spark优化02
22.4 提高并行度(资源足够的情况下)
在执行任务过程中,Spark集群的资源并不一定会被充分利用到,所以要尽量设置合理的并行度,来充分地利用集群的资源。才能充分提高Spark应用程序的性能。
Spark会自动设置以文件作为输入源的RDD的并行度,依据其大小,比如HDFS,就会给每一个block创建一个partition,也依据这个设置并行度。对于reduceByKey等会发生shuffle的操作,就使用并行度最大的父RDD的并行度即可。
1)使用textFile()、parallelize()方法时的第二个参数设置并行度;
2)使用 coalesce 或 repartition 设置并行度;
3)使用像 reduceByKey的第二个参数设置并行度;
4)使用spark.default.parallelism参数,来设置统一的并行度。Spark官方的推荐是,给集群中的每个cpu core设置2\~3个task。
比如说,spark-submit设置了executor数量是10个,每个executor要求分配2个core,那么application总共会有20个core。此时可以设置new SparkConf().set(“spark.default.parallelism”, “60”)来设置合理的并行度,从而充分利用资源。
推荐:一个CPU核对应2-3个task数。
任务运行数量与资源分配:
Task被执行的并行度 = Executor数目 * 每个Executor核数(=core总个数)
当 executor数=2, 每个executor核数=1, task被执行的并行度= 2 * 1 = 2, 8个task就需要迭代4次。
当 executor数=2, 每个executor核数=2, task被执行的并行度= 2 * 2 = 4, 8个task就需要迭代2次。
因为一个job会划分很多个阶段,所以没必要把所有阶段的task都占有一个CPU核,这样会极大的浪费资源。
分配资源时,尽量task数能整除开 task被执行的并行度,这样不会有CPU核空转。
比如 6 executor数=2, 每个executor核数=3, task被执行的并行度= 2 * 3 = 6, 那执行一次后,就有4个核空转,浪费资源。
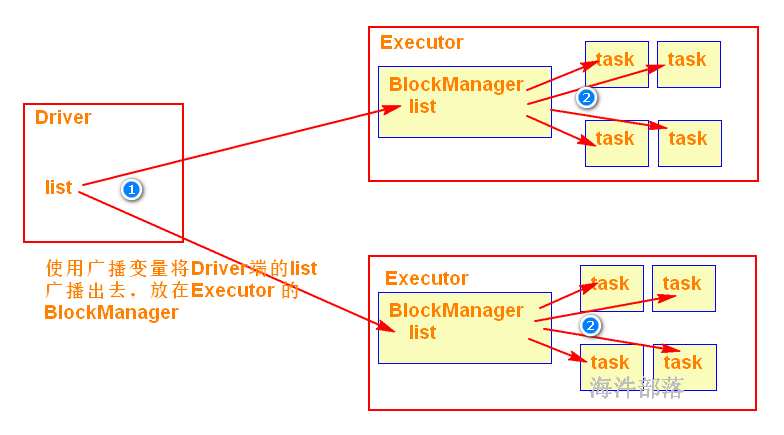
22.5 广播共享数据
如果你的算子函数中,使用到了特别大的数据,那么这个时候,推荐将该数据进行广播。这样的话,就不至于将一个大数据拷贝到每一个task上去。而是给每个节点拷贝一份,然后节点上的task共享该数据。
这样就可以减少大数据在节点上的内存消耗。并且可以减少数据到节点的网络传输消耗。
22.6 数据本地化
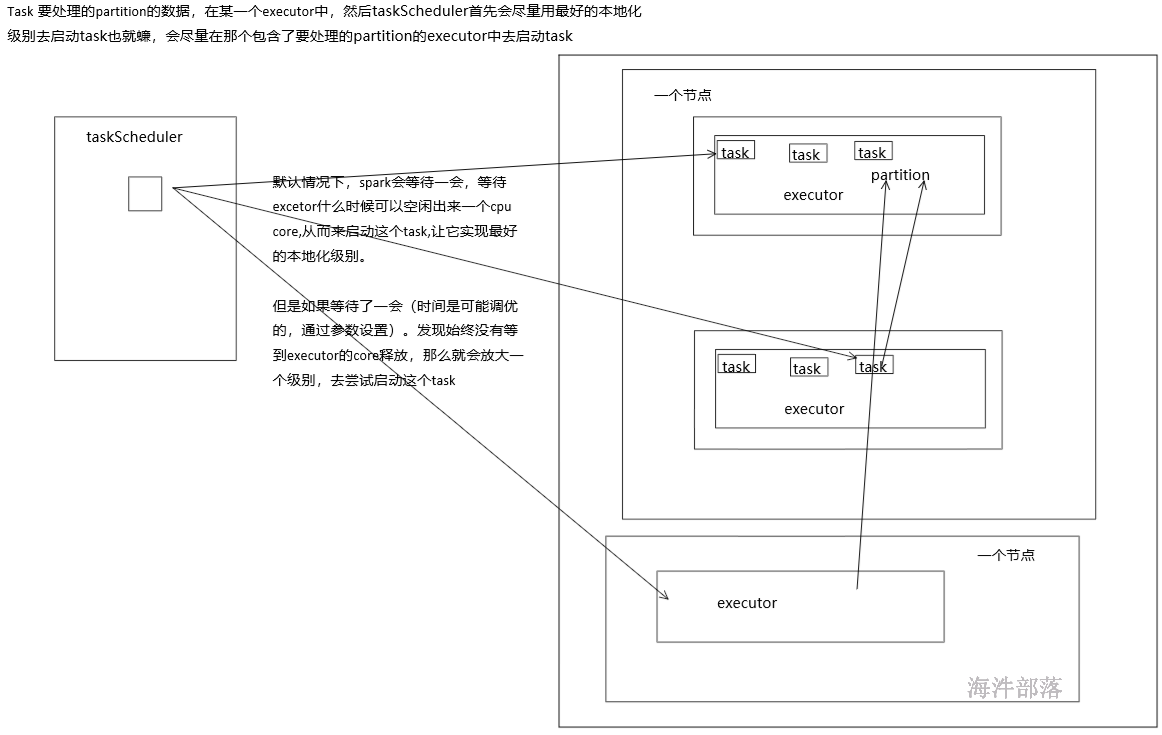
数据本地化对于Spark Job性能有着巨大的影响。如果数据以及要计算它的代码是在一起的,那么性能当然会非常高。但是,如果数据和计算它的代码是分开的,那么其中之一必须到另外一方的机器上。通常来说,移动代码到其他节点,会比移动数据到代码所在的节点上去,速度要快得多,因为代码比较小。Spark也正是基于这个数据本地化的原则来构建task调度算法的。
数据本地化,指的是数据离计算它的代码有多近。基于数据距离代码的距离,有几种数据本地化级别:
PROCESS_LOCAL:
进程本地化。数据和计算它的代码在同一个JVM进程中。
NODE_LOCAL:
节点本地化。数据和计算它的代码在一个节点上,但是不在一个进程中,比如在不同的executor进程中,但是尽量在读取文件(HDFS文件的block)所在的机器上
NO_PREF:
对于task来说,数据从哪里获取都一样,没有好坏之分,比如从数据库中获取数据。
RACK_LOCAL:
机架本地化。数据和计算它的代码在一个机架上。
ANY:
数据和task可能在集群中的任何地方,而且不在一个机架中,性能最差。

Spark默认会等待一会儿,来期望task要处理的数据所在的节点上的executor空闲出一个cpu,从而将task分配过去。只要超过了时间,那么Spark就会将task分配到其他任意一个空闲的executor上。
可以设置参数,spark.locality系列参数,来调节Spark等待task可以进行数据本地化的时间。
spark.locality.wait(3000毫秒) spark.locality.wait.process spark.locality.wait.node spark.locality.wait.rack
22.7 数据倾斜
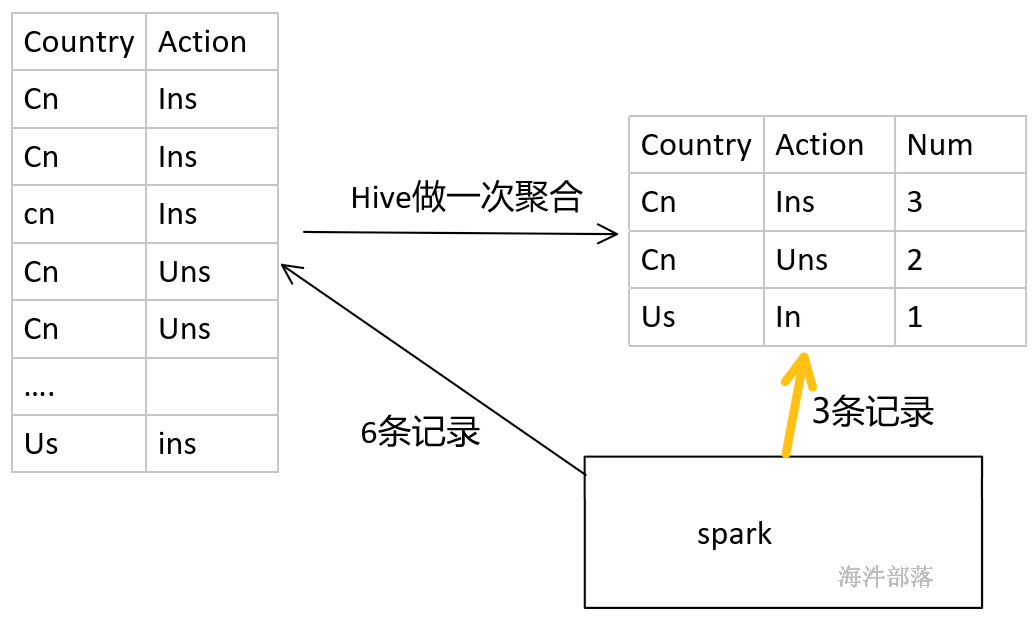
1)可以用hive进行发生倾斜的key做聚合
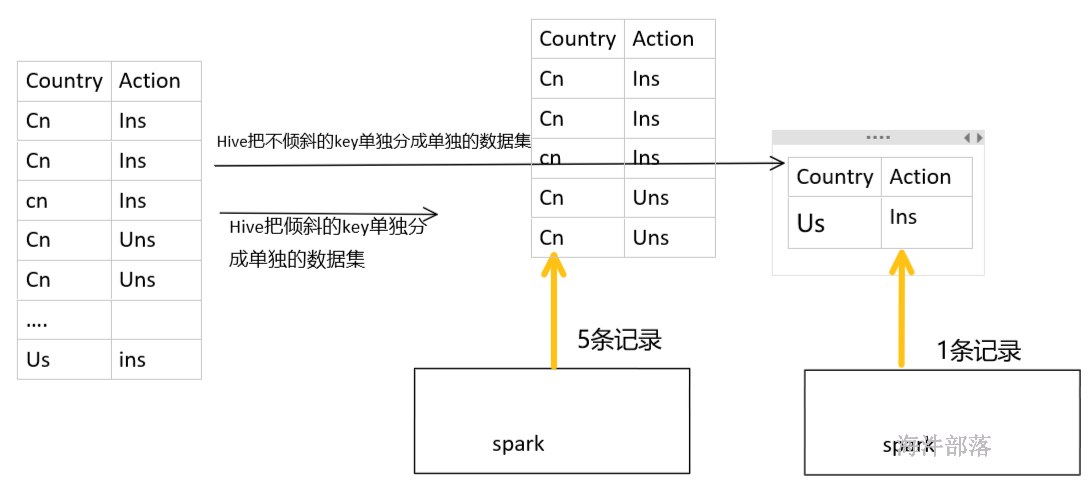
2)进行数据的清洗,把发生倾斜的刨除,用单独的程序去算倾斜的key
方法是打上随机前缀先聚合一次,然后去掉随机前缀再聚合一次。适用场景groupby
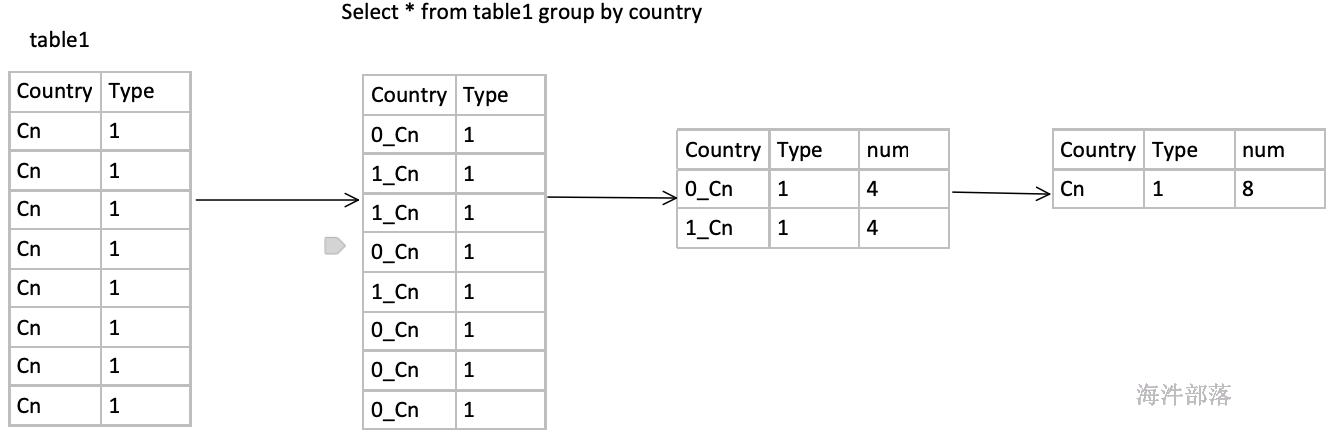
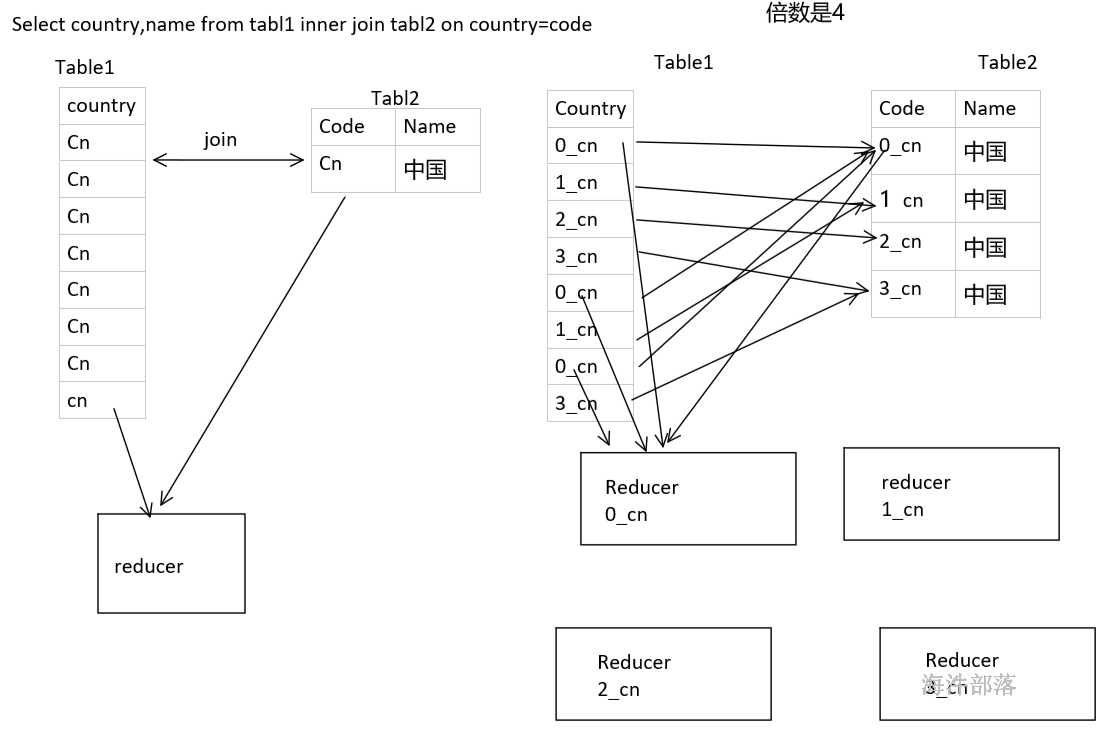
适用场景join
5)缩小粒度
比如年月日 省市县
6)能不shuffle就不shuffle
23 spark-streaming优化
Streaming应用程序中获得最佳性能,需要考虑两件事:
1)通过有效使用群集资源减少每批数据的处理时间。
2)设置正确的批处理大小,使得数据处理跟上数据摄取的速度。
23.1 带有receiver的数据接收并行度调优——多个DStream
通过网络接收数据时(比如Kafka、Flume),会将数据反序列化,并存储在Spark的内存中。如果数据接收成为系统的瓶颈,那么可以考虑并行化数据接收。每一个输入DStream都会在某个Worker的Executor上启动一个Receiver,该Receiver接收一个数据流。因此可以通过创建多个输入DStream,并且配置它们接收数据源不同的分区数据,达到接收多个数据流的效果。比如说,一个接收两个Kafka Topic的输入DStream,可以被拆分为两个输入DStream,每个分别接收一个topic的数据。这样就会创建两个Receiver,从而并行地接收数据,进而提升吞吐量。多个DStream可以使用union算子进行聚合,从而形成一个DStream。然后后续的transformation算子操作都针对该一个聚合后的DStream即可。
注意这种增加receiver的方法不适合DirectStream直连模式,因直连模式不需要Receiver。
val numStreams = 5
// 每个topic 创建流,流多receiver就多
val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...) }
val unifiedStream = streamingContext.union(kafkaStreams)
unifiedStream.print()设置socket的revicer

23.2 带有receiver的数据接收并行度调优——blockinterval
数据接收并行度调优,除了创建更多输入DStream和Receiver以外,还可以考虑调节block interval。通过参数,spark.streaming.blockInterval,可以设置block interval,默认是200ms。对于大多数Receiver来说,都会将数据切分为一个一个的block。而每个batch中的block数量,则决定了该batch对应的RDD的partition的数量,以及针对该RDD执行transformation操作时,创建的task的数量。每个batch对应的task数量是大约估计的,即batch interval / block interval。
例如说,batch interval为2s,block interval为200ms,会创建10个task。如果你认为每个batch的task数量太少,即低于每台机器的cpu core数量,那么就说明batch的task数量是不够的,因为所有的cpu资源无法完全被利用起来。要为batch增加block的数量,那么就减小block interval。然而,推荐的block interval最小值是50ms,如果低于这个数值,那么大量task的启动时间,可能会变成一个性能开销点。
现在是没有数据接收,所以receiver就是skipped,那这个task的并行度其实是根据任务的cpu core来定,默认情况下,当然可以通过设置spark.streaming.blockInterval来自己指定任务数。
receiver task的并行度是由bacth inerval/block interval决定,初始没有数据的时候,task的数量是由 cpu core来定,随着数据量越来越大,task的数量也在增加,当数据量达到一定规模,task数就能达到 bacth inerval/block interval 数量。
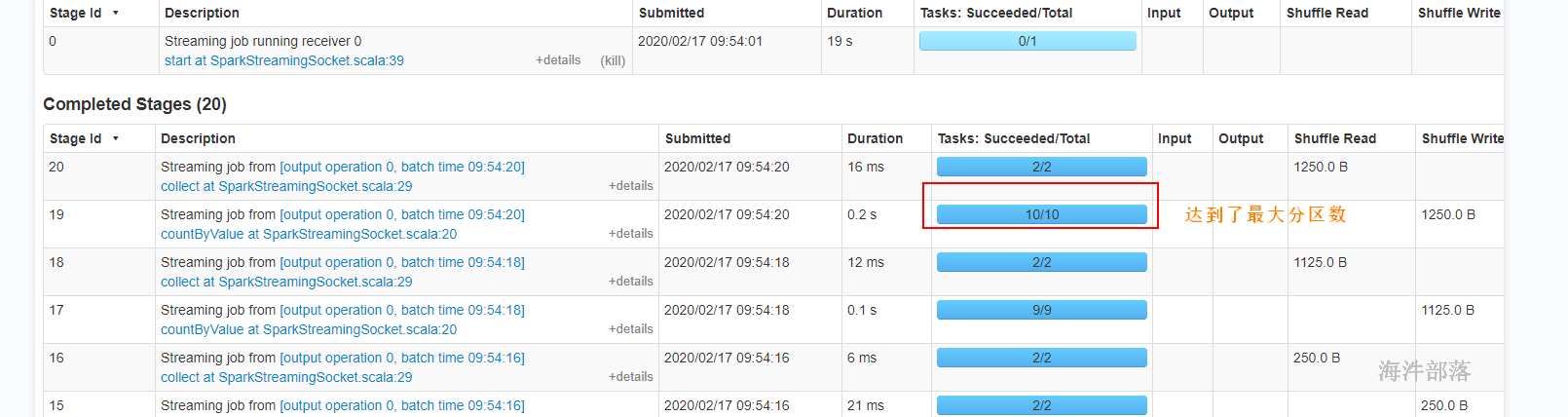
23.3 数据接收并行度调优——task
如果每秒钟启动的task过于多,比如每秒钟启动50个,那么发送这些task去Worker节点上的Executor的性能开销,会比较大,而且此时基本就很难达到毫秒级的延迟了。当然也要结合优化你的数据结构,尽量减少序列化后task的大小(注意:使用Kryo序列化只能优化shuffle数据不能用来序列化task),从而减少发送这些task到各个Worker节点上的Executor的时间。可以将每个batch的处理时间减少100毫秒。
23.4 数据处理并行度调优
如果在计算的任何stage中使用的并行task的数量没有足够多,那么集群资源是无法被充分利用的。举例来说,对于分布式的reduce操作,比如reduceByKey和reduceByKeyAndWindow,默认的并行task的数量是由spark.default.parallelism参数决定的。你可以在reduceByKey等操作中,传入第二个参数,手动指定该操作的并行度,也可以调节全局的spark.default.parallelism参数。
23.5 数据序列化调优
数据序列化造成的系统开销可以由序列化格式来减小。在流传输过程中,有两种类型的数据需要序列化:
1)输入数据:
默认情况下,接收到的输入数据,是存储在Executor的内存中的,使用的持久化级别是StorageLevel.MEMORY_AND_DISK_SER_2。这意味着,数据被序列化为字节从而减小GC开销,并且会复制其它executor进行失败的容错。因此,数据首先会存储在内存中,然后在内存不足时会溢写到磁盘上,从而为流式计算来保存所有需要的数据。这里的序列化有明显的性能开销——Receiver必须反序列化从网络接收到的数据,然后再使用Spark的序列化格式序列化数据。
2)流式计算操作生成的持久化RDD:
流式计算操作生成的持久化RDD,可能会持久化到内存中。例如,窗口操作默认就会将数据持久化在内存中,因为这些数据后面可能会在多个窗口中被使用,并被处理多次。流式计算操作生成的RDD的默认持久化级别是StorageLevel.MEMORY_ONLY_SER ,默认就会减小GC开销。
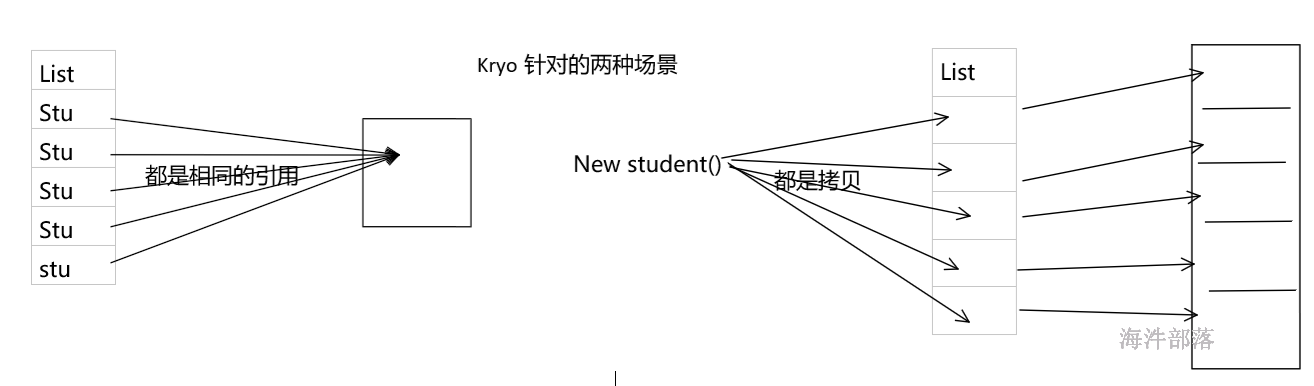
在上述的场景中,使用Kryo序列化类库可以减小CPU和内存的性能开销。使用Kryo时,一定要考虑注册自定义的类,并且禁用对应引用的tracking(spark.kryo.referenceTracking)。
| spark.kryo.referenceTracking | true | 当用Kryo序列化时,跟踪是否引用同一对象。如果你的对象图有环,这是必须的设置。如果他们包含相同对象的多个副本,这个设置对效率是有用的。如果你知道不在这两个场景,那么可以禁用它以提高效率 |
|---|---|---|
23.6 batch interval调优(最重要)
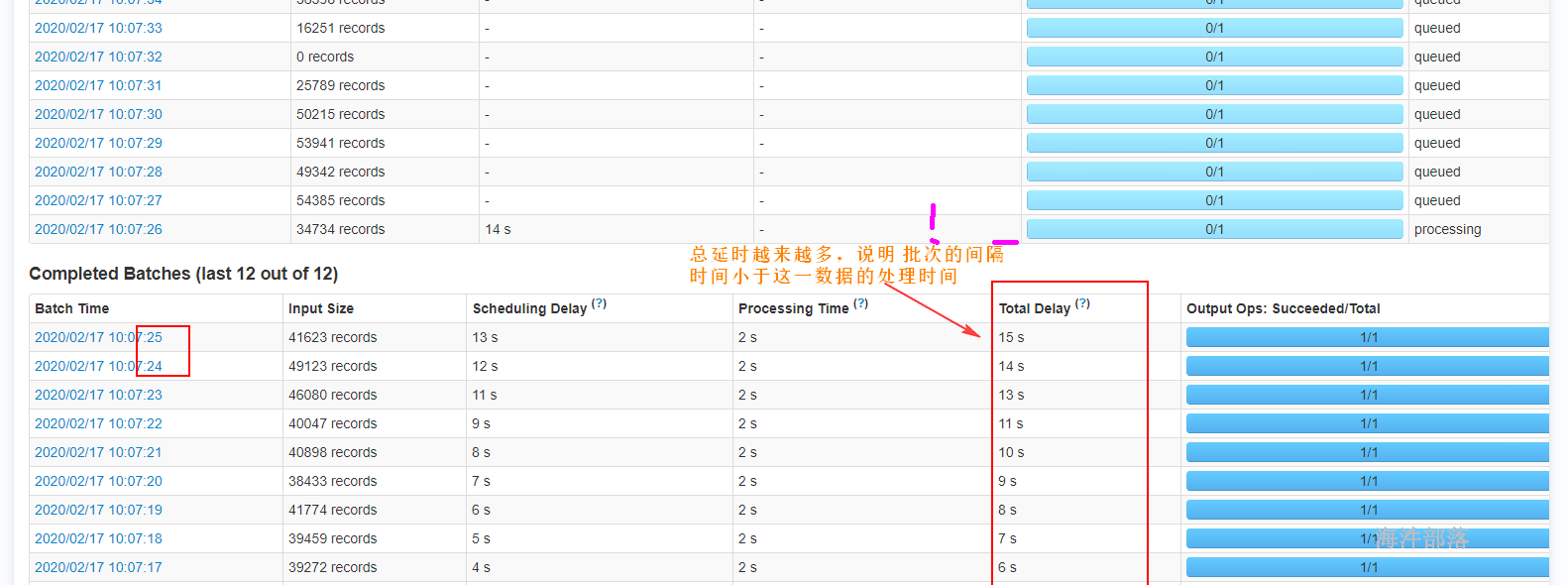
如果想让一个运行在集群上的Spark Streaming应用程序可以稳定,它就必须尽可能快地处理接收到的数据。换句话说,批量数据的处理速度应与生成它们的速度一样快。对于一个应用来说,可以通过观察Spark UI上的batch处理时间来定。batch处理时间必须小于batch interval时间。
基于流式计算的本质,batch interval对于,在固定集群资源条件下,应用能保持的数据接收速率,会有巨大的影响。例如,在WordCount例子中,对于一个特定的数据接收速率,应用业务可以保证每2秒打印一次单词计数,而不是每500ms。因此batch interval需要被设置得,让预期的数据接收速率可以在生产环境中保持住。
为你的应用计算正确的batch大小的比较好的方法,是在一个很保守的batch interval,比如5\~10s,以很慢的数据接收速率进行测试。要检查应用是否跟得上这个数据速率,可以检查每个batch的处理时间的延迟,如果处理时间与batch interval基本吻合,那么应用就是稳定的。否则,如果batch调度的延迟持续增长,那么就意味应用无法跟得上这个速率,也就是不稳定的。因此你要想有一个稳定的配置,可以尝试提升数据处理的速度,或者增加batch interval。记住,由于临时性的数据增长导致的暂时的延迟增长,可以合理的,只要延迟情况可以在短时间内恢复即可。
测试代码
package sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Duration, Durations, StreamingContext}
object SparkStreamingSocket {
def main(args: Array[String]): Unit = {
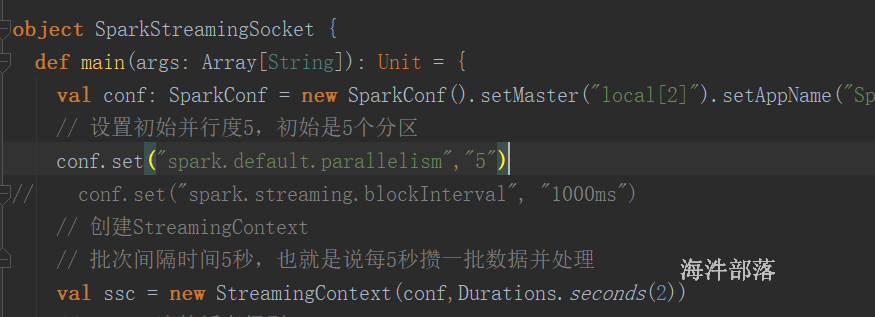
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("SparkStreamingSocket")
// 设置初始并行度5,初始是5个分区
// conf.set("spark.default.parallelism","5")
// conf.set("spark.streaming.blockInterval", "1000ms")
// 创建StreamingContext
// 批次间隔时间5秒,也就是说每5秒攒一批数据并处理
val ssc = new StreamingContext(conf,Durations.seconds(1))
// socket流的缓存级别: storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
// DStream 转换操作
val reduceByKeyDS: DStream[(String, Long)] = inputDS.countByValue()
reduceByKeyDS.foreachRDD((rdd,t) =>{
// 使每批次数据处理达到2s以上
Thread.sleep(2000)
println(s"count time:${t}\t${rdd.collect().toBuffer}")
})
// 启动流式计算
ssc.start()
// 阻塞一直运行下去,除非异常退出或关闭
ssc.awaitTermination()
}
}
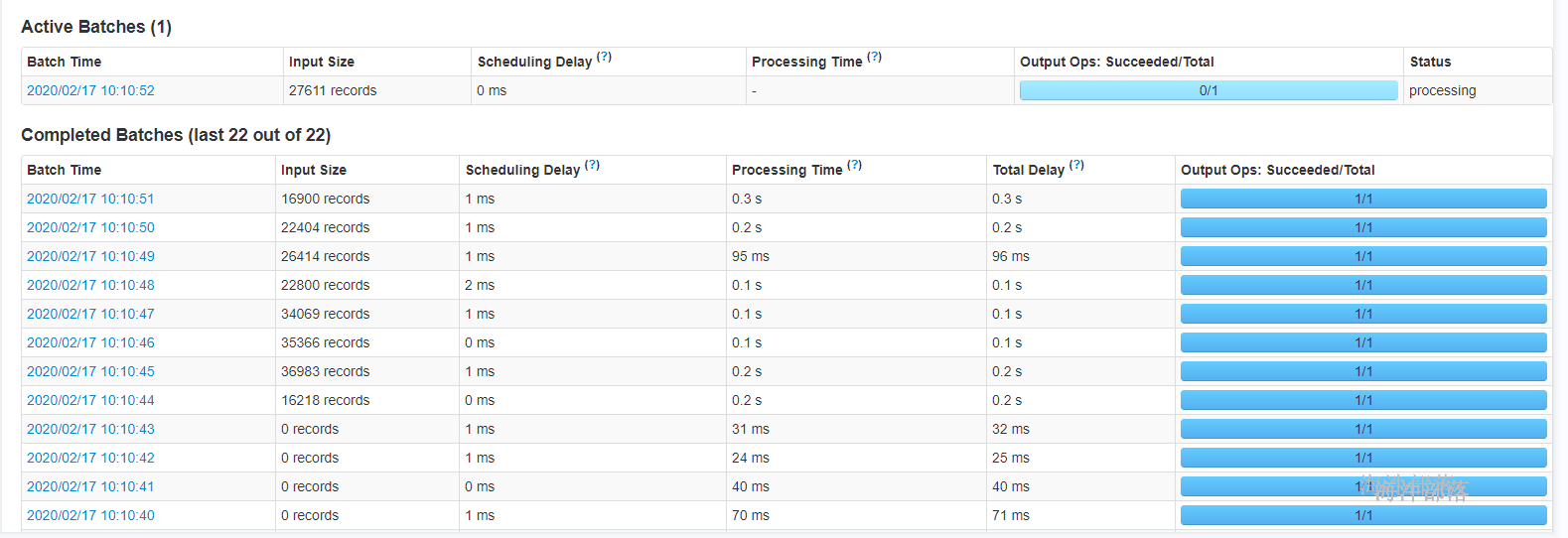
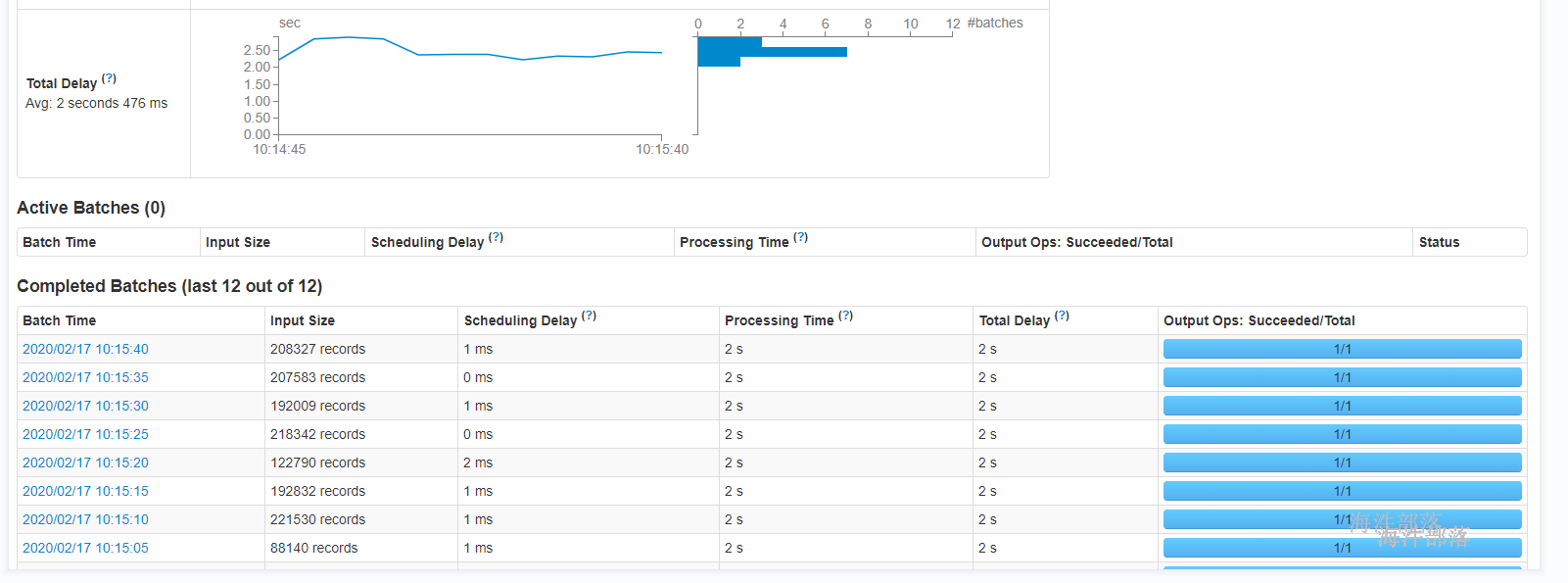
提升数据处理的速度,本例是把延时2s取消。
23.7 内存调优
Spark Streaming应用需要的集群内存资源,是由使用的transformation操作类型决定的。举例来说,如果想要使用一个窗口长度为10分钟的window操作,那么集群就必须有足够的内存来保存10分钟内的数据。如果想要使用updateStateByKey来维护许多key的state,那么你的内存资源就必须足够大。反过来说,如果想要做一个简单的map-filter-store操作,那么需要使用的内存就很少。
通常来说,通过Receiver接收到的数据,会使用StorageLevel.MEMORY_AND_DISK_SER_2持久化级别来进行存储,因此无法保存在内存中的数据会溢写到磁盘上。而溢写到磁盘上,是会降低应用的性能的。因此,通常是建议为应用提供它需要的足够的内存资源。建议在一个小规模的场景下测试内存的使用量,并进行评估。
内存调优的另外一个方面是垃圾回收。对于流式应用程序,如果要获得低延迟,肯定不想要有因为JVM垃圾回收导致的长时间延迟。
减少存储空间的方式:
1)DStream的持久化:输入数据和某些操作生产的中间RDD,默认持久化时都会序列化为字节。与非序列化的方式相比,这会降低内存和GC开销。使用Kryo序列化机制可以进一步减少内存使用和GC开销。
2)进一步降低内存使用率,可以对数据进行压缩,由spark.rdd.compress参数控制(默认false)。


