Spark的RDD编程03
9.2.1.5 join练习
以后在计算的过程中我们不可能是单文件计算,以后会涉及到多个文件联合计算
现在存在这样的两个文件
# 需求
# 存在这样一个表 movies电影表
# movie_id movie_name movie_types
# 存在一个评分表
# user_id movie_id score timestamp
# 腾讯视频或者是爱奇艺
# 看过这个电影的人喜欢什么
# 问题1 每个用户最喜欢哪个类型的电影[按照观看量]
# 问题2 每个类型中评分最高的前三个电影[平均分]
# 问题3 给每个用户推荐最喜欢的类型的前三个电影第一问代码:
package com.hainiu.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Step1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("step2")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val moviesRDD: RDD[(String, (String, String))] = sc.textFile("data/movies.txt")
//mid name type
.map(t => {
val strs = t.split(",")
val mid = strs.head
val types = strs.reverse.head
val name = strs.tail.reverse.tail.reverse.mkString(" ")
(mid, name, types)
}).flatMap(t => {
val types = t._3.split("\\|")
types.map(e => (t._1, (t._2, e)))
//mid name type
})
val ratingsRDD: RDD[(String, (String, Double))] = sc.textFile("data/ratings.txt")
.map(t => {
val strs = t.split(",")
(strs(1), (strs(0), strs(2).toDouble))
//mid userid score
})
//mid name type userid score
val baseData: RDD[(String, ((String, String), (String, Double)))] = moviesRDD.join(ratingsRDD)
val rdd1: RDD[((String, String), Int)] = baseData.map(t => {
((t._2._2._1, t._2._1._2), 1)
}).reduceByKey(_ + _)
val rdd2: RDD[(String, Iterable[(String, Int)])] = rdd1.map(t => {
(t._1._1, (t._1._2, t._2))
}).groupByKey()
val res: RDD[(String, (String, Int))] = rdd2.mapValues(t => {
var max = 0
var max_tp: (String, Int) = null
t.foreach(tp => {
if (tp._2 > max) {
max = tp._2
max_tp = tp
}
})
max_tp
})
res.foreach(println)
}
}第二问代码:
package com.hainiu.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Step2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("step2")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val moviesRDD: RDD[(String, (String, String))] = sc.textFile("data/movies.txt")
//mid name type
.map(t => {
val strs = t.split(",")
val mid = strs.head
val types = strs.reverse.head
val name = strs.tail.reverse.tail.reverse.mkString(" ")
(mid, name, types)
}).flatMap(t => {
val types = t._3.split("\\|")
types.map(e => (t._1, (t._2, e)))
//mid name type
})
val ratingsRDD: RDD[(String, (String, Double))] = sc.textFile("data/ratings.txt")
.map(t => {
val strs = t.split(",")
(strs(1), (strs(0), strs(2).toDouble))
//mid userid score
})
//mid name type userid score
val baseData: RDD[(String, ((String, String), (String, Double)))] = moviesRDD.join(ratingsRDD)
val groupData: RDD[((String, String), Iterable[Double])] = baseData.map(t => {
((t._2._1._2, t._2._1._1), t._2._2._2)
//type name score
}).groupByKey()
val typeMovieAvg: RDD[((String, String), Double)] = groupData.mapValues(t=> t.sum/t.size)
val groupedData: RDD[(String,Iterable[(String,Double)])] =typeMovieAvg.map(t=>{
(t._1._1,(t._1._2,t._2))
}).groupByKey()
val res = groupedData.mapValues(_.toList.sortBy(-_._2).take(3))
res.foreach(println)
}
}第三问代码:
package com.hainiu.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Step1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("step2")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val moviesRDD: RDD[(String, (String, String))] = sc.textFile("data/movies.txt")
//mid name type
.map(t => {
val strs = t.split(",")
val mid = strs.head
val types = strs.reverse.head
val name = strs.tail.reverse.tail.reverse.mkString(" ")
(mid, name, types)
}).flatMap(t => {
val types = t._3.split("\\|")
types.map(e => (t._1, (t._2, e)))
//mid name type
})
val ratingsRDD: RDD[(String, (String, Double))] = sc.textFile("data/ratings.txt")
.map(t => {
val strs = t.split(",")
(strs(1), (strs(0), strs(2).toDouble))
//mid userid score
})
//mid name type userid score
val baseData: RDD[(String, ((String, String), (String, Double)))] = moviesRDD.join(ratingsRDD)
val rdd1: RDD[((String, String), Int)] = baseData.map(t => {
((t._2._2._1, t._2._1._2), 1)
}).reduceByKey(_ + _)
val rdd2: RDD[(String, Iterable[(String, Int)])] = rdd1.map(t => {
(t._1._1, (t._1._2, t._2))
}).groupByKey()
val res: RDD[(String, (String, Int))] = rdd2.mapValues(t => {
var max = 0
var max_tp: (String, Int) = null
t.foreach(tp => {
if (tp._2 > max) {
max = tp._2
max_tp = tp
}
})
max_tp
})
res.foreach(println)
}
}9.2.1.4 RDD 间操作
假设rdd的元素是:{1, 2, 3},other元素是:{3, 4, 5}
| 函数 | 目的 | 示例 | 结果 |
|---|---|---|---|
| union(other) | 生成一个包含两个RDD中所有元素的RDD | rdd.union(other) | {1,2,3,3,4,5} |
| intersection(other) | 求两个RDD交集的RDD | rdd.intersection(other) | {3} |
| subtract(other) | 移除一个RDD中的内容,差集 | rdd.subtract(other) | {1,2} |
| cartesian(other) | 与另一个RDD的笛卡儿积 | rdd.cartesian(other) | {(1,3),(1,4)….} |
注意:类型要一致
scala> val arr = Array(1,2,3,4,5)
arr: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val arr1 = Array(3,4,5,6,7)
arr1: Array[Int] = Array(3, 4, 5, 6, 7)
scala> sc.makeRDD(arr)
res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:27
scala> sc.makeRDD(arr1)
res1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:27
scala> res0 union res1
res2: org.apache.spark.rdd.RDD[Int] = UnionRDD[2] at union at <console>:28
scala> res2.collect
res3: Array[Int] = Array(1, 2, 3, 4, 5, 3, 4, 5, 6, 7)
scala> res0 subtract res1
res4: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[6] at subtract at <console>:28
scala> res4.collect
res5: Array[Int] = Array(1, 2)
scala> res0 intersection res1
res6: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[12] at intersection at <console>:28
scala> res6.collect
res7: Array[Int] = Array(3, 4, 5)
scala> res0.partitions.size
res8: Int = 9
scala> res0 cartesian res1
res9: org.apache.spark.rdd.RDD[(Int, Int)] = CartesianRDD[13] at cartesian at <console>:28
scala> res9.collect
res10: Array[(Int, Int)] = Array((1,3), (1,4), (1,5), (1,6), (1,7), (2,3), (2,4), (2,5), (2,6), (2,7), (3,3), (3,4), (3,5), (3,6), (3,7), (4,3), (4,4), (4,5), (4,6), (4,7), (5,3), (5,4), (5,5), (5,6), (5,7))
scala> res9.partitions.size
res11: Int = 81UNION算子的特殊之处
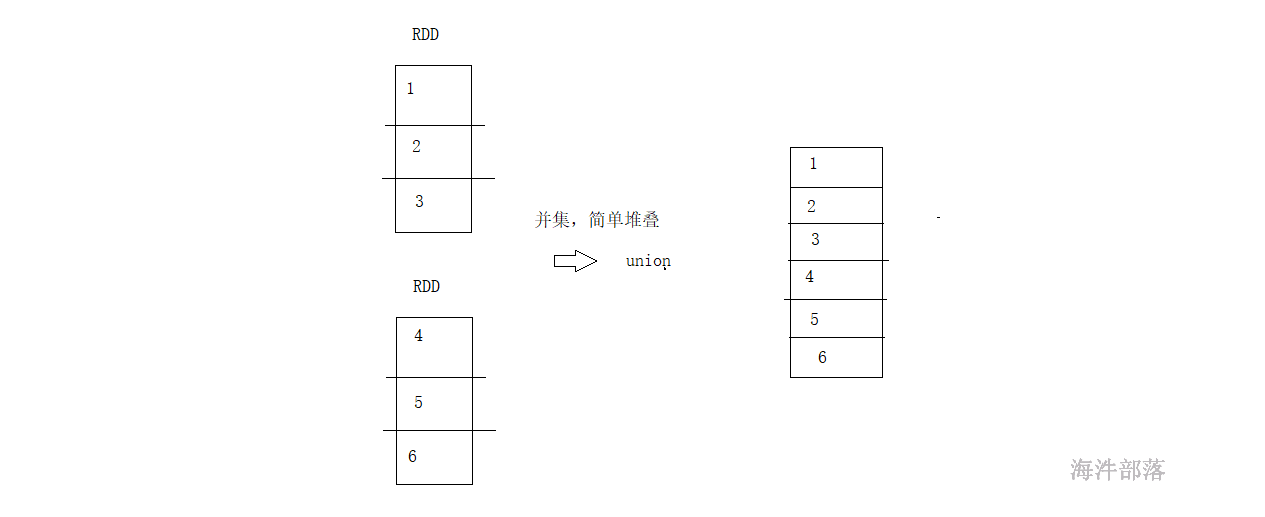
union完毕以后rdd的分区数量会增多,和原来的rdd相比元素分配是一样的,并且不存在shuffle
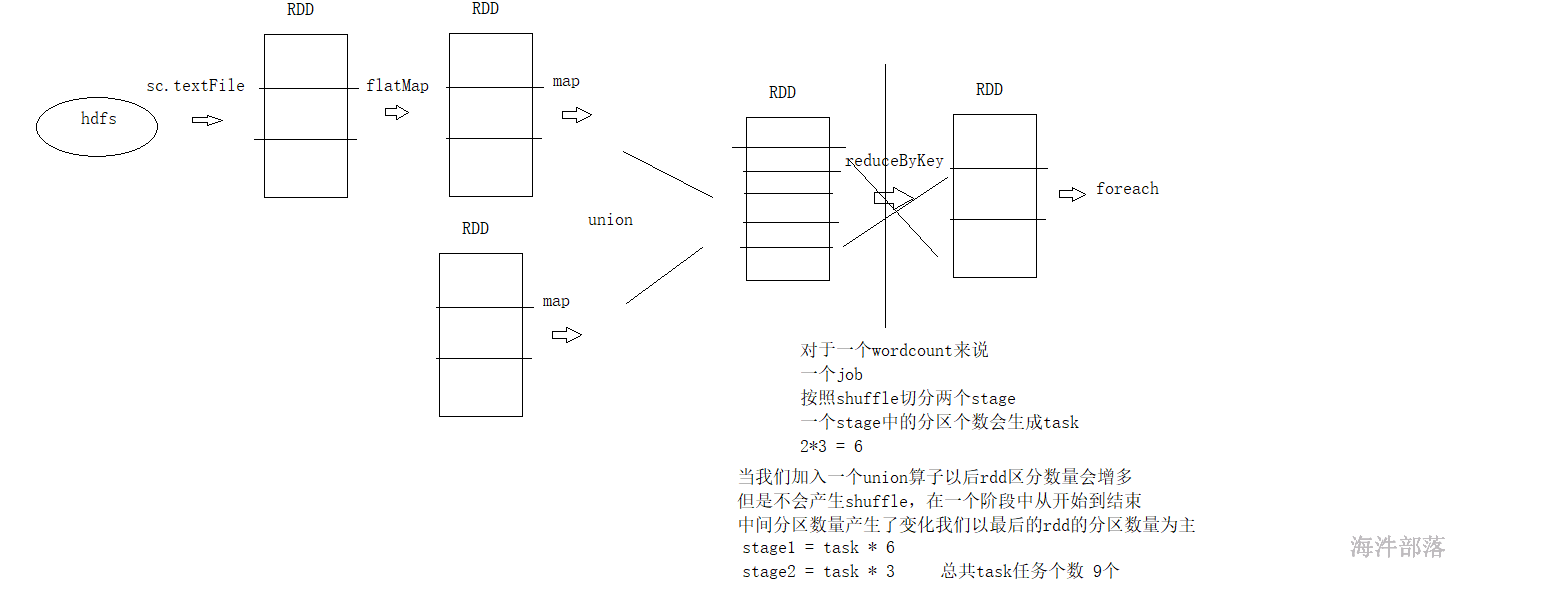
一个阶段中的task任务的个数以最后一个rdd的分区数量为主
9.2.1.5 coalesce 与 repartition

当分区由多变少时,不需要shuffle,也就是父RDD与子RDD之间是窄依赖。 但极端情况下(1000个分区变成1个分区),这时如果将shuffle设置为false,父子RDD是窄依赖关系,他们同处在一个Stage中,就可能造成spark程序的并行度不够,从而影响性能,如果1000个分区变成1个分区,为了使coalesce之前的操作有更好的并行度,可以将shuffle设置为true。
scala> val arr = Array(1,2,3,4,5,6,7,8,9)
arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> sc.makeRDD(arr,3)
res12: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[14] at makeRDD at <console>:27
scala> res12.coalesce(2)
res13: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[15] at coalesce at <console>:26
scala> res13.partitions.size
res14: Int = 2
scala> res12.coalesce(12)
res15: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[16] at coalesce at <console>:26
scala> res15.partitions.size
res16: Int = 3
scala> res12.repartition(2)
res17: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[20] at repartition at <console>:26
scala> res17.partitions.size
res18: Int = 2
scala> res12.repartition(12)
res19: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[24] at repartition at <console>:26
scala> res19.partitions.size
res20: Int = 12

repartition带有shuffle可以增加也可以减少
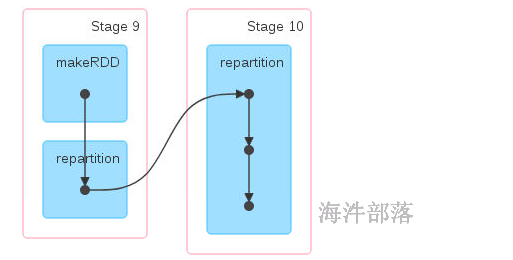
coalesce算子只能减少不能增加

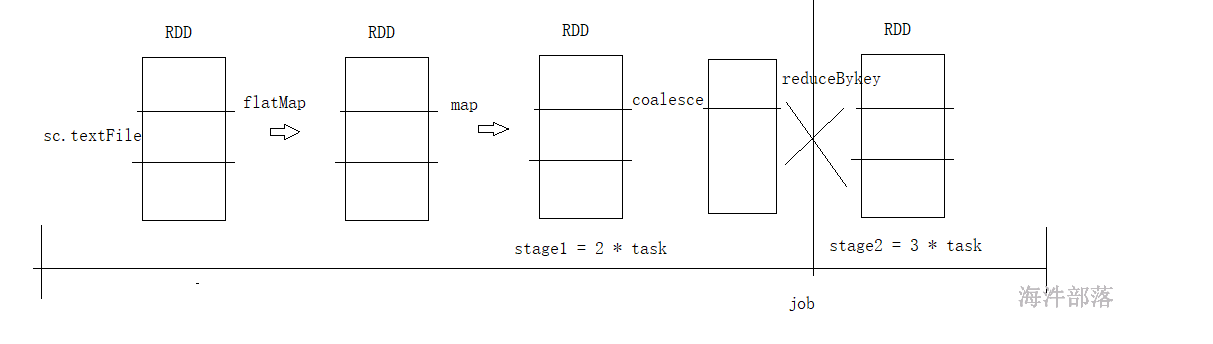
如果说一个阶段中存在union或者是coalesce算子会出现rdd的分区数量变化,但是没有shuffle的情况,看最后的rdd的分区个数就是当前阶段的task任务的个数
9.2.1.6 其他转换操作
foldByKey


scala> val arr = Array(("a",1),("b",1),("a",1),("b",1),("a",1),("c",1))
arr: Array[(String, Int)] = Array((a,1), (b,1), (a,1), (b,1), (a,1), (c,1))
scala> sc.makeRDD(arr,3)
res30: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[33] at makeRDD at <console>:27
scala> res30.reduceByKey(_+_)
res31: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[34] at reduceByKey at <console>:26
scala> res31.collect
res32: Array[(String, Int)] = Array((c,1), (a,3), (b,2))
scala> res30.foldByKey
def foldByKey(zeroValue: Int)(func: (Int, Int) => Int): org.apache.spark.rdd.RDD[(String, Int)]
def foldByKey(zeroValue: Int,numPartitions: Int)(func: (Int, Int) => Int): org.apache.spark.rdd.RDD[(String, Int)]
def foldByKey(zeroValue: Int,partitioner: org.apache.spark.Partitioner)(func: (Int, Int) => Int): org.apache.spark.rdd.RDD[(String, Int)]
scala> res30.foldByKey(0)(_+_)
res33: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[35] at foldByKey at <console>:26
scala> res33.collect
res34: Array[(String, Int)] = Array((c,1), (a,3), (b,2))
scala> res30.foldByKey(10)(_+_)
res35: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[36] at foldByKey at <console>:26
scala> res35.collect
res36: Array[(String, Int)] = Array((c,11), (a,33), (b,22))
scala> res30.foldByKey(0,10)(_+_)
res37: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[37] at foldByKey at <console>:26
scala> res37.partitions.size
res38: Int = 10带有shuffle并且可以修改分区
aggregateByKey
带有初始值的reduceByKey,
分区内的算法和分区间的算法可以不一样

对PairRDD中相同的Key值进行聚合操作,在聚合过程中同样使用了一个中立的初始值。和aggregate函数类似,aggregateByKey返回值的类型不需要和
RDD中value的类型一致。因为aggregateByKey是对相同Key中的值进行聚合操作,所以aggregateByKey函数最终返回的类型还是PairRDD,对应的结果是Key和聚合后的值。
scala> arr
res39: Array[(String, Int)] = Array((a,1), (b,1), (a,1), (b,1), (a,1), (c,1))
scala> sc.makeRDD(arr,3)
res40: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[38] at makeRDD at <console>:27
scala> res40.aggregateByKey(0)(_+_,_+_)
res41: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[39] at aggregateByKey at <console>:26
scala> res41.collect
res42: Array[(String, Int)] = Array((c,1), (a,3), (b,2))
scala> res40.aggregateByKey(10)(_+_,_+_)
res43: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[40] at aggregateByKey at <console>:26
scala> res43.collect
res44: Array[(String, Int)] = Array((c,11), (a,33), (b,22))
scala> res40.aggregateByKey
def aggregateByKey[U](zeroValue: U)(seqOp: (U, Int) => U,combOp: (U, U) => U)(implicit evidence$3: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[(String, U)]
def aggregateByKey[U](zeroValue: U,numPartitions: Int)(seqOp: (U, Int) => U,combOp: (U, U) => U)(implicit evidence$2: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[(String, U)]
def aggregateByKey[U](zeroValue: U,partitioner: org.apache.spark.Partitioner)(seqOp: (U, Int) => U,combOp: (U, U) => U)(implicit evidence$1: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[(String, U)]
scala> res40.aggregateByKey(10,5)(_+_,_+_)
res45: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[41] at aggregateByKey at <console>:26
scala> res45.partitions.size
res46: Int = 5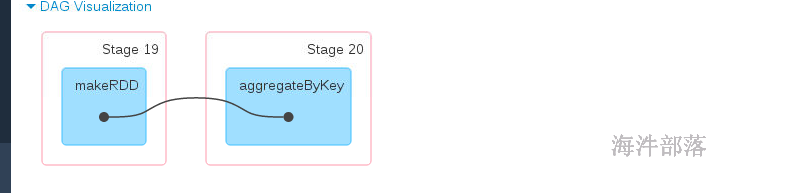
带有shuffle的,并且可以修改分区数量,也是分组类算子的一种,采用的时候hash分区器
combineByKey
spark的reduceByKey、aggregateByKey、foldByKey函数底层调用的都是 combinerByKey(现在换成了 combineByKeyWithClassTag);他们都可以实现局部聚合再全局聚合;语法:
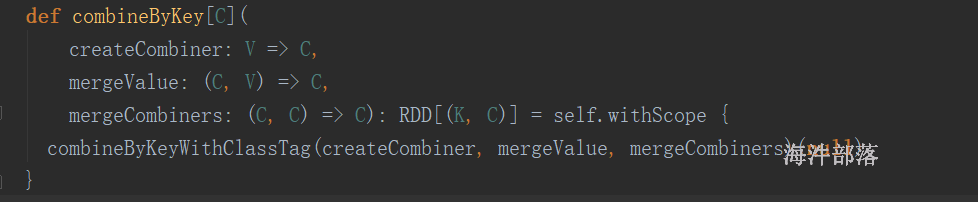
mergeValue: (C, V) => C,该函数把元素V合并到之前的元素C(createCombiner)上 (这个操作在每个分区内进行)
mergeCombiners: (C, C) => C,该函数把2个元素C合并 (这个操作在不同分区间进行)
scala> arr
res47: Array[(String, Int)] = Array((a,1), (b,1), (a,1), (b,1), (a,1), (c,1))
scala> sc.makeRDD(arr,3)
res48: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[42] at makeRDD at <console>:27
scala> res48.combineByKey
combineByKey combineByKeyWithClassTag
scala> res48.combineByKey
def combineByKey[C](createCombiner: Int => C,mergeValue: (C, Int) => C,mergeCombiners: (C, C) => C): org.apache.spark.rdd.RDD[(String, C)]
def combineByKey[C](createCombiner: Int => C,mergeValue: (C, Int) => C,mergeCombiners: (C, C) => C,numPartitions: Int): org.apache.spark.rdd.RDD[(String, C)]
def combineByKey[C](createCombiner: Int => C,mergeValue: (C, Int) => C,mergeCombiners: (C, C) => C,partitioner: org.apache.spark.Partitioner,mapSideCombine: Boolean,serializer: org.apache.spark.serializer.Serializer): org.apache.spark.rdd.RDD[(String, C)] ^
scala> res48.combineByKey((t:Int)=> t,(a:Int,b:Int)=> a+b , (a:Int,b:Int)=> a+b)
res50: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[43] at combineByKey at <console>:26
scala> res50.collect
res51: Array[(String, Int)] = Array((c,1), (a,3), (b,2))
scala> res48.combineByKey((t:Int)=> t+10,(a:Int,b:Int)=> a+b , (a:Int,b:Int)=> a+b)
res52: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[44] at combineByKey at <console>:26
scala> res52.collect
res53: Array[(String, Int)] = Array((c,11), (a,33), (b,22))初始化值以函数的形式进行使用

filterByRange
filter过滤元素,在排序完毕以后的结果集上面使用,按照范围得出符合元素规则的子结果集
子结果集是原来rdd的一个片段,分区和元素的部署对应情况不变
scala> val arr = Array((1,1),(2,2),(3,3),(4,4),(5,5),(6,6))
arr: Array[(Int, Int)] = Array((1,1), (2,2), (3,3), (4,4), (5,5), (6,6))
scala> sc.makeRDD(arr,6)
res57: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[47] at makeRDD at <console>:27
scala> res57.sortByKey()
res58: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[50] at sortByKey at <console>:26
scala> res58.mapPartitionsWithIndex((index,it)=> it.map((index,_)))
res59: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[51] at mapPartitionsWithIndex at <console>:26
scala> res59.collect
res60: Array[(Int, (Int, Int))] = Array((0,(1,1)), (1,(2,2)), (2,(3,3)), (3,(4,4)), (4,(5,5)), (5,(6,6)))
scala> res58.filterByRange(2,3)
res61: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[53] at filterByRange at <console>:26
scala> res61.collect
res62: Array[(Int, Int)] = Array((2,2), (3,3))
scala> res61.mapPartitionsWithIndex((index,it)=> it.map((index,_)))
res63: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[54] at mapPartitionsWithIndex at <console>:26
scala> res63.collect
res64: Array[(Int, (Int, Int))] = Array((0,(2,2)), (1,(3,3)))9.2.2 行动操作
假设rdd 的元素是:{1, 2, 3, 3}
假设rdd2 的元素是:{(“a”, 1), (“b”, 2)}
| 函数 | 目的 | 示例 | 结果 |
|---|---|---|---|
| collect() | 以数组的形式返回RDD中的所有元素 | rdd.collect() | {1, 2, 3, 3} |
| collectAsMap() | 该函数用于Pair RDD 最终返回Map类型的结果 | rdd2.collectAsMap() | Map(“a”->1,“b”->2) |
| count() | RDD中的元素个数 | rdd.count() | 4 |
| countByValue() | 各元素在RDD中出现的次数 | rdd.countByValue() | {(1, 1), (2, 1), (3, 2)} |
| take(n) | 从RDD中返回 n 个元素 | rdd.take(1) | {1} |
| first() | 从RDD中返回第一个元素 | rdd.first() | 1 |
| top(num) | 返回最大的 num 个元素 | rdd.top(2) | {3,3} |
| takeOrdered(num)(ordering) | 按照指定顺序返回前面num个元素 | rdd.takeOrdered(2) | {1,2} |
| reduce(func) | 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素,比如求和 | rdd.reduce((a,b)=>a+b) | ((1+2) + 3) + 3) = 9 |
| fold(zero)(func) | 和reduce一样,给定初值,每个分区计算时都会使用此初值 | rdd.fold(1)((a,b)=>a+b) | 2个分区时结果:1+ ((1+1) + 2) + ((1 +3) +3) |
| aggregate(zeroValue)(seqOp,combOp) | 和reduce类似,但可以返回类型不同的结果 | rdd.aggregate(0)((x,y) => x + y, (x,y) => x + y) | 9 |
| foreach(func) | 对每个元素使用func函数 | rdd.foreach(println(_)) | 在executor端打印输出所有元素 |
| foreachPartition | 每个分区遍历一次 |
演示代码
scala> val arr = Array(1,2,3,4,5,6,7,8,9)
arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> sc.makeRDD(arr,3)
res65: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[55] at makeRDD at <console>:27
scala> res65.collect
res66: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> res65.collectAsMap
<console>:26: error: value collectAsMap is not a member of org.apache.spark.rdd.RDD[Int]
res65.collectAsMap
^
scala> res65.map(t=>(t,t))
res68: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[56] at map at <console>:26
scala> res68.collect
res69: Array[(Int, Int)] = Array((1,1), (2,2), (3,3), (4,4), (5,5), (6,6), (7,7), (8,8), (9,9))
scala> res69.toMap
res70: scala.collection.immutable.Map[Int,Int] = Map(5 -> 5, 1 -> 1, 6 -> 6, 9 -> 9, 2 -> 2, 7 -> 7, 3 -> 3, 8 -> 8, 4 -> 4)
scala> res68.collectAsMap
res71: scala.collection.Map[Int,Int] = Map(8 -> 8, 2 -> 2, 5 -> 5, 4 -> 4, 7 -> 7, 1 -> 1, 9 -> 9, 3 -> 3, 6 -> 6)
scala>
scala> res65.size
<console>:26: error: value size is not a member of org.apache.spark.rdd.RDD[Int]
res65.size
^
scala> res65.length
<console>:26: error: value length is not a member of org.apache.spark.rdd.RDD[Int]
res65.length
^
scala> res65.count()
res74: Long = 9
scala> sc.textFile("/a.txt")
res75: org.apache.spark.rdd.RDD[String] = /a.txt MapPartitionsRDD[58] at textFile at <console>:25
scala> res75.flatMap(_.split(" "))
res76: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[59] at flatMap at <console>:26
scala> res76.map((_,1)).reduceByKey(_+_)
res77: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[61] at reduceByKey at <console>:26
scala> res77.collect
res78: Array[(String, Int)] = Array((tom,8), (hello,16), (world,8))
scala> res76.countByValue()
res79: scala.collection.Map[String,Long] = Map(tom -> 8, hello -> 16, world -> 8)
scala> arr
res80: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> sc.makeRDD(arr,3)
res81: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[65] at makeRDD at <console>:27
scala> res81.take(4)
res82: Array[Int] = Array(1, 2, 3, 4)
scala> rdd.sortBYKey()filterByRange()
<console>:24: error: not found: value rdd
rdd.sortBYKey()filterByRange()
^
scala> res81.first
res84: Int = 1
scala> res81.top(3)
res85: Array[Int] = Array(9, 8, 7)
scala> res81.takeOrdered(4)
res86: Array[Int] = Array(1, 2, 3, 4)
scala> class Student(val name:String,val age:Int)
defined class Student
scala> val s1 = new Student("zhangsan",20)
s1: Student = Student@281b0150
scala> val s2 = new Student("zhangsan",25)
s2: Student = Student@130ef15d
scala> val s3 = new Student("zhangsan",21)
s3: Student = Student@11ae085
scala> val arr = Array(s1,s2,s3)
arr: Array[Student] = Array(Student@281b0150, Student@130ef15d, Student@11ae085)
scala> sc.makeRDD(arr)
res87: org.apache.spark.rdd.RDD[Student] = ParallelCollectionRDD[68] at makeRDD at <console>:27
scala> res87.top(3)
<console>:26: error: No implicit Ordering defined for Student.
res87.top(3)
^
scala> arr
res89: Array[Student] = Array(Student@281b0150, Student@130ef15d, Student@11ae085)
scala> val arr = Array(1,2,3,4,5,6,7,8,9)
arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> sc.makeRDD(arr,3)
res90: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[69] at makeRDD at <console>:27
scala> res90.reduce((a,b)=> a+b)
res92: Int = 45
scala> res90.reduce(_+_)
res93: Int = 45
scala> res90.fold(0)(_+_)
res94: Int = 45
scala> res90.fold(10)(_+_)
res95: Int = 85
scala> res90.aggregate(0)(_+_,_+_)
res96: Int = 45
scala> res90.aggregate(10)(_+_,_+_)
res97: Int = 85foreachPartition
scala> res90.foreach(println)
scala> res90.foreachPartition(println)一般连接的数据都会使用foreachPartition或者是mapPartitions,查询数据mapPartitions,插入数据foreachPartition
比如我们将wordcount的最终结果插入到外部存储redis中
准备redis的环境
本地data/a.txt创建文件并且加入如下内容
hello tom hello jack
hello tom hello jack
hello tom hello jack
hello tom hello jack
hello tom hello jack整体代码
package com.hainiu.spark
import org.apache.spark.{SparkConf, SparkContext}
import redis.clients.jedis.Jedis
/**
* redis是一个k-v类型的数据库
* set 插入或者更新数据
* get 查询数据
*/
object ForeachPartition2Redis {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("test redis")
val sc = new SparkContext(conf)
sc.textFile("data/a.txt")
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.foreachPartition(it=>{
val redis = new Jedis("11.112.227.15",6379)
it.foreach(tp=>{
redis.set(tp._1,tp._2.toString)
})
redis.close()
})
}
}redis中的结果


