Spark的背景以及安装和部署
1.1 Spark产生的背景
MapReduce的局限性:
1)仅支持Map 和 Reduce 两种操作;
2)MapReduce多个任务的中间结果落地磁盘,不能充分利用内存,任务运行效率低;
3)适合批处理,不适合实时性要求高的场景;
4)程序编写过于复杂;
5)资源不能复用,每次需要重新发分配资源
1.2 什么是Spark
Spark,是一种通用的大数据计算框架,正如传统大数据技术Hadoop的MapReduce、Hive引擎,以及flink流式实时计算引擎等。
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架,用于构建大型的、低延迟的数据分析应用程序。
Spark使用强大的Scala语言开发,它还提供了对Scala、Python、Java(支持Java 8)和R语言的支持。
Apache顶级项目,项目主页:http://spark.apache.org
1.3 Spark历史
2009年由Berkeley’s AMPLab开始编写最初的源代码
2010年开放源代码
2013年6月进入Apache孵化器项目
2014年2月成为Apache的顶级项目(8个月时间)
2014年5月底Spark1.0.0发布,打破Hadoop保持的基准排序纪录
2014年12月Spark1.2.0发布
2015年11月Spark1.5.2发布
2016年1月Spark1.6发布
2016年12月Spark2.1发布
1.4 为什么要用Spark
运行速度快:
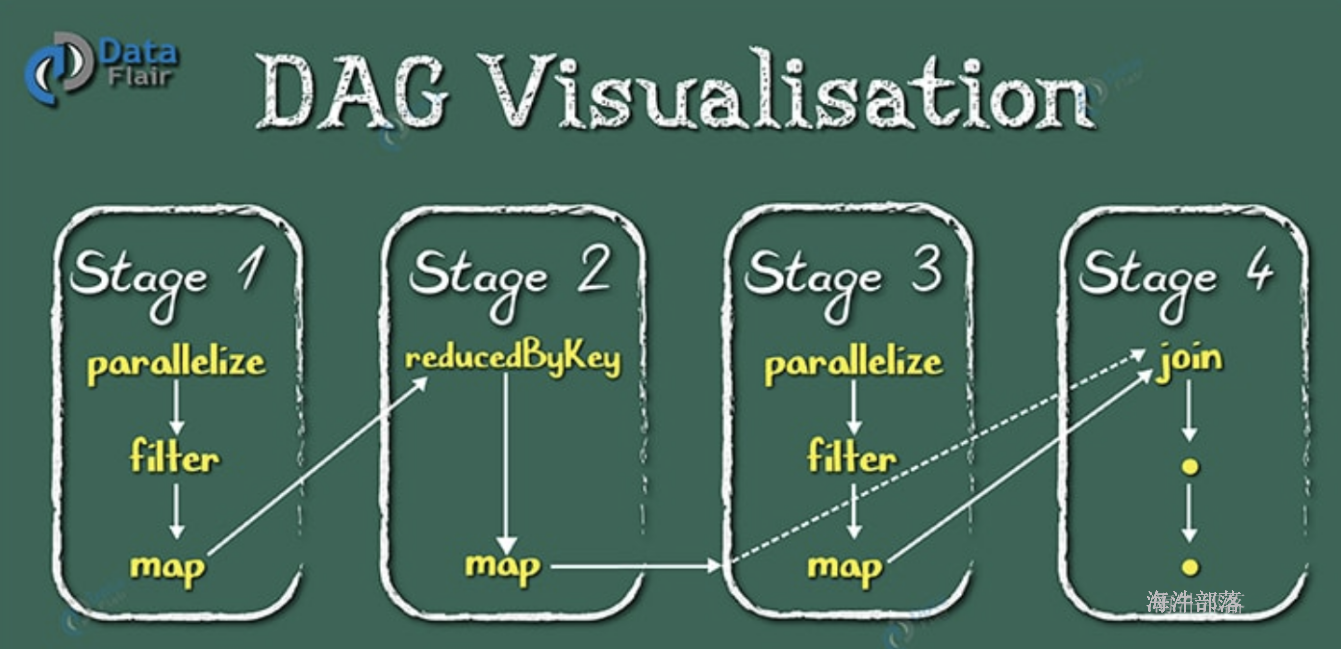
使用DAG(全称 Directed Acyclic Graph, 中文为:有向无环图)执行引擎以支持循环数据流与内存计算(当然也有部分计算基于磁盘,比如shuffle);
易用性好:
支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程 ;
通用性强:
Spark提供了完整而强大的工具,包括SQL查询、流式计算、机器学习和图算法组件;
随处运行:
可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源;
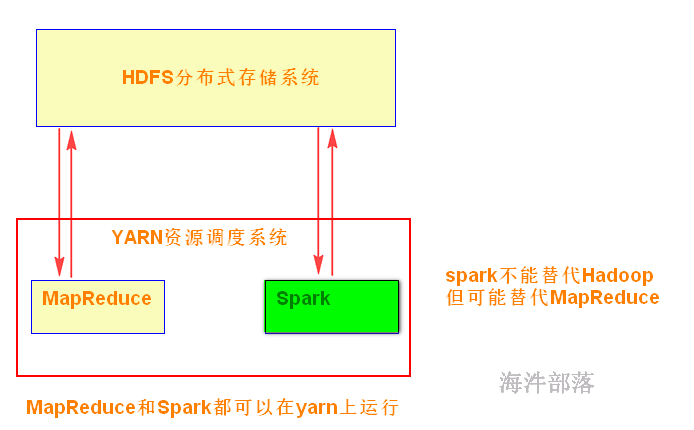
Hadoop:
可以用普通硬件搭建Hadoop集群,用于解决存储和计算问题;
1)解决存储:HDFS
2)解决计算:MapReduce
3)资源管理:YARN
Spark:
Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷;
Spark不能代替Hadoop,但可能代替MapReduce。
现状:
Spark主要用于大数据的计算,而Hadoop以后主要用于大数据的存储(HDFS),以及资源调度(Yarn)。Spark+Hadoop的组合,是未来大据领域最热门的组合,也是最有前景的组合! 当然spark也有自己的集群模式。
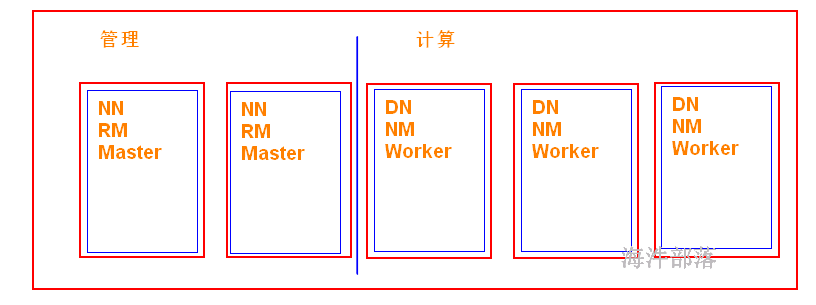
通过yarn队列去管理mr 和 spark任务的资源。
1.6 Spark 对比 MapReduce
1)spark可以把多次使用的数据放到内存中
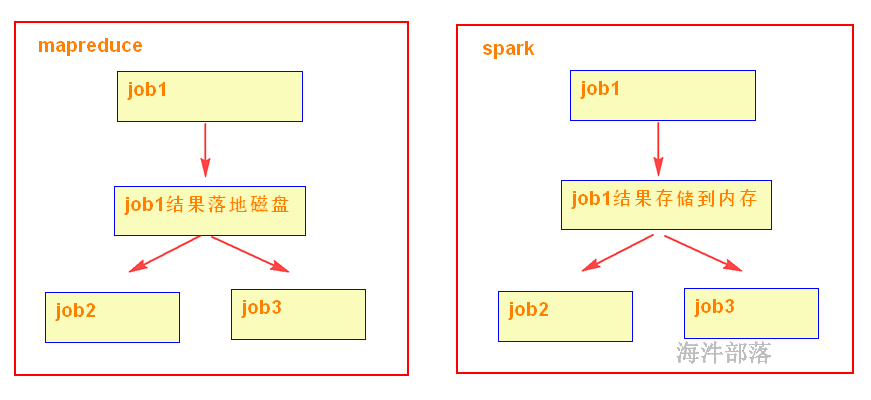
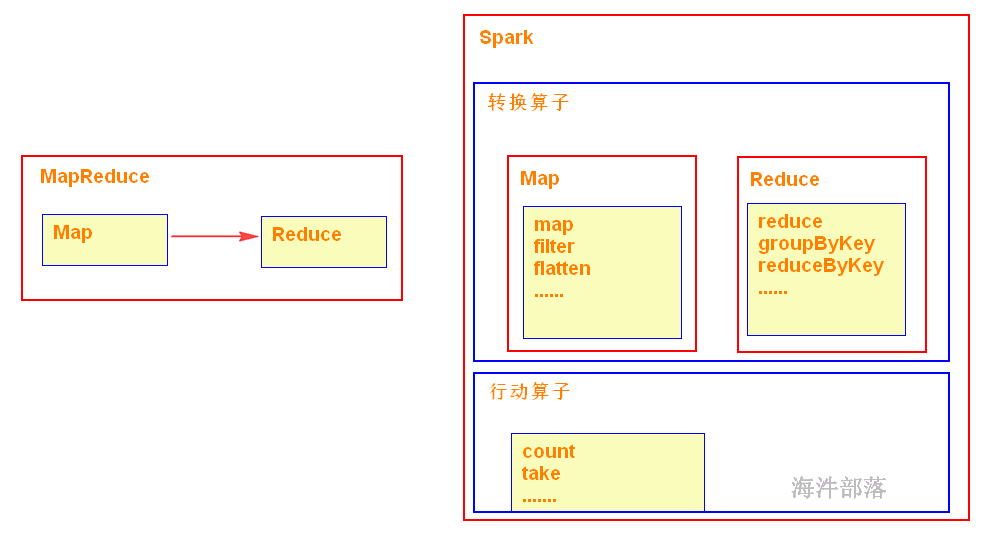
4)在代码编写方面,不需要写那么复杂的MapReduce逻辑。
缺点:
过度依赖内存,内存不够用了就很难堪

2 spark生态
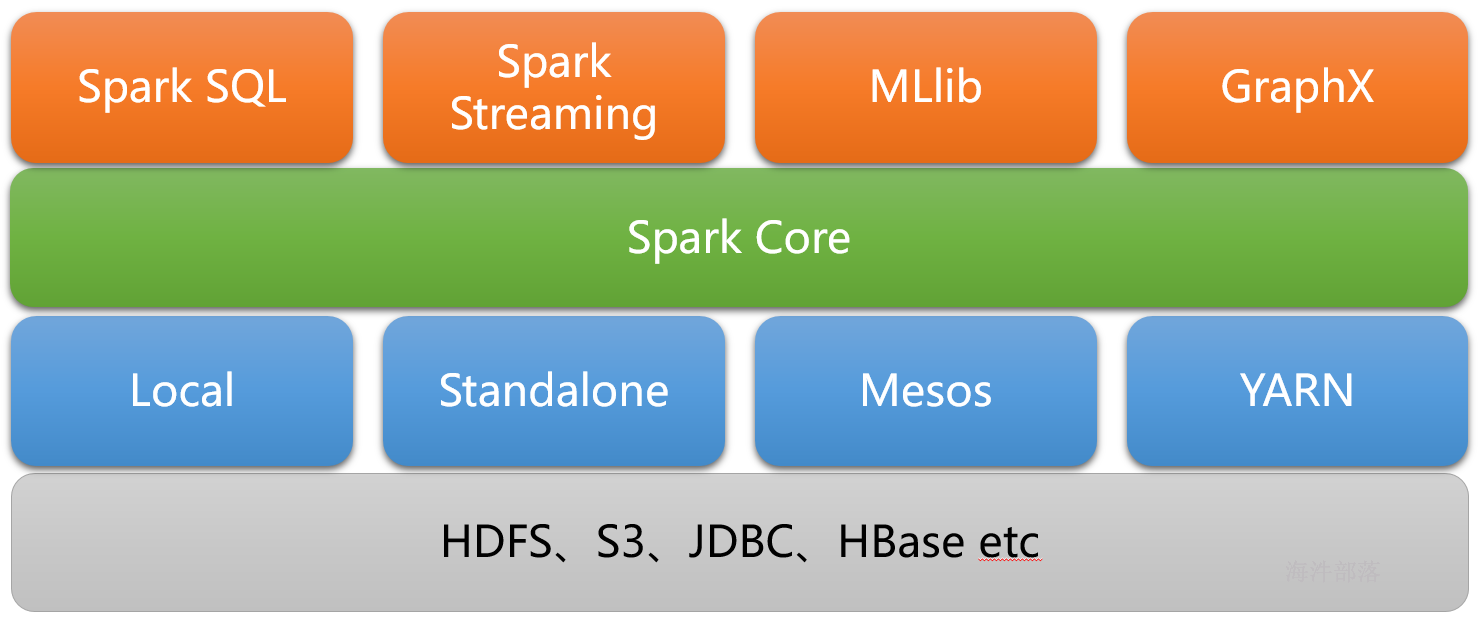
实现了spark的基本功能、包括任务调度、内存管理、错误恢复与存储系统交互等模块。spark core中还包含了对弹性分布式数据集(resileent distributed dataset)的定义;
spark sql:
是spark用来操作结构化数据的程序,通过SPARK SQL,我们可以使用SQL或者HIVE(HQL)来查询数据,支持多种数据源,比如HIVE表就是JSON等,除了提供SQL查询接口,还支持将SQL和传统的RDD结合,开发者可以在一个应用中同时使用SQL和编程的方式(API)进行数据的查询分析,SPARK SQL是在1.0中被引入的;
Spark Streaming:
是Spark提供的对实时数据进行流式计算的组件,比如网页服务器日志,或者是消息队列都是数据流。
MLLib:
是Spark中提供常见的机器学习功能的程序库,包括很多机器学习算法,比如分类、回归、聚类、协同过滤等。
GraphX:
是用于图计算的比如社交网络的朋友关系图。
3 Spark应用场景
Yahoo将Spark用在Audience Expansion中的应用,进行点击预测和及时查询等;
淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等。应用于内容推荐、社区发现等;
腾讯大数据精准推荐借助Spark快速迭代的优势,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上;
优酷土豆将Spark应用于视频推荐(图计算)、广告业务,主要实现机器学习、图计算等迭代计算;
目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上。在广告业务方面需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排名、个性化推荐以及热点点击分析等。这些应用场景的普遍特点是计算量大、效率要求高。
4 Spark环境部署
主要运行方式
Local
Standalone
On YARN
On Mesos
5 Standalone集群模式安装
环境准备
机器的环境 配置ip,hosts映射,jdk,yarn
我们就可以直接使用hadoop的配置镜像
http://cloud.hainiubl.com/#/privateImageDetail?id=2851&imageType=private
准备镜像
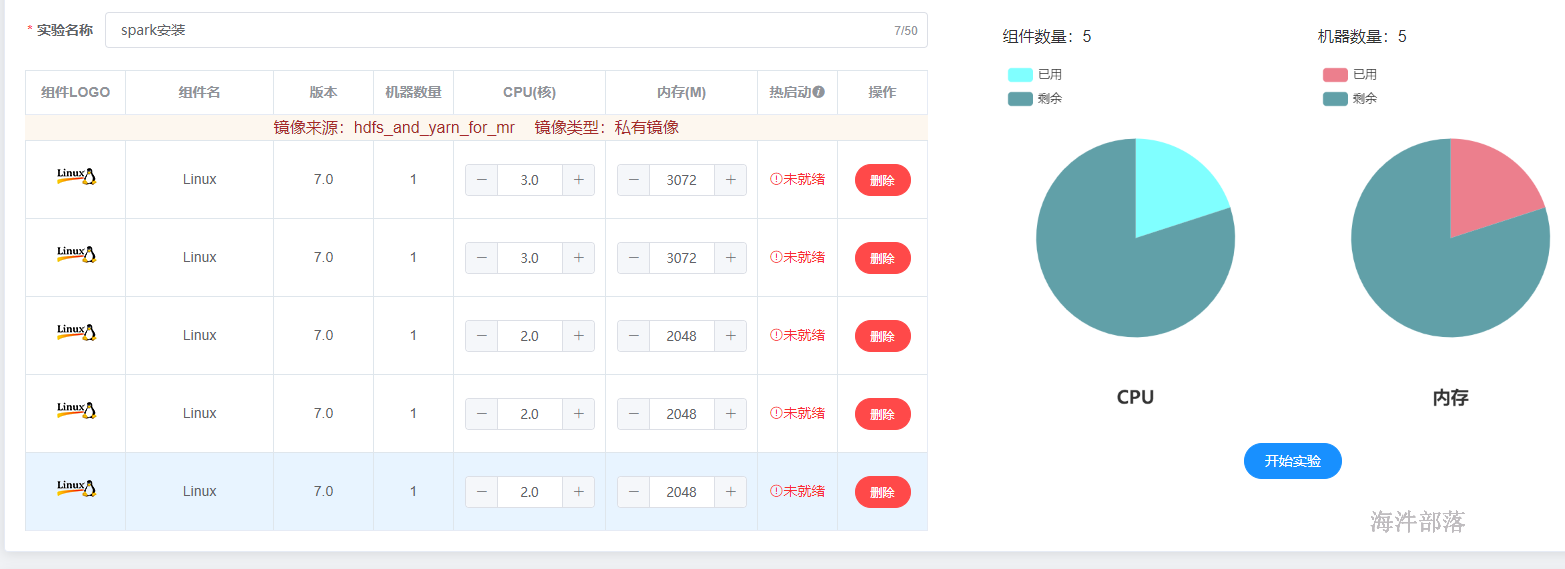
分别调节资源主节点3core 3G 从节点2core 2G
5.1 非高可用安装
5.1.1 安装步骤
1)已经存在压缩包

# 解压
ssh_root.sh tar -zxvf /public/software/bigdata/spark-3.1.2-bin-hadoop2.7.tgz -C /usr/local/
# 查看解压内容
3)修改权限为hadoop
ssh_root.sh chown hadoop:hadoop -R /usr/local/spark-3.1.2-bin-hadoop2.7/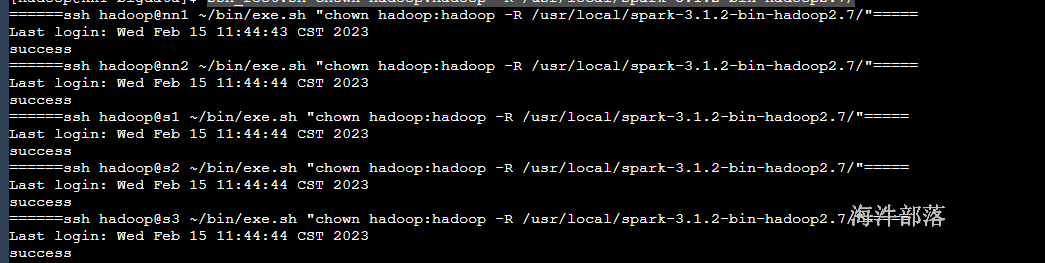
4)创建软件链接
ssh_root.sh ln -s /usr/local/spark-3.1.2-bin-hadoop2.7/ /usr/local/spark查看/usr/local/目录
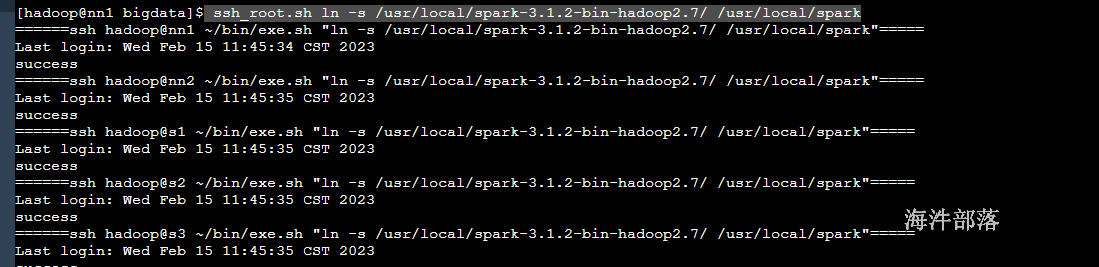

bin:可执行脚本
conf:配置文件目录
data:examples里的测试样例的测试数据集
examples:测试样例
jars:lib库
python/R:是python和R
sbin:控制脚本
yarn:yarn支持库
5)修改文件名
mv spark-env.sh.template spark-env.sh
mv workers.template workers6)在 nn1.hadoop 机器 修改spark-env.sh


scp_all.sh /usr/local/spark/conf/spark-env.sh /usr/local/spark/conf/
scp_all.sh /usr/local/spark/conf/workers /usr/local/spark/conf/10)在/etc/profile 下增加spark的path,并分发到其他机器
# 在/etc/profile中进行配置
echo 'export SPARK_HOME=/usr/local/spark' >> /etc/profile
echo 'export PATH=$PATH:$SPARK_HOME/bin' >> /etc/profile
echo 'export PATH=$PATH:$SPARK_HOME/sbin' >> /etc/profile
source /etc/profile5.1.2 启动spark
1)启动脚本
start-master.sh
start-workers.sh
启动spark

查看日志可以看到通信和监控端口号
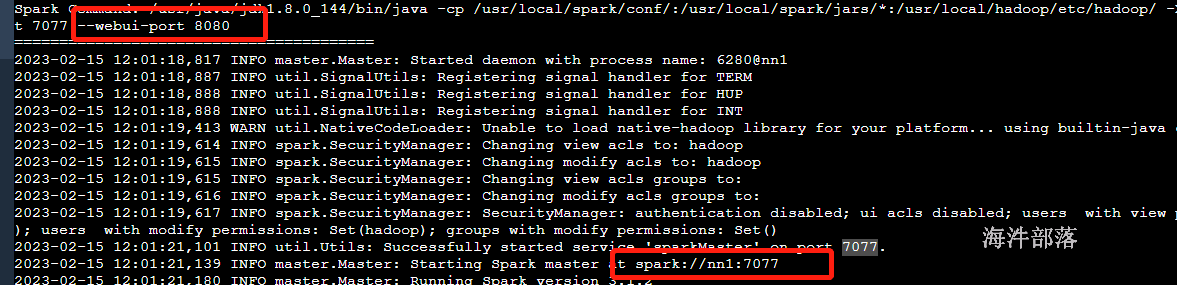
通过进程查看端口号
jps查看进程
netstat -natpl|grep 6280
3)masterUI界面
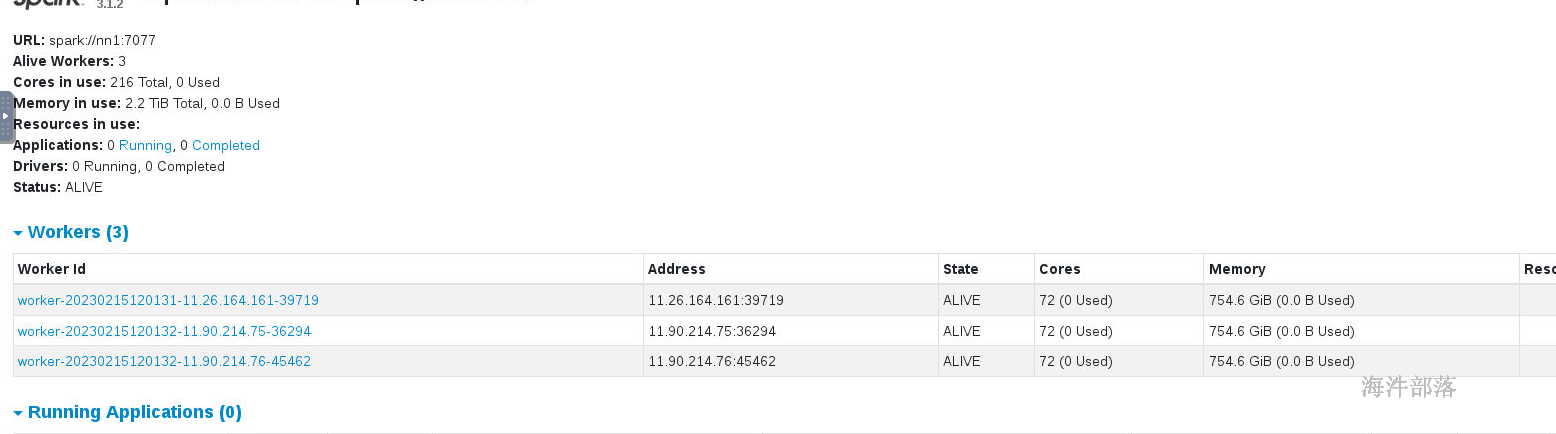

因为在海牛集群上资源是整个实验室的资源,需要进行调节,核数改为实验环境的核数,内存实验环境内存-1G
# 配置spark-env.sh
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=1G
# 分发到不同的节点
scp_all.sh /usr/local/spark/conf/spark-env.sh /usr/local/spark/conf/
# 重启集群
stop-master.sh
stop-workers.sh
start-master.sh
start-workers.sh查看监控头页面
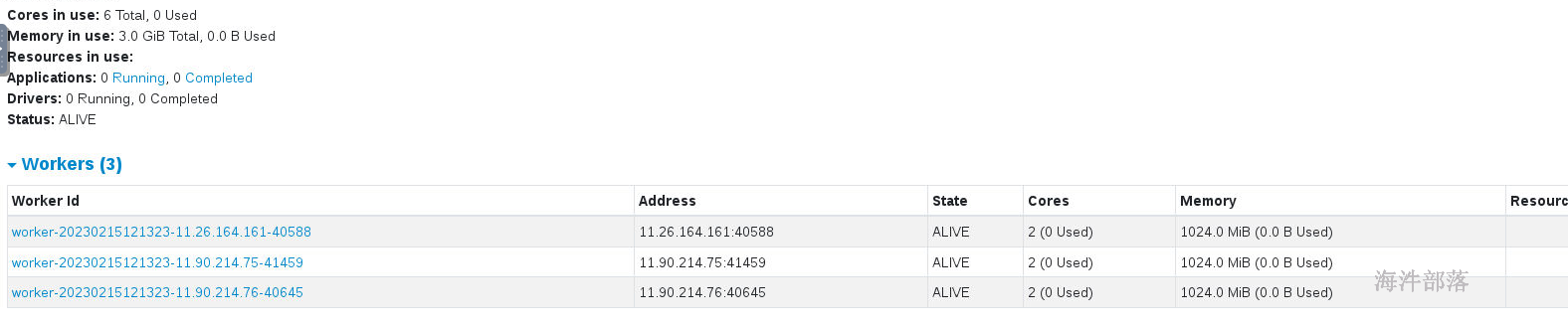
4)机器上的进程
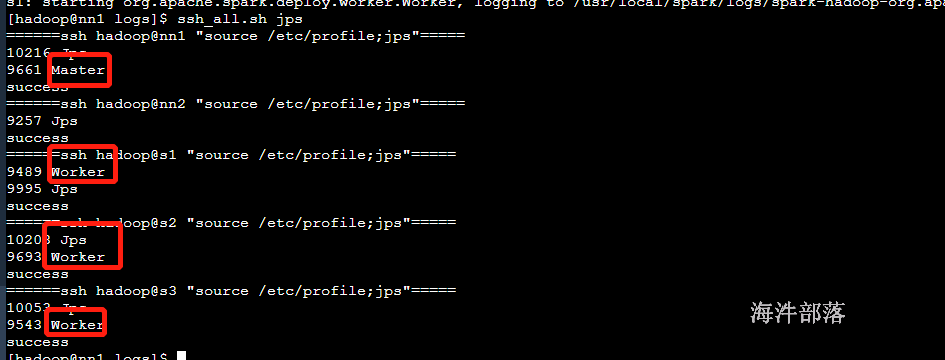
5.1.3 spark测试
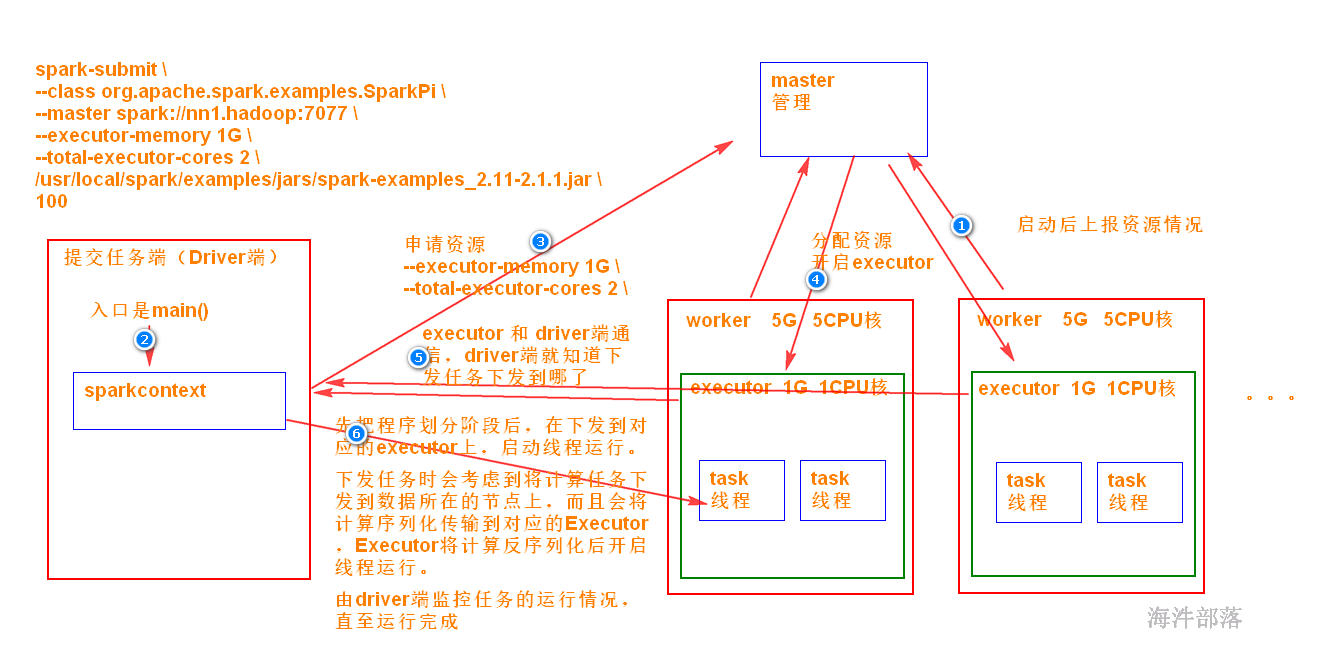
spark的集群运行结构

我们要选择第一种使用方式
命令组成结构 spark-submit [选项] jar包 参数
standalone集群能够使用的选项
--master MASTER_URL #集群地址
--class class_name #jar包中的类
--executor-memory MEM #executor的内存
--executor-cores NUM # executor的核数
--total-executor-cores NUM # 总核数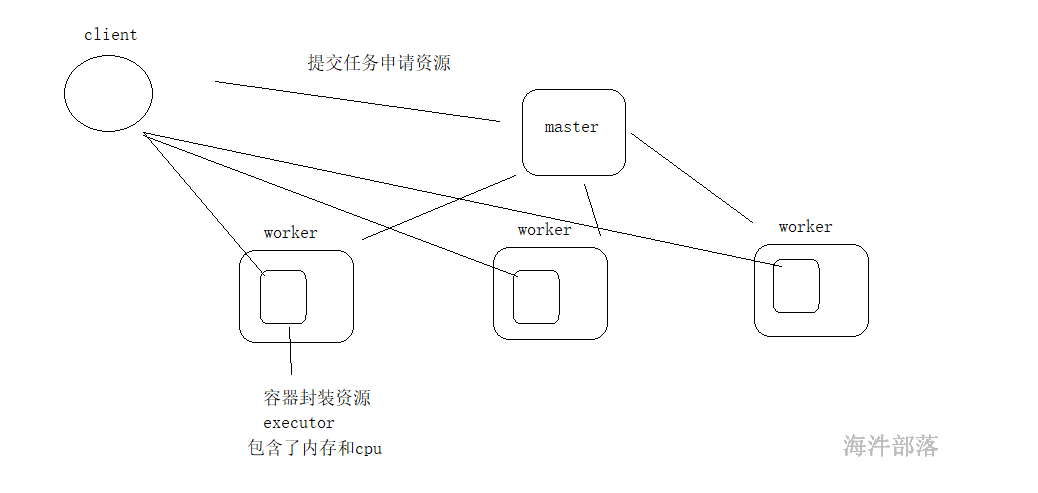
用spark-submit提交spark应用程序。
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://nn1.hadoop:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/usr/local/spark/examples/jars/spark-examples_2.12-3.1.2.jar \
100参考:
集群参数配置
--master MASTER_URL #集群地址
--class class_name #jar包中的类
--executor-memory MEM #executor的内存
--executor-cores NUM # executor的核数
--total-executor-cores NUM # 总核数spark webUI

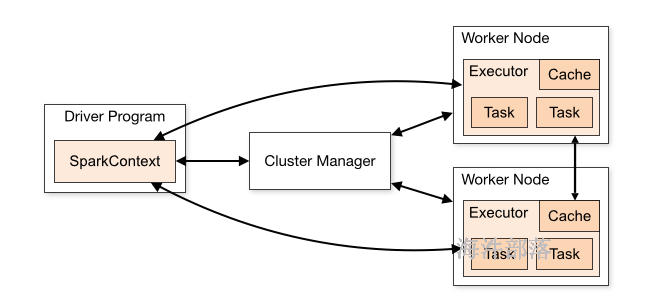
Driver: 运行 Application 的 main() 函数的节点,提交任务,并下发计算任务;
Cluster Manager:在standalone模式中即为Master主节点,负责整个集群节点管理以及资源调度;在YARN模式中为资源管理器;
Worker节点:上报自己节点的资源情况,启动 和 管理 Executor;
Executor:执行器,是为某个Application运行在worker节点上的一个进程;负责执行task任务(线程);
Task:被送到某个Executor上的工作单元,跟MR中的MapTask和ReduceTask概念一样,是运行Application的基本单位。
运行大概流程:
1)driver 端提交应用,并向master申请资源;
2)Master节点通过RPC和Worker节点通信,根据资源情况在相应的worker节点启动Executor 进程;并将资源参数和Driver端的位置传递过来;
3)启动的Executor 进程 会主动与 Driver端通信,Driver 端根据代码的执行情况,产生多个task,发送给Executor;
4)Executor 启动 task 做真正的计算,每个Task 得到资源参数后,对相应的输入分片数据执行计算逻辑;
5.1.5 spark的资源设定
在默认搭建完毕集群后。worker的内存和cpu是存在默认设定的

端口存在默认值

资源的设定
worker的默认值是all cores 已经总内存 -1G
executor的默认值
executor的默认资源是1G的内存


默认的executor的核数是当前worker的所有的核数
5.2 高可用安装
spark 高可用是通过zookeeper 实现。
5.2.1 修改配置spark-env.sh,并分发到其他机器
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=nn1:2181,nn2:2181,s1:2181 -Dspark.deploy.zookeeper.dir=/spark3"

# 分发
scp_all.sh /usr/local/spark/conf/spark-env.sh /usr/local/spark/conf/
#启动zookeeper
ssh_all_zk.sh /usr/local/zookeeper/bin/zkServer.sh start
# 关闭spark重启
stop-master.sh
stop-workers.sh
start-master.sh
start-workers.sh
# 在nn2单独启动master
start-master.sh启动后查看进程:
千万别用root用户启动,因为再次使用hadoop用户启动权限不足
# 一定要记得修改spark的所有权限
ssh_root.sh chown hadoop:hadoop -R /usr/local/spark/查看nn1和nn2 spark的web页面,当前是standby 状态。

查看zookeeper中的内容
# zkCli.sh 客户端
zkCli.sh

-
/spark/leader_election主要是选举
- /spark/master_status 主要是记录集群的状态
5.2.3 高可用演示
在运行下面的任务的同时,kill 掉 ALIVE 的 master,看会不会切换
spark-submit
–class org.apache.spark.examples.SparkPi
–master spark://nn1.hadoop:7077,nn2.hadoop:7077
–executor-memory 1G
–total-executor-cores 2
/usr/local/spark/examples/jars/spark-examples_2.12-3.1.2.jar
5000
为了不打印太多日志,把log 级别设置成WARN
# 首先修改配置文件的名称
mv log4j.properties.template log4j.properties
vim /usr/local/spark/conf/log4j.properties
# 分发数据
scp_all.sh /usr/local/spark/conf/log4j.properties /usr/local/spark/conf/
演示主节点切花
# 在nn1节点关闭master
stop-master.sh
提交应用程序后,kill掉alive的master, 任务继续运行,没影响
# 提交任务然后杀死alive节点
spark-submit --master spark://nn1:7077,nn2:7077 \
--executor-cores 2 \
--executor-memory 1G \
--total-executor-cores 6 \
--class org.apache.spark.examples.SparkPi \
/usr/local/spark/examples/jars/spark-examples_2.12-3.1.2.jar \
10000
# 杀死alive节点
查看webui发现, standby 的已经转成 alive

5.2.4 高可用原理
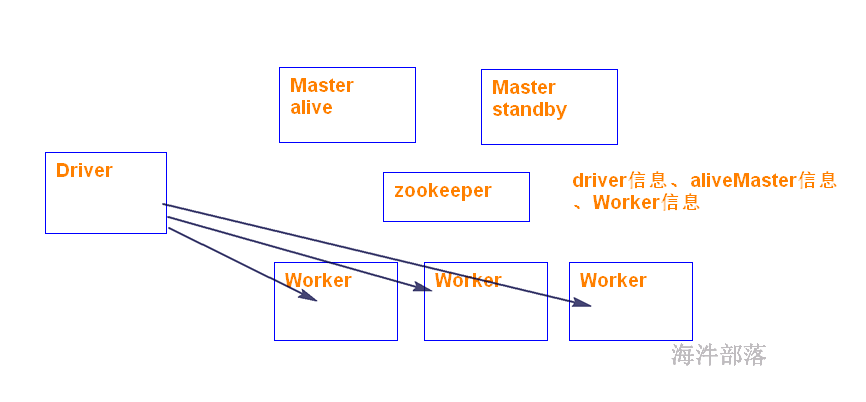
在应用程序执行过程中,如果进行master 的ha切换会影响应用程序的运行吗?
不会,因为程序运行前已经向master申请过资源了。申请过后就是Driver与Executors之间的通信,这个过程一般不需要Master参与,除非executor有故障。
粗粒度:应用程序需要多少资源,就一次性分配。
好处:是一次性分配资源好后,不需要再关心资源的分配,而在作业运行过程中可以让driver和executors交互,
完成作业或程序运行。
弊端:假设有一百万个任务,如果只有一个任务没有完成,那么其他所有资源都会闲置,其他任务会等待,造成浪费。
5.3 spark-shell和提交模式
5.3.1 Spark Shell:
是基础scala的的命令行客户端,是一个spark的driver应用程序,可以写spark程序进行测试,可以本地运行也可以集群运行,取决于是否设置 –master
spark-shell是交互式命令行,出发点是在客户端,主要是为了编程测试使用的
与spark-submit不同,提交的是一个整体的代码,打包成jar
spark-shell是写一行命令执行一行
命令的整体
spark-shell --master spark://nn1:7077 \
--executor-cores 2 \
--executor-memory 2G \
--total-executor-cores 6
5.3.2 本地提交模式
集群存在比较常用的四种
- local 模式,直接使用的是机器本地的资源。本地运行和集群无关
- standalone集群,独立部署模式
以上两种我们做一下测试
本地提交
spark-shell|spark-submit --master spark:// #这种方式它就是standalone集群的提交方式
spark-shell|spark-submit --master local | local[N] | local[*]
# local 本地执行使用一个核
# local[3] 本地三个核相当于是一个伪集群
# local[*] 本地所有的核
本地执行,集群中不占有任何资源

本地执行模式相当于是本地的多线程模拟
5.3.3 集群资源计算
spark集群在standalone模式中默认存在一个问题,一旦设定好了每个executor的资源大小,它会按照整个集群的资源全部都给executor进行分配
比如我们只设定executor的资源
spark-submit --executor-cores 2 --executor-memory 1G整个集群的资源每个机器是3G+3cores
每个worker = 2G + 3cores
在分配资源的时候会,按照木桶原理,默认会启动3个executor,尽量占用所有的资源
这样多个任务就不能并行执行
首先不做任何资源限定
spark的executor默认占用1G内存和所有的核数
spark-shell --master spark://nn1:7077

再次提交任务
spark-submit --master spark://nn1:7077
发现另一个任务没有任何的资源

我们设定资源提交
#多个任务并行执行
spark-shell --master spark://nn1:7077 --executor-cores 1 --executor-memory 1G \
--total-executor-cores 3
spark-shell --master spark://nn1:7077 --executor-cores 1 --executor-memory 1G \
--total-executor-cores 3
设定完毕资源以后每个任务占用集群的一部分资源,都可以执行
集群中的资源 3*worker = 3cores + 2G =[9cores + 6G]
| --executor-cores | --executor-memory | --total-executor-cores | num |
|---|---|---|---|
| no [all] | no [1G] | no | 3 |
| no [all] | 512M | no | 3 |
| 1 | 1G | no | 6 |
| 1 | 1G | 3 | 3 |
| 1 | 1G | 2 | 2 |
| 4 | 1G | no | 0 |
5.4 Yarn和Spark的StandAlone调度模式对比
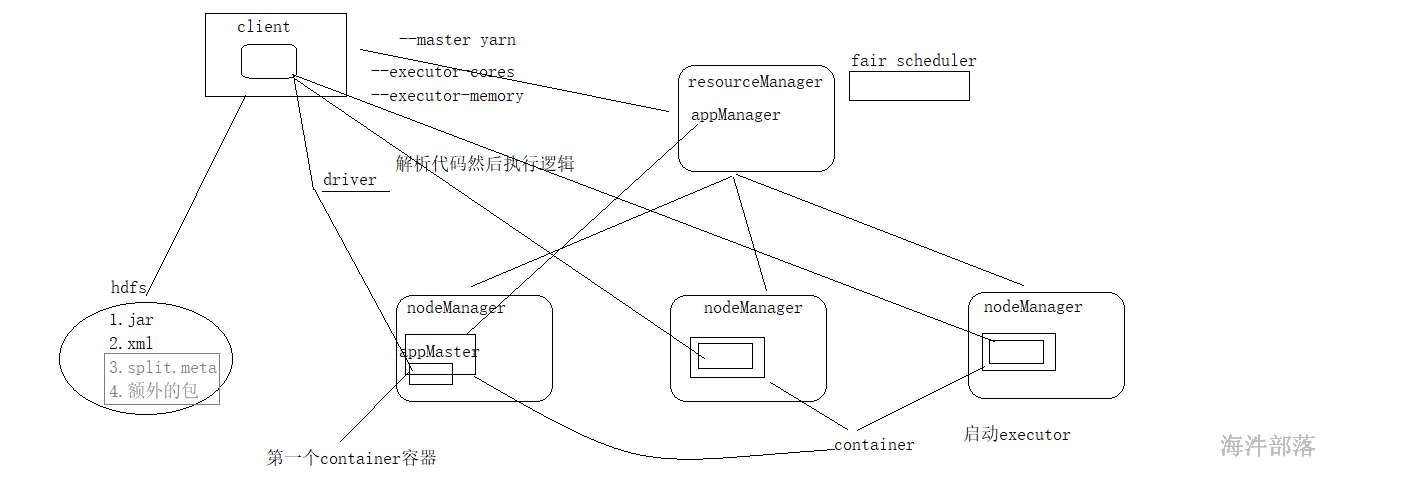
| yarn | spark的standAlone调度模式对比 | spark集群各组件的功能 |
|---|---|---|
| ResourceManager | Master | 管理子节点,调度资源,接受任务请求 |
| NodeManger | Worker | 管理当前节点,并管理子节点 |
| YarnChild | Executor (Task) | 运行真正的计算逻辑(Task) |
| client | client | driver(Client+AppMaster)提交App,管理该任务的Executor |
| ApplicationMaster | driver |
yarn的原理
5.4.1 yarn的提交命令
# yarn的提交命令参数
--master yarn #执行集群
--deploy-mode # 部署模式
--class #指定运行的类
--executor-memory #指定executor的内存
--executor-cores # 指定核数
--num-executors # 直接指定executor的数量
--queue # 指定队列为了提交任务首先修改yarn的配置文件
<!--修改最大内存申请量 /usr/local/hadoop/etc/hadoop/yarn-site.xml -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1536</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1536</value>
<description>单个任务可申请的最多物理内存量</description>
</property># 分发配置文件
scp_all.sh /usr/local/hadoop/etc/hadoop/yarn-site.xml /usr/local/hadoop/etc/hadoop/
# 重启yarn集群
stop-yarn.sh
start-yarn.sh5.4.2 yarn-client模式
是driver端是独立于 yarn集群的,运算的时候,driver端需要管理executor 中task的运行,所以driver端(客户端)是不能离开的。
driver端在客户端上,所以好调试日志。
当在客户端提交多个spark应用时,它会对客户端造成很大的网络压力,yarn-client模式只适合 交互式环境开发。
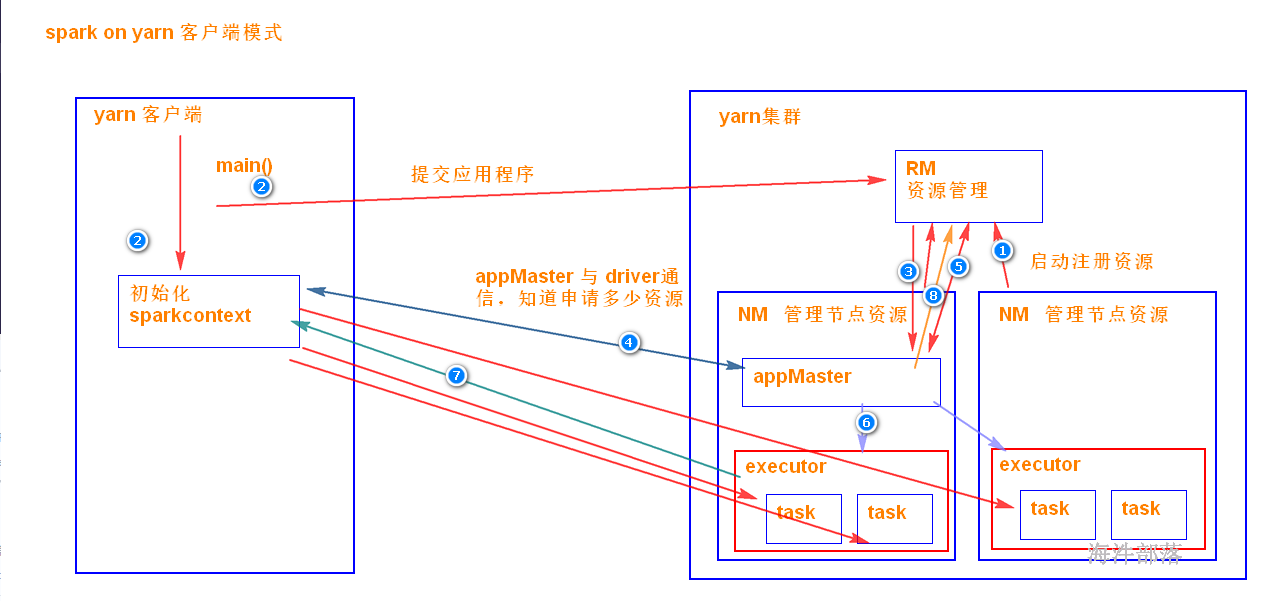
spark-shell --master yarn --deploy-mode client --queue root.hainiu --executor-cores 1 --executor-memory 1G
可以点击application --> appMaster进入到监控页面
client模式提交driver端在客户端

客户端在nn1 driver也在nn1

发现appmaster也会占用资源在s1节点,s2和s3分别运行的是executor
spark-submit提交代码
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--queue hainiu \
/usr/local/spark/examples/jars/spark-examples_2.12-3.1.2.jar \
20000不加deploy-mode默认值是client

运行期间不能断开客户端的链接,不然driver端死掉


driver端也是在客户端

可以将结果数据直接打印到客户端中
在yarn模式中不设置资源也会存在默认值
- executor-memory =1G
- executor-cores = 1
- num-executors = 2
5.4.3 yarn-cluster模式
driver端是在APPMater节点,是在yarn集群里面,那运行和监控executor 的任务都是在yarn集群里面。yarn提交任务的客户端是可以离开的。
driver端在yarn集群里面,所以不好调试日志。
客户端一经提交可以离开,常用于正常的提交应用,适合生产环境。
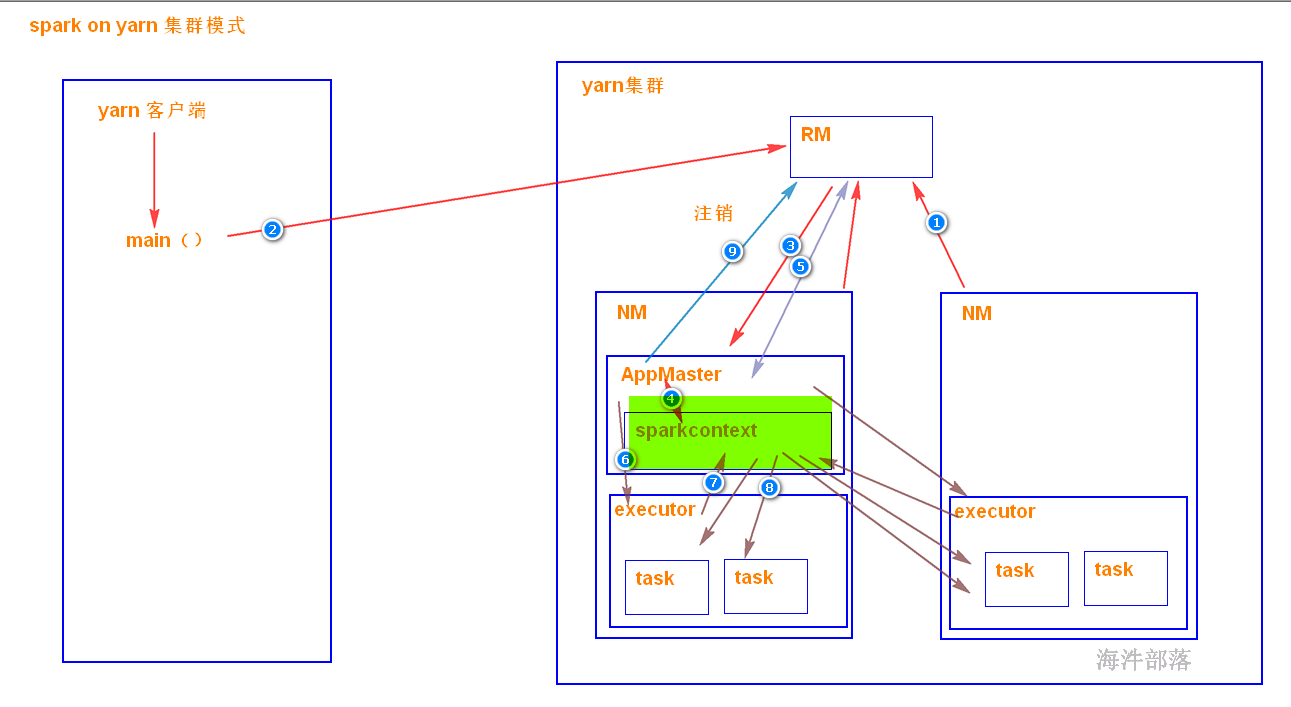

集群模式是不支持spark-shell的
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--queue hainiu \
--deploy-mode cluster \
/usr/local/spark/examples/jars/spark-examples_2.12-3.1.2.jar \
20000启动完毕以后查看appmaster

appMaster和driver在一起的

如果不设置默认启动两个executor

停止客户端

任务还在执行,因为driver端在appMaster在一起并不是在客户端client
任务的执行结果不能够直接查看到
需要用yarn logs -applicationId application_1676453244201_0003 | grep 3.14

任务在执行的时候可以看到,任务上传到hdfs中
含有的内容 jar xml split 额外jar

可以看到在/user/hadoop/.sparkStaging/applicationId/存在的依赖资源
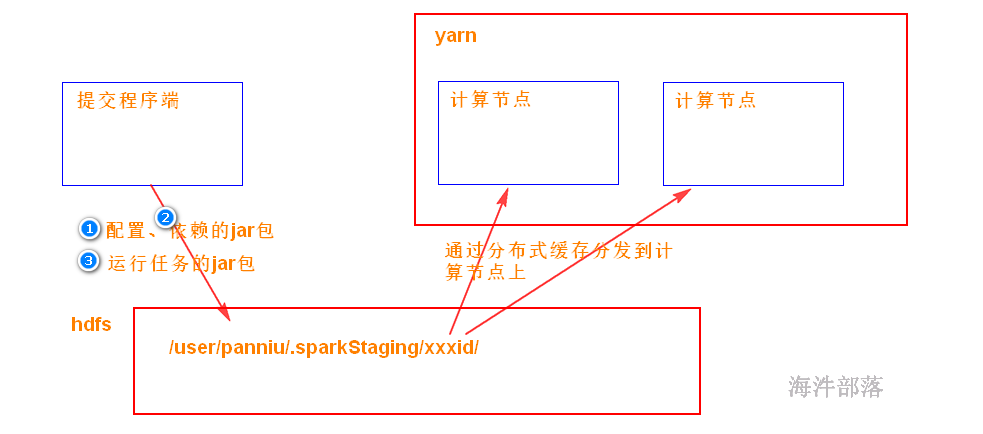
5.4.4 spark on yarn 提交流程
当spark在yarn上运行时,yarn要拿到 3样:
1)运行用的配置
2)运行要依赖的jar包
默认是SPARK_HOME/jars 目录下的jar包打包
如果想加入其它jar包,可通过 –jars 添加
3)运行任务的jar包(带有代码的jar包)
这3样需要从提交程序端 上传到 /user/xxx/.sparkStaging/yarnid/目录下(分布式缓存),然后再分发到运行任务的计算节点。
6.1 spark-shell开发
spark的代码分为两种
-
本地代码在driver端直接解析执行没有后续
-
集群代码,会在driver端进行解析,然后让多个机器进行集群形式的执行计算
spark-shell --master spark://nn1:7077 --executor-cores 2 --executor-memory 2G
sc.textFile("/home/hadoop/a.txt")
org.apache.spark.rdd.RDD[String] = /home/hadoop/a.txt MapPartitionsRDD[1] at textFile atrdd弹性分布式数据集合
- 如果是sc调用的方法会在集群中执行
- rdd调用的方法也会集群执行
sc.textFile("/home/hadoop/a.txt")不是单机代码,但是文件不能再某一个机器上,因为这个命令所有的机器都会执行
这个路径一定要放在hdfs中
问题:第一行代码就读取了数据,为什么第一行没有出现错误?
spark中的方法[算子]它是分为两种
- 转换类算子,定义逻辑,并且调用完毕以后具有返回值的,调用算子以后是不是返回rdd
- 行动类算子,触发计算,并且没有rdd的返回
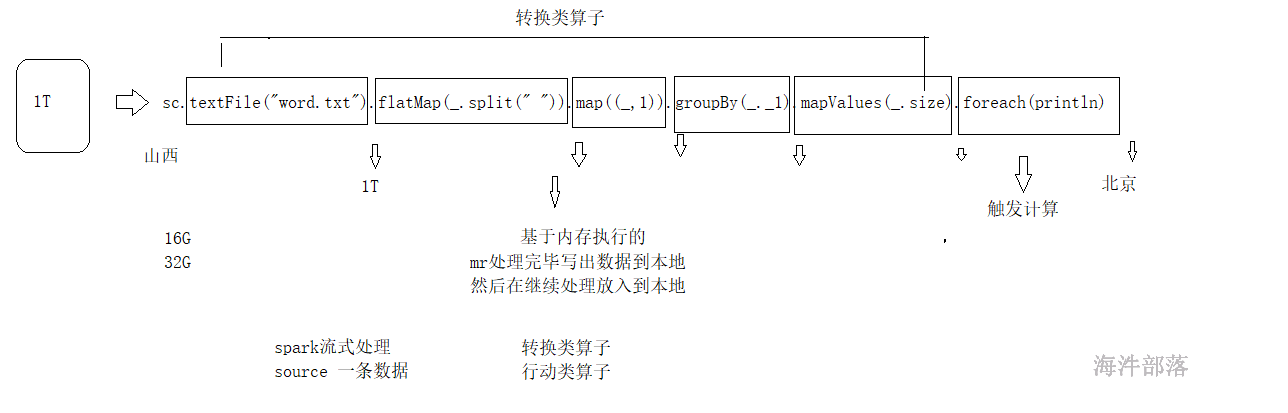
代码的整体逻辑是先使用转换类算子定义逻辑,但是不执行,一旦使用action算子就会触发运算,整体才执行,这样的设计能够最大化的减少内存的使用
所以上传hdfs文件,读取
hdfs dfs -put /home/hadoop/a.txt /spark-shell整体代码
scala> //在spark-env.sh中配置HADOOP_CONF_DIR,默认会读取hdfs中的文件
scala> sc.textFile("/a.txt")
res6: org.apache.spark.rdd.RDD[String] = /a.txt MapPartitionsRDD[5] at textFile at <console>:26
//放入数据到hdfs中
scala> res6.flatMap(_.split(" "))
res7: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at flatMap at <console>:27
scala> res7.map((_,1))
res8: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[7] at map at <console>:27
scala> res8.groupBy(_._1)
res9: org.apache.spark.rdd.RDD[(String, Iterable[(String, Int)])] = ShuffledRDD[9] at groupBy at <console>:27
//分组完毕的返回值不再是map而是RDD[String,Iterable]
scala> res9.mapValues(_.size)
res10: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[10] at mapValues at <console>:27
//mapValues在scala中只能作用在map集合上,现在可以作用在RDD[k,v]
scala> res10.foreach(println)
//打印数据的时候每个机器都有,因为是分布式执行的因为是分布式的,写代码的时候在driver,真正执行的时候在executor中,我们不在一起,所以看不到结果
去executor中查看

action算子会触发执行


所以我们看到在executor中展示结果数据
6.2 搭建spark的开发环境
1)打开海牛实验室,选择远程桌面,选择idea

2)安装scala插件
ctrl+alt+s进入设置页面,点击plugin搜索scala安装,安装完毕重启

已经在/public中已经准备好了scala的安装包,解压到桌面

配置sdk
5)pom.xml中添加maven依赖
在海牛实验室中maven的本地仓库配置,远程仓库配置以及插件全部配置完毕
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>6)添加 log4j.properties 在src/main/resources
log4j.rootLogger=info,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c %M(): %m%n7 spark wordcount 代码实现
7.1 scala版本
首先准备数据
# 创建data文件里面的a.txt文件输入如下内容
hello world hello tom
hello world hello tom
hello world hello tomwordcount的整体代码
package com.hainiu.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
/**
* 1 读取数据
* 2 切分压平
* 3 单词和 1
* 4.分组
* 5 求和
* sc rdd 调用的算子会在集群中执行
* spark-shell --> sc
* spark-submit
*/
object WordCount {
def main(args: Array[String]): Unit = {
val config = new SparkConf()
config.setAppName("word count")
config.setMaster("local[*]")
val sc = new SparkContext(config)
val rdd:RDD[String] = sc.textFile("data/a.txt")
val rdd1:RDD[String] = rdd.flatMap(_.split(" "))
val rdd2:RDD[(String,Int)] = rdd1.map((_,1))
val rdd3:RDD[(String,Iterable[(String,Int)])] = rdd2.groupBy(_._1)
val rdd4:RDD[(String,Int)] = rdd3.mapValues(_.size)
rdd4.foreach(println)
}
}在本地执行的时候要指定APPName和master地址为local[*]
7.2 wordcount的改版
保存数据的时候使用的mr的原生存储方式,那么文件结果必须不能存在
定义隐式转换的工具类
package com.hainiu.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
object FileUtils{
implicit def str2FileUtils(s:String) = new FileUtils(s)
}
class FileUtils(path:String) {
def delete = {
val fs = FileSystem.getLocal(new Configuration())
if(fs.exists(new Path((path))))
fs.delete(new Path(path),true)
}
}
package com.hainiu.spark
import com.hainiu.spark.FileUtils.str2FileUtils
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object WordCount {
def main(args: Array[String]): Unit = {
val config = new SparkConf()
config.setAppName("word count")
config.setMaster("local[*]")
val sc = new SparkContext(config)
val rdd:RDD[String] = sc.textFile("data/a.txt")
val rdd1:RDD[String] = rdd.flatMap(_.split(" "))
val rdd2:RDD[(String,Int)] = rdd1.map((_,1))
val rdd3:RDD[(String,Iterable[(String,Int)])] = rdd2.groupBy(_._1)
val rdd4:RDD[(String,Int)] = rdd3.mapValues(_.size)
// rdd4.foreach(println)
val output = "data/res"
output.delete
rdd4.saveAsTextFile(output)
}
}
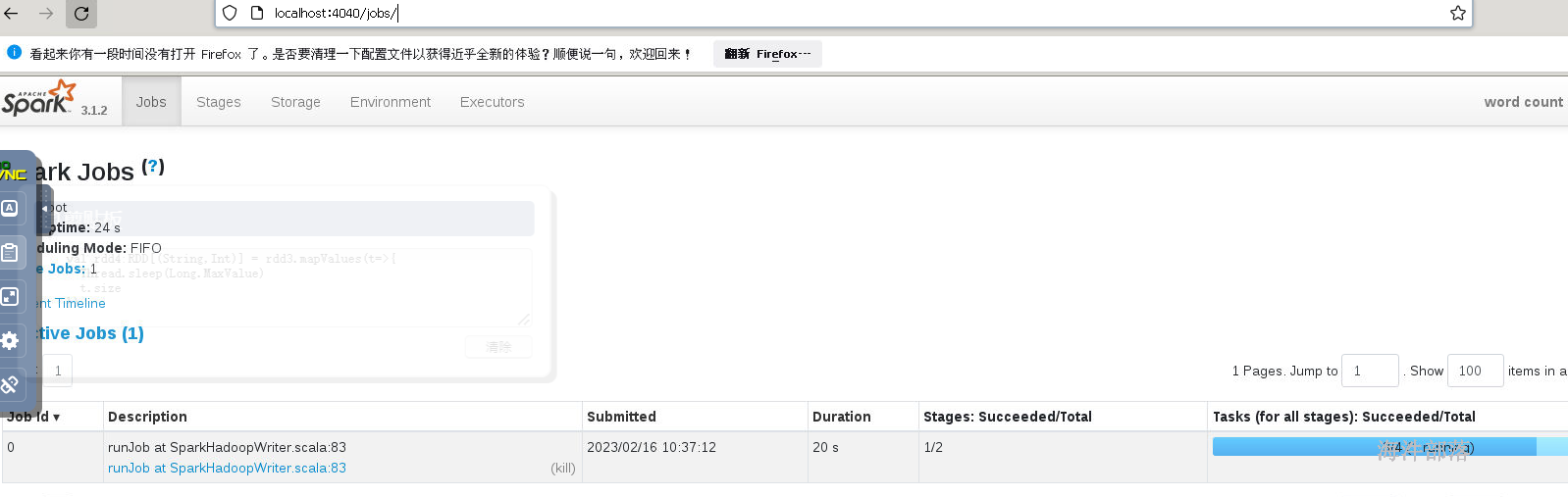
并且在本地是存在监控页面的,但是我们将整个代码的执行延迟
val rdd4:RDD[(String,Int)] = rdd3.mapValues(t=>{
Thread.sleep(Long.MaxValue)
t.size
})需要设定一下整个的执行逻辑延迟,然后就可以看到代码执行页面
7.3 打包执行
首先修改代码
// appName和master需要去掉, spark-submit --master
// 输入路径和输出路径都变化
// 接受数据的时候使用args
// 需要进行编译
// maven项目分为两个 src中这里面是认为开发的源码
// target目录是编译后的class文件
// package打包,就是将target目录中的所有class文件打成一个jar包
// 最好用的编译方式,运行不管是不是出错肯定先编译整体代码
package com.hainiu.spark
import com.hainiu.spark.FileUtils.str2FileUtils
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
// spark-submit --master
// spark-submit --master --executor-cores --executor-memory --class com.hainiu.spark.WordCountForCluster spark.jar xx aa
object WordCountForCluster {
//args接受参数
def main(args: Array[String]): Unit = {
val Array(input,output) = args
val config = new SparkConf()
// config.setAppName("word count")
// config.setMaster("local[*]")
val sc = new SparkContext(config)
val rdd:RDD[String] = sc.textFile(input)
val rdd1:RDD[String] = rdd.flatMap(_.split(" "))
val rdd2:RDD[(String,Int)] = rdd1.map((_,1))
val rdd3:RDD[(String,Iterable[(String,Int)])] = rdd2.groupBy(_._1)
val rdd4:RDD[(String,Int)] = rdd3.mapValues(t=>{
// Thread.sleep(Long.MaxValue)
t.size
})
output.delete
rdd4.saveAsTextFile(output)
}
}

先执行然后打包
在集群中执行,但是远程桌面和集群不在一起,我们要将打包的内容发送到集群的机器中
首先查看nn1节点的ip

远程发送包
scp /headless/workspace/spark/target/spark-1.0-SNAPSHOT.jar hadoop@11.237.80.59:/home/hadoop/
在nn1节点查看数据

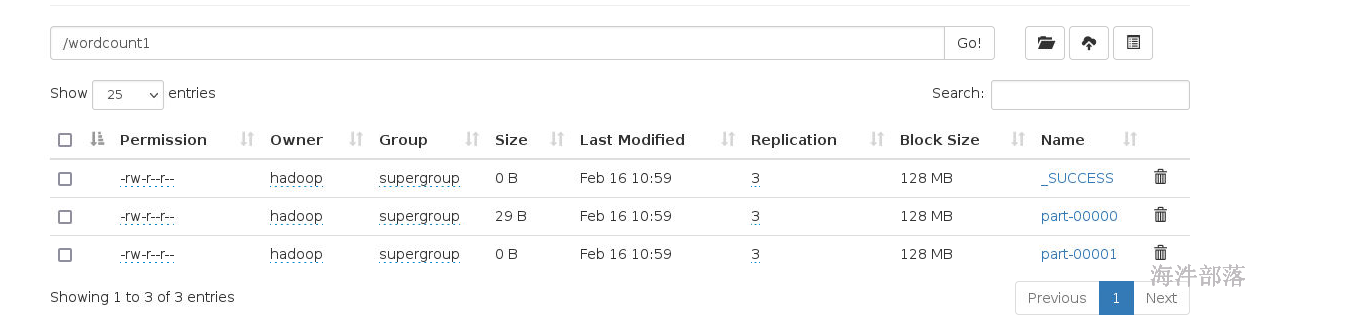
开始提交任务到集群中
spark-submit --master spark://nn1:7077 --executor-cores 2 --executor-memory 2G --total-executor-cores 6 --class com.hainiu.spark.WordCountForCluster spark-1.0-SNAPSHOT.jar /a.txt /wordcount1