kafka之consumer
1.kafka的数据存储结构
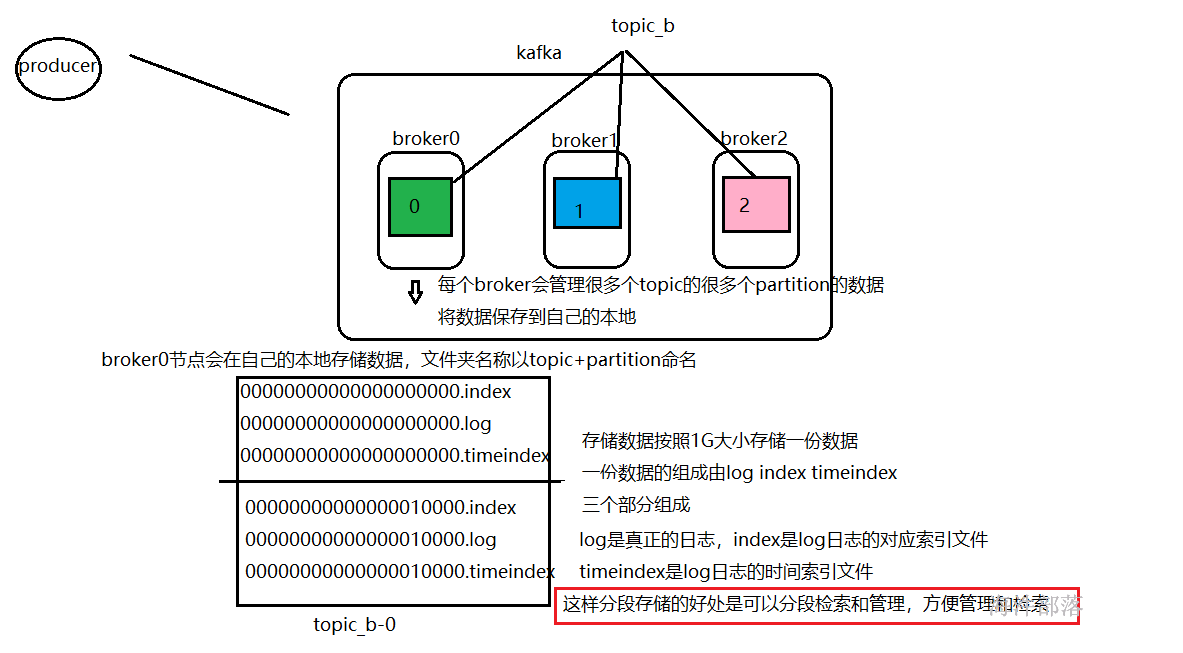
以上是kafka的数据的存储方式
这些数据可以在服务器集群上对应的文件夹中查看到

每个文件夹以topic+partition进行命名,更加便于管理和查询检索,因为kafka的数据都是按照条进行处理和流动的一般都是给流式应用做数据供给和缓冲,所以检索速度必须要快,分块管理是最好的方式
消费者在检索相应数据的时候会非常的简单
consumer检索数据的过程
首先文件的存储是分段的,那么文件的名称代表的就是这个文件中存储的数据范围和条数
00000000000000000000.index
00000000000000000000.log
00000000000000000000.timeindex
代表存储的数据是从0条开始的00000000000000100000.index
00000000000000100000.log
00000000000000100000.timeindex
代表存储的数据是从100000条开始的
所以首先检索数据的时候就可以跳过1G为大小的块,比如检索888这条数据的,就可以直接去00000000000000000000.log中查询数据
那么查询数据还是需要在1G大小的内容中找寻是比较麻烦的,这个时候可以从index索引出发去检索,首先我们可以通过kafka提供的工具类去查看log和index中的内容
# 首先创建一个topic_b
kafka-topics.sh --bootstrap-server nn1:9092 --create --topic topic_b --partitions 5 --replication-factor 2
# 然后通过代码随机向不同的分区中分发不同的数据1W条package com.hainiu.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class ProducerWithMultiConfig {
public static void main(String[] args) throws InterruptedException {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
pro.put(ProducerConfig.LINGER_MS_CONFIG, 100);
pro.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 1024*1024*64);
pro.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
pro.put(ProducerConfig.RETRIES_CONFIG, 3);
pro.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
pro.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 5);
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);
for (int i = 0; i < 10000; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>("topic_b", ""+i,"this is hainiu");
producer.send(record);
}
producer.close();
}
}
然后去查看log和index中的内容
# kafka查看日志和索引的命令
kafka-run-class.sh kafka.tools.DumpLogSegments --files xxx

整理一下我们看到的内容
index索引
| offset 第几条 | position 物理偏移量位置,也就是第几个字 |
|---|---|
| 1187 | 5275 |
| 1767 | 10140 |
| 2022 | 15097 |
log日志
# 打印日志内容的命令 --print-data-log 打印数据
kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log --print-data-log
可以看到刷写的日志
baseOffset: 1768 lastOffset: 2022 count: 255
从1768到2022条一次性刷写255条
lastSequence: 2022 producerId: 1007 position: 15097
刷写事物日志编号,生产者的编号,最后一条数据的物理偏移量
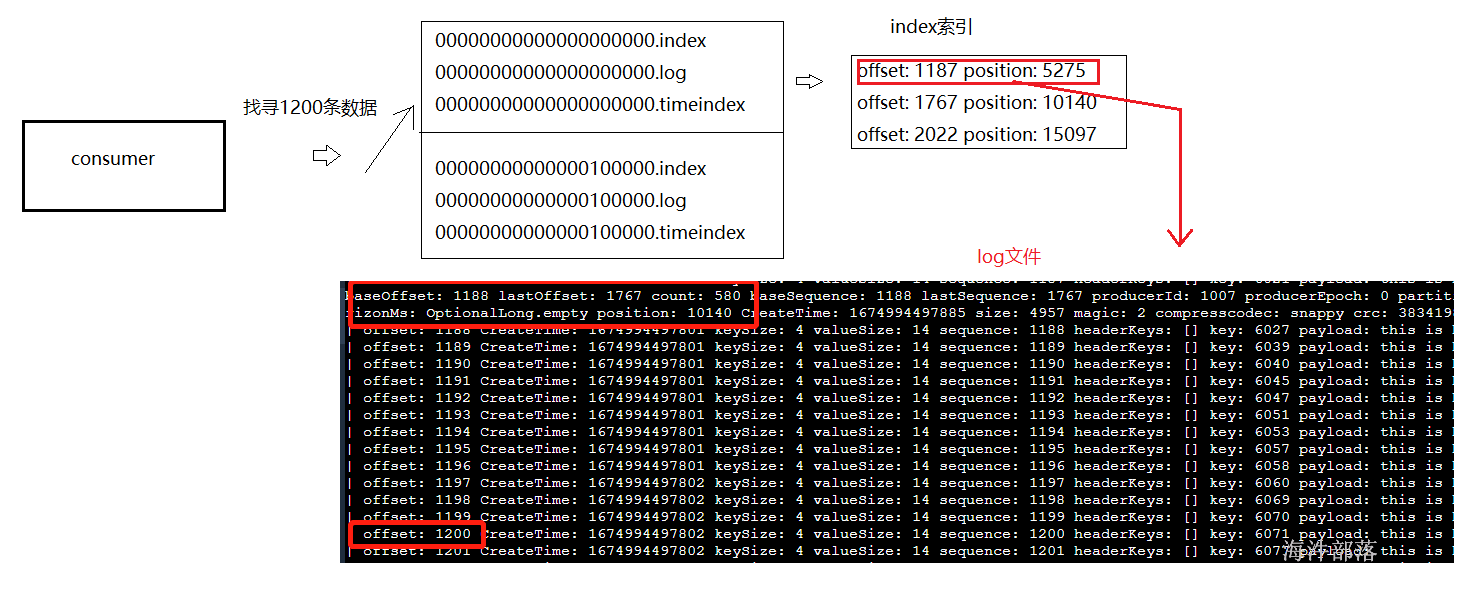
通过名称跳过1G的端,然后找到相应的index的偏移量,然后根据偏移量定位log位置,不断向下找寻数据
大家可以看到index中的索引数据是轻量稀疏的,这个数据是按照4KB为大小生成的,一旦刷写4KB大小的数据就会写出相应的文件索引
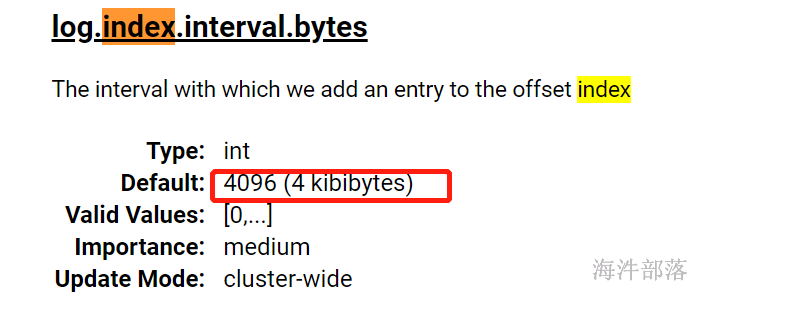
官网给出的默认值4KB
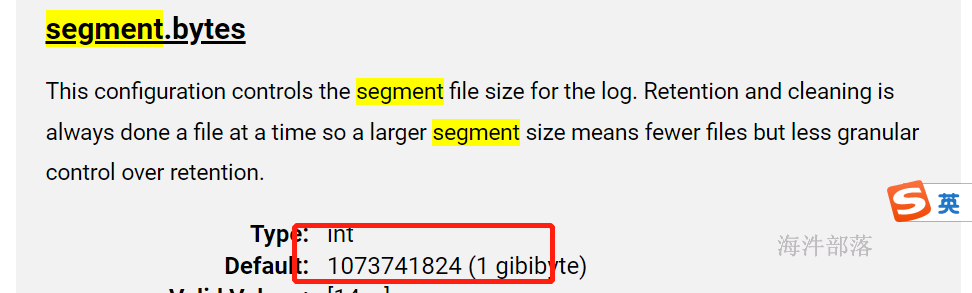
一个数据段大小是1G
timeIndex
我们看到在数据中还包含一个timeindex的时间索引
# 查询时间索引
kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.timeindex 
可以看到和index索引一样,这个也是4Kb写出一部分数据,但是写出的是时间,我们可以根据时间进行断点找寻数据,指定时间重复计算
也就是说,写到磁盘的数据是按照1G分为一个整体部分的,但是这个整体部分需要4KB写一次,并且一次会生成一个索引问题信息,在检索的时候可以通过稀疏索引进行数据的检索,效率更快
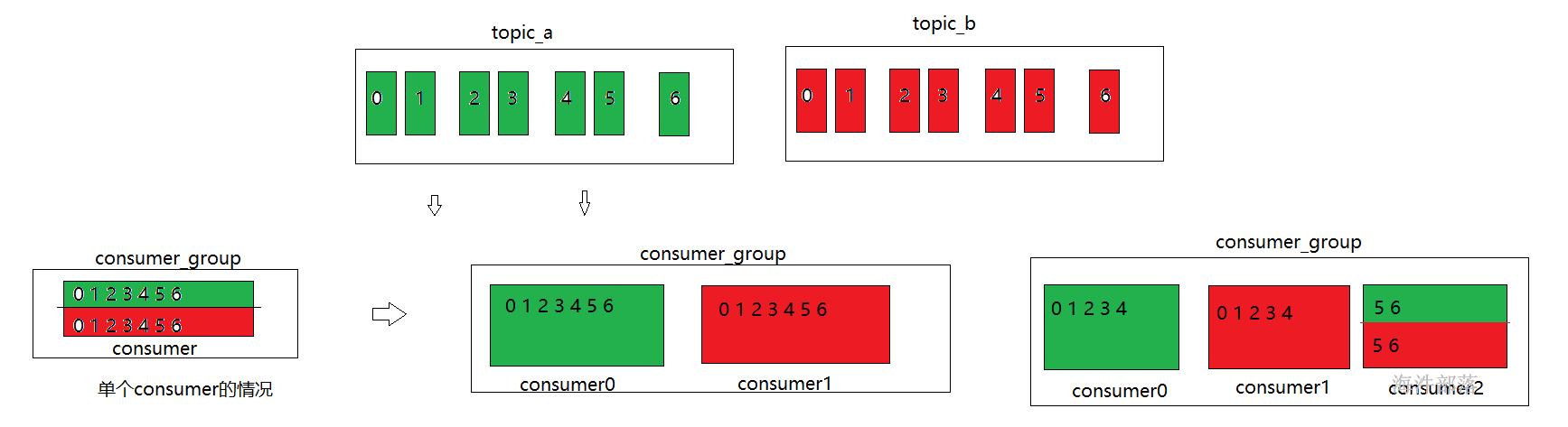
2.消费者结构
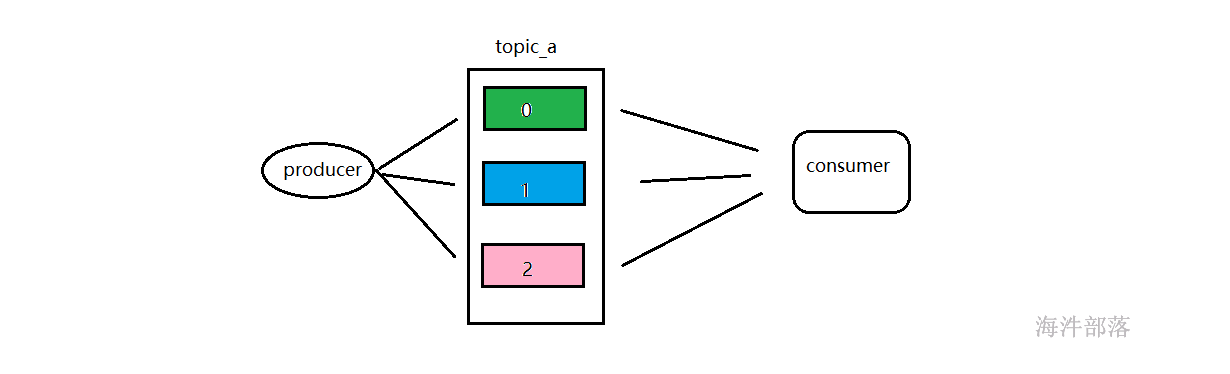
能够在kafka中拉取数据进行消费的组件或者程序都叫做消费者
这里面要设计到一个动作叫做拉取
首先我们要知道kafka这个消息队列主要的功能就是起到缓冲的作用,比如flume采集数据然后交给spark或者flink进行计算分析,但是flume采用的就是消息的push方式,这个方式不能够保证推送的数据消费者端一定会消费完毕,会出现数据的反压问题,这个问题很难解决,所以才出现了消息队列kafka,它可以起到一个缓冲的作用,生产者部分将数据直接全部推送到kafka,然后消费者从其中拉取数据,这边如果也采用推送的方式,那么也就在计算端会出现反压问题,所以kafka的消费者一般都是采用拉的方式pull,并不是push
消费者组
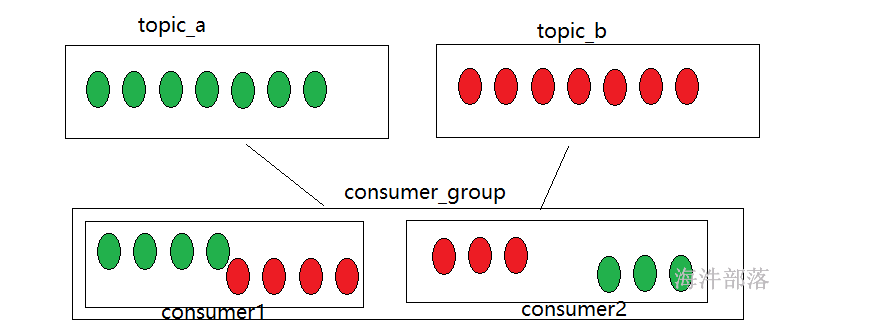
在一个topic中存在多个分区,可以分摊压力实现负载均衡,那么整体topic中的数据会很多,如果消费者只有一个的话很难全部消费其中的数据,压力也会集中在一个消费者中,并且在大数据行业中几乎所有的计算架构都是分布式的集群模式,那么这个集群模式中,计算的节点也会存在多个,这些节点都是可以从kafka中拉取数据的,所有消费者不可能只有一个,一般情况下都会有多个消费者
正因为topic存在多个分区,每个分区中的数据是独立的,那么消费者最好也是一个一个和分区进行一一对应的,所以有几个分区应该对应存在几个消费者是最好的
这个和分蛋糕是一样的,一个蛋糕分成几块,那么有几个人吃,应该是对应关系的
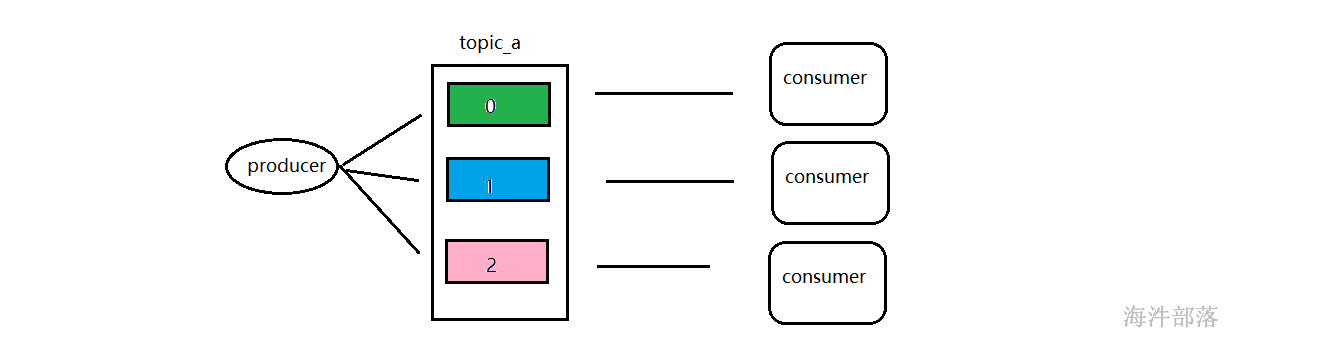
那么消费者是多个人,每个人对应一个单独的分区进行消费数据是最好的,但问题是一个消费者难道知道自己应该去消费哪个分区吗,他们直接会不会出现混乱呢
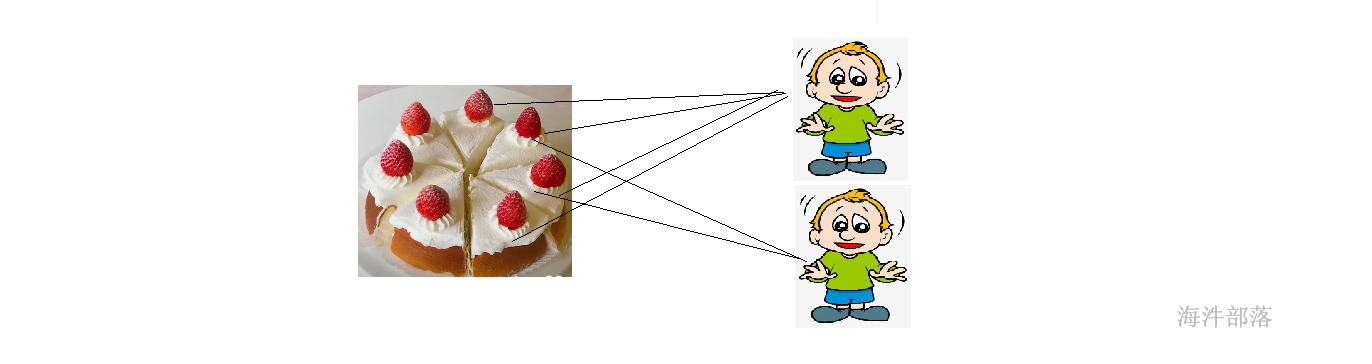
如果一个消费者想要消费多个分区的数据,或者两个消费者消费了同一个分区的数据怎么办
这样数据就会出现混乱了
消费者组出现了,它是一个组标识,每个消费者上面都应该设置一个消费者组标识,这样在进入到kafka消费相应分区的时候kafka就不会让数据混乱的分配给不同的消费者了,当然只有组内是有这样的分配关系的

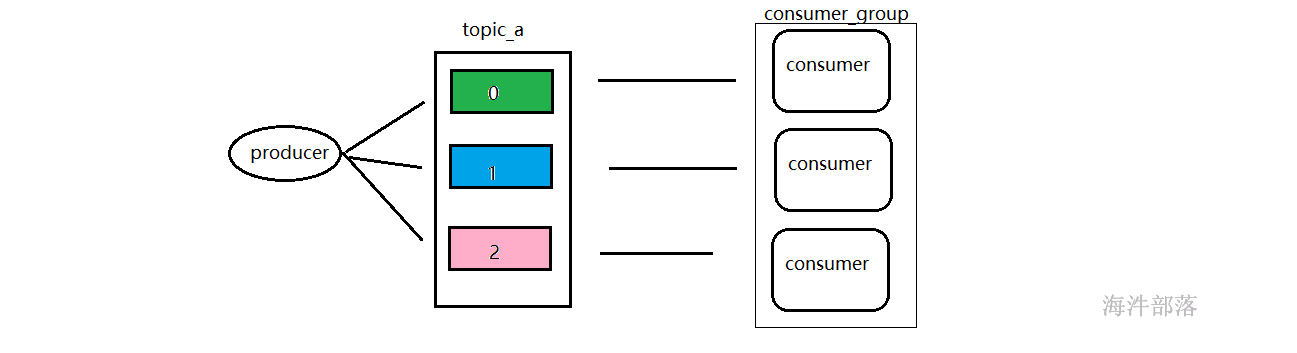
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
3.消费者实现
在实现消费者的时候我们需要知道几个消费者的配置重要参数
| 参数 | 解释 |
|---|---|
| bootstrap.servers | 集群地址 |
| key.deserializer | key反序列化器 |
| value.deserializer | value反序列化器 |
| group.id | 消费者组id |
首先创建消费者对象
消费者对象订阅相应的topic然后拉取其中的数据进行消费
整体代码如下
package com.hainiu.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.Properties;
public class Consumer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"hainiu_group");
//设定组id
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//设定key的反序列化器
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//设定value的反序列化器
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<String> topics = Arrays.asList("topic_a,topic_b");
//一个消费者可以消费多个分区的数据
consumer.subscribe(topics);
//订阅这个topic
while (true){
//死循环要一直消费数据
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
//间隔一秒钟消费一次数据,拉取一批数据过来
Iterator<ConsumerRecord<String, String>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());
}
}
}
}

发送数据
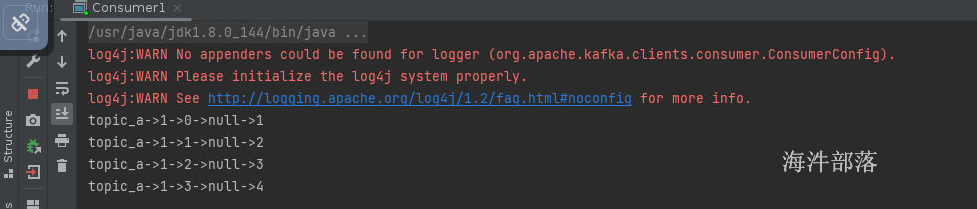
消费者打印出来数据
4.消费者和分区的对应关系
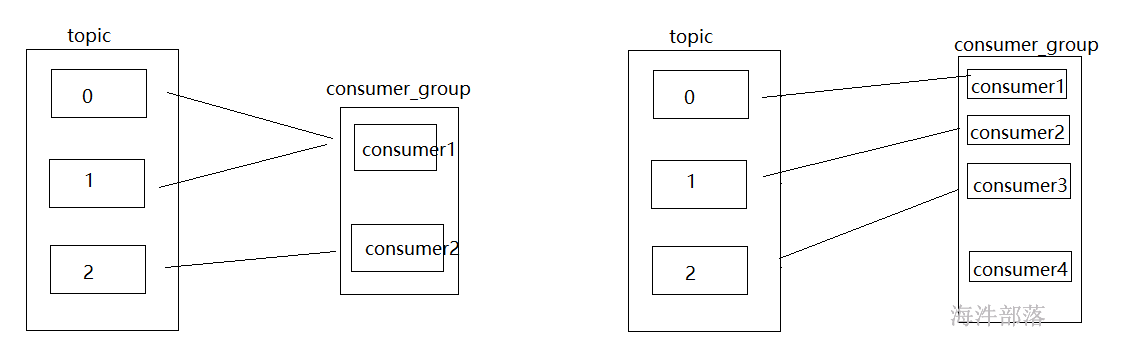
一个消费者组中的消费者和分区是一一对应的关系,一个分区应该对应一个消费者,但是如果消费者多了,那么有的消费者就没有分区消费,如果消费者少了那么会出现一个消费者消费多个分区的情况
# 首先创建topic_c 用于测试分区和消费者的对应关系
kafka-topics.sh --bootstrap-server nn1:9092 --create --topic topic_c --partitions 3 --replication-factor 2
# 启动两个消费者 刚才我们写的消费者main方法运行两次
# 然后分别在不同的分区使用生产者发送数据,看数据在消费者中的打印情况首先选择任务可以并行执行
选择任务修改配置
我们可以看到允许多实例并行执行
启动两次,这个时候我们就有了两个消费者实例
生产者线程:分别向三个分区中发送1 2 3元素
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class Producer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);
ProducerRecord<String, String> record1 = new ProducerRecord<>("topic_c", 0,null,"1");
ProducerRecord<String, String> record2 = new ProducerRecord<>("topic_c", 1,null,"2");
ProducerRecord<String, String> record3 = new ProducerRecord<>("topic_c", 2,null,"3");
producer.send(record1);
producer.send(record2);
producer.send(record3);
producer.close();
}
}
可以看到有的消费者消费了两个分区的数据
如果启动三个消费者会发现每个人消费一个分区的数据

如果启动四个消费者

我们发现有一个消费者没有数据
5.消费多topic数据
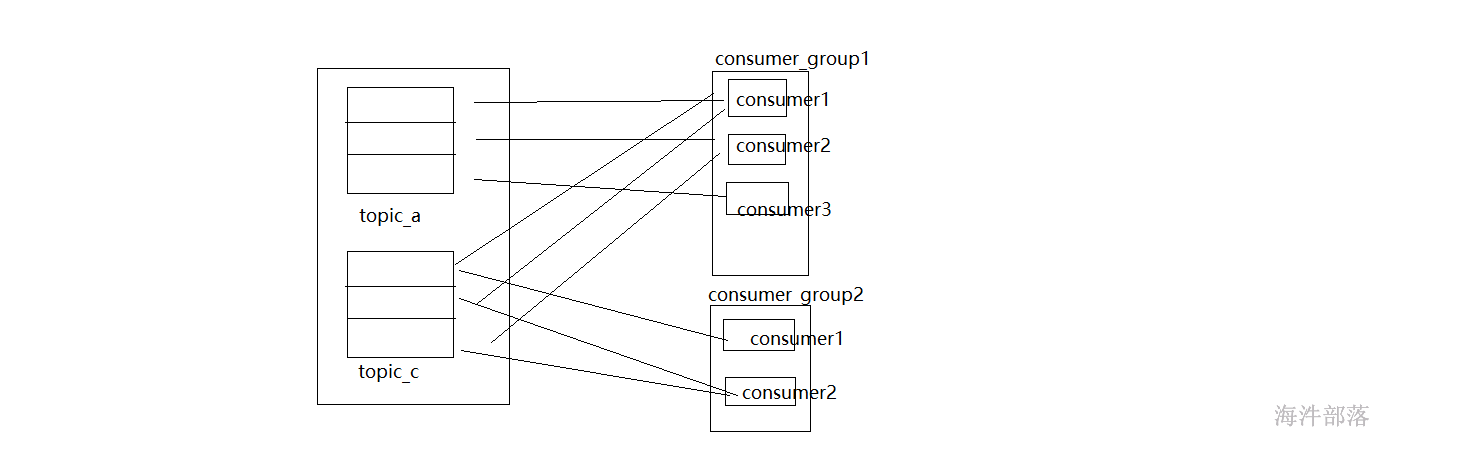
不同组消费不同的topic或者一个组可以消费多个topic都是可以的
整体代码如下:
package com.hainiu.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.Properties;
public class Consumer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"hainiu_group");
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<String> topics = Arrays.asList("topic_c","topic_a");
//订阅多个topic的数据变化
consumer.subscribe(topics);
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());
}
}
}
}
两个topic同时发布数据
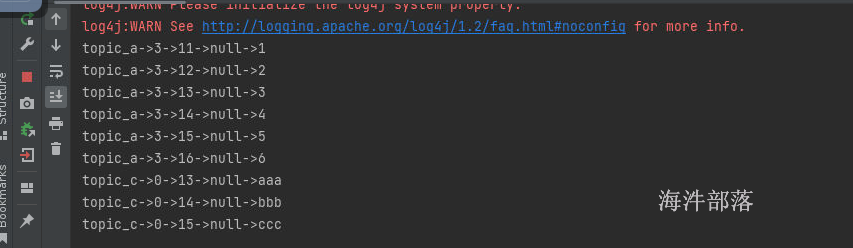
两个topic的数据全部都消费到了
6.多个组消费一个topic
同一个topic可以由多个消费者组进行消费数据,并且相互之间是没有任何影响的
修改同一份代码的组标识不同。启动两个实例查看里面的消费信息
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"hainiu_group1");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"hainiu_group2");
//分别修改消费者组的id不同package com.hainiu.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.Properties;
public class Consumer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"hainiu_group");
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<String> topics = Arrays.asList("topic_c");
//订阅多个topic的数据变化
consumer.subscribe(topics);
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());
}
}
}
}
在topic_c中发送信息,会发现数据已经被两个组都消费到数据了

7.自定义反序列化器
反序列化器要和producer的序列化器一一对应,我们可以自定义实现类的反序列化
String类型的反序列化器
package com.hainiu.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.Deserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.nio.charset.StandardCharsets;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.Properties;
public class ConsumerWithStringDeserializer {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"hainiu_group1");
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, MyDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, MyDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<String> topics = Arrays.asList("topic_c","topic_a");
consumer.subscribe(topics);
while(true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
Iterator<ConsumerRecord<String, String>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"-->"+record.partition()+"-->"+record.key()+"-->"+record.value()+"-->"+record.offset());
}
}
}
public static class MyDeserializer implements Deserializer<String>{
@Override
public String deserialize(String topic, byte[] data) {
String line = new String(data, StandardCharsets.UTF_8);
return line;
}
}
}Student类型的反序列化器
package com.hainiu.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.Deserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.Properties;
public class ConsumerWithStudentDeSerializer {
public static class MyStudentDeserializer implements Deserializer<Student>{
@Override
public Student deserialize(String topic, byte[] data) {
ByteArrayInputStream byteIn = null;
ObjectInputStream objectIn = null;
Student s = null;
try {
byteIn = new ByteArrayInputStream(data);
objectIn = new ObjectInputStream(byteIn);
Object o = objectIn.readObject();
s = (Student) o;
} catch (Exception e) {
throw new RuntimeException(e);
}finally {
try {
byteIn.close();
objectIn.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return s;
}
}
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"hainiu_group1");
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, MyStudentDeserializer.class.getName());
KafkaConsumer<String, Student> consumer = new KafkaConsumer<String, Student>(pro);
List<String> topics = Arrays.asList("topic_c","topic_a");
consumer.subscribe(topics);
while(true){
ConsumerRecords<String, Student> records = consumer.poll(Duration.ofMillis(100));
Iterator<ConsumerRecord<String, Student>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, Student> record = it.next();
System.out.println(record.key()+"-->"+record.value());
}
}
}
}8.消费者的分区分配规则
上面我们提到过,消费者有的时候会少于或者多于分区的个数,那么如果消费者少了有的消费者要消费多个分区的数据,如果消费者多了,有的消费者就可能没有分区的数据消费
那么这个关系是如何分配的呢?
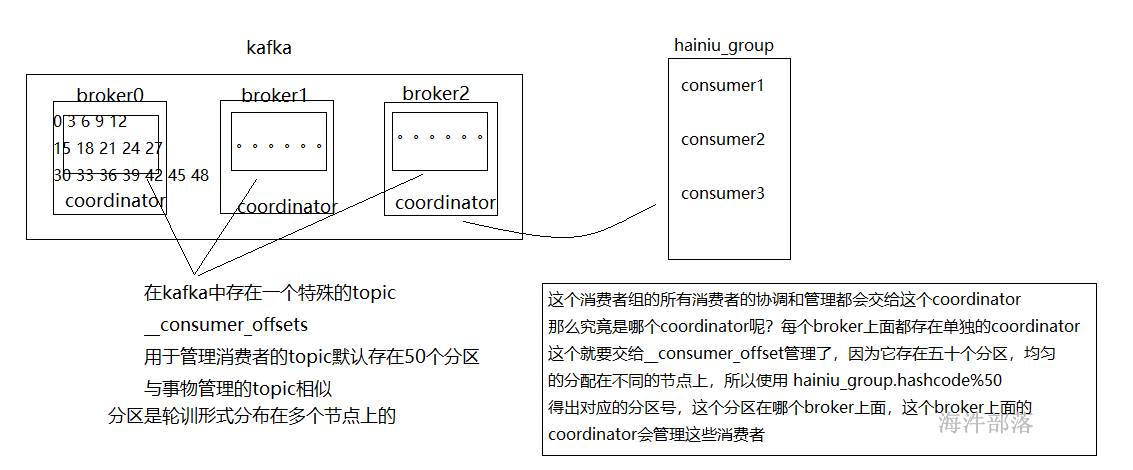
现在我们知道kafka中存在一个coordinator可以管理这么一堆消费者,它可以帮助一个组内的所有消费者进行分区的分配和对应
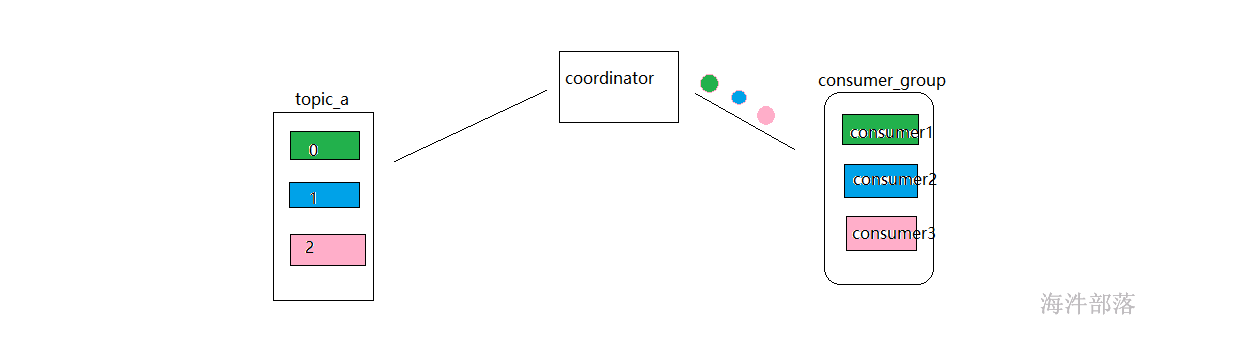
通过coordinator进行协调
这个分配规则分为以下几种
8.1 range分配器
按照范围形式进行分配分区数量
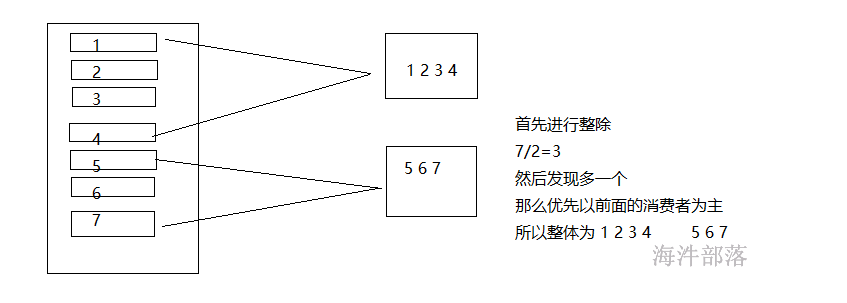
# 为了演示分区的分配效果我们创建一个topic_d,设定为7个分区
kafka-topics.sh --bootstrap-server nn1:9092 --topic topic_d --create --partitions 7 --replication-factor 2 consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
}
});然后改版订阅代码,subscribe订阅信息的时候展示出来分区的对应映射关系,这个只是一个监控的作用没有其他的代码影响,ConsumerRebalanceListener增加监视
其中存在两个比较直观的方法
onPartitionsRevoked回收的分区
onPartitionsAssigned分配的分区
能够直观展示在分区分配的对应关系
其中我们需要知道两个比较重要的参数
| 参数 | 解释 |
|---|---|
| offsets.topic.num.partitions | __consumer_offset这个topic的分区数量默认50个 |
| heartbeat.interval.ms | 消费者和协调器的心跳时间 默认3s |
| session.timeout.ms | 消费者断开的超时时间 默认45s,最小不能小于6000 |
| partition.assignment.strategy | 设定分区分配策略 |
也就是说我们想要直观查看消费者变化后的映射对应关系需要停止消费者以后45s才可以,这个在代码中我们需要人为设定小点,更加快速查看变化
代码测试原理
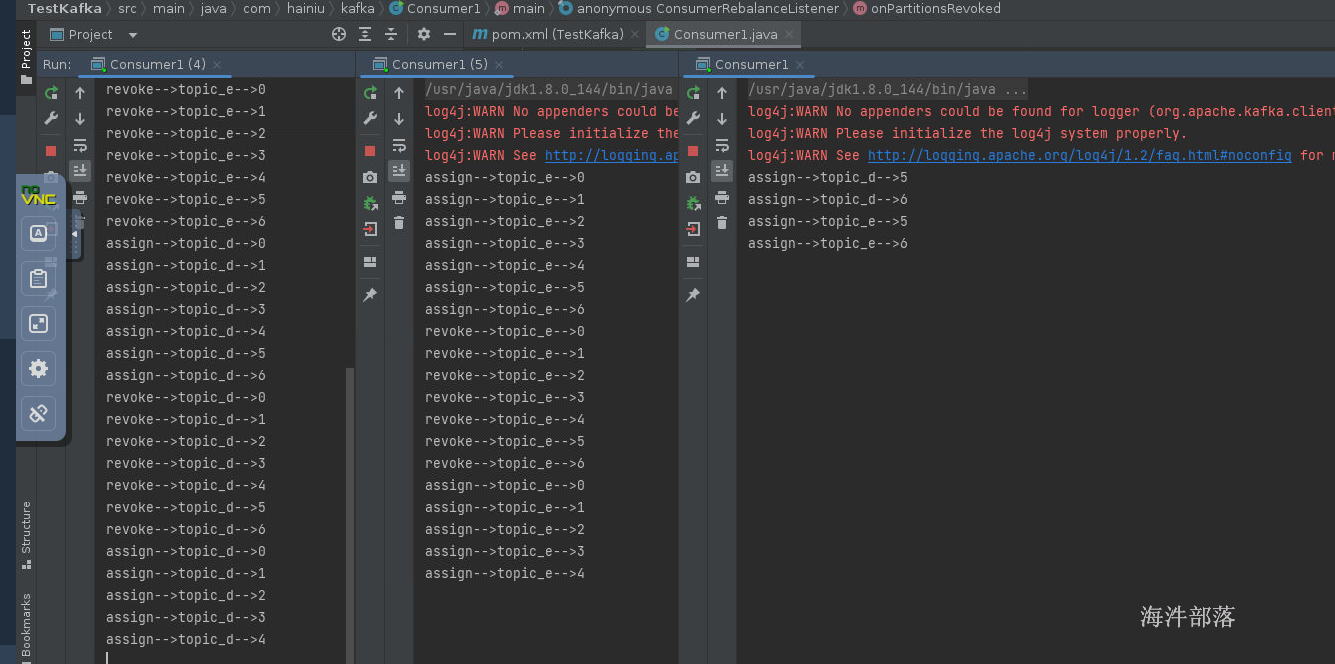
首先设定topic_d的分区为7个,然后启动一个组内的两个消费者,可以看到他们的分配关系在onPartitionsAssigned这个方法中打印出来,同时我们关闭一个消费者,可以看到onPartitionsRevoked可以展示回收的分区,onPartitionsAssigned以及这个方法中分配的分区
整体代码如下:
package com.hainiu.kafka;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class Consumer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"hainiu_group2");
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,RangeAssignor.class.getName());
//设定分区分配策略为range
pro.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,6000);
//设定consumer断开超时时间最小不能小于6s
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<String> topics = Arrays.asList("topic_d");
consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
for (TopicPartition partition : partitions) {
System.out.println("revoke-->"+partition.topic()+"-->"+partition.partition());
}
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
for (TopicPartition partition : partitions) {
System.out.println("assign-->"+partition.topic()+"-->"+partition.partition());
}
}
});
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());
}
}
}
}
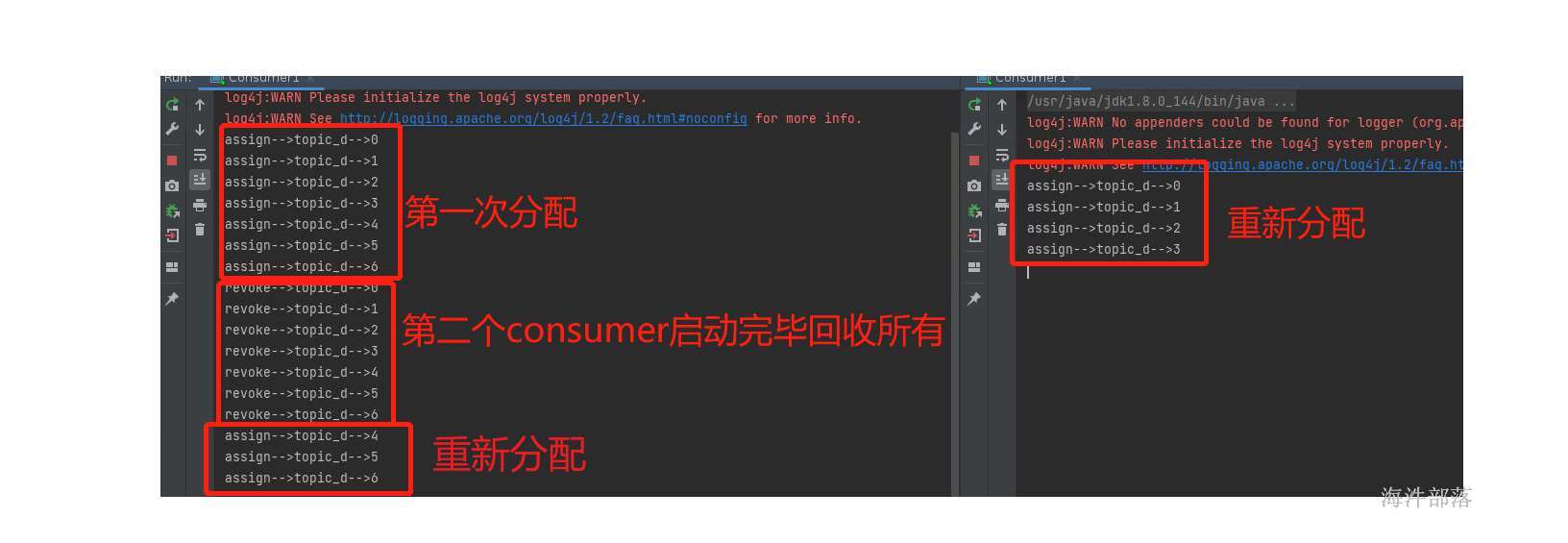
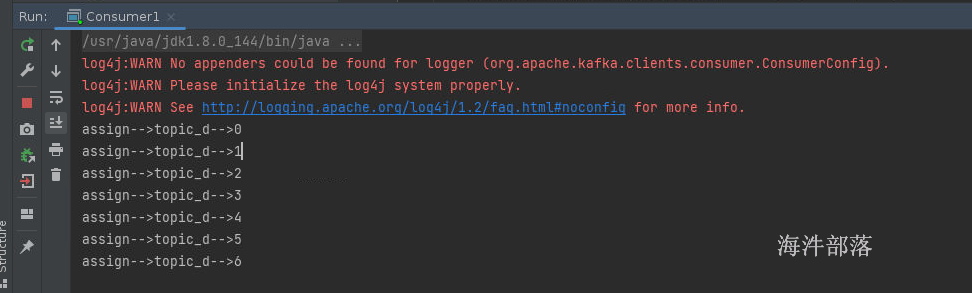
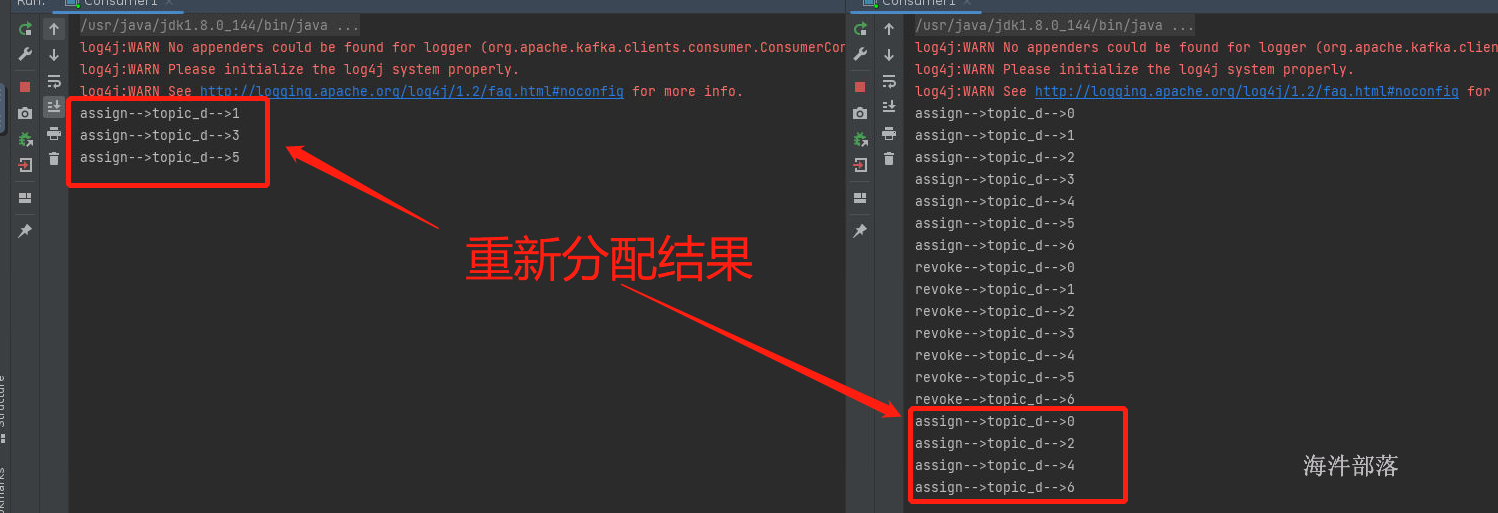
我们执行两个实例,两个实例代表两个消费者位于同一个组中,那么两个消费者的分配关系按照,范围进行分割
consumer0[0,1,2,3] consumer1[4,5,6]
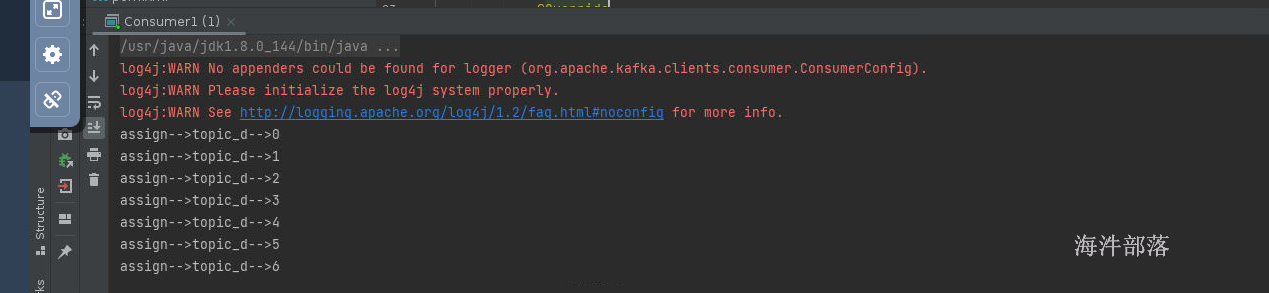
运行一个实例的时候可以看见,没有回收,因为第一次分配,所以第一个consumer消费所有的分区
如果启动第二个消费者可以看到,第一个消费者要回收所有的已经分配给他的分区,然后重新将分区分配给consumer1和consumer2,因为coordinator的分配规则基于eager协议,这个协议的规则就是当分配关系发生变化的时候要全部回收然后打乱重分
缺点:
这个协议只是按照范围形式进行重新分配分区,会造成单个消费者的压力过大问题,多个topic就会不均匀
会造成分配不均匀的问题
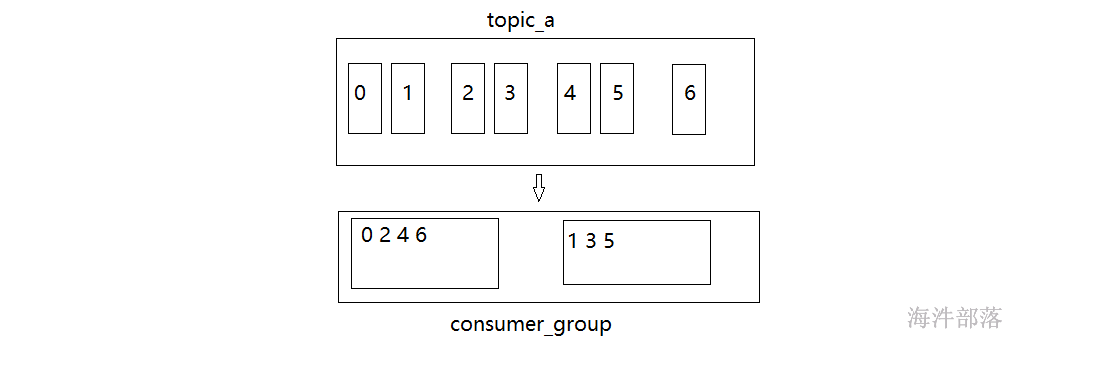
8.2 roundRobin轮训分配策略
轮训形式分配分区,一个消费者一个分区
整体代码如下:
pro.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,RoundRobinAssignor.class.getName());设定分配规则为roundRobin的
启动一个的效果
启动两个应用
优点:
同range方式相比,在多个topic的情况下,可以保证多个consumer负载均衡
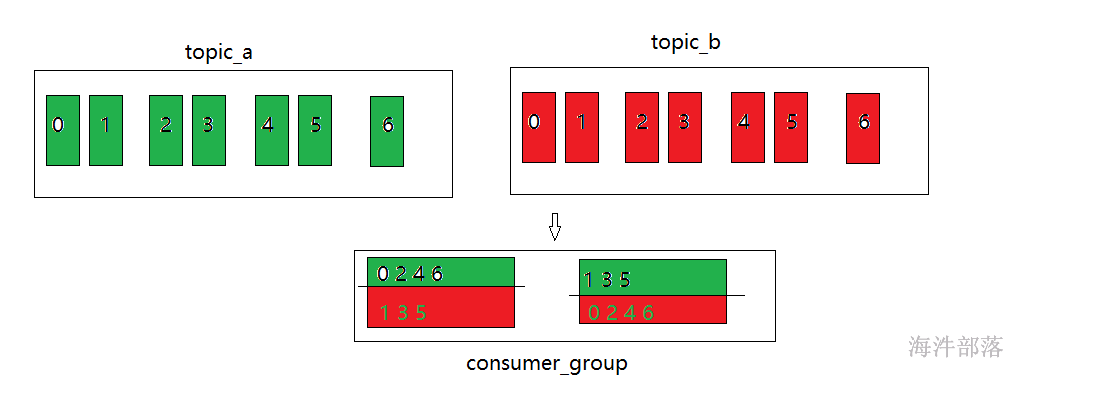
分配规则如上图,一人一个轮训形式
consumer0 [0 2 4 6 1 3 5]
consumer1 [1 3 5 0 2 4 6]
缺点
不管是range的还是roundRobin的分配方式都是全量收回打乱重新分配,这样的效率太低,所以我们使用下面的粘性分区策略
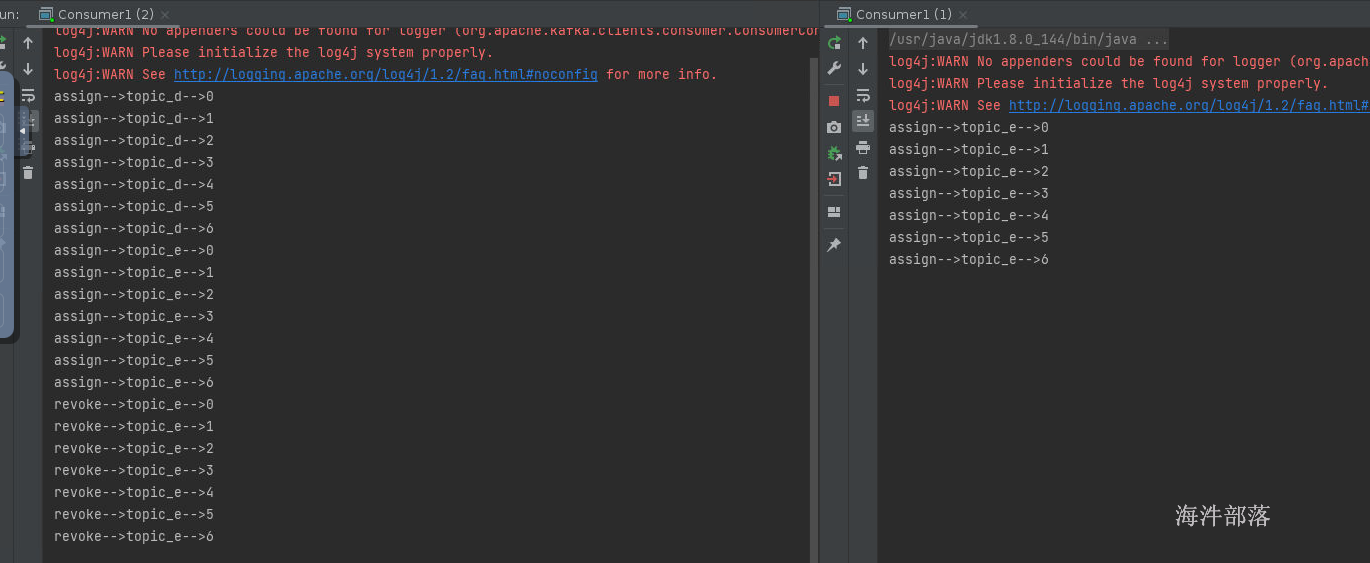
8.3 sticky粘性分区
粘性分区它的重新分区原理和原来的roundRobin的分区方式差不多,但是又不相同,主要是分区逻辑一样,但是重新分配分区的时候优先保留原分区,然后重新分配其他分区,从而不需要全部打乱重分,减少重新分配分区消耗
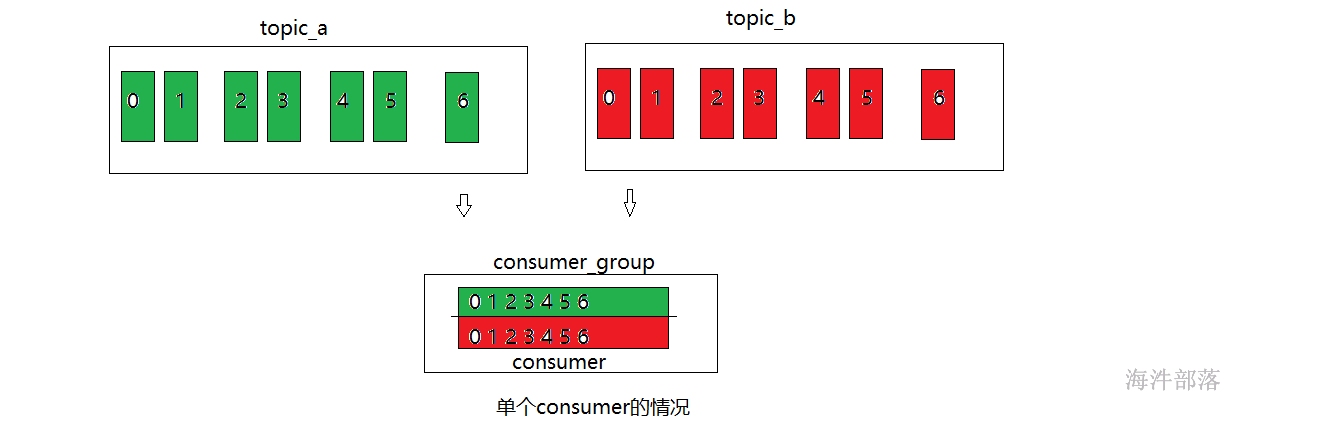
第二次启动
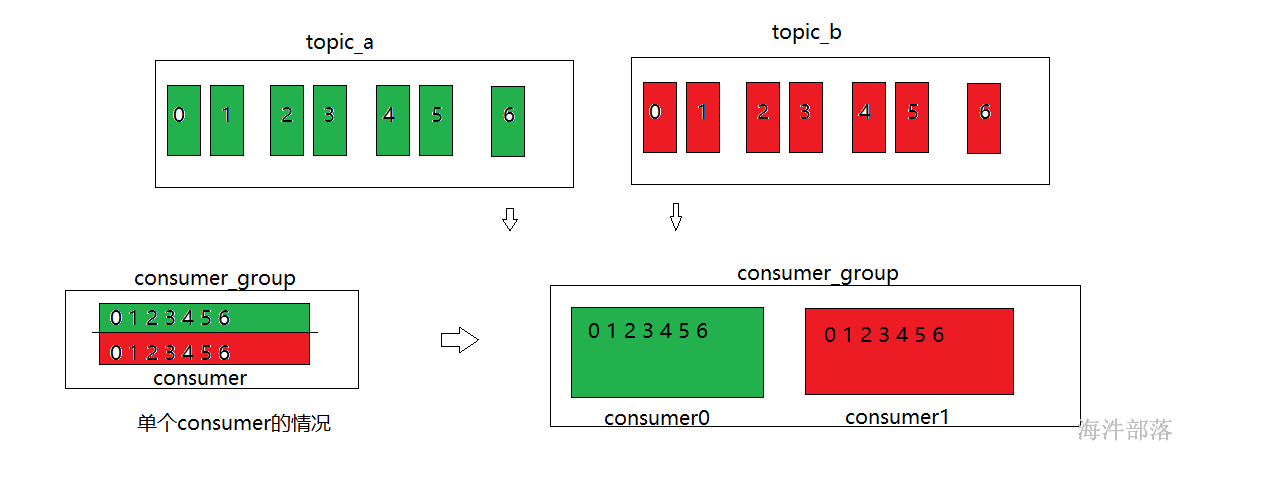
第三次
分区分配方式一样,但是如果重新分配的话会有很多原来分区的预留,重新分配新的分区
# 为了演示效果再次创建新的topic topic_e 七个分区
kafka-topics.sh --bootstrap-server nn1:9092 --topic topic_e --create --partitions 7 --replication-factor 2然后让复制代码,修改订阅两个topic
pro.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,StickyAssignor.class.getName());
//修改为粘性分区
List<String> topics = Arrays.asList("topic_d","topic_e");
//订阅两个topic并且运行应用实例分别运行1 ,2 ,3 多种个数的实例
截图不全,大家可以自己演示
我们发现多个实例的运行时候,优先保留之前的分区规则,然后重新分配,但是优先以分区分配均衡为主
以上三种都基于eager协议,也就是想要重新分配分区一定要将原来的所有分区回收,全部打乱重新,即使保留原来的分区规则,也需要全部都回收分区,这样效率非常低下,最后一种CooperativeSticky分区策略完全打破以上三种的分区关系
8.4 CooperativeSticky分区
以粘性为主,但是不全部收回分区,只是将部分需要重新分配的分区重新调配,效率高于以上三种分区策略
pro.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,CooperativeStickyAssignor.class.getName());
//设定分区策略运行两个实例,查看控制台信息发现
整个分区分配规则和粘性分区策略一致,但是并不需要收回全部分区
系统默认分区分配规则为:
range+CooperativeSticky
范围分区为主,优先粘性并且不急于eager协议
8.5 指定分区消费数据
在计算处理过程中,有时候我们需要指定一个消费者组消费指定的分区,计算其中的数据,这个时候以上的所有分区策略都不符合我们人为的要求,我们需要指定相应的分区进行消费
consumer.assign();
//用指定的方式定向消费相应的分区数据整体代码如下:
package com.hainiu.kafka;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class ConsumerAssginPartition {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"hainiu_group2");
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,CooperativeStickyAssignor.class.getName());
pro.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,6000);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<TopicPartition> list = Arrays.asList(
new TopicPartition("topic_d", 0),
new TopicPartition("topic_e", 0)
);
consumer.assign(list);
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());
}
}
}
}我们只消费topic_e的0号分区和topic_d的0号分区

生产者向两个topic的0号分区发送数据
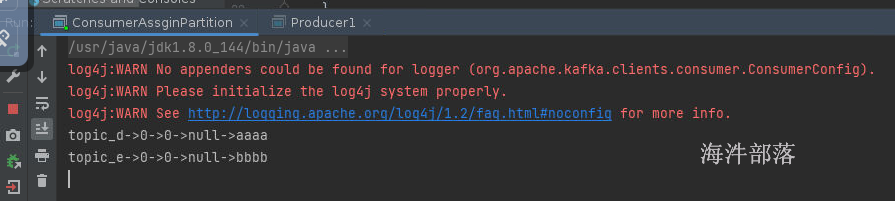
消费者可以直接消费其中的数据
9.kafka的偏移量
9.1偏移量的概念
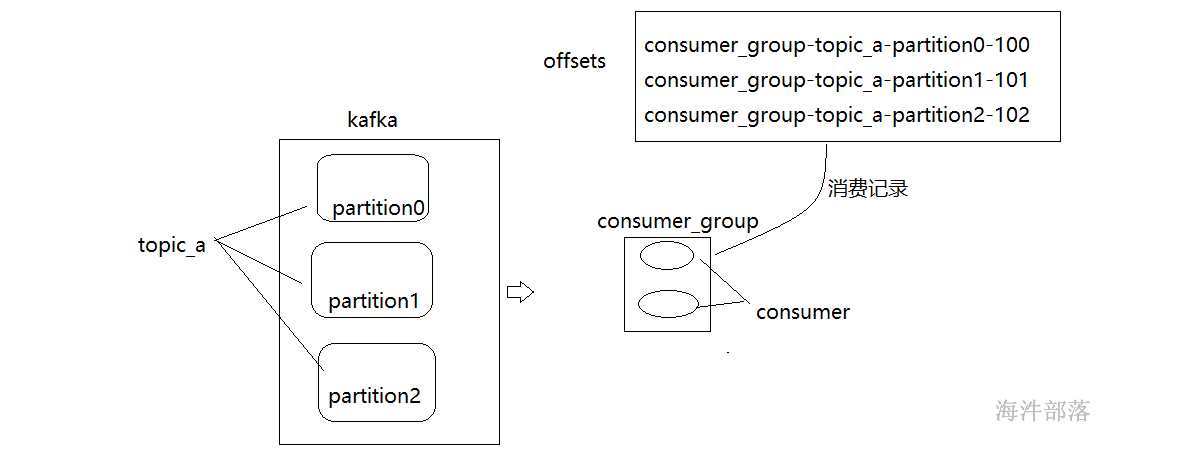
消费者在消费数据的时候需要将消费的记录存储到一个位置,防止因为消费者程序宕机而引起断点消费数据丢失问题,下一次可以按照相应的位置从kafka中找寻数据,这个消费位置记录称之为偏移量offset
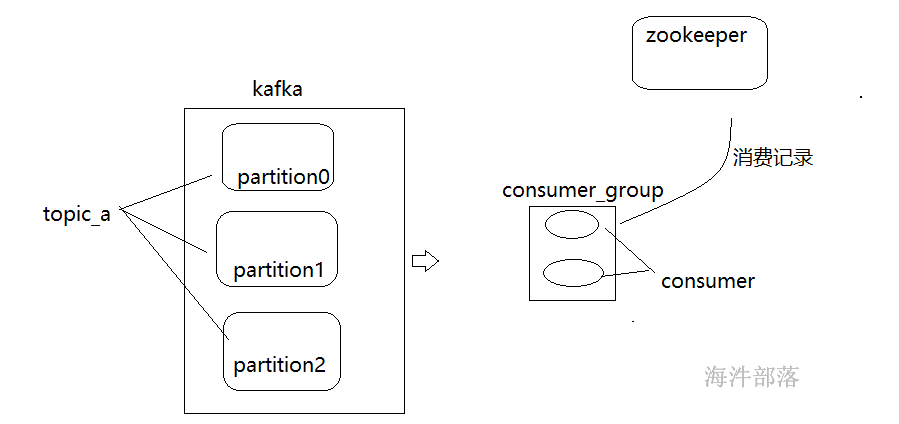
kafka0.9以前版本将偏移量信息记录到zookeeper中
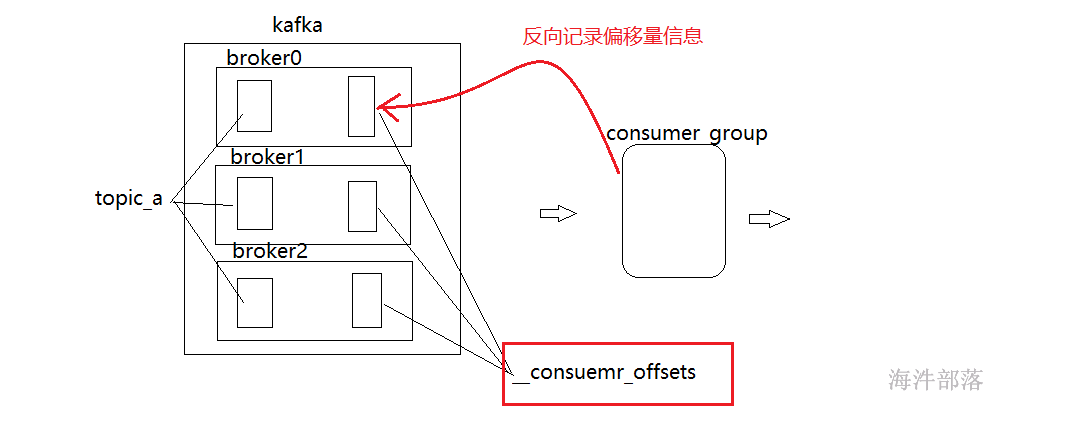
新版本中偏移量信息记录在__consumer_offsets中,这个topic是系统生成的,不仅仅帮助管理偏移量信息还能分配consumer给哪个coordinator管理,是一个非常重要的topic
它的记录方式和我们知道的记录方式一样 groupid + topic + partition ==> offset
其中存储到__consumer_offsets中的数据格式也是按照k-v进行存储的,其中k是groupid + topic + partition
value值为offset的偏移量信息
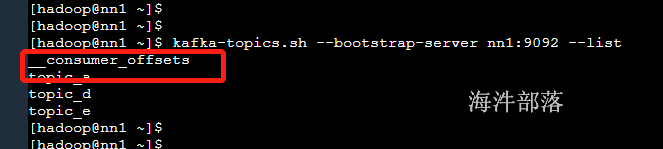
可以看到系统生成的topic
因为之前我们消费过很多数据,现在可以查看一下记录在这个topic中的偏移量信息
其中存在一个kafka-consumer-groups.sh 命令
# 查看消费者组信息
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
# 查询具体信息
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group
# 查看活跃信息
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group --members
当前使用组信息
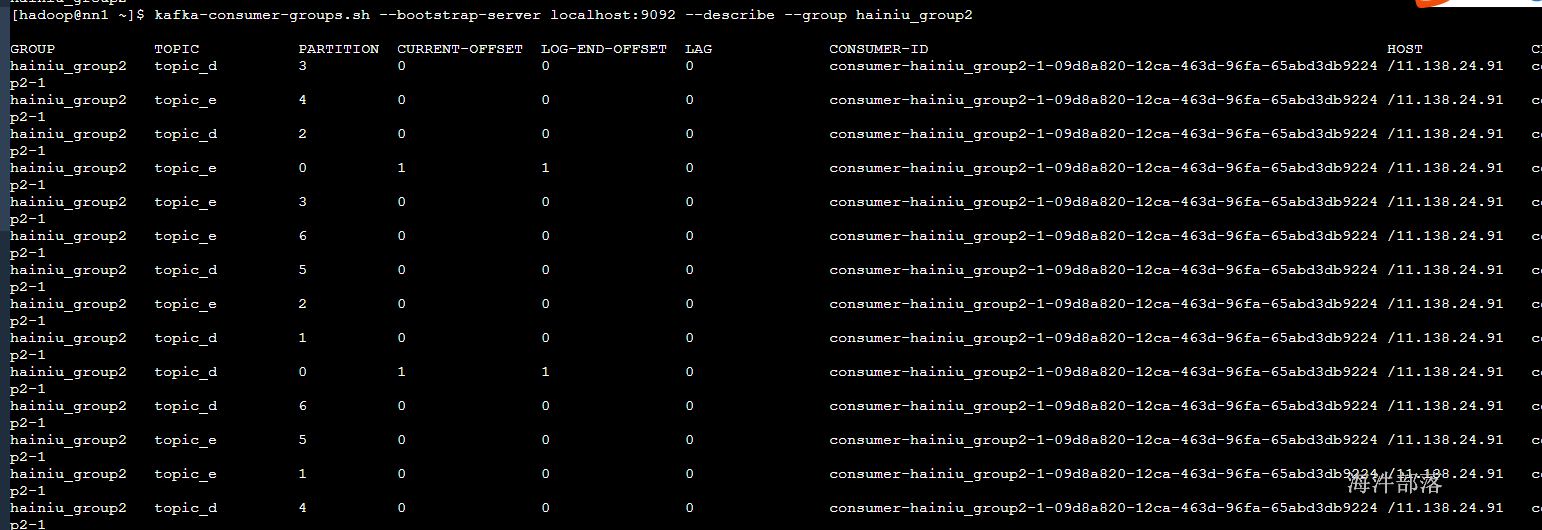
当前组消费偏移量信息
GROUP:组名
TOPIC:topic信息
PARTITION:分区
CURRENT-OFFSET:当前消费偏移量
LOG-END-OFFSET:这个分区总共存在多少数据
LAG:还差多少没消费
CONSUMER-ID:随机消费者id
HOST:主机名
CLIENT-ID:客户端id同时我们也可以查询__consumer_offset中的原生数据
kafka-console-consumer.sh --bootstrap-server nn1:9092 \
--topic __consumer_offsets --from-beginning --formatter \
kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter使用元数据格式化方式查看偏移量信息数据
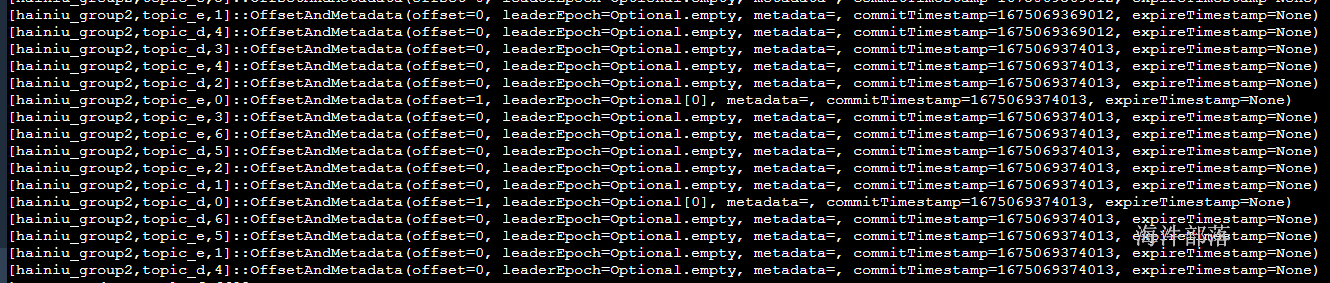
结果如下key展示的是groupid,topic,partition value值展示的是当前的偏移量信息
并且在这个topic中是追加形式一致往里面写入的
9.2 偏移量的自动管理
那么我们已经看到了偏移量的存储但是偏移量究竟是怎么提交的呢?
首先我们没有设置任何的偏移量提交的代码,这个是默认开启的,其中存在两个参数
pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
//开启自动提交偏移量信息
pro.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
//默认提交间隔5s

官网的设置参数为两个true和5000
所以我们在没有开启默认提交的时候已经自动提交了
为了演示自动提交的效果我们引入一个参数
auto.offset.reset
这个参数用于控制没有偏移量存储的时候,应该从什么位置进行消费数据
其中参数值官网中给出三个
[latest, earliest, none]
latest:从最新位置消费
earliest:最早位置消费数据
none:如果不指定消费的偏移量直接报错
一定要记得一点,如果有偏移量信息那么以上的设置是无效的

现在我们设置读取位置为最早位置,并且消费数据,看看可不可以记录偏移量,断点续传
思路:
首先修改组id为一个新的组,然后从最早位置消费数据,如果记录了偏移量,那么重新启动消费者会看到,没有任何数据,因为之前记录了消费数据的位置
整体代码如下:
package com.hainiu.kafka;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class Consumer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"new_group");
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
pro.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
pro.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<String> topics = Arrays.asList("topic_d","topic_e");
consumer.subscribe(topics);
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());
}
}
}
}
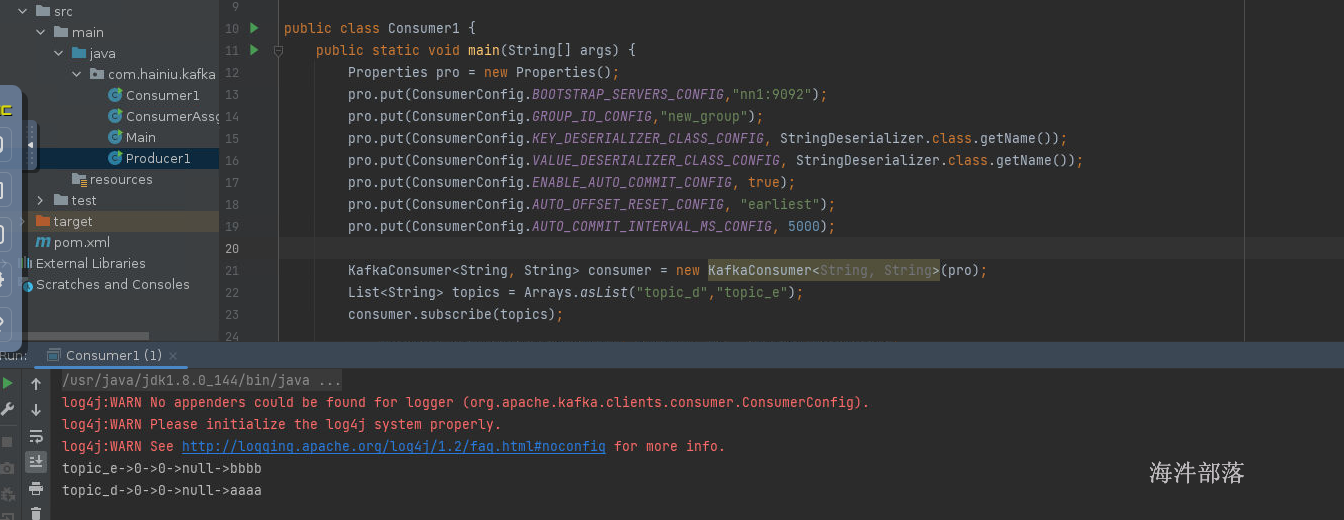
运行完毕打印数据
这个时候我们需要在5s之内关闭应用,然后重新启动,因为提交的间隔时间是5s
再次启动
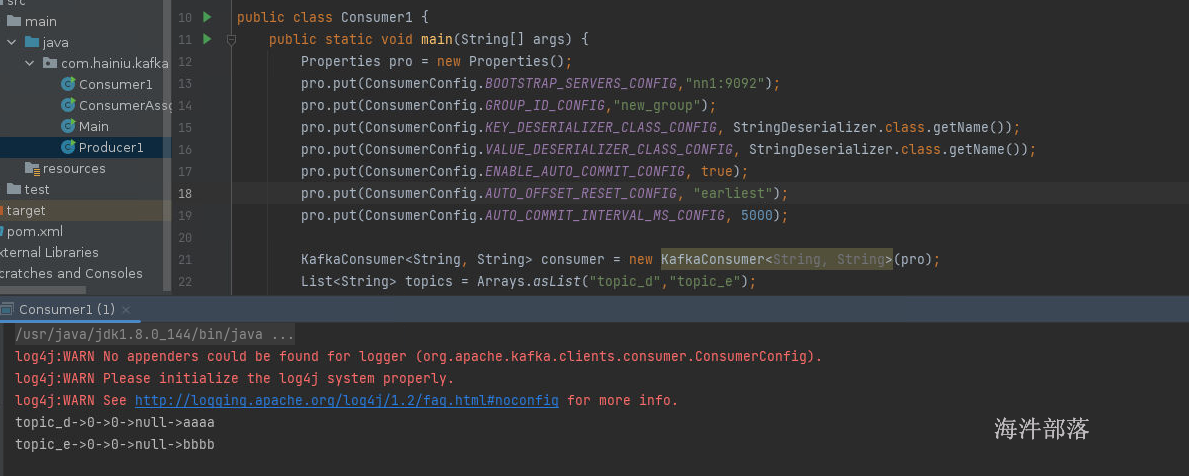
我们发现数据依旧被消费出来了,证明之前的偏移量存储没有任何效果和作用,因为间隔时间是5s
现在我们等待5s后在关闭应用
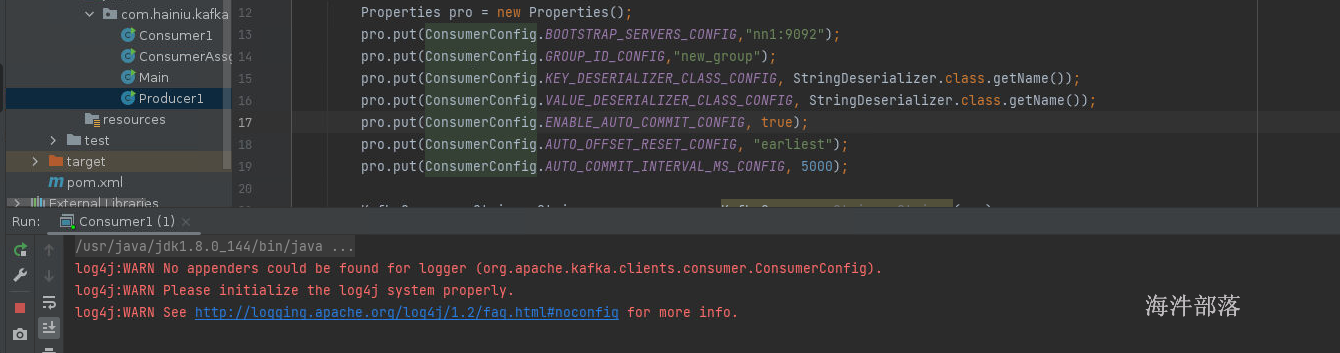
发现没有任何数据产生,因为偏移量已经提交了
9.3 偏移量的手动提交
如上的案例我们发现偏移量的管理如果交给系统自己管理,我们没有办法及时的修改和管理偏移量信息,这个时候我们需要手动来提交给管理偏移量,更加及时和方便
这个时候引入两个方法
consumer.commitAsync();
consumer.commitSync();commitAsync 异步提交方式:只提交一次,不管成功与否不会重试
commitSync 同步提交方式:同步提交方式会一直提交到成功为止
一般我们都会选择异步提交方式,他们的功能都是将拉取到的一整批数据的最大偏移量直接提交到__consumer_offsets中,但是同步方式会很浪费资源,异步方式虽然不能保证稳定性但是我们的偏移量是一直递增存储的,所以偶尔提交不成功一个两个不影响我们的使用
pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
//设定自动提交为false
consumer.commitSync();
consumer.commitAsync();
//设定提交方式为手动提交整体代码如下:
package com.hainiu.kafka;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class Consumer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"new_group1");
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
pro.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// pro.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<String> topics = Arrays.asList("topic_d","topic_e");
consumer.subscribe(topics);
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());
}
consumer.commitAsync();
// consumer.commitSync();
}
}
}现在先在topic中输入部分数据
然后启动消费者,当存在数据打印的时候马上关闭掉应用,在此启动会发现数据不会重新消费

现在启动应用,修改组id
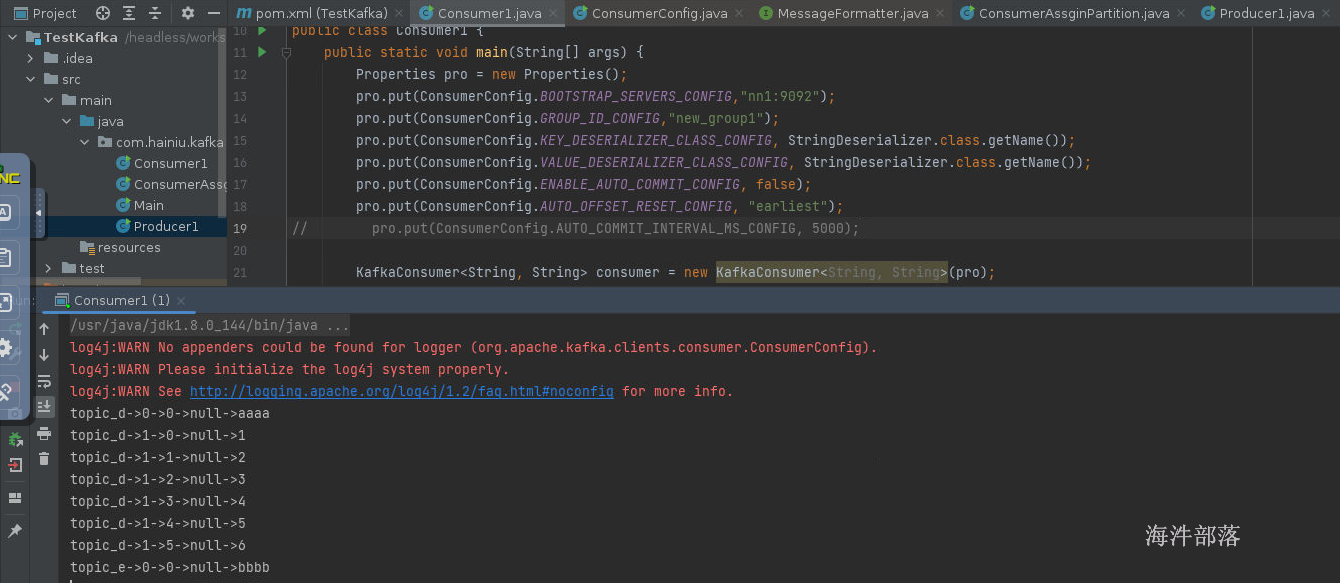
打印完毕数据立即重新启动应用

偏移量已经提交不会重复消费数据
9.4 断点消费数据
在没有偏移量的时候我们可以设定
auto.offset.reset进行数据的消费
可选参数有 latest earliest none等位置
但是如果存在偏移量以上的设定就不在好用了,我们需要根据偏移量的位置进行断点消费数据
但是有的时候我们需要指定位置消费相应的数据
这个时候我们需要使用到
consumer.seek();
//可以指定位置进行数据的检索但是我们不能随意的指定消费者消费数据的位置,因为在启动消费者的时候,一个组中会存在多个消费者,每个人拿到的对应分区是不同的,所以我们需要知道这个消费者能够获取的分区是哪个,然后再指定相应的断点位置
这里我们就需要监控分区的方法展示出来所有订阅的分区信息
consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
}
});为了演示效果我们使用生产者在topic_d中增加多个消息
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class Producer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);
for (int i = 0; i < 1000; i++) {
ProducerRecord<String, String> record = new ProducerRecord<String, String>("topic_d", "" + i, "message"+i);
producer.send(record);
}
producer.close();
}
}随机发送数据到不同的节点,使用随机k
然后使用断点消费数据
不设置任何的偏移量提交操作和断点位置
package com.hainiu.kafka;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class ConsumerWithUDOffset {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"new1");
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
pro.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,6000);
pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<String> topics = Arrays.asList("topic_e");
// range roundRobin sticky cooperativeSticky
consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> collection) {
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> collection) {
for (TopicPartition topicPartition : collection) {
consumer.seek(topicPartition,195);
}
}
});
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());
}
consumer.commitAsync();
}
}
}
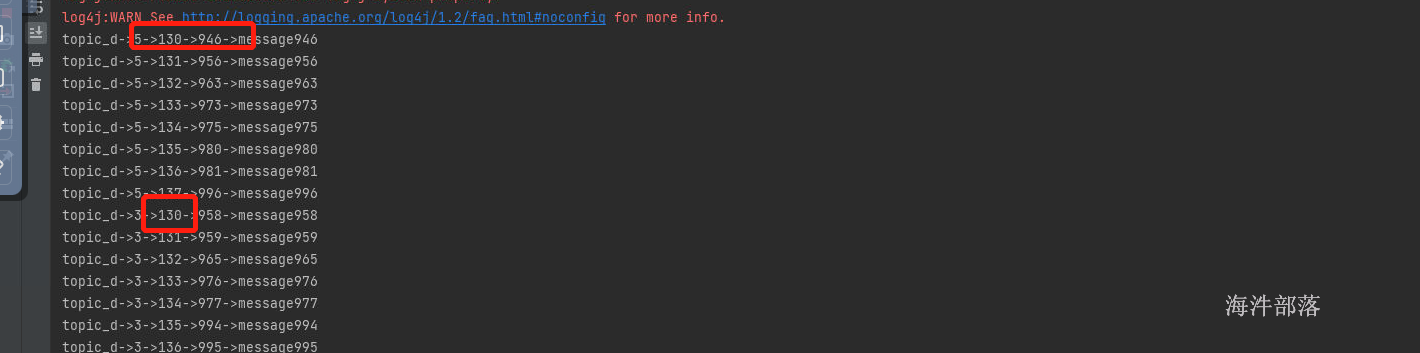
都从130的断点位置进行消费数据
9.5 时间断点
kafka没有给大家提供直接根据时间找到断点位置的方法,我们需要根据时间找到偏移量,然后根据偏移量进行数据消费
consumer.offsetsForTimes();
//通过这个方法找到对应时间的偏移量位置
consumer.seek();
//然后在通过这个方法根据断点进行消费数据思路:
找寻一个时间点,然后将它转换为时间戳,放入到consumer.offsetsForTimes();中找寻这个偏移量的位置,然后在根据偏移量seek到数据,一定要注意判断这个偏移量是否为空
整体代码如下
package com.hainiu.kafka;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class Consumer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"new_group221");
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<String> topics = Arrays.asList("topic_e");
consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// no op
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
HashMap<TopicPartition, Long> map = new HashMap<>();
for (TopicPartition partition : partitions) {
map.put(partition,1675076400000L);
//将时间和分区绑定在一起,然后合并在一起放入到检索方法中
}
Map<TopicPartition, OffsetAndTimestamp> offsets = consumer.offsetsForTimes(map);
//根据时间获取时间对应的偏移量位置
for (Map.Entry<TopicPartition, OffsetAndTimestamp> en : offsets.entrySet()) {
System.out.println(en.getKey()+"-->"+en.getValue());
if(en.getValue() != null){
consumer.seek(en.getKey(),en.getValue().offset());
//获取每个分区的偏移量的位置,使用seek进行找寻数据
}
}
}
});
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());
}
// consumer.commitAsync();
}
}
}
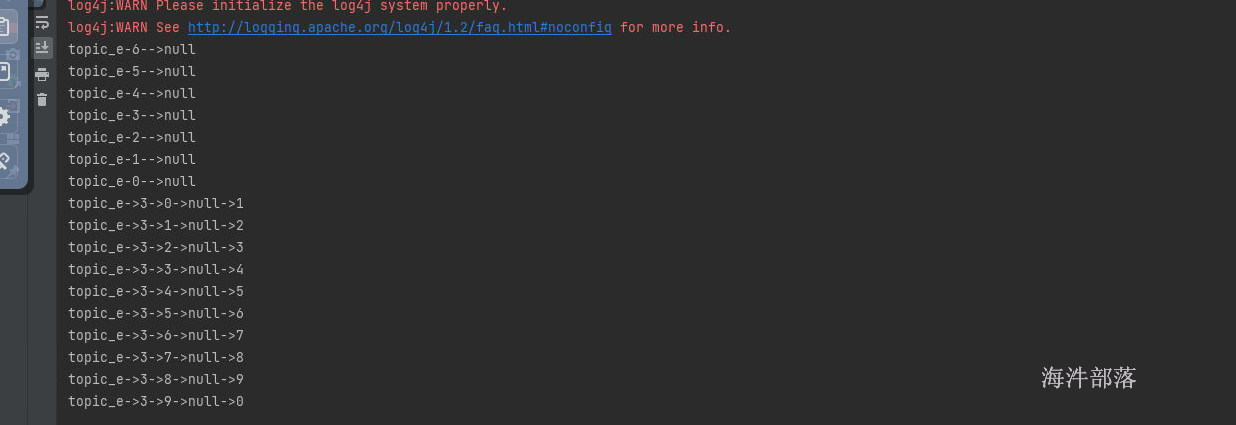
不用担心为空的数据,那些偏移量为空的分区也会被消费者消费到的
9.6 人为托管偏移量
以上关于偏移量的存储和使用问题我们都解决了
但是偏移量信息默认是存储在__consumer_offsets中的,有的时候我们需要进行偏移量的直观查看和管理,这个数据是没有办法做任何操作的,所以我们需要人为换介质存储和处理偏移量信息,这个时候我们会选择外部存储比如redis或者mysql等等存储偏移量信息
比如我们存储偏移量信息到redis中,那么首先我们需要准备环境
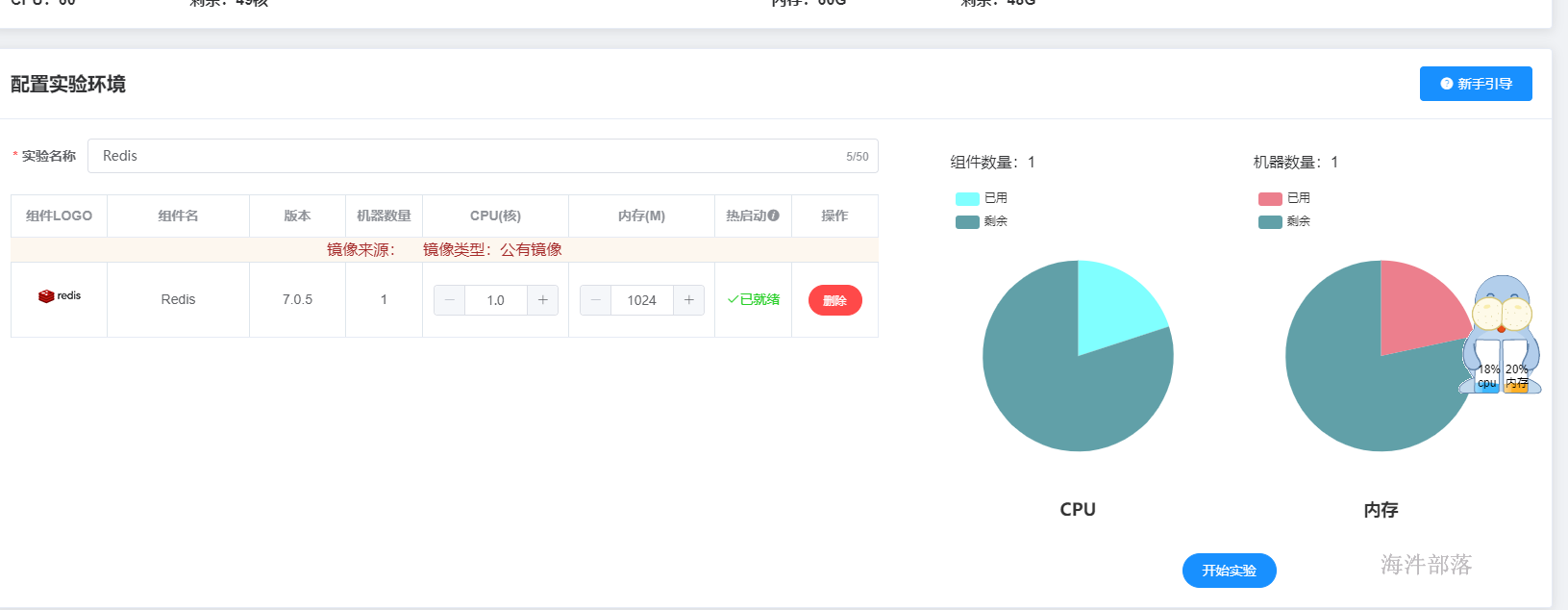
在海牛实验室中选择redis组件,进行启动
这个时候我们就拥有了一台redis服务器,非常的方便
然后在项目中增加依赖信息
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>整体思路:
- 不使用系统的偏移量提交和保存方式,都关闭掉
- 在ConsumerRebalanceListener监听方法中获取到相应的分区信息
- 一启动应用就去redis中查询对应的偏移量数据,然后从断点位置seek
- 下面消费数据的时候每次消费数据都要提交偏移量信息存储到redis进行更新
- redis的key设定为 [group-topic-partition] value值设定为[offsets]
整体代码如下:
package com.hainiu.kafka;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import redis.clients.jedis.Jedis;
import java.time.Duration;
import java.util.*;
public class ConsumerWithOffsets2Redis {
public static void main(String[] args) {
Properties pro = new Properties();
String groupId = "redis_group";
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,groupId);
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<String> topics = Arrays.asList("topic_e");
Jedis jedis = new Jedis("11.99.16.109");
consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// no op
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
for (TopicPartition partition : partitions) {
String topic = partition.topic();
int part = partition.partition();
String key = groupId+"_"+topic+"_"+part;
String offsetstr = jedis.get(key);
if(offsetstr != null){
consumer.seek(partition,Long.valueOf(offsetstr));
}
}
}
});
Map<String,Long> offsetMap = new HashMap<>();
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> it = records.iterator();
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());
String key = groupId+"_"+record.topic()+"_"+record.partition();
offsetMap.put(key,record.offset());
}
for (Map.Entry<String, Long> en : offsetMap.entrySet()) {
jedis.set(en.getKey(),en.getValue().toString());
}
}
}
}启动后在客户端给kafka中输入数据

代码控制台会打印数据
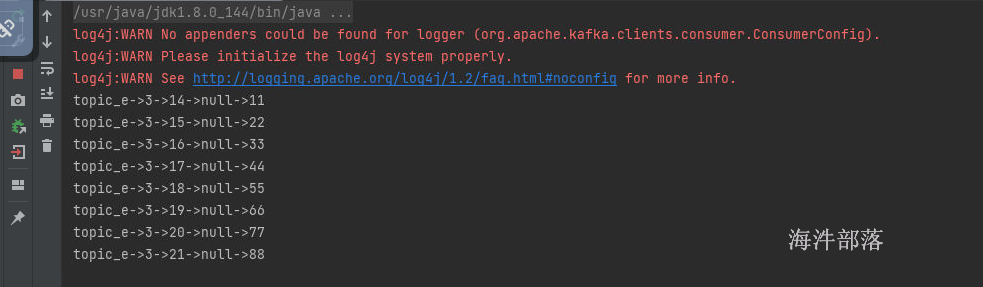
这个时候查看redis中的信息
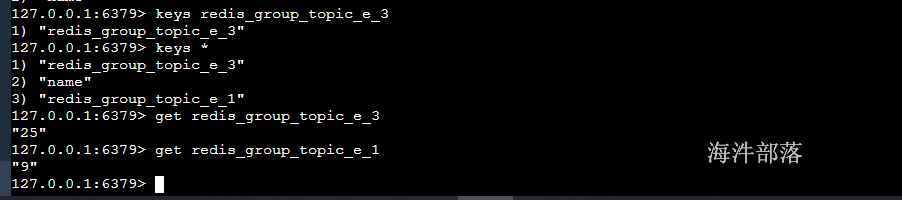
redis中可以查看到偏移量的信息
这个时候停止应用,然后重新启动
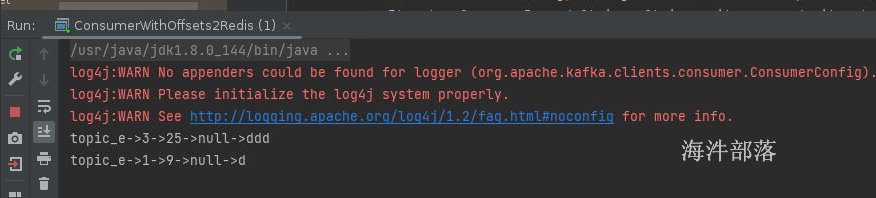
这个时候我们发现数据又出现了,这是因为我们存储的偏移量数据就是上一次的消费位置,所以还会从这个位置消费数据,这样会重复消费,所以我们需要在存储的时候偏移量+1 或者是寻址的时候偏移量+1

这个位置

或者这个位置
同样存储数据到mysql中
首先准备mysql环境
选择mysql进行试验的配置启动
# 创建mysql的数据库
mysql -uroot -phainiu
create database hainiu;
# 创建 mysql的表
create table my_offset(group_id varchar(20),topic varchar(20),`partition` int,offset bigint,primary key(group_id,topic,partition));整体代码如下
package com.hainiu.kafka;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import redis.clients.jedis.Jedis;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.time.Duration;
import java.util.*;
public class ConsumerWithMysql {
public static void main(String[] args) throws Exception{
String group_id = "group_redis";
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,group_id);
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
pro.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
pro.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,6000);
pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
//auto.offset.reset = latest
//enable.auto.commit = true
//interval = 5000
String url = "jdbc:mysql://11.87.38.45:3306";
String username = "root";
String password = "hainiu";
Connection connection = DriverManager.getConnection(url, username, password);
PreparedStatement selectPrp = connection.prepareStatement("select * from hainiu.my_offset where group_id = ? and topic = ? and `partition` = ?");
PreparedStatement insertPrp = connection.prepareStatement("replace into hainiu.my_offset(group_id,topic,`partition`,offset) values (?,?,?,?)");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);
List<String> topics = Arrays.asList("topic_e");
consumer.subscribe(topics, new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> collection) {
//no op
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> collection) {
for (TopicPartition tp : collection) {
String topic = tp.topic();
int partition = tp.partition();
try{
selectPrp.setString(1,group_id);
selectPrp.setString(2,topic);
selectPrp.setInt(3,partition);
ResultSet result = selectPrp.executeQuery();
while(result.next()){
long offset = result.getLong("offset");
consumer.seek(tp,offset+1);
}
selectPrp.clearParameters();
}catch (Exception e){
e.printStackTrace();
}
}
}
});
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Iterator<ConsumerRecord<String, String>> it = records.iterator();
Map<String,Long> offsetMap = new HashMap<>();
//topic-partition offset
while(it.hasNext()){
ConsumerRecord<String, String> record = it.next();
System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());
offsetMap.put(record.topic()+"-"+record.partition(),record.offset());
}
//insert redis k[group-topic-partition] v[offset]
for (Map.Entry<String, Long> en : offsetMap.entrySet()) {
String topicAndPartition = en.getKey();
Long offset = en.getValue();
String[] strs = topicAndPartition.split("-");
insertPrp.setString(1,group_id);
insertPrp.setString(2,strs[0]);
insertPrp.setInt(3,Integer.valueOf(strs[1]));
insertPrp.setLong(4,offset);
insertPrp.execute();
insertPrp.clearParameters();
}
}
}
}
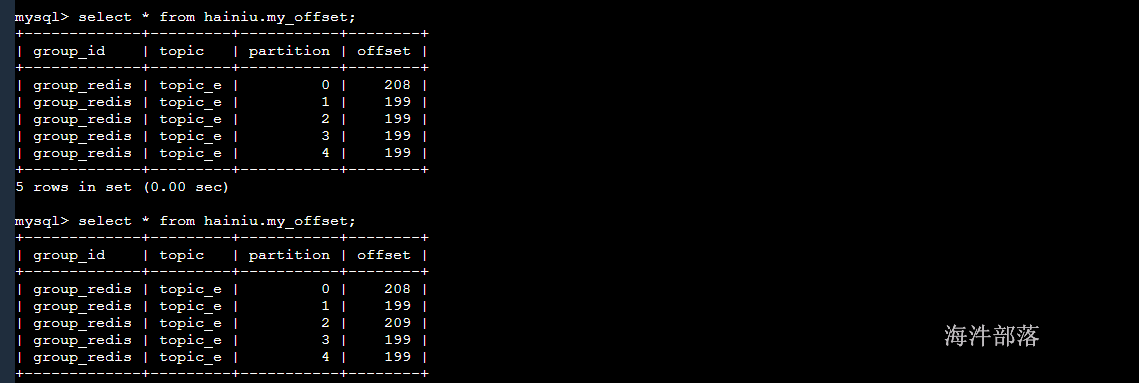
查看mysql


