spark优化01 22 Spark优化汇总
由于大多数Spark计算的内存性质,Spark程序可能会受到集群中任何资源(CPU,网络带宽或内存)的瓶颈。Spark优化主要是围绕着这几个瓶颈展开,优化方式包括序列化调优、内存调优等。
22.1 数据序列化
在任何分布式系统中,序列化都是扮演着一个重要的角色的。如果使用的序列化技术,在执行序列化操作的时候很慢,或者是序列化后的数据还是很大,那么会让分布式应用程序的性能下降很多。所以,进行Spark性能优化的第一步,就是进行序列化的性能优化。
Spark 旨在便利性(允许您在操作中使用任何 Java 类型)和性能之间取得平衡。它提供了两个序列化库:
Java 序列化机制:
默认情况下,spark使用此种机制。
默认情况下,Spark使用Java自身的ObjectInputStream和ObjectOutputStream机制进行对象的序列化。而且Java序列化机制是提供了自定义序列化支持的,只要你实现Serializable接口即可实现自己的更高性能的序列化算法。Java序列化机制的速度比较慢,而且序列化后的数据占用的内存空间比较大。
Kryo 序列化机制:
Spark也支持使用Kryo类库来进行序列化。Kryo序列化机制比Java序列化机制更快,而且序列化后的数据占用的空间更小,通常比Java序列化的数据占用的空间要小10倍。Kryo序列化机制之所以不是默认序列化机制的原因是,有些类型它也不一定能够进行序列化;此外,如果你要得到最佳的性能,Kryo还要求你在Spark应用程序中,对所有你需要序列化的类型都进行注册。
如何使用Kryo 序列化机制

优化Kryo 类库的使用
1)优化缓存大小
如果注册的要序列化的自定义的类型,本身特别大,比如包含了超过100个field。那么就会导致要序列化的对象过大。此时就需要对Kryo本身进行优化。因为Kryo内部的缓存可能不够存放那么大的class对象。此时就需要调用SparkConf.set()方法,设置spark.kryoserializer.buffer.max参数的值,将其调大。
默认情况下它的值是64,就是说最大能缓存64M的对象,然后进行序列化。可以在必要时将其调大。
2)预先注册自定义类型
使用自定义类型时需要预先注册好要序列化的自定义的类。
在什么场景下使用Kryo 序列化类库?
1)从 Spark 2.0.0 开始,在内部使用 Kryo 序列化程序来对具有简单类型、简单类型数组或字符串类型的 RDD 进行shuffle。
2)在你的算子中使用了别人实现写的且没有实现Serializable,比如hadoop的Text。
3)算子函数使用到了外部的大对象情况。比如我们在外部自定义了一个Map对象,里面包含了100m的数据。然后,在算子函数里面,使用到了这个外部的大对象。此时用广播变量替代大对象。
22.2 内存调优
22.2.1 内存都花费在哪了
1)每个Java对象,都有一个对象头,会占用16个字节,主要是包括了一些对象的元信息,比如指向它的类的指针。如果一个对象本身很小,比如就包括了一个int类型的field,那么它的对象头实际上比对象自己还要大。
JAVA对象 = 对象头 + 实例数据 + 对象填充(补余用的,用于保证对象所占空间是8个字节的整数倍)
2)Java的String对象,会比它内部的原始数据,要多出40个字节。因为它内部使用char数组来保存内部的字符序列的,并且还得保存诸如数组长度之类的信息。而且因为String使用的是UTF-16编码,所以每个字符会占用2个字节。比如,包含10个字符的String,会占用60个字节。
3)Java中的集合类型,比如HashMap和LinkedList,内部使用的是链表数据结构,所以对链表中的每一个数据,都使用了Entry对象来包装。Entry对象不仅有对象头,还有指向下一个Entry的指针,通常占用8个字节。
4)元素类型为原始数据类型(比如int)的集合,内部通常会使用原始数据类型的包装类型,比如用Integer来存储元素。
下面将从 Spark 中内存管理的概述开始,然后我们讨论可以采取的特定策略,以更有效地使用内存。特别是,我们将描述如何确定对象的内存使用情况,以及如何改进它——通过更改数据结构或以序列化格式存储数据。然后我们将介绍调整 Spark 的缓存大小和 Java 垃圾收集器。
22.2.2 内存管理
Spark的内存可以大体归为两类:execution(运行内存)和storage(存储内存),前者包括shuffles、joins、sorts和aggregations所需内存,后者包括cache和节点间数据传输所需内存;
Spark1.6及以后,引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域,提供更好的性能。此种方式使得我们不需要修改内存比例。
22.2.3 如何判断你的程序消耗了多少内存?
这里有一个非常简单的办法来判断,你的spark程序消耗了多少内存。
1)首先,自己设置RDD的并行度,有下列方法:
a) 在parallelize()、textFile()等方法中,传入第二个参数,设置RDD的task 或 partition的数量;
b) 用SparkConf.set()方法,设置一个参数,spark.default.parallelism,可以统一设置这个application所有RDD的partition数量。
2)其次,在程序中将RDD cache到内存中,调用RDD.cache()方法即可。
3)最后,观察web ui

val cacheRdd = rdd.cache() //应该根据这个地方cache的结果,进行内存的调节
cacheRdd.count()
22.2.4 优化数据结构
减少内存消耗的第一种方法是避免Java语法特性中所导致的额外内存的开销,比如基于指针的Java数据结构,以及包装类型。
有一个关键的问题,就是优化什么数据结构?其实主要就是优化你的算子函数,内部使用到的局部数据,或者是算子函数外部的数据。都可以进行数据结构的优化。优化之后,都会减少其对内存的消耗和占用。
优化方法:
1)能用数组取代,就不用集合。比如:用Array代替List。
2)能用字符串取代,就不用数组或集合。
3)能用int型取代,就不要用字符串;比如:Map的key可以用int取代字符串。
22.2.5 对多次使用的RDD进行持久化或Checkpoint
RDD 持久化:
如果程序中,对某一个RDD,基于它进行了多次transformation或者action操作。那么就非常有必要对其进行持久化操作,以避免对一个RDD反复进行计算。
此外,如果RDD的持久化数据可能会丢失的(因为使用cache的时候),还要保证高性能,那么可以对RDD进行Checkpoint操作。
checkpoint:
checkpoint的意思就是建立检查点,类似于快照,当DAG计算过程出现问题了就可以从这个快照中恢复,当然我们也可以通过cache或者persist将中间的计算结果放到内存或者磁盘中,但也未必完全可靠,假如内存或者硬盘坏了,也会导致spark从头再根据rdd计算一遍,所以就有了checkpoint,其中checkpoint的作用就是将DAG中比较重要的中间数据做一个检查点将结果存储到一个高可用的地方比如HDFS。
使用方法:

22.2.6 选择带有序列化的持久化级别
除了对多次使用的RDD进行持久化操作之外,还可以进一步优化其性能。如果RDD数据持久化到内存或磁盘时,如果内存不够就可能只缓存RDD的部分数据。
为了提高效率,可以采取序列化持久到内存,这样内存占用少。比如MEMORY_ONLY_SER、MEMORY_AND_DISK_SER等。
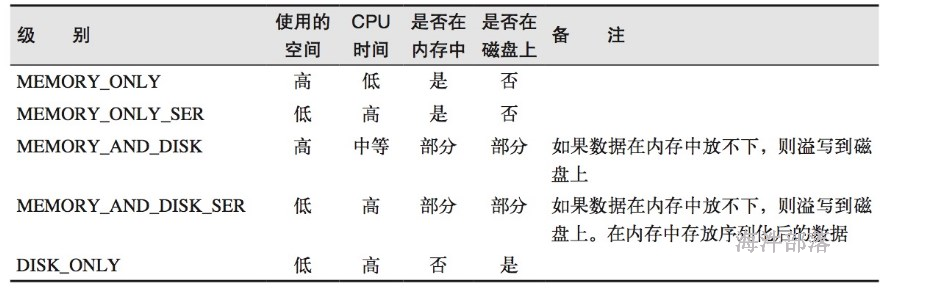
对于序列化的持久化级别,还可以使用Kryo序列化进一步优化,这样,可以获得更快的序列化速度,并且占用更小的内存空间。
22.2.7 JVM调优
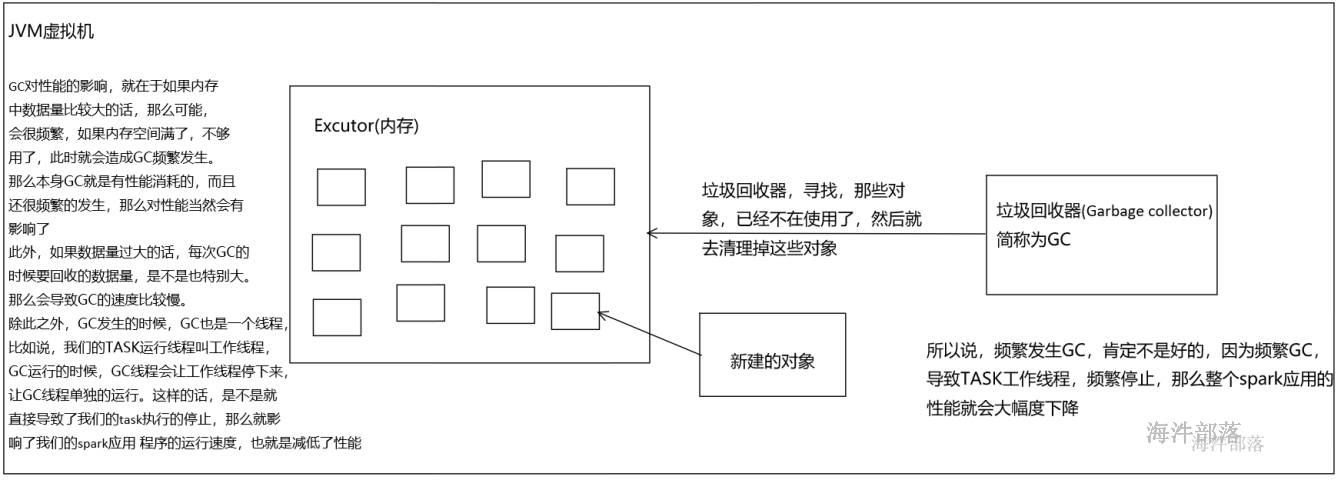
22.2.7.1 Java虚拟机垃圾回收调优的背景
如果在持久化RDD的时候,持久化了大量的数据,那么Java虚拟机的垃圾回收就可能成为一个性能瓶颈。因为Java虚拟机会定期进行垃圾回收,此时就会追踪所有的java对象,并且在垃圾回收时,找到那些已经不在使用的对象,然后清理旧的对象,来给新的对象腾出内存空间。
垃圾回收的性能开销,是跟内存中的对象的数量,成正比的。所以,对于垃圾回收的性能问题,首先要做的就是,使用更高效的数据结构,比如array和string;其次就是在持久化rdd时,使用序列化的持久化级别,而且用Kryo序列化类库,这样,每个partition就只是一个对象——一个字节数组。
我们可以对垃圾回收进行监测,包括多久进行一次垃圾回收,以及每次垃圾回收耗费的时间。只要在spark-submit脚本中,增加一个配置即可,–conf “spark.executor.extraJavaOptions=-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps”。
但是要记住,这里虽然会打印出Java虚拟机的垃圾回收的相关信息,但是是输出到了worker上的日志中,而不是driver的日志中。
其实完全可以通过SparkUI(4040端口)来观察每个stage的垃圾回收的情况。
spark.executor.extraJavaOptions是配置executor的jvm参数
spark.driver.extraJavaOptions是配置driver的jvm参数
22.2.7.3 垃圾回收机制
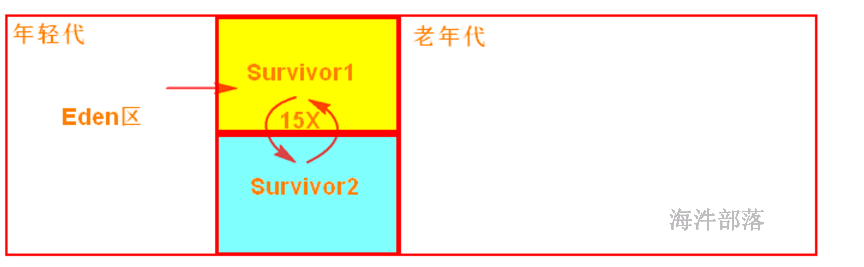
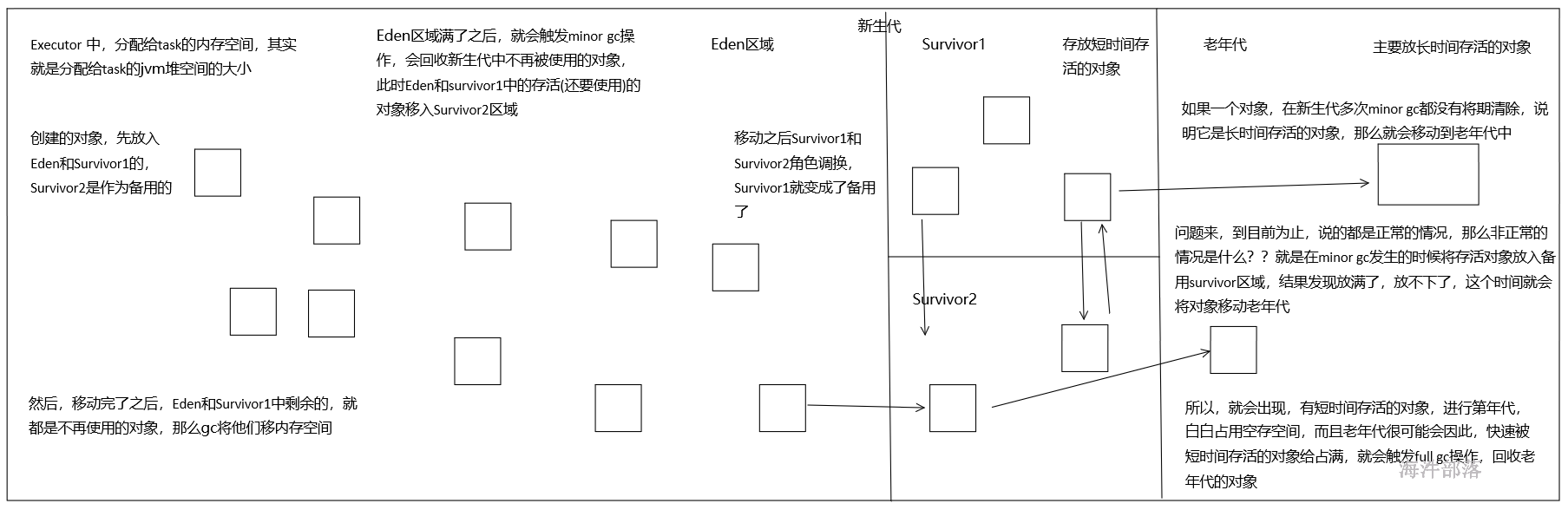
首先,Eden区域和Survivor1区域用于存放对象,Survivor2区域备用。创建的对象,首先放入Eden区域和Survivor1区域,如果Eden区域满了,那么就会触发一次Minor GC,进行年轻代的垃圾回收。Eden和Survivor1区域中存活的对象,会被移动到Survivor2区域中。然后Survivor1和Survivor2的角色调换,Survivor1变成了备用。
如果一个对象,在年轻代中,撑过了多次垃圾回收,都没有被回收掉,那么会被认为是长时间存活的,此时就会被移入老年代。此外,如果在将Eden和Survivor1中的存活对象,尝试放入Survivor2中时,发现Survivor2放满了,那么会直接放入老年代。此时就出现了,短时间存活的对象,进入老年代的问题。
如果老年代的空间满了,那么就会触发Full GC,进行老年代的垃圾回收操作。
22.2.7.4 高级垃圾回收调优
Spark如果发现,在task执行期间,大量full gc发生了,那么说明,年轻代的Eden区域,给的空间不够大。此时可以执行一些操作来优化垃圾回收行为:
1)包括降低存储内存的比例(spark.memory.storageFraction),给年轻代更多的空间,来存放短时间存活的对象;
2)当大对象很多,但minorGC少,说明大对象都进入了老年代,此时给Eden区域分配更大的空间,使用-Xmn(年轻代的heap大小)即可,通常建议给Eden区域,预计大小的4/3;
3)如果使用的是HDFS文件,那么很好估计Eden区域大小,如果每个executor有4个task,然后每个hdfs压缩块解压缩后是该压缩块大小的3倍,每个hdfs块的大小是128M,那么Eden区域的预计大小就是:4 * 3 * 128MB,然后呢,再通过-Xmn参数,将Eden区域大小设置为4 * 3 * 128* 4/3。
22.2.7.5 最后一点总结
根据经验来看,对于垃圾回收的调优,因为jvm的调优是非常复杂和敏感的。除非真的到了万不得已的地步,并且,自己本身又对jvm相关的技术很了解,那么此时进行Eden区域的调节是可以的。
一些高级的参数:
-XX:SurvivorRatio=4:
设置年轻代中Eden区与Survivor区的大小比值。如果值为4,那么就是Eden跟两个Survivor的比例是4:2,也就是说每个Survivor占据的年轻代的比例是1/6,所以,你其实也可以尝试调大Survivor区域的大小。
-XX:NewRatio=4:
调节新生代和老年代的比例。如果为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5。
其它设置内存大小的参数:
-Xms:为jvm启动时分配的内存,比如-Xms200m,表示分配200M。
-Xmx:为jvm运行过程中分配的最大内存,比如-Xms500m,表示jvm进程最多只能够占用500M内存。
-Xmn:年轻代的heap大小
-Xss:为jvm启动的每个线程分配的内存大小
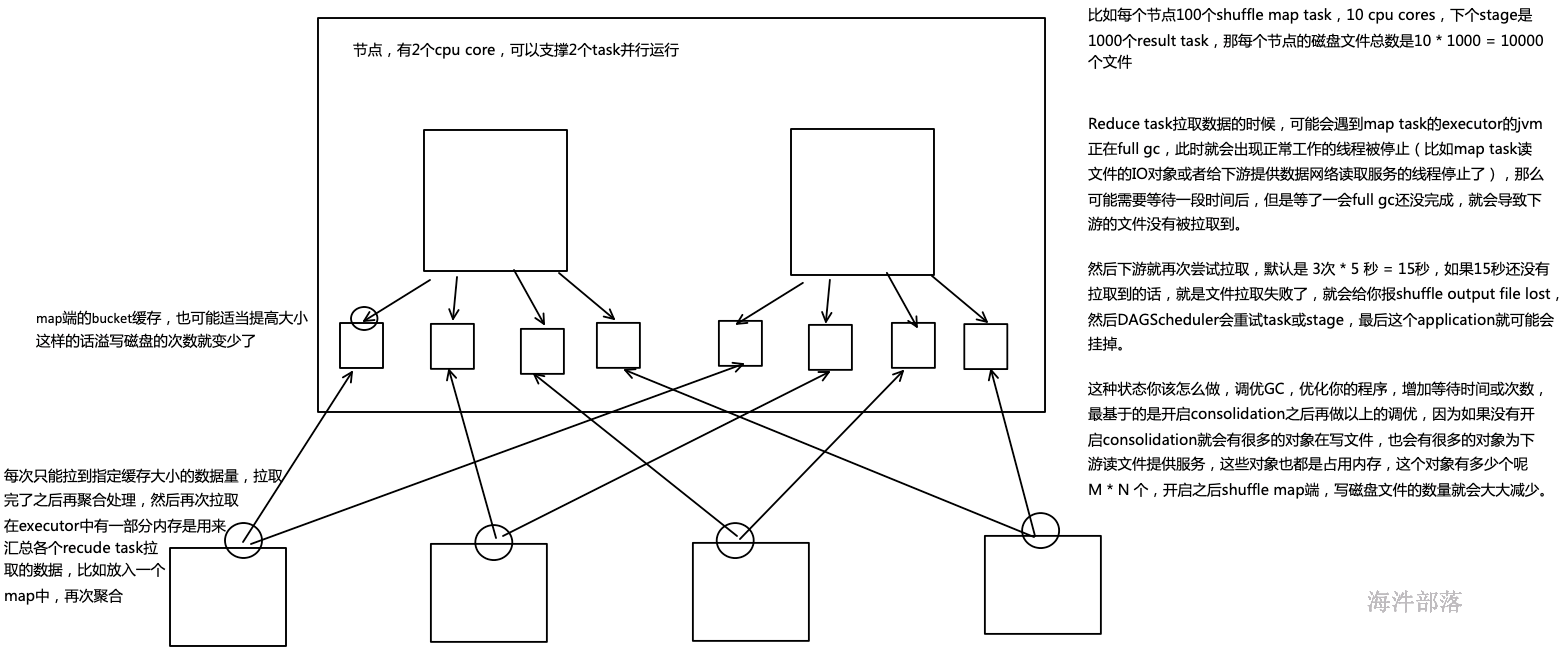
22.3 常用shuffle优化
shuffle是一个涉及到CPU(序列化反序列化)、网络IO(跨节点数据传输)以及磁盘IO(shuffle中间结果落盘)的操作。
优化思路:
减少shuffle的数据量,减少shuffle的次数
具体方式:
1)能不shuffle的时候尽量不要shuffle数据,可以使用mapjoin(广播变量);
2)能用reduceByKey就不要用groupByKey,因为reducerByKey会在shuffle前进行本地聚合,可以使在shuffle过程中减少磁盘IO;
3)spark2.0后已经没有HashShuffleManager,只有SortShuffleManager,SortShuffleManager内部有3种shuffle操作,可适应小中大集群。
4)参数调节:
spark.reducer.maxSizeInFlight:reduce task的拉取缓存,默认48m
spark.shuffle.file.buffer:map task的写磁盘缓存,默认32k
spark.shuffle.io.maxRetries:拉取失败的最大重试次数,默认3次
spark.shuffle.io.retryWait:拉取失败的重试间隔,默认5s