1 排序

order by
会对输入做全局排序,因此只有一个reducer。
设置reduce个数没用
order by 在hive.mapred.mode = strict 模式下 必须指定 limit 否则执行会报错。
sort by
不是全局排序,其在数据进入reducer前完成排序。 因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1, 则sort by只保证每个reducer的输出有序,不保证全局有序。
distribute by
(类似于分桶),就是把相同的key分到一个reducer中,根据distribute by指定的字段对数据进行划分到不同的输出reduce 文件中。
CLUSTER BY
cluster by column = distribute by column + sort by column (注意,都是针对column列,且采用默认ASC,不能指定排序规则为asc 或者desc)
示例
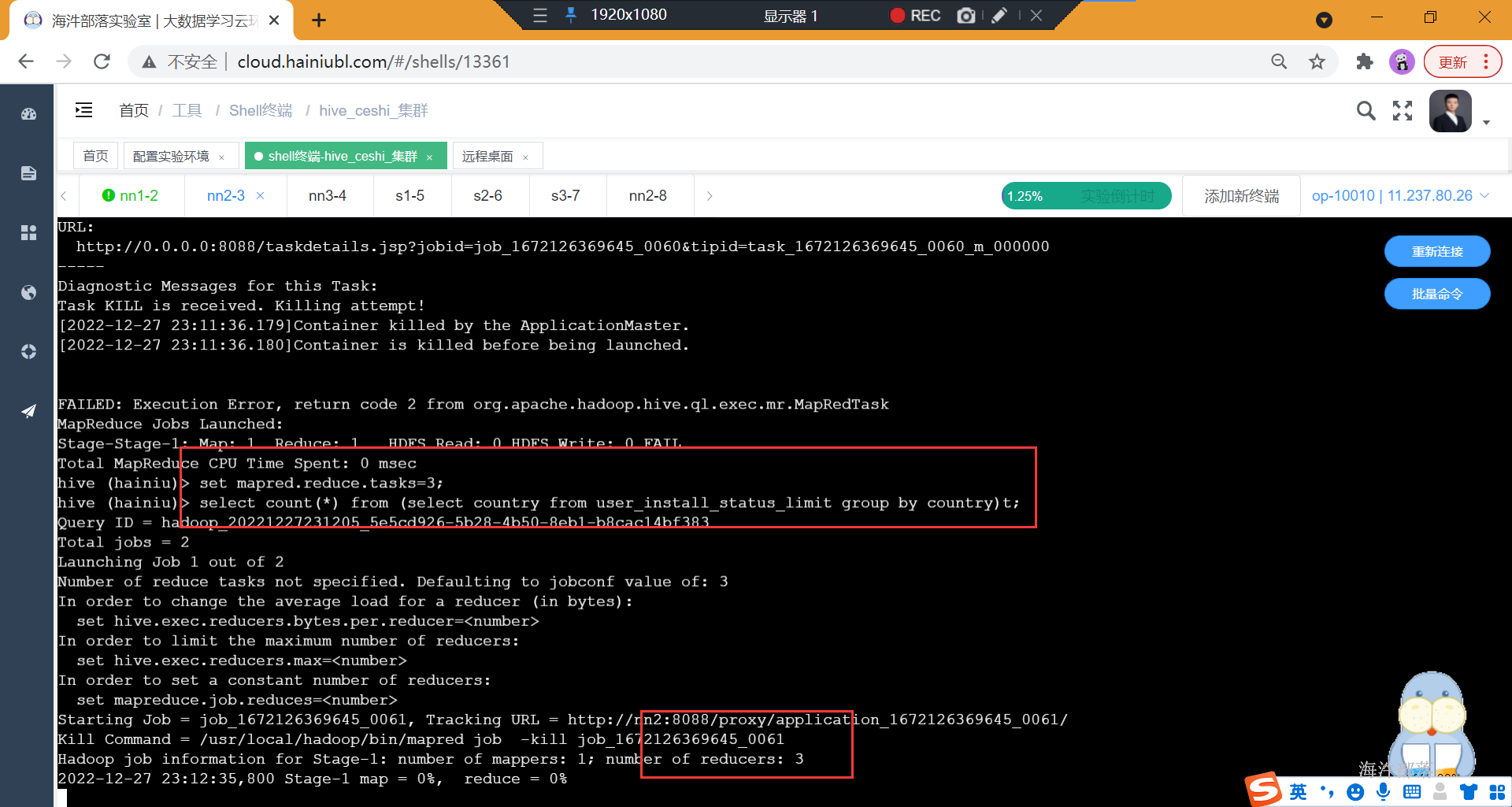
1)order by只能有一个reducer,设置了reducer也不起作用
-- 设置reduce个数为2
set mapred.reduce.tasks=2;
insert overwrite local directory '/home/hadoop/export_order'
select * from user_install_status_limit order by uptime limit 10;设置的reduce数量不起作用
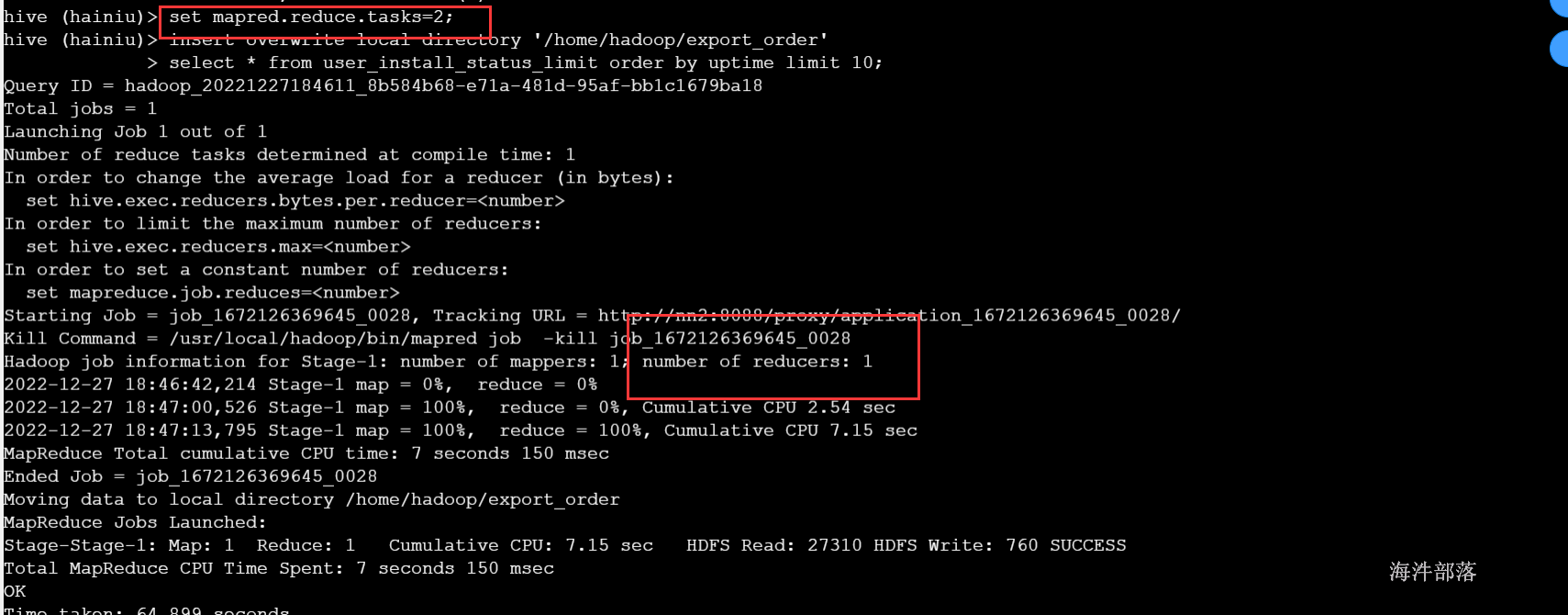
2)sort by只能保证单个文件内有序,如果设置成一个reducer那作用和order是一样的
set mapred.reduce.tasks=2;
insert overwrite local directory '/home/hadoop/export_sort'
select * from user_install_status_limit sort by uptime ;
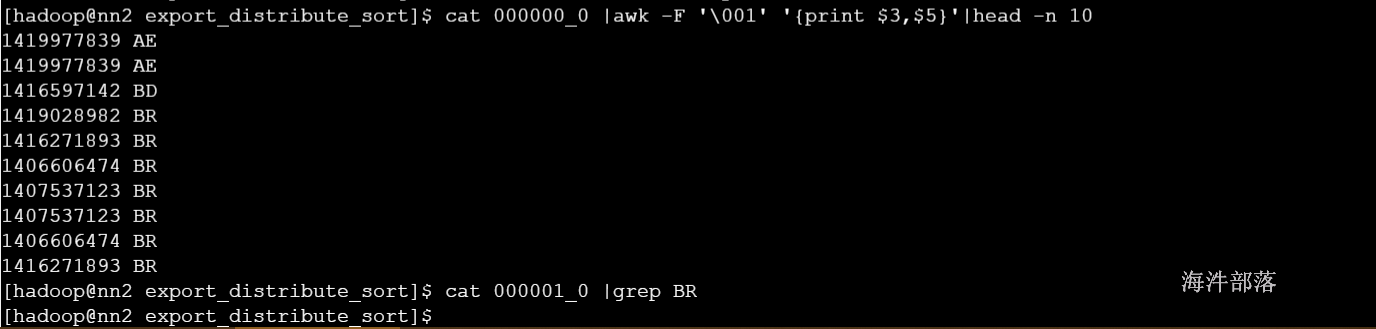
3)distribute by sort by = cluster by
distribute by可以让相同的字段去往同一个文件,sort by可以让每一个文件中的数据按照指定的字段进行排序,并且可以指定升序或者降序
cluster by 等价于distribute by sort by 但是只能升序
set mapred.reduce.tasks=2;
insert overwrite local directory '/home/hadoop/export_distribute_sort'
select * from user_install_status_limit distribute by country sort by country;
--等于
set mapred.reduce.tasks=2;
insert overwrite local directory '/home/hadoop/export_cluster'
select * from user_install_status_limit cluster by country;
想实现降序,需要用 distribute by country sort by country组合
set mapred.reduce.tasks=2;
insert overwrite local directory '/home/hadoop/export_distribute_sort_desc'
select * from user_install_status_limit distribute by country sort by country desc;
2 窗口函数
聚合函数(如sum()、avg()、max()等等)是针对定义的行集(组)执行聚集,每组只返回一个值。
窗口函数也是针对定义的行集(组)执行聚集,可为每组返回多个值。如既要显示聚集前的数据,又要显示聚集后的数据。
select sex, count(*) from student group by sex;窗口查询有两个步骤:将记录分割成多个分区,然后在各个分区上调用窗口函数。
语法:主要是over( PARTITION BY (根据某条件分组,形成一个小组)….ORDER BY(再组内进行排序) …. )
2.1 over
语法:
over (order by col1) --按照 col1 排序
over (partition by col1) --按照 col1 分区
over (partition by col1 order by col2) -- 按照 col1 分区,按照 col2 排序
--带有窗口范围
over (partition by col1 order by col2 ROWS 窗口范围) -- 在窗口范围内,按照 col1 分区,按照 col2 排序--建表
CREATE TABLE wt1(
id int,
name string,
age int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
--wt1 表数据
id name age
1 a1 10
2 a2 10
3 a3 10
4 a4 20
5 a5 20
6 a6 20
7 a7 20
8 a8 30
load data local inpath '/home/hadoop/wt1' overwrite into table wt1;
-- 窗口范围是整个表
-- 按照age排序,每阶段的age数据进行统计求和
select
id,
name,
age,
count(*) over (order by age) as n
from wt1;
1 a1 10 3
2 a2 10 3
3 a3 10 3
4 a4 20 7
5 a5 20 7
6 a6 20 7
7 a7 20 7
8 a8 30 8
------------------------------------
-- 窗口范围是表下按照age进行分区
-- 在分区里面,再按照age进行排序
select
id,
name,
age,
count(*) over (partition by age order by age) as n
from wt1;
1 a1 10 3
2 a2 10 3
3 a3 10 3
4 a4 20 4
5 a5 20 4
6 a6 20 4
7 a7 20 4
8 a8 30 1
----------------------------------
-- 窗口范围是表下按照age进行分区
-- 在分区里面,再按照id进行降序排序
select
id,
name,
age,
count() over (partition by age order by id desc) as n
from wt1;
3 a1 10 1
2 a2 10 2
1 a3 10 3
7 a4 20 1
6 a5 20 2
5 a6 20 3
4 a7 20 4
8 a8 30 1
--------------------------------------2.2 序列函数
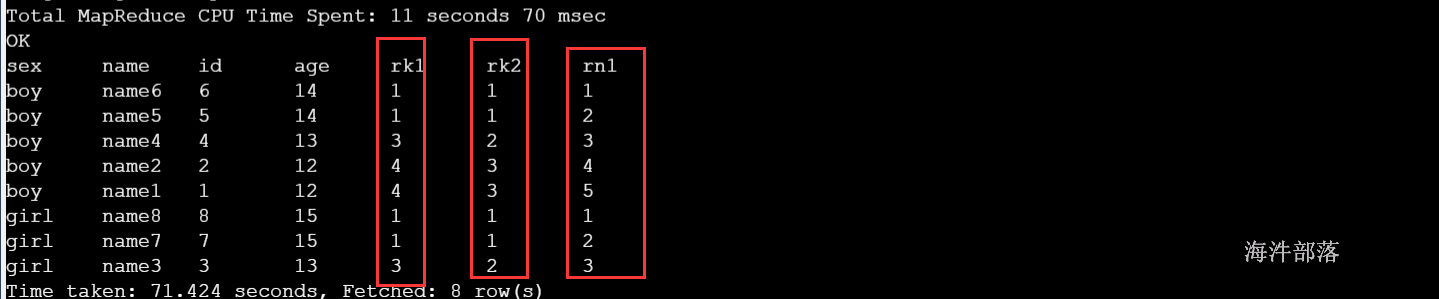
row_number:会对所有数值,输出不同的序号,序号唯一且连续,如:1、2、3、4、5。
rank:会对相同数值,输出相同的序号,而且下一个序号间断,如:1、1、3、3、5。
dense_rank:会对相同数值,输出相同的序号,但下一个序号不间断,如:1、1、2、2、3。
2.1.1 三个函数的结果比对
-- 按照性别分组,再按照年龄降序排序
set hive.cli.print.header=true;
select sex,name,id,age,
rank() over(partition by sex order by age desc) as rk1,
dense_rank() over(partition by sex order by age desc) as rk2,
row_number() over(partition by sex order by age desc) as rn1
from student_grouping;查询结果
2.2.2 ROW_NUMBER()
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)。
示例
-- rn_id 按照性别分组,按照id 降序排序
select sex,name,id,
row_number() over(partition by sex order by id desc) as rn_id
from student_grouping;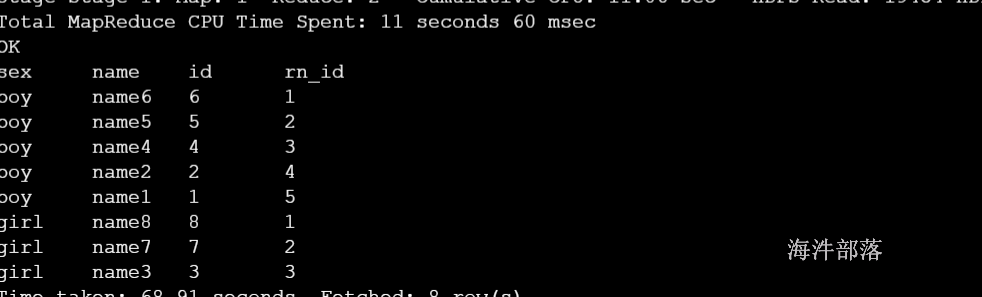
在上面的数据集结果里,能查询出来每个性别的最大id用户数据
select t1.sex,t1.name,t1.id from
(
select sex,name,id,
row_number() over(partition by sex order by id desc) as rn_id
from student_grouping
) t1 where t1.rn_id=1;
应用场景:求按照班级分组,统计最大的或最小的成绩对应的学生信息;
求按照班级分组,统计成绩前几名的学生信息;(分组后 top N)
求按照用户分组,统计每个用户最新的访问记录;
over中partition by和distribute by区别
1)partition by [key..] order by [key..]只能在窗口函数中使用,而distribute by [key...] sort by [key...]在窗口函数和select中都可以使用。
2)窗口函数中两者是没有区别的
示例
-- 不在窗口函数中使用,报错
select * from student_grouping partition by sex order by age;
-- 不在窗口函数中使用,不报错
select * from student_grouping distribute by sex sort by age;
-- distribute 可以在窗口函数中使用
select
id,name,age,sex,
row_number() over (distribute by sex sort by id desc) as rn_id
from student_grouping;2.3 Window 函数
ROWS窗口函数中的行选择器
rows between
[n|unbounded preceding]|[n|unbounded following]|[current row]
an d
[n|unbounded preceding]|[n|unbounded following]|[current row]
参数解释:
n行数
unbounded不限行数
preceding在前N行
following在后N行
current row当前行组合出的结果:
-- 前无限行到当前行
rows between unbounded preceding and current row
-- 前2 行到当前行
rows between 2 preceding and current row
-- 当前行到后2行
rows between current row and 2 following
-- 前无限行到后无限行
rows between unbounded preceding and unbounded following应用场景:
1)查询当月销售额和近三个月的销售额
2)查询当月销售额和今年年初到当月的销售额
示例:
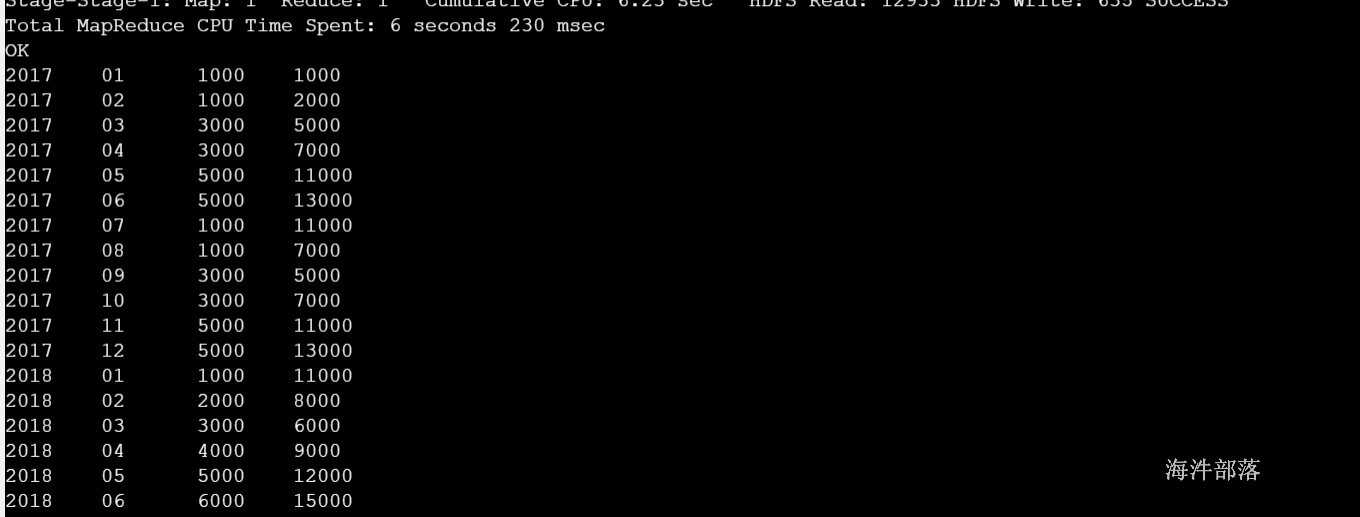
年份 月份 销售额
2017 01 1000
2017 02 1000
2017 03 3000
2017 04 3000
2017 05 5000
2017 06 5000
2017 07 1000
2017 08 1000
2017 09 3000
2017 10 3000
2017 11 5000
2017 12 5000
2018 01 1000
2018 02 2000
2018 03 3000
2018 04 4000
2018 05 5000
2018 06 6000建表导入数据
CREATE TABLE sale_table(
y string,
m string,
sales int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';查询
-- 查询当月销售额和近三个月的销售额
select
y,
m,
sales,
sum(sales) over(order by y,m rows between 2 preceding and current row) as last3sales
from sale_table;结果:
-- 查询当月销售额和年初到当月的销售额
select
y,
m,
sales,
sum(sales) over(partition by y order by y,m rows between unbounded preceding and current row) as sales2
from sale_table;
3 UDF函数
UDF的全称为user-defined function,用户定义函数,为什么有它的存在呢?有的时候 你要写的查询无法轻松地使用Hive提供的内置函数来表示,通过写UDF,Hive就可以方便地插入用户写的处理代码并在查询中使用它们,相当于在HQL(Hive SQL)中自定义一些函数。
UDF、UDAF、UDTF区别
UDF (user defined function) 用户自定义函数:对单行记录进行处理得到单行的结果
UDAF (user defined aggregation function) 用户自定义聚合函数,多行记录汇总成一行,常用于聚合函数;
UDTF:单行记录转换成多行记录;
3.1 UDF
3.1.1创建使用函数流程
1)自定义一个Java类
2)继承类 GenericUDF
3)重写继承的方法
4)在hive执行创建模板函数
5)hql中使用
3.1.2 实现需求,能将国家编码转成中文国家名的UDF函数
1)首先上传code对应名称的数据
#将数据传到远程桌面上
scp country.dict root@11.94.204.94:/headless/Desktop放到resource目录下
导包
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.35</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-cli</artifactId>
<version>3.1.3</version>
</dependency>2)创建自定义UDF类并继承hive的GenericUDF 类
首先把数据读到缓存里,然后选择性实现 5个 方法。
//可选,该方法中可以通过context.getJobConf()获取job执行时候的Configuration;
//可以通过Configuration传递参数值
public void configure(MapredContext context) {}
//必选,该方法用于函数初始化操作,并定义函数的返回值类型,判断传入参数的类型;
public ObjectInspector initialize(ObjectInspector[] arguments)
//必选,函数处理的核心方法,用途和UDF中的evaluate一样,每一行都调用一次;
public Object evaluate(DeferredObject[] args){}
//必选,显示函数的帮助信息
public String getDisplayString(String[] children)
//可选,map完成后,执行关闭操作
public void close(){}具体代码
package com.hainiu.function;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.lazy.LazyString;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.Text;
/**
* 实现国家码转国家名称的UDF函数
* code2name(CN) --> 中国
*/
public class CountryCode2CountryNameUDF extends GenericUDF{
static Map<String,String> countryMap = new HashMap<String,String>();
static{
// 将 字典文件数据写入内存
try(
InputStream is = CountryCode2CountryNameUDF.class.getResourceAsStream("/country_dict.txt");
BufferedReader reader = new BufferedReader(new InputStreamReader(is, "utf-8"));
){
String line = null;
while((line = reader.readLine()) != null){
String[] arr = line.split("\t");
String code = arr[0];
String name = arr[1];
countryMap.put(code, name);
}
System.out.println("countryMap.size: " + countryMap.size());
}catch(Exception e){
e.printStackTrace();
}
}
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
System.out.println("initialize");
// 校验函数输入参数和 设置函数返回值类型
// 1) 校验入参个数
if(arguments.length != 1){
throw new UDFArgumentException("input params must one");
}
ObjectInspector inspector = arguments[0];
// 2) 校验参数的大类
// 大类有: PRIMITIVE(基本类型), LIST, MAP, STRUCT, UNION
if(! inspector.getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentException("input params Category must PRIMITIVE");
}
// 3) 校验参数的小类
// VOID, BOOLEAN, BYTE, SHORT, INT, LONG, FLOAT, DOUBLE, STRING,
// DATE, TIMESTAMP, BINARY, DECIMAL, VARCHAR, CHAR, INTERVAL_YEAR_MONTH, INTERVAL_DAY_TIME,
// UNKNOWN
if(! inspector.getTypeName().equalsIgnoreCase(PrimitiveObjectInspector.PrimitiveCategory.STRING.name())){
throw new UDFArgumentException("input params PRIMITIVE Category type must STRING");
}
// 4) 设置函数返回值类型
// writableStringObjectInspector 里面有 Text, Text 里面有String类型
return PrimitiveObjectInspectorFactory.writableStringObjectInspector;
}
/**
* 定义函数输出对象
*/
Text output = new Text();
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
System.out.println("evaluate");
// 核心算法, 一行调用一次
// 获取入参数据
Object obj = arguments[0].get();
String code = null;
if(obj instanceof LazyString){
LazyString lz = (LazyString)obj;
Text t = lz.getWritableObject();
code = t.toString();
}else if(obj instanceof Text){
Text t = (Text)obj;
code = t.toString();
}else{
code = (String)obj;
}
// 翻译国家码
String countryName = countryMap.get(code);
countryName = countryName == null ? "某个小国" : countryName;
output.set(countryName);
return output;
}
@Override
public String getDisplayString(String[] children) {
// 报错说明
return Arrays.toString(children);
}
}3.1.3 集群运行自定义udf函数
1)首先给项目打成jar包;
2)进入hive控制台,然后使用add jar把刚才打的jar包添加进去;
#格式
add jar [local_jar_path];
#实例
add jar /home/hadoop/udf.jar;
#如果上传的jar包运行时报错,当你修改完再次上传时,要重启hive客户端,再重新添加jar,运行。
#创建自定义函数
CREATE TEMPORARY FUNCTION codetoname AS 'com.hainiu.udf.CodeToCountryNameUDF';
-- 查询验证
select country, codetoname(country) name from user_install_status_limit limit 10;3.2 UDTF
UDTF(User-Defined Table-Generating Functions) :接受零个或者多个输入,然后产生多列或者多行输出。
需求:
id name_nickname
1 name1#n1;name2#n2
2 name3#n3;name4#n4;name5#n5 将以上文件数据多行多列输出
id name nickname
1 name1 n1
1 name2 n2
2 name3 n3
2 name4 n4
2 name5 n53.2.1 UDTF编写流程
1)继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,实现initialize, process, close三个方法。
2)UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。
3)初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每调用一次forward()产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。
4)最后close()方法调用,对需要清理的方法进行清理。
代码实现:
package com.hainiu.function;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.lazy.LazyString;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.Text;
/**
* 实现 udtf函数
* split_udtf("name_nikename") --> 多行多列
*/
public class SplitUDTF extends GenericUDTF{
@Override
public StructObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
// 校验函数输入参数和 设置函数返回值类型
// 1) 校验入参个数
if(arguments.length != 1){
throw new UDFArgumentException("input params must one");
}
ObjectInspector inspector = arguments[0];
// 2) 校验参数的大类
// 大类有: PRIMITIVE(基本类型), LIST, MAP, STRUCT, UNION
if(! inspector.getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentException("input params Category must PRIMITIVE");
}
// 3) 校验参数的小类
// VOID, BOOLEAN, BYTE, SHORT, INT, LONG, FLOAT, DOUBLE, STRING,
// DATE, TIMESTAMP, BINARY, DECIMAL, VARCHAR, CHAR, INTERVAL_YEAR_MONTH, INTERVAL_DAY_TIME,
// UNKNOWN
if(! inspector.getTypeName().equalsIgnoreCase(PrimitiveObjectInspector.PrimitiveCategory.STRING.name())){
throw new UDFArgumentException("input params PRIMITIVE Category type must STRING");
}
// 4) 设置函数返回值类型(struct<name:string, nickname:string>)
// struct内部字段的名称
List<String> names = new ArrayList<String>();
names.add("name");
names.add("nickname");
// struct内部字段的名称对应的类型
List<ObjectInspector> inspectors = new ArrayList<ObjectInspector>();
inspectors.add(PrimitiveObjectInspectorFactory.writableStringObjectInspector);
inspectors.add(PrimitiveObjectInspectorFactory.writableStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(names, inspectors);
}
/**
* 函数输出类型
* 第一个参数:name
* 第二个参数:nickname
*/
Object[] outputs = new Object[]{new Text(), new Text()};
@Override
public void process(Object[] args) throws HiveException {
// 核心方法 一行调用一次
System.out.println("process()");
Object obj = args[0];
String data = null;
if(obj instanceof LazyString){
LazyString lz = (LazyString)obj;
Text t = lz.getWritableObject();
data = t.toString();
}else if(obj instanceof Text){
Text t = (Text)obj;
data = t.toString();
}else{
data = (String)obj;
}
// name1#n1;name2#n2
String[] arr1 = data.split(";");
// name1#n1
for(String data2 : arr1){
String[] arr2 = data2.split("#");
String name = arr2[0];
String nickname = arr2[1];
// 想输出就调用forward()
((Text)outputs[0]).set(name);
((Text)outputs[1]).set(nickname);
System.out.println("forward()");
forward(outputs);
}
}
@Override
public void close() throws HiveException {
}
}
3.2.2 提供测试数据测试
1)根据数据创建表
create table udtf_table (
id int,
name_nickname string
)
row format delimited fields terminated by '\t';3)把数据拷贝到表中
4)创建函数
CREATE TEMPORARY FUNCTION udtf_split AS 'com.hainiu.udf.SplitUDTF'; 5)执行函数测试
-- 带有表头字段
set hive.cli.print.header=true;
select udtf_split(name_nickname) from udtf_table;
select udtf_split(name_nickname) as (name1,nickname1) from udtf_table;自带的:

起别名的:

3.2.3 UDTF的两种使用方法
UDTF有两种使用方法:一种直接放到select后面,一种和lateral view一起使用;
3.2.4 直接select中使用
语法格式:
-- 可以自定义表头字段名称
select udtf_func(properties) as (col1,col2) from tablename;
-- 用UDTF代码里写的字段名称
select udtf_func(properties) from tablename;注意:
UDTF函数不可以使用的场景
1)不可以添加其他字段使用;
select values, udtf_split(valuse) as (col1,col2) from udtftest;错误例子
select id, udtf_split(name_nickname) from udtf_table;2)不可以嵌套调用;
select udtf_split(udtf_split(strsplit)) from udtftest;3)不可以和group by/cluster by/distribute by/sort by一起使用;
select udtf_split(strsplit) as (col1,col2) from udtftest group by col1, col2;3.2.5 和lateral view一起使用
通过Lateral view可以方便的将UDTF得到的行转列的结果集,合在一起提供服务;
lateral view用于和UDTF一起使用,为了解决UDTF不允许在select字段的问题;
-- 首先table_name表每行调用udtf_func,会把一行拆分成一或者多行
-- 再把结果组合,产生一个支持别名表tableAlias的虚拟表
select table_name.id, tableAlias.col1, tableAlias.col2
from table_name
lateral view udtf_func(properties) tableAlias as col1,col2;示例:
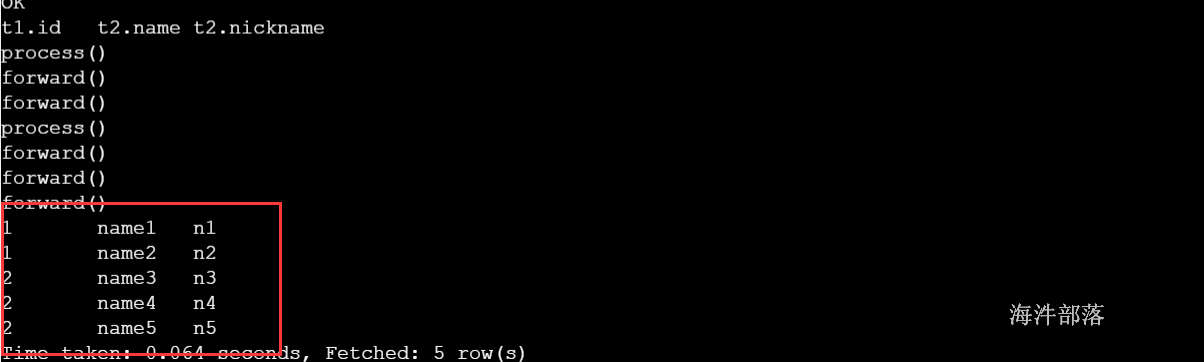
1)利用lateral view 查看表的数据
select t1.id, t2.name, t2.nickname
from udtf_table t1
lateral view udtf_split(name_nickname) t2 as name,nickname;查询结果:
2)在示例1的基础上,分组查询统计每个id有多少条记录
select t3.id, count(*) as n from
(select t1.id, t2.name, t2.nickname
from udtf_table t1
lateral view udtf_split(name_nickname) t2 as name,nickname) t3 group by t3.id;
3.3 UDAF
UDAF类似于聚合函数,可以将多条输入的内容进行汇总,最后输出一条数据
需求:统计flow_table中的总金额:
flow_table -- 流水表
文件1:
日期dt 金额amt
0528 100
0529 150
0530 50
0531 200
0601 100
文件2:
日期 金额
0520 100
0521 100
0522 200
select sum(amt) from flow_table;3.3.1 开发UDAF步骤
一般情况下,完整的UDAF逻辑是一个mapreduce过程:
如果有mapper和reducer,就会经历PARTIAL1(mapper),FINAL(reducer);
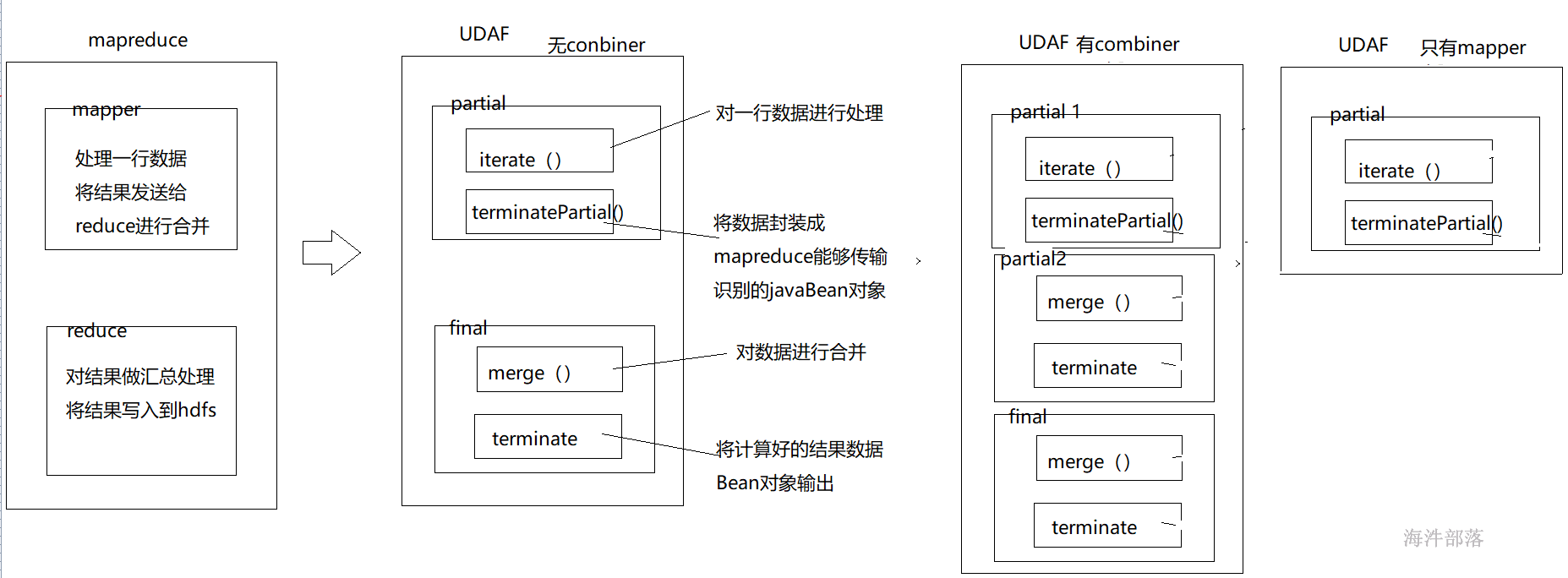
/**
* PARTIAL1: 这个是mapreduce的map阶段:从原始数据到部分数据聚合
* 将会调用iterate()和terminatePartial()
*/
iterate():把mapper中每行的数据汇总到一起,放到一个bean里面,这个bean在mapper和reducer的内部。
amt bean对象
0528 100 100
0529 150 250
0530 50 300
0531 200 500
0601 100 600 ---》 bean(600)
0520 100 100
0521 100 200
0522 200 400 ---》 bean(400)
terminatePartial() : 把带有中间结果的bean转换成能实现序列化在mapper 和 reducer 端传输的对象。
bean(600) --> IntWritable(600)
bean(400) --> IntWritable(400)
/**
* FINAL: mapreduce的reduce阶段:从部分数据的聚合到完全聚合
* 将会调用merge()和terminate()
*/
FINAL,
merge(): reduce端把mapper端输出的数据进行全局合并,把合并的结果放到bean里
bean
IntWritable(600) bean(600)
IntWritable(400) bean(1000) ---> bean(1000)
terminate() :把bean里的全局聚合结果,转换成能实现序列化的输出对象
bean(1000) ---》 IntWritable(1000)流程
1)自定义UDAF类,需要继承AbstractGenericUDAFResolver;
2)自定义Evaluator类,需要继承GenericUDAFEvaluator,真正实现UDAF的逻辑;
3)自定义bean类,需要继承 AbstractAggregationBuffer,用于在mapper或reducer内部传递数据;
具体代码:
/**
* SumUDAF.java
* com.hainiu.hive.func
* Copyright (c) 2021, 海牛学院版权所有.
*/
package com.hainiu.hive.func;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator.Mode;
import org.apache.hadoop.hive.serde2.lazy.LazyInteger;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.io.IntWritable;
/**
* 自定义udaf函数实现sum
*/
public class SumUDAF extends AbstractGenericUDAFResolver{
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] infos) throws SemanticException {
// 校验输入参数
// 1) 校验入参参数个数
if(infos.length != 1){
throw new UDFArgumentException("input param num must one");
}
// 2) 校验入参大类: PRIMITIVE, LIST, MAP, STRUCT, UNION
// 字符串属于 PRIMITIVE 大类
TypeInfo info = infos[0];
if(! info.getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentException("input param Category must PRIMITIVE");
}
// public static enum PrimitiveCategory
// {
// VOID, BOOLEAN, BYTE, SHORT, INT, LONG, FLOAT, DOUBLE, STRING,
// DATE, TIMESTAMP, BINARY, DECIMAL, VARCHAR, CHAR, INTERVAL_YEAR_MONTH, INTERVAL_DAY_TIME,
// UNKNOWN;
// }
// 3)校验入参小类 是Int
if(! info.getTypeName().equalsIgnoreCase(PrimitiveObjectInspector.PrimitiveCategory.INT.name())){
throw new UDFArgumentException("input param PRIMITIVE Category type must Int");
}
// 返回能实现sum的核心算法类对象实例
return new SumEvaluator();
}
/**
* 实现sum的核心算法类
*/
public static class SumEvaluator extends GenericUDAFEvaluator{
/**
* 用于存储中间结果
*/
public static class SumAgg extends AbstractAggregationBuffer{
/**
* 统计的中间结果
*/
private int sum;
public int getSum() {
return sum;
}
public void setSum(int sum) {
this.sum = sum;
}
}
/**
* 由于sum函数mapper端和reduce端输出都是IntWritable,所以定义一个输出对象即可
*/
IntWritable outputs = new IntWritable();
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
// 创建中间结果对象
System.out.println("do getNewAggregationBuffer()");
return new SumAgg();
}
@Override
public void reset(AggregationBuffer paramAggregationBuffer) throws HiveException {
// 重置中间结果对象数据
System.out.println("do reset()");
SumAgg sumAgg = (SumAgg)paramAggregationBuffer;
sumAgg.setSum(0);
}
@Override
public void iterate(AggregationBuffer paramAggregationBuffer, Object[] paramArrayOfObject)
throws HiveException {
// iterate():接收每一行,汇总出局部的结果,放在中间结果bean对象里
// 一行调用一次
System.out.println("do iterate()");
Object obj = paramArrayOfObject[0];
int amt = 0;
if(obj instanceof LazyInteger){
LazyInteger lz = (LazyInteger)obj;
IntWritable w = lz.getWritableObject();
amt = w.get();
}else if(obj instanceof IntWritable){
IntWritable w = (IntWritable)obj;
amt = w.get();
}else{
amt = (int)obj;
}
SumAgg sumAgg = (SumAgg)paramAggregationBuffer;
// 之前sum结果 + 当前的金额 ==》 当前sum结果
sumAgg.setSum(sumAgg.getSum() + amt);
}
@Override
public Object terminatePartial(AggregationBuffer paramAggregationBuffer) throws HiveException {
// terminatePartial():把每个map的局部聚合结果(bean对象里的), 转成能序列化的格式(IntWritable)输出
//
// bean(600) ---> IntWritable(600)
// bean(400) ---> IntWritable(400)
System.out.println("do terminatePartial()");
SumAgg sumAgg = (SumAgg)paramAggregationBuffer;
outputs.set(sumAgg.getSum());
return outputs;
}
@Override
public void merge(AggregationBuffer paramAggregationBuffer, Object obj) throws HiveException {
// merge(): 把多个map的输出结果进行聚合,并把结果放在(bean对象里)
// bean
// IntWritable(600) 600
// IntWritable(400) 1000 --> 1000
System.out.println("do merge()");
int amt = 0;
if(obj instanceof LazyInteger){
LazyInteger lz = (LazyInteger)obj;
IntWritable w = lz.getWritableObject();
amt = w.get();
}else if(obj instanceof IntWritable){
IntWritable w = (IntWritable)obj;
amt = w.get();
}else{
amt = (int)obj;
}
SumAgg sumAgg = (SumAgg)paramAggregationBuffer;
// 之前sum结果 + 当前的金额 ==》 当前sum结果
sumAgg.setSum(sumAgg.getSum() + amt);
}
@Override
public Object terminate(AggregationBuffer paramAggregationBuffer) throws HiveException {
// terminate():把reduce最终聚合结果(bean对象里的), 转成能序列化的格式(IntWritable)输出
// bean(1000) ---> IntWritable(1000)
System.out.println("do terminate()");
SumAgg sumAgg = (SumAgg)paramAggregationBuffer;
outputs.set(sumAgg.getSum());
return outputs;
}
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
// 根据mapper端,reduce端输出的不同设置不同类型
// 又因为 mapper端,reduce端输出都是int,所以都一样,就不分阶段了
System.out.println("do init()");
super.init(m, parameters);
// 内部封装的是IntWritable
return PrimitiveObjectInspectorFactory.writableIntObjectInspector;
}
}
}
建表测试
-- 建表
CREATE TABLE flow_table(
dt string,
amt int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 表数据:
文件1:
0528 100
0529 150
0530 50
0531 200
0601 100
文件2:
0520 100
0521 100
0522 200
创建临时函数并使用
--hive默认会将输入小文件合并,如果不想合并的话可以执行下面参数
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
CREATE TEMPORARY FUNCTION suma AS 'com.hainiu.udf.SumUDAF';
select suma(amt) from flow_table;结果:

4 hive优化
hive性能优化时,把HiveQL当做M/R程序来读,即从M/R的运行角度来考虑优化性能,从更底层思考如何优化运算性能,而不仅仅局限于逻辑代码的替换层面。
4.1 列裁剪
Hive 在读数据的时候,可以只读取查询中所需要用到的列,而忽略其它列。
4.2 分区裁剪
可以在查询的过程中减少不必要的分区,不用扫描全表。
4.3 合理设置reduce的数量
reduce个数的设定极大影响任务执行效率,在设置reduce个数的时候需要考虑这两个原则:使大数据量利用合适的reduce数;使每个reduce任务处理合适的数据量。
在不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下,两个设定:
参数1:hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,在Hive 0.14.0及更高版本中默认为256M)
参数2:hive.exec.reducers.max(每个任务最大的reduce数,在Hive 0.14.0及更高版本中默认为1009)
计算reducer数的公式: N = min( 参数2,总输入数据量 / 参数1 )
默认情况,执行6个reduce
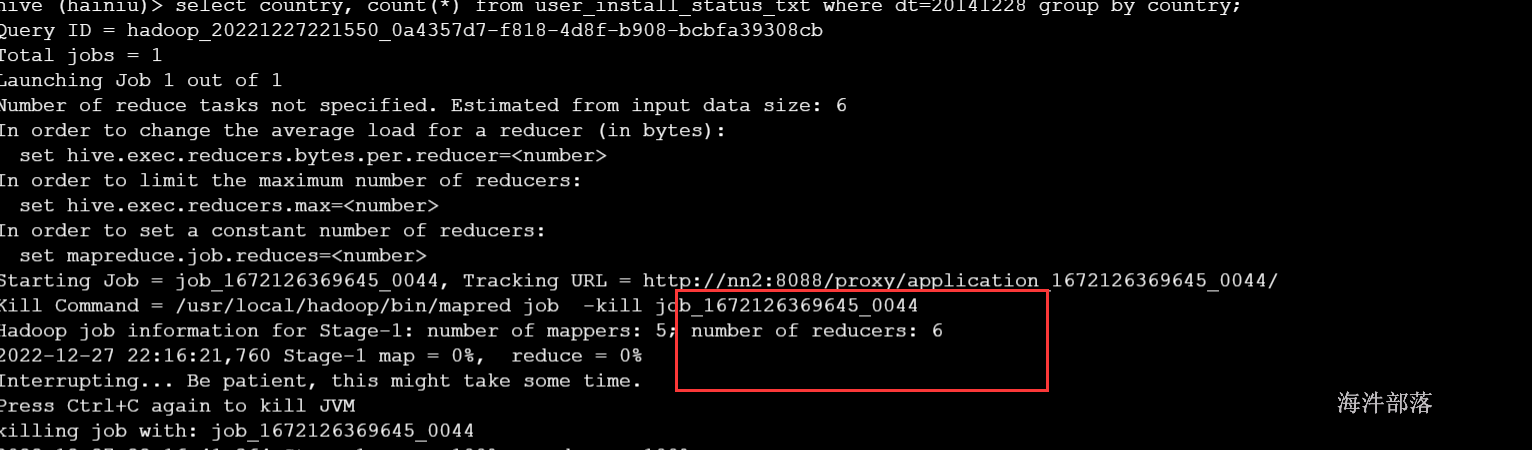
-- 设置每个reduce处理的数据量为500M,查看reduce个数;
set hive.exec.reducers.bytes.per.reducer=500000000;
select country, count(*) from user_install_status_other where dt=20141228 group by country;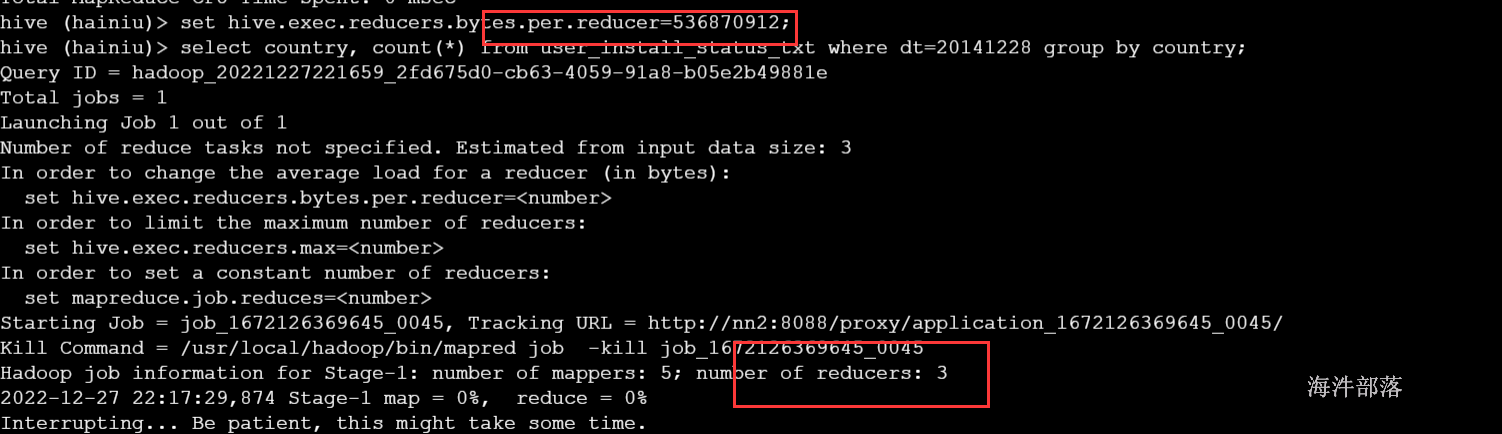
也可以通过直接通过参数来设置reduce个数。
mapred.reduce.tasks (默认是-1,代表hive自动根据输入数据设置reduce个数)
reduce个数并不是越多越好,启动和初始化reduce会消耗时间和资源;另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题。
4.4 job并行运行设置
带有子查询的hql,如果子查询间没有依赖关系,可以开启任务并行,设置任务并行最大线程数。
hive.exec.parallel (默认是false, true:开启并行运行)
hive.exec.parallel.thread.number (最多可以并行执行多少个作业, 默认是 8)
测试并行运算:
关闭并行运行,发现没有依赖的子查询不会同步执行
-- 关闭并行运行, 默认是false
set hive.exec.parallel=false;
select a.country,a.cn,round(a.cn/b.cn*100,6) from
(select country,count(1) cn,'nn' as joinc from user_install_status_other where dt='20141228' group by country) a
inner join
(select count(1) cn,'nn' as joinc from user_install_status_other where dt='20141228') b on a.joinc=b.joinc;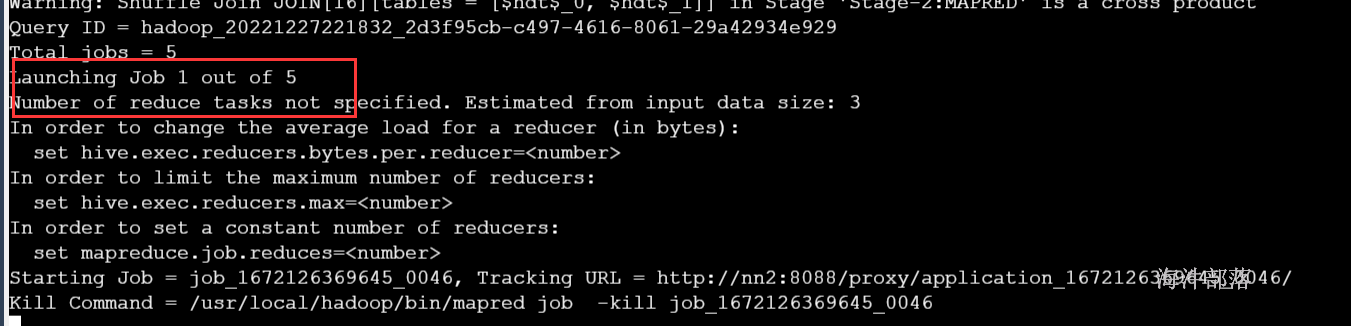
开启并行运行,发现没有依赖的子查询会同步执行
-- 开启并行运行
set hive.exec.parallel=true;
select a.country,a.cn,round(a.cn/b.cn*100,6) from
(select country,count(1) cn,'nn' as joinc from user_install_status_other where dt='20141228' group by country) a
inner join
(select count(1) cn,'nn' as joinc from user_install_status_other where dt='20141228') b on a.joinc=b.joinc;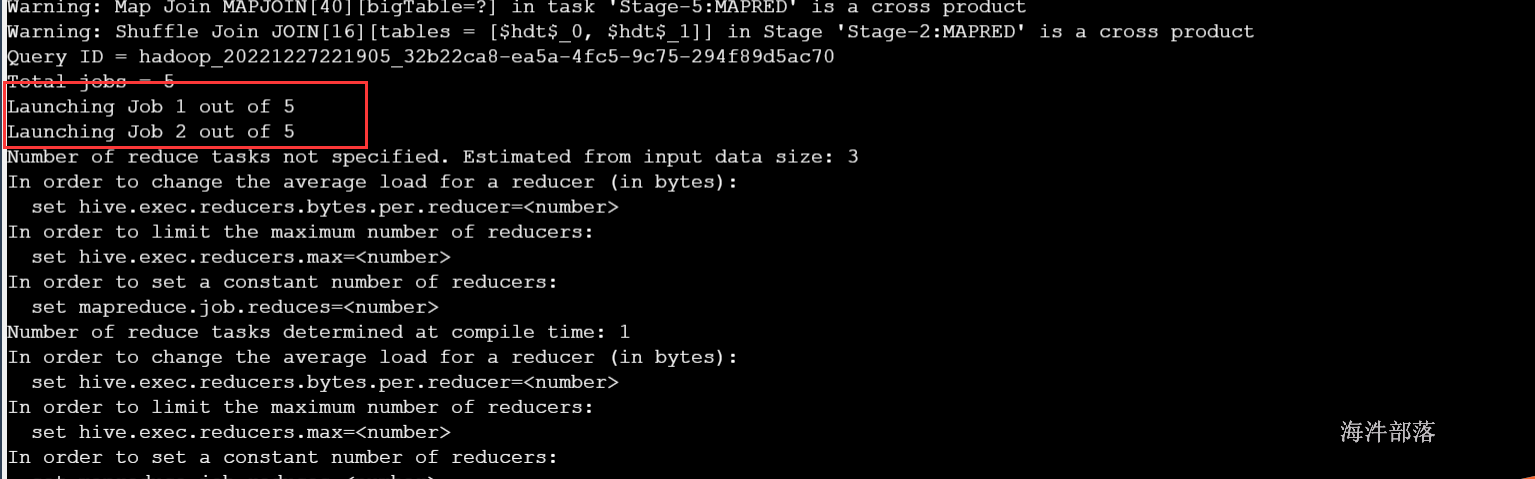
4.5 小文件的问题优化
如果小文件多,在map输入时,一个小文件产生一个map任务,这样会产生多个map任务;启动和初始化多个map会消耗时间和资源,所以hive默认是将小文件合并成大文件。
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; (默认)
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;(关闭小文件合并大文件)
如果map输出的小文件过多,hive 默认是开启map 输出合并。
set hive.merge.mapfiles=true (默认是 false)
set hive.merge.mapredfiles=true (默认是 false)
hive.merge.size.per.task(合并文件的大小,默认 256M)
hive.merge.smallfiles.avgsize(文件的平均大小小于该值时,会启动一个MR任务执行merge,默认16M )
4.6 join 操作优化
多表join,如果join字段一样,只生成一个job 任务;
Join 的字段类型要一致。
--只产生一个job任务
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
select * from test_a a
inner join test_b b on a.id=b.id
inner join test_c c on a.id=c.id;
--产生多个job任务
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
select * from test_a a
inner join test_b b on a.id=b.id
inner join test_c c on a.name=c.name;MAP JOIN操作
如果你有一张表非常非常小,而另一张关联的表非常非常大的时候,你可以使用mapjoin此Join 操作在 Map 阶段完成,不再需要Reduce,hive默认开启mapjoin。
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
select * from user_install_status_other u join country_dict c on u.country=c.code limit 10
-- 将小表刷入内存中,默认是true
set hive.auto.convert.join=true;
set hive.ignore.mapjoin.hint=true;
-- 刷入内存表的大小(字节),根据自己的数据集加大
set hive.mapjoin.smalltable.filesize=2500000;
select * from user_install_status_other u join country_dict c on u.country=c.code limit 104.7 SMBJoin
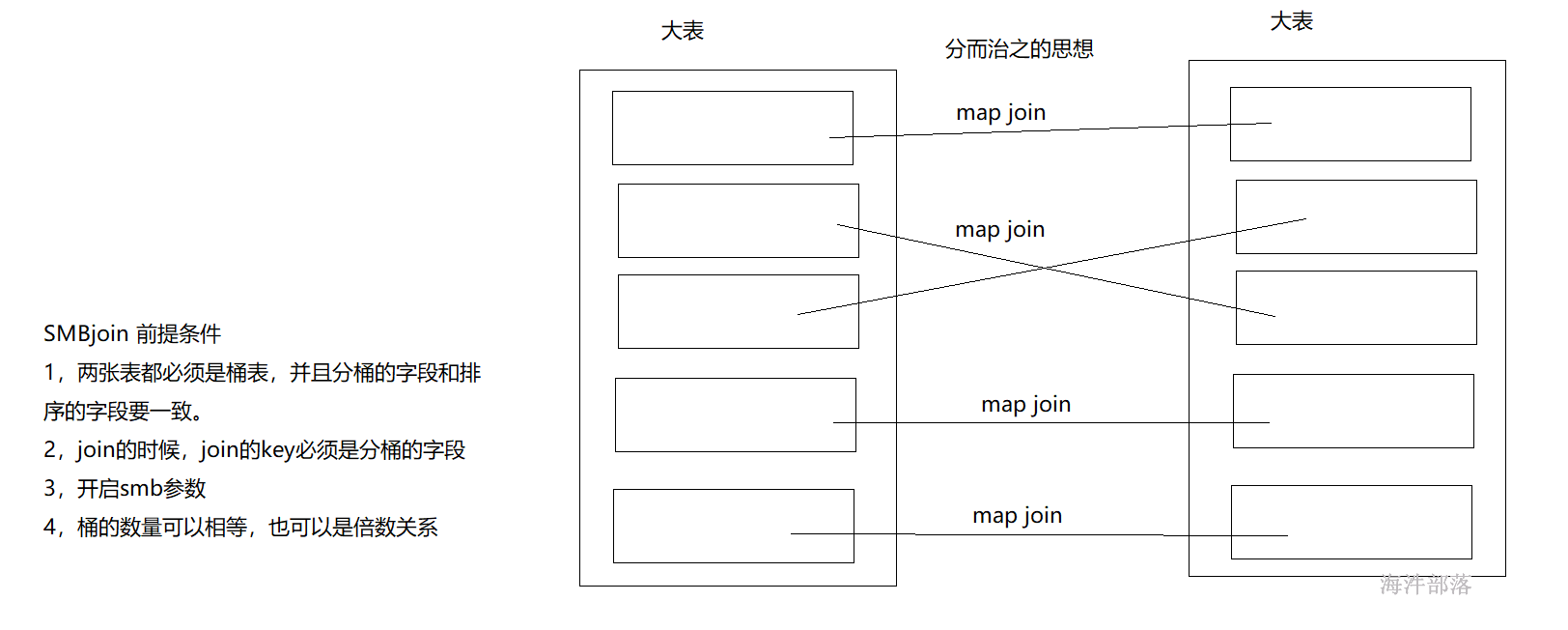
SMB Join是 sort merge bucket操作,首先进行排序,继而合并,然后放到所对应的bucket中去,bucket是hive中和分区表类似的技术,就是按照key进行hash,相同的hash值都放到相同的bucket中去。在进行两个表联合的时候。我们首先进行分桶,在join会大幅度的对性能进行优化。
桶可以保证相同key 的数据都分在了一个桶里,这个时候我们关联的时候不需要去扫描整个表的数据,只需要扫描对应桶里的数据(因为key 相同的一定在一个桶里),smb的设计是为了解决大表和大表之间的join的,核心思想就是大表化成小表,然后map join 解决是典型的分而治之的思想。
4.7.1 SMB join 成立的前提条件
1)两张表是桶表,且分桶字段和桶内排序字段要一致,在创建表的时候需要指定:
CREATE TABLE(……) CLUSTERED BY (col_1) SORTED BY (col_1) INTO buckets_Nums BUCKETS
2)两张表分桶的字段必须是JOIN 的 KEY
3)设置bucket 的相关参数,默认是 false,true 代表开启 smb join。
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
4)两个join的桶表内桶数量可以相等,也可以是倍数关系。
4.7.2 两个桶表数量相等的join
1)创建桶表(按照country 分桶, 桶内文件按照 country 排序)
CREATE TABLE user_buckets(
`aid` string,
`pkgname` string,
`uptime` bigint,
`type` int,
`country` string,
`gpcategory` string)
COMMENT 'This is the buckets_table table'
CLUSTERED BY(country) SORTED BY(country) INTO 20 BUCKETS;2)导入数据
insert overwrite table user_buckets
select
aid,
pkgname,
uptime,
type,
country,
gpcategory
from user_install_status_other
where dt='20141228';3)设置桶相关的参数,并进行执行计划对比
-- 设置都为true,查看执行计划发现没有Reducer Operator Tree, 采用SMB join
hive (hainiu)> set hive.auto.convert.sortmerge.join=true;
hive (hainiu)> set hive.optimize.bucketmapjoin.sortedmerge = true;
hive (hainiu)> explain select t2.* from user_buckets t1
> inner join user_buckets t2 on t1.country=t2.country;
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 9208046 Data size: 612991442 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: country is not null (type: boolean)
Statistics: Num rows: 9208046 Data size: 612991442 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: country (type: string)
outputColumnNames: _col0
Statistics: Num rows: 9208046 Data size: 612991442 Basic stats: COMPLETE Column stats: NONE
-- 只有mapper没有reducer,采用的join是 Sorted Merge Bucket
Sorted Merge Bucket Map Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: string)
1 _col4 (type: string)
outputColumnNames: _col1, _col2, _col3, _col4, _col5, _col6
Select Operator
expressions: _col1 (type: string), _col2 (type: string), _col3 (type: bigint), _col4 (type: int), _col5 (type: string), _col6 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
File Output Operator
compressed: false
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.146 seconds, Fetched: 41 row(s)
--------------------------------------
-- 设置都为false,查看执行计划发现有Reducer Operator Tree,采用的是Common join
hive (hainiu)> set hive.auto.convert.sortmerge.join=false;
hive (hainiu)> set hive.optimize.bucketmapjoin.sortedmerge = false;
hive (hainiu)> explain select t2.* from user_buckets t1
> inner join user_buckets t2 on t1.country=t2.country;
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: t1
Statistics: Num rows: 9208046 Data size: 612991442 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: country is not null (type: boolean)
Statistics: Num rows: 9208046 Data size: 612991442 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: country (type: string)
outputColumnNames: _col0
Statistics: Num rows: 9208046 Data size: 612991442 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: string)
sort order: +
Map-reduce partition columns: _col0 (type: string)
Statistics: Num rows: 9208046 Data size: 612991442 Basic stats: COMPLETE Column stats: NONE
TableScan
alias: t1
Statistics: Num rows: 9208046 Data size: 612991442 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: country is not null (type: boolean)
Statistics: Num rows: 9208046 Data size: 612991442 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: aid (type: string), pkgname (type: string), uptime (type: bigint), type (type: int), country (type: string), gpcategory (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 9208046 Data size: 612991442 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col4 (type: string)
sort order: +
Map-reduce partition columns: _col4 (type: string)
Statistics: Num rows: 9208046 Data size: 612991442 Basic stats: COMPLETE Column stats: NONE
value expressions: _col0 (type: string), _col1 (type: string), _col2 (type: bigint), _col3 (type: int), _col5 (type: string)
-- 带有reducer
Reduce Operator Tree:
Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: string)
1 _col4 (type: string)
outputColumnNames: _col1, _col2, _col3, _col4, _col5, _col6
Statistics: Num rows: 10128850 Data size: 674290600 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col1 (type: string), _col2 (type: string), _col3 (type: bigint), _col4 (type: int), _col5 (type: string), _col6 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5
Statistics: Num rows: 10128850 Data size: 674290600 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 10128850 Data size: 674290600 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.095 seconds, Fetched: 66 row(s)4.7.3 执行SQL看对比情况
1)开启SMBJoin的运行
hive (hainiu)> set hive.auto.convert.sortmerge.join=true;
hive (hainiu)> set hive.optimize.bucketmapjoin.sortedmerge = true;
hive (hainiu)> set hive.optimize.bucketmapjoin = true;
hive (hainiu)> select count(*) from
> (
> select t2.* from country_dict_buckets t1
> inner join country_dict_buckets t2 on t1.country=t2.country
> ) t3;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = panniu_20210630231053_20dc1a24-6faa-4ac6-b7bc-5b8319603aa7
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1623410979404_5850, Tracking URL = http://nn1.hadoop:8041/proxy/application_1623410979404_5850/
Kill Command = /usr/local/hadoop/bin/hadoop job -kill job_1623410979404_5850
Hadoop job information for Stage-1: number of mappers: 40; number of reducers: 1
2021-06-30 23:11:14,545 Stage-1 map = 0%, reduce = 0%
2021-06-30 23:11:25,163 Stage-1 map = 4%, reduce = 0%, Cumulative CPU 183.3 sec
2021-06-30 23:11:26,216 Stage-1 map = 5%, reduce = 0%, Cumulative CPU 247.74 sec
2021-06-30 23:11:27,272 Stage-1 map = 7%, reduce = 0%, Cumulative CPU 338.36 sec
2021-06-30 23:11:28,323 Stage-1 map = 14%, reduce = 0%, Cumulative CPU 473.21 sec
2021-06-30 23:11:29,373 Stage-1 map = 18%, reduce = 0%, Cumulative CPU 561.52 sec
2021-06-30 23:11:30,414 Stage-1 map = 22%, reduce = 0%, Cumulative CPU 611.33 sec
2021-06-30 23:11:31,480 Stage-1 map = 25%, reduce = 0%, Cumulative CPU 670.88 sec
2021-06-30 23:11:32,528 Stage-1 map = 29%, reduce = 0%, Cumulative CPU 708.38 sec
2021-06-30 23:11:33,580 Stage-1 map = 30%, reduce = 0%, Cumulative CPU 735.09 sec
2021-06-30 23:11:34,633 Stage-1 map = 34%, reduce = 0%, Cumulative CPU 786.53 sec
2021-06-30 23:11:35,682 Stage-1 map = 37%, reduce = 0%, Cumulative CPU 823.27 sec
2021-06-30 23:11:36,735 Stage-1 map = 38%, reduce = 0%, Cumulative CPU 852.77 sec
2021-06-30 23:12:07,634 Stage-1 map = 61%, reduce = 0%, Cumulative CPU 942.41 sec
2021-06-30 23:12:08,672 Stage-1 map = 88%, reduce = 0%, Cumulative CPU 2268.99 sec
2021-06-30 23:12:17,050 Stage-1 map = 88%, reduce = 29%, Cumulative CPU 2270.15 sec
2021-06-30 23:12:27,958 Stage-1 map = 89%, reduce = 29%, Cumulative CPU 2297.12 sec
2021-06-30 23:12:37,066 Stage-1 map = 90%, reduce = 29%, Cumulative CPU 2360.78 sec
2021-06-30 23:12:40,221 Stage-1 map = 91%, reduce = 29%, Cumulative CPU 2443.65 sec
2021-06-30 23:12:43,337 Stage-1 map = 92%, reduce = 29%, Cumulative CPU 2460.19 sec
2021-06-30 23:12:46,466 Stage-1 map = 93%, reduce = 29%, Cumulative CPU 2476.57 sec
2021-06-30 23:12:48,577 Stage-1 map = 94%, reduce = 29%, Cumulative CPU 2521.11 sec
2021-06-30 23:12:54,863 Stage-1 map = 96%, reduce = 29%, Cumulative CPU 2329.68 sec
2021-06-30 23:12:58,013 Stage-1 map = 96%, reduce = 30%, Cumulative CPU 2344.81 sec
2021-06-30 23:12:59,057 Stage-1 map = 97%, reduce = 30%, Cumulative CPU 2345.71 sec
2021-06-30 23:13:00,105 Stage-1 map = 99%, reduce = 30%, Cumulative CPU 2351.01 sec
2021-06-30 23:13:13,680 Stage-1 map = 100%, reduce = 30%, Cumulative CPU 2368.0 sec
2021-06-30 23:13:23,074 Stage-1 map = 100%, reduce = 31%, Cumulative CPU 2186.1 sec
2021-06-30 23:13:26,294 Stage-1 map = 100%, reduce = 33%, Cumulative CPU 2186.17 sec
2021-06-30 23:13:27,518 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2189.62 sec
MapReduce Total cumulative CPU time: 36 minutes 29 seconds 620 msec
Ended Job = job_1623410979404_5850
MapReduce Jobs Launched:
Stage-Stage-1: Map: 40 Reduce: 1 Cumulative CPU: 2189.62 sec HDFS Read: 73474091 HDFS Write: 111 SUCCESS
Total MapReduce CPU Time Spent: 36 minutes 29 seconds 620 msec
OK
13153396573
Time taken: 168.857 seconds, Fetched: 1 row(s)2)没开启SMBJoin的运行
hive (hainiu)> set hive.auto.convert.sortmerge.join=false;
hive (hainiu)> set hive.optimize.bucketmapjoin.sortedmerge = false;
hive (hainiu)> set hive.optimize.bucketmapjoin = false;
hive (hainiu)> select count(*) from
> (
> select t2.* from country_dict_buckets t1
> inner join country_dict_buckets t2 on t1.country=t2.country
> ) t3;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = panniu_20210630231634_c7714429-e51c-4c17-9d7c-e4e123fcb5c2
Total jobs = 2
Stage-1 is selected by condition resolver.
Launching Job 1 out of 2
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1623410979404_5851, Tracking URL = http://nn1.hadoop:8041/proxy/application_1623410979404_5851/
Kill Command = /usr/local/hadoop/bin/hadoop job -kill job_1623410979404_5851
Hadoop job information for Stage-1: number of mappers: 6; number of reducers: 1
2021-06-30 23:16:41,732 Stage-1 map = 0%, reduce = 0%
2021-06-30 23:16:44,883 Stage-1 map = 17%, reduce = 0%, Cumulative CPU 12.27 sec
2021-06-30 23:16:45,946 Stage-1 map = 33%, reduce = 0%, Cumulative CPU 14.45 sec
2021-06-30 23:16:49,092 Stage-1 map = 50%, reduce = 0%, Cumulative CPU 16.33 sec
2021-06-30 23:16:50,145 Stage-1 map = 67%, reduce = 0%, Cumulative CPU 17.37 sec
2021-06-30 23:16:51,200 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 19.2 sec
2021-06-30 23:16:57,504 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 28.56 sec
2021-06-30 23:17:15,436 Stage-1 map = 100%, reduce = 68%, Cumulative CPU 49.85 sec
2021-06-30 23:17:42,729 Stage-1 map = 100%, reduce = 69%, Cumulative CPU 80.65 sec
2021-06-30 23:18:04,763 Stage-1 map = 100%, reduce = 70%, Cumulative CPU 104.0 sec
2021-06-30 23:18:31,964 Stage-1 map = 100%, reduce = 71%, Cumulative CPU 133.74 sec
2021-06-30 23:18:52,841 Stage-1 map = 100%, reduce = 72%, Cumulative CPU 157.84 sec
2021-06-30 23:19:17,937 Stage-1 map = 100%, reduce = 73%, Cumulative CPU 184.7 sec
2021-06-30 23:19:38,835 Stage-1 map = 100%, reduce = 74%, Cumulative CPU 208.15 sec
2021-06-30 23:20:02,796 Stage-1 map = 100%, reduce = 75%, Cumulative CPU 235.21 sec
2021-06-30 23:20:24,703 Stage-1 map = 100%, reduce = 76%, Cumulative CPU 258.85 sec
2021-06-30 23:20:51,844 Stage-1 map = 100%, reduce = 77%, Cumulative CPU 289.24 sec
2021-06-30 23:21:12,753 Stage-1 map = 100%, reduce = 78%, Cumulative CPU 312.97 sec
2021-06-30 23:21:36,801 Stage-1 map = 100%, reduce = 79%, Cumulative CPU 340.32 sec
2021-06-30 23:21:58,681 Stage-1 map = 100%, reduce = 80%, Cumulative CPU 364.56 sec
2021-06-30 23:22:28,814 Stage-1 map = 100%, reduce = 81%, Cumulative CPU 398.69 sec
2021-06-30 23:22:56,973 Stage-1 map = 100%, reduce = 82%, Cumulative CPU 429.31 sec
2021-06-30 23:23:24,096 Stage-1 map = 100%, reduce = 83%, Cumulative CPU 459.95 sec
2021-06-30 23:23:44,904 Stage-1 map = 100%, reduce = 84%, Cumulative CPU 483.95 sec
2021-06-30 23:24:08,933 Stage-1 map = 100%, reduce = 85%, Cumulative CPU 511.2 sec
2021-06-30 23:24:30,809 Stage-1 map = 100%, reduce = 86%, Cumulative CPU 535.3 sec
2021-06-30 23:24:54,815 Stage-1 map = 100%, reduce = 87%, Cumulative CPU 562.95 sec
2021-06-30 23:25:16,677 Stage-1 map = 100%, reduce = 88%, Cumulative CPU 586.94 sec
2021-06-30 23:25:43,808 Stage-1 map = 100%, reduce = 89%, Cumulative CPU 617.6 sec
2021-06-30 23:26:07,827 Stage-1 map = 100%, reduce = 90%, Cumulative CPU 644.62 sec
2021-06-30 23:26:34,944 Stage-1 map = 100%, reduce = 91%, Cumulative CPU 675.18 sec
2021-06-30 23:26:59,904 Stage-1 map = 100%, reduce = 92%, Cumulative CPU 702.32 sec
2021-06-30 23:27:23,912 Stage-1 map = 100%, reduce = 93%, Cumulative CPU 729.76 sec
2021-06-30 23:27:51,029 Stage-1 map = 100%, reduce = 94%, Cumulative CPU 760.19 sec
2021-06-30 23:28:19,232 Stage-1 map = 100%, reduce = 95%, Cumulative CPU 790.8 sec
2021-06-30 23:28:49,489 Stage-1 map = 100%, reduce = 96%, Cumulative CPU 824.96 sec
2021-06-30 23:29:13,442 Stage-1 map = 100%, reduce = 97%, Cumulative CPU 852.12 sec
2021-06-30 23:29:40,543 Stage-1 map = 100%, reduce = 98%, Cumulative CPU 882.45 sec
2021-06-30 23:30:07,723 Stage-1 map = 100%, reduce = 99%, Cumulative CPU 913.02 sec
2021-06-30 23:30:52,674 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 963.8 sec
MapReduce Total cumulative CPU time: 16 minutes 3 seconds 800 msec
Ended Job = job_1623410979404_5851
Launching Job 2 out of 2
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1623410979404_5857, Tracking URL = http://nn1.hadoop:8041/proxy/application_1623410979404_5857/
Kill Command = /usr/local/hadoop/bin/hadoop job -kill job_1623410979404_5857
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 1
2021-06-30 23:31:01,492 Stage-2 map = 0%, reduce = 0%
2021-06-30 23:31:02,557 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 3.35 sec
2021-06-30 23:31:03,613 Stage-2 map = 100%, reduce = 100%, Cumulative CPU 4.74 sec
MapReduce Total cumulative CPU time: 4 seconds 740 msec
Ended Job = job_1623410979404_5857
MapReduce Jobs Launched:
Stage-Stage-1: Map: 6 Reduce: 1 Cumulative CPU: 963.8 sec HDFS Read: 193649423 HDFS Write: 2250716 SUCCESS
Stage-Stage-2: Map: 1 Reduce: 1 Cumulative CPU: 4.74 sec HDFS Read: 7018 HDFS Write: 607107 SUCCESS
Total MapReduce CPU Time Spent: 16 minutes 8 seconds 540 msec
OK
13153396573
Time taken: 870.771 seconds, Fetched: 1 row(s)结论:开启MSBJoin 要比不开启快很多,大表优化可以采用。
4.8 hive的数据倾斜优化
对于mapreduce 计算框架,数据量大不是问题,数据倾斜是个问题。
4.8.1 数据倾斜的原因
1)key分布不均匀,本质上就是业务数据有可能会存在倾斜
2)某些SQL语句本身就有数据倾斜
| 关键词 | 情形 | 后果 |
|---|---|---|
| Join | 其中一个表较小,但是key集中 | 分发到某一个或几个Reduce上的数据远高于平均值 |
| group by | group by 维度过小,某值的数量过多 | 处理某值的reduce非常耗时 |
数据产生倾斜的原理:
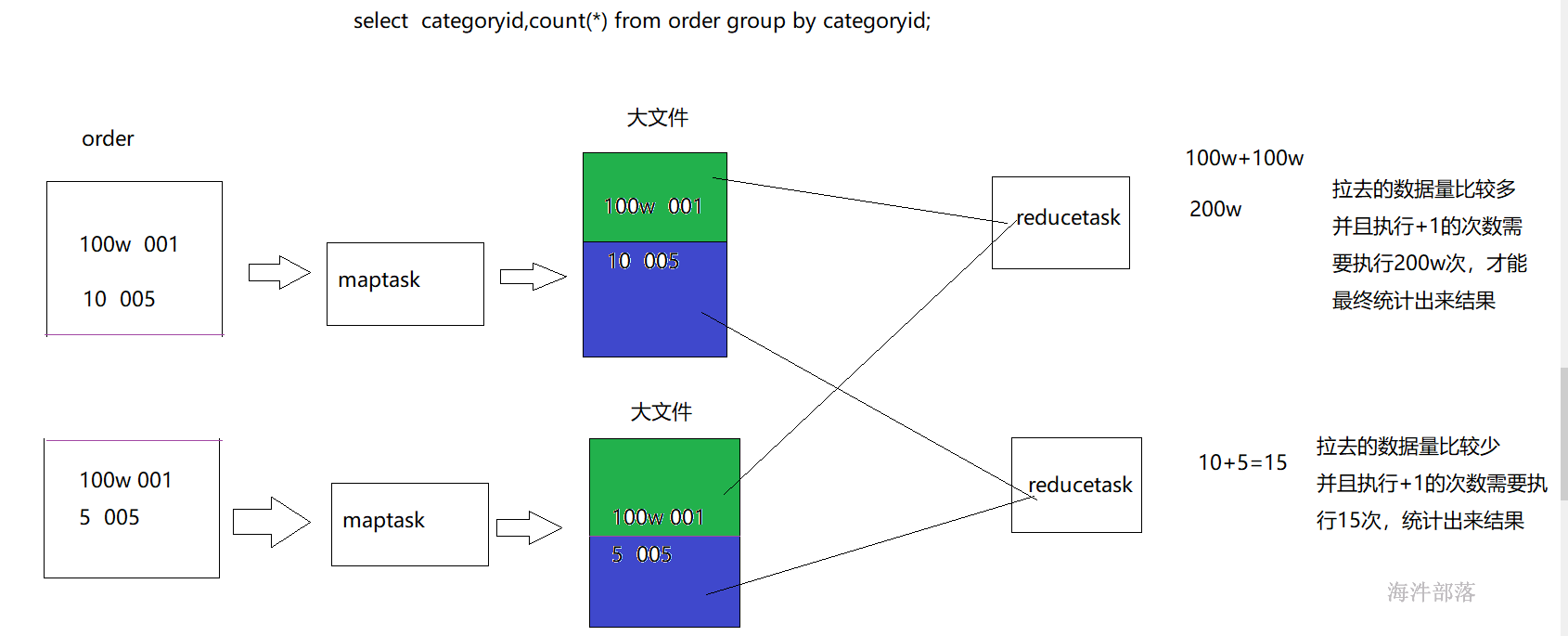
4.8.2 数据倾斜的表现
任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
4.8.3 通用解决方案——参数调节
对于group by 产生倾斜的问题
set hive.map.aggr=true; (默认是 true)
开启map端combiner,减少reduce 拉取的数据量。
set hive.groupby.skewindata=true; (默认是 false)
有数据倾斜的时候进行负载均衡,当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
如果开启负载均衡:
执行:
set mapred.reduce.tasks=3;
set hive.groupby.skewindata=true;
select sum(1) as n from
( select country from hainiu.user_install_status_other group by country) t ;会有3个MapReduce任务
第一个:select country from user_install_status group by country, 将key放到不同的reduce里
第二个:将第一个任务生成的临时文件,按照key 进行group by,此时,会将数据放到一个reduce里。
第三个:用group by 的中间结果,进行sum。
通过查看执行计划
1)设置了负载均衡
set hive.groupby.skewindata=true;
explain select sum(1) as n from
( select country from user_install_status_other group by country) t ;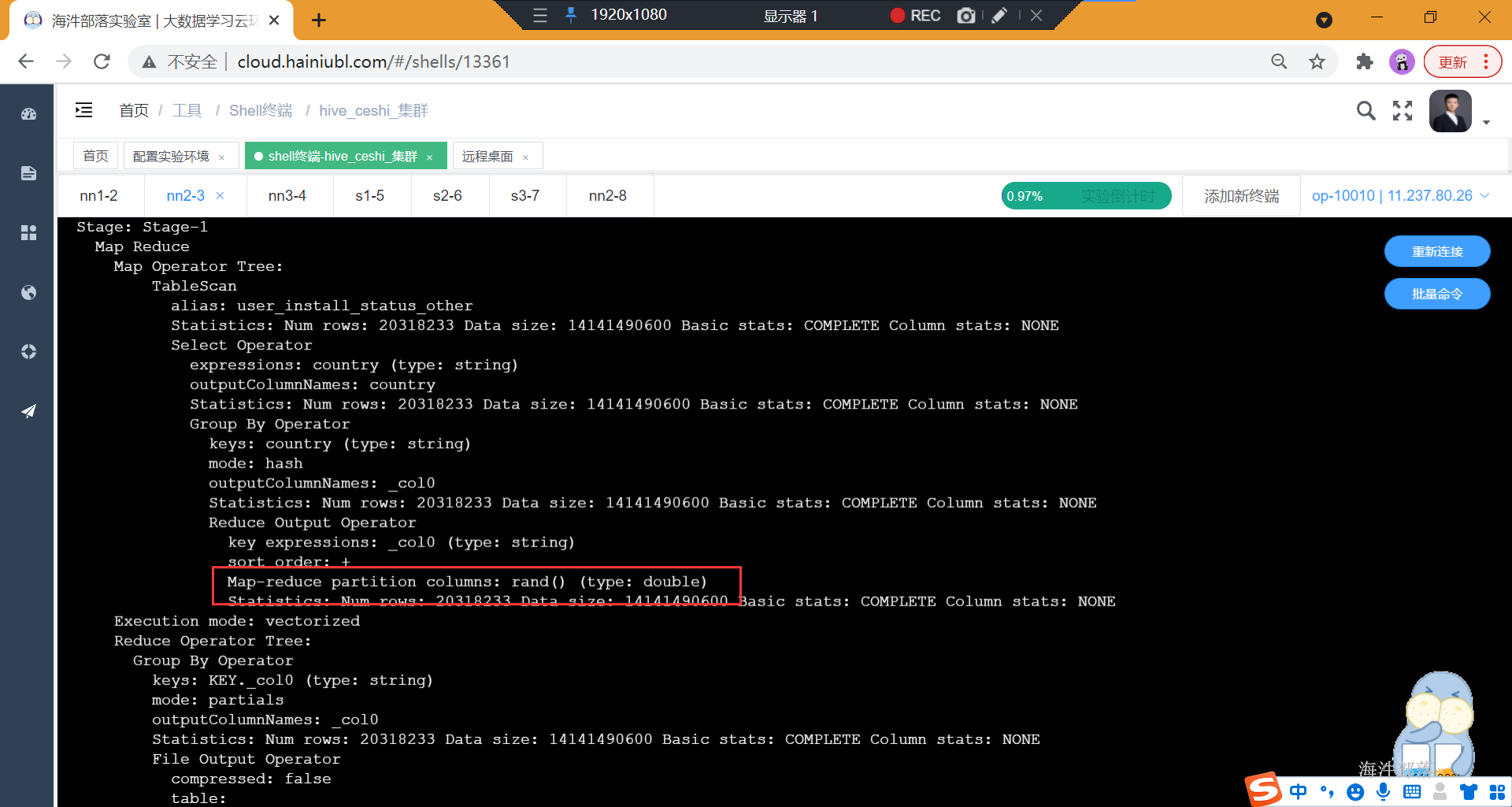
2) 没设置负载均衡
set hive.groupby.skewindata=false;
explain select sum(1) as n from
( select country from user_install_status_other group by country) t ;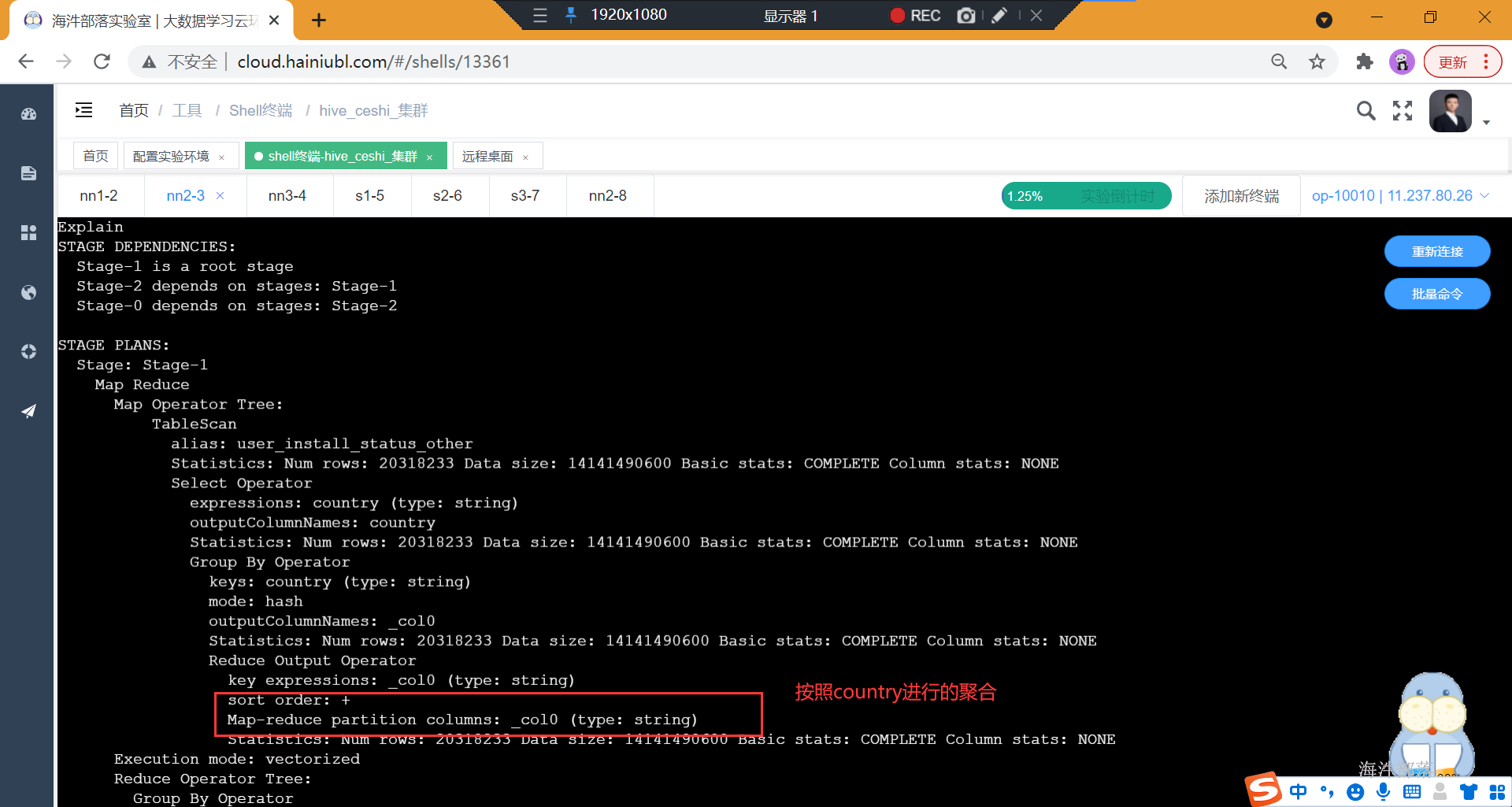
4.8.4 SQL 语句调节
1)大表Join小表:
非法数据太多,比如null。
假设:有表test_a, test_b, 需要执行test_a left join test_b, test_a 表id字段有大量null值。
test_a:总记录数:700多万, id is null 记录数:700万
test_b:总记录数:3条
-- 关闭mapjoin
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
set mapred.reduce.tasks=3;
insert overwrite local directory '/home/hadoop/outputjoin'
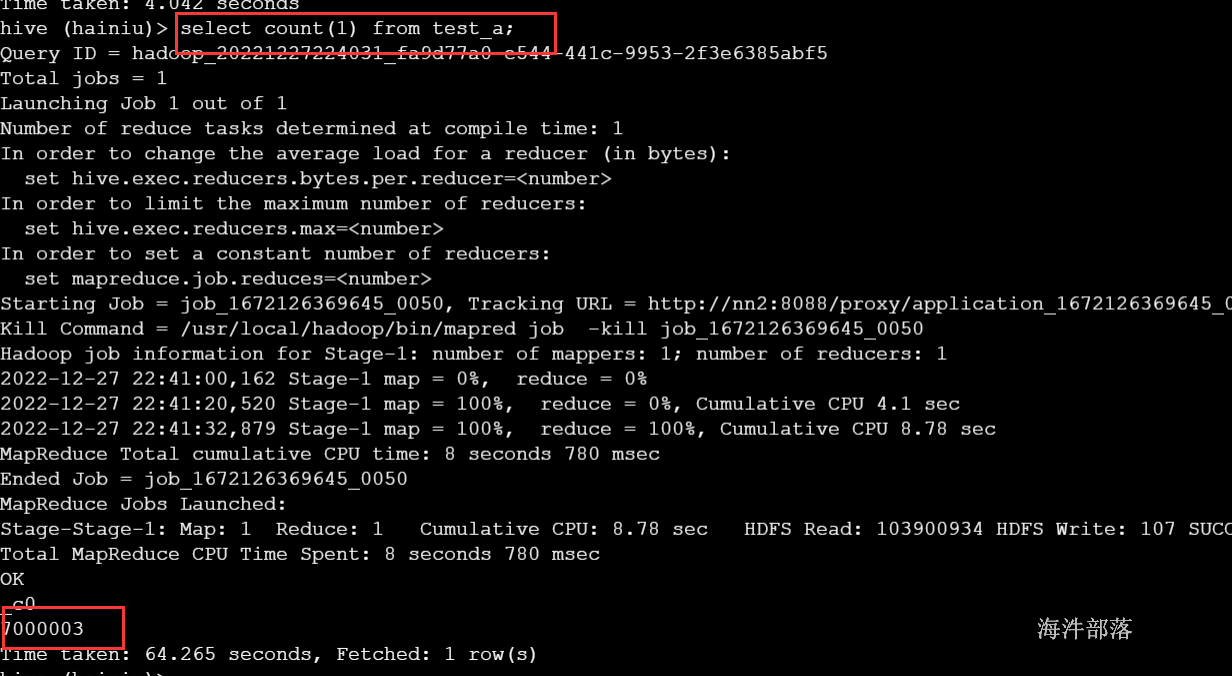
SELECT * FROM test_a a
left JOIN test_b b
ON a.id=b.id 上面的SQL会将所有的null值分到一个reduce里。

也可以通过导出的文件判断
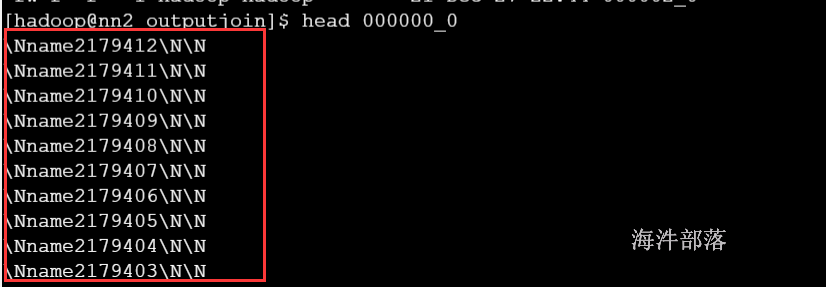
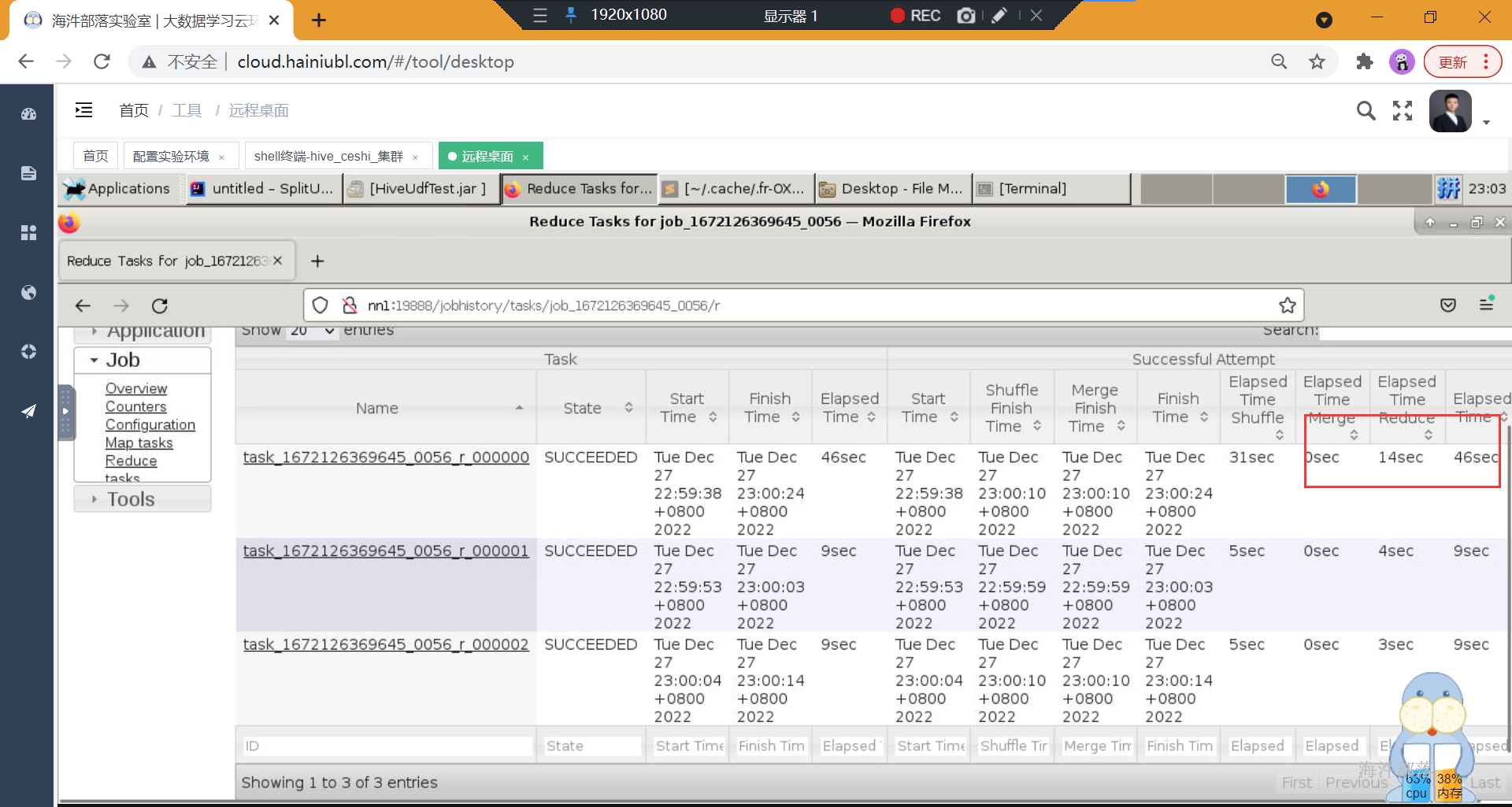
解决方案:
把空值的key变成一随机数(随机值类型需要跟key的类型一致),把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
set mapred.reduce.tasks=3;
insert overwrite local directory '/home/hadoop/outputdemo3'
SELECT * FROM test_a a
LEFT JOIN
test_b b
ON
CASE WHEN a.id IS NULL THEN ceiling(rand() * 100 + 100) ELSE a.id END =b.id; reduce执行时间相对平均
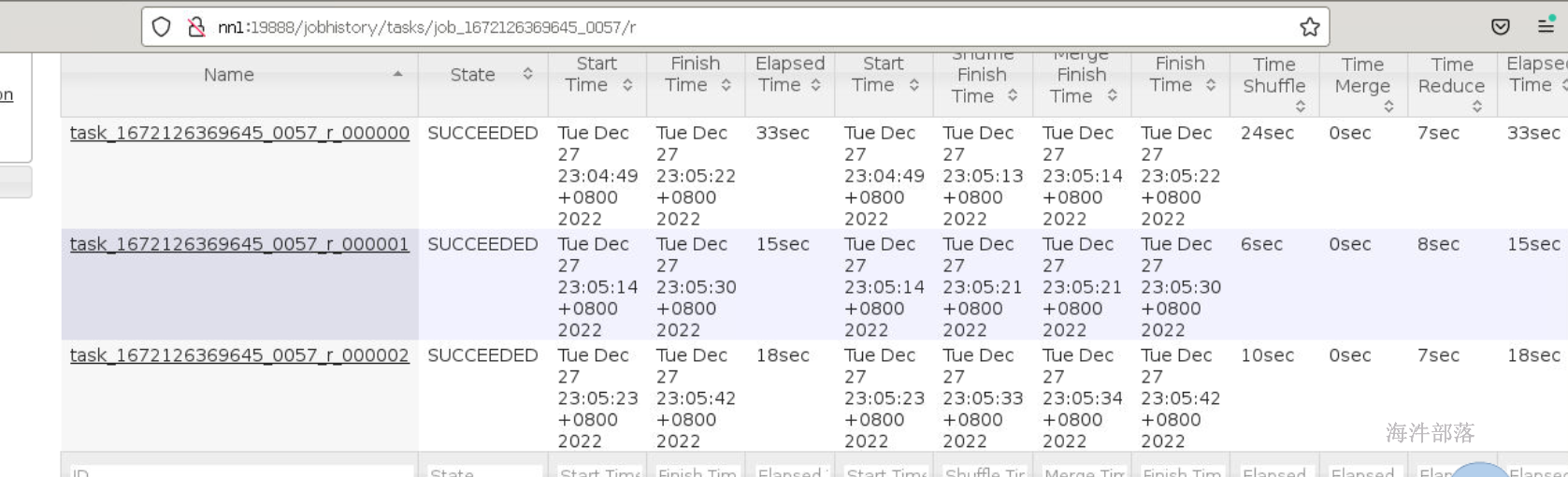
通过产生的文件数据,reduce处理的数据也比较均衡

注意:join的字段类型一定要一致,否则数据不会分到不同的reduce上。
ceiling(rand() * 100) ----------> CONCAT('hainiu',RAND())
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
set mapred.reduce.tasks=3;
insert overwrite local directory '/home/hadoop/outputdemo4'
SELECT * FROM test_a a
LEFT JOIN
test_b b
ON
CASE WHEN a.id IS NULL THEN CONCAT('hainiu',RAND()) ELSE a.id END =b.id; 由于join字段类型不同,导致数据不会分到不同的reduce上。

2)count distinct 数据倾斜
在执行下面的SQL时,即使设置了reduce个数也没用,它会忽略设置的reduce个数,而强制使用1。这唯一的Reduce Task需要Shuffle大量的数据,并且进行排序聚合等处理,这使得它成为整个作业的IO和运算瓶颈。
set mapred.reduce.tasks=3;
-- 关闭负载均衡
set hive.groupby.skewindata=false;
select count (distinct country) from user_install_status_limit;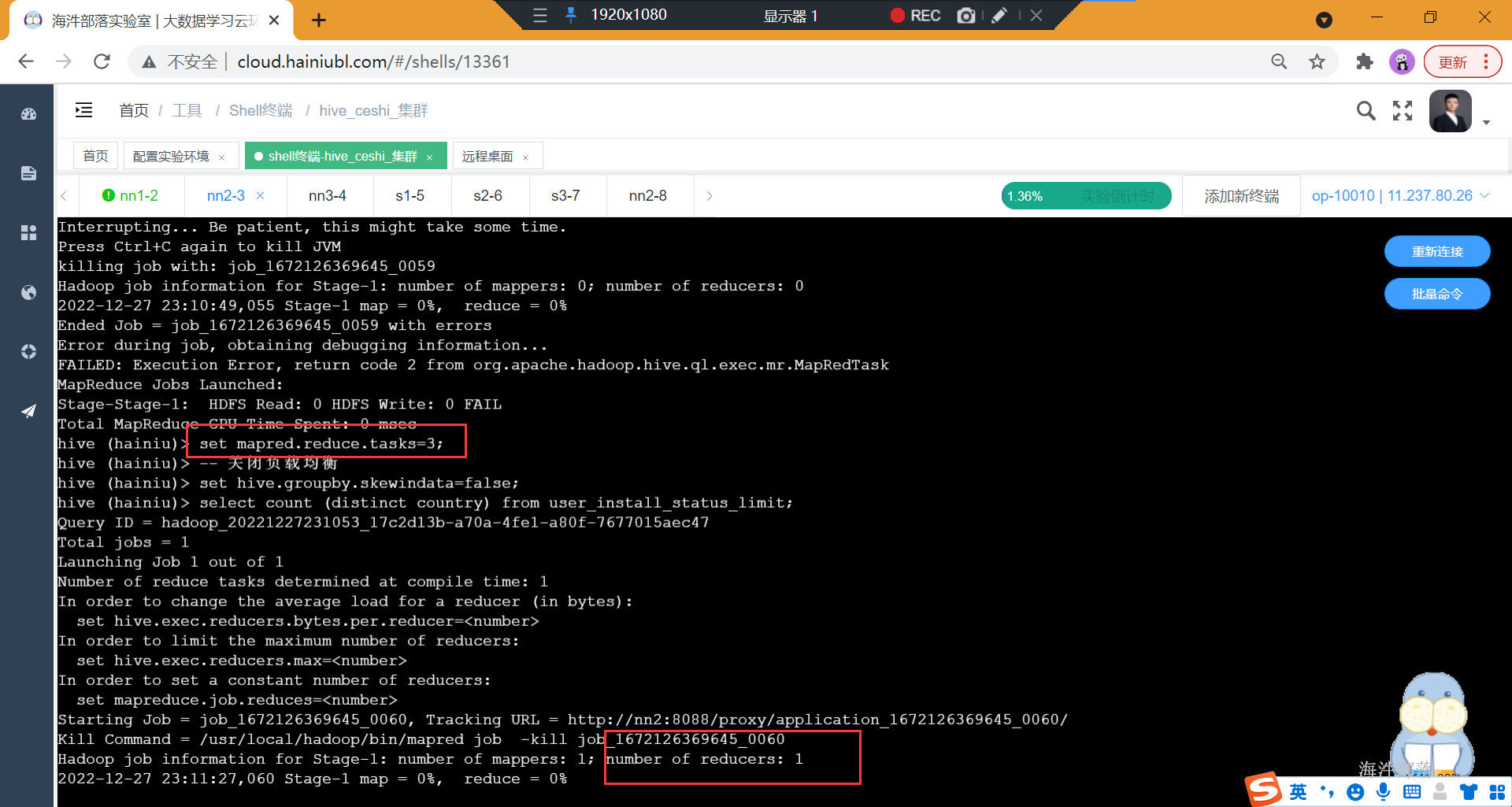
优化方案:
设置多个reduce时,在reduce阶段可以多个reduce处理数据,而不是只有一个reduce处理数据。
set mapred.reduce.tasks=3;
select count(*) from (select country from user_install_status_limit group by country)t;
或
select count(*) from (select distinct country from user_install_status_limit)t;