sparkStreaming02
21.4.2 updateStateByKey
java updateStateByKey方法 使用代码示例:
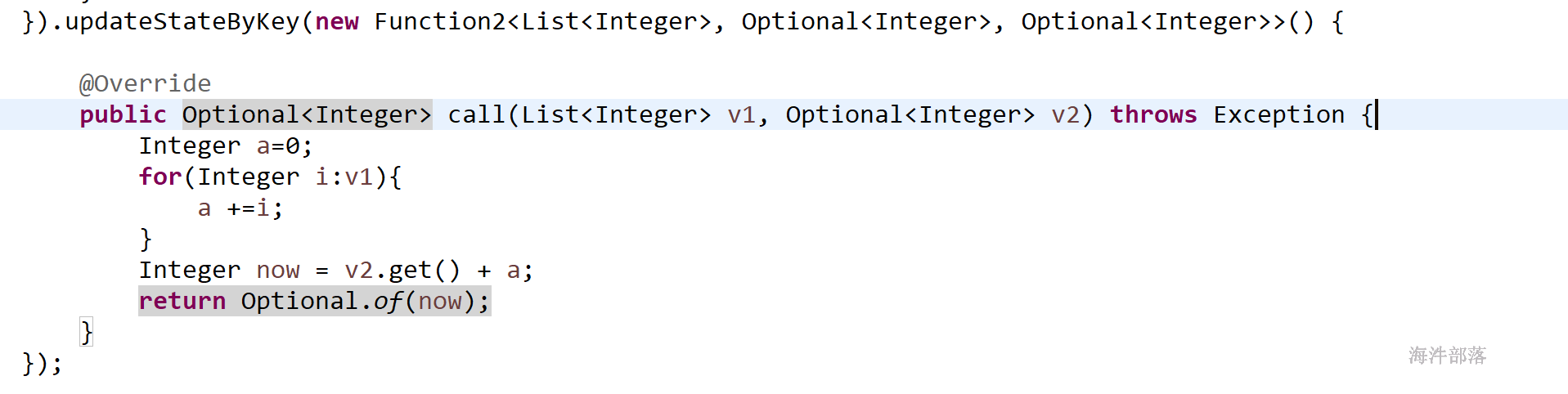
V2:上次数据
返回结果本次汇总数据,也就是下次的V2数据
scala代码:
package com.hainiu.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* calculate with state
* keep all result
*/
object TestUpdateStateByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("updateStateByKey")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.checkpoint("file:///headless/workspace/spark/data/ckpt")
ssc.socketTextStream("nn1",6666)
.flatMap(_.split(" "))
.map((_,1))
// .reduceByKey(_+_)
.updateStateByKey((curr:Seq[Int],last:Option[Int])=>{
Option(curr.sum + last.getOrElse(0))
})
.print()
ssc.start()
ssc.awaitTermination()
}
}
结果:
第一次执行代码

打印日志

第二次执行代码:
发现上次的数据并没有加载进来,说明只接收了socket流,并没有加载checkpoint的数据。

21.4.3 streaming用checkpoint恢复历史数据
通过StreamingContext.getOrCreate()
该方法优先使用checkpoint 检查点的数据创建StreamingContext;如果checkpoint没有数据,则将通过调用提供的“ creatingFunc”来创建StreamingContext。
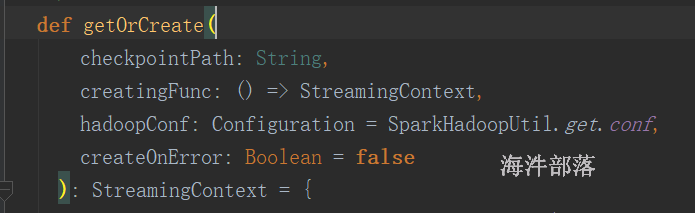
代码:
package com.hainiu.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* calculate with state
* keep all result
*/
object TestUpdateStateByKeyWithRecovery {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("updateStateByKey")
conf.setMaster("local[*]")
val ssc = StreamingContext.getOrCreate("file:///headless/workspace/spark/data/ckpt",()=>{
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint("file:///headless/workspace/spark/data/ckpt")
ssc.socketTextStream("nn1", 6666)
.flatMap(_.split(" "))
.map((_, 1))
// .reduceByKey(_+_)
.updateStateByKey((curr: Seq[Int], last: Option[Int]) => {
Option(curr.sum + last.getOrElse(0))
})
.print()
ssc
})
ssc.start()
ssc.awaitTermination()
}
}
删除checkpoint 目录,第一次启动程序
运行日志:
第二次启动程序
运行日志:
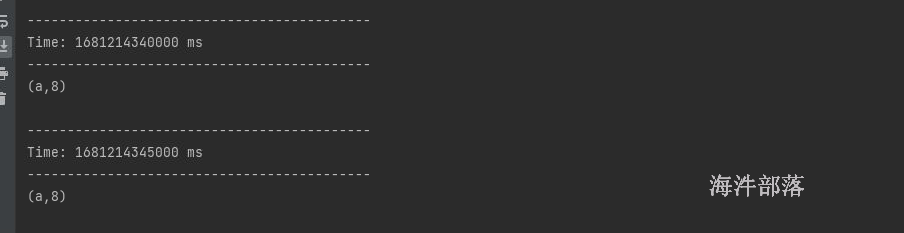
说明先加载checkpoint的数据,然后接收的socket 的流数据。
21.4.4 updateStateByKey只使用最近更新的值
背景:
把流式数据每批次计算的结果持久到MySQL数据库。
用 updateStateByKey,会保留之前批次的数据,更新时,如果每次都要把所有 单词 做更新,效率太低。
如何能只将当前批次的数据做更新,这就需要 批次数据中带有状态,来区分是本次更新的数据还是以前的数据。
代码:
package com.hainiu.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* calculate with state
* keep all result
*/
object TestUpdateStateByKeyWithRecoveryAndCheck {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("updateStateByKey")
conf.setMaster("local[*]")
val ssc = StreamingContext.getOrCreate("file:///headless/workspace/spark/data/ckpt",()=>{
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint("file:///headless/workspace/spark/data/ckpt")
ssc.socketTextStream("nn1", 6666)
.flatMap(_.split(" "))
.map((_, IsUpdateVo(1,false)))
// .reduceByKey(_+_)
.updateStateByKey((curr: Seq[IsUpdateVo], last: Option[IsUpdateVo]) => {
val currnumber = curr.map(_.number).sum
val lastnumber = if(last.isDefined) last.get.number else 0
val result = if(currnumber>0) IsUpdateVo(currnumber+lastnumber,true) else IsUpdateVo(currnumber+lastnumber,false)
Option(result)
})
.print()
ssc
})
ssc.start()
ssc.awaitTermination()
}
}
case class IsUpdateVo(var number:Int,var update:Boolean)
批次数据:

运行结果:
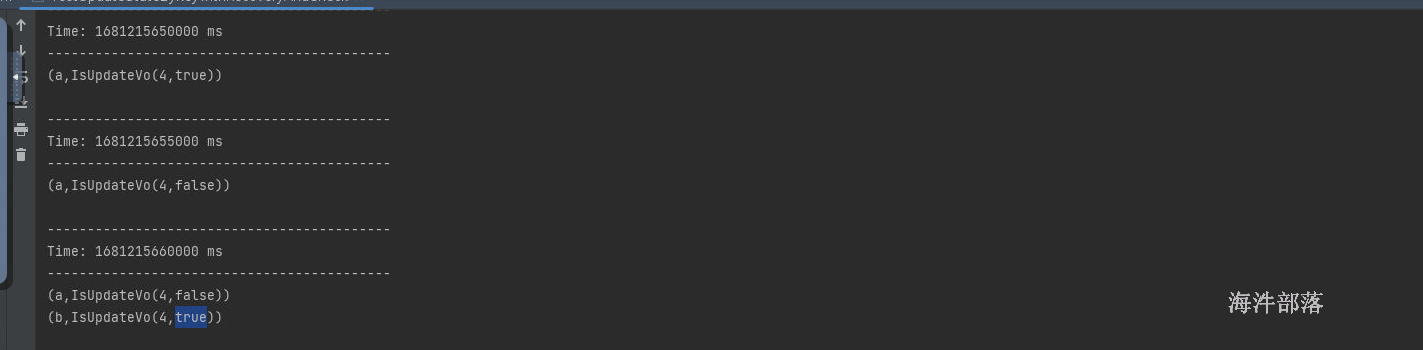
21.4.5 window 操作
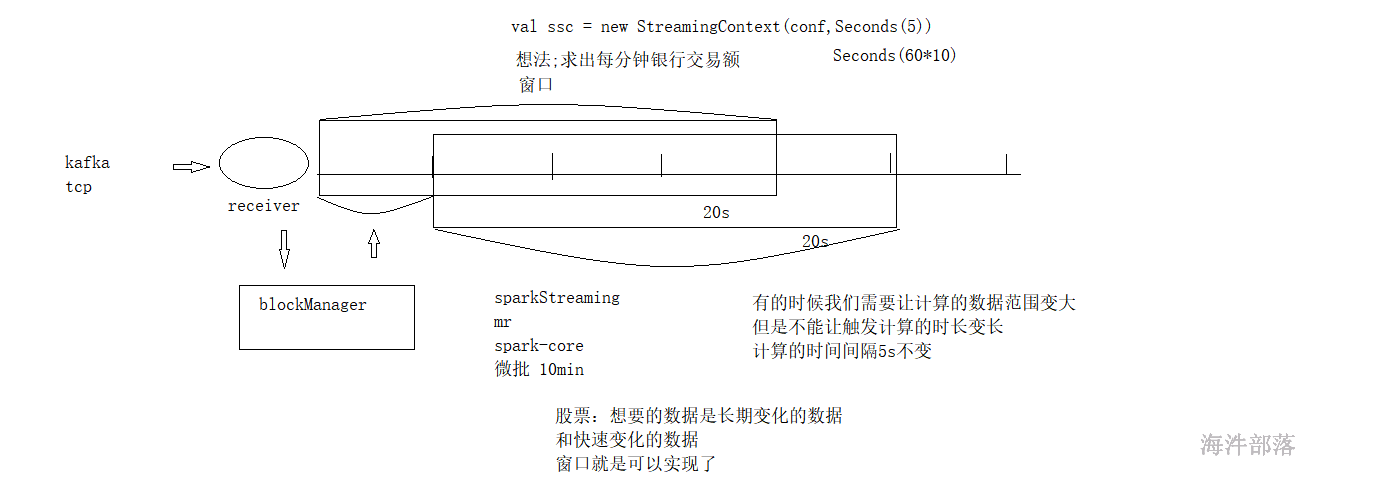
sparkStreaming 支持 window 操作,当你需要跨批次去处理时就可以用,比如:统计过去10分钟的数据做均值、top(热词、热搜等)。
| 转换 | 描述 |
|---|---|
| window(windowLength, slideInterval) | 返回一个基于源DStream的窗口批次计算后得到新的DStream。 |
| countByWindow(windowLength,slideInterval) | 返回基于滑动窗口的DStream中的元素的数量。 |
| reduceByWindow(func, windowLength,slideInterval) | 基于滑动窗口对源DStream中的元素进行聚合操作,得到一个新的DStream。 |
| reduceByKeyAndWindow(func,windowLength,slideInterval, [numTasks]) | 基于滑动窗口对(K,V)键值对类型的DStream中的值按K使用聚合函数func进行聚合操作,得到一个新的DStream。可以进行repartition操作。 |
| reduceByKeyAndWindow(func,invFunc,windowLength, slideInterval, [numTasks]) | 更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作(func),并对离开窗口的老数据进行“逆向reduce” 操作(invFunc)。但是,只能用于“可逆的reduce函数”必须启用“检查点”才能使用此操作 |
| countByValueAndWindow(windowLength,slideInterval, [numTasks]) | 基于滑动窗口计算源DStream中每个RDD内每个元素出现的频次并返回DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素频次。与countByValue一样,reduce任务的数量可以通过一个可选参数进行配置。 |
21.4.5.1 window函数的使用
它是将多个批次的数据结果进行封装,变成一个整体进行执行,其实就是扩大了计算范围
window中的参数,如果设定了窗口大小,默认窗口滑动大小就是批次大小
整体代码如下:
package com.hainiu.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object TestWindow {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("window")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.socketTextStream("nn1",6666)
.window(Seconds(20))
//default sliding = batch-size
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
}
}
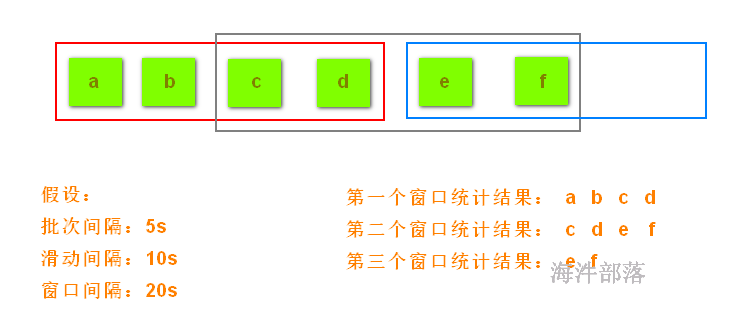
数据的变化逻辑
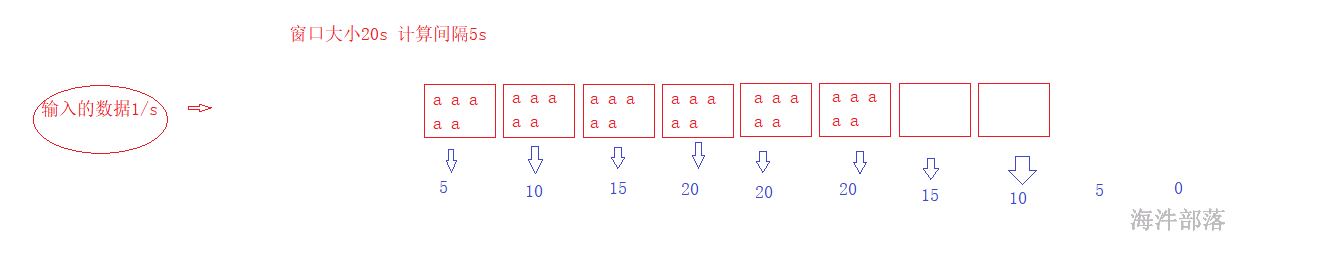
window函数中可以设置窗口大小和滑动大小
但是窗口的大小或者是滑动大小必须是批次间隔的整数倍
window(窗口大小,滑动大小)
object TestWindow {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("window")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.socketTextStream("nn1",6666)
.window(Seconds(20),Seconds(12))
//default sliding = batch-size
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
}
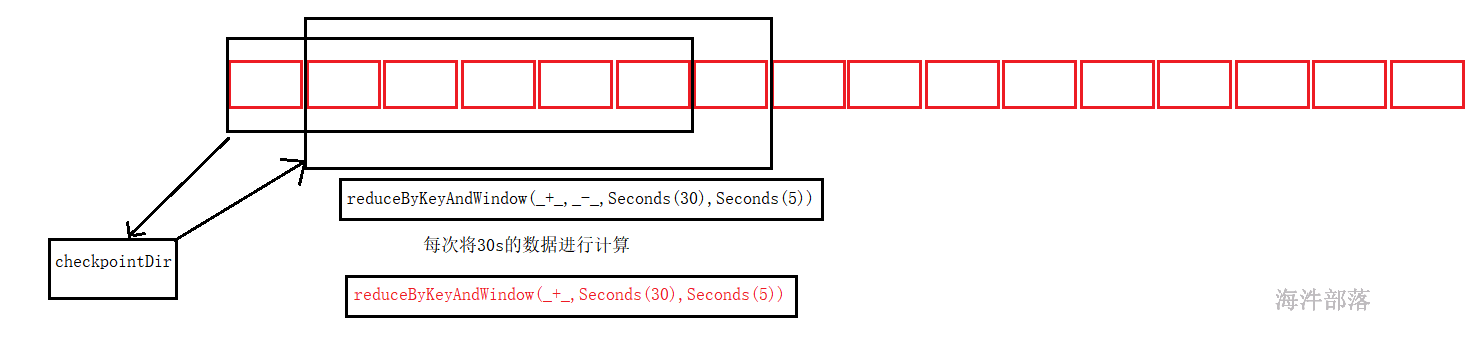
}21.4.5.2 reduceByKeyAndWindow函数的使用
window函数就是将数据进行累加,然后计算其中的结果数据
window进行累加+ reduceByKey进行聚合
简便的写法 reduceByKeyAndWindow()
// .window(Seconds(20))
// .reduceByKey(_+_)
.reduceByKeyAndWindow((a:Int,b:Int)=> a+b,Seconds(20),Seconds(10))整体代码如下:
package com.hainiu.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object TestWindow {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("window")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.checkpoint("file:///headless/workspace/spark/data/ckpt")
ssc.socketTextStream("nn1",6666)
// .window(Seconds(20),Seconds(12))
//default sliding = batch-size
.flatMap(_.split(" "))
.map((_,1))
// .window(Seconds(20))
// .reduceByKey(_+_)
.reduceByKeyAndWindow((a:Int,b:Int)=> a+b,(a:Int,b:Int)=>a-b,Seconds(20),Seconds(10))
.print()
ssc.start()
ssc.awaitTermination()
}
}
21.4.5.3 其他的window算子
整体代码
package com.hainiu.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object TestWindow {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("window")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.checkpoint("file:///headless/workspace/spark/data/ckpt")
val ds = ssc.socketTextStream("nn1", 6666)
.flatMap(_.split(" "))
// ds.window(Seconds(10)).count()
ds.countByWindow(Seconds(10),Seconds(5)).print()
// ds.window(Seconds(10)).countByValue()
ds.countByValueAndWindow(Seconds(10),Seconds(5)).print()
// ds.window(Seconds(10)).reduce((a,b)=> a+"-"+b)
ds.reduceByWindow((a,b)=> a+b,Seconds(10),Seconds(5)).print()
ssc.start()
ssc.awaitTermination()
}
}21.4.5 SparkStreaming 何时使用缓存?何时开启检查点?
分析sparkStreaming 什么时候使用缓存?
1)DStream 和 RDD相似,如果DStream中的数据将被多次计算(例如,对同一数据进行多次操作),这将很有用。可以调用 cache()或 persist() 方法缓存。
2)对于基于窗口的操作reduceByWindow和 reduceByKeyAndWindow和基于状态的操作updateStateByKey,由于窗口的操作生成的DStream会自动保存在内存中,而无需开发人员调用persist()。
分析 sparkStreaming 什么时候开启检查点checkpoint?
1)有状态转换的用法 -如果在应用程序中使用updateStateByKey或reduceByKeyAndWindow(带有反函数),则必须提供checkpoint目录以允许定期进行RDD的checkpoint。
2)从运行应用程序的驱动程序故障中恢复,checkpoint用于恢复进度信息。
包括:
配置:用于创建流应用程序的配置。
DStream 操作:定义流应用程序的一组 DStream 操作。
不完整的批次:作业已排队但尚未完成的批次。
21.4.6 多receiver源union的方式
当数据源多时,有多个数据源就有多个DStream,每个DStream生成自己的任务,为了提高运行效率,可以将多个数据源的流数据union在一起,进而达到减少task的目的。
每个socket 源,都需要有一个receiver接收数据,一个receiver 需要一个CPU核,运行的时候还需要CPU核。
也可以通过本地修改CPU核数,看是否能运行任务
日志提示,且没有CPU核运行任务:
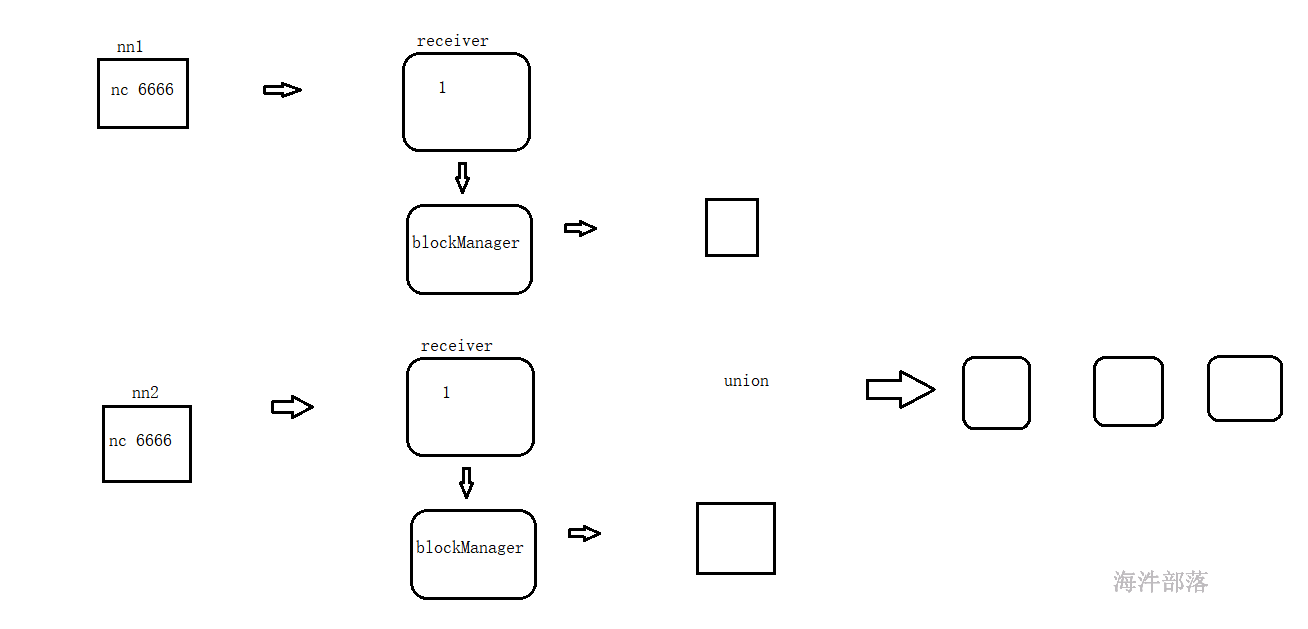
通过 StreamingContext 的 union 方法把多个receiver 源 union到一起。

首先准备nc在nn2机器上
yum -y install nc
nc -l -k -p 66661)先union,再处理
package com.hainiu.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object TestWindow {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("window")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.checkpoint("file:///headless/workspace/spark/data/ckpt")
val ds1 = ssc.socketTextStream("nn1", 6666)
val ds2 = ssc.socketTextStream("nn2", 6666)
//union
val ds3 = ds1.union(ds2)
ds3.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
}
}

2)先加工,再union,然后再处理
package com.hainiu.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object TestWindow {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("window")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.checkpoint("file:///headless/workspace/spark/data/ckpt")
val ds1 = ssc.socketTextStream("nn1", 6666)
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
val ds2 = ssc.socketTextStream("nn2", 6666)
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
//union
ds1.union(ds2).print()
ssc.start()
ssc.awaitTermination()
}
}
21.4.7 SparkStreaming输出到HDFS
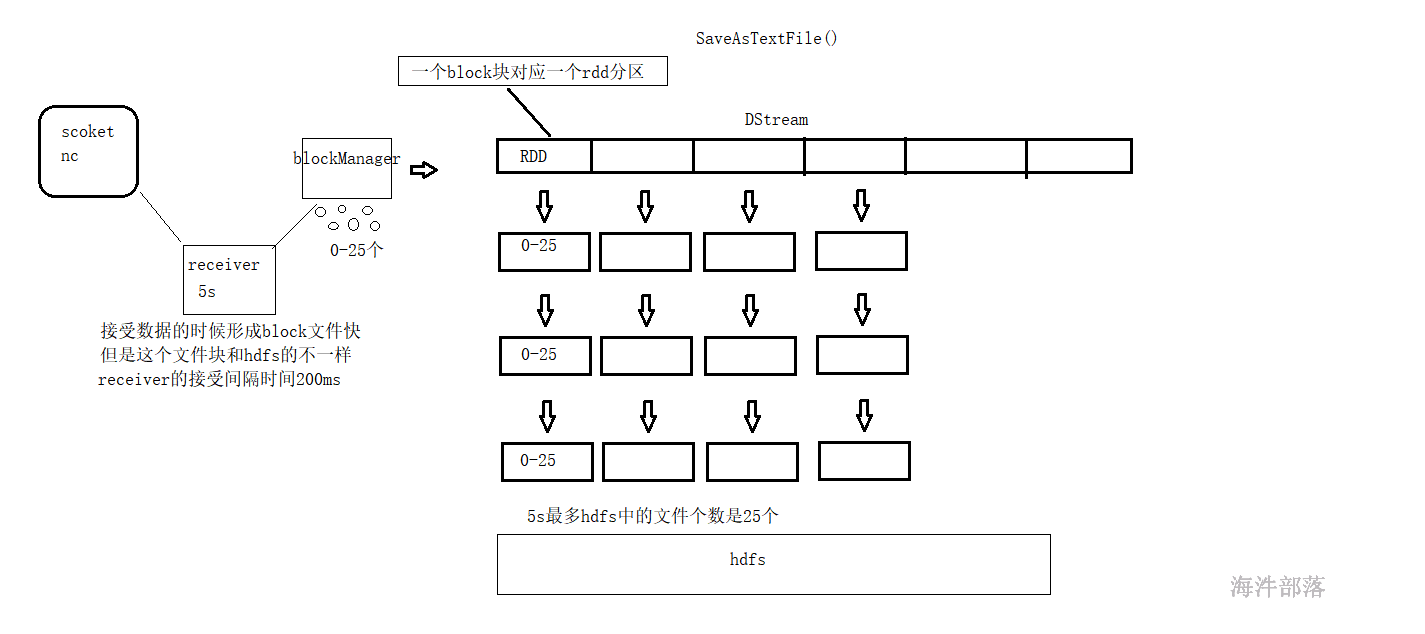
socket 源如何分区?
当从socket 源接收数据时,receiver 会创建数据块。每blockInterval毫秒生成一个新的数据块。在batchInterval期间创建了N个数据块,其中N = batchInterval / blockInterval。
blockInterval 默认是200ms,如果 batchInterval 设置为 2s,理论这个批次会产生 10个分区。如果某个blockInterval 时间内没有数据,则这个blockInterval 时间 就没有产生数据块。也就是说,开启socket源的sparkStreaming程序,如果socket端不喂数据,那这个批次就不会产生数据块,进而分区数是0。

小文件就会带来一系列的问题:
小文件多会占用很大的namenode的元数据空间,下游使用小文件的JOB会产生很多个partition,如果是mr任务就会有很多个map,如果是spark任务就会有很多个task。
如何解决写出小文件问题?
4种方法:
1)增加批次间隔的大小。(不建议使用)
失去了流式计算的意义。
2)使用批处理任务进行小文件的合并。(不建议使用)
需要新开个任务将多个小文件合并成大文件。
3)使用coalesce 减少分区数,进而减少输出小文件的个数。
4)使用HDFS的append方式,追加写入文件中。
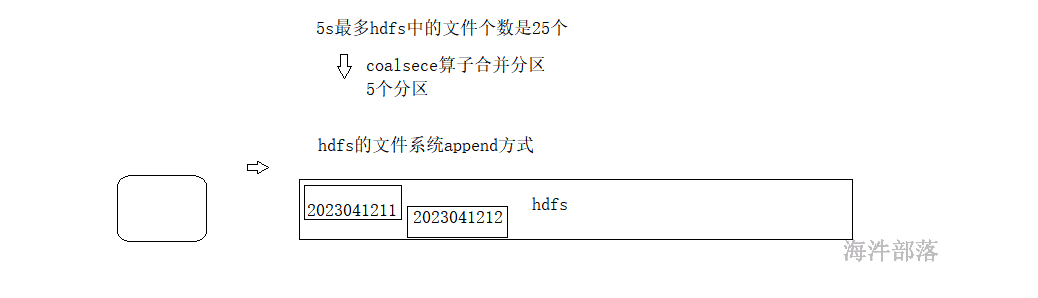
package com.hainiu.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FSDataOutputStream, FileSystem, Path}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import java.io.PrintWriter
import java.text.SimpleDateFormat
import java.util.Date
object Test {
def main(args: Array[String]): Unit = {
val parent_path = "/spark_sink/"
val file_name = "t.txt"
val conf = new SparkConf()
conf.setAppName("test sink")
conf.setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(20))
ssc.socketTextStream("nn1",6666)
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.foreachRDD(rdd=>{
rdd.coalesce(2).mapPartitionsWithIndex((index,it)=>{
val fs = FileSystem.get(new Configuration())
val df = new SimpleDateFormat("yyyy/MM/dd/HH")
val date_str = df.format(new Date())
val all_path = parent_path+date_str+"/"+index+"_"+file_name
var stream: FSDataOutputStream = null
if(fs.exists(new Path(all_path))){
stream = fs.append(new Path(all_path))
}else{
stream = fs.create(new Path(all_path))
}
val pw = new PrintWriter(stream,true)
it.foreach(t=>{
val line = t._1+"->"+t._2
pw.println(line)
})
pw.close()
fs.close()
Iterator.empty
}).foreach((t:String)=>{})
})
ssc.start()
ssc.awaitTermination()
}
}
代码执行
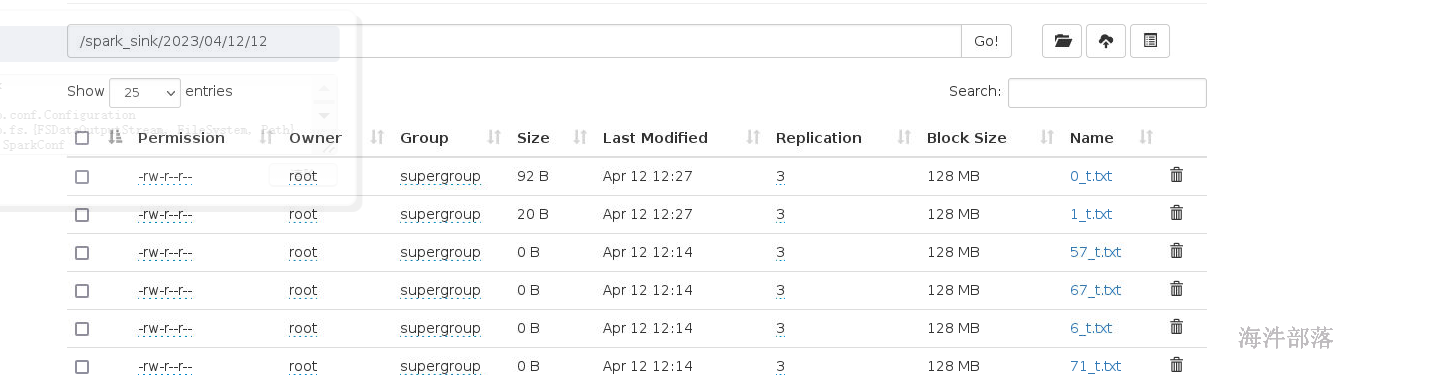
请注意:我们需要调节hdfs的链接的个数,也就是调小分区个数,增加批次间隔,不然会出现连接hdfs的时候因为连接数量过大产生问题,这个是spark的自动反压解决不了的,会出现很多的任务在队列中没办法执行
此段代码的注意点:
-
mapParittionsWithIndex算子实现分区创建链接并且获取分区下标作为文件名
- 使用日期进行格式化替代路径一个小时写入一个文件夹中
- 如果存在就追加不存在就创建
- 使用转换类算子需要返回数据
- 转换类算子需要触发运算执行
最根本的思想就是取出DStream中的RDD然后使用最原始的方式存储数据到外部


