spark-rdd的缓存和内存管理 10 rdd的缓存和执行原理
10.1 cache算子
cache算子能够缓存中间结果数据到各个executor中,后续的任务如果需要这部分数据就可以直接使用避免大量的重复执行和运算
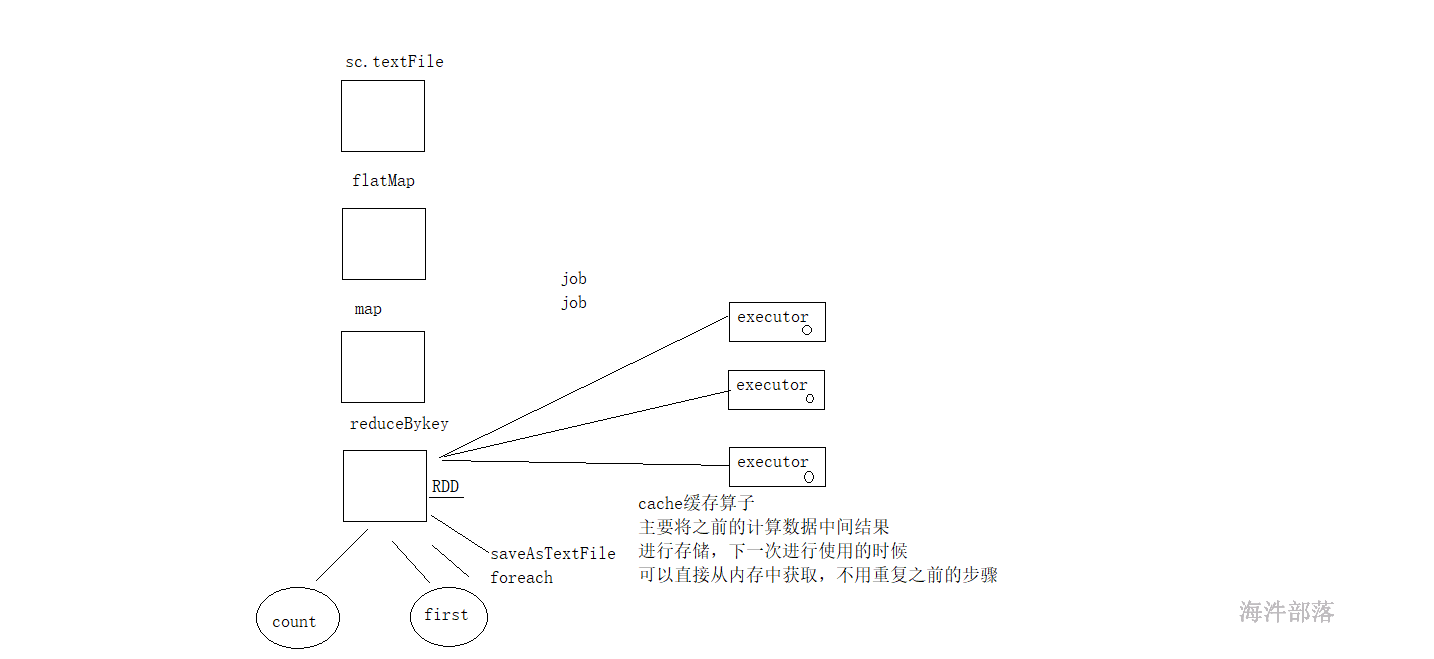
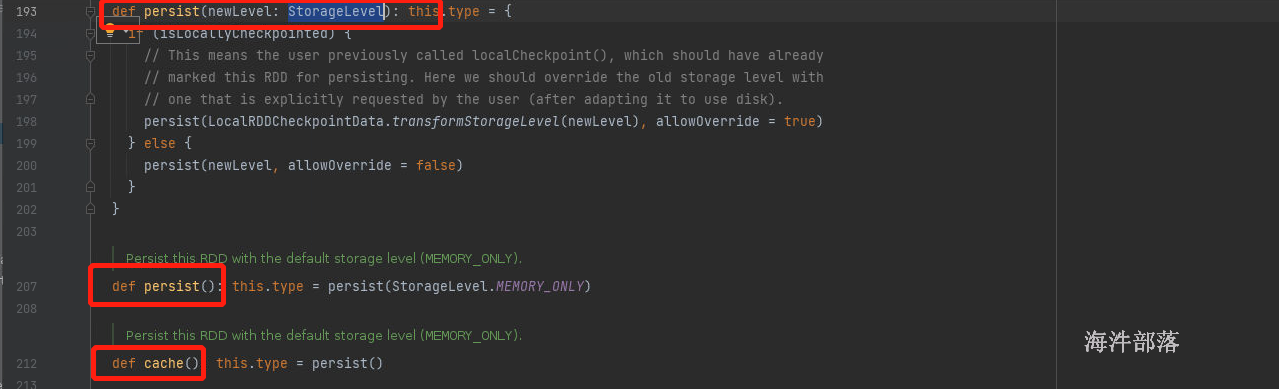
rdd 存储级别中默认使用的算子cache算子,cache算子的底层调用的是persist算子,persist算子底层使用的是persist(storageLevel)默认存储级别是memoryOnly
scala> sc.textFile("/a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
res101: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[78] at reduceByKey at <console>:25
scala> res101.cache()
res102: res101.type = ShuffledRDD[78] at reduceByKey at <console>:25
scala> res102.count
res103: Long = 3
scala> res102.first
res104: (String, Int) = (tom,8)
scala> res102.collect
res105: Array[(String, Int)] = Array((tom,8), (hello,16), (world,8))cache算子是转换类算子,不会触发执行运算,count算子触发运算,后续的算子的使用就可以直接从内存中取出值了
10.2 cache算子的存储位置
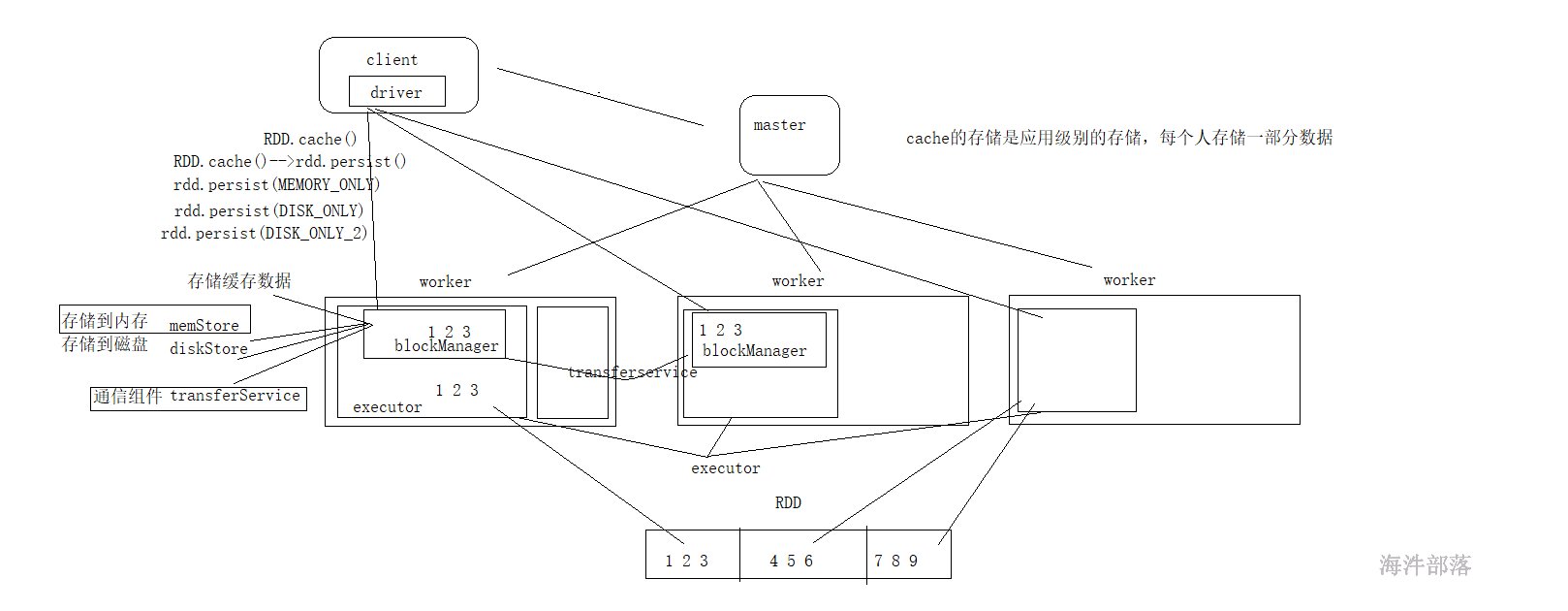
每个executor中都存在一个blockManager的组件,这个组件主要是executor缓存数据用的,并且是job级别
每个blockManager中存在三个组成部分 memstore diskStore transferService
10.3 rdd的缓存级别
rdd的存储级别选项

存储级别分为12种
分别根据构造器的参数不同
none 不存储
DISK_ONLY 仅磁盘方式,必然序列化 _deserialized = false
DISK_ONLY_2 存储磁盘并且备份数量2
MEMORY_ONLY 仅内存_deserialized = true 不序列化,executor就是一个jvm,使用的内存是jvm的内存,可以直接存储对象数据
MEMORY_ONLY_SER 仅内存并且是序列化的方式 _deserialized = true,将存储的jvm中的对象进行二进制byte[],存储起来,以内存的方式,序列化完毕的数据更能够减少存储空间
MEMORY_AND_DISK 先以内存为主,然后再使用磁盘,存储空间不够不会报错,会存储一部分数据,可以不序列化,不序列化指的时候内存的部分
MEMORY_AND_DISK_SER 存储的时候将存储的内容先序列化然后存储
OFF_HEAP 堆外内存,一个机器中除了jvm以外的内存,又叫做直接内存
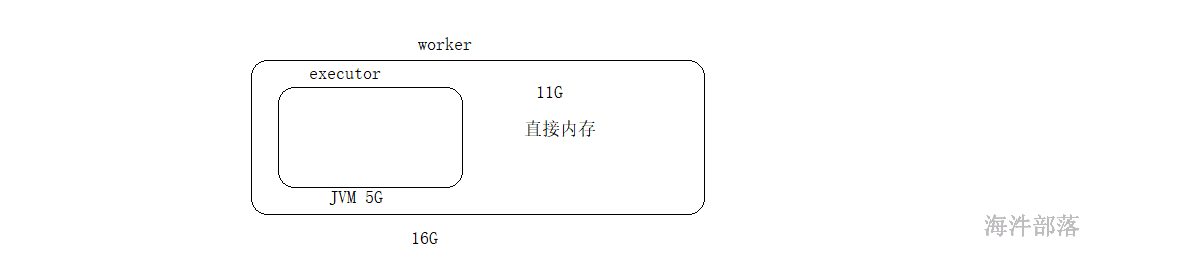
首先存储到直接内存中,可以使得jvm的内存使用量减少,效率更高,但是比较危险,jvm中存在GC,可以清空垃圾,但是如果使用直接内存的话,垃圾多了我们可以删除,但是如果应用程序异常退出,这个时候内存是没有人可以管理的
10.4 缓存的使用
scala> sc.textFile("/a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
res106: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[83] at reduceByKey at <console>:25
scala> res106.cache()
res107: res106.type = ShuffledRDD[83] at reduceByKey at <console>:25
scala> res107.count
res108: Long = 3
scala> res107.collect
res109: Array[(String, Int)] = Array((tom,8), (hello,16), (world,8))res107已经被缓存了,下次进行执行的时候可以从这个缓存数据中读取


绿色的RDD代表已经存储完毕

前面的应用计算已经跳过
查看缓存数据

缓存的位置,可以点进去查看

去重缓存
rdd.unpersist()
缓存是应用级别的,spark-shell它启动完毕的所有job都可以使用,关闭应用缓存也会失效
10.5 checkpoint
cache是应用级别的,spark-submit或者是spark-shell提交完毕都会启动一套executor
在这个应用中执行的所有job任务都可以共享cache的缓存数据,当然是单个应用的
多个应用共享一份数据怎么进行实现
checkpoint就是实现多应用共享数据的一种方式,原理就是一个应用将数据存储到外部,一个大家都能访问的位置,然后就可以直接使用了,使用的存储是hdfs,saveAsTextFile存储起来
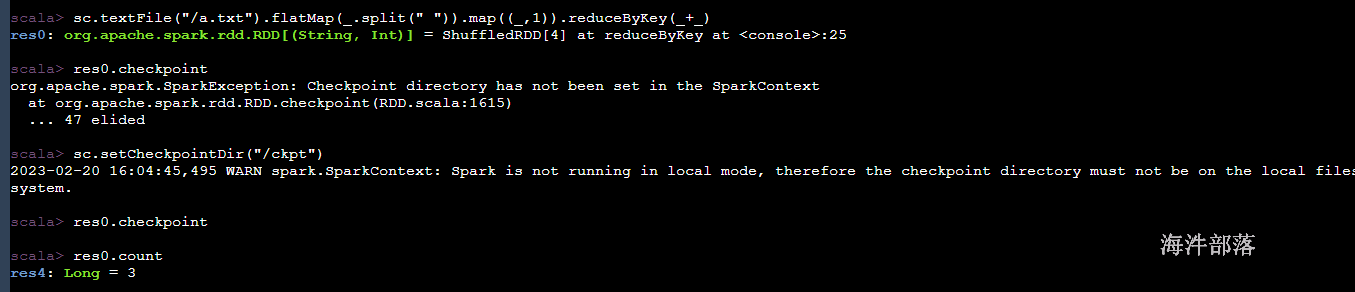
存储的hdfs的文件
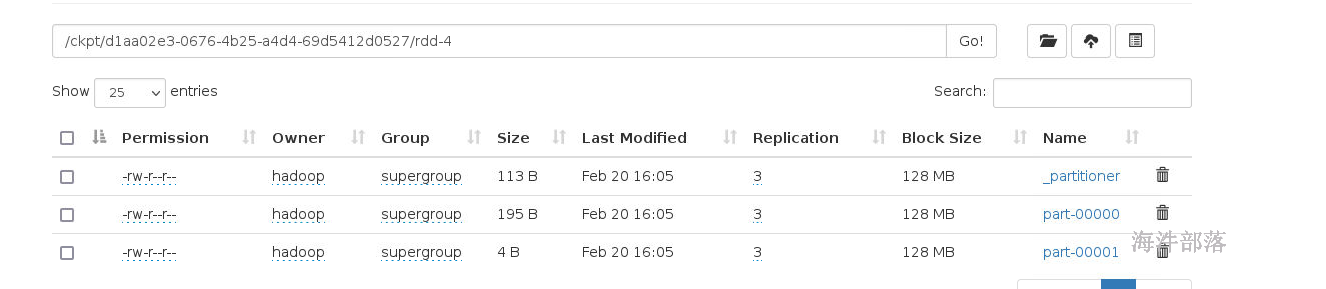
使用的时候和cache一样


我们发现数据是直接从ckpt中读取的,前面的计算逻辑都被跳过了
首先就是数据共享,现在数据已经存储到hdfs中了,我们直接从hdfs中拿,实现多应用共享
cache数据缓存完毕,下次使用的时候逻辑是不截断的,ckpt是截断的,前面什么都没有了
checkpoint是存储数据到hdfs的共享盘中,cache是存储到内存的缓存中,所以ckpt需要另外触发一次计算才可以


一次性调用collect,但是spark会执行两个任务
第一次的任务是collect,第二次的任务是为了存储数据到外部
所以为了优化任务的执行
rdd.cache()
rdd.checkpoint()
cache和checkpoint连用,这样的话,第二次执行的时候就可以直接从缓存中读取数据了,不需要进行第二次计算
10.6 rdd的五大特性
分析一下rdd的特性和执行流程
- A list of partitions 存在一系列的分区列表
- A function for computing each split 每个rdd上面都存在compute方法进行计算
- A list of dependencies on other RDDs 每个rdd上面都存在一系列的依赖关系
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) 在k-v类型的rdd上面存在可选的分区器
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file) 优先位置进行计算
1.每个rdd都存在一系列的分区列表,rdd弹性分布式数据集,必须是存在分区的,因为存在分区才会让集群多个线程进行执行,并行操作速度和效率更快
分区可以进行调节,shuffle类算子可以修改分区,coalesce算子和repartition算子,修改分区在一定程度上可以增加计算效率,一个阶段中的一个rdd的分区代表的是一个task任务,并且在读取hdfs文件的时候,一个block块对应的是一个分区,让数据的计算本地化执行
2.rdd是调用算子进行计算的,一个元素一个元素的进行计算,compute帮助进行递归rdd的数据使用用户定义的逻辑进行计算


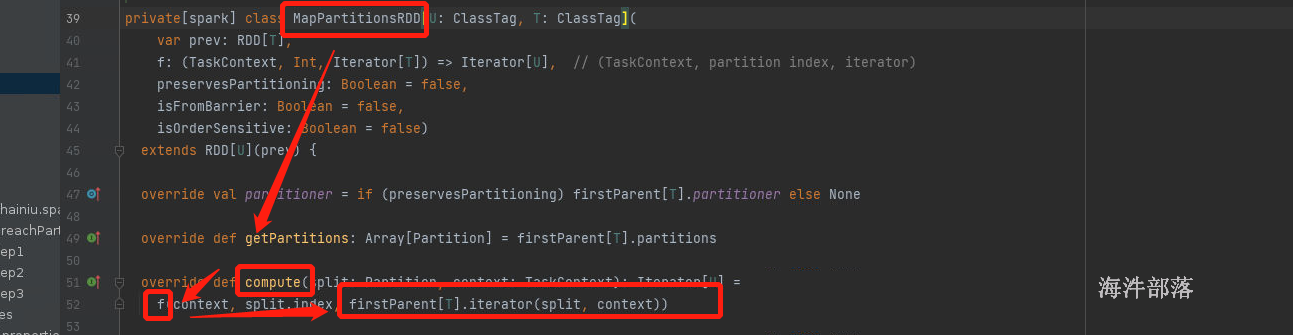
我们compute方法是如何遍历RDD中的元素的

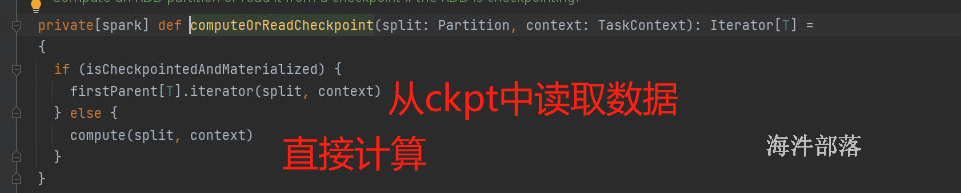

如果是缓存了,那么从缓存中读取数据 getOrCompute
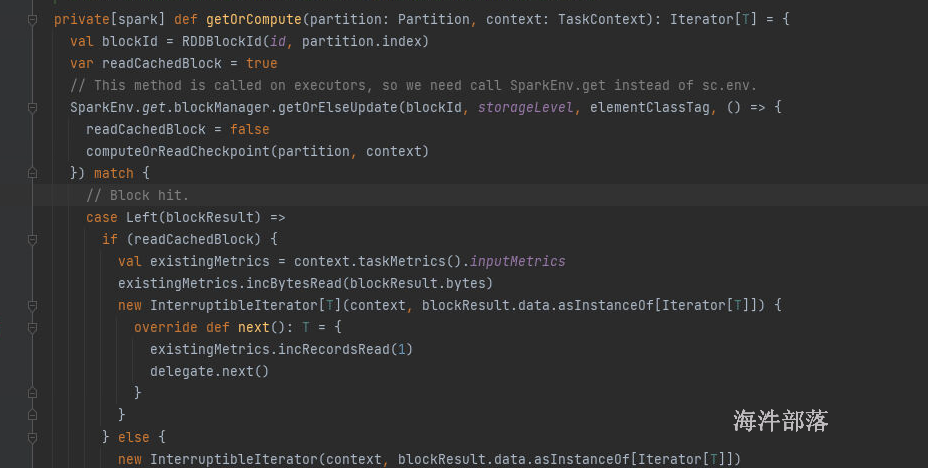
如果设置了缓存,并且已经有人计算完毕放入到缓存中了,那么直接从缓存中取值,如果缓存中没有值,我们需要计算并且存储到缓存中

读取数据,如果命中就直接返回,如果没有命中就计算
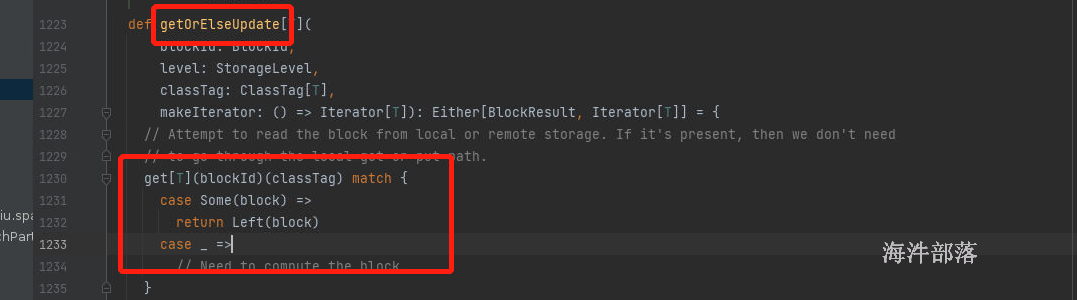
获取缓存数据
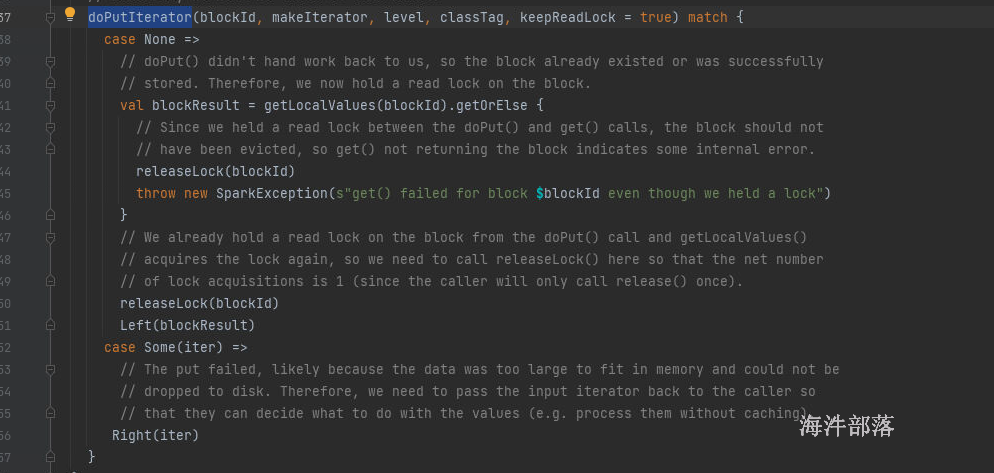
没有获取到数据需要进行计算,放入到缓存中,在从缓存中读取数据
doPutIterator 存储数据到缓存中,判断存储级别,分别放入数据到缓存或者磁盘中并且对数据进行备份和副本
然后当放入完毕以后再次从缓存中读取数据
3.rdd之间存在一系列的依赖关系
所说的依赖关系就是rdd之间的关系,依赖关系就是算子的关系,转换类算子的关系,比如调用的算子不同关系也不相同
map flatMap mapPartitions filter 一对一的关系,窄依赖
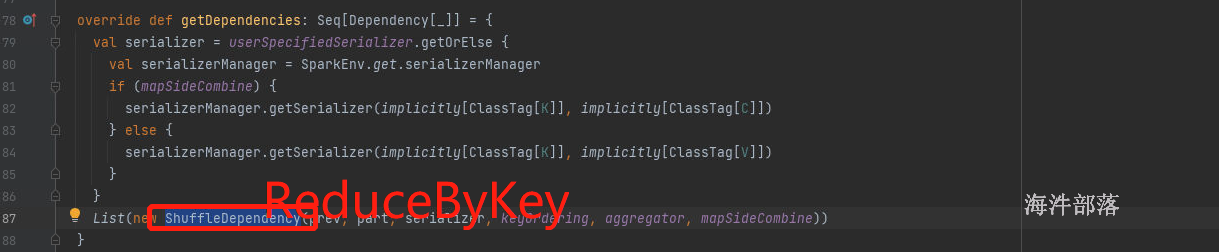
groupBy sortBy groupByKey sortByKey reduceBykey 他们都是带有shuffle的算子,都会产生宽依赖
shuffle就是宽依赖,非shuffle的算子就是窄依赖

shuffleDependency:宽依赖
narrowDependency:窄依赖

窄依赖分为三种:
oneToOne 一个对一个的关系 map FlatMap filter...
rangeDependency: union范围依赖
pruneDependency: filterByRange 子类关系,父节点的部分数据被子节点继承了,排序完毕的结果被子节点继承一部分
宽依赖的关系
窄依赖的关系
map算子中的依赖关系

union算子
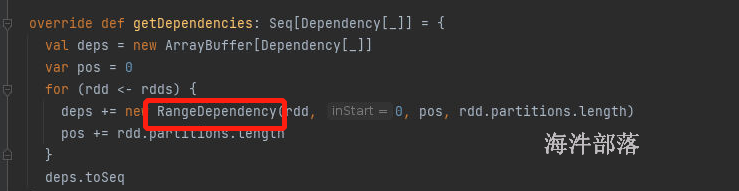
filterByRange

4.在kv类型的rdd上面存在可选的分区器
首先rdd上面是不存在分区器的,只有调用了shuffle类算子才会有分区器,默认的分区器HashPartition[分组]
rangePartitioner[排序] 同样我们可以人为自定义分区器,但是不管是人为的还是系统自带的都需要在Key进行处理
不是kv类型的rdd肯定没有分区器,kv类型的rdd上面不一定存在分区器,分区器可以规定数据的流向,上游的数据到下游的相应的分区中是可以定义规则的
5.优先位置进行计算
一般数据的切片大小和block块的大小是一一对应的,可以实现本地化执行操作,避免了远程io
读取hdfs的文件切片计算逻辑中就可以找到
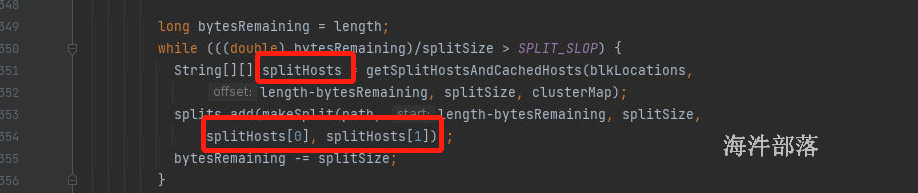
每次形成切片的时候都带有block的域名信息,处理和计算的时候就可以直接找到地址,按照本地化进行执行
11 spark 内存管理
Spark 作为一个以擅长内存计算为优势的计算引擎,内存管理方案是其非常重要的模块; Spark的内存可以大体归为两类:execution(运行内存)和storage(存储内存),前者包括shuffles、joins、sorts和aggregations所需内存,后者包括cache和节点间数据传输所需内存;
在Spark 1.5和之前版本里,运行内存和存储内存是静态配置的,不支持借用;Spark 1.6之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域,提供更好的性能。
11.1 静态内存管理——spark1.5
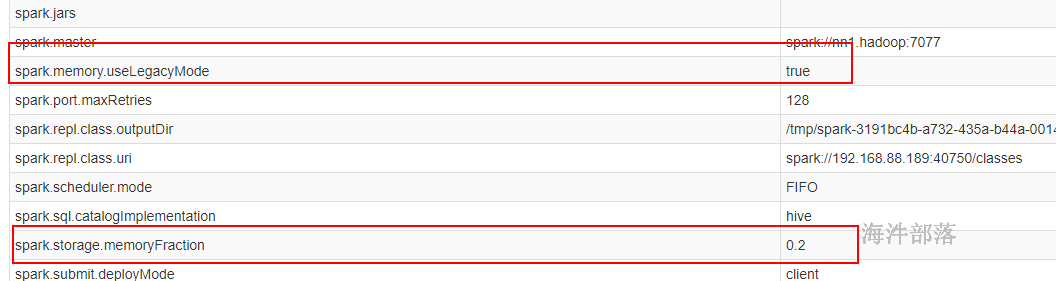
spark1.6 及以后兼容了 spark1.5 的内存管理。当配置 spark.memory.useLegacyMode=true 时,采用spark1.5的内存管理;当spark.memory.useLegacyMode=false时,采用spark1.6 及以后的内存管理。
spark1.5 的内存管理实现类: StaticMemoryManager
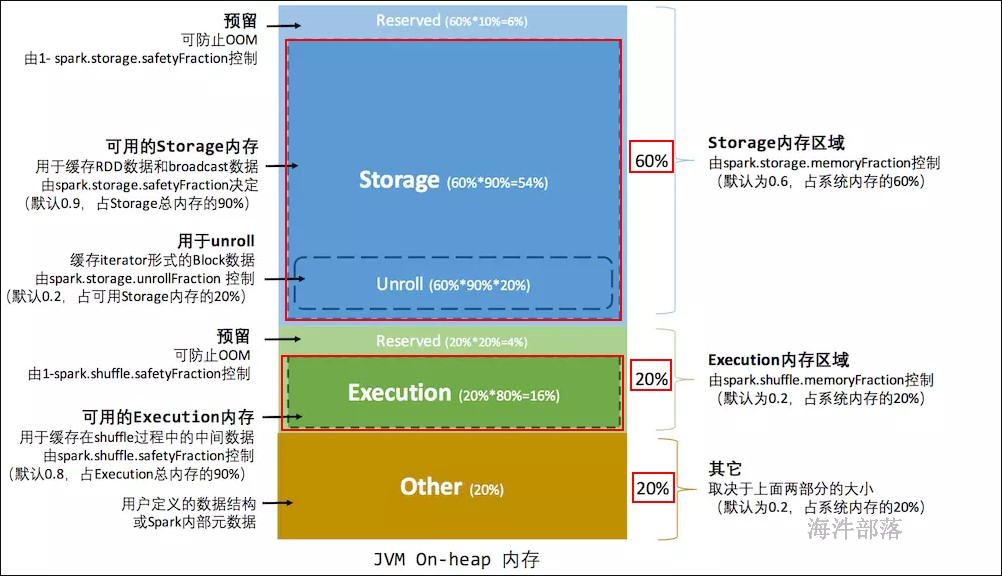
spark.storage.memoryFraction:
spark 存储总内存占 系统内存的百分比,默认是 0.6。
spark.shuffle.memoryFraction:
spark shuffle 执行用到的内存 占系统内存的百分比,默认是0.2。
spark.storage.safetyFraction:
可用的存储内存占总存储内存的百分比,默认是 0.9。
spark.shuffle.safetyFraction:
可用的shuffle操作执行内存占总执行内存的百分比, 默认是 0.8。
private def getMaxExecutionMemory(conf: SparkConf): Long = {
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
// 如果拿到的最大内存 < 32M
if (systemMaxMemory < MIN_MEMORY_BYTES) {
throw new IllegalArgumentException(s"System memory $systemMaxMemory must " +
s"be at least $MIN_MEMORY_BYTES. Please increase heap size using the --driver-memory " +
s"option or spark.driver.memory in Spark configuration.")
}
if (conf.contains("spark.executor.memory")) {
val executorMemory = conf.getSizeAsBytes("spark.executor.memory")
if (executorMemory < MIN_MEMORY_BYTES) {
throw new IllegalArgumentException(s"Executor memory $executorMemory must be at least " +
s"$MIN_MEMORY_BYTES. Please increase executor memory using the " +
s"--executor-memory option or spark.executor.memory in Spark configuration.")
}
}
val memoryFraction = conf.getDouble("spark.shuffle.memoryFraction", 0.2)
val safetyFraction = conf.getDouble("spark.shuffle.safetyFraction", 0.8)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}
private def getMaxStorageMemory(conf: SparkConf): Long = {
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6)
val safetyFraction = conf.getDouble("spark.storage.safetyFraction", 0.9)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}举例:executor 的最大可用内存1000M
存储总内存 = 1000M * 0.6 = 600M
运行总内存 = 1000M * 0.2 = 200M
other = 1000M - 600M - 200M = 200M
存储总内存 = 安全存储内存 + 预留内存(防止OOM)
安全存储内存 = 存储总内存 * 0.9 = 600 * 0.9 = 540M
预留内存 = 存储总内存 * (1-0.9) = 60M
运行总内存 = 安全运行内存 + 预留内存(防止OOM)
安全运行内存 = 运行总内存 * 0.8 = 200M * 0.8 = 160M
预留内存 = 运行总内存 * (1-0.8) = 40M
缺点:
这种内存管理方式的缺陷,即 execution 和 storage 内存分配,即使在一方内存不够用而另一方内存空闲的情况下也不能共享,造成内存浪费。
11.2 统一内存管理——spark1.6以后
当spark.memory.useLegacyMode=false时,采用spark1.6 及以后的内存管理。
spark1.6及以后 的内存管理实现类: UnifiedMemoryManager
当前spark版本是 spark3.1.2 ,参数配置部分与spark1.6 不同,下面讲解按照spark3.1.2 版本进行参数讲解。
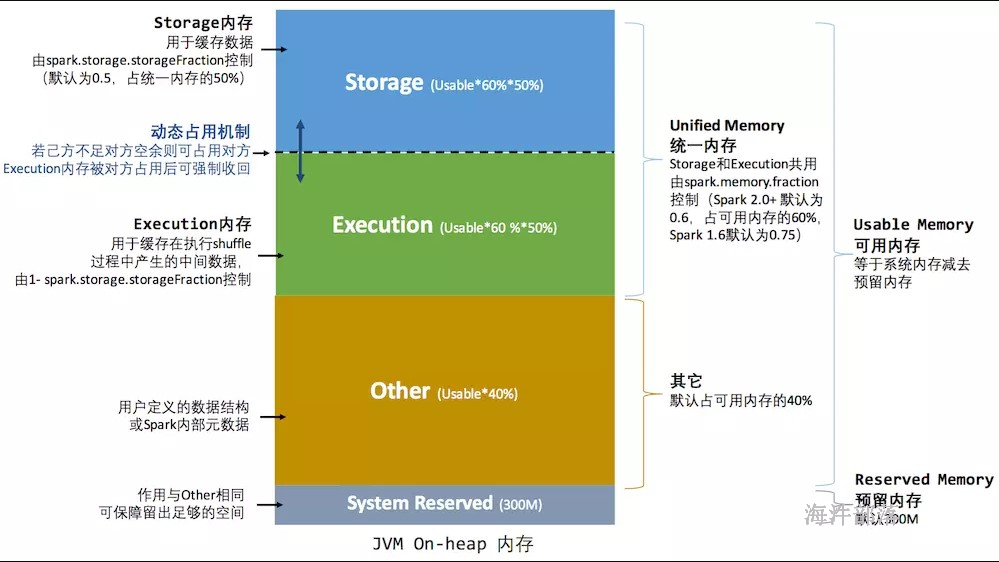
spark.memory.fraction:
spark内存占可用内存(系统内存 - 300)的百分比,默认是0.6。
spark.memory.storageFraction:
spark的存储内存占spark内存的百分比,默认是0.5。
spark的统一内存管理,可以通过配置 spark.memory.storageFraction ,来调整 存储内存和执行内存的比例,进而实现内存共享。
private def getMaxMemory(conf: SparkConf): Long = {
val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val reservedMemory = conf.getLong("spark.testing.reservedMemory",
// 300M
if (conf.contains("spark.testing")) 0 else RESERVED_SYSTEM_MEMORY_BYTES)
// 最小内存大小:450M
val minSystemMemory = (reservedMemory * 1.5).ceil.toLong
if (systemMemory < minSystemMemory) {
throw new IllegalArgumentException(s"System memory $systemMemory must " +
s"be at least $minSystemMemory. Please increase heap size using the --driver-memory " +
s"option or spark.driver.memory in Spark configuration.")
}
// SPARK-12759 Check executor memory to fail fast if memory is insufficient
if (conf.contains("spark.executor.memory")) {
val executorMemory = conf.getSizeAsBytes("spark.executor.memory")
if (executorMemory < minSystemMemory) {
throw new IllegalArgumentException(s"Executor memory $executorMemory must be at least " +
s"$minSystemMemory. Please increase executor memory using the " +
s"--executor-memory option or spark.executor.memory in Spark configuration.")
}
}
val usableMemory = systemMemory - reservedMemory
val memoryFraction = conf.getDouble("spark.memory.fraction", 0.6)
(usableMemory * memoryFraction).toLong
}
def apply(conf: SparkConf, numCores: Int): UnifiedMemoryManager = {
// 获取最大可用内存
val maxMemory = getMaxMemory(conf)
new UnifiedMemoryManager(
conf,
maxHeapMemory = maxMemory,
// 存储内存 = 获取最大可用内存 * 0.5
onHeapStorageRegionSize =
(maxMemory * conf.getDouble("spark.memory.storageFraction", 0.5)).toLong,
numCores = numCores)
}举例:系统内存1000M
系统预留内存 = 300M
可用内存 = 系统内存 - 系统预留内存 = 1000 - 300 = 700M
spark内存 = 可用内存 * 0.6 = 700 * 0.6 = 420M
存储内存 和 执行内存 均占一半, 210M
为了提高内存利用率,spark针对Storage Memory 和 Execution Memory有如下策略:
1)一方空闲,一方内存不足情况下,内存不足一方可以向空闲一方借用内存;
2)只有Execution Memory可以强制拿回Storage Memory在Execution Memory空闲时,借用的Execution Memory的部分内存(如果因强制取回,而Storage Memory数据丢失,重新计算即可);
3)Storage Memory只能等待Execution Memory主动释放占用的Storage Memory空闲时的内存。(这里不强制取回,因为如果task执行,数据丢失就会导致task 失败);
用spark1.5的方式提交,
spark-shell –master spark://nn1.hadoop:7077 –executor-memory 1G –total-executor-cores 5 –conf spark.memory.useLegacyMode=true

spark-shell –master spark://nn1.hadoop:7077 –executor-memory 1G –total-executor-cores 5
存储内存是可用内存的一半。可用内存分配比:60%
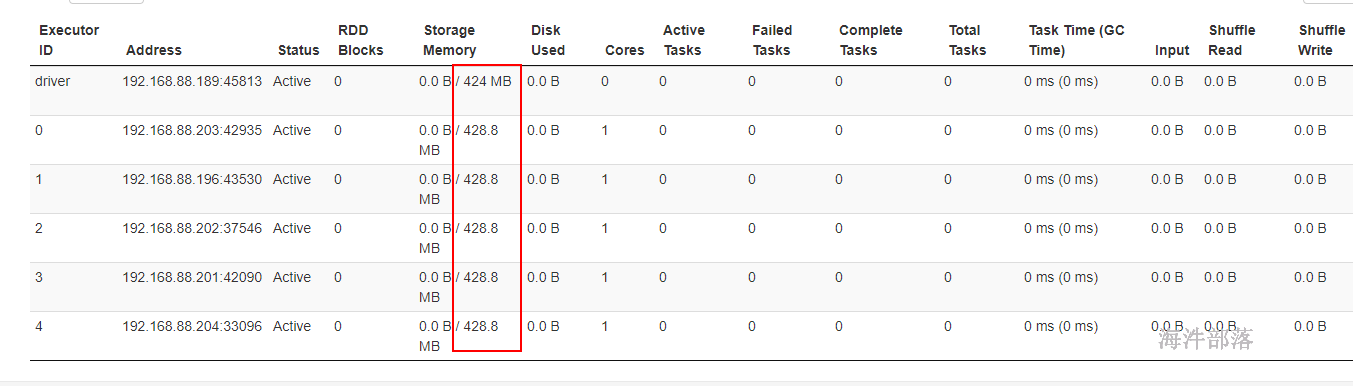
存储内存是可用内存的一半。可用内存分配比:20%
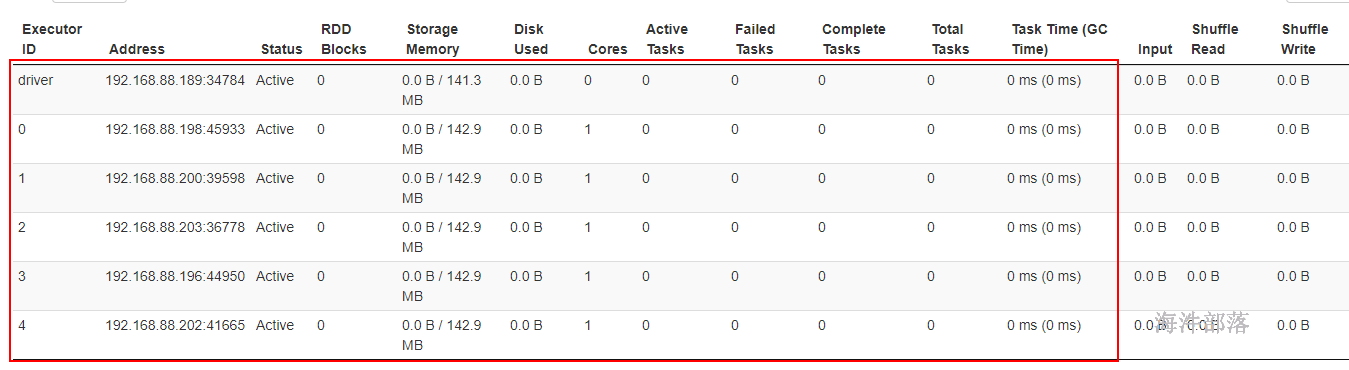
jvm的内存查看参数
--conf "spark.executor.extraJavaOptions=-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC"
# 整体提交代码如下
spark-shell --master spark://nn1:7077,nn2:7077 --executor-cores 3 --executor-memory 2G --conf "spark.executor.extraJavaOptions=-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC"
伊甸园区和逃生者区以及老年代的大小相加正好是给定的2G


