kafka之producer
1.kafka的整体框架

首先kafka启动以后所有的broker都会向zookeeper进行注册,在/brokers/ids中以列表的形式展示所有的节点,在/controller节点中使用独享锁实现broker的选举,其中一个机器为主节点。其他的为从节点,选举的根本原则就是谁先来的谁就是主节点
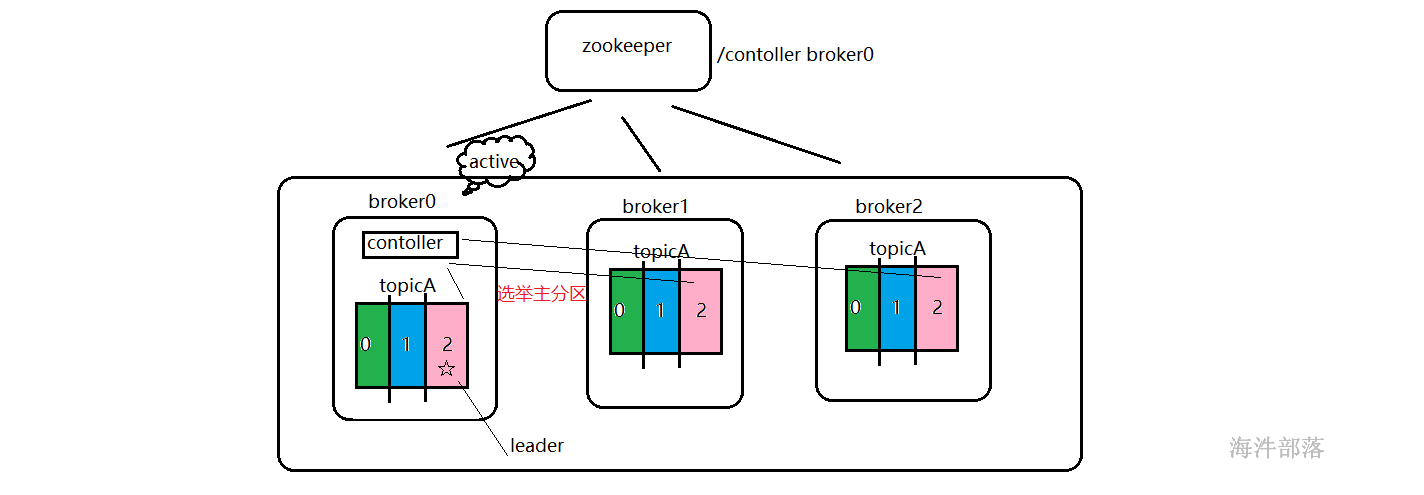
broker0现在是controller节点,他会监听所有的broker节点的动态变化,然后选举出来所有的topic的分区的主从,这个选举完毕以后,所有的操作都会指向主分区,不管是生产数据还是消费数据都是主分区在管理,从分区只是同步数据的
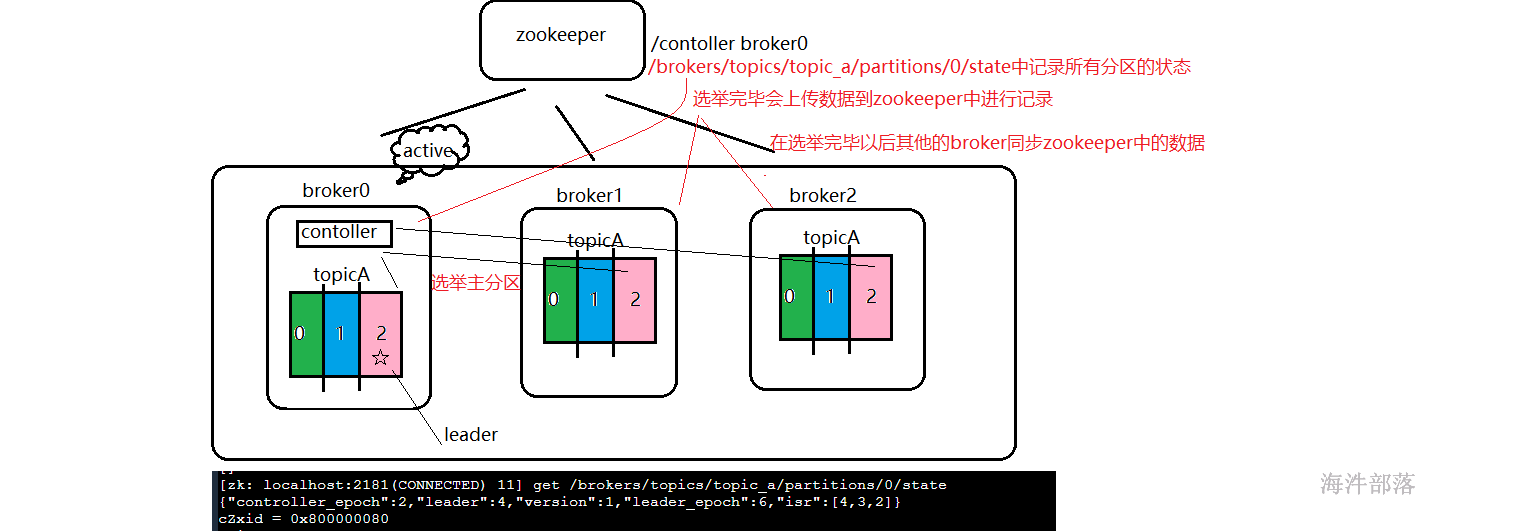
broker0选举完毕以后将数据上传到zookeeper中,记录在/broker/topics这个目录中,具体的topic信息都会被其他的broker节点进行同步过去,多个broker都会识别选举出来的主从分区信息
其中在zookeeper中的ISR它是数据的传递优先级别顺序,如上图中数据的传输应该先到leader节点所在的机器4上面然后数据在同步到其他的从分区中,从而所有的分区数据都同步完毕保持一致
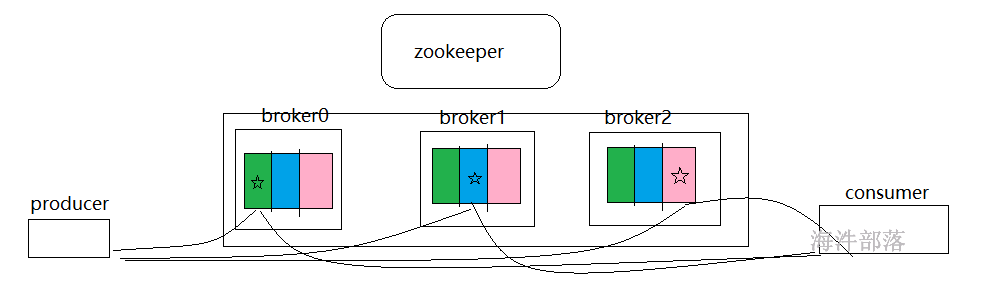
数据生产和传输都会走主节点,topic正常对外提供服务
2.kafka的基础数据结构
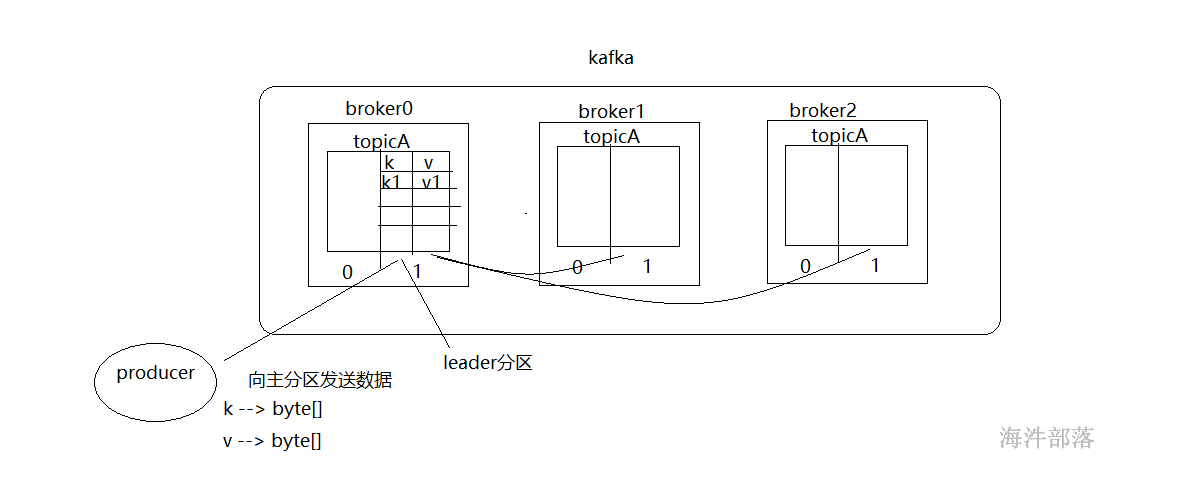
kafka中的数据存储分为两个部分,分别是k-v两个部分,并且存储的数据都是二进制的,我们在存储数据的时候要转换为二进制存储,使用的时候读出来也是二进制的,我们需要人为转换成自己想要的数据类型才能使用,这个和hbase的存储及其相似,但是其中的k一般我们都不会做任何操作,只放入value的值
注意,虽然数据分为k-v两个部分,但是不要把它当成map集合,相同的key的数据value不会被去重掉
3.producer的结构
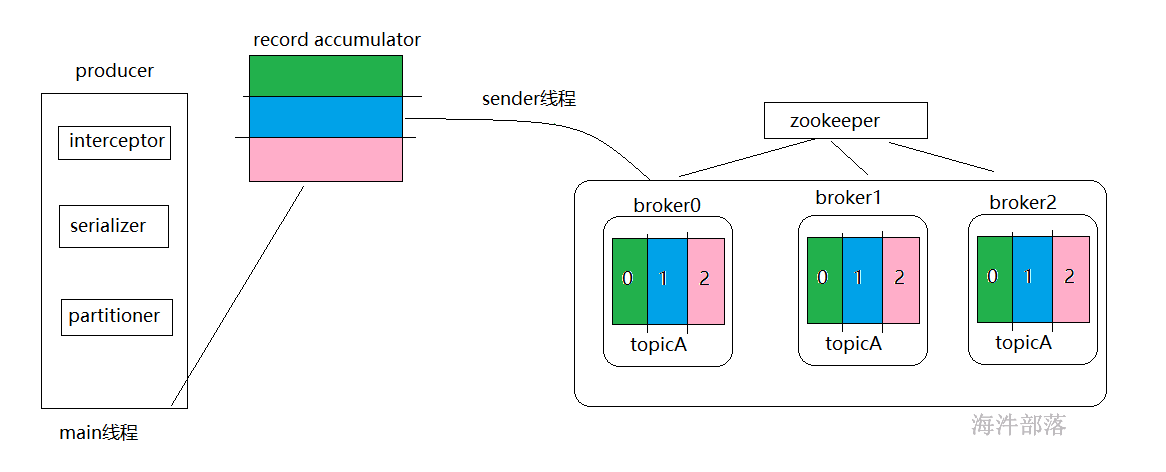
producer:生产者
它由三个部分组成
interceptor:拦截器,能拦截到数据,处理完毕以后发送给下游,它和过滤器不同并不是丢弃数据,而是将数据处理完毕再次发送出去,这个默认是不存在的
serialiazer:序列化器,kafka中存储的数据是二进制的,所以数据必须经过序列化器进行处理,这个是必须要有的,将用户的数据转换为byte[]的工具类,其中k和v要分别指定
partitioner: 分区器,主要是控制发送的数据到topic的哪个分区中,这个默认也是存在的
record accumulator
本地缓冲累加器 默认32M
producer的数据不能直接发送到kafka集群中,因为producer和kafka集群并不在一起,远程发送的数据不是一次发送一条这样太影响发送的速度和性能,所以我们发送都是攒一批数据发一次,record accumulator就是一个本地缓冲区,producer将发送的数据放入到缓冲区中,另外一个线程会去拉取其中的数据,远程发送给kafka集群,这个异步线程会根据linger.ms和batch-size进行拉取数据。如果本地累加器中的数据达到batch-size或者是linger.ms的大小阈值就会拉取数据到kafka集群中,这个本地缓冲区不仅仅可以适配两端的效率,还可以批次形式执行任务,增加效率
batch-size 默认16KB
linger.ms 默认为0
生产者部分的整体流程
首先producer将发送的数据准备好
经过interceptor的拦截器进行处理,如果有的话
然后经过序列化器进行转换为相应的byte[]
经过partitioner分区器分类在本地的record accumulator中缓冲
sender线程会自动根据linger.ms和batch-size双指标进行管控,复制数据到kafka
4.producer简单代码
使用producer的shell命令我们已经使用过
# 发送数据
kafka-console-producer.sh --bootstrap-server nn1:9092 --topic topicA现在我们要开发自己的producer端代码
首先在海牛实验室中准备好远程桌面
引入maven依赖
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>在resources文件中创建log4j.properties
log4j.rootLogger=info,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c %M(): %m%n生产者中的设定参数
| 参数 | 含义 |
|---|---|
| bootstrap.servers | kafka集群的地址 |
| key.serializer | key的序列化器,这个序列化器必须和key的类型匹配 |
| value.serializer | value的序列化器,这个序列化器必须和value的类型匹配 |
| batch.size | 批次拉取大小默认是16KB |
| linger.ms | 拉取的间隔时间默认为0,没有延迟 |
| partitioner | 分区器存在默认值 |
| interceptor | 拦截器选的 |
全部代码如下
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class Producer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
//设定集群地址
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//设定两个序列化器,其中StringSerializer是系统自带的序列化器,要和数据的类型完全一致
pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
//batch-size默认是16KB,参数的单位是byte
pro.put(ProducerConfig.LINGER_MS_CONFIG, 0);
//默认等待批次时长是0
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);
ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "this is hainiu");
//发送数据的时候有kv两个部分,但是一般k我们什么都不放,只放value的值
producer.send(record);
producer.close();
}
}在shell中消费topic_a的数据

5.producer端的回调和ack
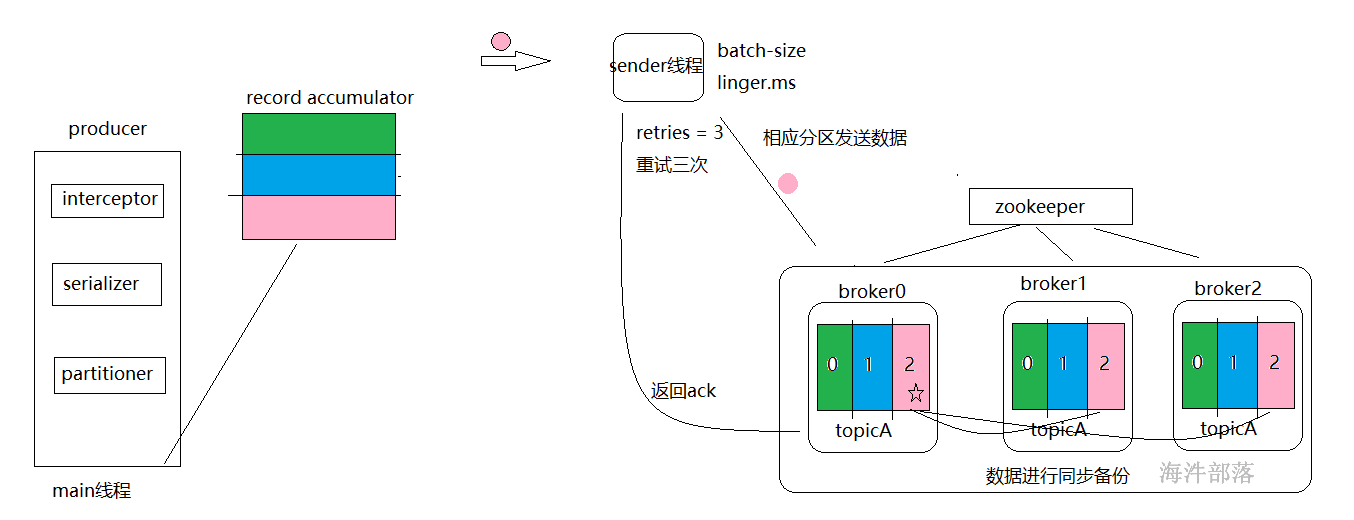
主线程将数据放入到本地累加器中record accumulator中进行存储,sender线程会异步的拉取数据到kafka集群中,这个数据拉取并且复制到kafka集群中以后,kafka需要返回给sender线程一个确认应答ack这个确认应答用于在sender线程中进行判定sender线程是否复制拉取数据成功,如果我们在producer中设定了retries开关,那么失败以后sender线程还会多次重新复制尝试拉取数据
其中失败尝试和producer端没有任何关系,producer端只是将数据放入到本地累加器中而已,失败尝试是由sender线程重新尝试的
ack的级别:
ack = 0 ;sender线程认为拉取过去的数据kafka一定会收到
ack = 1 ; sender线程拉取过去的数据leader节点接收到,并且存储到自己的本地,然后在返回ack
ack = -1 ; sender线程拉取数据,leader节点收到存储到本地,所有follower节点全部都接收到并且存储到本地这个时候leader返回ack
综上所述ack = -1的级别是数据稳定性最高的,因为能够保证数据全部都同步完毕再返回给sender线程
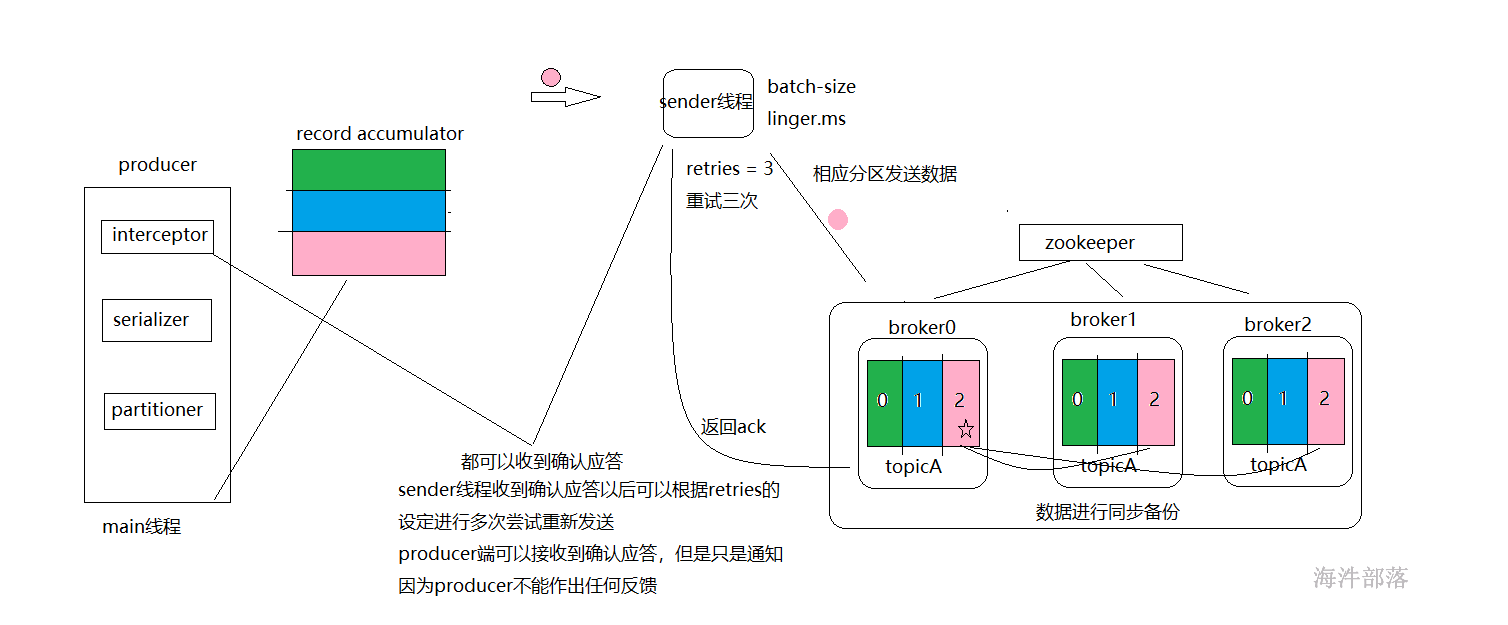
带有确认应答的代码:
其中回调函数中的metadata对象可以知道发送数据到哪里了,exception用于区分是不是本条数据发送成功
但是这个回调函数不能做出任何的反馈操作,只能起到通知的作用
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class ProducerWithCallBack {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.ACKS_CONFIG, "all");
//设定ack,在代码中ack的级别存在三种 0 1 all
pro.put(ProducerConfig.RETRIES_CONFIG,3 );
//设定重试次数
pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
pro.put(ProducerConfig.LINGER_MS_CONFIG, 0);
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);
ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "this is hainiu");
for(int i=0;i<5;i++){
producer.send(record, new Callback() {
//发送方法中增加回调代码
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
//metadata中包含所有的发送数据的元数据信息
//哪个topic的那个分区的第几个数据
String topic = metadata.topic();
int partition = metadata.partition();
long offset = metadata.offset();
if(exception == null ){
System.out.println("success"+" "+topic+" "+partition+" "+offset);
}else{
System.out.println("fail"+" "+topic+" "+partition+" "+offset);
}
}
});
}
producer.close();
}
}
6.自定义拦截器
interceptor是拦截器,可以拦截到发送到kafka中的数据进行二次处理,它是producer组成部分的第一个组件
public static class MyInterceptor implements ProducerInterceptor<String,String>{
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
return null;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}实现拦截器需要实现ProducerInterceptor这个接口,其中的泛型要和producer端发送的数据的类型一致
onSend方法是最主要的方法用户拦截数据并且处理完毕发送
onAcknowledgement 获取确认应答的方法,这个方法和producer端的差不多,只能知道结果通知
close是执行完毕拦截器最后执行的方法
configure方法是用于获取配置文件信息的方法
我们拦截器的实现基于场景是获取到producer端的数据然后给数据加上时间戳
整体代码如下:
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Date;
import java.util.Map;
import java.util.Properties;
public class ProducerWithInterceptor {
public static class MyInterceptor implements ProducerInterceptor<String,String>{
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
String value = record.value();
Long time = new Date().getTime();
String topic = record.topic();
//获取原始数据并且构建新的数据,增加时间戳信息
return new ProducerRecord<String,String>(topic,time+"-->"+value);
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
//获取确认应答和producer端的代码逻辑相同
String topic = metadata.topic();
int partition = metadata.partition();
long offset = metadata.offset();
if(exception == null ){
System.out.println("success"+" "+topic+" "+partition+" "+offset);
}else{
System.out.println("fail"+" "+topic+" "+partition+" "+offset);
}
}
@Override
public void close() {
//不需要任何操作
//no op
}
@Override
public void configure(Map<String, ?> configs) {
//不需要任何操作
//no op
}
}
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.ACKS_CONFIG, "all");
pro.put(ProducerConfig.RETRIES_CONFIG,3 );
pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
pro.put(ProducerConfig.LINGER_MS_CONFIG, 0);
pro.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,MyInterceptor.class.getName());
//设定拦截器
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);
ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "this is hainiu");
for(int i=0;i<5;i++){
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
String topic = metadata.topic();
int partition = metadata.partition();
long offset = metadata.offset();
if(exception == null ){
System.out.println("success"+" "+topic+" "+partition+" "+offset);
}else{
System.out.println("fail"+" "+topic+" "+partition+" "+offset);
}
}
});
}
producer.close();
}
}
在客户端消费者中可以打印出来信息带有时间戳
拦截器一般很少人为定义,比如一般producer在生产环境中都是有flume替代,一般flume会设定自己的时间戳拦截器,指定数据采集时间,相比producer更加方便实用
7.自定义序列化器
# 打印key
kafka-console.consumer.sh --property print.key=truekafka中的数据存储是二进制的byte数组形式,所以我们在存储数据的时候要使用序列化器进行数据的转换,序列化器的结构要和存储数据的kv的类型一致
比如我们要实现系统的String类型序列化器
整体代码如下
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.nio.charset.StandardCharsets;
import java.util.Map;
import java.util.Properties;
public class ProducerWithSerializer {
public static void main(String[] args) {
Properties pro = new Properties();
//bootstrap-server key value batch-size linger.ms ack retries interceptor
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,MyConfig.BOOTSTRAP_SERVERS);
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, MyStringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, MyStringSerializer.class.getName());
pro.put(ProducerConfig.BATCH_SIZE_CONFIG,MyConfig.BATCH_SIZE);
pro.put(ProducerConfig.LINGER_MS_CONFIG,MyConfig.LINGER_MS);
pro.put(ProducerConfig.ACKS_CONFIG,MyConfig.ACK);
pro.put(ProducerConfig.RETRIES_CONFIG,MyConfig.RETRIES);
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);
for (int i = 0; i < 100; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "hainiu","message_" + i);
producer.send(record);
}
producer.close();
}
public static class MyStringSerializer implements Serializer<String>{
@Override
public byte[] serialize(String topic, String data) {
return data.getBytes(StandardCharsets.UTF_8);
}
}
}
序列化对象整体
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.nio.charset.StandardCharsets;
import java.util.Properties;
/**
* producerRecord==> key:string,value:student
*/
public class ProducerWithStudentSerializer {
public static class Student implements Serializable{
private int id;
private String name;
private int age;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student() {
}
public Student(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
}
public static class MyStudentSerializer implements Serializer<Student>{
// ByteArrayOutputStream
// ObjectOutputStream
@Override
public byte[] serialize(String topic, Student data) {
ByteArrayOutputStream byteOS = null;
ObjectOutputStream objectOS = null;
try {
byteOS =new ByteArrayOutputStream();
objectOS = new ObjectOutputStream(byteOS);
objectOS.writeObject(data);
} catch (IOException e) {
throw new RuntimeException(e);
}finally {
try {
byteOS.close();
objectOS.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return byteOS.toByteArray();
}
}
public static void main(String[] args) {
Properties pro = new Properties();
//bootstrap-server key value batch-size linger.ms ack retries interceptor
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,MyConfig.BOOTSTRAP_SERVERS);
pro.put(ProducerConfig.BATCH_SIZE_CONFIG,MyConfig.BATCH_SIZE);
pro.put(ProducerConfig.LINGER_MS_CONFIG,MyConfig.LINGER_MS);
pro.put(ProducerConfig.ACKS_CONFIG,MyConfig.ACK);
pro.put(ProducerConfig.RETRIES_CONFIG,MyConfig.RETRIES);
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,MyStudentSerializer.class.getName());
KafkaProducer<String, Student> producer = new KafkaProducer<>(pro);
Student s1 = new Student(1, "zhangsan", 20);
Student s2 = new Student(2, "lisi", 30);
ProducerRecord<String, Student> r1 = new ProducerRecord<>("topic_a", "hainiu", s1);
ProducerRecord<String, Student> r2 = new ProducerRecord<>("topic_a", "hainiu", s2);
producer.send(r1);
producer.send(r2);
producer.close();
}
}
比如我们想要发送一个Student对象,其中包含id name age等字段,这个数据需要对应的序列化器
序列化器的实现需要指定类型并且实现
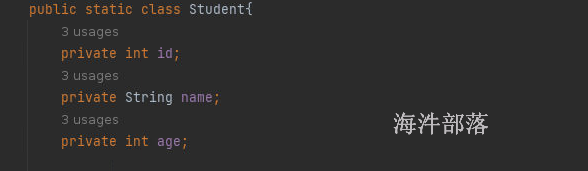
自定义的类
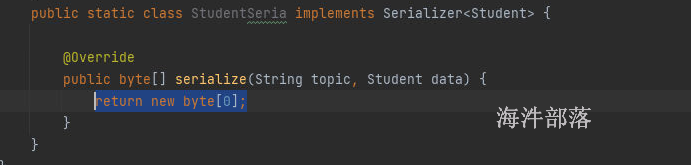
需要实现serializer接口,并且实现serialize的方法用于将数据对象转换为二进制的数组
整体代码如下:
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.nio.charset.Charset;
import java.util.Properties;
public class Producer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//key因为没有放入任何值,所以序列化器使用原生的就可以
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StudentSeria.class.getName());
//value的序列化器需要指定相应的student序列化器
pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
pro.put(ProducerConfig.LINGER_MS_CONFIG, 0);
KafkaProducer<String, Student> producer = new KafkaProducer<String, Student>(pro);
//producer生产的数据类型也必须是string,student类型的kv
Student student = new Student(1, "zhangsan", 30);
ProducerRecord<String, Student> record = new ProducerRecord<>("topic_a", student);
producer.send(record);
producer.close();
}
public static class Student{
private int id;
private String name;
private int age;
public int getId() {
return id;
}
public Student() {
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
}
public static class StudentSeria implements Serializer<Student> {
@Override
public byte[] serialize(String topic, Student data) {
String line =data.getId()+" "+data.getName()+" "+data.getAge();
//获取student对象中的所有数据信息
return line.getBytes(Charset.forName("utf-8"));
//转换为byte数组返回
}
}
}
shell消费者端打印的结果信息
8.分区器
首先在kafka存储数据的时候topic中的数据是分为多个分区进行存储的,topic设定分区的好处是可以进行分布式存储和分布式管理,那么好的分区器可以让数据尽量均匀的分布到不同的机器节点,数据更加均匀,那么kafka中的分区器是如果实现的呢?
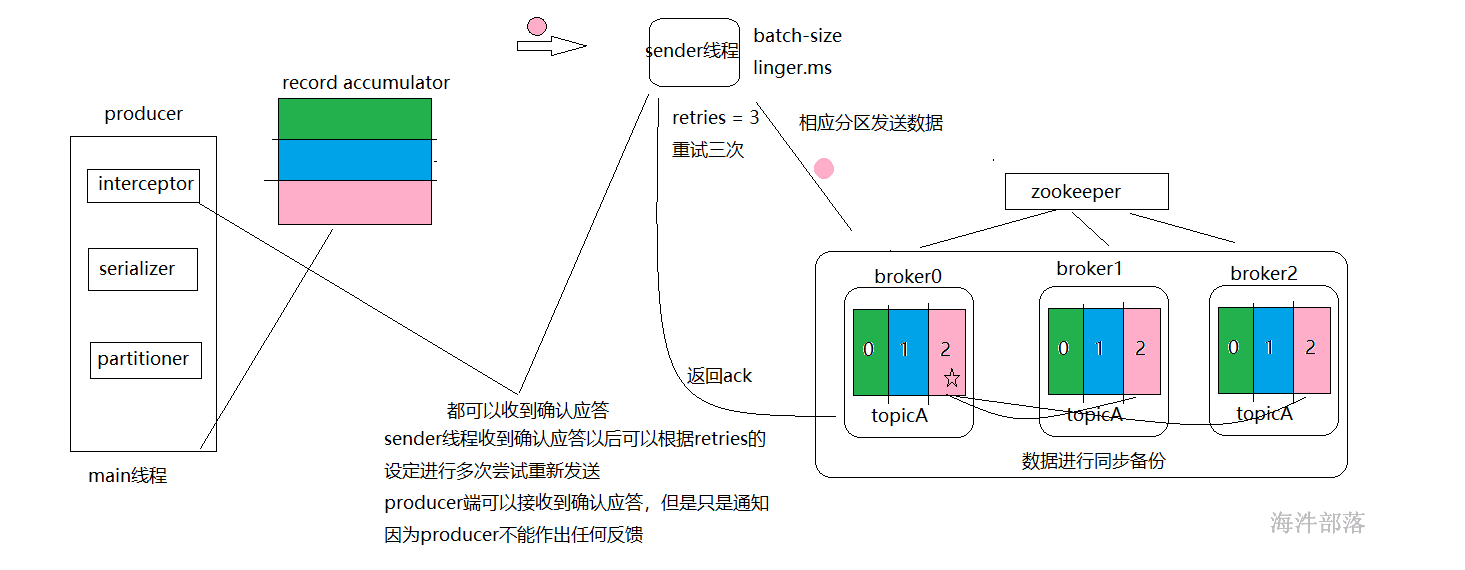
根据图我们可以看出数据首先通过分区器进行分类,在本地的累加器中进行存储缓存,然后在复制到kafka集群中,所以分区器产生作用的位置在本地的缓存之前
kafka的分区规则是如何实现的呢?
ProducerRecord<String, Student> record = new ProducerRecord<>("topic_a", student);
producer.send(record);kafka的生产者数据发送是通过上面的方法实现的
首先要构造一个ProducerRecord对象,然后通过producer.send来进行发送数据
其中ProducerRecord对象的构造器种类分为以下几种
/**
* Creates a record to be sent to a specified topic and partition
*
* @param topic The topic the record will be appended to
* @param partition The partition to which the record should be sent
* @param key The key that will be included in the record
* @param value The record contents
*/
public ProducerRecord(String topic, Integer partition, K key, V value) {
this(topic, partition, null, key, value, null);
}
/**
* Create a record to be sent to Kafka
*
* @param topic The topic the record will be appended to
* @param key The key that will be included in the record
* @param value The record contents
*/
public ProducerRecord(String topic, K key, V value) {
this(topic, null, null, key, value, null);
}
/**
* Create a record with no key
*
* @param topic The topic this record should be sent to
* @param value The record contents
*/
public ProducerRecord(String topic, V value) {
this(topic, null, null, null, value, null);
}我们想要发送一个数据到kafka的时候可以构造以上的ProducerRecord但是构造的方式却不同,大家可以发现携带的参数也有所不同,当携带不同参数的时候数据会以什么样的策略发送出去呢,这个时候需要引入一个默认分区器,就是在用户没有指定任何规则的时候系统自带的分区器规则
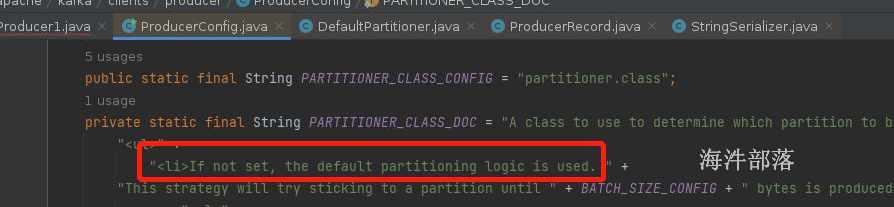
在producerConfig对象中我们可以看到源码指示,如果没有任何人为分区器规则指定,那么默认使用的DefaultPartitioner的规则
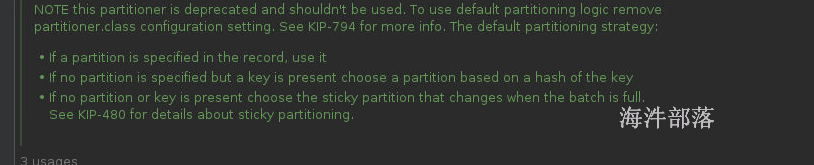
而打开DefaultPartitioner以后可以看到他的分区器规则,就是在构建ProducerRecord的时候
new ProducerRecord(topic,partition,k,v);
//指定分区直接发送数据到相应分区中
new ProducerRecord(topic,k,v);
//没有指定分区就按照k的hashcode发送到不同分区
new ProducerRecord(topic,v);
//如果k和partition都没有指定就使用粘性分区这个逻辑可以在DefaultPartitioner中看到
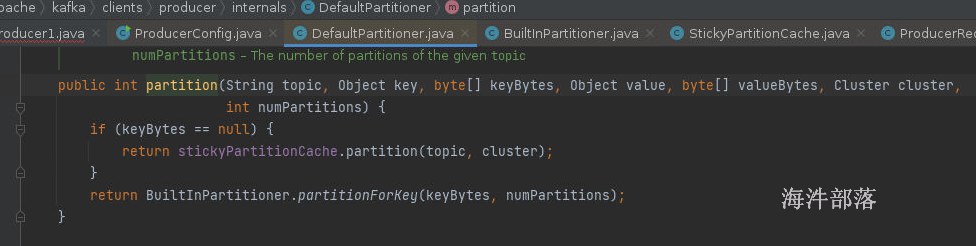
partition方法中,如果key为空就放入到粘性缓冲中,它的意思就是如果满足batch-size或者linger.ms就会触发应用执行,将数据复制到kafka中,并且再次随机到其他分区,所以简单来说粘性分区就是可一个分区放入数据,一旦满了以后才会改变分区,粘性分区规则使用主要是为了让每次复制数据更加快捷方便都赋值到一个分区中
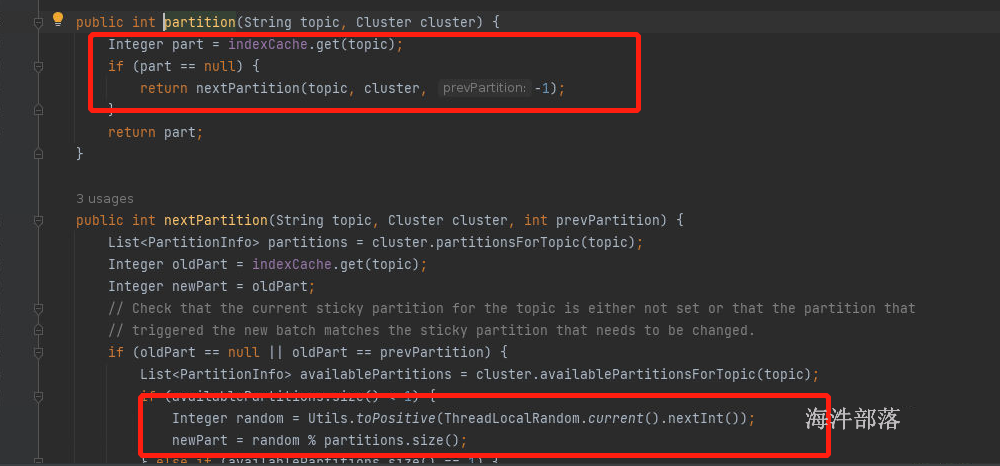
而如果key不为空那么就按照hashcode值进行取余处理

以上就是kafka的分区策略
我们也可以认为设定自己的分区器规则来替换kafka的分区器
下面我们对于默认分区器最验证
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.nio.charset.Charset;
import java.util.Properties;
public class Producer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
pro.put(ProducerConfig.LINGER_MS_CONFIG, 0);
KafkaProducer<String, String> producer = new KafkaProducer<>(pro);
ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", 0, null, "aaaa");
//创建对象指定分区
producer.send(record);
producer.close();
}
}
指定分区0进行消费数据,可以得到数据相应位置
System.out.println(Utils.toPositive(Utils.murmur2("111".getBytes()))); 不指定分区,携带key 111的hashcode值274292042,使用这个值和分区数4取余得出相应的分区编号为2
整体代码如下:
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.apache.kafka.common.utils.Utils;
import java.nio.charset.Charset;
import java.util.Properties;
public class Producer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
pro.put(ProducerConfig.LINGER_MS_CONFIG, 0);
KafkaProducer<String, String> producer = new KafkaProducer<>(pro);
ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "111", "111");
producer.send(record);
producer.close();
}
}
可以看出数据的计算是没有问题的,按照k的hashcode值进行分发
没有增加partition和key的时候会按照粘性分区规则进行分配
整体代码如下:
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.apache.kafka.common.utils.Utils;
import java.nio.charset.Charset;
import java.util.Properties;
public class Producer1 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
pro.put(ProducerConfig.LINGER_MS_CONFIG, 0);
KafkaProducer<String, String> producer = new KafkaProducer<>(pro);
for (int i = 0; i < 5; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "hahahaha");
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
String topic = metadata.topic();
int partition = metadata.partition();
System.out.println(topic+"-->"+partition);
}
});
}
producer.close();
}
}
我们没有指定任何分区和key,默认分区器会自动随机一个分区。然后数据以粘性的方式分发到不同的分区中
9.自定义分区器
以上规则的演示全部都是按照默认分区器的规则DefaultPartitioner
我们可以人为定义分区器的规则来替换原生分区器的规则,因为在很多时候默认分区器的规则都不适用于业务场景
程序背景:
使用producer采集本地数据并且发送到不同的分区中,按照每个专业的类别将数据分发到不同的分区
# 首先创建topic名称为teacher,设定分区数量为spark和java两个分区
kafka-topics.sh --bootstrap-server nn1:9092 --create --topic teacher --partitions 6 --replication-factor 2
# 创建一个data/teacher.txt 放入老师的访问数据,然后分类发送
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang实现思路就是采集数据然后将数据按照专业分类,分别发送到不同的分区中,自定分区器逻辑
public static class MyPartitioner implements Partitioner{
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}自定义分区器要实现Partitioner接口
其中Partition方法是最重要的方法,可以根据不同的数据发送到不同的分区
close方法是关闭时候执行的方法一般不做任何操作
configure方法是获取配置文件的方法,一般也不做任何操作
思路就是在partition方法中得到value值中是否包含spark或者java,然后分类发送
整体代码如下:
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.serialization.StringSerializer;
import org.apache.kafka.common.utils.Utils;
import java.io.FileInputStream;
import java.net.URL;
import java.util.*;
public class ProducerWithUDPartitioner {
public static class MyTeacherPartitioner implements Partitioner{
List<String> list = Arrays.asList(
"unclewang",
"xiaohe",
"laoyang",
"laochen",
"laoliu",
"laozhang"
);
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String valueStr = value.toString();
return list.indexOf(valueStr);
}
@Override
public void close() {
//no - op
}
@Override
public void configure(Map<String, ?> configs) {
// no - op
}
}
public static void main(String[] args) throws Exception{
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,MyTeacherPartitioner.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);
FileInputStream in = new FileInputStream("data/teacher.txt");
Scanner sc = new Scanner(in);
while(sc.hasNext()){
String line = sc.nextLine();
URL url = new URL(line);
String host = url.getHost();
String path = url.getPath();
String subject = host.split("\\.")[0];
String teacher = path.substring(1);
ProducerRecord<String, String> record = new ProducerRecord<>("teacher", subject, teacher);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null){
System.out.println(metadata.topic()+"-->"+metadata.partition()+"-->"+record.key()+"-->"+record.value());
}else{
System.out.println("fail");
}
}
});
}
producer.close();
}
}
数据已经按照规则进行分类
10.kafka的ack和一致性
上文中我们提到过kafka是存在确认应答机制的,也就是数据在发送到kafka的时候,kafka会回复一个确认信息,这个确认信息是存在等级的
ack=0 这个等级是最低的,这个级别中数据sender线程复制完毕数据默认人为kafka已经接收到数据
ack=1 这个级别中,sender线程复制完毕数据leader分区拿到数据放入到自己的存储并且返回确认信息
ack= -1 这个级别比较重要,sender线程复制完毕数据,主分区接受完毕数据并且从分区都同步完毕数据然后在返回确认信息
那么以上的等级在使用的时候都会出现什么问题呢?
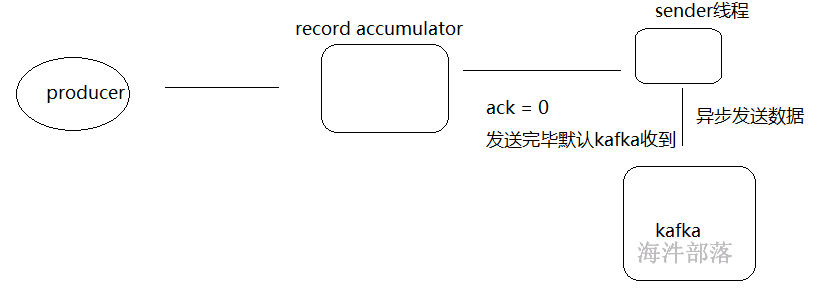
ack = 0 会丢失数据
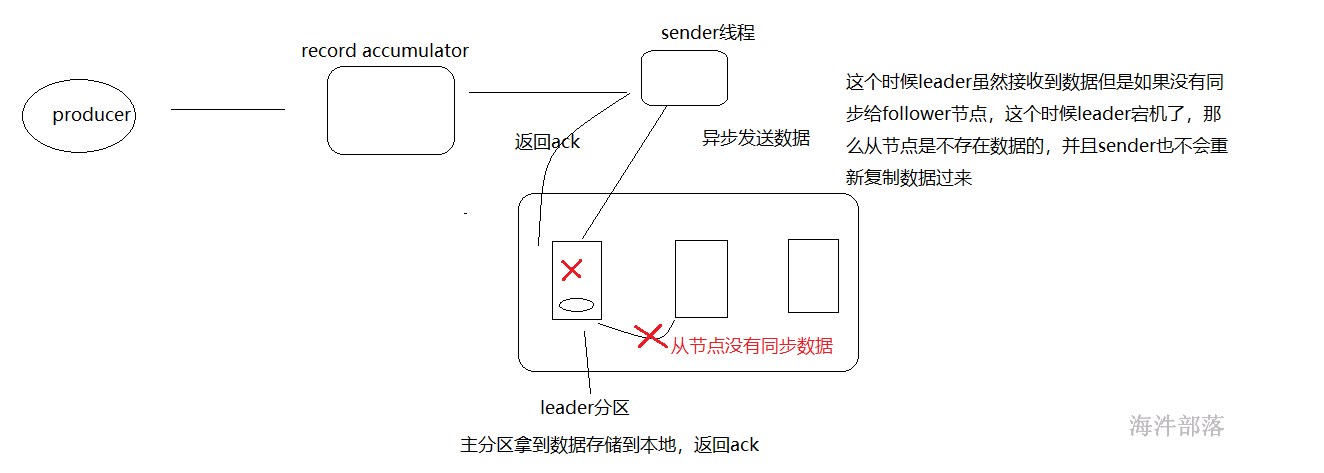
ack=1的时候leader虽然接收到数据存储到本地,但是没有同步给follower节点,这个时候主节点宕机,从节点重新选举新的主节点,主节点是不含有这个数据的,数据会丢失
ack = -1
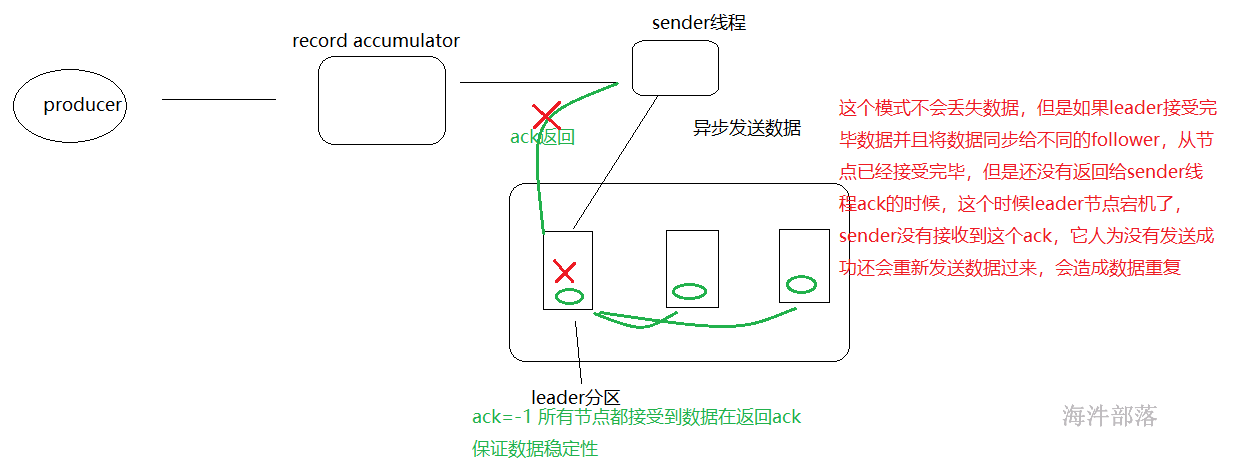
这个模式不会丢失数据,但是如果leader接受完毕数据并且将数据同步给不同的follower,从节点已经接受完毕,但是还没有返回给sender线程ack的时候,这个时候leader节点宕机了,sender没有接收到这个ack,它人为没有发送成功还会重新发送数据过来,会造成数据重复
一般前两种都适合在数据并不是特别重要的时候使用,而最后一种效率会比较低下,但是适用于可靠性比较高的场景使用
所以一般使用我们都会使用ack = -1 retries = N 联合在一起使用
那么我们如何能够保证数据的一致性呢?
幂等性
在kafka的0.10以后的版本中增加了新的特性,幂等性,主要就是为了解决kafka的ack = -1的时候,数据的重复问题,设计的原理就是在kafka中增加一个事物编号
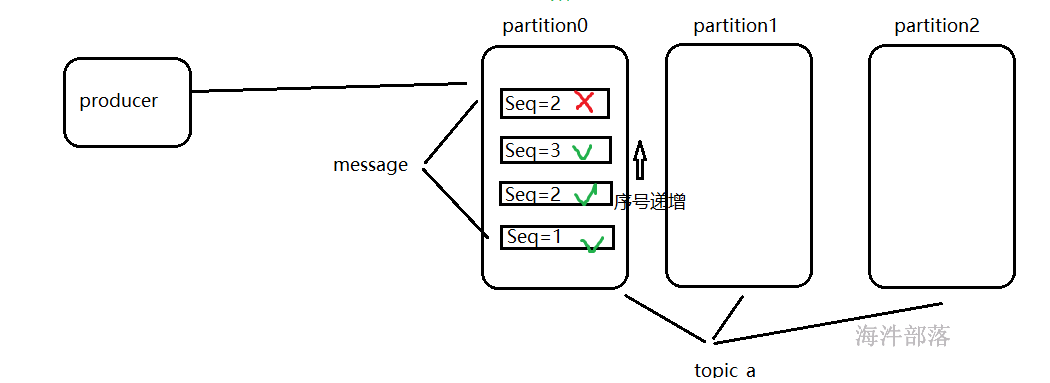
数据在发送的时候在单个分区中的seq事物编号是递增的,如果重复的在一个分区中多次插入编号一致的两个信息,那么这个数据会被去重掉
在单个分区中序号递增,也就是我们开启幂等性也只能保证单个分区的数据是可以去重的
整体代码如下:
pro.put(ProducerConfig.RETRIES_CONFIG,3);
pro.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,true);设定retries = 3 ,enable.idempotence = true
幂等性开启的时候,ack默认设定为-1
幂等性的工作原理很简单,每条消息都有一个「主键」,这个主键由 <PID, Partition, SeqNumber> 组成,他们分别是:
- PID:ProducerID,每个生产者启动时,Kafka 都会给它分配一个 ID,ProducerID 是生产者的唯一标识,需要注意的是,Kafka 重启也会重新分配 PID
- Partition:消息需要发往的分区号
- SeqNumber:生产者,他会记录自己所发送的消息,给他们分配一个自增的 ID,这个 ID 就是 SeqNumber,是该消息的唯一标识
对于主键相同的数据,Kafka 是不会重复持久化的,它只会接收一条,但由于是原理的限制,幂等性也只能保证单分区、单会话内的数据不重复,如果 Kafka 挂掉,重新给生产者分配了 PID,还是有可能产生重复的数据,这就需要另一个特性来保证了 ——Kafka 事务。
11.kafka 事务原理
Kafka 事务基于幂等性实现,通过事务机制,Kafka 可以实现对多个 Topic 、多个 Partition 的原子性的写入,即处于同一个事务内的所有消息,最终结果是要么全部写成功,要么全部写失败。
Kafka 事务分为生产者事务和消费者事务,但它们并不是强绑定的关系,消费者主要依赖自身对事务进行控制,因此这里我们主要讨论的是生产者事务。
1. 如何开启事务?
创建一个 Producer,指定一个事务 ID:
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//设置事务ID,必须
properties.setProperty(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transactional_id_1");
//创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);使用事务发送消息:
// 初始化事务
producer.initTransactions();
// 开启事务
producer.beginTransaction();
//发送10条消息往kafka,假如中间有异常,所有消息都会发送失败
try {
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<>("topic-test", "a message" + i));
}
}
// 提交事务
producer.commitTransaction();
} catch (Exception e) {
// 终止事务
producer.abortTransaction();
} finally {
producer.close();
}2. 事务工作原理
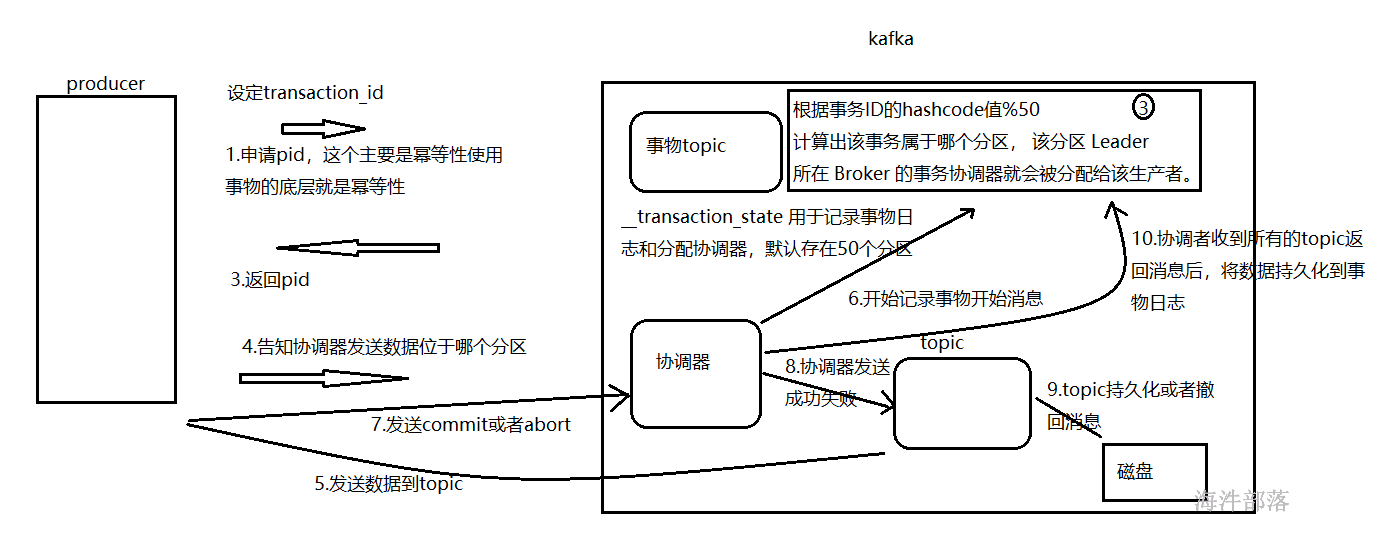
1)启动生产者,分配协调器
在使用事务的时候,必须给生产者指定一个事务 ID,生产者启动时,Kafka 会根据事务 ID 来分配一个事务协调器(Transaction Coordinator) 。每个 Broker 都有一个事务协调器,负责分配 PID(Producer ID) 和管理事务。
事务协调器的分配涉及到一个特殊的主题 __transaction_state,该主题默认有 50 个分区,每个分区负责一部分事务;Kafka 根据事务ID的hashcode值%50 计算出该事务属于哪个分区, 该分区 Leader 所在 Broker 的事务协调器就会被分配给该生产者。
分配完事务协调器后,该事务协调器会给生产者分配一个 PID,接下来生产者就可以准备发送消息了。
2)发送消息
生产者分配到 PID 后,要先告诉事务协调器要把消息发往哪些分区,协调器会做一个记录,然后生产者就可以开始发送消息了,这些消息与普通的消息不同,它们带着一个字段标识自己是事务消息。
当生产者事务内的消息发送完毕,会向事务协调器发送 Commit 或 Abort 请求,此时生产者的工作已经做完了,它只需要等待 Kafka 的响应。
3)确认事务
当生产者开始发送消息时,协调器判定事务开始。它会将开始的信息持久化到主题 __transaction_state 中。
当生产者发送完事务内的消息,或者遇到异常发送失败,协调器会收到 Commit 或 Abort 请求,接着事务协调器会跟所有主题通信,告诉它们事务是成功还是失败的。
如果是成功,主题会汇报自己已经收到消息,协调者收到所有主题的回应便确认了事务完成,并持久化这一结果。
如果是失败的,主题会把这个事务内的消息丢弃,并汇报给协调者,协调者收到所有结果后再持久化这一信息,事务结束;整个放弃事务的过程消费者是无感知的,它并不会收到这些数据。
事物不仅可以保证多个数据整体成功失败,还可以保证数据丢失后恢复
3.代码实现
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class ProducerWithTransaction {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"transaciton_test");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);
ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "this is hainiu");
producer.initTransactions();
producer.beginTransaction();
try{
for(int i=0;i<5;i++){
producer.send(record);
}
// int a = 1/0;
producer.commitTransaction();
}catch (Exception e){
producer.abortTransaction();
}finally {
producer.close();
}
}
}使用int a = 1/0;手动抛出异常信息
如果出现异常那么数据不会出现
异常关闭会一次性出现五条结果

12.一致性语义
在大数据场景中存在三种时间语义,分别为
At Least Once 至少一次,数据至少一次,可能会重复
At Most Once 至多一次,数据至多一次,可能会丢失
Exactly Once 精准一次,有且只有一次,准确的消息传输
那么针对于以上我们学习了ack已经幂等性以及事物
所以我们做以下分析:
如果设定ack = 0 或者是 1 出现的语义就是At Most Once 会丢失数据
如果设定ack = - 1 会出现At Least Once 数据的重复
在ack = -1的基础上开启幂等性会解决掉数据重复问题,但是不能保证一个批次的数据整体一致,所以还要开启事物才可以
13.参数调节
| 参数 | 调节 |
|---|---|
| buffer.memory | record accumulator的大小,适当增加可以保证producer的速度,默认32M |
| batch-size | 异步线程拉取的批次大小,适当增加可以提高效率,但是会增加延迟性 |
| linger.ms | 异步线程等待时长一般根据生产效率而定,不建议太大增加延迟效果 |
| acks | 确认应答一般设定为-1,保证数据不丢失 |
| enable.idempotence | 开启幂等性保证数据去重,实现exactly once语义 |
| retries | 增加重试次数,保证数据的稳定性 |
| compression.type | 增加producer端的压缩 |
| max.in.flight.requests.per.connection | sender线程异步复制数据的阻塞次数,当没收到kafka的ack之前可以最多发送五个写入请求,调节这个参数可以保证数据的有序性 |
全部代码如下:
package com.hainiu.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class ProducerWithMultiConfig {
public static void main(String[] args) throws InterruptedException {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
pro.put(ProducerConfig.LINGER_MS_CONFIG, 100);
pro.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 1024*1024*64);
pro.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
pro.put(ProducerConfig.RETRIES_CONFIG, 3);
pro.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
pro.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 5);
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);
ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "this is hainiu");
producer.send(record);
producer.close();
}
}其中max.in.flight.requests.per.connection参数设定后可以增加producer的阻塞大小
在未开启幂等性的时候,这个值设定为1,可以保证单个批次的数据有序,在分区内部有序
如果开启了幂等性可以设定最大值不超过5,可以保证五个request请求单个分区内有序

因为没有开启幂等性的时候如果第一个请求失败,第二个请求重新发送的时候需要二次排序
要是开启幂等性了会保留原来的顺序性,不需要重新排序
总而言之kafka可以保证单分区有序但是整体是无序的

