hbase高级部分和API
12.hbase的高级部分
12.1 hbase性能保证
写入数据的性能:
首先我们使用memstore进行缓存,不会将数据直接放入到hdfs中,插入完毕数据可以直接返回成功,可以根据zookeeper直接定位到meta表,根据meta表可以直接找到数据所对应的regionserver,表的管理部分,每个表拆分为不同的region区域,每个区域会交给不同的regionserver进行管理,分布式管理均衡压力,并且每个列族都会有一个单独的组件store进行管理
首先存数据放入到memstore中,这个数据在内存中仅仅是追加形式的,不需要任何计算
读数据的性能:
与写出数据相比,寻址也是比较方便的,而且还可以在客户端选择性存储
memstore在写入数据到达阈值以后,将数据存储到hdfs中,这个文件叫做hfile,这个文件在存储的时候,需要做三件事情,按照rowkey进行排序,这样可以生成索引文件LSM Tree 【日志合并树】,生成相应的bloom过滤器的文件存储
读取数据的时候memstore>blockCache>Hfile,如果真的找到HFile还可以通过startkey endkey跳过HFIle,通过bloom过滤器实现跳过,如果真的存在就可以直接通过索引文件
blockCache regionserver级别的缓存,读取进来的时候会加载所有的HFile的元数据信息,以及查询到的block【64KB】数据,每次查询都可以直接从缓存中读取数据,免去多次查询,缓存会失效,每次查询并不是直接使用blockCache中的数据,拿到blockCache的元数据和Hfile中的数据进行比对,失效策略是LRU机制
12.2 memstore的刷写
1)hbase.hregion.memstore.flush.size
单个region内所有的memstore大小总和超过指定值时,flush该region的所有memstore。这里为什么是所有memsotre?因为一张表可能有多个CF,其对应的一个Region自然包含多个CF(即HStore),每个Store都有自己的memstore,这个配置值是所有的store的memstore的总和。当这个总和达到配置值时,即针对每个HSotre,都触发其Memstore,刷写成storefile(HFile的封装)文件。
hbase.hregion.memstore.block.multiplier默认值:2
说明:当一个region里总的memstore占用内存大小超过hbase.hregion.memstore.flush.size两倍的大小时,block该region的所有请求,进行flush,释放内存。虽然我们设置了region所占用的memstores总内存大小,比如64M,但想象一下,在最后63.9M的时候,我Put了一个200M的数据,此时memstore的大小会瞬间暴涨到超过预期的hbase.hregion.memstore.flush.size的几倍。这个参数的作用是当memstore的大小增至超过hbase.hregion.memstore.flush.size2倍时,block所有请求,遏制风险进一步扩大。
调优:这个参数的默认值还是比较靠谱的。如果你预估你的正常应用场景(不包括异常)不会出现突发写或写的量可控,那么保持默认值即可。如果正常情况下,你的写请求量就会经常暴长到正常的几倍,那么你应该调大这个倍数并调整其他参数值,比如hfile.block.cache.size和hbase.regionserver.global.memstore.upperLimit/lowerLimit,以预留更多内存,防止HBase server OOM。
2)当 HRegionServer 中 memstore 的总量达到
java堆内存 hbase.regionserver.global.memstore.size(默认0.4) hbase.regionserver.global.memstore.size.lower.limit(默认0.95),
RegionServer 会把所有memstore 按照由大到小的顺序依次进行刷写。直到 HRegionServer 中所有memstore的总大小减小到上述值以下。
当 HRegionServer 中 memstore 的总量达到 java堆内存 * hbase.regionserver.global.memstore.size(默认值0.4) (Memstore 所占最大堆空间比例)时,会阻塞往memstore的写操作。(regionserver级别的)
hbase.regionserver.global.memstore.lowerLimit
同upperLimit,只不过lowerLimit在所有region的memstores所占用内存达到Heap的35%时,不flush所有的memstore。它会找一个memstore内存占用最大的region,做个别flush,此时写更新还是会被block。lowerLimit算是一个在所有region强制flush导致性能降低前的补救措施。在日志中,表现为“** Flush thread woke up with memory above low water.”。
3)到达自动刷写的时间,也会触发memstore flush。自动刷新的时间间隔由该属性进行配置hbase.regionserver.optionalcacheflushinterval(默认1小时,-1 代表不自动刷写)。
4)全局性的触发刷写
当数据被写入时会默认先写入Write-ahead Log(WAL)。WAL中包含了所有已经写入Memstore但还未Flush到HFile的更改(edits)。在Memstore中数据还没有持久化,当RegionSever宕掉的时候,可以使用WAL恢复数据。
若是关闭WAL,则在hbase-site.xml新增hbase.regionserver.hlog.enabled配置,设为false即可,不建议关闭。
当WAL(在HBase中成为HLog)变得很大的时候,在恢复的时候就需要很长的时间。因此,对WAL的大小也有一些限制,当达到这些限制的时候,就会触发Memstore的flush。Memstore flush会使WAL减少,因为数据持久化之后(写入到HFile),就没有必要在WAL中再保存这些修改。有两个属性可以配置:
(1)hbase.regionserver.hlog.blocksize
(2)hbase.regionserver.maxlogs
WAL的最大值由hbase.regionserver.maxlogs*hbase.regionserver.hlog.blocksize (2GB by default)决定。一旦达到这个值,Memstore flush就会被触发。所以,当你增加Memstore的大小以及调整其他的Memstore的设置项时,你也需要去调整HLog的配置项。否则,WAL的大小限制可能会首先被触发,因而,你将利用不到其他专门为Memstore而设计的优化。抛开这些不说,通过WAL限制来触发Memstore的flush并非最佳方式,这样做可能会会一次flush很多Region,尽管“写数据”是很好的分布于整个集群,进而很有可能会引发flush“大风暴”。
12.3 storeFile的合并
Compaction 操作分成下面两种:
-
Minor Compaction:是选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,对于删除、过期、多余版本的数据不进行清除。
- Major Compaction:是指将所有的StoreFile合并成一个StoreFile,对于删除、过期、多余版本的数据进行清除。优先采用Minor Compaction,如果达不到要求,再执行Major Compaction 。
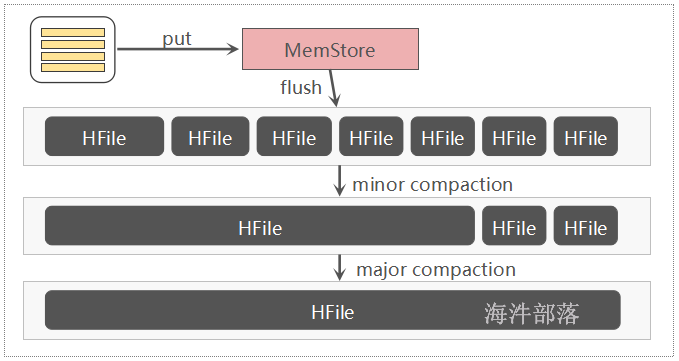
注:Compaction的触发时机Major Compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此线上业务都会将关闭自动触发Major Compaction功能,改为手动在业务低峰期触发。
HBase中可以触发compaction的因素有很多,最常见的因素有这么三种:Memstore Flush、后台线程周期性检查、手动触发。
1)Memstore Flush:
每当 RegionServer发生一次Memstore flush操作之后也会进行检查是否需要进行Compaction操作。
2)周期性检查:
通过CompactionChecker线程来定时检查是否需要执行compaction(RegionServer启动时在initializeThreads()中初始化),每隔10000毫秒(可配置)检查一次。
一般系统触发都是minorCompact
合并主要有以下几个参数进行配置
hbase.store.compaction.ratio默认值1.2f,大于最小值但是小于1.2倍数的大小的数据也参加合并
hbase.hstore.compaction.min 默认值2,每次合并最少两个hfile
hbase.hstore.compaction.max 默认值10,每次合并最多10个hfile
hbase.hstore.compaction.min.size 小于这个值的file肯定会参加合并
hbase.hregion.memstore.flush.size (128 mb).
hbase.hstore.compaction.max.size 大于这个值的肯定不会参加合并3)手动触发:
手动触发compection通常是为了执行major compaction,执行命令"major_compact '表名'",原因如下:
自动major compaction影响读写性能,因此会选择低峰期手动触发;
执行完alter操作之后希望立刻生效,执行手动触发major compaction;
# 创建表
create 'hainiu:student1','cf1'
put 'hainiu:student1','id01','cf1:name', 'n1'
flush 'hainiu:student1'
scan 'hainiu:student1' # 拿到n1 的时间戳
put 'hainiu:student1','id01','cf1:name', 'n2'
flush 'hainiu:student1'
scan 'hainiu:student1' # 拿到n2 的时间戳
# 用 n1的时间戳指定查询,是能查询到的
get 'hainiu:student1', 'id01', {COLUMN => 'cf1:name', TIMESTAMP => 1673596645265}
# 执行major合并, 由于n1是历史版本,所以n1被合并没了, 只留下n2(最新版本数据)
major_compact 'hainiu:student1'
# 用 n1的时间戳指定查询,查询不到了(n1被合并没了)
get 'hainiu:student1', 'id01', {COLUMN => 'cf1:name', TIMESTAMP => 1673596645265} 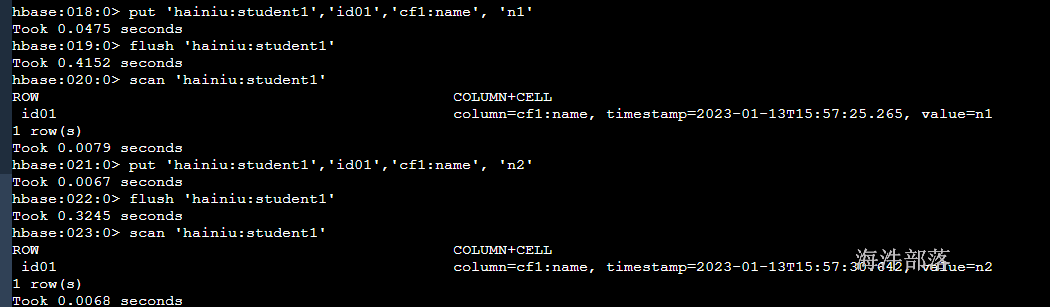


12.4 region split机制
HRegionServer拆分region的步骤是,先将该region下线,然后拆分,将其子region加入到hbase:meta表中,再将他们加入到原本的HRegionServer中,最后汇报Master。
split前:hbase:meta表有: region_p
-
在region_p对应的hdfs目录下生成.splits目录,用于保存分割后的region信息,如:tablename/region_p/.splits
-
关闭region_p,数据写入并触发flush操作,将写入region的数据全部持久化到磁盘。
- 在region_p对应的.splits目录下,创建两个子目录,并在里面创建两个子region的引用文件。
| .split引用文件目录 |
|---|
| tablename/region_p/.splits/region1/region1引用文件 (splitkey, true) |
| tablename/region_p/.splits/region2/region2引用文件 (splitkey, false) |
引用文件用于记录从哪分割(splitkey)和是上半部分(true)还是下半部分(false)
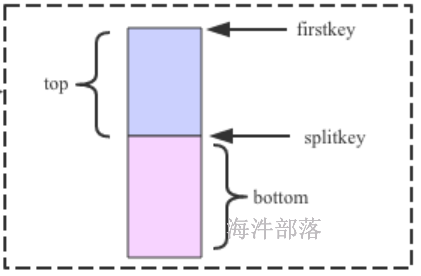
- region_p 分裂为两个子region后,将.split目录下的region1、region2 的目录 copy 到region_p的同级目录下,形成两个新的region。
| tablename目录结构 |
|---|
| tablename/region_p/.splits |
| tablename/region1/cf/region1引用文件(splitkey, true) |
| tablename/region2/cf/region2引用文件(splitkey, false) |
- 把region_p在hbase:meta表标记下线和split,把两个子region添加到hbase:mate表。
| regionname | location | split | offline | split |
|---|---|---|---|---|
| region_p | /xxxx/xxxx/xxxx/ | true | true | region1,region2 |
| region1 | /xxxx/xxxx/xxxx/ | false | false | |
| region2 | /xxxx/xxxx/xxxx/ | false | false |
-
开启两个子region,可以接收请求了。此时还没有拉取region_p split的数据。
-
当region发生major compact时,会把父region的split数据拉取到子region,并和当前的子region进行合并,子region拉取完数据后,把引用文件删除。
- hbase会启动线程检查父region是否达到删除的条件,如果达到就删除父region。
删除条件:父region的元数据是split状态and所有子region下的引用文件已删除。
12.5 region split策略
可以通过设置RegionSplitPolicy的实现类来指定拆分策略,RegionSplitPolicy类的实现类有:
ConstantSizeRegionSplitPolicy
IncreasingToUpperBoundRegionSplitPolicy
DelimitedKeyPrefixRegionSplitPolicy
KeyPrefixRegionSplitPolicy
DisabledRegionSplitPolicy // 不拆分其中:
ConstantSizeRegionSplitPolicy:(一刀切)【0.94前】
当一个region中最大store大小大于设置阈值(hbase.hregion.max.filesize 默认10G)就会触发切分,每10s检查一次region大小,hbase.server.thread.wakefrequency=10000。
弊端: 设置阈值大些,对大表友好,但对小表并不友好,可能小表不会分裂;
如果阈值小些,对小表友好,但对大表并不友好,可能会大量分裂;
IncreasingToUpperBoundRegionSplitPolicy【0.94-2.0】:
默认使用的拆分策略,Region的前几次拆分的阈值不是固定的数值,是需要进行计算得到,当同一table在同一regionserver上的region数量在[0,100)之间时按照如下的计算公式算,否则按照ConstantSizeRegionSplitPolicy策略计算:
Min (R^3 "hbase.hregion.memstore.flush.size"2, "hbase.hregion.max.filesize")
-
R为同一个table中在同一个regionserver中region的个数
-
hbase.hregion.memstore.flush.size默认为128M
- hbase.hregion.max.filesize默认为10G
第一次分裂: 1*1*1*128*2=256M
第二次分裂:8*128*2 = 2G
第三次分裂: 27*128*2 = 6.75G
SteppingSplitPolicy【2.x版本】:
这种策略和IncreasingToUpperBoundRegionSplitPolicy策略很相似,但更简单,第一个Region容量的上限为256M,之后都是10G,这个策略考虑到IncreasingToUpperBoundRegionSplitPolicy会多拆分几个Region(256M -> 2G -> 6.75G -> 10G),所以进行了简化。
查看webui :

12.6 rowkey设计
RowKey可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,字典顺序排序,rowkey的设计至关重要,会影响region分布,如果rowkey设计不合理还会出现region写热点等一系列问题。
rowkey设计原则:
-
保证rowkey的唯一性:性质与主键唯一一致。
-
能满足需求的情况下,长度越短越好:推荐16字节。
- 高位散列:高位散列的目的是使数据均匀分布到不同的region上,散列方式一般采用"反转"、"加盐"、"MD5"的方式对高位进行处理。(防止写热点问题)
需求:hbase存储的是用户的交易信息, 我想查某个用户在某个时间段内的交易记录,如何设计rowkey
用户id(md5), 用户名称, 交易时间, 交易金额, 交易说明
用户id(md5), 交易时间
rowkey设计: 用户id(md5) + _ + 交易时间
create 'hainiu:flow', 'cf'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210110000', 'cf:name', 'user1'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210110000', 'cf:amt', '1000'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210110000', 'cf:time', '2021-12-10 11:00:00'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210120000', 'cf:name', 'user1'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210120000', 'cf:amt', '2000'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210120000', 'cf:time', '2021-12-10 12:00:00'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210130000', 'cf:name', 'user1'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210130000', 'cf:amt', '3000'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210130000', 'cf:time', '2021-12-10 13:00:00'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210140000', 'cf:name', 'user1'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210140000', 'cf:amt', '4000'
put 'hainiu:flow', '02f5adff232b37422fc846cc5c1d8328_20211210140000', 'cf:time', '2021-12-10 14:00:00'
# 查询 某个人在 20211210 日 11 点 到 20211211 日 12:30 间的交易记录
scan 'hainiu:flow', {STARTROW => '02f5adff232b37422fc846cc5c1d8328_2021121011' , STOPROW=> '02f5adff232b37422fc846cc5c1d8328_202112101230'}

我们可以发现数据已经可以按照范围查询了
重点:
有的时候我们的单点查询比较频繁,那么我们将数据按照散列形式打散然后穿插到不同的region中可以有效的防止读和写热点问题
有时候我们查询的数据是范围性的扫描,这样时候我们就要知道数据必须要有相似的前缀,这样非常好按照范围查询,防止多region扫描问题的产生,比如人口普查数据,我们最好按照省份开头一样,这样的数据范围性比较好查询
但是这个时候会出现数据倾斜或者热点问题,所以我们在这个基础上还可以实现预分区的设计,在设定表的时候指定分区的数据范围,保证数据的分布均匀12.7 Hbase预分区
为了解决数据的倾斜问题,或者数据在刚开始插入的数据都在一个region中,使得一个region中的压力太大,我们可以预先设定一个表数据的分区范围,让数据更加均匀的分布在不同的分区中,或者我们在做数据分类的时候可以按照不同的类别将数据放入到不同的region中扫面数据的时候会比较容易,防止跨多个分区进行操作查询
预分region需要考虑两个因素,即region个数与region大小。
- region个数
官方推荐region个数计算公式:
(RS Xmx * hbase.regionserver.global.memstore.size) / (hbase.hregion.memstore.flush.size * column familys)其中:
RS Xmx:regionserver堆栈内存大小,官方推荐每台regionserver内存大小设置20-24G,不推荐设置更大,因为更大的堆栈内存GC效率较低。
hbase.regionserver.global.memstore.size:为整个regionserver中memstore总大小占用总内存的比例,一般默认为0.4
hbase.hregion.memstore.flush.size:为memstoreflush阈值,一般默认128,可以自己设置
column familys:为列族数
例:(20G*0.4)/(128M*2)=32
官方推荐每个regionserver上region个数在20-200之间。
- region大小
单个region官方推荐大小为5-10GB,可以通过hbase.hregion.max.filesize设置,当超过该值后会触发split,与region split策略相关。
# 首先我们需要创建预分区文件
# 比如我们做人口普查,需要将不同省份的数据放入到不同的region中
河北省,山西省,吉林省,辽宁省,黑龙江省,陕西省,甘肃省,青海省,山东省,福建省,浙江省,台湾省,河南省,湖北省,湖南省,江西省,江苏省,安徽省,广东省,海南省,四川省,贵州省,云南省
#首先我们按照这些省份的字典顺序将字母排序
云南省
台湾省
吉林省
四川省
安徽省
山东省
山西省
广东省
江苏省
江西省
河北省
河南省
浙江省
海南省
湖北省
湖南省
甘肃省
福建省
贵州省
辽宁省
陕西省
青海省
黑龙江省
# 然后将这些数据放入到一个文件中 /home/hadoop/split.txt
create 'hainiu:advance_split_region', 'cf', {SPLITS_FILE => '/home/hadoop/split.txt'}
查看监控页面


可以查看到所有的分区数据
12.8 hbase的压缩
建表时指定压缩格式,开启压缩后可以非常有效的缓解hbase数据膨胀问题。
create 'hainiu:flow',{NAME => 'cf',VERSIONS => 3,COMPRESSION => 'SNAPPY'}, {SPLITS_FILE => '/tmp/advance_split_region_file'}如果建表没指定压缩格式,那需要修改列族支持,步骤如下:
1) disable 'hainiu:flow'
如果表的数据量很大,region很多,disable过程会比较缓慢,需要等待较长时间。过程可以通过查看hbase master log日志监控。
2) alter 'hainiu:flow', NAME => 'cf', COMPRESSION => 'snappy'
NAME即column family,列族。HBase修改压缩格式,需要一个列族一个列族的修改。名字一定要与你自己列族的名字一致,否则就会创建一个新的列族并且压缩格式是snappy的。
3)enable 'hainiu:flow'
重新enable表
4)major_compact 'hainiu:flow'
enable表后,HBase表的压缩格式并没有生效,还需要执行一个命令,major_compact
Major compact除了做文件Merge操作,还会将其中的delete项删除。



13.hbase API
首先引入hbase的依赖
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.4.13</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>将hbase-site.xml放入到resouces文件夹中
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<!--
The following properties are set for running HBase as a single process on a
developer workstation. With this configuration, HBase is running in
"stand-alone" mode and without a distributed file system. In this mode, and
without further configuration, HBase and ZooKeeper data are stored on the
local filesystem, in a path under the value configured for `hbase.tmp.dir`.
This value is overridden from its default value of `/tmp` because many
systems clean `/tmp` on a regular basis. Instead, it points to a path within
this HBase installation directory.
Running against the `LocalFileSystem`, as opposed to a distributed
filesystem, runs the risk of data integrity issues and data loss. Normally
HBase will refuse to run in such an environment. Setting
`hbase.unsafe.stream.capability.enforce` to `false` overrides this behavior,
permitting operation. This configuration is for the developer workstation
only and __should not be used in production!__
See also https://hbase.apache.org/book.html#standalone_dist
-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns1/hbase</value>
</property>
<!-- hbase在hdfs中的存储位置 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 开启hbase的全分布式 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<!-- zookeeper的端口号 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>nn1,nn2,s1</value>
</property>
<!-- zookeeper集群的主机名 -->
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<!-- hbase的临时文件存储路径 -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- 开启配置防止hmaster启动问题 -->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<!-- 监控页面端口 -->
</configuration>
整体代码如下:
package com.hainiu.hbase;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.ColumnValueFilter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class TestHbase {
public static Connection connection;
static{
try {
connection = ConnectionFactory.createConnection();
//创建链接
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void TestCreateNameSpace() throws IOException {
Admin admin = connection.getAdmin();
//获取管理员对象
NamespaceDescriptor desc = NamespaceDescriptor.create("test").build();
//创建命名空间描述
admin.createNamespace(desc);
}
public static void TestSearchNameSpace()throws Exception{
Admin admin = connection.getAdmin();
//获取管理员对象
String[] spaces = admin.listNamespaces();
for (String space : spaces) {
System.out.println(space);
}
}
public static void TestCreateTable()throws Exception{
Admin admin = connection.getAdmin();
TableDescriptorBuilder build = TableDescriptorBuilder.newBuilder(TableName.valueOf("test:student"));
//创建表描述对象
ColumnFamilyDescriptor info = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info")).build();
//创建列描述对象
TableDescriptor desc = build.setColumnFamily(info).build();
//将列和表融合
admin.createTable(desc);
}
public static void TestListTable() throws Exception{
Admin admin = connection.getAdmin();
List<TableDescriptor> tableDescriptors = admin.listTableDescriptors();
//创建表查询对象
for (TableDescriptor tableDescriptor : tableDescriptors) {
TableName name = tableDescriptor.getTableName();
System.out.println(name);
}
}
public static void TestDeleteTable()throws Exception{
Admin admin = connection.getAdmin();
admin.disableTable(TableName.valueOf("test:student"));
admin.deleteTable(TableName.valueOf("test:student"));
}
public static void TestInsertData() throws Exception{
Table table = connection.getTable(TableName.valueOf("test:student"));
Put put = new Put(Bytes.toBytes("001"));
//创建插入对象
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes("zhangsan"));
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes("20"));
//增加列值
table.put(put);
}
public static void TestInsertDataBatch() throws Exception{
Table table = connection.getTable(TableName.valueOf("test:student"));
List<Put> list = new ArrayList<Put>();
for(int i=0;i<100;i++){
Put put = new Put(Bytes.toBytes(i));
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes("zhangsan"+i));
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes(i));
list.add(put);
}
table.put(list);
}
public static void TestGetData()throws Exception{
Table table = connection.getTable(TableName.valueOf("test:student"));
Get get = new Get(Bytes.toBytes(1));
Result result = table.get(get);
//获取一行内容数据
byte[] name = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name"));
byte[] age = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age"));
//列和列族的数据必须是字节数组
String name_str = Bytes.toString(name);
int age_int = Bytes.toInt(age);
//查询完毕的数据要转换为string或者int的原类型
System.out.println(name_str+","+age_int);
}
public static void TestScan()throws Exception{
Table table = connection.getTable(TableName.valueOf("test:student"));
Scan scan = new Scan();
ResultScanner res = table.getScanner(scan);
//创建扫面对象
for(Result r:res){
byte[] name = r.getValue(Bytes.toBytes("info"), Bytes.toBytes("name"));
byte[] age = r.getValue(Bytes.toBytes("info"), Bytes.toBytes("age"));
String name_str = Bytes.toString(name);
int age_int = Bytes.toInt(age);
System.out.println(name_str+","+age_int);
}
}
public static void TestScanLimit()throws Exception{
Table table = connection.getTable(TableName.valueOf("test:student"));
Scan scan = new Scan();
scan.withStartRow(Bytes.toBytes(10));
scan.withStopRow(Bytes.toBytes(30));
//增加rowkey的扫描范围
ResultScanner res = table.getScanner(scan);
for(Result r:res){
byte[] name = r.getValue(Bytes.toBytes("info"), Bytes.toBytes("name"));
byte[] age = r.getValue(Bytes.toBytes("info"), Bytes.toBytes("age"));
String name_str = Bytes.toString(name);
int age_int = Bytes.toInt(age);
System.out.println(name_str+","+age_int);
}
}
public static void TestScanWithFilter()throws Exception{
Table table = connection.getTable(TableName.valueOf("test:student"));
Scan scan = new Scan();
// ColumnValueFilter filter = new ColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("age"), CompareOperator.EQUAL, Bytes.toBytes(30));
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("age"),
//增加过滤器,ColumnValueFilter只能显示出一列,SingleColumnValueFilter能够显示出来所有的列
CompareOperator.EQUAL, Bytes.toBytes(20));
scan.setFilter(filter);
ResultScanner res = table.getScanner(scan);
for(Result r:res){
byte[] name = r.getValue(Bytes.toBytes("info"), Bytes.toBytes("name"));
byte[] age = r.getValue(Bytes.toBytes("info"), Bytes.toBytes("age"));
String name_str = Bytes.toString(name);
int age_int = Bytes.toInt(age);
System.out.println(name_str+","+age_int);
}
}
public static void deleteData() throws Exception{
Table table = connection.getTable(TableName.valueOf("test:student"));
Delete delete = new Delete(Bytes.toBytes(20));
table.delete(delete);
}
public static void main(String[] args) throws Exception{
// TestCreateNameSpace();
// TestSearchNameSpace();
// TestCreateTable();
// TestListTable();
// TestDeleteTable();
// TestInsertData();
// TestInsertDataBatch();
// TestGetData();
// TestScan();
// TestScanLimit();
// TestScanWithFilter();
// deleteData();
connection.close();
}
}14. hbase的参数优化
Zookeeper 会话超时时间
属性:zookeeper.session.timeout
解释:默认值为 90000 毫秒(90s)
hbase.client.pause(默认值 100ms)重试间隔
hbase.client.retries.number(默认 15 次)重试次数
设定线程数量
hbase.regionserver.handler.count
默认值30,可以增加处理请求的线程数量
优化客户端缓存
hbase.client.write.buffer
增加缓存大小可以多缓存元数据信息,并且减少查询数据通信次数
提交读取缓存大小
hfile.block.cache.size
默认 0.2,调节大小可以增加缓存数据,blockCache大小
设定内存大小
export HBASE_HEAPSIZE=1G
设定hbase的内存大小
设定hbase的列族
一般多种数据会设定多个列族,减少冗余数据的查询,但是也不要设定太多列族,一般2两个列族就可以了

