender','male'
# 因为hbase是以列族为主的,那么存储的数据在不同的行是可以存在不同列的
# scan是扫描的方法,可以直接查看所有的表的数据
scan 'hainiu:student'
数据在插入的时候会显示当时插入的时间戳信息,并且在hbase中不存在修改操作,只有put,如果数据重复就会覆盖更新值
hbase 删除数据
插入数据在cf1列族中
# delete 删除一个值
delete <table><rowkey><columnFamily:column>
# delete all 删除一整行
deleteall <table><rowkey>
# truncate 可以直接清空表的全部数据
#直接删除表,并且重建表,速度特别快
truncate 'hainiu:student'

10.hbase的读数据流程
在解析读取流程之前我们还需要知道两个功能性的组件和HFIle的格式信息
HFILE
存储在hdfs中的hbase文件,这个文件中会存在hbase中的数据已kv类型显示,同时还会存在hbase的元数据信息,包括整个hfile文件的索引大小,描述,k和v的均匀长度,文件中包含的开始的key和结束的key,以及中位数key,等信息便于检索,以及布隆过滤器等信息,这个数据在我们hbase进行查询读取的时候按照64KB为一个大小进行读取内容数据,其中读取的元数据会全部加载,但是kv类型的真正存储数据会按照64KB为最小单位读取进来
# flush表的数据,清空memstore
flush <table>
# 查看命令为
hbase hfile -m -b -p -f <hfile的文件路径>
-m 打印元数据信息
-b 打印块信息
-p 打印数据内容
-f 后面接文件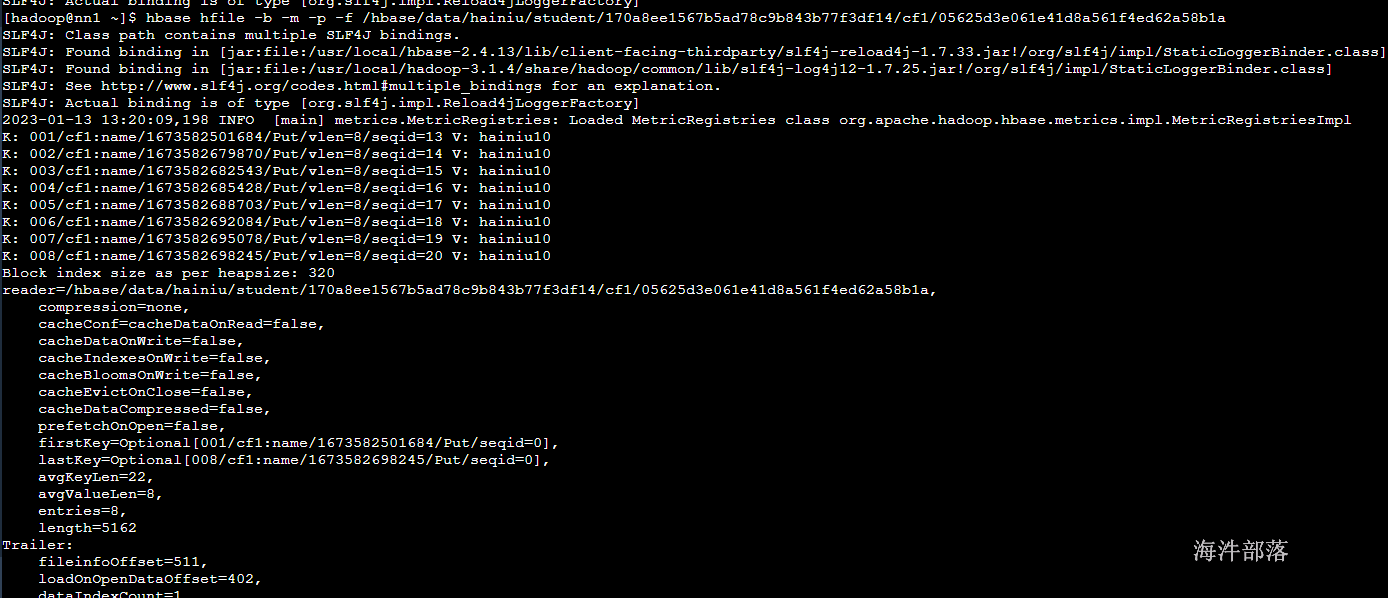
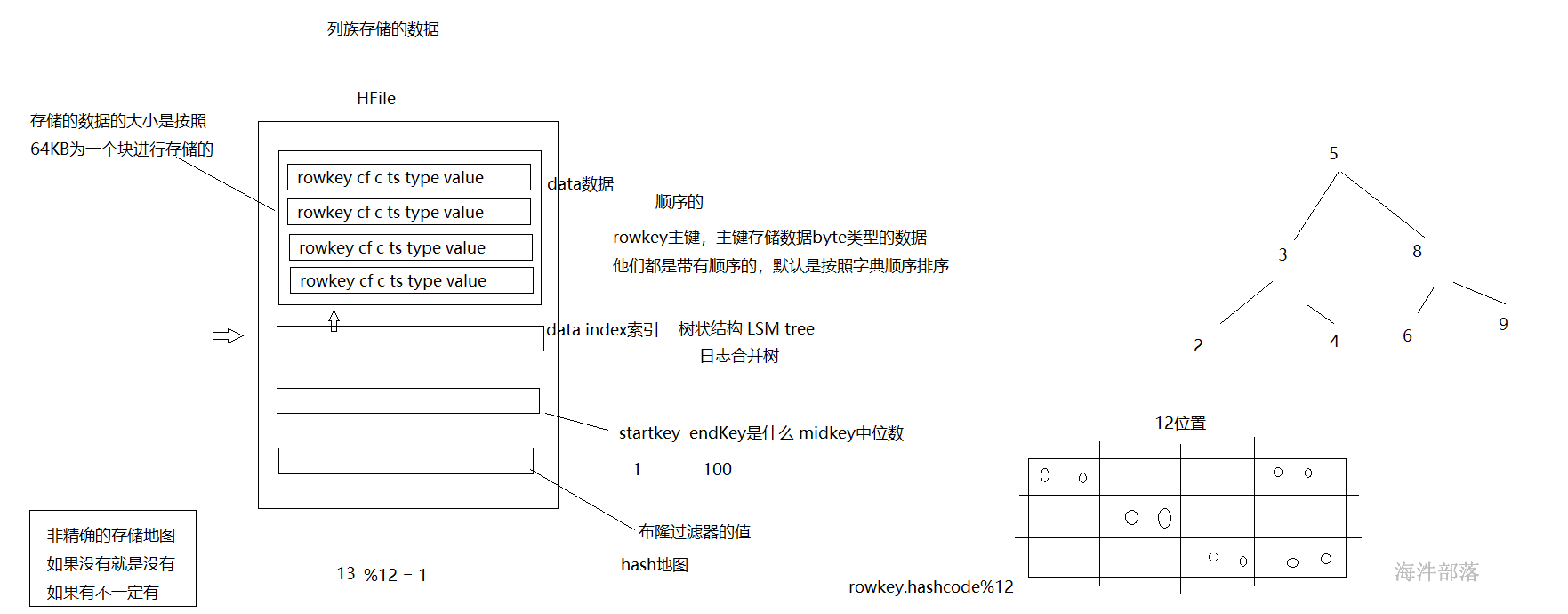
布隆过滤器:
一个使用hash表作为计算规则的过滤器,也就是在写入数据到hbase的时候要先将数据写出到memstore中,在memstore写满了以后就会将数据以storeFile形式写出到磁盘上,这个时候也会生成一份对应数据的hash表文件,以metablock的形式存储到起来,它的功能非常实用,比如我们在查询数据的时候就可以首先将这个数据进行hash处理,然后和hash表进行比对,如果不存在可以直接避免扫描这个storeFile文件。在巨大的数据面前可以进行高效的数据

blockCache
对应表数据的regionserver级别的缓存组件,主要使用规则就是在查询数据的时候也会将查询结果缓存到regionserver对应的blockCache组件中,下次查询的时候可以直接使用上次查询的结果,blockCache中存储的数据内存包含索引文件,布隆过滤器的值和数据的key,其他的value数据,会以64Kb为大小进行存储,如果数据过期了先清理value的数据,而索引等数据和元数据信息不会清理出去

所以hbase的读写数据流程为:
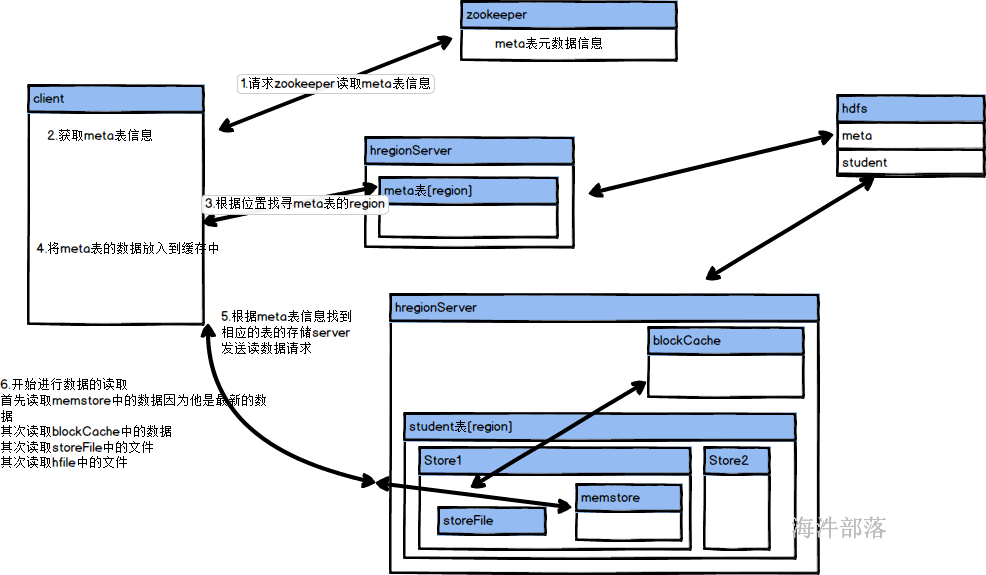
读取数据流程
- 首先读取zookeeper中的元数据meta表的信息
- 其次根据meta表的信息找寻相应的region获取元数据信息
- 然后将meta表的元数据信息放入到自己的客户端缓存中
- 根据meta表的信息找寻student表对应的region所在的regionserver
- 然后根据查询的内容先去memstore文件中找寻数据
- 如果没有再去blockcache缓存中找寻数据,但是并不是直接将数据返回,而是通过key和索引文件去storeFile中查询比对,不然会出现数据过期问题
- 都没有再从storeFile和hfile中找寻数据,这个过程会使用到布隆过滤器
- 然后在将数据存储到blockcache中然后在返回给客户端
11.hbase读取数据
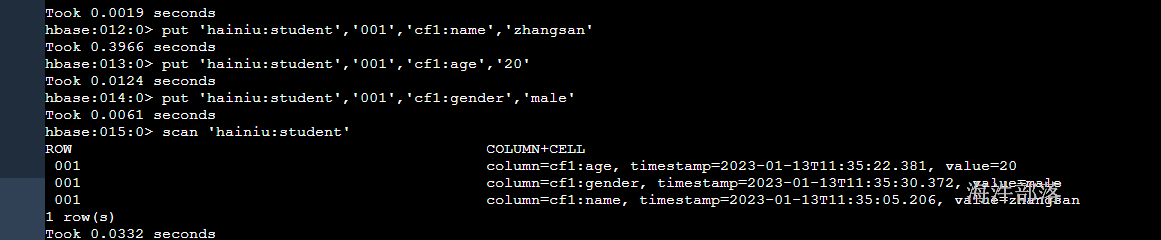
首先在hbase的hainiu:student表中增加多条数据
put 'hainiu:student','001','cf1:name','zhangsan'
put 'hainiu:student','001','cf1:age','20'
put 'hainiu:student','001','cf1:gender','male'
put 'hainiu:student','002','cf1:name','lisi'
put 'hainiu:student','002','cf1:age','30'
put 'hainiu:student','002','cf1:gender','female'
# get 获取一个内容按照rowkey查询数据
get 'hainiu:student','001'
# get 获取对应列族的数据
get 'hainiu:student','001','cf1'
# get 获取对应列的信息
get 'hainiu:student','001','cf1:name'
# scan扫描表的数据
scan table
# 扫描limit
scan 'hainiu:student', {LIMIT => 2}
# 扫描指定的列族
scan 'hainiu:student',{COLUMNS=>'cf1'}
# 扫描指定的列
scan 'hainiu:student',{COLUMNS=>'cf1:age'}


# 过滤器查询
scan 'hainiu:student', FILTER=>"ValueFilter(=,'binary:20')"
# 指定列等值查询
scan 'hainiu:student',{COLUMNS=>'cf1:age',FILTER=>"ValueFilter(!=,'binary:20')"}
# 范围查询
scan 'hainiu:student', { STARTROW => '001', STOPROW => '003'}
# 分页查询
scan 'hainiu:student', {COLUMNS => 'cf1', LIMIT => 2, STARTROW => '001'}
# 范围查询指定相应的列信息
scan 'hainiu:student', { STARTROW => '001', STOPROW => '002', COLUMN => 'cf1:name'}




行数查询
# 查询表的行数
# 语法:count <table>, {INTERVAL => intervalNum, CACHE => cacheNum}
# INTERVAL设置多少行显示一次及对应的rowkey,默认1000;
# CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度
count 'hainiu:student'
# 直接查询完毕返回值
count 'hainiu:student', {INTERVAL => 2,CACHE=>50}
# 间隔两秒返回一次结果值
大表统计
# 大表统计的时候不能使用hbase自带的count命令,这样hbase压力太大
# 我们可以通过外置的mr进行计算统计大小
hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'tablename' 

多版本查询
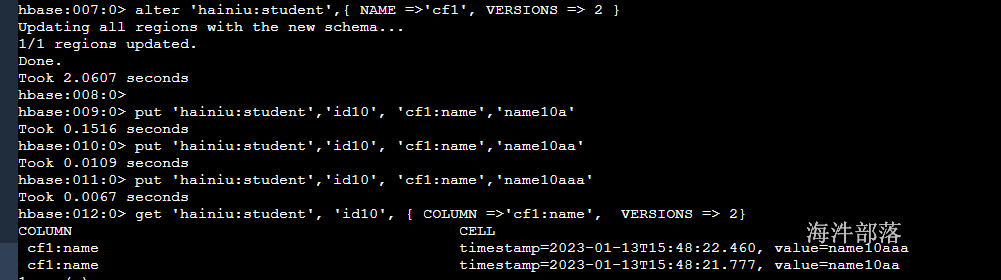
#修改设置版本,查询时,加上版本就可以查出来版本
alter 'hainiu:student',{ NAME =>'cf1', VERSIONS => 2 }
put 'hainiu:student','id10', 'cf1:name','name10a'
put 'hainiu:student','id10', 'cf1:name','name10aa'
put 'hainiu:student','id10', 'cf1:name','name10aaa'
#此时,可以查询出2个版本的数据
get 'hainiu:student', 'id10', { COLUMN =>'cf1:name', VERSIONS => 2}