Spark的RDD编程02
9.2.1.2 键值对RDD操作
键值对RDD(pair RDD)是指每个RDD元素都是(key, value)键值对类型;
| 函数 | 目的 |
|---|---|
| reduceByKey(func) | 合并具有相同键的值,RDD[(K,V)] => RDD[(K,V)]按照key进行分组,并通过func 进行合并计算 |
| groupByKey() | 对具有相同键的值进行分组,RDD[(K,V)] => RDD[(K, Iterable)]只按照key进行分组,不对value合并计算 |
| mapValues(func) | 对 PairRDD中的每个值应用一个函数,但不改变键不会对值进行合并计算 |
| flatMapValues(func) | 对PairRDD 中的每个值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键的键值对记录 |
| keys() | 返回一个仅包含键的 RDD,RDD[(K,V)] => RDD[K]返回键不去重 |
| values() | 返回一个仅包含值的 RDD,RDD[(K,V)] => RDD[V] |
| sortByKey() | 返回一个根据键排序的 RDD,默认是升序false:降序 |
| Intersection union subtract | |
| subtractByKey(other) | 删掉RDD中键与other RDD中的键相同的元素 |
| cogroup | 将两个RDD中拥有相同键的数据分组到一起,RDD[(K,V)],RDD[(K, W)] => RDD[(K, (Iterable,Iterable))] |
| join(other) | 对两个RDD进行内连接,RDD[(K,V)],RDD[(K, W)] => RDD[(K, (V, W))]相当于MySQL 的 innerjoin |
| rightOuterJoin | 对两个RDD进行右连接,RDD[(K,V)],RDD[(K, W)] => RDD[(K, (Option[V], W))]相当于MySQL 的 rightjoin |
| leftOuterJoin | 对两个RDD进行左连接,RDD[(K,V)],RDD[(K, W)] => RDD[(K, (V, Option[W]))]相当于MySQL 的 leftjoin |
groupBykey的代码
它和groupBy相比返回值 RDD[k,Iterable[v]]
因为它也是shuffle类算子可以修改分区数量
scala> sc.textFile("/a.txt")
res51: org.apache.spark.rdd.RDD[String] = /a.txt MapPartitionsRDD[42] at textFile at <console>:25
scala> res51.flatMap(_.split(" "))
res52: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[43] at flatMap at <console>:26
scala> res52.map((_,1))
res53: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[44] at map at <console>:26
scala> res53.groupBy(_._1)
res54: org.apache.spark.rdd.RDD[(String, Iterable[(String, Int)])] = ShuffledRDD[46] at groupBy at <console>:26
scala> res53.groupByKey()
res55: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[47] at groupByKey at <console>:26
scala> res55.mapValues(_.sum)
res56: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[48] at mapValues at <console>:26
scala> res56.collect
res57: Array[(String, Int)] = Array((tom,8), (hello,16), (world,8))
scala> val arr = Array(("love",("taitannike",9.9)),("love",("cndqsjlg",8.5)),())
arr: Array[Any] = Array((love,(taitannike,9.9)), (love,(cndqsjlg,8.5)), ())
scala> val arr = Array(("love",("taitannike",9.9)),("love",("cndqsjlg",8.5)),("honor",("zh1",9.5)),("honor",("zh2",9.3)))
arr: Array[(String, (String, Double))] = Array((love,(taitannike,9.9)), (love,(cndqsjlg,8.5)), (honor,(zh1,9.5)), (honor,(zh2,9.3)))
scala> sc.makeRDD(arr)
res58: org.apache.spark.rdd.RDD[(String, (String, Double))] = ParallelCollectionRDD[49] at makeRDD at <console>:27
scala> res58.groupByKey()
res59: org.apache.spark.rdd.RDD[(String, Iterable[(String, Double)])] = ShuffledRDD[50] at groupByKey at <console>:26
scala> res59.collect
res60: Array[(String, Iterable[(String, Double)])] = Array((love,CompactBuffer((taitannike,9.9), (cndqsjlg,8.5))), (honor,CompactBuffer((zh1,9.5), (zh2,9.3))))
scala> res58.partitions.size
res61: Int = 9
scala> res58.groupByKey(4)
res62: org.apache.spark.rdd.RDD[(String, Iterable[(String, Double)])] = ShuffledRDD[51] at groupByKey at <console>:26
scala> res62.partitions.size
res63: Int = 4如果用groupBykey实现distinct去重
scala> arr
res66: Array[Int] = Array(1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6)
scala> sc.makeRDD(arr)
res67: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[53] at makeRDD at <console>:27
scala> res67.map((_,null))
res68: org.apache.spark.rdd.RDD[(Int, Null)] = MapPartitionsRDD[54] at map at <console>:26
scala> res68.groupByKey()
res69: org.apache.spark.rdd.RDD[(Int, Iterable[Null])] = ShuffledRDD[55] at groupByKey at <console>:26
scala> res69.map(_._1)
res71: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[56] at map at <console>:26
scala> res71.collect
res72: Array[Int] = Array(1, 2, 3, 4, 5, 6)reduceBykey
按照key进行合并,不仅仅能够分组还能够合并
scala> val rdd = sc.textFile("/a.txt")
rdd: org.apache.spark.rdd.RDD[String] = /a.txt MapPartitionsRDD[58] at textFile at <console>:24
scala> rdd.flatMap(_.split(" "))
res73: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[59] at flatMap at <console>:26
scala> res73.map((_,1))
res74: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[60] at map at <console>:26
scala> res74.reduceByKey(_+_)
res75: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[61] at reduceByKey at <console>:26
scala> res75.collect
res76: Array[(String, Int)] = Array((tom,8), (hello,16), (world,8))
scala> res74.partitions.size
res77: Int = 2
scala> res75.partitions.size
res78: Int = 2
scala> res74.reduceByKey(_+_,5)
res79: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[62] at reduceByKey at <console>:26
scala> res79.partitions.size
res80: Int = 5reduceBykey实现distinct的去重
scala> arr
res81: Array[Int] = Array(1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6)
scala> sc.makeRDD(arr)
res82: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[63] at makeRDD at <console>:27
scala> res82.map((_,null))
res83: org.apache.spark.rdd.RDD[(Int, Null)] = MapPartitionsRDD[64] at map at <console>:26
scala> res83.reduceByKey((a,b)=> a)
res84: org.apache.spark.rdd.RDD[(Int, Null)] = ShuffledRDD[65] at reduceByKey at <console>:26
scala> res84.collect
res85: Array[(Int, Null)] = Array((1,null), (2,null), (3,null), (4,null), (5,null), (6,null))
scala> res84.map(_._1)
res86: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[66] at map at <console>:26
scala> res86.collect
res87: Array[Int] = Array(1, 2, 3, 4, 5, 6)distinct的源码实现方式和案例是一样的
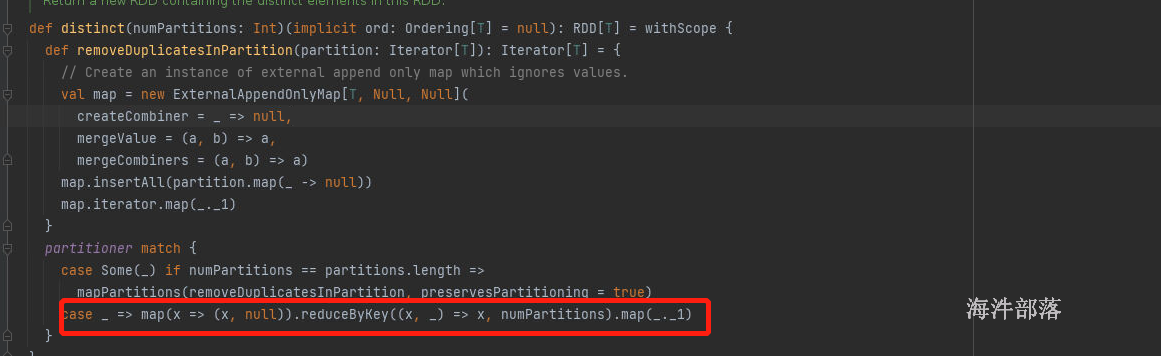
groupByKey() vs reduceByKey()
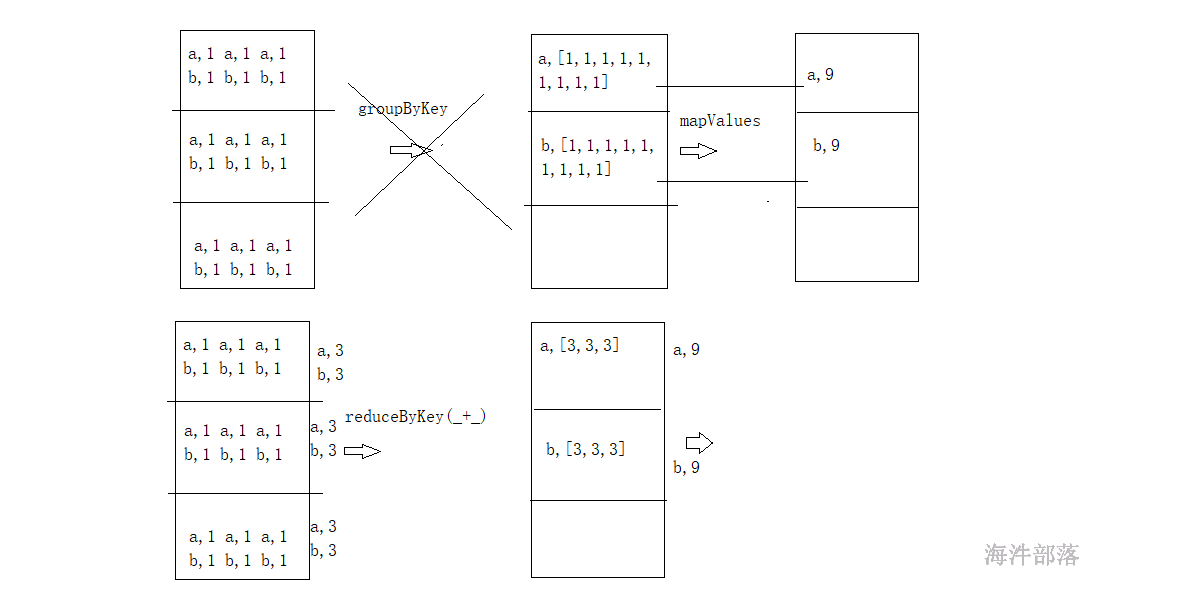
公共调用的底层方法

groupByKey()
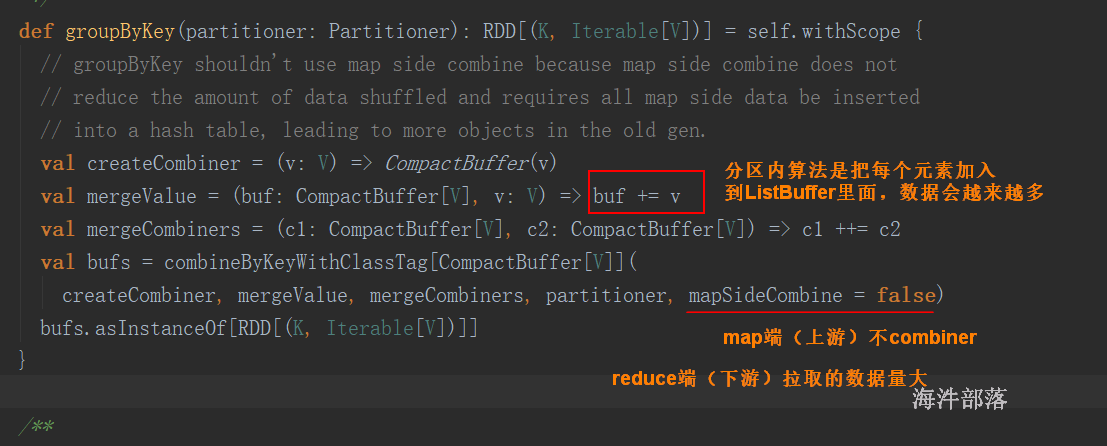
reduceByKey(func)

WordCount reduceByKey和groupByKey.map
scala> sc.textFile("/a.txt")
res0: org.apache.spark.rdd.RDD[String] = /a.txt MapPartitionsRDD[1] at textFile at <console>:25
scala> res0.flatMap(_.split(" "))
res1: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at <console>:26
scala> res1.map((_,1))
res2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:26
scala> res2.groupByKey()
res3: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[4] at groupByKey at <console>:26
scala> res3.mapValues(_.sum)
res4: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[5] at mapValues at <console>:26
scala> res4.collect
res5: Array[(String, Int)] = Array((tom,8), (hello,16), (world,8)) 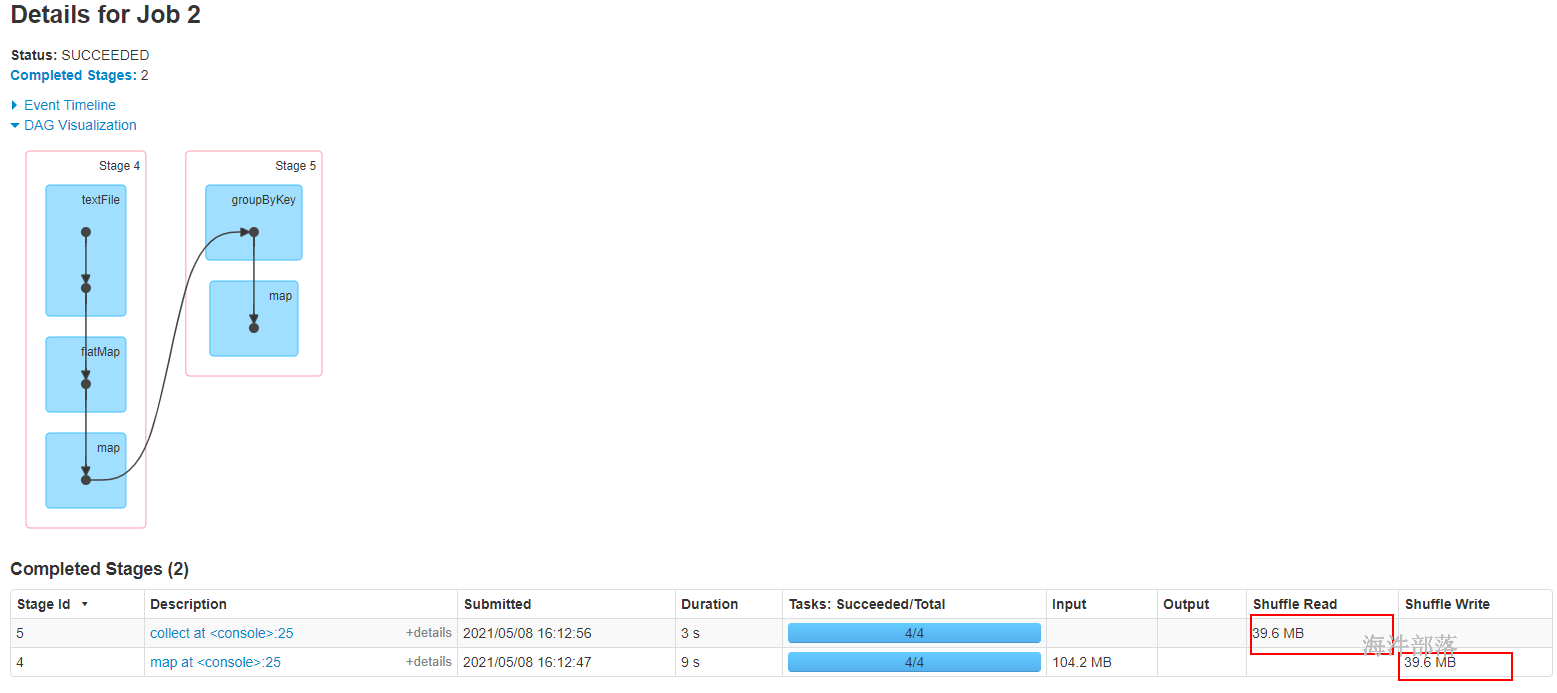
scala> sc.textFile("/a.txt")
res0: org.apache.spark.rdd.RDD[String] = /a.txt MapPartitionsRDD[1] at textFile at <console>:25
scala> res0.flatMap(_.split(" "))
res1: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at <console>:26
scala> res1.map((_,1))
res2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:26
scala> res2.reduceByKey(_+_)
res6: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[6] at reduceByKey at <console>:26
scala> res6.collect
res7: Array[(String, Int)] = Array((tom,8), (hello,16), (world,8))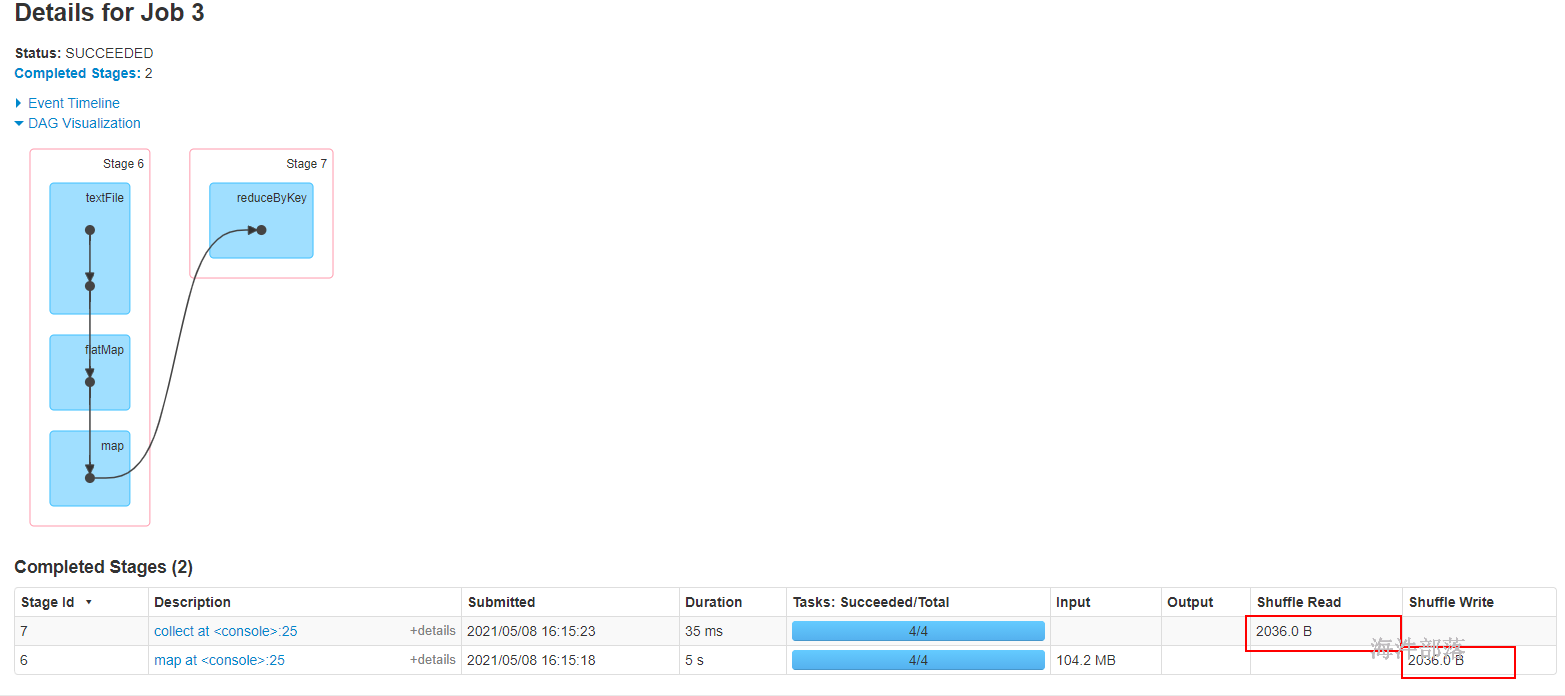

课堂练习
以如下的数据为案例
# 首先在data文件夹下面创建一个teacher.txt
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/unclewang
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/xiaohe
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://spark.hainiubl.com/laoyang
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laochen
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laoliu
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang
http://java.hainiubl.com/laozhang需求
# 首先求出整个文档中访问量最高的前三个
# 每个专业中访问量最高的前两个整体top3
package com.hainiu.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import java.net.URL
// http://java.hainiubl.com/laochen
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("teacher")
val sc = new SparkContext(conf)
// all top3
// group top2
val teacherVisit:RDD[((String,String),Int)] = sc.textFile("data/teacher.txt")
.map(t=>{
val url = new URL(t)
val subject = url.getHost.split("\\.")(0)
val teacher = url.getPath.substring(1)
((subject,teacher),1)
}).reduceByKey(_+_)
teacherVisit.sortBy(-_._2)
.take(3)
.foreach(println)
}
}分组top2
package com.hainiu.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import java.net.URL
// http://java.hainiubl.com/laochen
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("teacher")
val sc = new SparkContext(conf)
// all top3
// group top2
val teacherVisit:RDD[((String,String),Int)] = sc.textFile("data/teacher.txt")
.map(t=>{
val url = new URL(t)
val subject = url.getHost.split("\\.")(0)
val teacher = url.getPath.substring(1)
((subject,teacher),1)
}).reduceByKey(_+_)
val groupData:RDD[(String,Iterable[(String,Int)])] =
teacherVisit.map(t=>(t._1._1,(t._1._2,t._2))).groupByKey()
groupData.mapValues(t=>{
t.toList.sortBy(-_._2).take(2)
}).foreach(println)
}
}keys
values
mapValues(func)
scala> val arr = Array(1,1,2,2,3,3,4,4,5,5,6,6)
arr: Array[Int] = Array(1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6)
scala> sc.makeRDD(arr)
res8: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[7] at makeRDD at <console>:27
scala> res8.map((_,null))
res9: org.apache.spark.rdd.RDD[(Int, Null)] = MapPartitionsRDD[8] at map at <console>:26
scala> res9.groupByKey()
res10: org.apache.spark.rdd.RDD[(Int, Iterable[Null])] = ShuffledRDD[9] at groupByKey at <console>:26
scala> res10.map(_._1)
res11: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[10] at map at <console>:26
scala> res10.keys
res12: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[11] at keys at <console>:26
scala> res10.values
res13: org.apache.spark.rdd.RDD[Iterable[Null]] = MapPartitionsRDD[12] at values at <console>:26
scala> res10.map(_._2)
res14: org.apache.spark.rdd.RDD[Iterable[Null]] = MapPartitionsRDD[13] at map at <console>:26
scala> val arr = Array(("zhangsan",3000),("lisi",3500),("wangwu",4300))
arr: Array[(String, Int)] = Array((zhangsan,3000), (lisi,3500), (wangwu,4300))
scala> arr.mapValues(_+1000)
<console>:26: error: value mapValues is not a member of Array[(String, Int)]
arr.mapValues(_+1000)
^
scala> sc.makeRDD(arr)
res16: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[14] at makeRDD at <console>:27
scala> res16.mapValues(_+1000)
res17: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[15] at mapValues at <console>:26flatMapValues(func)
scala> val arr = Array("a b c","d e f")
arr: Array[String] = Array(a b c, d e f)
scala> sc.makeRDD(arr)
res18: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[16] at makeRDD at <console>:27
scala> res18.flatMap(_.split(" "))
res19: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[17] at flatMap at <console>:26
scala> val arr = Array(("zhangsan",Array(100,98,95)),("lisi",Array(95,35,100,82)))
arr: Array[(String, Array[Int])] = Array((zhangsan,Array(100, 98, 95)), (lisi,Array(95, 35, 100, 82)))
scala> sc.makeRDD(arr)
res20: org.apache.spark.rdd.RDD[(String, Array[Int])] = ParallelCollectionRDD[18] at makeRDD at <console>:27
scala> res20.flatMap(t=> t._2.map((t._1,_)))
res21: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[19] at flatMap at <console>:26
scala> res21.collect
res22: Array[(String, Int)] = Array((zhangsan,100), (zhangsan,98), (zhangsan,95), (lisi,95), (lisi,35), (lisi,100), (lisi,82))
scala> res20.flatMapValues()
<console>:26: error: not enough arguments for method flatMapValues: (f: Array[Int] => TraversableOnce[U])org.apache.spark.rdd.RDD[(String, U)].
Unspecified value parameter f.
res20.flatMapValues()
^
scala> res20.flatMapValues(t=> t)
res24: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[20] at flatMapValues at <console>:26
scala> val arr = Array(("zhangsan","100,98,92"),("lisi","100,93,45,60"))
arr: Array[(String, String)] = Array((zhangsan,100,98,92), (lisi,100,93,45,60))
scala> sc.makeRDD(arr)
res25: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[21] at makeRDD at <console>:27
scala> res25.flatMapValues(_.split(","))
res26: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[22] at flatMapValues at <console>:26
scala> res26.collect
res27: Array[(String, String)] = Array((zhangsan,100), (zhangsan,98), (zhangsan,92), (lisi,100), (lisi,93), (lisi,45), (lisi,60))flatMapvalues它的功能是压平value,并且和key进行匹配,flatMapValues中放入的函数功能是怎么处理value变成集合形式
课堂练习
# 输入如下:
Array("chinese-zhangsan,lisi,wangwu"
,"math-zhangsan,zhaosi"
,"english-lisi,wangwu,zhaosi")
# 求出每个老师教授的课程都有什么?
zhangsan-chinese,math
lisi-chinese,english
wangwu-chinese,english
zhaosi-math,english
# 思路是反推
# 1.通过结果能够得出,上一步的数据是 (zhangsan,chinese),(zhangsan,math)
# 2.reduceBykey进行合并得出的
# 3.数据怎么变成的 (zhangsan,chinese),(zhangsan,math)
# 4.首先应该将chinese-zhangsan,lisi,wangwu 处理掉整体代码:
package com.hainiu.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("parse")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val arr = Array("chinese-zhangsan,lisi,wangwu", "math-zhangsan,zhaosi", "english-lisi,wangwu,zhaosi")
val rdd:RDD[String] = sc.makeRDD(arr)
rdd.map(t => {
val strs = t.split("-")
(strs(0), strs(1))
}).flatMapValues(_.split(","))
.map(_.swap)
.reduceByKey(_+","+_)
.foreach(t=>println(t._1+"-"+t._2))
}
}
sortByKey()
scala> sc.textFile("/a.txt").flatMap(_.split(" ")).map((_,1))
res28: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[26] at map at <console>:25
scala> res28.reduceByKey(_+_)
res29: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[27] at reduceByKey at <console>:26
scala> res29.collect
res30: Array[(String, Int)] = Array((tom,8), (hello,16), (world,8))
scala> res29.sortByKey()
res31: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[30] at sortByKey at <console>:26
scala> res31.collect
res32: Array[(String, Int)] = Array((hello,16), (tom,8), (world,8))
scala> res29.sortByKey(false)
res33: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[33] at sortByKey at <console>:26
scala> res33.collect
res34: Array[(String, Int)] = Array((world,8), (tom,8), (hello,16))
scala> res29.sortByKey(false,3)
res35: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[36] at sortByKey at <console>:26
scala> res35.partitions.size
res36: Int = 3
scala> res29.map(t=> (t._2,t))
res37: org.apache.spark.rdd.RDD[(Int, (String, Int))] = MapPartitionsRDD[37] at map at <console>:26
scala> res29.map(t=> (t._2,t)).values
res38: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[39] at values at <console>:26
scala> res38.collect
res39: Array[(String, Int)] = Array((tom,8), (hello,16), (world,8))sortBy()
scala> res29
res40: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[27] at reduceByKey at <console>:26
scala> res29.collect
res41: Array[(String, Int)] = Array((tom,8), (hello,16), (world,8))
scala> res29.sortBy(-_._2)
res42: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[44] at sortBy at <console>:26
scala> res42.collect
res43: Array[(String, Int)] = Array((hello,16), (tom,8), (world,8))
scala> res29.sortBy
def sortBy[K](f: ((String, Int)) => K,ascending: Boolean,numPartitions: Int)(implicit ord: Ordering[K],implicit ctag: scala.reflect.ClassTag[K]): org.apache.spark.rdd.RDD[(String, Int)]
scala> res29.sortBy(-_._2,false,3)
res44: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[49] at sortBy at <console>:26
scala> res44.collect
res45: Array[(String, Int)] = Array((tom,8), (world,8), (hello,16))
scala> res44.partitions.size
res46: Int = 3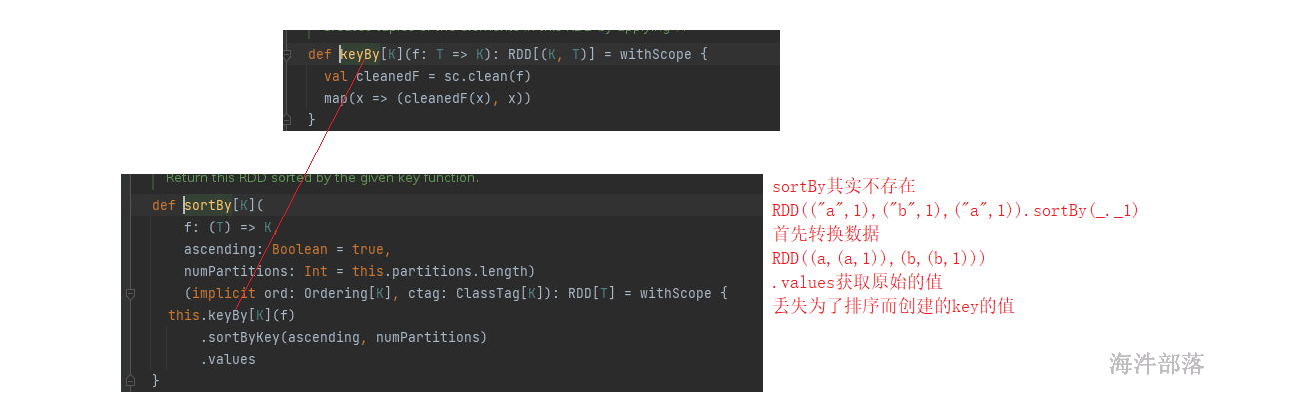
同样groupby底层和sortby的底层实现一样,groupby底层是groupBykey
cogroup()
scala> arr
res70: Array[(String, Int)] = Array((zhangsan,300), (lisi,400), (wangwu,350), (zhaosi,450))
scala> arr1
res71: Array[(String, Int)] = Array((zhangsan,22), (lisi,24), (wangwu,30), (guangkun,5))
scala> sc.makeRDD(arr)
res72: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[68] at makeRDD at <console>:27
scala> sc.makeRDD(arr1)
res73: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[69] at makeRDD at <console>:27
scala> res72 cogroup res73
res74: org.apache.spark.rdd.RDD[(String, (Iterable[Int], Iterable[Int]))] = MapPartitionsRDD[71] at cogroup at <console>:28
scala> res74.collect
res75: Array[(String, (Iterable[Int], Iterable[Int]))] = Array((zhangsan,(CompactBuffer(300),CompactBuffer(22))), (wangwu,(CompactBuffer(350),CompactBuffer(30))), (lisi,(CompactBuffer(400),CompactBuffer(24))), (zhaosi,(CompactBuffer(450),CompactBuffer())), (guangkun,(CompactBuffer(),CompactBuffer(5))))
scala> res74.mapValues(t=> t._1.sum * t._2.sum)
res76: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[72] at mapValues at <console>:26
scala> res76.collect
res77: Array[(String, Int)] = Array((zhangsan,6600), (wangwu,10500), (lisi,9600), (zhaosi,0), (guangkun,0))join()——innerjoin
scala> val arr = Array(("zhangsan",300),("lisi",400),("wangwu",350),("zhaosi",450))
arr: Array[(String, Int)] = Array((zhangsan,300), (lisi,400), (wangwu,350), (zhaosi,450))
scala> val arr1 = Array(("zhangsan",22),("lisi",24),("wangwu",30),("guangkun",5))
arr1: Array[(String, Int)] = Array((zhangsan,22), (lisi,24), (wangwu,30), (guangkun,5))
scala> sc.makeRDD(arr)
res47: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[50] at makeRDD at <console>:27
scala> sc.makeRDD(arr1)
res48: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[51] at makeRDD at <console>:27
scala> res47 join res48
res49: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[54] at join at <console>:28
scala> res49.collect
res50: Array[(String, (Int, Int))] = Array((zhangsan,(300,22)), (wangwu,(350,30)), (lisi,(400,24)))
scala> res49.mapValues(t=> t._1*t._2)
res51: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[55] at mapValues at <console>:26
scala> res51.collect
res52: Array[(String, Int)] = Array((zhangsan,6600), (wangwu,10500), (lisi,9600))leftOuterJoin()——leftjoin
scala> arr
res53: Array[(String, Int)] = Array((zhangsan,300), (lisi,400), (wangwu,350), (zhaosi,450))
scala> arr1
res54: Array[(String, Int)] = Array((zhangsan,22), (lisi,24), (wangwu,30), (guangkun,5))
scala> sc.makeRDD(arr)
res55: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[56] at makeRDD at <console>:27
scala> sc.makeRDD(arr1)
res56: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[57] at makeRDD at <console>:27
scala> res55 leftOuterJoin res56
res57: org.apache.spark.rdd.RDD[(String, (Int, Option[Int]))] = MapPartitionsRDD[60] at leftOuterJoin at <console>:28
scala> res57.collect
res58: Array[(String, (Int, Option[Int]))] = Array((zhangsan,(300,Some(22))), (wangwu,(350,Some(30))), (lisi,(400,Some(24))), (zhaosi,(450,None)))
scala> res57.mapValues(t=> t._1*t._2.getOrElse(0))
res59: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[61] at mapValues at <console>:26
scala> res59.collect
res60: Array[(String, Int)] = Array((zhangsan,6600), (wangwu,10500), (lisi,9600), (zhaosi,0))rightOuterJoin()——rightjoin
scala> arr
res61: Array[(String, Int)] = Array((zhangsan,300), (lisi,400), (wangwu,350), (zhaosi,450))
scala> arr1
res62: Array[(String, Int)] = Array((zhangsan,22), (lisi,24), (wangwu,30), (guangkun,5))
scala> sc.makeRDD(arr)
res63: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[62] at makeRDD at <console>:27
scala> sc.makeRDD(arr1)
res64: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[63] at makeRDD at <console>:27
scala> res63 rightOuterJoin res64
res65: org.apache.spark.rdd.RDD[(String, (Option[Int], Int))] = MapPartitionsRDD[66] at rightOuterJoin at <console>:28
scala> res65.mapValues(t=> t._2*t._1.getOrElse(0))
res68: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[67] at mapValues at <console>:26
scala> res68.collect
res69: Array[(String, Int)] = Array((zhangsan,6600), (wangwu,10500), (lisi,9600), (guangkun,0))9.2.1.3 rdd上面的分区器
之前学过的kv类型上面的算子
groupby groupByKey reduceBykey sortBy sortByKey join[cogroup left inner right] shuffle的
mapValues keys values flatMapValues 普通算子,管道形式的算子
shuffle的过程是因为数据产生了打乱重分,分组、排序、join等算子需要将数据重新排版
shuffle的过程是上游的数据处理完毕写出到自己的磁盘上,然后下游的数据从磁盘上面拉取
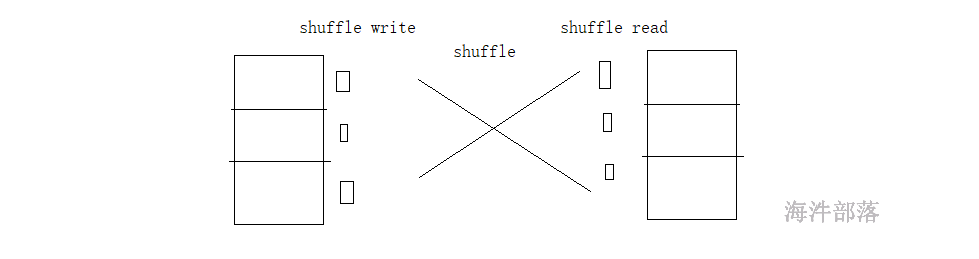
重新排版打乱重分是需要存在规则的
中间数据的流向规则叫做分区器 partitioner,这个分区器一般是存在于shuffle类算子中的,我们可以这么说,shuffle类算子一定会带有分区器,分区器也可以单独存在,人为定义分发规则
groupBy groupBykey reduceBykey 自带的分区器HashPartitioner

sortby sortBykey rangePartitioner

hashPartitioner
规则 按照key的hashCode %下游分区 = 分区编号


保证取余的结果为正向结果
hash取余的方式,不管数据分发到下游的什么分区中,最终结果都是相同的数据放入到一起
演示结果
scala> val arr = Array(1,2,3,4,5,6,7,8,9)
arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> sc.makeRDD(arr,3)
res78: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[73] at makeRDD at <console>:27
scala> res78.mapPartitionsWithIndex((index,it)=> it.map((index,_)))
res79: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[74] at mapPartitionsWithIndex at <console>:26
scala> res79.collect
res80: Array[(Int, Int)] = Array((0,1), (0,2), (0,3), (1,4), (1,5), (1,6), (2,7), (2,8), (2,9))
scala> res78.map(t=>(t,t))
res81: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[75] at map at <console>:26
scala> res78.partitioner
res82: Option[org.apache.spark.Partitioner] = None
scala> res81.reduceByKey(_+_)
res84: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[76] at reduceByKey at <console>:26
scala> res84.partitioner
res85: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@3)
scala> res84.mapPartitionsWithIndex((index,it)=> it.map((index,_)))
res88: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[77] at mapPartitionsWithIndex at <console>:26
scala> res88.collect
res89: Array[(Int, (Int, Int))] = Array((0,(6,6)), (0,(3,3)), (0,(9,9)), (1,(4,4)), (1,(1,1)), (1,(7,7)), (2,(8,8)), (2,(5,5)), (2,(2,2)))演示的逻辑,就是按照key.hashcode进行分区,int类型的hashcode值是自己的本身
并且hash分区器的规则致使我们可以任意的修改下游的分区数量
scala> res81.reduceByKey(_+_,100)
res91: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[78] at reduceByKey at <console>:26
scala> res91.partitions.size
res92: Int = 100
scala> res81.reduceByKey(_+_,2)
res93: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[79] at reduceByKey at <console>:26
scala> res93.partitions.size
res94: Int = 2rangePartitioner
hashPartitioner规则非常简单,直接规定来一个数据按照hashcode规则的分配,规则比较简答,但是会出现数据倾斜
range分区规则中存在两个方法

rangeBounds界限,在使用这个分区器之前先做一个界限划定
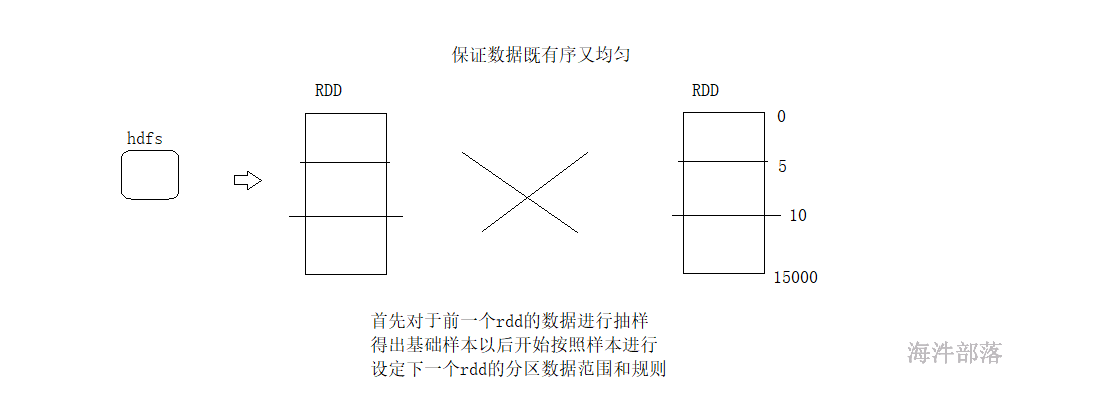
首先使用水塘抽样算法,在未知的数据集中抽取能够代表整个数据集的样本,根据样本进行规则设定
然后在使用getPartitions

首先存在水塘抽样,规定数据的流向以后再执行整体逻辑,会先触发计算

sortBykey是转换类的算子,不会触发计算

但是我们发现它触发计算了,因为首先在计算之前先进行水塘抽样,能够规定下游的数据规则,然后再进行数据的计算
scala> arr
res101: Array[Int] = Array(1, 9, 2, 8, 3, 7, 4, 6, 5)
scala> arr.map(t=> (t,t))
res102: Array[(Int, Int)] = Array((1,1), (9,9), (2,2), (8,8), (3,3), (7,7), (4,4), (6,6), (5,5))
scala> sc.makeRDD(res102)
res104: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[94] at makeRDD at <console>:27
scala> res104.sortByKey()
res105: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[97] at sortByKey at <console>:26
scala> res105.partitioner
res106: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.RangePartitioner@fe1f9dea)
scala> res104.sortByKey(true,3)
res107: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[100] at sortByKey at <console>:26
scala> res107.mapPartitionsWithIndex((index,it)=> it.map((index,_)))
res109: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[101] at mapPartitionsWithIndex at <console>:26
scala> res109.collect
res110: Array[(Int, (Int, Int))] = Array((0,(1,1)), (0,(2,2)), (0,(3,3)), (1,(4,4)), (1,(5,5)), (1,(6,6)), (2,(7,7)), (2,(8,8)), (2,(9,9)))range分区器,它是先做抽样然后指定下游分区的数据界限
它可以修改分区数量,但是分区数量不能大于元素个数,必须要保证每个分区中都有元素
scala> res104.sortByKey(true,3)
res111: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[104] at sortByKey at <console>:26
scala> res104.sortByKey(true,300)
res112: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[107] at sortByKey at <console>:26
scala> res111.partitions.size
res114: Int = 3
scala> res112.part9.2.1.4 自定义分区器
工作的过程中我们会遇见数据分类的情况,想要根据自己的需求定义分区的规则,让符合规则的数据发送到不同的分区中,这个时候我们就需要自定义分区器了
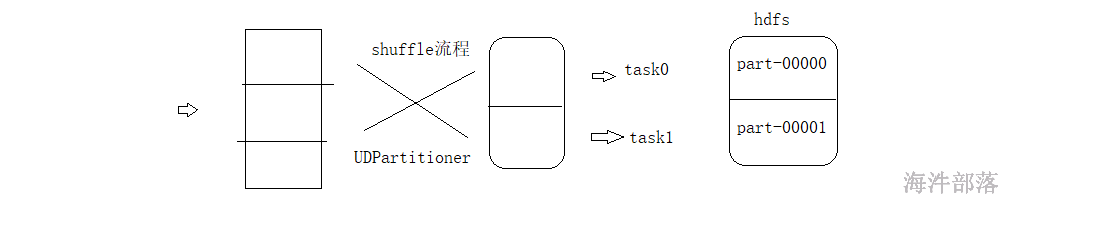
定义分区器,让数据发送到不同的分区,从而不同的task任务输出的文件结果内容也不同
# 自己创建数据data/a.txt
hello tom hello jack
hello tom hello jack
hello tom hello jack
hello tom hello jack
hello tom hello jack
# 需求就是将数据按照规则进行分发到不同的分区中
# 存储的时候一个文件存储hello其他的文件存储tom jack分区器的定义需要实现分区器的接口
class MyPartitioner extends Partitioner{
override def numPartitions: Int = ???
// 设定下游存在几个分区
override def getPartition(key: Any): Int = ???
// 按照key设定分区的位置
}整体代码:
package com.hainiu.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
object Test1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("parse")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.textFile("data/a.txt")
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
val rdd1 = rdd.partitionBy(new MyPartitioner)
val fs = FileSystem.get(new Configuration())
val out = "data/res"
if(fs.exists(new Path(out)))
fs.delete(new Path(out),true)
rdd1.saveAsTextFile(out)
}
}
class MyPartitioner extends Partitioner{
override def numPartitions: Int = 2
override def getPartition(key: Any): Int = {
if(key.toString.equals("hello"))
0
else
1
}
}
课堂练习
# 需求
# 按照teacher.txt中的数据,包含专业和老师的数据
# 使用自定义分区的方式实现专业top2
# 思路
# 1 首先求出每个老师的访问量
# 2 按照专业将访问量进行分区
# 3 然后使用mapPartitions一次性取出一个分区进行排序package com.hainiu.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import java.net.URL
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("parse")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd:RDD[((String,String),Int)] = sc.textFile("data/teacher.txt")
.map(t=>{
val url = new URL(t) //spark.hainiubl.com/unclewang
val host = url.getHost //spark.hainiubl.com
val path = url.getPath // /unclewang
val subject = host.split("\\.")(0)
val teacher = path.substring(1)
((subject,teacher),1)
}).reduceByKey(_+_)
val rddSubject:RDD[String] = rdd.keys.map(_._1).distinct()
val arrSubject = rddSubject.collect()
val rdd1 = rdd.partitionBy(new MyTeacherPartitioner(arrSubject))
rdd1.mapPartitions(it=>{
it.toList.sortBy(-_._2).take(2).toIterator
}).foreach(println)
}
}
class MyTeacherPartitioner(arr:Array[String]) extends Partitioner{
override def numPartitions: Int = arr.size
override def getPartition(key: Any): Int = {
val subject = key.asInstanceOf[(String,String)]._1
arr.indexOf(subject)
}
}
9.2.1.5 join的原理
join是两个结果集之间的链接,需要进行数据的匹配
演示一下join是否存在shuffle
scala> val arr = Array(("zhangsan",300),("lisi",400),("wangwu",350),("zhaosi",450))
arr: Array[(String, Int)] = Array((zhangsan,300), (lisi,400), (wangwu,350), (zhaosi,450))
scala> val arr1 = Array(("zhangsan",22),("lisi",24),("wangwu",30),("guangkun",5))
arr1: Array[(String, Int)] = Array((zhangsan,22), (lisi,24), (wangwu,30), (guangkun,5))
scala> sc.makeRDD(arr,3)
res116: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[108] at makeRDD at <console>:27
scala> sc.makeRDD(arr1,3)
res117: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[109] at makeRDD at <console>:27
scala> res116 join res117
res118: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[112] at join at <console>:28
scala> res118.collect
res119: Array[(String, (Int, Int))] = Array((zhangsan,(300,22)), (wangwu,(350,30)), (lisi,(400,24)))如果两个rdd没有分区器,分区个数一致
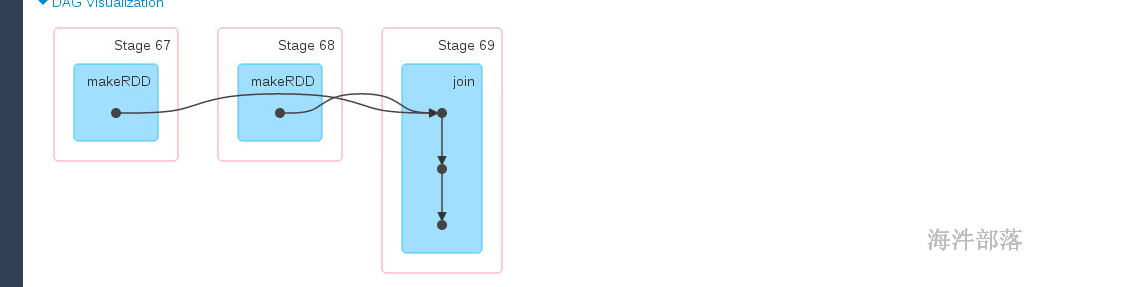

分区个数不变
如果分区个数不一致,产生的rdd的分区个数以多的为主
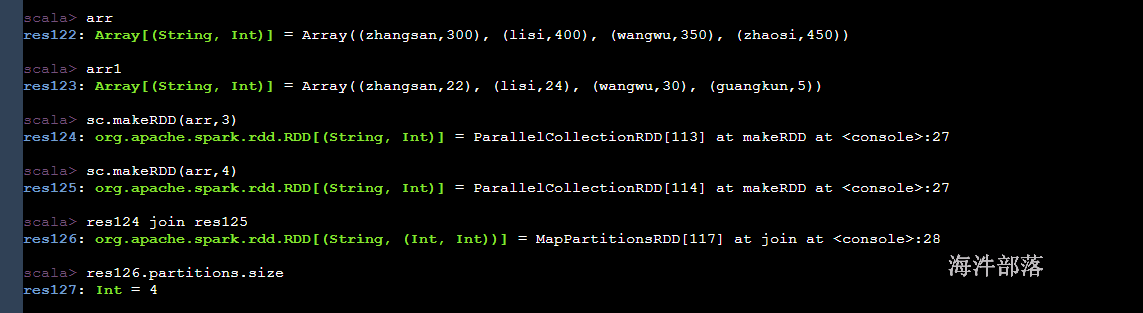
scala> sc.makeRDD(arr,3)
res128: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[118] at makeRDD at <console>:27
scala> sc.makeRDD(arr1,3)
res129: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[119] at makeRDD at <console>:27
scala> res128.reduceByKey(_+_)
res130: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[120] at reduceByKey at <console>:26
scala> res129.reduceByKey(_+_)
res131: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[121] at reduceByKey at <console>:26
scala> res130 join res131
res132: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[124] at join at <console>:28
scala> res132.collect
res133: Array[(String, (Int, Int))] = Array((zhangsan,(300,22)), (wangwu,(350,30)), (lisi,(400,24)))
scala> res132.partitions.size
res134: Int = 3如果分区个数一样并且分区器一样,那么是没有shuffle的
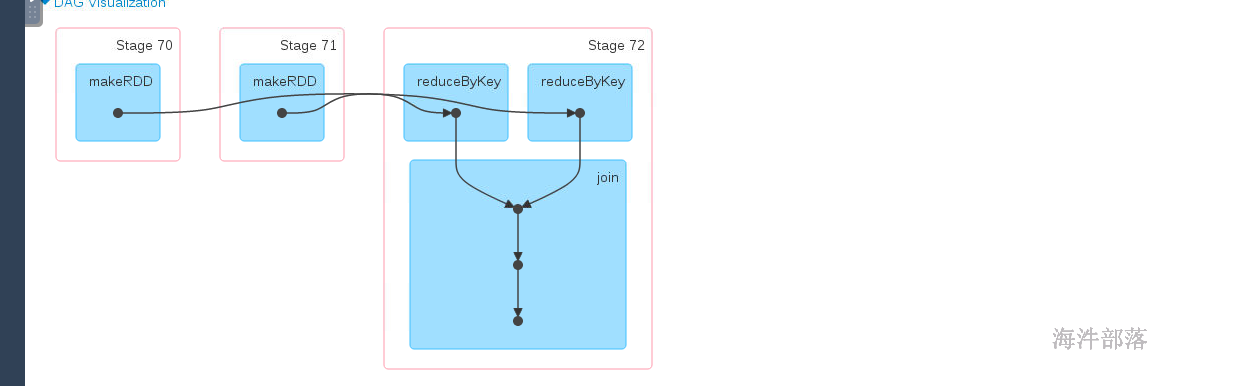
分区个数和原来的一样
scala> val arr = Array(("zhangsan",300),("lisi",400),("wangwu",350),("zhaosi",450))
arr: Array[(String, Int)] = Array((zhangsan,300), (lisi,400), (wangwu,350), (zhaosi,450))
scala> val arr1 = Array(("zhangsan",22),("lisi",24),("wangwu",30),("guangkun",5))
arr1: Array[(String, Int)] = Array((zhangsan,22), (lisi,24), (wangwu,30), (guangkun,5))
scala> sc.makeRDD(arr,3)
res0: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[0] at makeRDD at <console>:27
scala> sc.makeRDD(arr1,4)
res1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[1] at makeRDD at <console>:27
scala> res0.reduceByKey(_+_)
res2: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[2] at reduceByKey at <console>:26
scala> res1.reduceByKey(_+_)
res3: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[3] at reduceByKey at <console>:26
scala> res2 join res3
res4: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[6] at join at <console>:28
scala> res4.collect
res5: Array[(String, (Int, Int))] = Array((zhangsan,(300,22)), (wangwu,(350,30)), (lisi,(400,24)))
scala> res4.partitions.size
res6: Int = 4都存在分区器但是分区个数不同,也会存在shuffle
分区个数以多的为主
scala> arr
res7: Array[(String, Int)] = Array((zhangsan,300), (lisi,400), (wangwu,350), (zhaosi,450))
scala> arr1
res8: Array[(String, Int)] = Array((zhangsan,22), (lisi,24), (wangwu,30), (guangkun,5))
scala> sc.makeRDD(arr,3)
res9: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[7] at makeRDD at <console>:27
scala> sc.makeRDD(arr,4)
res10: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[8] at makeRDD at <console>:27
scala> res9.reduceByKey(_+_)
res11: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[9] at reduceByKey at <console>:26
scala> res10 join res11
res12: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[12] at join at <console>:28
scala> res12.partitions.size
res13: Int = 3
scala> res12.collect
res14: Array[(String, (Int, Int))] = Array((zhangsan,(300,300)), (wangwu,(350,350)), (lisi,(400,400)), (zhaosi,(450,450)))
一个带有分区器一个没有分区器,那么以带有分区器的rdd分区数量为主,并且存在shuffle

