sparkStreaming03
21.5.sparkStreaming接入kafka
21.5.1 spark-streaming-kafka
kafka回顾
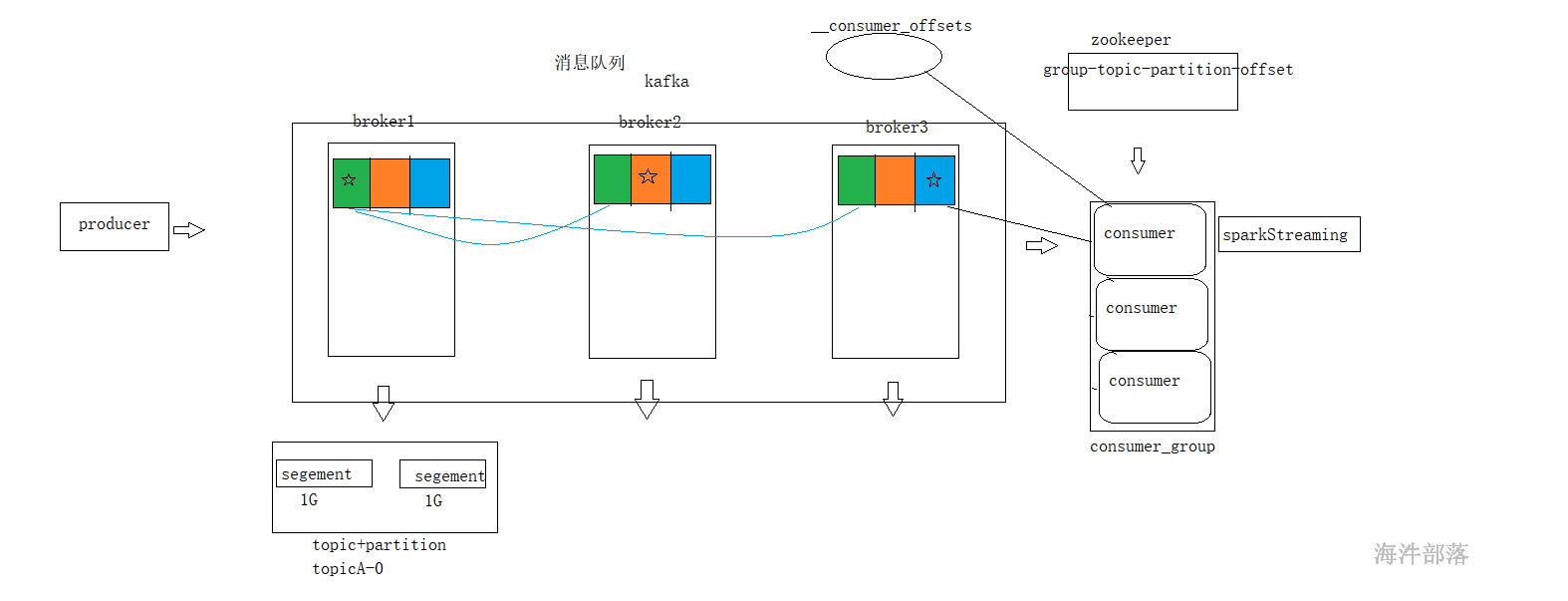
准备环境
创建topic
kafka-topics.sh --bootstrap-server kafka1-24406:9092 --create --topic topic_hainiu --partitions 3 --replication-factor 2
kafka读取数据的配置
sparkStreaming 读kafka,有两种方式,一种读zookeeper(现有版本已抛弃),一种读broker,也就是kafka直连流方式。
1)位置策略
Spark Streaming 中提供了如下三种位置策略,用于指定 Kafka 主题分区与 Spark 执行程序 Executors 之间的分配关系:
PreferConsistent : 它将在所有的 Executors 上均匀分配分区;
PreferBrokers : 当 Spark 的 Executor 与 Kafka Broker 在同一机器上时可以选择该选项,它优先将该 Broker 上的首领分区分配给该机器上的 Executor;
PreferFixed : 可以指定主题分区与特定主机的映射关系,显示地将分区分配到特定的主机,其构造器如下:
@Experimental
def PreferFixed(hostMap: collection.Map[TopicPartition, String]): LocationStrategy =
new PreferFixed(new ju.HashMap[TopicPartition, String](hostMap.asJava))
@Experimental
def PreferFixed(hostMap: ju.Map[TopicPartition, String]): LocationStrategy =
new PreferFixed(hostMap)2)消费策略
订阅和分配。
订阅:可订阅一个主题所有分区或多个主题所有分区。
分配:可消费指定主题分区数据。
Spark Streaming 提供了两种主题订阅方式,分别为 Subscribe 和 SubscribePattern。后者可以使用正则匹配订阅主题的名称。其构造器分别如下:
/**
\* @param topics 需要订阅的主题的集合
\* @param Kafka 消费者参数
\* @param offsets(可选): 在初始启动时开始的偏移量。如果没有,则将使用保存的偏移量或 auto.offset.reset 属性的值
*/
def Subscribe[K, V](
topics: ju.Collection[jl.String],
kafkaParams: ju.Map[String, Object],
offsets: ju.Map[TopicPartition, jl.Long]): ConsumerStrategy[K, V] = { ... }
/**
\* @param pattern需要订阅的正则
\* @param Kafka 消费者参数
\* @param offsets(可选): 在初始启动时开始的偏移量。如果没有,则将使用保存的偏移量或 auto.offset.reset 属性的值
*/
def SubscribePattern[K, V](
pattern: ju.regex.Pattern,
kafkaParams: collection.Map[String, Object],
offsets: collection.Map[TopicPartition, Long]): ConsumerStrategy[K, V] = { ... }3)程序代码
package com.hainiu.spark
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 1.kafka params
* 2.topic
* 3.subsribe
* 4.calculate
*/
object Testkafka {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("kafka").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(2))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "kafka1-24406:9092,kafka2-24406:9092,kafka3-24406:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "sparkStreaming",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topic_hainiu")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
//stream ==> topic partition offset k v
stream.map(_.value()).print()
ssc.start()
ssc.awaitTermination()
}
}
测试输入数据
kafka-console-producer.sh --bootstrap-server kafka1-24406:9092 --topic topic_hainiu 
idea打印数据

21.5.2 SparkStreaming动态更新广播变量
广播变量
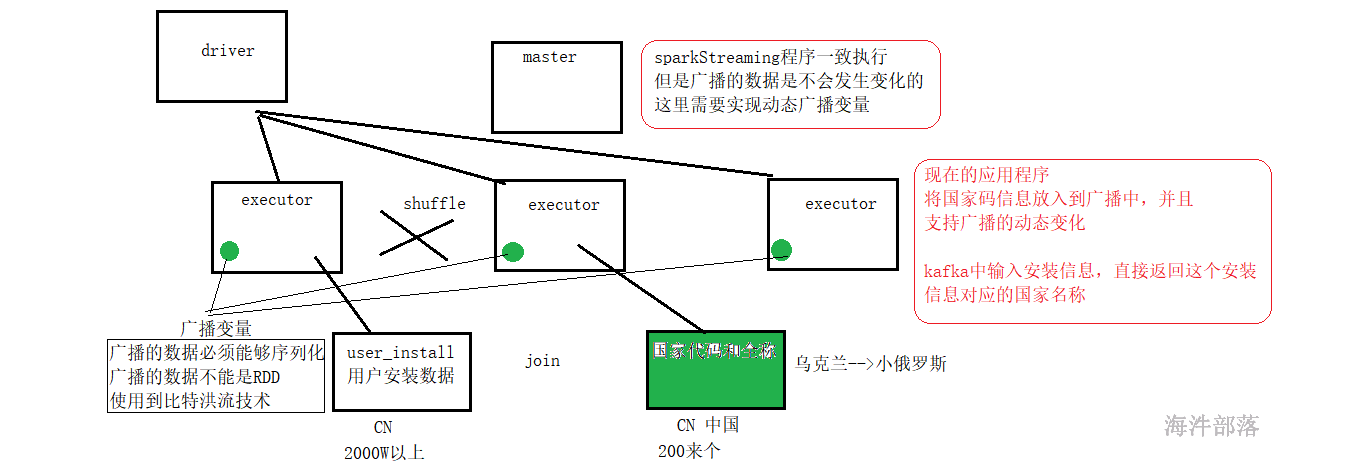
所以我们需要实现动态广播技术
准备数据从/public/data/country_data中复制country.txt到idea中
并且拆分一个国家信息文件为两个,将这个文件夹中的数据作为广播

整体代码如下:
package com.hainiu.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Seconds, StreamingContext}
import java.util.Scanner
import scala.collection.mutable
/**
* 1.kafka params
* 2.topic
* 3.subsribe
* 4.calculate
*/
object TestkafkaWithDynamicBroadcast {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("kafka").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(2))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "kafka1-24406:9092,kafka2-24406:9092,kafka3-24406:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "sparkStreaming",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topic_hainiu")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
//stream ==> topic partition offset k v
val fs = FileSystem.getLocal(new Configuration())
val map = mutable.Map[String,String]()
var bs = ssc.sparkContext.broadcast(map)
val interval = 10000
var lastUpdateTime = 0L
stream.map(_.value())
.foreachRDD(rdd=>{
//driver
if(bs.value.isEmpty || System.currentTimeMillis() - lastUpdateTime > interval){
val statuses = fs.listStatus(new Path("data/country"))
statuses.foreach(t=>{
val in = fs.open(t.getPath)
val scanner = new Scanner(in)
while(scanner.hasNext()){
val line = scanner.nextLine()
val strs = line.split("\t")
map.put(strs(0),strs(1))
}
in.close()
})
bs.unpersist()
bs = ssc.sparkContext.broadcast(map)
lastUpdateTime = System.currentTimeMillis()
}
rdd.map(code=>{
bs.value.getOrElse(code,"unknow")
}).foreach(println)
})
ssc.start()
ssc.awaitTermination()
}
}
将CN改为中华人民共和国

21.5.3 sparkStreaming-kafka的offset管理
21.5.3.1 receiver方式 vs 直连方式
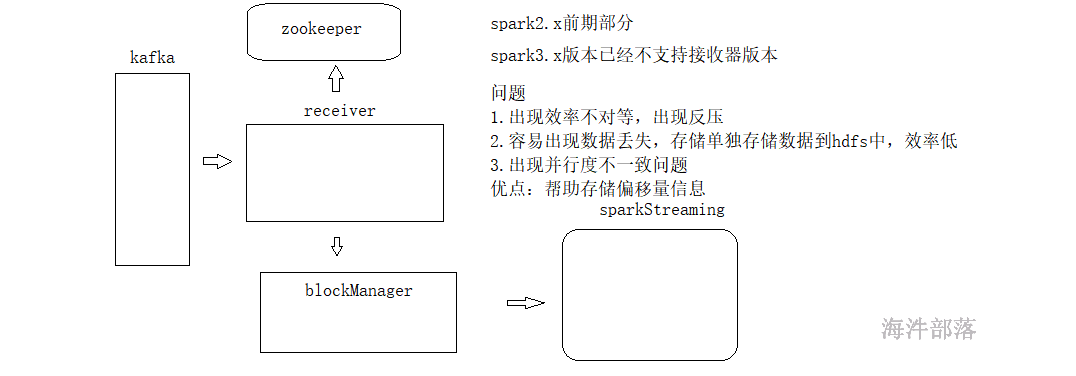
sparkStreaming-kafka 的 receiver 方式
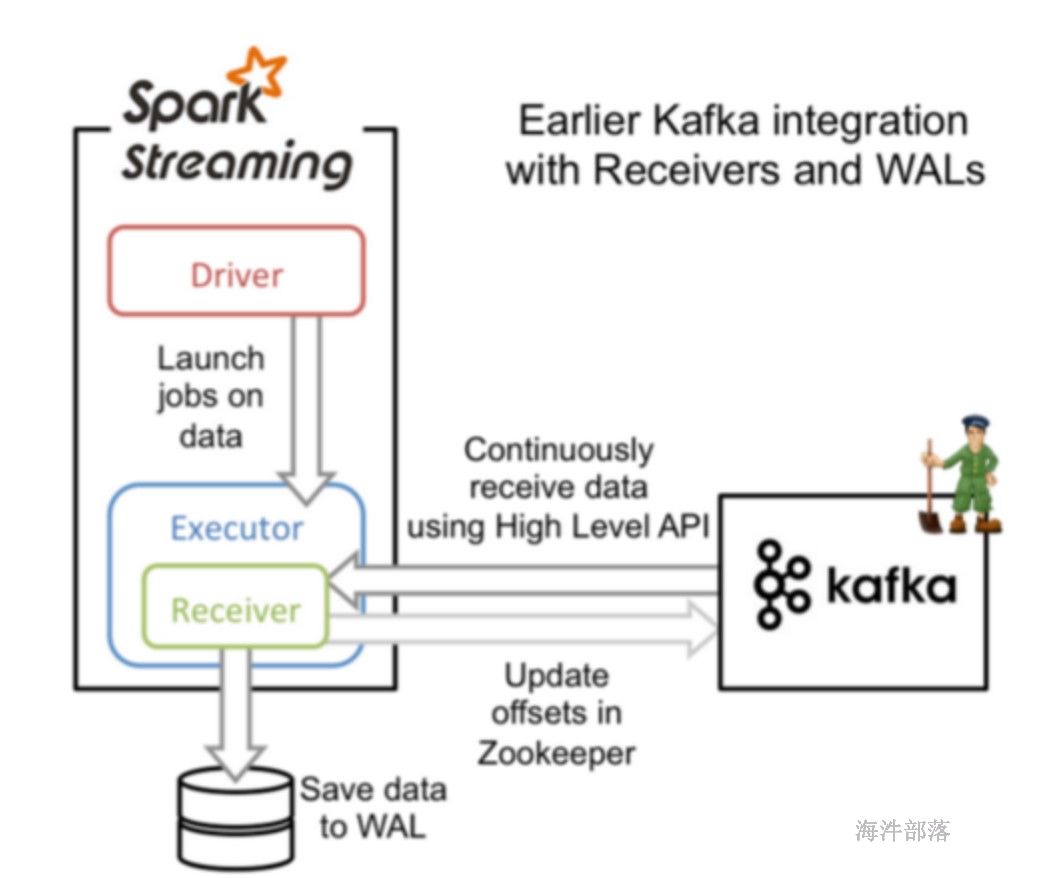
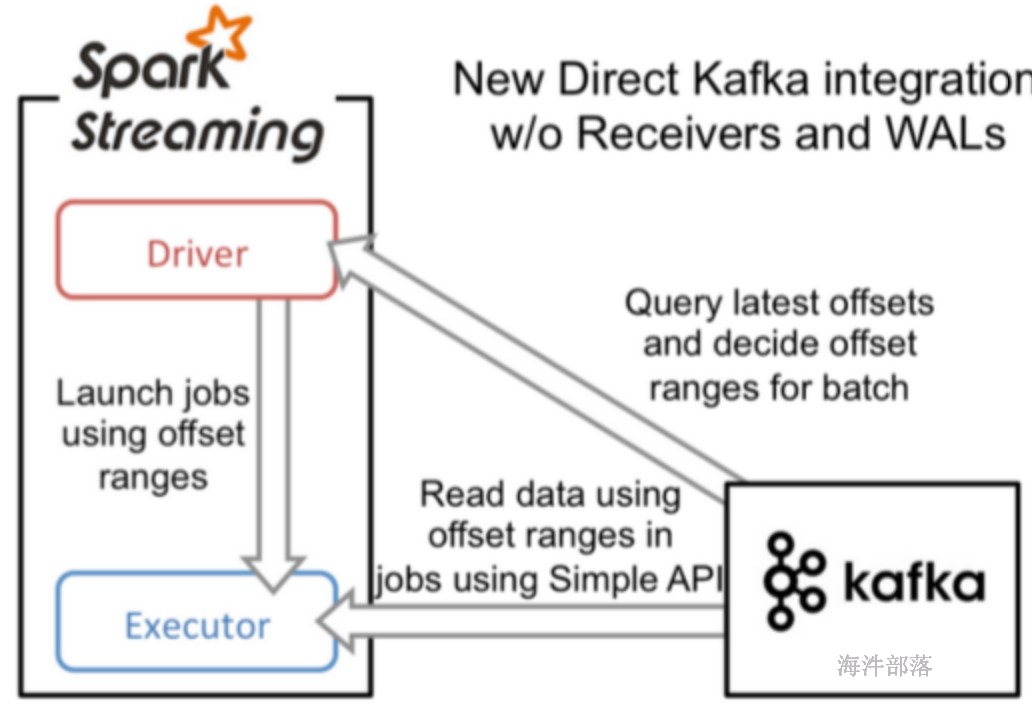
sparkStreaming-kafka 的 Direct 方式
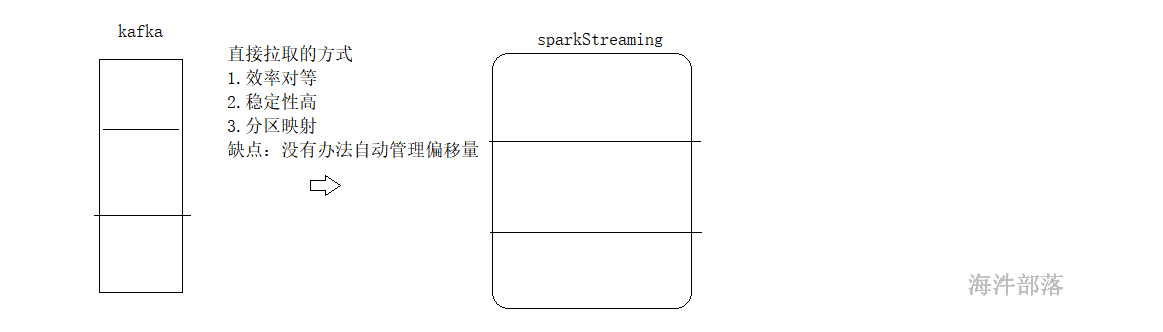
receiver 和 direct 方式有什么区别?
receiver 方式:
receiver把固定间隔的数据放在内存中,使用kafka高级的API,自动维护偏移量,达到固定的时间一起处理每个批次的offset数据,效率低且容易丢数据,因为数据在内存中,为了容错,还得加入预写日志。
Direct 直连方式:
会周期性地查询Kafka,获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
此种方式相当于直接连接到kafka的分区上(无需receiver,也不需要预写日志),一个RDD的分区对应一个Kafka的分区,使用Kafka底层的API去读取数据,效率高。
流式计算有三种容错语义,分别是:
at-most-once(最多一次):每条记录将被处理一次或根本不处理。
at-least-once(至少一次):每条记录将被处理一次或多次。这比最多一次强,因为它确保不会丢失任何数据。但可能有重复。
Exactly once(只处理一次):每条记录只会被处理一次 - 不会丢失任何数据,也不会多次处理数据。这显然是三者中最强的保证。
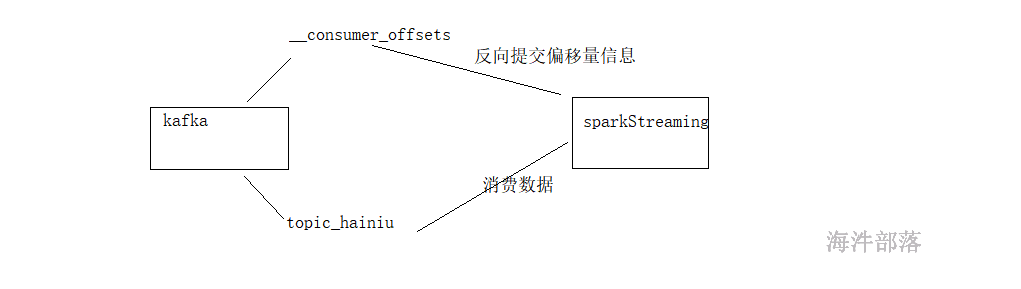
SparkStreaming直连kafka可以保证时效最强语义,但需要我们自己去维护偏移量(现在比较流行的方式是手动把offset维护到第三方存储,比如zookeeper、MySQL等。)。
如果想实现最强语义,需要做到以下几点:
1)kafka源支持重复读取。
2)SparkStreaming的输出要支持幂等性或事务。
幂等性:输出多次的操作内容是一样的。
事务:将输出和维护offset放在一个事务中,要么都成功,要么都失败。
3)需要我们自己手动去维护消费的offset。
总结下来就是:
直连kafka,kafka的offset 由 开发者自己维护,获取要消费的offset,进行消费处理,处理完成后,自行维护offset,输出要支持幂等性或事务。
http://spark.apache.org/docs/2.1.1/streaming-kafka-integration.html
例子见如下代码
21.5.3.2 receiver方式管理offset
代码:SparkStreamingKafkaStream
目前被直连方式替代,代码看看即可。
21.5.3.3 direct方式管理offset
21.5.3.3.1手动提交offset到kafka
代码:SparkStreamingKafkaOffsetNotAutoCommit
代码逻辑:

整体代码:
package com.hainiu.spark
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.{CanCommitOffsets, HasOffsetRanges, KafkaUtils}
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 1.kafka params
* 2.topic
* 3.subsribe
* 4.calculate
*/
object Testkafka {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("kafka").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(2))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "kafka1-24406:9092,kafka2-24406:9092,kafka3-24406:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "sparkStreaming1",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topic_hainiu")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
//stream ==> topic partition offset k v
// stream.map(_.value()).print()
stream.foreachRDD(rdd=>{
val ranges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd.foreach(println)
stream.asInstanceOf[CanCommitOffsets].commitAsync(ranges)
})
ssc.start()
ssc.awaitTermination()
}
}
21.5.3.3.2手动提交offset到zookeeper(外部存储系统)
代码:SparkStreamingKafkaOffsetZKForeachRDD
代码逻辑:

整体代码:
package com.hainiu.spark.offset
import kafka.utils.{ZKGroupTopicDirs, ZkUtils}
import org.I0Itec.zkclient.ZkClient
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.{Durations, StreamingContext}
import scala.collection.mutable.HashMap
/**
* 偏移量保存到zk中
* 不使用DStream的transform等其它算子
* 将DStream数据处理方式转成纯正的spark-core的数据处理方式
*/
object SparkStreamingKafkaOffsetZKForeachRDD {
def main(args: Array[String]): Unit = {
//指定组名
val group = "groupxxx"
//创建SparkConf
val conf = new SparkConf().setAppName("SparkStreamingKafkaOffsetZK").setMaster("local[*]")
//创建SparkStreaming,设置间隔时间
val ssc = new StreamingContext(conf, Durations.seconds(5))
//指定 topic 名字
val topic = "topic_41"
//指定kafka的broker地址,SparkStream的Task直连到kafka的分区上,用底层的API消费,效率更高
// val brokerList = "s1.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092"
val brokerList = "s1.hadoop:9092"
//指定zk的地址,更新消费的偏移量时使用,当然也可以使用Redis和MySQL来记录偏移量
val zkQuorum = "nn1.hadoop:2181"
//SparkStreaming时使用的topic集合,可同时消费多个topic
val topics: Set[String] = Set(topic)
//topic在zk里的数据路径,用于保存偏移量
val topicDirs = new ZKGroupTopicDirs(group, topic)
//得到zk中的数据路径 例如:"/consumers/${group}/offsets/${topic}"
val zkTopicPath = s"${topicDirs.consumerOffsetDir}"
//kafka参数
val kafkaParams = Map(
"bootstrap.servers" -> brokerList,
"group.id" -> group,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"enable.auto.commit" -> (false: java.lang.Boolean),
//earliest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
//latest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
//none topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
"auto.offset.reset" -> "latest"
)
//定义一个空的kafkaStream,之后根据是否有历史的偏移量进行选择
var kafkaStream: InputDStream[ConsumerRecord[String, String]] = null
//如果存在历史的偏移量,那使用fromOffsets来存放存储在zk中的每个TopicPartition对应的offset
var fromOffsets = new HashMap[TopicPartition, Long]
//创建zk客户端,可以从zk中读取偏移量数据,并更新偏移量
val zkClient = new ZkClient(zkQuorum)
//从zk中查询该数据路径下是否有每个partition的offset,这个offset是我们自己根据每个topic的不同partition生成的
//数据路径例子:/consumers/${group}/offsets/${topic}/${partitionId}/${offset}"
//zkTopicPath = /consumers/group1311/offsets/hainiu_test/
// /consumers/groupid/offsets/topic
//路径 /consumers/g3/topic_42/0 --> 100
//路径 /consumers/g3/topic_42/1 --> 100
//路径 /consumers/g3/topic_42/2 --> 100
val children = zkClient.countChildren(zkTopicPath)//3
//判断zk中是否保存过历史的offset
if (children > 0) {
for (i <- 0 until children) {
// /consumers/group100/offsets/hainiu_html/0
// get /consumers/lishuai38/offsets/hainiu_html/44
val partitionOffset = zkClient.readData[String](s"$zkTopicPath/${i}")
// hainiu_html/0
val tp = new TopicPartition(topic, i)
//将每个partition对应的offset保存到fromOffsets中
// hainiu_html/0 -> 888
fromOffsets += tp -> partitionOffset.toLong
}
// println(fromOffsets)
//通过KafkaUtils创建直连的DStream,并使用fromOffsets中存储的历史偏离量来继续消费数据
kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams, fromOffsets))
} else {
//如果zk中没有该topic的历史offset,那就根据kafkaParam的配置使用最新(latest)或者最旧的(earliest)的offset
kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams))
}
//通过rdd转换得到偏移量的范围
var offsetRanges = Array[OffsetRange]()
//迭代DStream中的RDD,将每一个时间间隔对应的RDD拿出来,这个方法是在driver端执行
//在foreachRDD方法中就跟开发spark-core是同样的流程了,当然也可以使用spark-sql
kafkaStream.foreachRDD((kafkaRDD, time) => {
if (!kafkaRDD.isEmpty()) {
//得到该RDD对应kafka消息的offset,该RDD是一个KafkaRDD,所以可以获得偏移量的范围
//不使用transform可以直接在foreachRDD中得到这个RDD的偏移量,这种方法适用于DStream不经过任何的转换,
//直接进行foreachRDD,因为如果transformation了那就不是KafkaRDD了,就不能强转成HasOffsetRanges了,从而就得不到kafka的偏移量了
offsetRanges = kafkaRDD.asInstanceOf[HasOffsetRanges].offsetRanges
val dataRDD: RDD[String] = kafkaRDD.map(_.value())
//执行这个rdd的aciton,这里rdd的算子是在集群上执行的
dataRDD.foreachPartition(partition =>
partition.foreach(x => {
println(x)
})
)
// 将最新的offset更新到zookeeper外部存储
for (o <- offsetRanges) {
// /consumers/group100/offsets/hainiu_html/0
val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}"
//将该 partition 的 offset 保存到 zookeeper
// /consumers/group100/offsets/hainiu_html/12
println(s"time:${time}==>维护到zk的offset是:${zkPath}__${o.untilOffset.toString}")
ZkUtils(zkClient, false).updatePersistentPath(zkPath, o.untilOffset.toString)
}
}
})
ssc.start()
ssc.awaitTermination()
}
}修改组id ,zookeeper的地址使用的是spark的集群的zk,kafka集群的地址
执行代码输入kafka中的数据
在nn1机器节点中进入zookeeper中查询偏移量信息
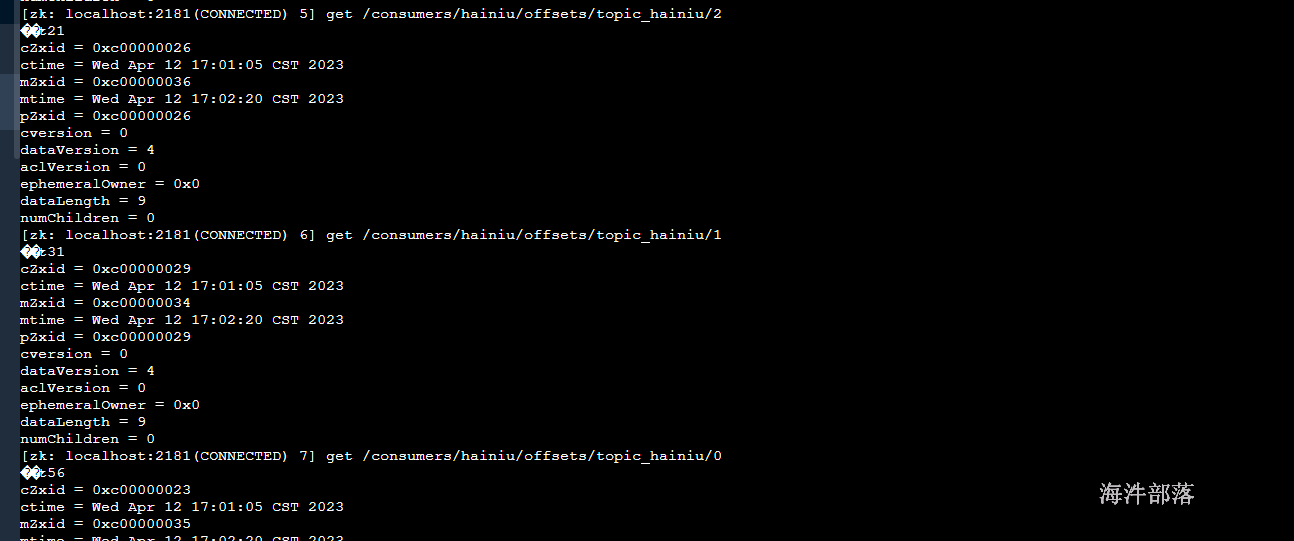
21.5.3.3.3 解决数据丢失的时候,程序启动问题
Kafka的数据默认保存7天,如果zookeeper里维护的是7天前数据的消费offset,当启动程序时会报错,如何解决?
说明:
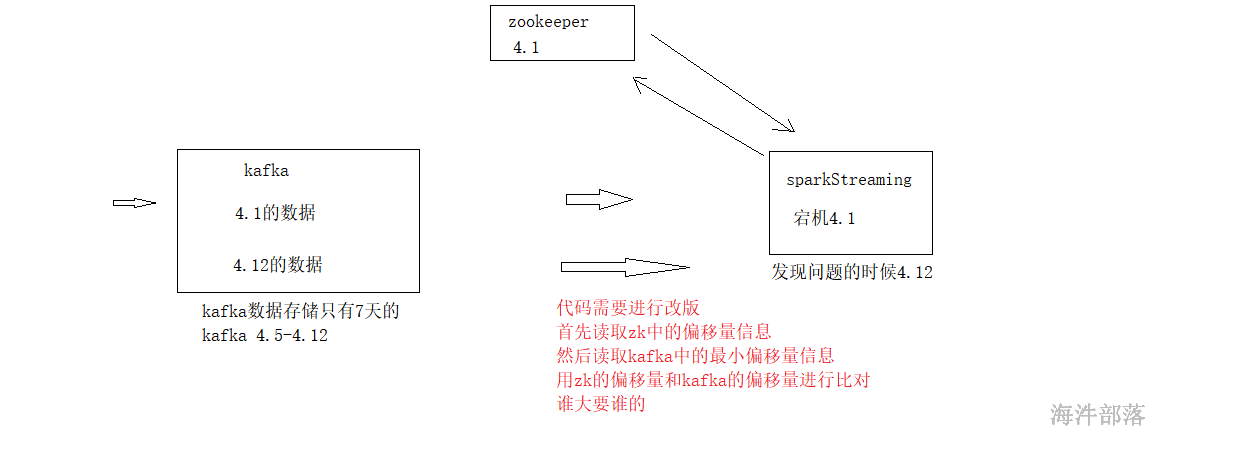
代码逻辑:

整体代码
package com.hainiu.spark.offset
import kafka.utils.{ZKGroupTopicDirs, ZkUtils}
import org.I0Itec.zkclient.ZkClient
import org.apache.kafka.clients.consumer.{ConsumerRecord, KafkaConsumer}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.kafka.common.{PartitionInfo, TopicPartition}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.{Durations, StreamingContext}
import java.{lang, util}
import scala.collection.mutable.{HashMap, ListBuffer}
/**
* 偏移量保存到zk中
* 不使用DStream的transform等其它算子
* 将DStream数据处理方式转成纯正的spark-core的数据处理方式
* 由于SparkStreaming程序长时间中断,再次消费时kafka中数据已过时,
* 上次记录消费的offset已丢失的问题处理
*/
object SparkStreamingKafkaOffsetZKRecovery {
def main(args: Array[String]): Unit = {
//指定组名
val group = "group40"
//创建SparkConf
val conf = new SparkConf().setAppName("SparkStreamingKafkaOffsetZKRecovery").setMaster("local[*]")
//创建SparkStreaming,设置间隔时间
val ssc = new StreamingContext(conf, Durations.seconds(5))
//指定 topic 名字
val topic = "topic_41"
//指定kafka的broker地址,SparkStream的Task直连到kafka的分区上,用底层的API消费,效率更高
// val brokerList = "s1.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092"
val brokerList = "s1.hadoop:9092"
//指定zk的地址,更新消费的偏移量时使用,当然也可以使用Redis和MySQL来记录偏移量
val zkQuorum = "nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181"
//SparkStreaming时使用的topic集合,可同时消费多个topic
val topics: Set[String] = Set(topic)
//topic在zk里的数据路径,用于保存偏移量
val topicDirs = new ZKGroupTopicDirs(group, topic)
//得到zk中的数据路径 例如:"/consumers/${group}/offsets/${topic}"
val zkTopicPath = s"${topicDirs.consumerOffsetDir}"
//kafka参数
val kafkaParams = Map(
"bootstrap.servers" -> brokerList,
"group.id" -> group,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"enable.auto.commit" -> (false: java.lang.Boolean),
//earliest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
//latest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
//none topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
"auto.offset.reset" -> "earliest"
)
//定义一个空的kafkaStream,之后根据是否有历史的偏移量进行选择
var kafkaStream: InputDStream[ConsumerRecord[String, String]] = null
//如果存在历史的偏移量,那使用fromOffsets来存放存储在zk中的每个TopicPartition对应的offset
// 是外部存储zookeeper存的offset
val zkOffsetMap = new HashMap[TopicPartition, Long]
//创建zk客户端,可以从zk中读取偏移量数据,并更新偏移量
val zkClient = new ZkClient(zkQuorum)
//从zk中查询该数据路径下是否有每个partition的offset,这个offset是我们自己根据每个topic的不同partition生成的
//数据路径例子:/consumers/${group}/offsets/${topic}/${partitionId}/${offset}"
//zkTopicPath = /consumers/group100/offsets/hainiu_html/
val children = zkClient.countChildren(zkTopicPath)
//判断zk中是否保存过历史的offset
if (children > 0) {
for (i <- 0 until children) {
// /consumers/group100/offsets/hainiu_html/0
val partitionOffset = zkClient.readData[String](s"$zkTopicPath/${i}")
// hainiu_html/0
val tp = new TopicPartition(topic, i)
//将每个partition对应的offset保存到fromOffsets中
// hainiu_html/0 -> 888
zkOffsetMap += tp -> partitionOffset.toLong
}
println("-------consumer zookeeper offset---------------")
println(zkOffsetMap)
/*
通过kafkaConsumer对象,获取对应topic所有分区的kafka 数据最早的offset
*/
// 创建kafkaConsumer对象
import scala.collection.convert.ImplicitConversionsToJava.`map AsJavaMap`
val kafkaConsumer = new KafkaConsumer(kafkaParams)
// 获取topic的所有分区信息,主要拿到每个分区的编号
val kafkaPartitionInfoList: util.List[PartitionInfo] = kafkaConsumer.partitionsFor(topic)
import scala.collection.convert.ImplicitConversions.`collection AsScalaIterable`
val kafkaTopicPartitions = new ListBuffer[TopicPartition]
for(f <- kafkaPartitionInfoList){
val topicName: String = f.topic()
val partitionId: Int = f.partition()
kafkaTopicPartitions += new TopicPartition(topicName, partitionId)
}
// 根据每个分区编号获取每个分区中,kafka数据最早的offset
import scala.collection.convert.ImplicitConversionsToJava.`collection asJava`
val kafkaDataEarliestOffsetMap: util.Map[TopicPartition, lang.Long] = kafkaConsumer.beginningOffsets(kafkaTopicPartitions)
println("-----kafka data Earliest offset----------------")
println(kafkaDataEarliestOffsetMap)
/*
通过 zkOffset 与 kafkaDataEarliestOffset 做对比来修正 zkOffset
用于解决SparkStreaming程序长时间中断,再次消费时已记录的offset丢失导致程序启动报错问题
*/
import scala.collection.convert.ImplicitConversions.`map AsScala`
// 外循环是kafkaDataOffset,内循环是zkOffset
for((tp, value) <- kafkaDataEarliestOffsetMap){
val partitionId: Int = tp.partition()
val dataOffset: lang.Long = value
val option: Option[Long] = zkOffsetMap.get(tp)
// kafka 有的分区,但zk 没有, 给zk新增分区
if (option == None) {
zkOffsetMap += (tp -> dataOffset)
} else {
var zkOffset: Long = option.get
if (zkOffset < dataOffset) {
zkOffset = dataOffset
zkOffsetMap += (tp -> zkOffset)
}
}
}
println("----修正后的 zkOffset--------------")
println(zkOffsetMap)
//通过KafkaUtils创建直连的DStream,并使用fromOffsets中存储的历史偏离量来继续消费数据
kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams, zkOffsetMap))
} else {
//如果zk中没有该topic的历史offset,那就根据kafkaParam的配置使用最新(latest)或者最旧的(earliest)的offset
kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams))
}
//通过rdd转换得到偏移量的范围
var offsetRanges = Array[OffsetRange]()
//迭代DStream中的RDD,将每一个时间间隔对应的RDD拿出来,这个方法是在driver端执行
//在foreachRDD方法中就跟开发spark-core是同样的流程了,当然也可以使用spark-sql
kafkaStream.foreachRDD(kafkaRDD => {
if (!kafkaRDD.isEmpty()) {
//得到该RDD对应kafka消息的offset,该RDD是一个KafkaRDD,所以可以获得偏移量的范围
//不使用transform可以直接在foreachRDD中得到这个RDD的偏移量,这种方法适用于DStream不经过任何的转换,
//直接进行foreachRDD,因为如果transformation了那就不是KafkaRDD了,就不能强转成HasOffsetRanges了,从而就得不到kafka的偏移量了
offsetRanges = kafkaRDD.asInstanceOf[HasOffsetRanges].offsetRanges
val dataRDD: RDD[String] = kafkaRDD.map(_.value())
// 加载广播变量
// 初始化累加器
//执行这个rdd的aciton,这里rdd的算子是在集群上执行的
dataRDD.foreachPartition(partition =>
// executor 运行的业务在这里写
partition.foreach(x => {
println(x)
})
)
//累加器统计结果写入MySQL
for (o <- offsetRanges) {
// /consumers/group100/offsets/hainiu_html/0
val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}"
//将该 partition 的 offset 保存到 zookeeper
// /consumers/group100/offsets/hainiu_html/888
println(s"${zkPath}__${o.untilOffset.toString}")
ZkUtils(zkClient, false).updatePersistentPath(zkPath, o.untilOffset.toString)
}
}
})
ssc.start()
ssc.awaitTermination()
}
}
修改zk地址,kafka地址,groupid
运行结果如下:



