
1 flume概述
Flume是cloudera(CDH版本的hadoop) 开发的一个分布式、可靠、高可用的海量日志收集系统。它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到HDFS、Hbase,简单来说flume就是收集日志的。
Flume两个版本区别:
1)Flume-og
2)Flume-ng
1.1 flume的结构模型
Flume 运行的核心是 Agent,Flume以agent为最小的独立运行单位,含有三个核心组件,分别是source、 channel、 sink,通过这些组件, Event 可以从一个地方流向另一个地方,如下图所示。
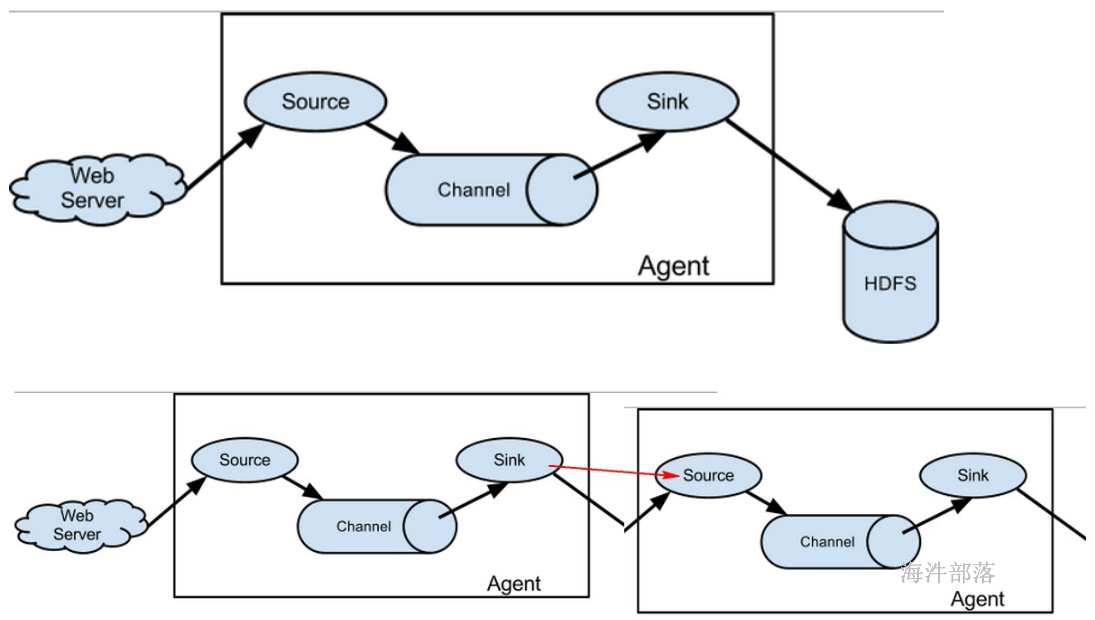
Source:
从Client上收集数据并对数据进行格式化,以Event(事件)的形式传递给单个或多个Channel。
Channel:
短暂的存储容器,将从Source接收到的Event进行缓存直到被Sink消费掉,Channel是Source和Sink之间的桥梁,Channal是一个完整的事务,能保证了数据在收发时的一致性,并且一个Channel可以同时和任意数量的Source和Sink建立连接。
Sink:
从Channel中消费数据(Event)并传递到存储容器(Hbase、HDFS)或其他的Source中。
工作流程:
把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。
为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume再删除自己缓存的数据。
什么是Event?
1)event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录。
2)event也是事务的基本单位。
3)event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。
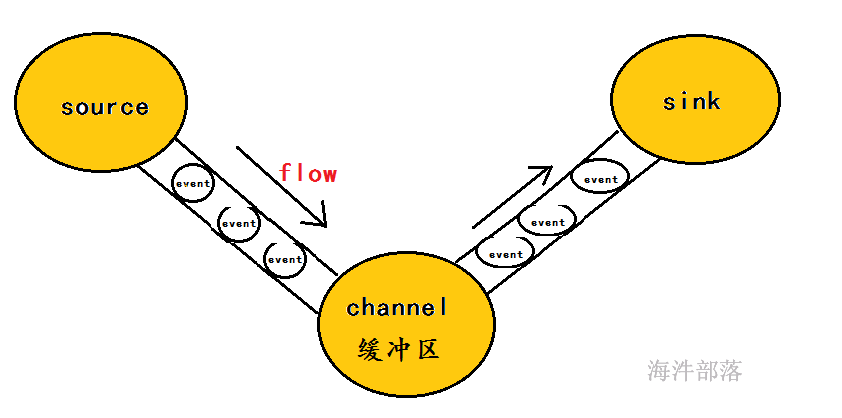
Agent:
Flume以 Agent 为最小的独立运行单元,Agent 依赖于 JVM ,一个 Agent 的运行就伴随一个 JVM 实例的产生。
一台机器可以运行多个Agent,一个Agent中可以包含多个Source、Channel。Sink。
1.2 flume各组件介绍
Flume提供了大量内置的Source、Channel和Sink类型,不同类型的Source,Channel和Sink可以自由组合.组合方式基于用户设置的配置文件。
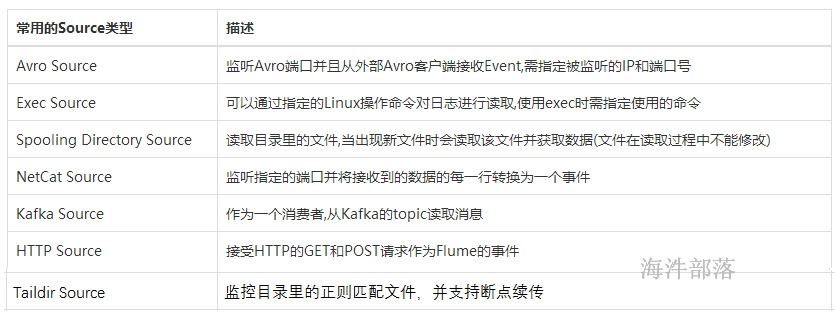
1.2.1 Source组件
Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中,Flume提供了各种source的实现,包括Avro Source、Exce Source、Spooling Directory Source、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source,etc。如果内置的Source无法满足需要, Flume还支持自定义Source。
1.2.2 Channel组件
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件,Flume对于Channel,则提供了Memory Channel、JDBC Chanel、File Channel,etc。
MemoryChannel可以实现高速的吞吐,但是无法保证数据的完整性。
MemoryRecoverChannel在官方文档的建议上已经建义使用FileChannel来替换。
FileChannel保证数据的完整性与一致性。

1.2.3 Sink组件
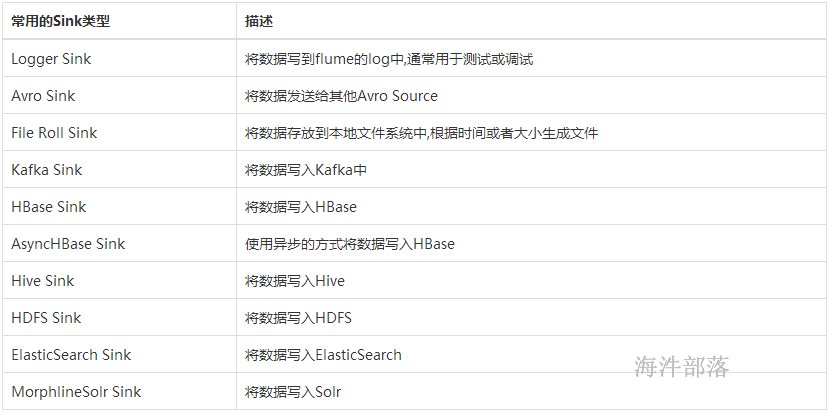
Flume Sink取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。Flume也提供了各种sink的实现,包括HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink,etc。
Flume Sink在设置存储数据时,可以向文件系统中,数据库中,hadoop中储数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据,在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
2 flume 安装
在海牛实验室选择一个公用linux组件
安装jdk
rpm -ivh jdk-8u144-linux-x64.rpm
配置jdk环境变量
#编辑环境变量文件
vim /etc/profile
#添加配置信息
export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin
#让环境变量立即生效
source /etc/profile将flume安装包解压到到/usr/local目录下
tar -zxvf apache-flume-1.10.1-bin.tar.gz -C /usr/local/
创建flume的软链接
ln -s apache-flume-1.10.1-bin/ flume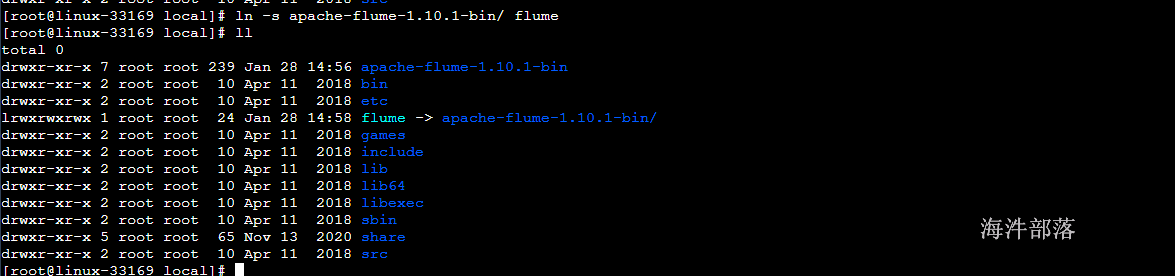
配置环境变量
#编辑环境变量文件
vim /etc/profile
#添加配置信息
export FLUME_HOME=/usr/local/flume
export PATH=$PATH:$FLUME_HOME/bin
#让环境变量立即生效
source /etc/profile修改flume中log4j2.xml配置文件,将LogFile改为Console
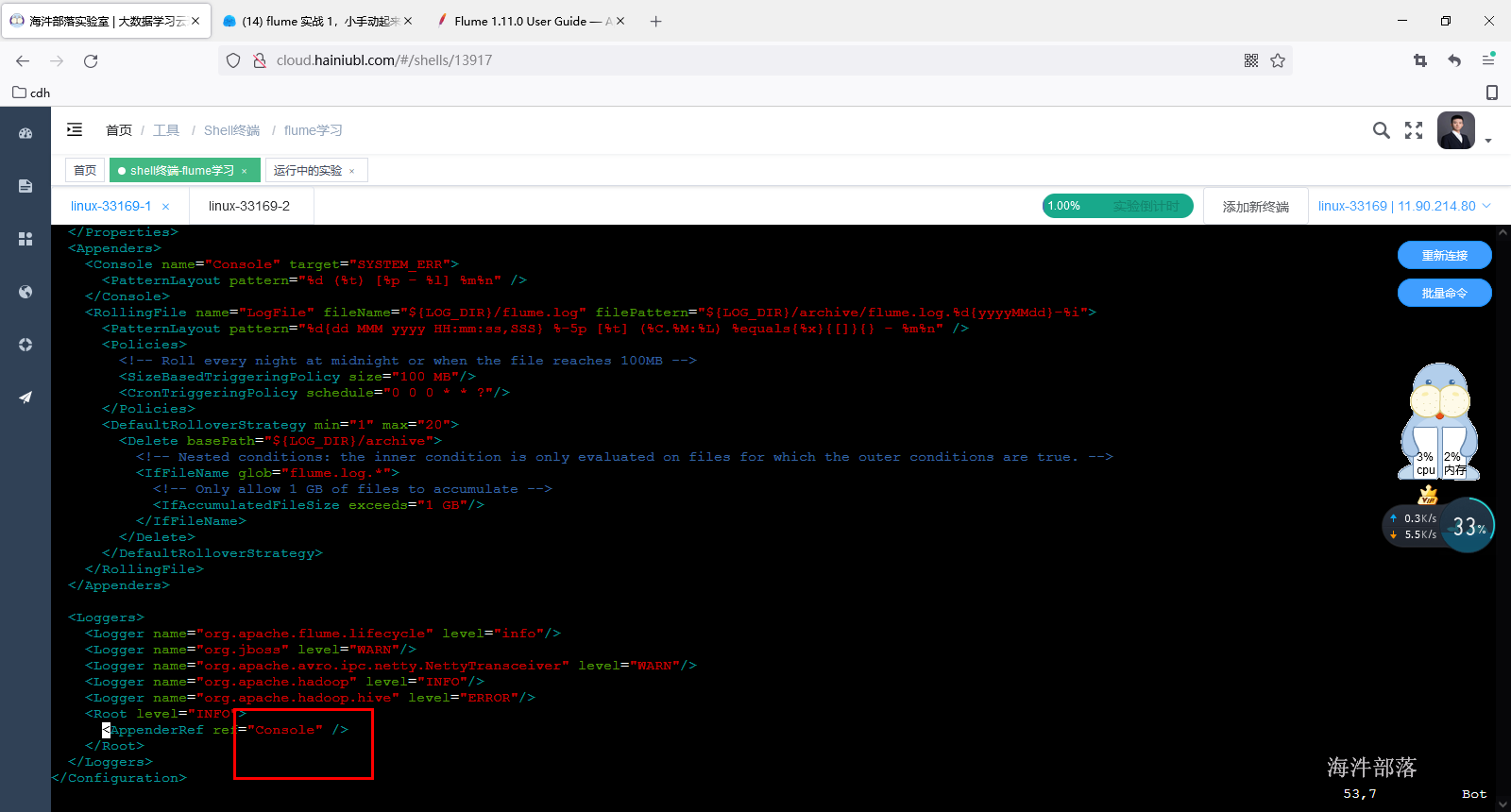
修改flume运行时占用jvm堆内存大小,修改flume-env.sh.template
mv flume-env.sh.template flume-env.sh
#添加
export JAVA_OPTS="-Xms512m -Xmx1024m -Dcom.sun.management.jmxremote"3 flume 常用source介绍
flume应用就是学组价的搭配应用,根据各组件的不同,配置内容也不同
可参考官方网站:http://flume.apache.org/FlumeUserGuide.html
3.1 官方案例演示
监听一个指定的网络端口,即只要应用程序向这个端口里面写数据,这个source组件就可以获取到信息。
其中:
Source:netcat
Sink:logger
Channel:memory
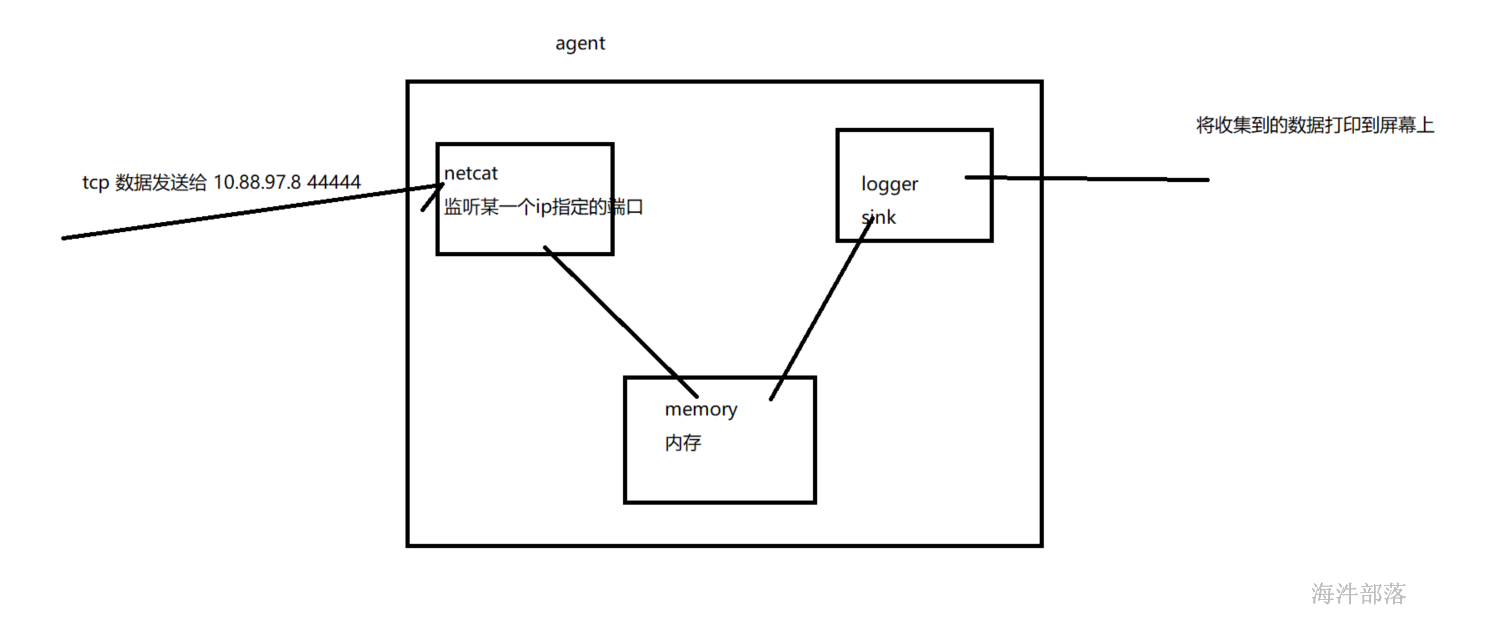
1)从整体上描述代理agent中sources、sinks、channels所涉及到的组件
# 配置Agent
a1.sources = r1
a1.sinks = k1
a1.channels = c12)分别配置三个组件的具体实现
# 配置Source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 192.168.142.160
a1.sources.r1.port = 22222
# 配置Sink
a1.sinks.k1.type = logger
# 配置Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1003)将三个组件进行连接
# 将三者连接
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c14)启动flume agent a1 服务端
# 每个人用自己的,注意给自己用户权限 /data/xxx/flume
flume-ng agent -n a1 -c /usr/local/flume/conf/ -f ./demo.agent -Dflume.root.logger=INFO,console参数说明:
-n :指定agent名称(与配置文件中代理的名字相同)
-c :指定flume中配置文件的目录
-f :指定配置文件
-Dflume.root.logger=DEBUG,console :设置日志等级
5)使用telnet发送数据
在虚拟机里发送命令
telnet 192.168.142.160 22222
aa bb cc
6)在控制台上查看flume收集到的日志数据

3.2 exec source
Exec Source:监听一个指定的命令,获取一条命令的结果作为它的数据源 ;
常用的是tail -F file指令监控一个文件,即只要应用程序向日志(文件)里面写数据,source组件就可以获取到日志(文件)中最新的内容 。
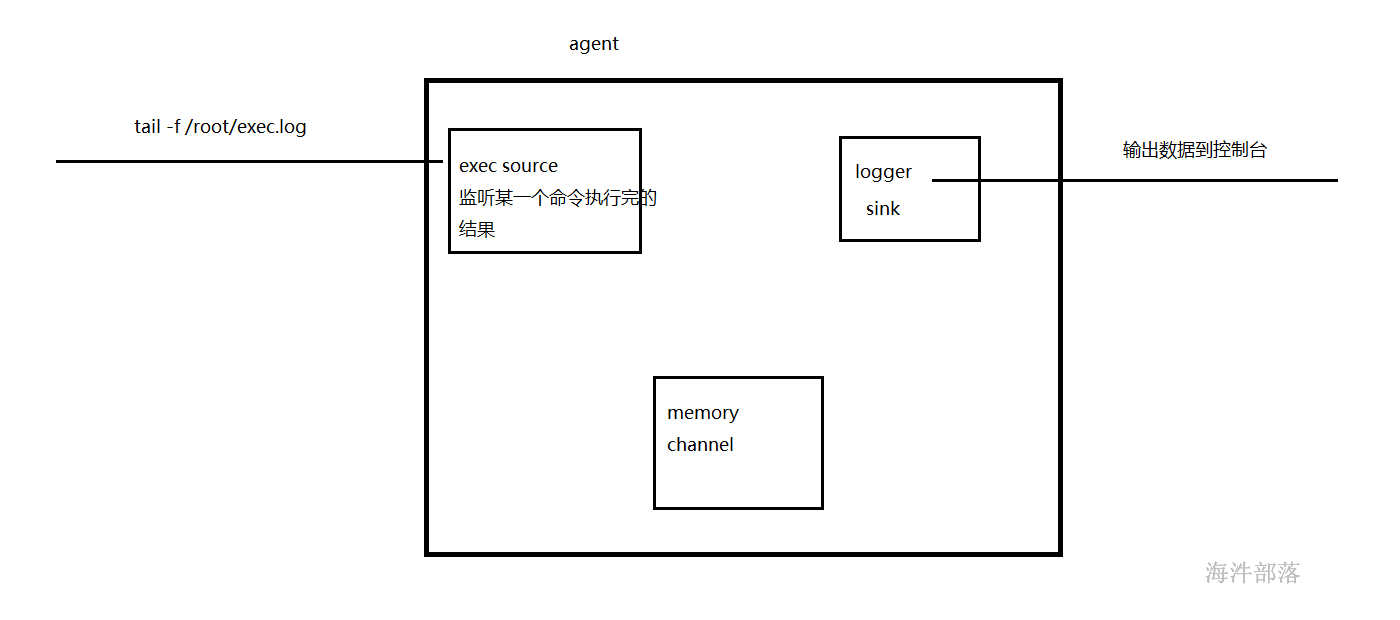
可用此方式进行实时抽取。
配置如下:
Source:exec
Sink:logger
Channel:memory
# exec source
#给agent组件起名
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#定义source
a1.sources.r1.type=exec
a1.sources.r1.command=tail -f /root/exec.log
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=logger
#绑定
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1创建监控文件
cd /root && touch exec.log && echo 'OK'启动flume agent a1 服务端
flume-ng agent -n a1 -c /usr/local/flume/conf/ -f ./exec.agent -Dflume.root.logger=INFO,console向exec.log文件中添加数据

观察结果

3.3 Taildir Source
Taildir Source:监听一个指定的目录下,指定正则格式的文件的内容,作为它的数据源,并支持断点续传功能 ;
如何支持断点续传的?
有个文件,存储断点续传的位置。
用于实时抽取指定目录下的多个文件。
创建配置文件
vim /opt/flume/taildir.agent填写如下配置到文件中
配置方式:
Source:Taildir
Sink:logger
Channel:memory
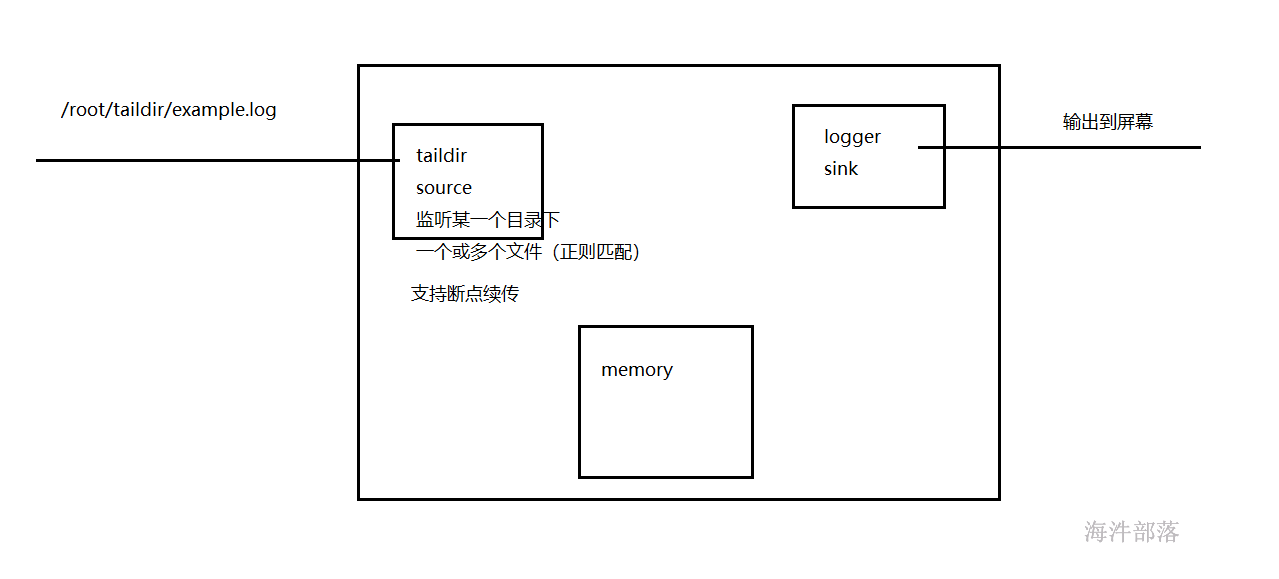
# taildir source
#给agent组件起名
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#定义source
a1.sources.r1.type=taildir
a1.sources.r1.positionFile = /root/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /root/taildir/example.log
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=logger
#绑定
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1创建监控目录
mkdir -p /root/taildir启动flume agent a1服务端
flume-ng agent -n a1 -c /usr/local/flume/conf/ -f ./taildir.agent -Dflume.root.logger=INFO,console追加N条数据到 t1.log中
echo `date` >> /root/taildir/example.log查看/root/taildir_position.json 文件内容
内部记录了归集到哪个文件的哪个位置

此时关闭flume的agent。接着向example.log写入数据

重启flume会从上一次收集处接着收集

新的记录位置有更新

3.4 Spooling Directory Source
Spooling Directory Source:监听一个指定的目录,即只要应用程序向这个指定的目录中添加新的文件,source组件就可以获取到该信息,并解析该文件的内容,然后写入到channle。写入完成后,标记该文件已完成或者删除该文件。
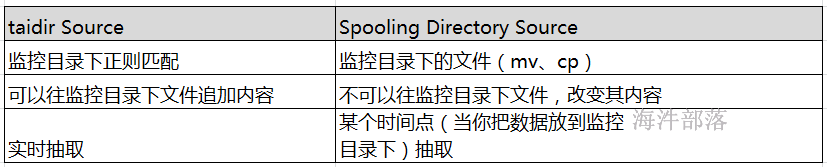
此种方式不是实时抽取,是定时抽取。
flume官网中Spooling Directory Source描述:
Property Name Default Description
channels –
type – The component type name, needs to be spooldir.
spoolDir – Spooling Directory Source监听的目录
fileSuffix .COMPLETED 文件内容写入到channel之后,标记该文件
deletePolicy never 文件内容写入到channel之后的删除策略: never or immediate
fileHeader false Whether to add a header storing the absolute path filename.
ignorePattern ^$ Regular expression specifying which files to ignore (skip)
interceptors – 指定传输中event的head(头信息),常用timestampa1.sources.r1.ignorePattern = ^(.)*\.tmp$ # 跳过.tmp结尾的文件
两个注意事项:
# 1) 拷贝到spool目录下的文件不可以再打开编辑
# 2) 不能将具有相同文件名字的文件拷贝到这个目录下配置如下:
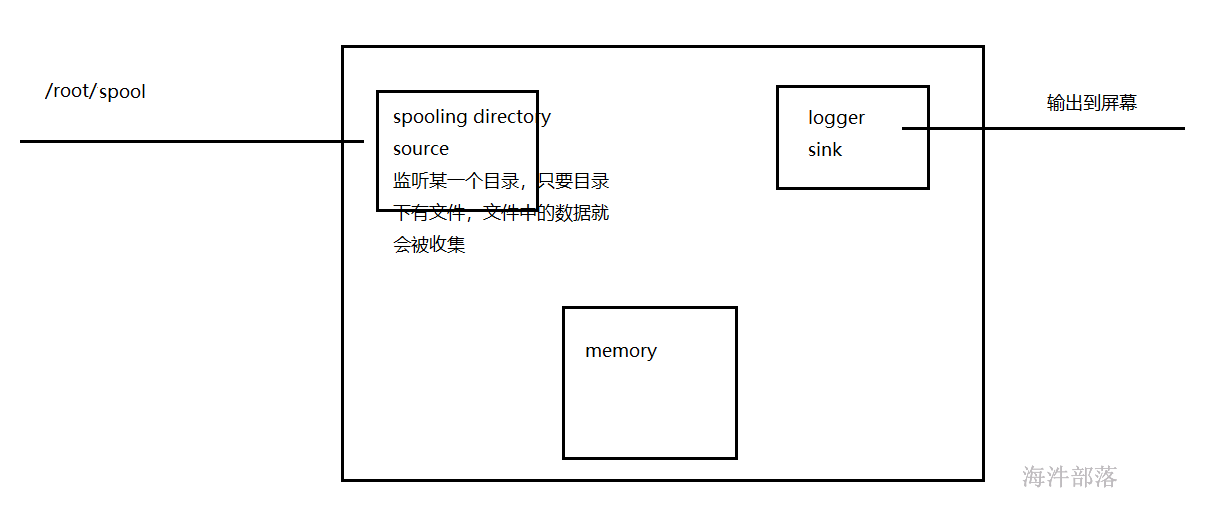
Source:Spooling Directory
Sink:logger
Channel:memory
#给agent组件起名
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#定义source
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/root/spool
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=logger
#绑定
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1其中:
Spooling Directory Source 监听/root/spool 下的是否有新文件,如果有,则读到channel。输出到控制台上。
创建监控目录
mkdir -p /root/spool启动flume agent a1 服务端
flume-ng agent -n a1 -c /usr/local/flume/conf/ -f ./spooling.agent -Dflume.root.logger=INFO,console监控/root/spool 目录,把文件cp到目录下,flume就开始归集,归集完,把文件重命名为xxx.COMPLETED
cp文件到目标目录(文件不重名)

已经被归集的文件,被重命名

输出的内容如下

3.5 HTTP Source
用来接收http协议通过get或者post请求发送过来的数据,一般get用于测试,常用的是接收post请求发送过来的数据。
配置如下:
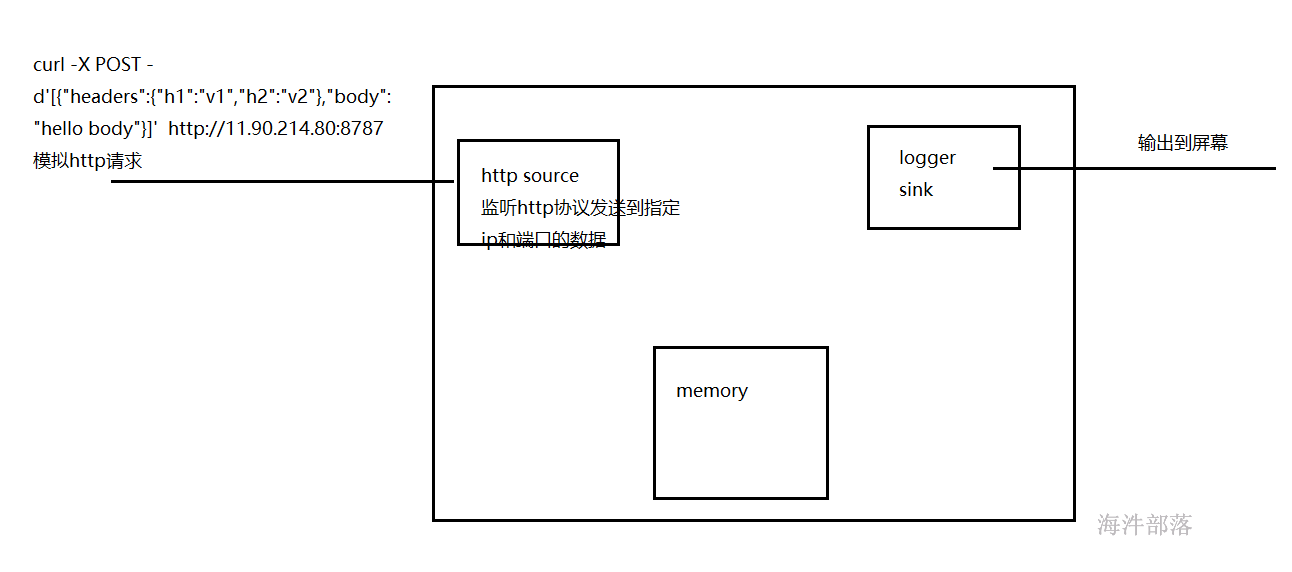
Source:http
Sink:logger
Channel:memory
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#定义source
a1.sources.r1.type=http
a1.sources.r1.bind=11.90.214.80
a1.sources.r1.port=8787
#定义channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000000
a1.channels.c1.transactionCapacity=100
#定义sink
a1.sinks.k1.type=logger
#绑定
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动flume agent a1 服务端
flume-ng agent -n a1 -c /usr/local/flume/conf/ -f ./http.agent -Dflume.root.logger=INFO,console发送http请求,并携带请求数据
curl -X POST -d'[{"headers":{"h1":"v1","h2":"v2"},"body":"hello body"}]' http://11.90.214.80:8787结果


