1 HDFS原理及搭建
前提:HDFS在Hadoop中是用来对数据进行分布式存储的,提供了数据的容错能力。在没有Hadoop之前,我们的数据存储在哪?以及怎样保证数据的容错特性呢?
1.1 单块硬盘
单机时代:早期互联网刚发展的时候,各种硬件资源相对缺乏,成本较高。我们将数据写入到磁盘中,一块不够再来一块,如果把数据一块磁盘一块磁盘的写,有如下问题:
1)单块磁盘写,磁盘读写速度上不去,读写慢;
2)数据写入单块磁盘,一旦磁盘故障导致数据丢失;
在这种情况下,RAID技术就应运而生了。
1.2 RAID
RAID ( Redundant Array of Independent Disks )即独立磁盘冗余阵列,简称为「磁盘阵列」,其实就是用多个独立的磁盘组成在一起形成一个大的磁盘系统,从而实现比单块磁盘更好的存储性能和更高的可靠性。

根据 RAID 算法的不同,RAID 有很多种。下面主要介绍 RAID0、RAID1、RAID10。
1.2.1 RAID0
RAID0 是一种非常简单的的方式,它将多块磁盘组合在一起形成一个大容量的存储。
假设阵列中有N块磁盘,当写数据时,会将数据分为N份,然后分别写入N块 磁盘中。因此,RAID0将提供非常优秀的读写性能。
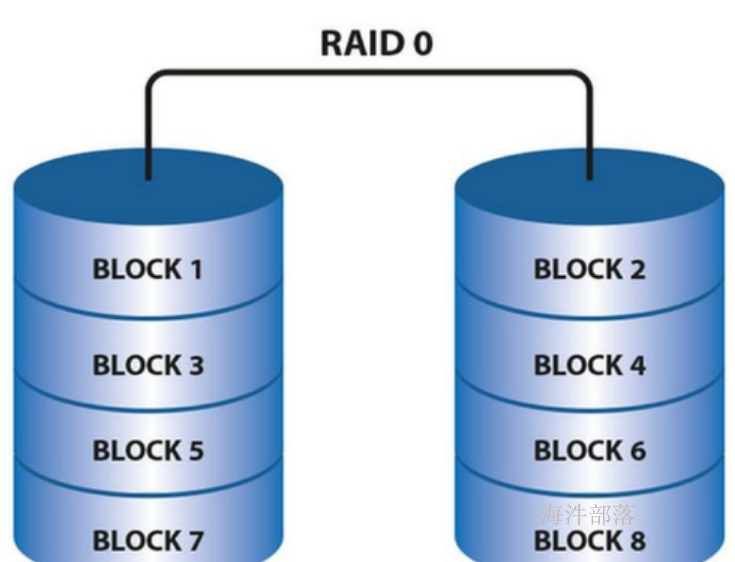
优点:
并行写入读取快,空间利用率高。
如果你要读取/写入 2G 的数据,在普通硬盘上,要以单盘的速度读取/写入 2G 的数据。
如果在 4 盘 RAID0 阵列中,每个盘只需读取/写入 500MB 的数据,四个盘可以并行读取/写入,因此理论的读写速度将是单块硬盘的4倍。
缺点:
只要阵列中有一块硬盘坏掉,由于这块硬盘保存着所有数据(每个文件)的某一部分,因此所有数据都将无法读取,整个阵列中的数据将宣告报废。
1.2.2 RAID1
RAID1 是磁盘阵列中单位成本最高的一种方式。因为它的原理是在往磁盘写数据的时候,将同一份数据无差别的写两份到磁盘,分别写到工作磁盘和镜像磁盘,那么它的实际空间使用率只有50%了,两块磁盘当做一块用,这是一种比较昂贵的方案。
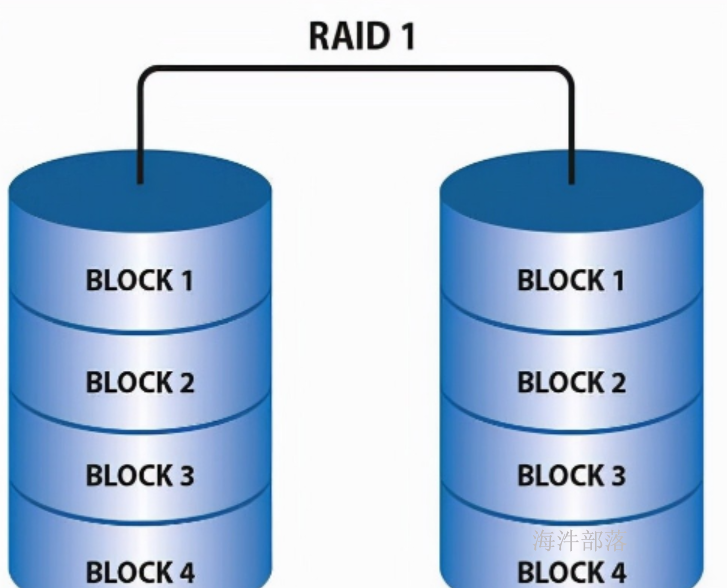
优点:
数据写入两个磁盘,通过冗余存储实现容错。
缺点:
空间利用率低,读写速度慢。
1.2.3 RAID10
RAID10其实就是RAID1与RAID0的一个合体。
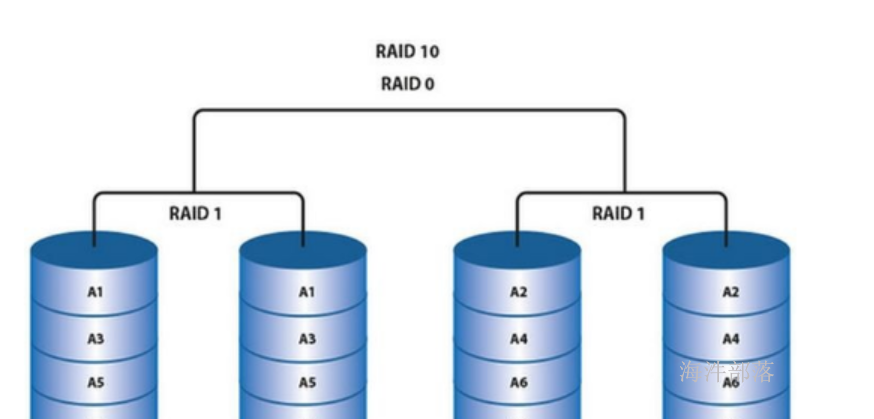
先将磁盘阵列组成 RAID1, 再将多个RAID1 组成 RAID0。
读写数据时,可以将数据分N块,并行写入,而且每块数据都有备份。
这样既可以通过冗余存储容错,也可以提高读写的效率。
2 HDFS组件详解
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统,用来解决存储问题。
HDFS 可以使用低成本的硬件来搭建。
HDFS 可以对海量的数据进行分布式存储。
HDFS 实现软件RAID10。
2.1 HDFS 组件介绍-namenode、datanode

在 HDFS 体系结构中有两类结点:
一类是 NameNode,又叫“名称结点”
另一类是 DataNode,又叫“数据结点”。
NameNode:
1)用来存储元数据。接收客户端的读写请求 ,namenode元数据保存到了内存中和磁盘中,保存到内存中是为了快速查询数据信息,保存到磁盘中是为了数据安全。
元数据包括:
- 文件名称
- 文件大小
- 文件权限
- 文件所有者
- 文件切了几块
- 副本数量
- 每一块数据存到了哪一个datanode上
- 等
2)一般有一个active状态的namenode,有两个standby状态的namenode,其中,active状态的NameNode负责所有的客户端操作,standby状态的NameNode处于从属地位,维护着数据状态,随时准备切换。
3)一个数据块的元数据信息占用namenode内存存储空间为150字节。块越小读取的速度就越快,但是整体占用namenode的空间就越大。
DataNode:
干活的。负责存储client发来的数据块block;执行数据块的读写操作。
2.2 namenode环境搭建
- 2.2.1一共需要6台服务器,复用之前我们的6台服务器
-
namenode所在服务器:nn1 nn2 nn3
- datanode所在服务器:s1 s2 s3

2.启动6台服务器,并打开所有服务器的shell终端,通过批量命令切换到hadoop用户
#切换用户
su - hadoop
#解压hadoop到 /usr/local目录中
ssh_root.sh tar -zxvf /public/software/bigdata/hadoop-3.1.4.tar.gz -C /usr/local/
#查询解压完毕的安装包
ssh_root.sh ls /usr/local/|grep hadoop-3.1.4
#修改安装包的用户权限归属为hadoop用户,因为以后我们都使用hadoop用户安装和使用
ssh_root.sh chown -R hadoop:hadoop /usr/local/hadoop-3.1.4/
#创建软连接,使用起来更方便 连接文件不用修改权限
ssh_root.sh ln -s /usr/local/hadoop-3.1.4/ /usr/local/hadoop
3)打开hadoop安装目录

(1)bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
# 配置环境变量
echo 'export HADOOP_HOME=/usr/local/hadoop' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile
#分发所有机器上
scp_all.sh /etc/profile /tmp
ssh_root.sh mv /tmp/profile /etc
#让环境变量生效
ssh_all.sh source /etc/profile
4)修改配置文件启动namenode和datanode
- 进入hadoop的配置文件目录

core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
<description>默认文件服务的协议和NS逻辑名称,和hdfs-site.xml里的对应此配置替代了1.0里的fs.default.name</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/tmp</value>
<description>数据存储目录</description>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>hadoop</value>
<description>配置root(超级用户)允许通过代理用户所属组</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>localhost</value>
<description>配置root(超级用户)允许通过代理访问的主机节点</description>
</property> hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/namenode</value>
<description>namenode本地文件存放地址</description>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
<description>提供服务的NS逻辑名称,与core-site.xml里的对应</description>
</property>
<!--主要的-->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2,nn3</value>
<description>列出该逻辑名称下的NameNode逻辑名称</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>nn1:9000</value>
<description>指定NameNode的RPC位置</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>nn1:50070</value>
<description>指定NameNode的Web Server位置</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>nn2:9000</value>
<description>指定NameNode的RPC位置</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>nn2:50070</value>
<description>指定NameNode的Web Server位置</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.rpc-address.ns1.nn3</name>
<value>nn3:9000</value>
<description>指定NameNode的RPC位置</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.http-address.ns1.nn3</name>
<value>nn3:50070</value>
<description>指定NameNode的Web Server位置</description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>77</value>
<description>namenode的工作线程数</description>
</property>hadoop-env.sh
# The maximum amount of heap to use, in MB. Default is 1000.
# java虚拟机使用的最大内存
source /etc/profile
export HADOOP_HEAPSIZE_MAX=512
#首先分发以上配偶的文件到其他机器中
scp_all.sh /usr/local/hadoop/etc/hadoop/core-site.xml /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/hadoop-env.sh /usr/local/hadoop/etc/hadoop/5)将/data目录所有者和属组改为hadoop
ssh_root.sh chown hadoop:hadoop /data
6)格式化第一台namenode
#在第一台机器上面进行数据的格式化
hdfs namenode -format
7)格式化成功之后会看到/data/namenode/current目录下有一个fsimage文件

fsimage文件是namenode元数据的镜像文件,想当于内存中元数据的快照。
#启动第一台namenode
hadoop-daemon.sh start namenode
8)格式化第二台和第三台namenode
#在nn2和nn3上执行
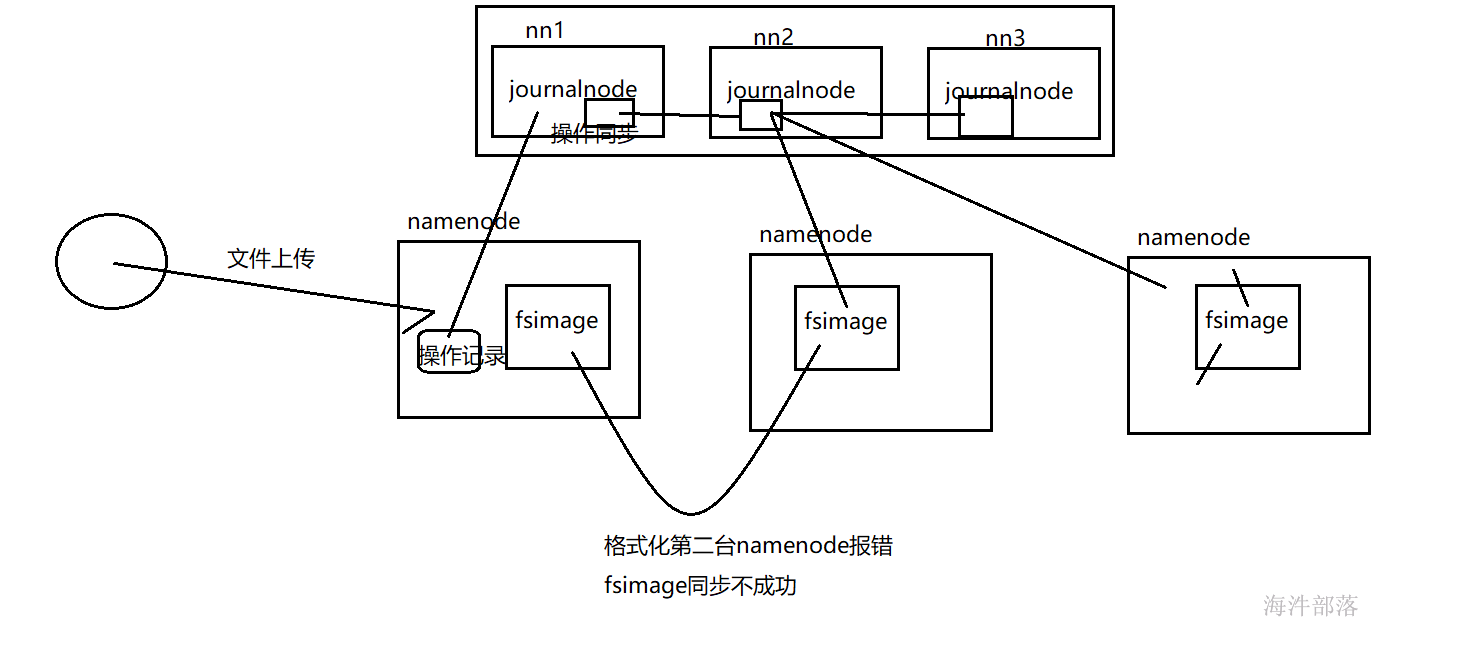
hdfs namenode -bootstrapStandby注意:此时不出意外的话要出意外了,格式化第二台namenode的时候竟然没有成功
分析原因:当我格式化第二台namenode的时候需要从第一台同步元数据,多台namenode要保证数据一致,此时需要另外一个组件journalnode
2.3 journalnode环境搭建
-
journalnode的配置-在hdfs-site.xml中添加如下配置
<property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://nn1:8485;nn2:8485;nn3:8485/ns1</value> <description>指定用于HA存放edits的共享存储,通常是namenode的所在机器</description> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/data/journaldata/</value> <description>journaldata服务存放文件的地址</description> </property> <property> <name>ipc.client.connect.max.retries</name> <value>10</value> <description>namenode和journalnode的链接重试次数10次</description> </property> <property> <name>ipc.client.connect.retry.interval</name> <value>10000</value> <description>重试的间隔时间10s</description> </property>
#将hdfs-site.xml发送到其他节点
scp_all.sh /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hadoop/etc/hadoop/2.因为journalnode是用来进行namenode数据同步的,所以需要先启动三台journalnode再对namenode进行格式化
启动journalnode之前先将nn1上namenode停掉,并将格式化生成的/data/namenode目录删除掉
hadoop-daemon.sh stop namenode
rm -rf /data/namenode#启动两个机器的journalnode
#nn1 nn2 nn3
su - hadoop
hadoop-daemon.sh start journalnode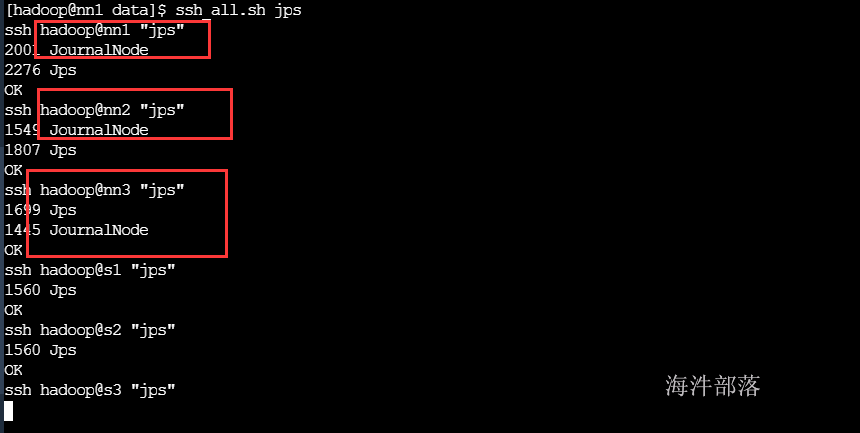

3.journalnode已经准备完毕,那么再次格式化第一台namenode并启动,
#在nn1机器上面进行namenode的格式化
hdfs namenode -format
#启动nn1上的namenode
hadoop-daemon.sh start namenode然后再次格式化第二台namenode试一下,你会惊奇的发现意外没有了,并且成功同步了nn1节点的元数据。


4,格式化并启动第三台namenode,并访问页面进行测试
#格式化第二台和第三台namenode
hdfs namenode -bootstrapStandby
#启动第二台和第三台namenode
hadoop-daemon.sh start namenode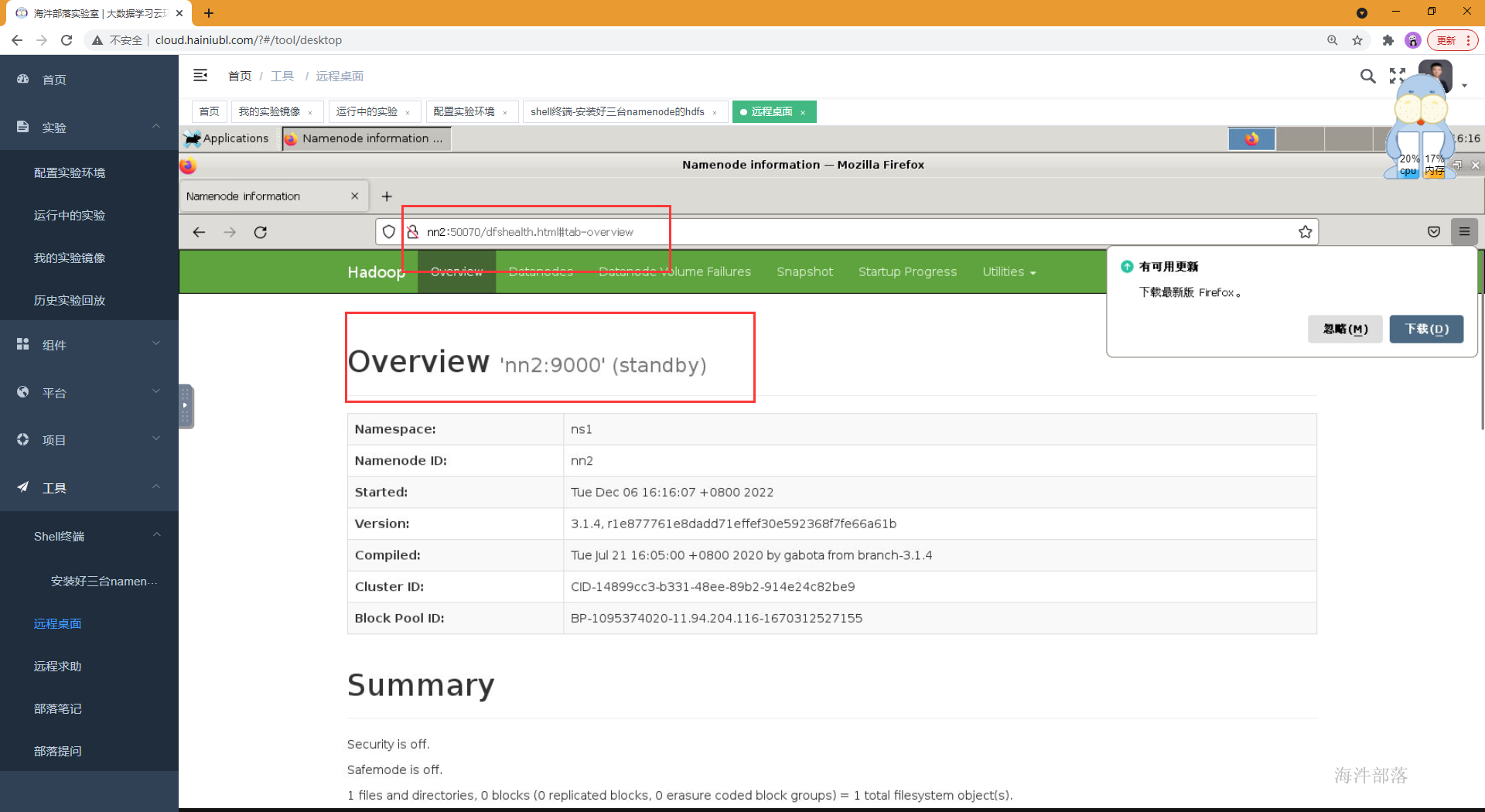
5.格式化第三台namenode并启动测试
6.到此为止namenode和journalnode全部搭建完毕,开心一小下,离成功越来越近了

7.环境搭建问题解决了,大家跟我想另外两个问题
- journalnode怎么做到的元数据的同步。
-
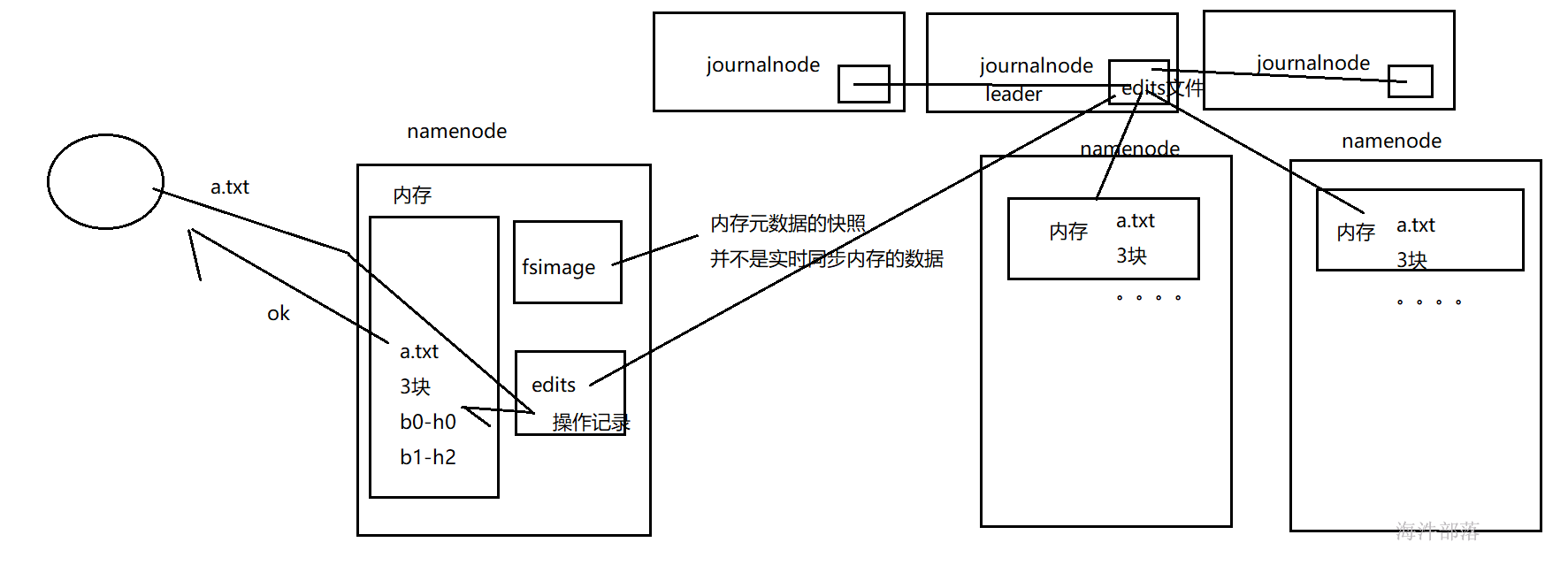
Namenode 除了内存存储元数据外,磁盘也存储,主要维护两个文件,一个是fsimage,一个是 editlog
editlog(简称edits):
操作日志文件,记录了NameNode所要执行的操作;
**fsimage:** 元数据镜像文件。存储某NameNode元数据信息,并不是实时同步内存中的数据。
一般而言,fsimage中的元数据是落后于内存中的元数据的;
当有写请求时,NameNode会首先写该操作先写到磁盘上的edits文件中,当edits文件写成功后才会修改NameNode内存的元数据,内存修改成功后向客户端返回成功信号。
请求操作记录除了会写入到activenamenode中的edits文件中,还会给journalnode中写入edits文件,然后journalnode会将本地的edits文件中的请求操作,在standbynamenode中进行同步。这样就可以进行元数据的同步了
-
namenode元数据是怎么进行合并的。
- 随着edits记录的操作越来越多,内存中的元数据越来越多,这样的话内存中的元数据存在风险,一旦宕机,内存数据丢失,所以为了安全起见,需要将内存中的元数据,周期性的写入到fsimage文件中。如果数据出错可以通过 fsimage + edits 恢复。
- 因为ActiveNamenode相对来说比较忙,所以选择相对轻松的StandbyNamenode来做元数据同步这个事情
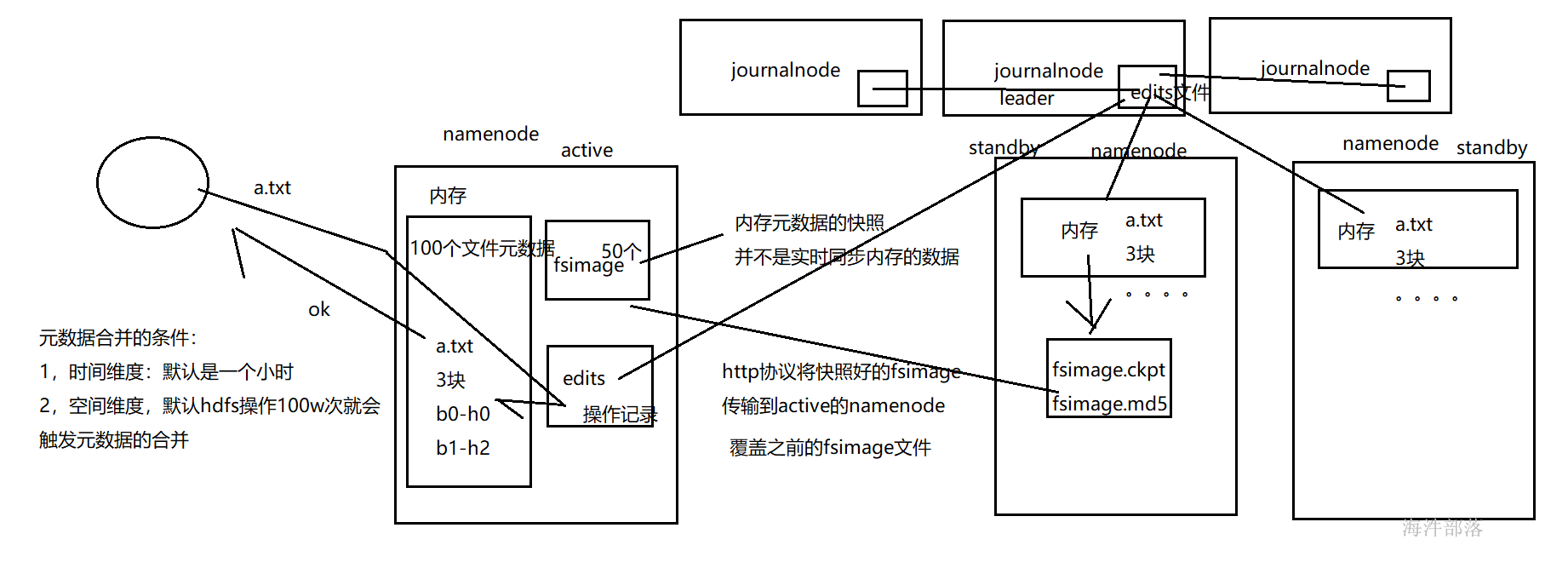
3.合并周期是什么呢?
-
StandByNamenode检查是否达到checkpoint条件:离上一次checkpoint操作是否已经有一个小时,或者HDFS已经进行了100万次操作。
-
StandByNamenode检查达到checkpoint条件后,将该元数据以fsimage.ckpt_txid格式保存到StandByNamenode的磁盘上,并且随之生成一个MD5文件。然后将该fsimage.ckpt_txid文件重命名为fsimage_txid。
-
然后StandByNamenode通过HTTP联系ActiveNameNode。
-
ActiveNameNode通过StandByNamenode从StandByNamenode获取最新的fsimage_txid文件并保存为fsimage.ckpt_txid,然后也生成一个MD5,将这个MD5与StandByNamenode的MD5文件进行比较,确认ANN已经正确获取到了StandByNamenode最新的fsimage文件。然后将fsimage.ckpt_txid文件重命名为fsimage_txit。
通过上面一系列的操作,SBNN上最新的FSImage文件就成功同步到了ANN上
4,周期不是固定的,可以通过配置文件进行配置
<property>
<name> dfs.namenode.checkpoint.period</name>
<value>3600</value>
<description>
两次连续的 checkpoint 之间的时间间隔。默认 1 小时
</description>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>最大的没有执行 checkpoint 事务的数量,满足将强制执行紧急 checkpoint,即使尚未达到检查点周期。默认设置为 100 万。
</description>
</property>2.4 ZKFC环境搭建
-
三台namenode已经全部启动成功,但是和我们想的还不太一样,最开始我们定的是有一个namenode是active的也就是老大,另外两个namenode是备份的小弟,但是现在查看三个namenode都是小弟,这怎么办?
答案:可以程序员自己决定
#手动切换nn1的节点是主节点 hdfs haadmin -transitionToActive nn1 #查看节点状态 hdfs haadmin -getServiceState nn1

-
如果每次都是程序员自己切换的话,那也太不灵活了,所以需要引入一个组件,就是zkfc
-
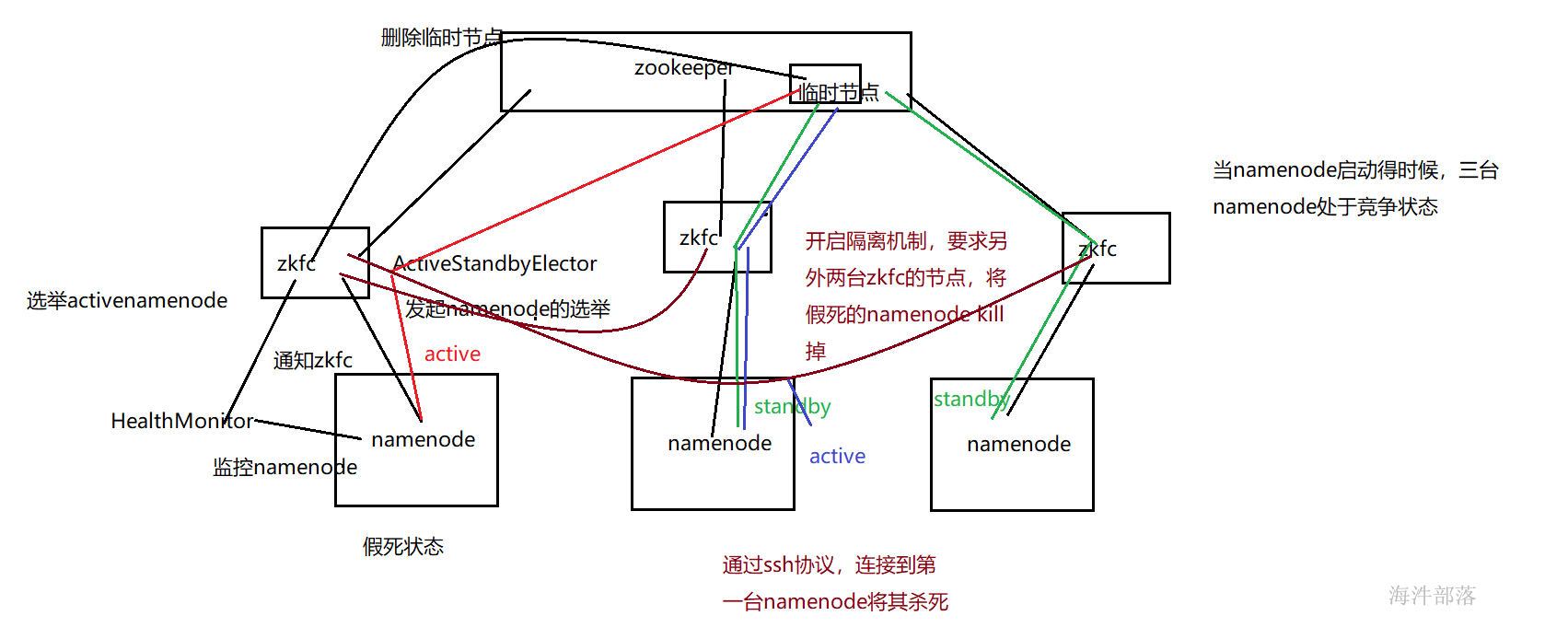
zkfc本质上就是一个进程,全称是ZKFailoverController,需要在三台namenode上启动。它的主要任务就是一边联系同服务器的namenode,一边连接zookeeper。我们三个namenode启动之后,怎么通过zkfc选出一个active的namenode呢?那就看哪台节点的zkfc先在zookeeper中创建节点。谁创建成功,哪台服务器就是active的namenode,具体过程如下:
主备切换过程
-
① 启动NameNode,ZKFC,此时三个NameNode的状态都是竞选状态
-
② 三个ZKFC分别通过ActiveStandbyElector发起NameNode的选举
通过zookeeper的写一致性以及临时节点来实现 -
③ 发起主备选举的时候,ActiveStandbyElector会尝试在zookeeper的/hadoop-ha/ns1创建一个临时节点,zookeeper的写一致性会保证只有一个节点创建成功
-
④ 创建成功的ActiveStandbyElector通过回调方式通知ZKFC,将对应的NameNode切换为Active状态;创建失败的也通过同样方式将NameNode切换为Standby状态
-
⑤ 无论是否创建成功,这些ActiveStandbyElector都会监听/hadoop-ha/ns1;
当Active NameNode对应的HealthMonitor监控到NameNode异常时,会告知ZKFC,ZKFC通过ActiveStandbyElector删除所创建的临时节点 - ⑥ 此时处于Standby的NameNode会监控到这个消息它首先会通过判断节点是否存在来确认情况
如果是正常关闭的,则发起主备选举,成功创建临时节点,并且将NameNode的状态切换为Active
-
4.zkfc安装
core-site.xml中添加一下内容
<property>
<name>ha.zookeeper.quorum</name>
<value>nn1:2181,nn2:2181,nn3:2181</value>
<description>HA使用的zookeeper地址</description>
</property>hdfs-site.xml增加如下配置
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<description>指定HA做隔离的方法,缺省是ssh,可设为shell,稍后详述</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
<description>杀死命令脚本的免密配置秘钥</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.auto-ha</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>#分发脚本配置到各个节点
scp_all.sh /usr/local/hadoop/etc/hadoop/core-site.xml /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hadoop/etc/hadoop/
启动zkfc之前需要在zookeeper中初始化zkfc的节点
#在nn1节点执行
hdfs zkfc -formatZK
分别在nn1,nn2,nn3 机器启动zkfc
#nn1 nn2 nn3启动zkfc
hadoop-daemon.sh start zkfc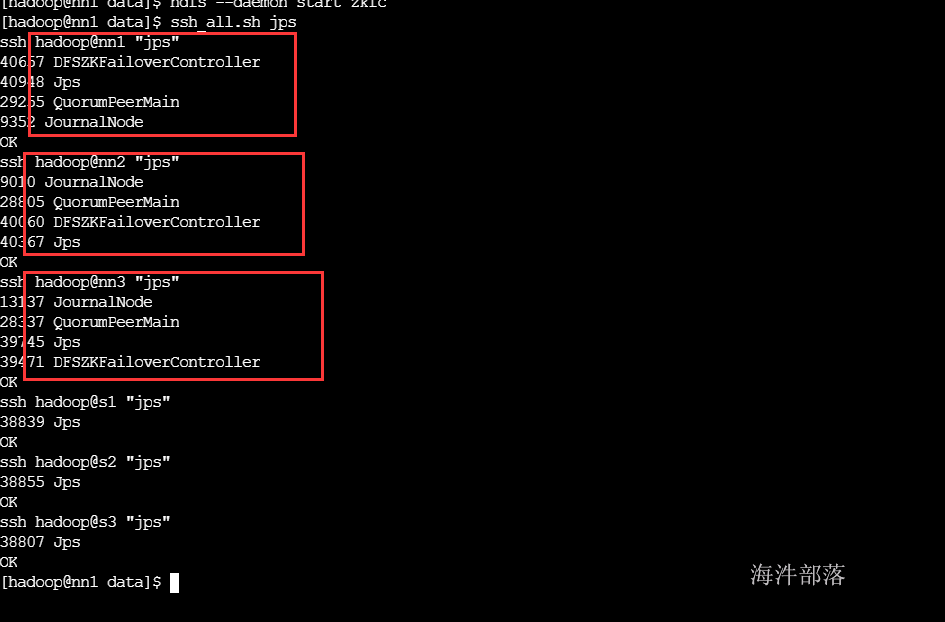
重启三台namenode查看是否会选举active namenode
#三个机器分别重启namenode
hadoop-daemon.sh stop namenode
hadoop-daemon.sh start namenode
当nn1的namenode宕掉,看看是否可以进行故障切换
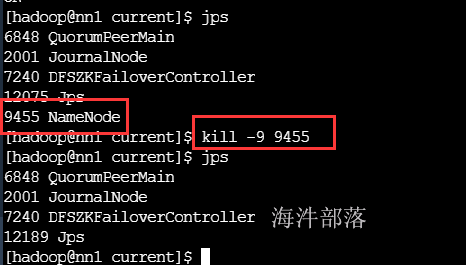
恭喜nn2变成active的namenode
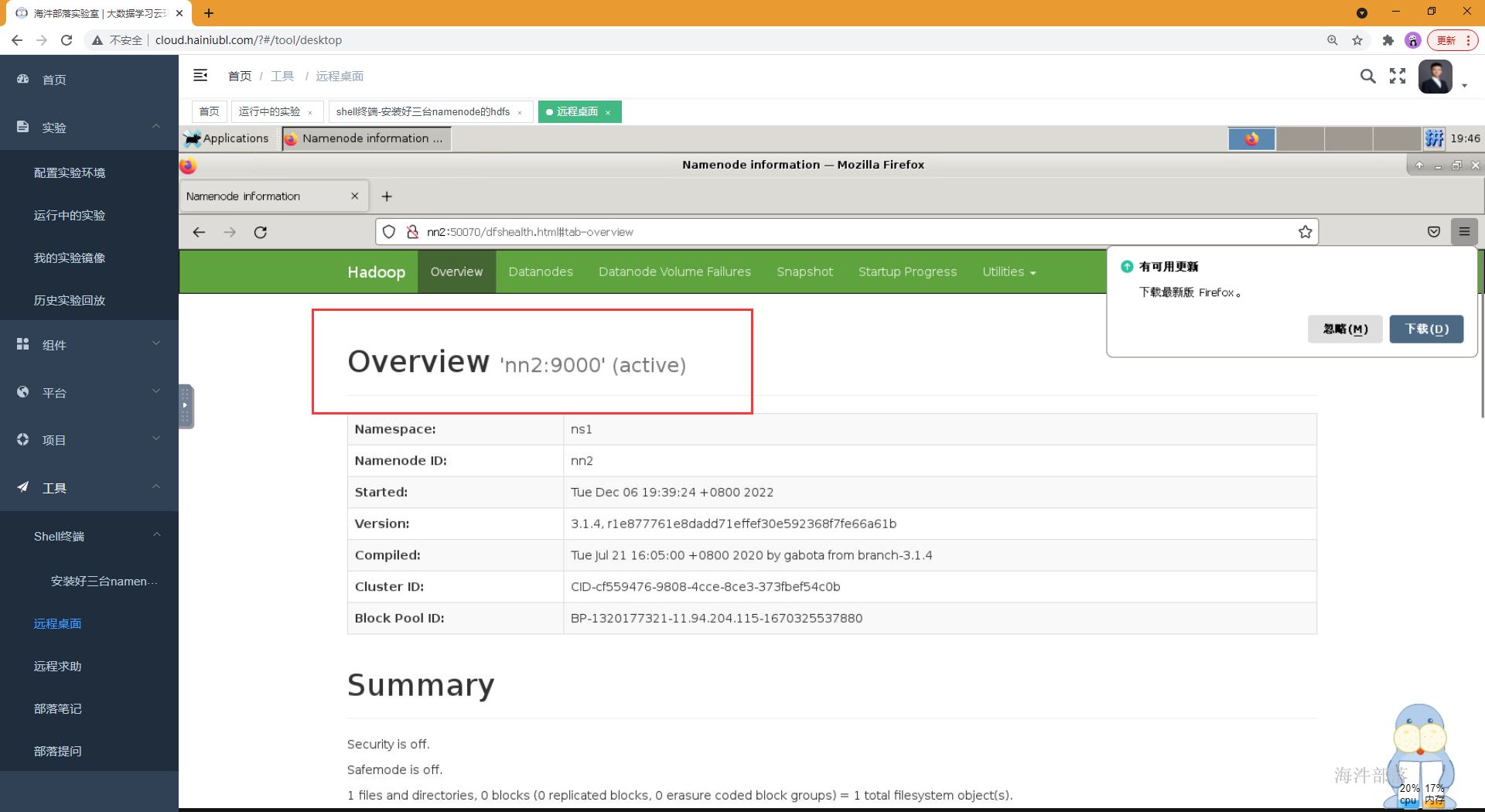
当nn2的namenode宕掉,看看是否可以再次进行故障切换
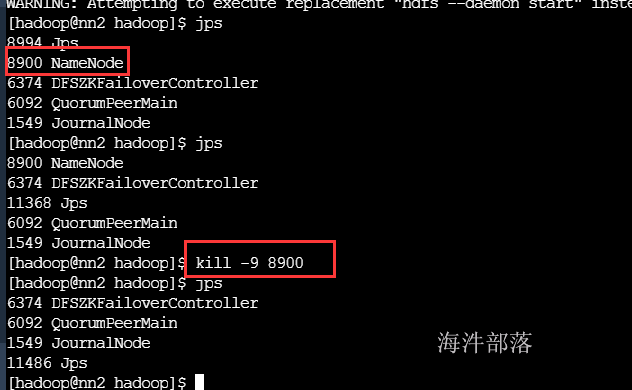
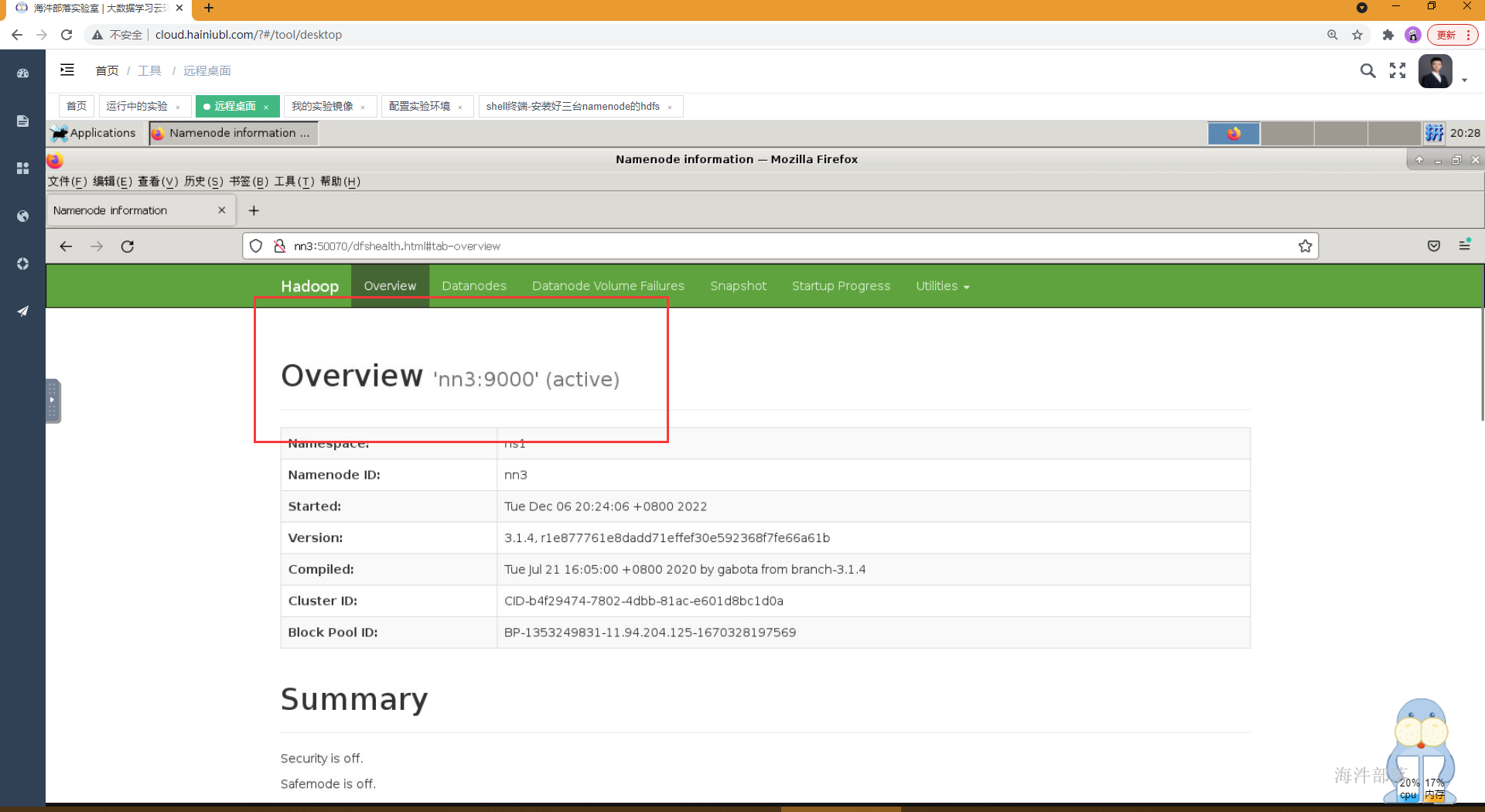
hadoop3.x之后,可以两个namenode宕机
2.5 Datanode环境搭建
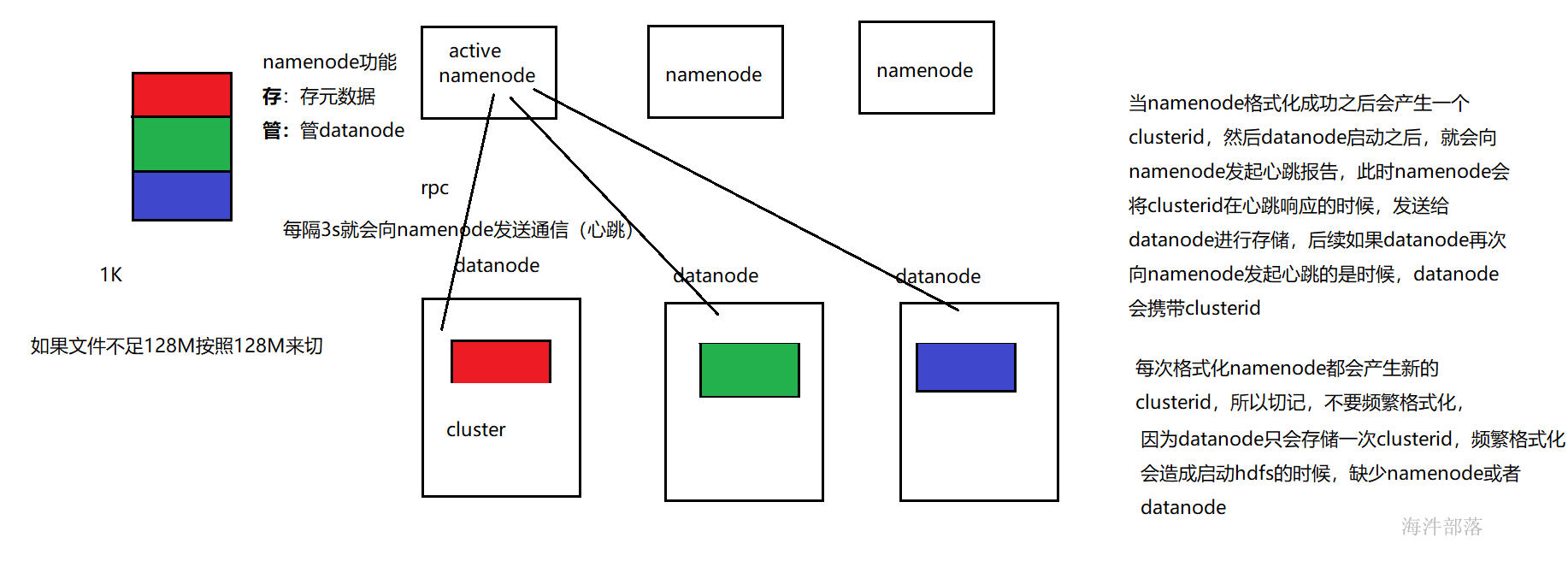
- 数据是切块进行分布式存储的,而每个block块都需要存储在datanode上。
- 我们之前了解到namenode的其中一个作用是存元数据,另外一个作用就是用来管理datanode
- 每隔3sdatanode就会想namenode汇报自身情况,如果超过10min中没有收到datanode的心跳信息,namenode就会认为此datanode丢失了,将其身上的数据拷贝到其他服务器中。
-
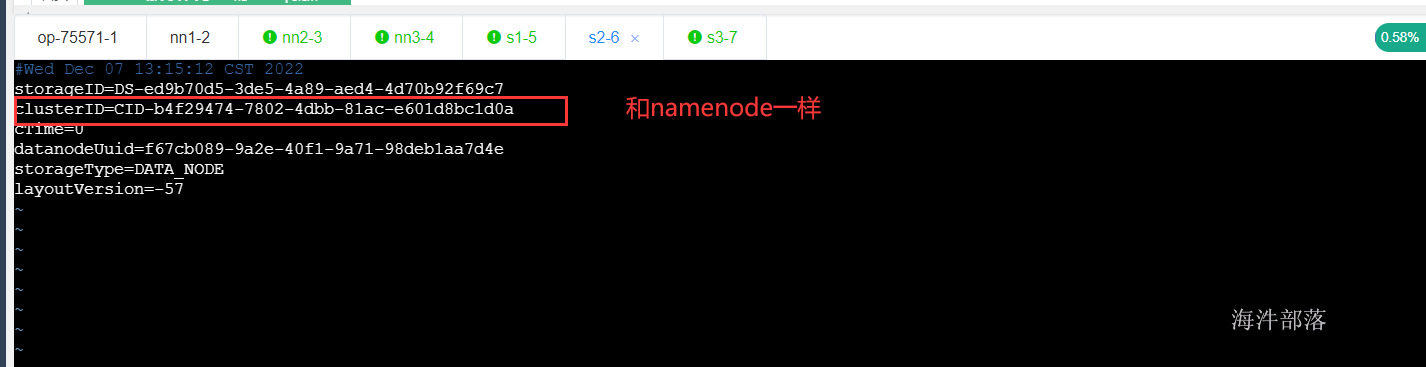
datanode在启动成功之后会接收namenode同步过来的clusterid,之后的通信过程中,datanode都会带着clusterid去和namenode通信,所以切记不要频繁的格式化namenode,因为每一次格式化namenode都会重新产生新的clusterid,造成namenode和datanode起不来的情况出现
-
安装 datanode
修改hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/datanode</value>
<description>datanode本地文件存放地址</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>文件复本数</description>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>true</value>
</property>修改workers

#分发配置文件到各个节点中
scp_all.sh /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/workers /usr/local/hadoop/etc/hadoop/
#启动各个节点的datanode
hadoop-deamons.sh start datanode
到此为止,hdfs所有组件全部启动成功。如果大家和我一样的话,恭喜大家!!!
以后启动可以不用一个一个启,我们可以一起全部启动
# 关闭hdfs的所有进程
stop-dfs.sh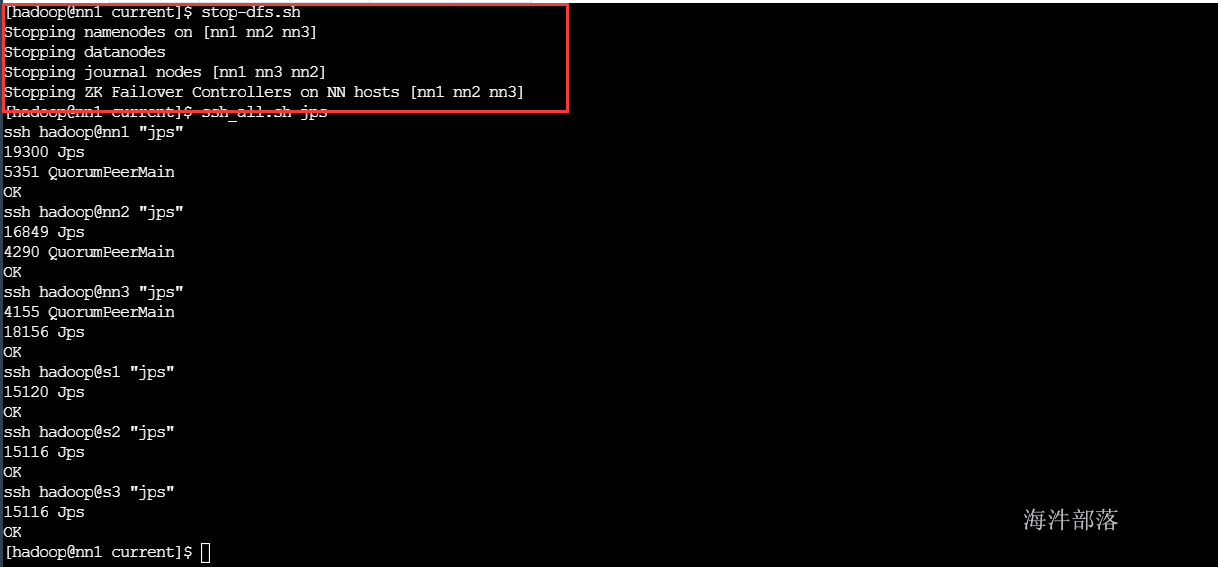
#启动hdfs的所有进程
start-dfs.sh 
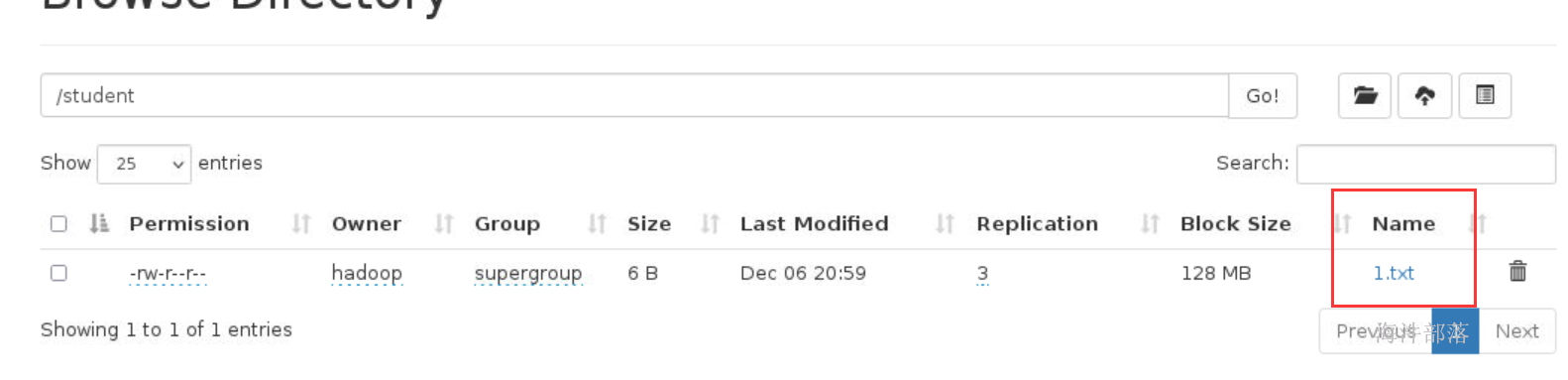
测试向hdfs存储数据
# 在hdfs的根路径创建student目录
hadoop fs -mkdir /student
# 向student目录上传文件 1.txt 是linux本地文件
hadoop fs -put 1.txt /student
datanode数据存储路径:
/data/datanode/current/BP-1353249831-11.94.204.125-1670328197569/current/finalized/subdir0/subdir0
#存储文件
blk_1073741831
#这个blk的信息[大小 创建时间 校验和]
blk_1073741831_1007.meta

总结:
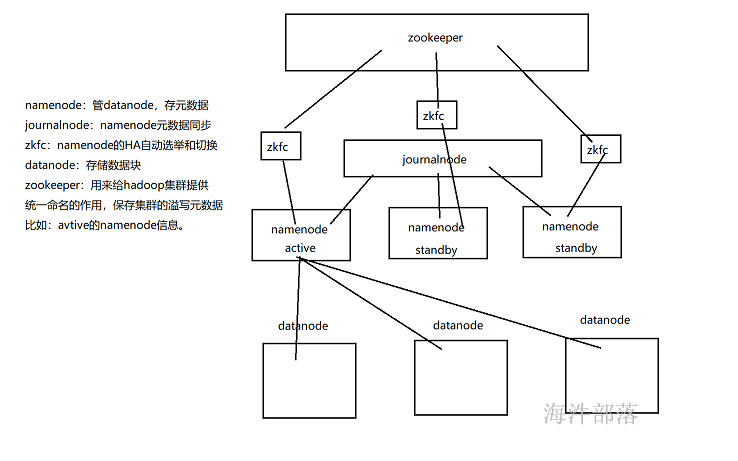
NameNode:用来管理datanode,并用来存储元数据
journalnode:负责两个状态的namenode进行数据同步,保持数据一致。
ZKFC:作用是HA自动切换。会将NameNode的active状态信息保存到zookeeper。
DataNode:负责存储client发来的数据块block;执行数据块的读写操作。
2.6.hdfs的高级配置
core-site.xml中进行配置
#开启本地库对压缩的支持
<property>
<name>io.native.lib.available</name>
<value>true</value>
<description>开启本地库支持</description>
</property>#支持的压缩格式
<property>
<name>io.compression.codecs</name> <value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec</value>
<description>相应编码的操作类</description>
</property>#SequenceFiles在读写中可以使用的缓存大小
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>SequenceFiles在读写中可以使用的缓存大小</description>
</property># 设置mr输入到hdfs中的数据的压缩是按照块压缩
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name>
<value>BLOCK</value>
</property>
# 出入到hdfs中的文件是按照块为一个整体进行压缩
<property>
<name>io.seqfile.compressioin.type</name>
<value>BLOCK</value>
</property># 客户端连接超时时间
<property>
<name>ipc.client.connection.maxidletime</name>
<value>60000</value>
</property>hdfs-site.xml中的配置
# hdfs开启支持文件追加操作
#关闭文件系统权限
#开启垃圾箱,删除的文件不会消失会移除到垃圾箱中
<property>
<name>dfs.support.append</name>
<value>true</value>
<description>是否支持追加</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>是否开启目录权限</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>2880</value>
<description>回收周期</description>
</property># datanode在读写本地文件的时候设置最大机器文件打开数
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>8192</value>
<description>相当于linux下的打开文件最大数量,文档中无此参数,当出现DataXceiver报错的时候,需要调大。默认256</description>
</property># 在hdfs多个节点中数据均衡的时候能够用到的最大系统带宽,防止占用太多带宽
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>104857600</value>
</property># 设置每个机器的磁盘要预留两个G的数据,不能全部都给hdfs使用
# 设置存储的datanode机器的选择策略,优先以机器剩余磁盘存储两个G以上
<property>
<name>dfs.datanode.du.reserved</name>
<value>2147483648</value>
<description>每个存储卷保留用作其他用途的磁盘大小</description>
</property>
<property>
<name>dfs.datanode.fsdataset.volume.choosing.policy</name>
<value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value>
<description>存储卷选择策略</description>
</property>
<property>
<name>dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold</name>
<value>2147483648</value>
<description>允许的卷剩余空间差值,2G</description>
</property># 设置客户端读取数据
# 如果读取数据的客户端和datanode在同一个机器上那么可以直接从本地读取数据,不需要走远程IO
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/data/dn_socket_PORT</value>
</property>#复制以上内容到core-site.xml和hdfs-site.xml中
#将这个文件分发到不同的机器中
scp_all.sh /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/core-site.xml /usr/local/hadoop/etc/hadoop/
#重启集群
stop-dfs.sh
start-dfs.sh3 HDFS命令
3.1 配置操作机

hadoop集群在正常公司集群部署的时候我们是不能直接使用的,这也是为了集群安全来考虑,所以需要一个操作机去代理我们将请求发送到hadoop集群。
这就需要让操作机能够识别我们的操作命令。需要给操作机配置相应的环境
#进入op机器,并且创建hadoop用户
useradd hadoop
#设置hadoop密码
passwd hadoop
#使用root用户解压hadoop到/usr/local下面
tar -zxvf /public/software/bigdata/hadoop-3.1.4.tar.gz -C /usr/local
#删除原来的软连接
#使用root用户创建软连接
rm -rf /usr/local/hadoop
ln -s /usr/local/hadoop-3.1.4/ /usr/local/hadoop
#删除hadoop的配置文件
rm -rf /usr/local/hadoop/etc/hadoop/*
# 将nn1配置好的配置文件放入到op机中
scp -r root@11.237.80.38:/usr/local/hadoop/etc/hadoop/ /usr/local/hadoop/etc/hadoop/* 
# 修改hadoop文件夹的权限给hadoop用户使用
chown hadoop:hadoop -R /usr/local/hadoop-3.1.4/
# 切换用户,配置环境变量
su - hadoop
vim ~/.bash_profile
#增加如下配置
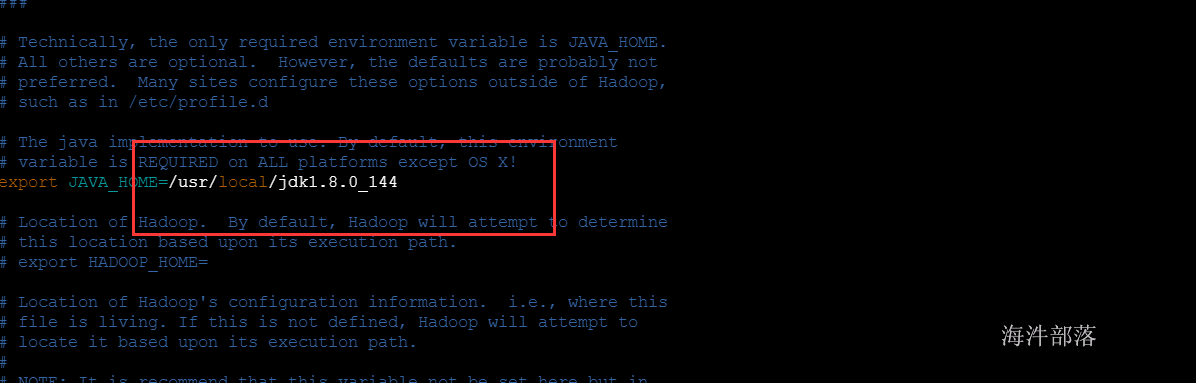
export JAVA_HOME=/usr/local/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# source配置文件生效
source ~/.bash_profile
测试操作机好不好用

3.2 hdfs常用命令
1) 查看hdfs根目录
# 标准写法
hadoop fs -ls hdfs://ns1/
# 简写(推荐)
hadoop fs -ls /
# -h:文件大小显示为最大单位,更加人性化
hadoop fs -ls -h /
# -R:递归显示
hadoop fs -ls -R / 
2) 上传文件/目录 put
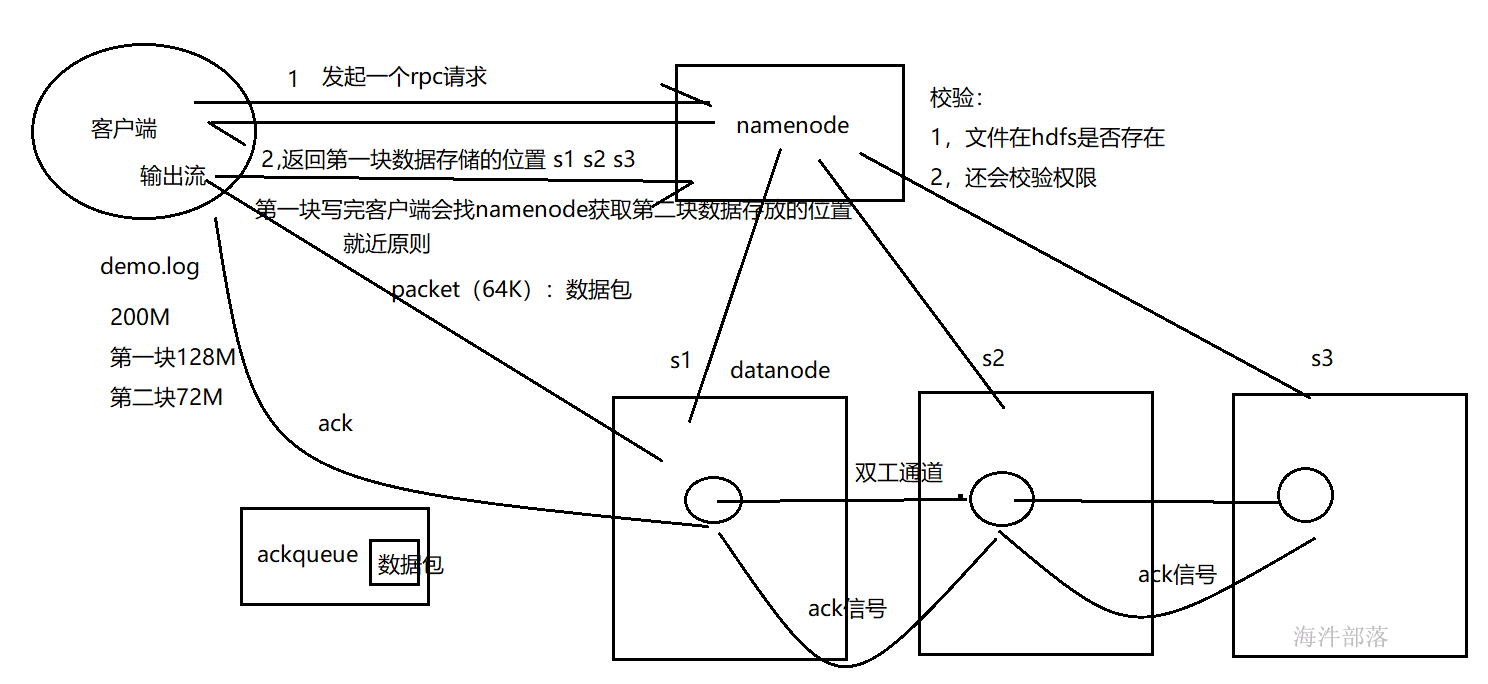
hdfs的写流程:
#创建本地文件
echo hello wuyifan >> ~/demo.txt
#标准写法:put 左面:是本地,右面是hdfs集群
hadoop fs -put ~/demo.txt hdfs://ns1/
#简写:右面默认找hdfs (推荐)
hadoop fs -put ~/demo.txt /
#当上传时要对文件进行重名
hadoop fs -put ~/demo.txt /demo1.txt
#在本地创建多个文件
echo 'hello' >> a.txt
echo 'world' >> b.txt
#一次上传多个文件到HDFS路径
hadoop fs -put a.txt b.txt /
#上传目录
mkdir ceshi
cd ceshi
touch aa.txt
touch bb.txt
hadoop fs -put ceshi /
# -f覆盖上传
hadoop fs -put -f demo.txt /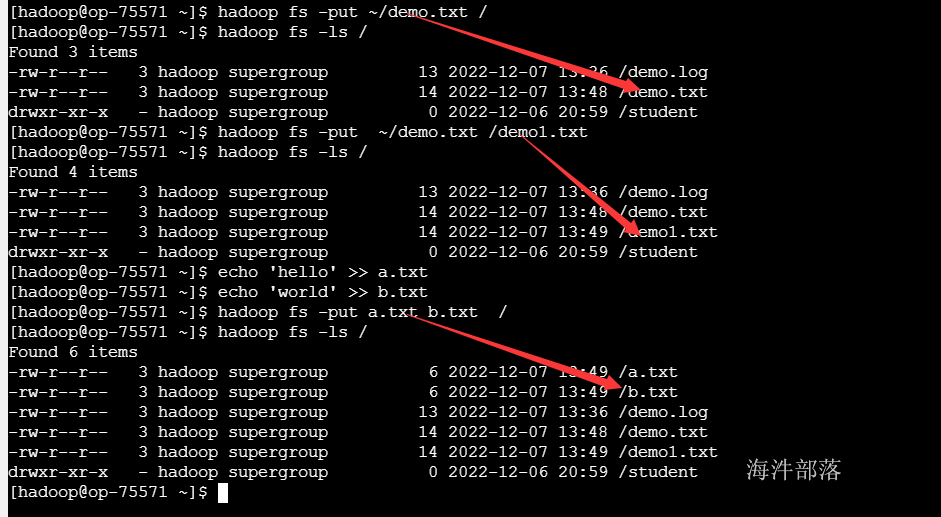

3) 读取文件 cat
HDFS的读流程

#如果文件太大,不要用cat读取文件
hadoop fs -cat /data/demo.log4) 下载文件/目录 get
#下载hdfs文件到本地目录
hadoop fs -get /demo.txt ./
#下载hdfs文件到本地目录并重命名
hadoop fs -get /demo.txt ./nihao.txt
5) 拷贝文件/目录 cp
# 创建新的文件
touch word.txt
# 上传本地文件使用file:开头
hadoop fs -cp file:/home/hadoop/word.txt /
# 查看上传
hadoop fs -ls /
# 从hdfs进行拷贝
hadoop fs -cp /demo.txt /ceshi
# 查询
hadoop fs -ls /ceshi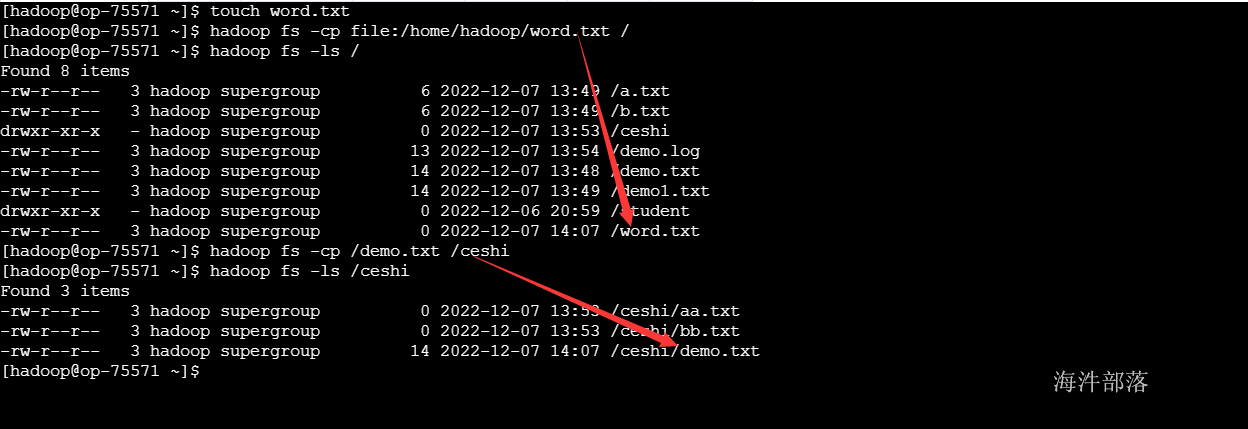
6) 剪切文件 mv
#剪切
hadoop fs -mv /b.txt /ceshi
#查询
hadoop fs -ls /
hadoop fs -ls /ceshi
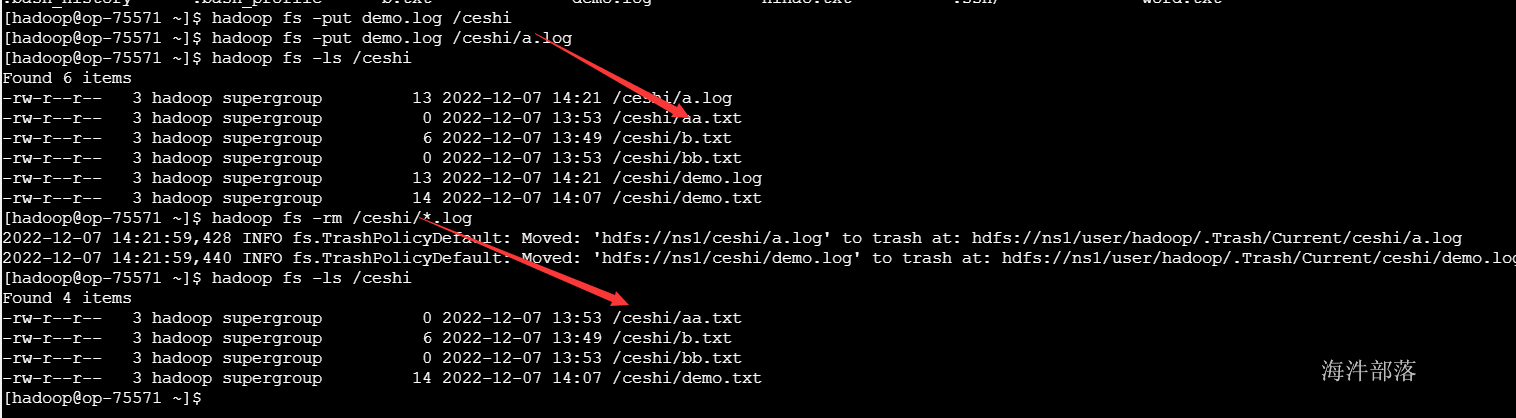
7)删除文件/目录 rm
执行-rm 命令后,默认是把文件移动到 user/hadoop/.Trash/Current 下,会根据配置文件配置的清理周期定期清理。
#删除文件
hadoop fs -rm /demo.txt
#匹配模式删除所有文件
hadoop fs -ls /ceshi
hadoop fs -rm /ceshi/*.log
#报错 rm只能删除文件
hadoop fs -rm /ceshi
#强制删除,并且递归删除文件夹中的内容
hadoop fs -rmr /ceshi
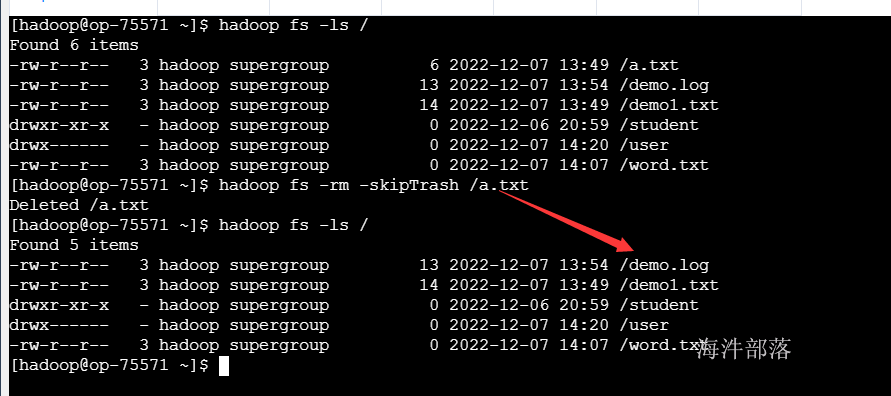
#删除之后不放到回收站
hadoop fs -rm -skipTrash /a.txt

8)创建空文件 touchz
hadoop fs - touchz /aa.txt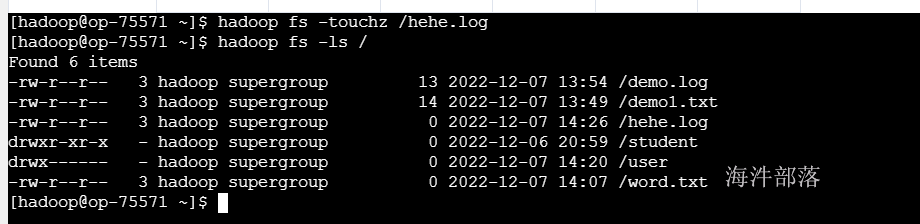
9) 创建目录 mkdir
#可以同时创建多个目录
hadoop fs -mkdir /tmp1 /tmp2
#同时创建父级目录
hadoop fs -mkdir -p /dir1/dir2/dir3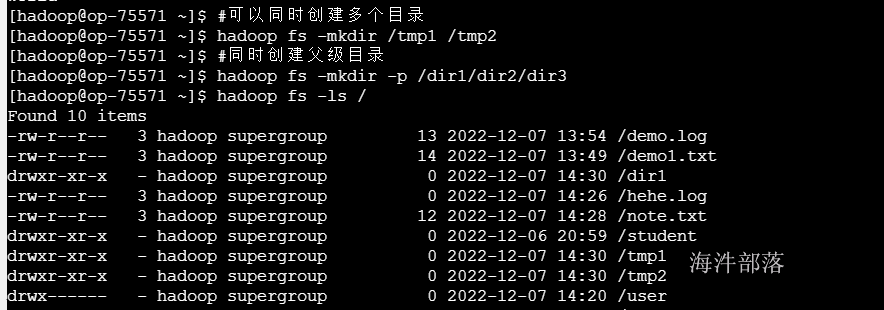
10) 读取文件尾部 tail**
#查看尾部1K字节
hadoop fs -tail /demo1.txt
11) 追加写入文件 appendToFile
#本地创建文件 note.txt
touch note.txt
#写入hello
echo 'hello' >> note.txt
#本地创建文件 new.txt
touch new.txt
#写入world
echo 'world' >> new.txt
#将note.txt上传到hdfs中
hadoop fs -put note.txt /
#将new.txt的内容追加到node.txt中
hadoop fs -appendToFile new.txt /note.txt
12 获取逻辑空间文件/目录大小 du
#显示HDFS根目录中各文件和文件夹大小
hadoop fs -du /
#以最大单位显示HDFS根目录中各文件和文件夹大小
hadoop fs -du -h /
#仅显示HDFS根目录大小。即各文件和文件夹大小之和
hadoop fs -du -s -h /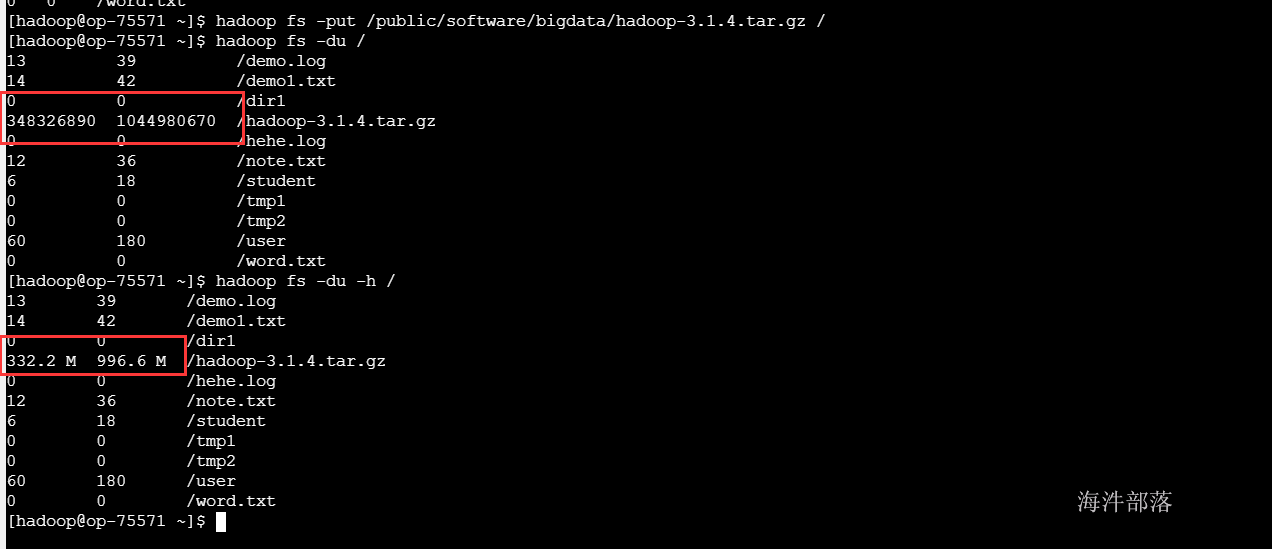

13 改变文件副本数 setrep
#-R 递归改变目录下所有文件的副本数。
#-w 等待副本数调整完毕后返回。可理解为加了这个参数就是阻塞式的了。
hadoop fs -setrep -R -w 2 /demo.txt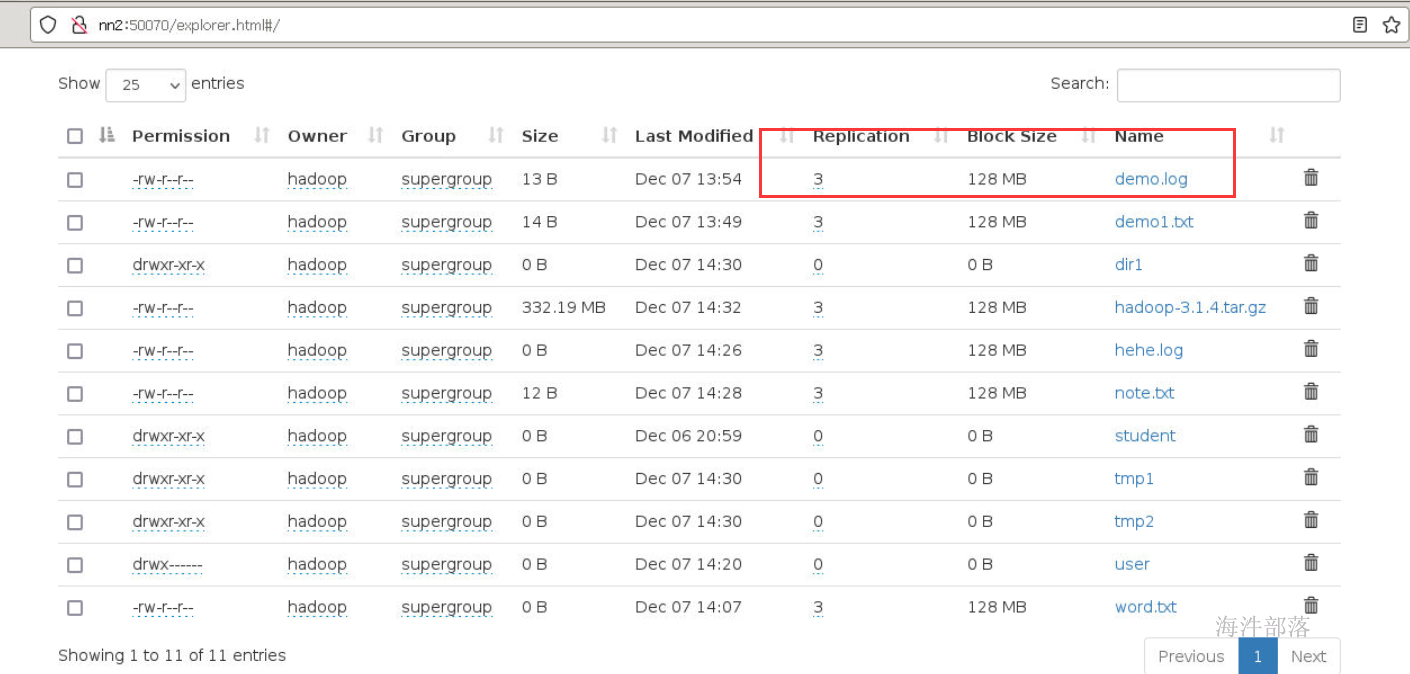
修改之后


14 ) 获取HDFS目录的物理空间信息 count
hadoop fs -count / #显示HDFS根目录在物理空间的信息
3.3 hdfs高级命令
hdfs dfsadmin**
例如:hadoop dfsadmin -report
dfsadmin命令详解
1) -report:
查看文件系统的基本信息和统计信息。
2)-safemode :
安全模式命令。安全模式是NameNode的一种状态,在这种状态下,NameNode不接受对元数据的更改(只读);不复制或删除块。NameNode在启动时自动进入安全模式,当配置块的最小百分数满足最小副本数的条件时,会自动离开安全模式。enter是进入,leave是离开 。
#进入安全模式
hadoop dfsadmin -safemode enter
#离开安全模式
hadoop dfsadmin -safemode leave
#获取安全模式信息
hadoop dfsadmin -safemode get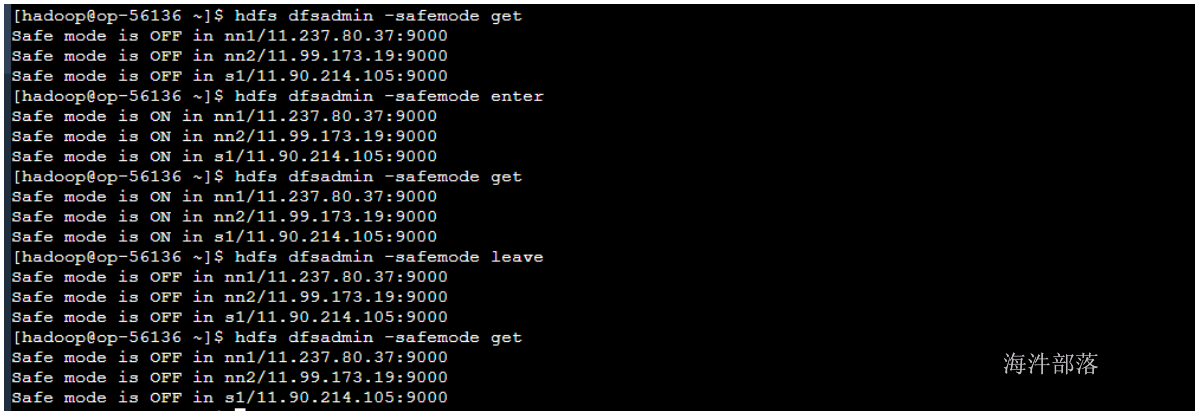
在安全模式情况下不允许任何hdfs的修改操作的

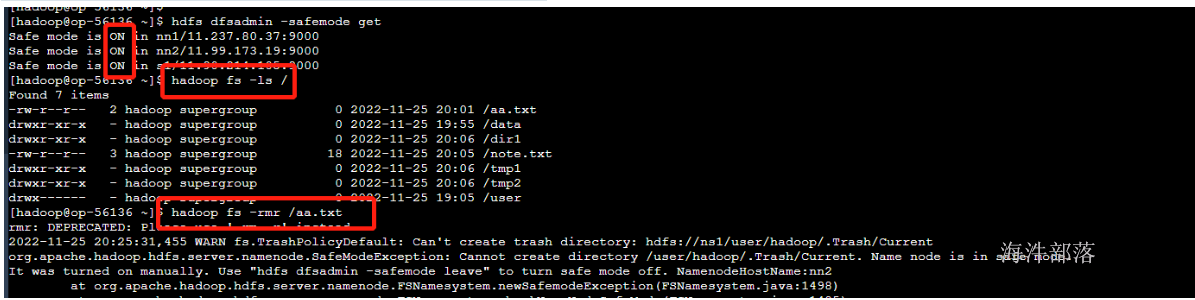
安全模式下可以查询元数据信息,但是不能对文件做任何的修改
4 Fsimage和Edits文件详解
1) 首先我们看一下两个文件存放的目录/data/namenode/current
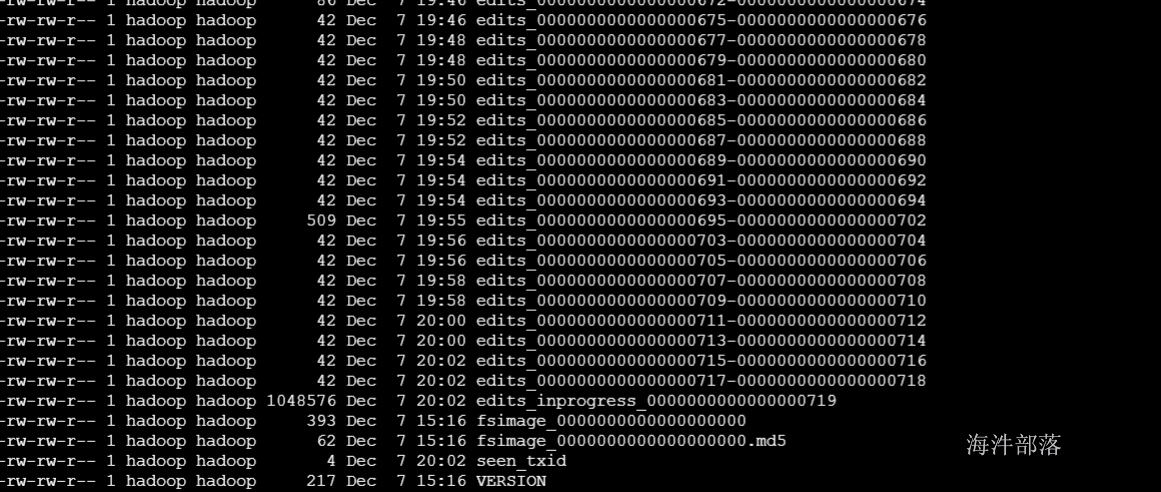
2) VERSION是java属性文件,内容大致如下:
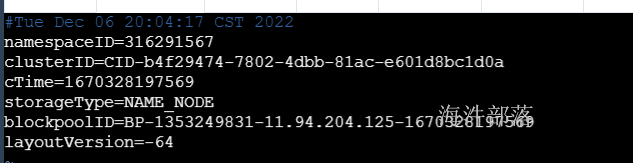
- namespaceID是文件系统唯一标识符
- clusterID是系统生成或手动指定的集群ID
- cTime表示Namenode存储的创建时间
- storageType表示这个文件存储的是什么进程的数据结构信息
- blockpoolID表示每一个namenode对应的块池id,这个id包括了其对应的Namenode节点的ip地址。
- layoutVersion表示HDFS永久性数据结构的版本信息,只要数据结构变更,版本号也要递减
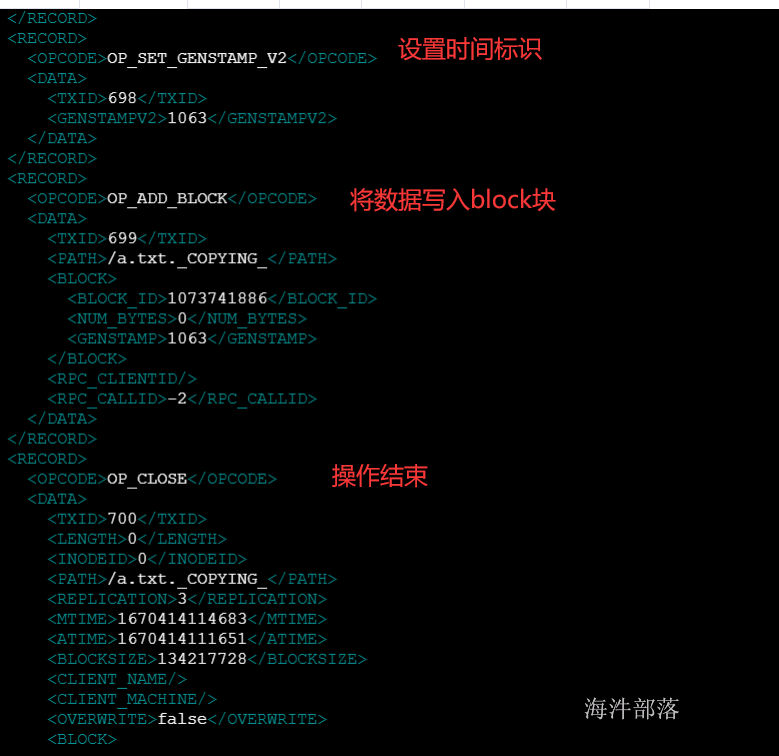
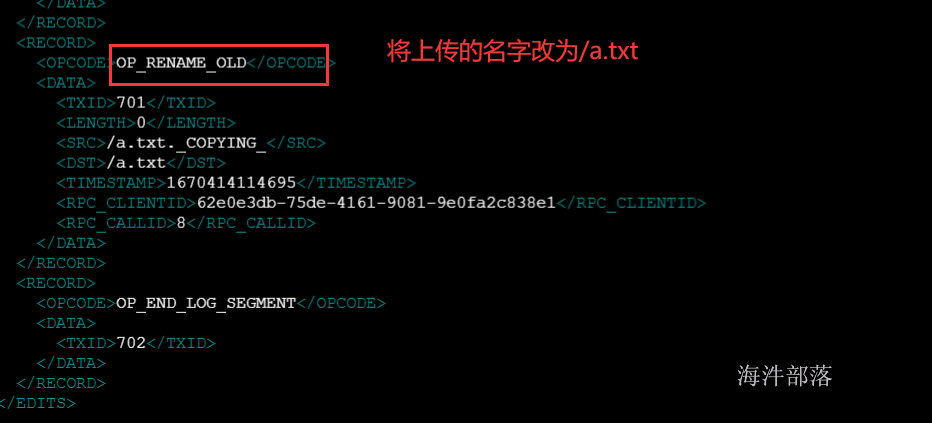
*3)edits_文件**
edits文件中存放的是客户端执行的所有更新命名空间的操作。
# hdfs oev 解析操作日志文件并且输入到相应的目录中 -i 输入 -o 输出 -p 默认就是xml
hdfs oev -i edits_0000000000000000138-0000000000000000145 -o ~/edits.txt
#查看edits文件
vim ~/edits.txt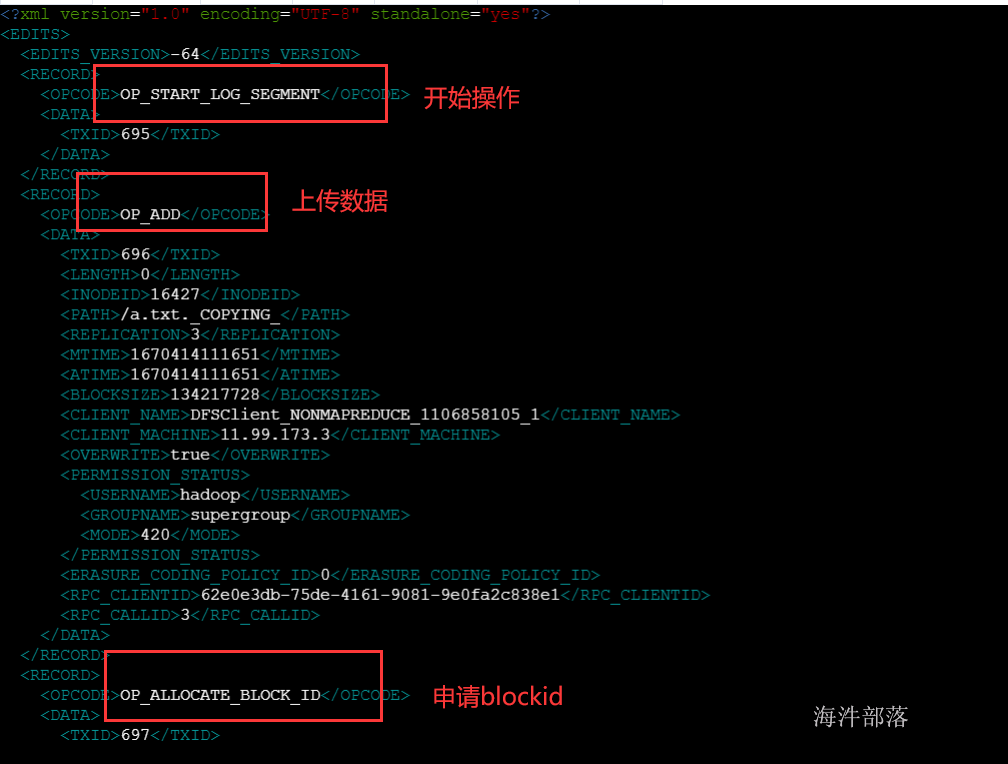
4) seen_txid文件
这个文件中保存了一个事务id,这个事务id并不是Namenode内存中最新的事务id。这个文件的作用在于Namenode启动时,利用这个文件判断是否有edits文件丢失,Namenode启动时会检查seen_txid并确保内存中加载的事务id至少超过seen_txid,否则Namenode将终止启动操作。
*5) fsimage_文件**
#先进入安全模式
hadoop dfsadmin -safemode enter
#首先我们手动触发合并元数据
hadoop dfsadmin -saveNamespace
#然后将fsimage数据导出到文本中
hdfs oiv -i fsimage_0000000000000000024 -o ~/fs.xml -p xmlfs.xml里面有
- version:version描述的一些版本信息
- NameSection:描述的是命名空间的一些信息
- ErasureCodingSection:纠删码
- INodeSection:INodeSection 由一段一段inode组成,是image中内容最大部分,除了上述的几个片段,image中剩下的内容全部都是inode。
*6) fsimage_.md5文件**
md5校验文件,用于确保fsimage文件的正确性,可以作用于磁盘异常导致文件损坏的情况。
5 扩容datanode节点
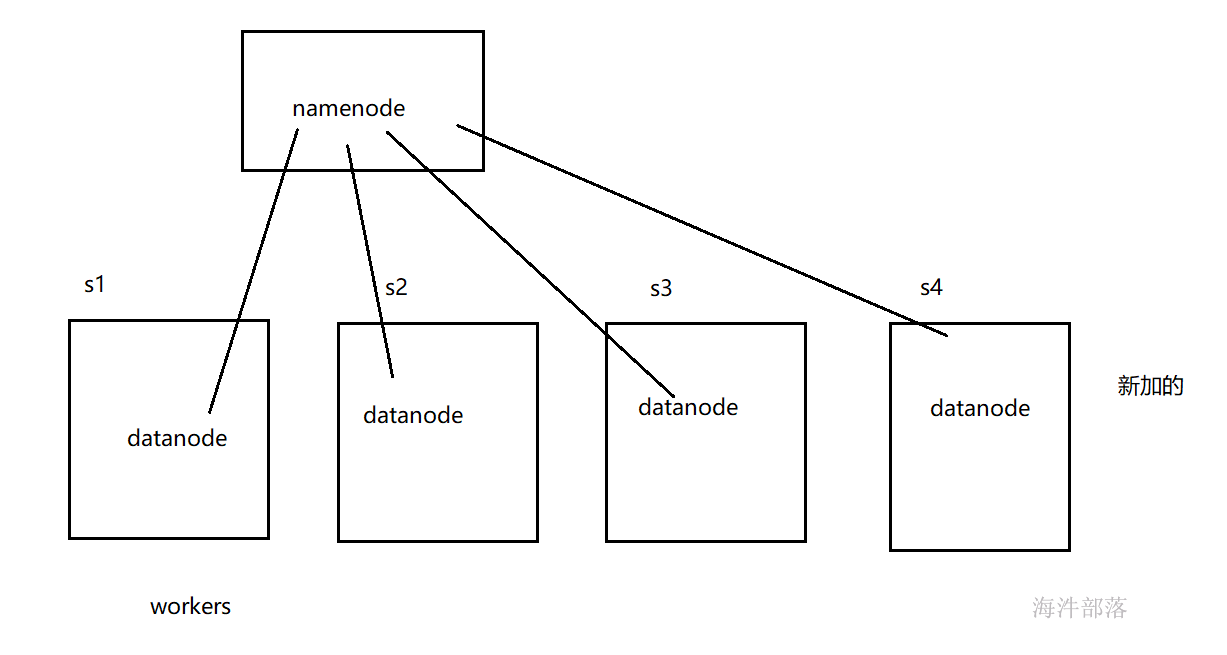
当磁盘容量不够的时候需要对集群进行动态扩容,还不能停止先有集群正常工作,怎么办呢?
动态增加一个或者多个服务器
1) 连接新的服务器

2) 创建hadoop用户并设置密码
useradd hadoop
#密码输入12345678
passwd hadoop3)安装jdk
rpm -ivh /public/software/java/jdk-8u144-linux-x64.rpm
4) 配置s4的主机名
vim /etc/hostname
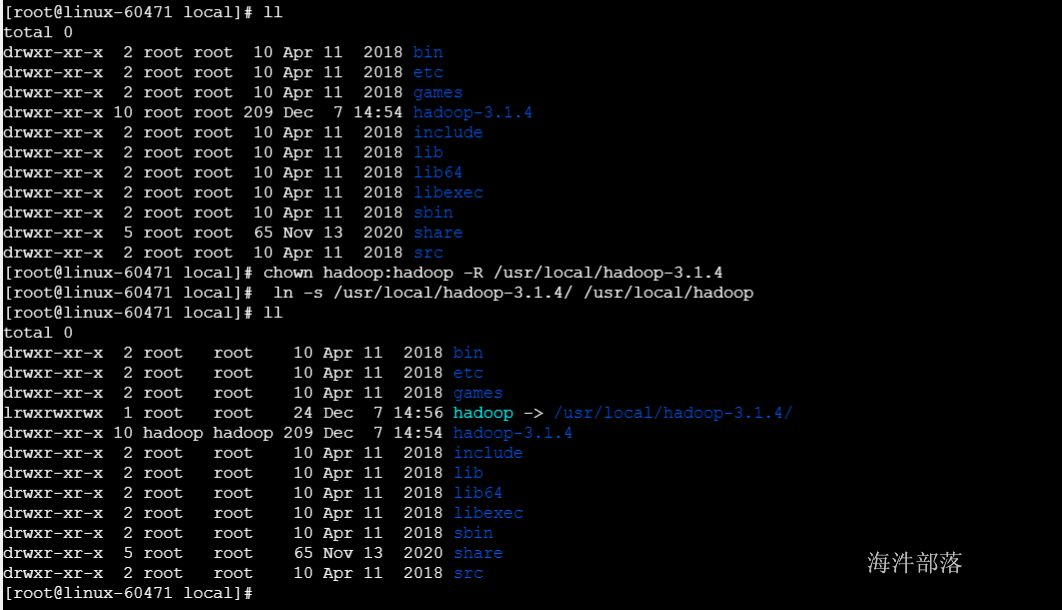
5) 将s3上的hadoop安装目录传输到s4上,并配置软连接
scp -r hadoop@s3:/usr/local/hadoop-3.1.4 /usr/local/
#修改所有者和属组
chown hadoop:hadoop -R /usr/local/hadoop-3.1.4
#创建软连接
ln -s /usr/local/hadoop-3.1.4/ /usr/local/hadoop
6) 将环境变量文件也拷贝一份
scp -r root@s3:/etc/profile /etc/
source /etc/profile
7) 修改/data目录所有者和属组
chown hadoop:hadoop /data
8) 修改 hosts文件

9) 修改其他服务器,添加s4节点的映射
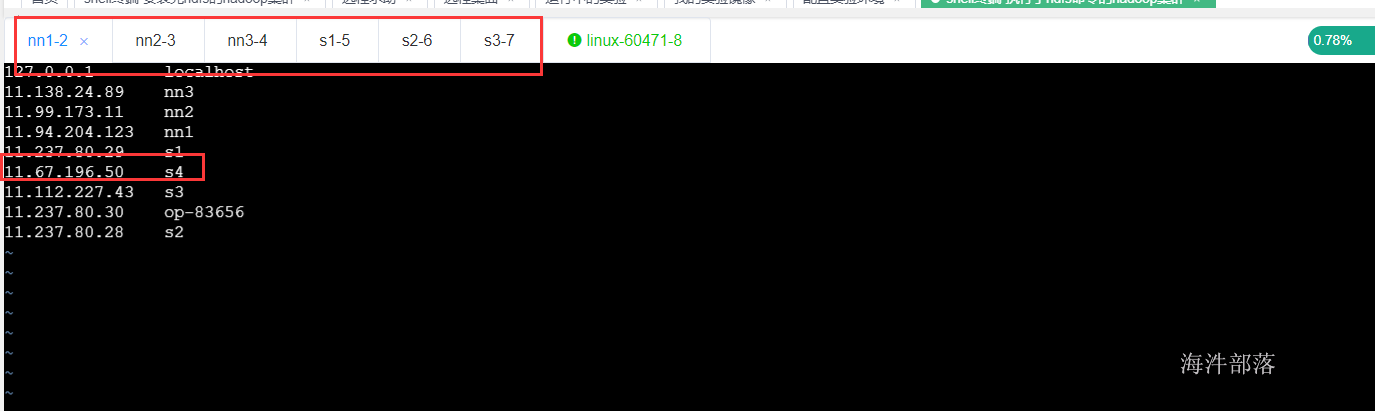
10) 配置s4和其他服务器免密码登录
scp -r hadoop@s3:/home/hadoop/.ssh /home/hadoop/测试免密码登录是否好使

11)给workers文件添加s4
#所有节点执行
echo s4 >> /usr/local/hadoop/etc/hadoop/workers 12) 在新增的s4节点启动datanode

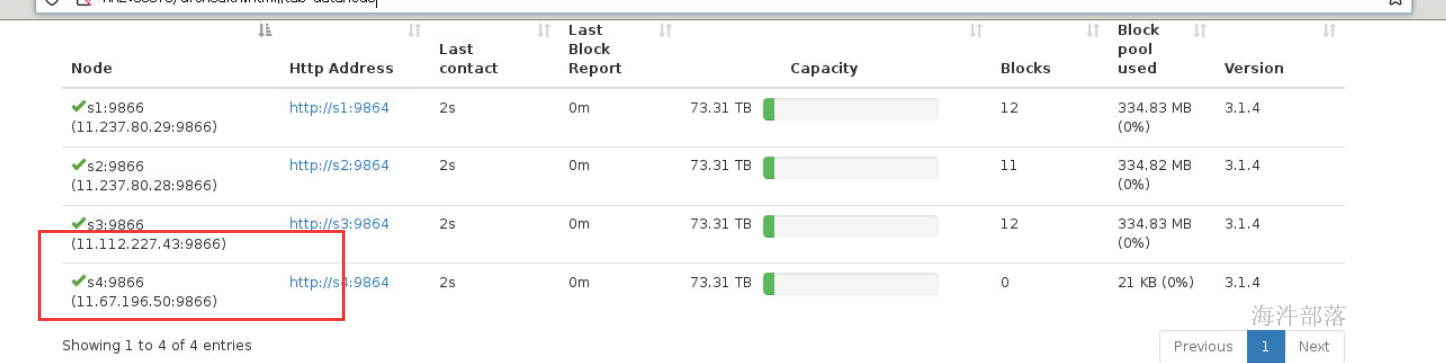
6 datanode下线

为了保证能够识别新创建的节点s4我们关闭环境,重新启动实验
先生成镜像然后重新启动
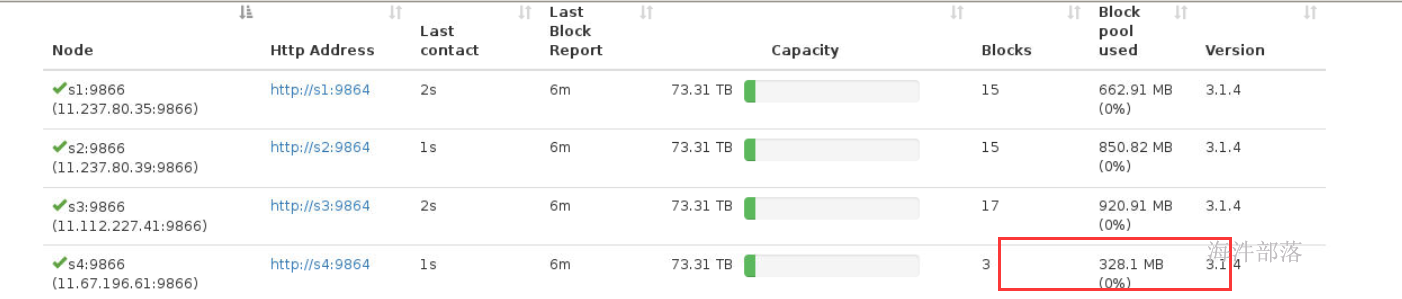
准备一个大文件上传到hdfs上


接下来删除s4节点 需要修改hdfs-site.xml,将要删除的节点配置在文件中,然后配置文件的路径
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/excludes</value>
</property>

将配置文件分发到各个机器节点中
scp_all.sh /usr/local/hadoop/etc/hadoop/excludes /usr/local/hadoop/etc/hadoop/excludes
scp_all.sh /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hadoop/etc/hadoop/#在nn1节点输入
hadoop dfsadmin -refreshNodes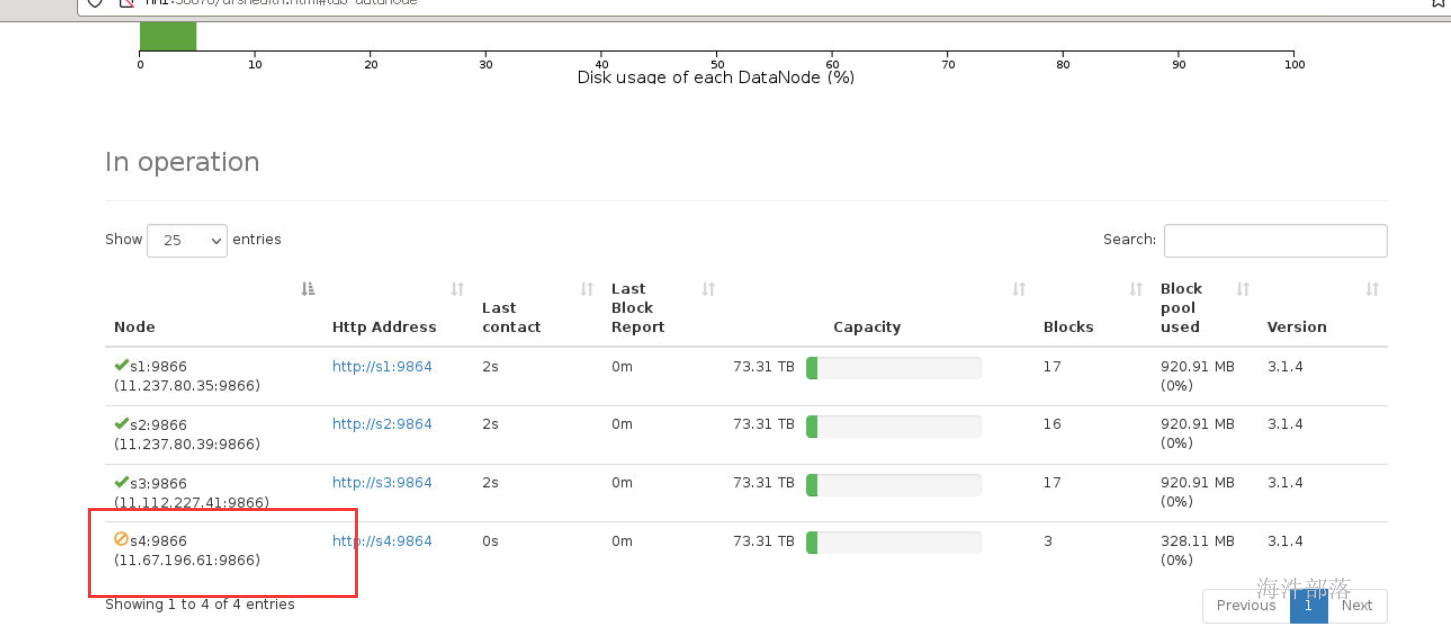
s4上面的数据迁移到了其他节点上,此时s4下线成功
后续我们删除 workers中的s4节点,那么下次就不会启动它了

scp_all.sh /usr/local/hadoop/etc/hadoop/workers /usr/local/hadoop/etc/hadoop/
7 hdfs数据负载均衡

Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,例如:当集群内新增、删除节点,或者某个节点机器内硬盘存储达到饱和值。当数据不平衡时,Map任务可能会分配到没有存储数据的机器,这将导致网络带宽的消耗,也无法很好的进行本地计算。
当HDFS负载不均衡时,需要对HDFS进行数据的负载均衡调整,即对各节点机器上数据的存储分布进行调整。从而,让数据均匀的分布在各个DataNode上,均衡IO性能,防止热点的发生。进行数据的负载均衡调整,必须要满足如下原则:
- 数据平衡不能导致数据块减少,数据块备份丢失
- 管理员可以中止数据平衡进程
- 每次移动的数据量以及占用的网络资源,必须是可控的
- 数据均衡过程,不能影响namenode的正常工作
在Hadoop中,包含一个 start-balancer.sh 脚本,通过运行这个工具,启动HDFS数据均衡服务。该工具可以做到热插拔,即无须重启计算机和 Hadoop 服务。
启动命令为:‘start-balancer.sh –threshold`
影响Balancer的参数:
- -threshold
- 默认设置:10,参数取值范围:1-100
- 参数含义:datanode间磁盘使用率相差阈值。理论上,该参数设置的越小,整个集群就越平衡。
#启动数据均衡,默认阈值为 10%
start-balancer.sh
#启动数据均衡,阈值 5%
start-balancer.sh -threshold 5
#停止数据均衡
stop-balancer.sh<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>104857600</value>
<description>根据每秒字节数指定每个数据节点可用于平衡的最大带宽,设置为100M</description>
</property>为了演示效果,上传一些大文件
在集群中上传hadoop的安装包
hdfs dfs -put /public/software/bigdata/hadoop-3.1.4.tar.gz /
复制多分文件
cp /public/software/bigdata/apache-dolphinscheduler-3.1.0-bin.tar.gz ./do1
#然后赋值翻倍数据
cp do1 do2
cp do1 do3
cp do1 do4
cp do1 do5
cp do1 do6
cp do1 do7
cp do1 do8
#在hdfs创建/test测试目录
hadoop fs -mkdir /test
#将数据存放到/test目录下
hadoop fs -put do1 do2 do3 do4 do5 do6 do7 do8 /test将s4节点增加进来
将之前excludes文件中s4删除掉,修改workers文件添加s4节点
#删除里面的s4
vim /usr/local/hadoop/etc/hadoop/excludes
echo "s4" >> /usr/local/hadoop/etc/hadoop/workers 
文件分发
scp_all.sh /usr/local/hadoop/etc/hadoop/excludes /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/workers /usr/local/hadoop/etc/hadoop/刷新集群
hadoop dfsadmin -refreshNodes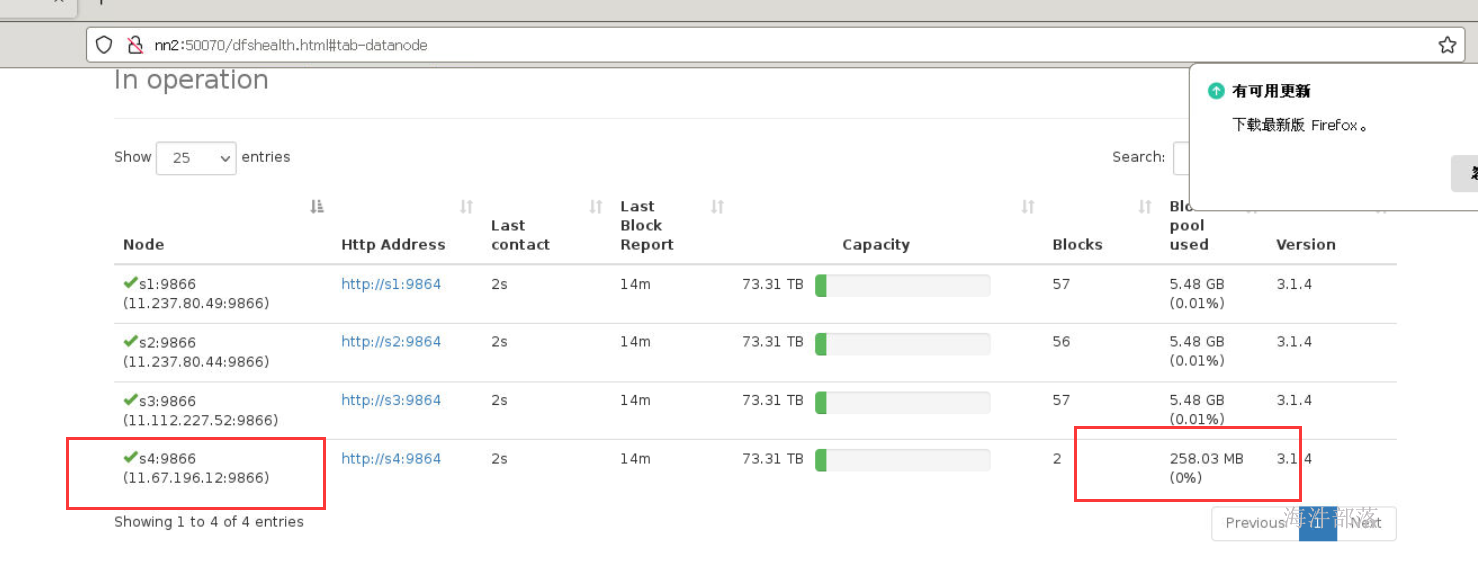
此时我们进行数据的负载均衡
首先先降低hdfs使用磁盘的容量,默认73T的容量,测试负载均衡比较困难
#每个节点预留内存是73T,剩余100G
<property>
<name>dfs.datanode.du.reserved</name>
<value>80484251153203</value>
<description>每个存储卷保留用作其他用途的磁盘大小</description>
</property>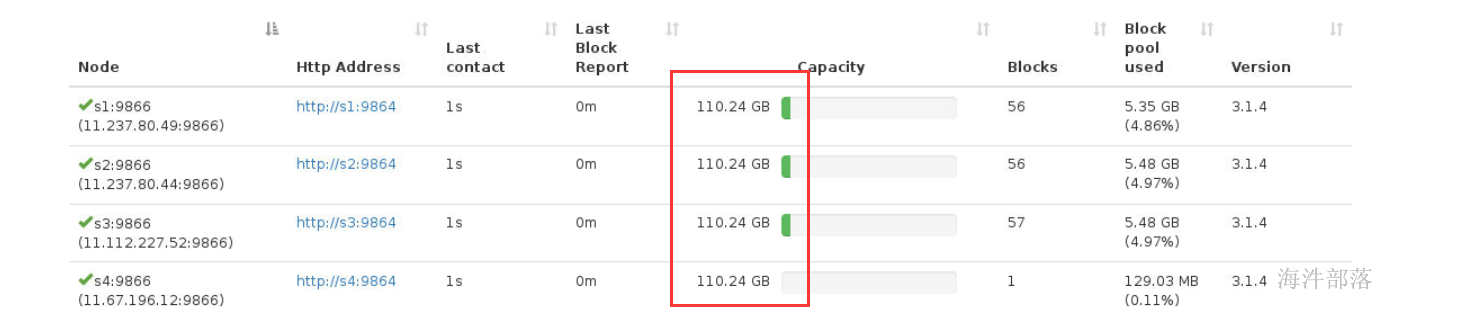
影响Balancer的参数:
- -threshold
- 默认设置:10,参数取值范围:1-100
- 参数含义:datanode间磁盘使用率相差阈值。理论上,该参数设置的越小,整个集群就越平衡
start-balancer.sh -threshold 1此时会发现s4数据量越来越多,数据也变得越来越均衡

8 机架感知策略
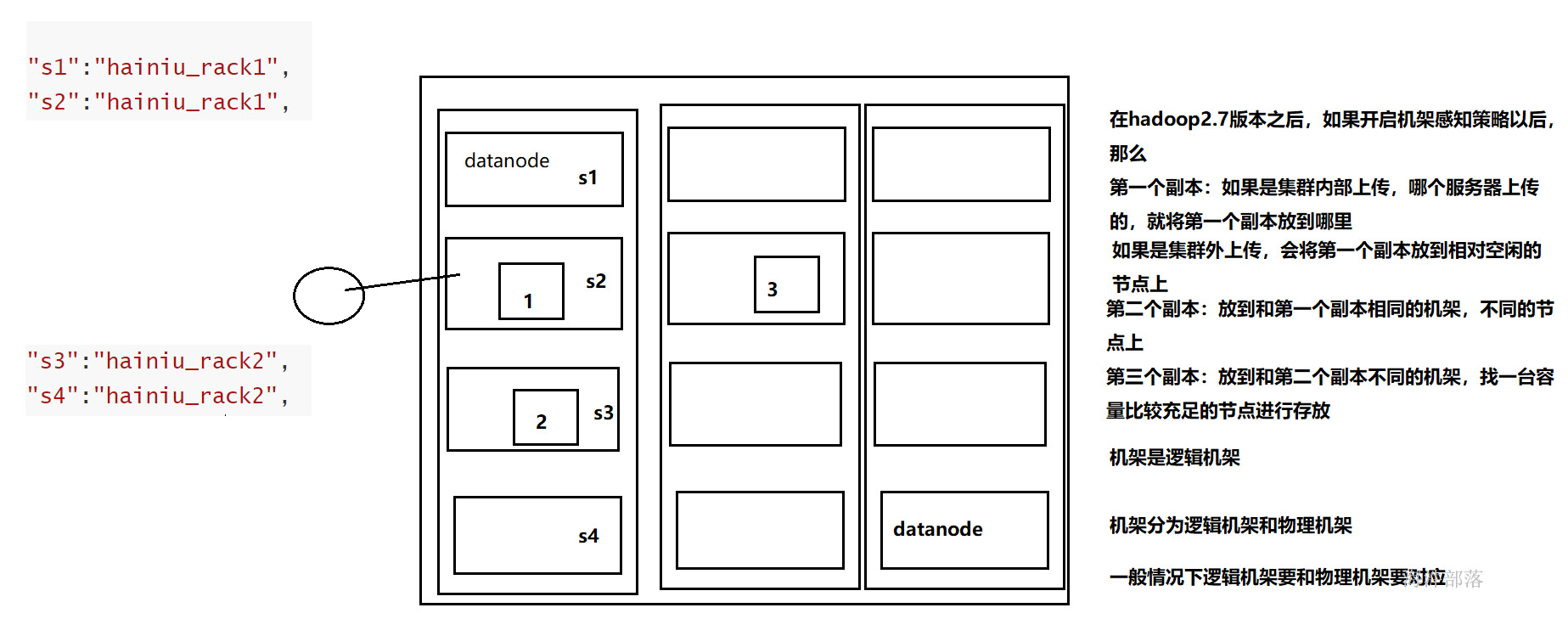
我们这里说的机架式逻辑机架而不是物理机架,但是在真正配置的时候,一般逻辑机架,要和物理机架相对应
默认情况下,Hadoop机架感知是没有启用的,需要在NameNode机器的hdfs-site.xml里配置一个选项,例如:
<property>
<name>topology.script.file.name</name>
<value>/usr/local/hadoop/etc/hadoop/tp.py</value>
</property>其中:
这个配置选项的 value 指定为一个可执行程序,通常为一个脚本,可以是shell脚本或者python脚本。
接受的参数通常为 datanode 机器的 ip 地址,而输出的值通常为该ip地址对应的 datanode 所在的rackID,例如”/rack1”。
Namenode 启动时,会判断该配置选项是否为空,如果非空,则表示已经启用机架感知的配置,此时 namenode 会根据配置寻找该脚本,并在接收到每一个 datanode 的 heartbeat 时,将该 datanode 的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode 所属的机架,保存到内存的一个map中。
至于脚本的编写,就需要将真实的网络拓朴和机架信息了解清楚后,通过该脚本能够将机器的ip地址正确的映射到相应的机架上去。
当没有配置机架信息时,所有的datanode,hadoop都默认在同一个名为 “/default-rack”机架下。
# 编辑to.py文件,因为官网没有指出到底是根据ip还是hostname进行判断机架
# 所以我们都配置 如下在tp.py中
#!/usr/bin/python
#-*-coding:UTF-8 -*-
import sys
rack = {
"s1":"hainiu_rack1",
"s2":"hainiu_rack1",
"s3":"hainiu_rack2",
"s4":"hainiu_rack2",
"11.237.80.49":"hainiu_rack1",
"11.237.80.44":"hainiu_rack1",
"11.112.227.52":"hainiu_rack2",
"11.67.196.12":"hainiu_rack2"
}
if __name__=="__main__":
print "/" + rack.get(sys.argv[1],"rack0")以上的内容根据/etc/hosts中的内容配置
这个时候在集群需要得到机器的远近的时候就可以通过传入ip或者hostname进行判断
#增加执行权限
ssh_all.sh chmod +x /usr/local/hadoop/etc/hadoop/tp.py
#输入命令打印机架感知
hadoop dfsadmin -printTopology重启hdfs之后查看


