1 数据类型
1.1 基本类型
| 数据类型 | 大小 | 范围 | 示例 |
|---|---|---|---|
| TINYINT | 1byte | -128 ~ 127 | 100Y |
| SMALLINT | 2byte | -32,768 ~ 32,767 | 100S |
| INT/INTEGER | 4byte | -2,147,483,648 ~ 2,147,483,647 | 100 |
| BIGINT | 8byte | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | 100L |
| FLOAT | 4byte | 单精度浮点数 | 3.1415926 |
| DOUBLE | 8byte | 双精度浮点数 | 3.1415926 |
| DECIMAL | - | 高精度浮点数 | DECIMAL(9,8) |
| BOOLEAN | - | 布尔型,TRUE/FALSE | true |
| BINARY | - | 二进制类型 | - |
1.1.1数字类型
整数类型
-2,147,483,648 ~ 2,147,483,647之间的整数类型默认是INT型,除非指定了格式100Y、100S、100L会自动转换为TINYINT、SMALLINT、BIGINT
浮点数类型
浮点数默认会当作DOUBLE型;
Hive中的DECIMAL基于Java中的BigDecimal,DECIMAL不指定精度时默认为DECIMAL(10,0);
1.1.2 字符串类型
string (后面常用string)
类型可以用单引号(')或双引号(")定义,这个类型是以后我们定义字符串的常用类型。
varchar
varchar类型由长度定义,范围为1-65355,如果存入的字符串长度超过了定义的长度,超出部分会被截断。
尾部的空格也会作为字符串的一部分,影响字符串的比较。
char
char是固定长度的,最大长度255,而且尾部的空格不影响字符串的比较。
三种类型对尾部空格的区别,参考如下例子,每个字段都插入同样的字符并且在尾部有不同的空格。
示例:
--建表
create table char_a (
c1 char(4),
c2 char(5),
str1 string,
str2 string,
var1 varchar(4),
var2 varchar(6));
--插入数据
insert into char_a values('ccc ','ccc ','ccc ','ccc ','ccc ','ccc ');
--查询
select c1=c2,str1=str2,var1=var2 from char_a;测试结果

1.1.3 日期与时间戳
timestamp
timestamp表示UTC时间,可以是以秒为单位的整数;带精度的浮点数,最大精确到小数点后9位,纳秒级;java.sql.Timestamp格式的字符串 YYYY-MM-DD hh:mm:ss.fffffffff
Date
Hive中的Date只支持YYYY-MM-DD格式的日期,其余写法都是错误的,如需带上时分秒,请使用timestamp。
示例:
--建带有timestamp格式字段的表
create table time_dual1(time timestamp);
--插入一个数据(一个数据占一个文件)
insert into table time_dual1 values('2017-06-01 10:30:49.223');
--建带有date格式字段的表
create table date_dual(d date);
--插入一个数据(一个数据占一个文件)
--虽然命令没报错,但只数据写入年月日。
insert into table date_dual values('2017-05-31 12:18:48.807');
--将日期覆盖插入的date_dual(将目录下的所有都删掉,再写入)
insert overwrite table date_dual values('2017-05-31');获取当前timestamp:
current_timestamp() --返回值: timestamp
获取当前日期:
current_date() --返回值:date
格式化timestamp/date/string 为字符串:
date_format(date/timestamp/string ts, string fmt)
--返回值:字符串 示例:
--当前日期格式化
select date_format(current_date(),'yyyy-MM-dd HH:mm:ss');
--当前时间格式化
select date_format(current_timestamp(), 'yyyy-MM-dd HH:mm:ss');
--字符串格式化
select date_format('2018-01-30 14:23:40', 'yyyy-MM-dd');
Unix时间戳:
从1970-01-01 00:00:00 UTC到指定时间的秒数,例如:1530752400
【当前时间或时间字符串】 转 【Unix时间戳】
--获取当前timestamp的Unix时间戳
select unix_timestamp(current_timestamp);
--获取指定字符串的Unix时间戳
select unix_timestamp('2018-07-05 09:00:00');测试结果

【Unix时间戳】转【时间字符串】
from_unixtime(bigint unixtime[, string format])
--unixtime:从1970-01-01 00:00:00 UTC到指定时间的秒数
--format:目标转换格式
--返回值: string
--说明: 转化UNIX时间戳(从1970-01-01 00:00:00 UTC到指定时间的秒数)到当前时区的时间格式示例:
--转换成 yyyy-MM-dd HH:mm:ss
select from_unixtime(1530755469);
--转换成指定格式的字符串
select from_unixtime(1530755469, "yyyy-MM-dd");测试结果

1.2 复杂类型
STRUCT
STRUCT类似于java的类变量使用,Hive中定义的struct类型也可以使用点来访问。从文件加载数据时,文件里的数据分隔符要和建表指定的一致。
struct(val1, val2, val3, ...) ,只有字段值;
named_struct(name1, val1, name2, val2, ...),带有字段名和字段值;一般用struct都是带有 字段名和字段值
ARRAY 相当于java的数组,通过arr[下标] 获取元素数据
ARRAY表示一组相同数据类型的集合,下标从零开始,可以用下标访问。如:arr[0]
MAP 相当于java的map
MAP是一组键值对的组合,可以通过KEY访问VALUE,键值之间同样要在创建表时指定分隔符。
如:map_col['name']
Hive除了支持STRUCT、ARRAY、MAP这些原生集合类型,还支持集合的组合,不支持集合里再组合多个集合。
示例:
1)创建带有复合结构的表
CREATE TABLE complex
(
id int,
struct_col struct<name:string,country:string>,
array_col array<string>,
map_col map<string,string>,
union_col map<string,array<string>>
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':';其中:
--这个子句表明hive使用字符‘,’作为列分隔符
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
--这个子句表明hive使用字符 ‘-’ 作为集合元素间分隔符(一个字段各个item的分隔符)
COLLECTION ITEMS TERMINATED BY '-'
--这个子句表明hive使用字符作为map的键和值之间分隔符
MAP KEYS TERMINATED BY ':'2)插入数据
insert into table complex
select
100,
NAMED_STRUCT('name','hainiu','country','cn') as struct_col,
array('99','21','33') as array_col,
map('english','aaaa') as map_col,
map('english',array('99','21','33')) as union_col;查看数据格式

3)用HQL查询
--查询struct
select struct_col.name from complex;
--查询数组第一个元素
select array_col[0] from complex;
--查询map中key对应的value值
select map_col['english'] from complex;
--查询复杂结构map<STRING,array<STRING>>中key对应的value值
select union_col['english'] from complex;
--查询复杂结构map<STRING,array<STRING>>中key对应的value值(数组)中的第一个元素
select union_col['english'][0] from complex;演示:
hive (hainiu)> select * from complex;
OK
100 {"name":"hainiu","country":"cn"} ["99","21","33"] {"english":"aaaa"} {"english":["99","21","33"]}
Time taken: 0.177 seconds, Fetched: 1 row(s)
hive (hainiu)> desc complex;
OK
id int
struct_col struct<name:string,country:string>
array_col array<string>
map_col map<string,string>
union_col map<string,array<string>>
Time taken: 0.042 seconds, Fetched: 5 row(s)
hive (hainiu)> select struct_col from complex;
OK
{"name":"hainiu","country":"cn"}
Time taken: 0.169 seconds, Fetched: 1 row(s)
hive (hainiu)> select struct_col.country from complex;
OK
cn
Time taken: 0.124 seconds, Fetched: 1 row(s)
hive (hainiu)> select struct_col.name from complex;
OK
hainiu
Time taken: 0.131 seconds, Fetched: 1 row(s)
hive (hainiu)> select array_col[1] from complex;
OK
21
Time taken: 0.407 seconds, Fetched: 1 row(s)
hive (hainiu)> select map_col['english'] from complex;
OK
aaaa
Time taken: 0.166 seconds, Fetched: 1 row(s)
hive (hainiu)>select union_col['english'][1] from complex;
OK
21
Time taken: 0.167 seconds, Fetched: 1 row(s)
hive (hainiu)> select union_col['english'] from complex;
OK
["99","21","33"]
Time taken: 0.141 seconds, Fetched: 1 row(s)
-- 如果key不存在,返回null
hive (hainiu)> select union_col['english1'] from complex;
OK
NULL1.2.1 hive读取json格式数据
JSON是一个包含对象或数组的字符串。
-
数据为 键 / 值 (name/value)对;
-
数据由逗号(,)分隔;
-
大括号保存对象(object);
- 方括号保存数组(Array);
例如:
{"code":"100"}
#对象由花括号括起来的逗号分割的成员构成,成员是字符串键和上文所述的值由逗号分割的键值对组成:
{“code”:20,"type":"mysql"}
#数组是由方括号括起来的一组值构成:
{"datesource":[
{"code":"20", "type":"mysql"},
{"code":"20", "type":"mysql"},
{"code":"20", "type":"mysql"}
]}
hive中提供了获取json数据的方法GET_JSON_OBJECT
SELECT
GET_JSON_OBJECT('{"level":"2","time":1650973942596,"type":"0"}','$.level' ) as level ;结果

如果想要读取个字段可以
SELECT
GET_JSON_OBJECT('{"level":"2","time":1650973942596,"type":"0"}','$.level' ) as level,
GET_JSON_OBJECT('{"level":"2","time":1650973942596,"type":"0"}','$.time' ) as times,
GET_JSON_OBJECT('{"level":"2","time":1650973942596,"type":"0"}','$.type' ) as types;运行结果:

为了解决get_json_object一次解析不了整个JSON文件的问题,我们就有了json_tuple这个函数,一条便能处理一条JSON数据,基础语法为:
json_tuple(json_string, k1, k2 ...)解析json的字符串json_string,可指定多个json数据中的key,返回对应的value。如果输入的json字符串无效,那么返回NULL
SELECT
json_tuple('{"level":"2","time":1650973942596,"type":"0"}','level','time','type') as (level,times,types);结果:

Hive解析JSON数组
[{"website":"baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]需求:解析JSON数组中website和name的数据
第一步将【】去掉
需要用到regexp_replace函数
#将字符串A中的符合java正则表达式B的部分替换为C。
regexp_replace(string A, string B, string C)select regexp_replace('[{"website":"baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]', '\\[|\\]','');
第二步:将‘,‘替换成’|’
select regexp_replace(regexp_replace('[{"website":"baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]', '\\[|\\]',''),'\\}\\,\\{','\\}\\|\\{')
第三步:按照‘|‘进行切分分成两个json字符串组成的数组
select split(regexp_replace(regexp_replace('[{"website":"baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]', '\\[|\\]',''),'\\}\\
','\\}\\|\\{'),'\\|');
第四步:将数组中两个字符串变成两行数据,需要用到explode语法
explode的基础语法为:
explode(Array OR Map)能:explode()函数接收一个array或者map类型的数据作为输入,然后将array或map里面的元素按照每行的形式输出,即将hive一列中复杂的array或者map结构拆分成多行显示,也被称为列转行函数。
select explode(split(regexp_replace(regexp_replace('[{"website":"baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]', '\\[|\\]',''),'\\}\\,\\{','\\}\\|\\{'),'\\|')) as json结果

第五步:再用json_tuple进行解析其中的website和name数据
select json_tuple(json, 'website', 'name')
from (
select explode(split(regexp_replace(regexp_replace('[{"website":"baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]', '\\[|\\]',''),'\\}\\,\\{','\\}\\|\\{'),'\\|')) as json) t;
2 操作符(Relational Operators)
2.1 关系操作符
以下操作符比较操作数(operands)从而产生TRUE/FALSE值。
| 运算符 | 操作数 | 描述 |
|---|---|---|
| A = B | 所有基本类型 | 如果表达A等于表达B,结果TRUE ,否则FALSE。 |
| A != B | 所有基本类型 | 如果A不等于表达式B表达返回TRUE ,否则FALSE。 |
| A < B | 所有基本类型 | TRUE,如果表达式A小于表达式B,否则FALSE。 |
| A <= B | 所有基本类型 | TRUE,如果表达式A小于或等于表达式B,否则FALSE。 |
| A > B | 所有基本类型 | TRUE,如果表达式A大于表达式B,否则FALSE。 |
| A >= B | 所有基本类型 | TRUE,如果表达式A大于或等于表达式B,否则FALSE。 |
| A IS NULL | 所有类型 | TRUE,如果表达式的计算结果为NULL,否则FALSE。 |
| A IS NOT NULL | 所有类型 | FALSE,如果表达式A的计算结果为NULL,否则TRUE。 |
| A LIKE B | 字符串 | TRUE,如果字符串模式A匹配到B,否则FALSE。关系型数据库中的like功能。 |
| A RLIKE B | 字符串 | B是否在A里面,在是TRUE,否则是FALSE(B可以是Java正则表达式) |
| A REGEXP B | 字符串 | 等同于RLIKE. |
-- 模糊查询的
select if(struct_col.name='hainiu1',1,0),struct_col.name from complex where map_col['english'] like '%a%';
-- 正则匹配的
select if(struct_col.name='hainiu1',1,0),struct_col.name from complex where map_col['english'] RLIKE '\\S';
-- 判断为null
select if(struct_col.name='hainiu1',1,0),struct_col.name from complex where map_col['english1'] is null;
-- 判断不为空
select if(struct_col.name='hainiu1',1,0),struct_col.name from complex where map_col['english'] is not null;
hive (hainiu)> select map_col['english'] from complex;
OK
aaaa
Time taken: 0.082 seconds, Fetched: 1 row(s)
hive (hainiu)> select map_col['english'] is null from complex;
OK
false
Time taken: 0.076 seconds, Fetched: 1 row(s)
hive (hainiu)> select map_col['english'] is not null from complex;
OK
true
Time taken: 0.066 seconds, Fetched: 1 row(s)
hive (hainiu)> select map_col['english'] like 'a%' from complex;
OK
true
Time taken: 0.072 seconds, Fetched: 1 row(s)
hive (hainiu)> select map_col['english'] like '%a%' from complex;
OK
true
Time taken: 0.066 seconds, Fetched: 1 row(s)
hive (hainiu)> select 'asdfa21445' rlike '\\S';
OK
true
Time taken: 0.051 seconds, Fetched: 1 row(s)
hive (hainiu)> select 'asdfa21445' rlike '\\D';
OK
true
Time taken: 0.046 seconds, Fetched: 1 row(s)
hive (hainiu)> select 'asdfa21445' rlike '\\d'; -- 有数字
OK
true
Time taken: 0.063 seconds, Fetched: 1 row(s)
hive (hainiu)> select 'asdfa21445' rlike '\\s'; -- 有空白字符
OK
false
Time taken: 0.049 seconds, Fetched: 1 row(s)
if函数
if(struct_col.name='hainiu1',1,0)
类似的三目运算符 if(条件, true的结果, false 的结果)
测试结果

2.2 算数运算符
这些运算符支持的操作数各种常见的算术运算。所有这些返回数字类型。
下表描述了在Hive中可用的算术运算符:
| 运算符 | 操作 | 描述 |
|---|---|---|
| A + B | 所有数字类型 | A加B的结果 |
| A - B | 所有数字类型 | A减去B的结果 |
| A * B | 所有数字类型 | A乘以B的结果 |
| A / B | 所有数字类型 | A除以B的结果 |
| A % B | 所有数字类型 | A除以B.产生的余数 |
| A & B | 所有数字类型 | A和B的按位与结果 |
| A | B | 所有数字类型 | A和B的按位或结果 |
| A ^ B | 所有数字类型 | A和B的按位异或结果 |
| ~A | 所有数字类型 | A按位非的结果 |
2.3 逻辑运算符
运算符是逻辑表达式。所有这些返回TRUE或FALSE。
| 运算符 | 操作 | 描述 |
|---|---|---|
| A AND B | boolean | TRUE,如果A和B都是TRUE,返回true,否则FALSE。 |
| A OR B | boolean | TRUE,如果A或B或两者都是TRUE,返回true,否则FALSE。 |
| NOT A | boolean | TRUE,如果A是FALSE,返回true,否则FALSE。 |
算术运算符和逻辑运算符使用的位置是根据自己的使用情况去定。但是一定符合语法规则。
测试

3 聚合函数
将多行聚合为一行
| 返回类型 | 函数 | 描述 |
|---|---|---|
| BIGINT | count(*), count(expr), | count(*) - 返回检索行的总数。 |
| DOUBLE | sum(col), sum(DISTINCT col) | 返回该组或该组中的列的不同值的分组和所有元素的总和。 |
| DOUBLE | avg(col), avg(DISTINCT col) | 返回上述组或该组中的列的不同值的元素的平均值。 |
| DOUBLE | min(col) | 返回该组中的列的最小值。 |
| DOUBLE | max(col) | 返回该组中的列的最大值。 |
count(1) count(*) count(字段)
count(1) count(*) 是包含null值
count(字段) 不包含null值
count(1) 稍微比 count(*) 快点
--准备数据文件data.txt
-- 创建表
CREATE TABLE `user_install_status_limit`(
`aid` string,
`pkgname` string,
`uptime` bigint,
`type` int,
`country` string,
`gpcategory` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
;
--将导出的100条data数据放到表的hdfs目录
hadoop fs -put data.txt /hive/warehouse/xinniu.db/user_install_status_limit其中:
aid:每个用户的标识
pkgname:用户安装某个手机应用的包名
uptime:更新时间
type:系统预装应用还是 用户自己装的应用
country:用户所在的国家
gpcategory:应用的类型,游戏类、社交类。。。
数据上传成功:
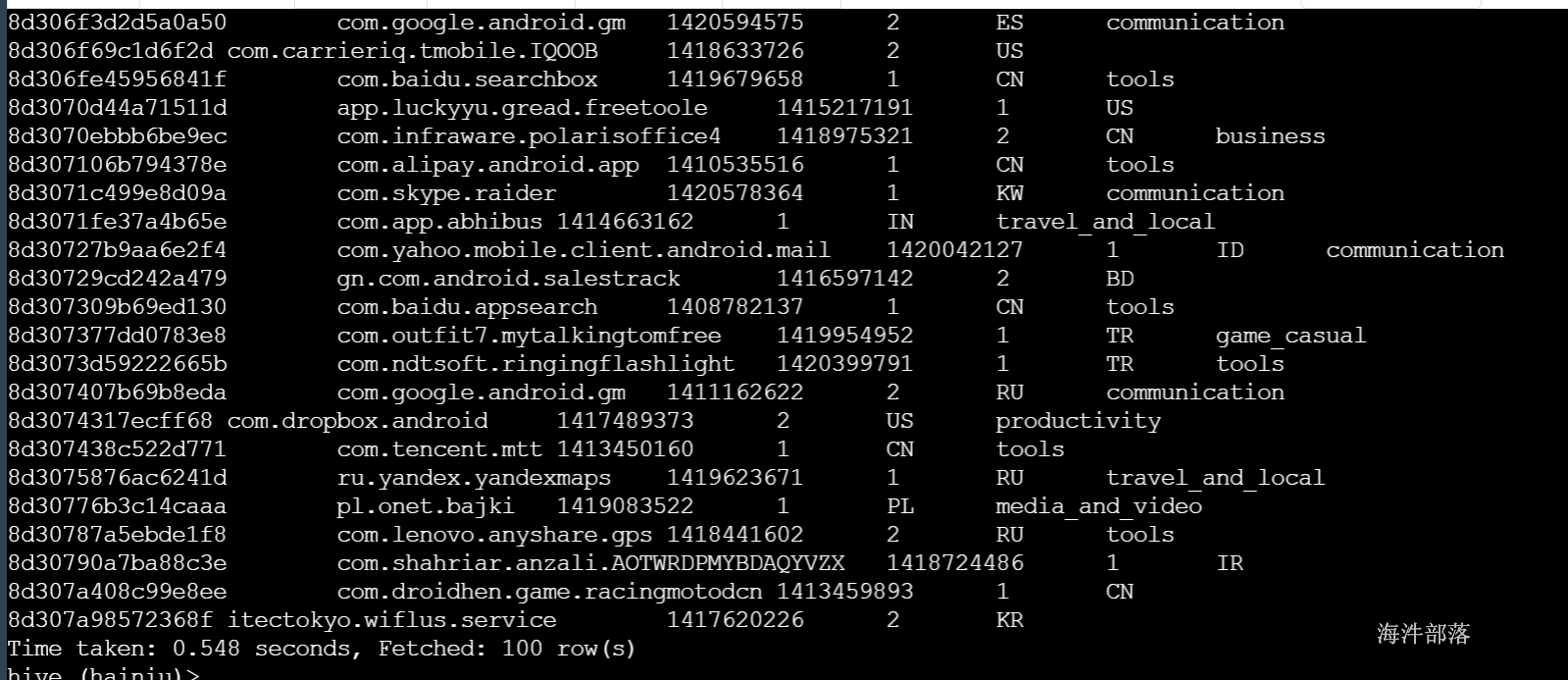
-- 不同用户数 统计用户id以8d304开头的记录数
select count(DISTINCT aid), sum(if(aid like '8d304%',1,0)) from user_install_status_limit;
--------------------
-- 统计用户id以8d304开头的记录数
select sum(1) from user_install_status_limit where aid like '8d304%';
8d304aaaa xxx
8d305aaaa xxx
8d304bbbb xxx
8d304cccc xxx
--------------------
-- sum(每个国家的不同用户数)
select sum(a.n) from (
-- 统计每个国家的不同用户数
select count(DISTINCT aid) n from user_install_status_limit group by country
) a;
--------------------
-- 不同用户数
select count(1) from (
select 1 from user_install_status_limit group by aid
) a;
8d304aaaa xxx
8d304aaaa xxx
8d304bbbb xxx
8d304cccc xxx
--------------------
-- 查询按照国家分组后的最大值
select max(a.n) from (
select country,count(1) n from user_install_status_limit group by country
) a;
BR 5
CN 12
CO 3
max() --> 12
-- 查询按照国家分组后的最大值和国家码
-- select * from 数据集1 t1 inner join 数据集2 t2 on t1.xx=t2.xx
select t1.maxn, t2.country from
(
select max(a.n) as maxn from (
select country,count(1) n from user_install_status_limit group by country
) a
) t1 inner join
(select country,count(1) n from user_install_status_limit group by country) t2
on t1.maxn=t2.n;
-- 查询按照国家分组后的最大值和国家码
--select * from 数据集1 t1 where t1.xx in (数据集2);
select t1.country, t1.n from
(select country,count(1) n from user_install_status_limit group by country) t1
where t1.n in (
select max(a.n) as maxn from (
select country,count(1) n from user_install_status_limit group by country
) a
);
-- group by 后查询的结果只能是 group by字段、聚合函数、常量
select country, count(*), 111 from user_ins tall_status_limit group by country;4 DDL(Data Definition Language)
数据定义包括schema的定义和查看,hive的主要DDL语句包括:
--创建语句
CREATE DATABASE/SCHEMA, TABLE, VIEW, FUNCTION, INDEX
--删除语句
DROP DATABASE/SCHEMA, TABLE, VIEW, INDEX
--清空语句
TRUNCATE TABLE
--修改语句
ALTER DATABASE/SCHEMA, TABLE, VIEW
--查看列表
SHOW DATABASES/SCHEMAS, TABLES, TBLPROPERTIES, PARTITIONS, FUNCTIONS, INDEX[ES], COLUMNS
--查看创建语句
SHOW CREATE TABLE
--查看结构语句
DESCRIBE DATABASE/SCHEMA, table_name, view_name4.1 数据库操作
创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];其中:
DATABASE 和 SCHEMA 的使用是一样的,CREATE DATABASE 是(HIVE-675)增加的。
WITH DBPROPERTIES 是(HIVE-1836)增加的,可以指定一下数据属性数据。
--创建带有属性的数据库
create database testdb_otherinfo WITH DBPROPERTIES ('creator' = 'hainiu', 'date' = '2022-11-30');
--显示创建语句
show create database testdb_otherinfo;
操作示例:
show databases;
#默认有一个default名字的数据库。
--创建一个名字为test的数据库
create database test;
--显示所有数据库
show databases;
--如果已经存在会报错
create database test;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Database test already exists
--可以增加if not exists 达到不存在再创建
create database if not exists test;
--describe命令(简写 desc)查看数据库定义元数据相关信息,可以查看数据location地址
describe database test;
--显示创建语句
show create database test;--使用数据库
use hainiu;
--查看当前数据库
select current_database();查看当前数据库也可以看hive后面的括号()内的内容

--切换到test数据库
use test;
select current_database();也可通过 hive.cli.print.current.db 参数将当前数据打印到CLI提示符
set hive.cli.print.current.db=true;
也可以直接配置到hive-site.xml中永久生效,set命令保障当前session生效
修改数据库
ALTER DATABASE database_name SET DBPROPERTIES (property_name=property_value, ...);删除数据库
DROP DATABASE [IF EXISTS] database_name [RESTRICT|CASCADE];删除数据库是会校验数据库下是否有表存在,如果在RESTRICT 模式有表存在则不能删除,修改为CASCADE模式可以级联删除数据库和数据库下所有表。删除操作要谨慎,删除前最好做一下检测和备份。
4.2 创建表
表分类

4.2.1 创建表语法
建表格式:
-- EXTERNAL 代表外部表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
-- 分区表设置 分区的字段和类型
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
-- 桶表设置 按照什么字段进行分桶
[CLUSTERED BY (col_name, col_name, ...)
-- 桶内的文件 是按照 什么字段排序 分多少个桶
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
-- 分隔符 + 序列化反序列化
[ROW FORMAT row_format]
-- 输入输出格式
[STORED AS file_format]
-- 表所对应的hdfs目录
[LOCATION hdfs_path] 其中:
1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常。
2)EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION);
3)COMMENT 可以为表与字段增加描述
4)ROW FORMAT 指定分隔符
-- 分隔符设置
-- 字段间分隔符
DELIMITED [FIELDS TERMINATED BY char]
-- 集合间分隔符
[COLLECTION ITEMS TERMINATED BY char]
-- map k v 间分隔符
[MAP KEYS TERMINATED BY char]
-- 行分隔符
[LINES TERMINATED BY char]
--序列化和反序列化设置
SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)] SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化。
Serialize把hive使用的java object转换成能写入hdfs的字节序列,或者其他系统能识别的流文件。
Deserilize把字符串或者二进制流转换成hive能识别的java object对象。
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
5)STORED AS
1. SEQUENCEFILE --包含键值对的二进制的文件存储格式,支持压缩,可以节省存储空间
2. TEXTFILE --最普通的文件存储格式,内容是可以直接查看(默认的)
3. AVRO --带有schema文件格式的, 一行的数据是个map,添加字段方便
4. RCFile --是列式存储文件格式,适合压缩处理。对于有成百上千字段的表而言,RCFile更合适。
5. ORC -- 是列式存储文件格式,带有压缩和轻量级索引, 一行数据是个数组,查询快,不适合添加字段
6. parquet -- 是列式存储文件格式,带有压缩和轻量级索引, 和orc比较类似 如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。
如果数据需要压缩,使用 STORED AS SEQUENCEFILE、RCFile、ORC 。
4.2.2 内部表与外部表

建表:
内部表 不需要指定location
外部表: 指定 external, location
删表:
内部表: 元数据和数据都删除
外部表:只删除元数据
内部表
--创建inner_test 表
CREATE TABLE inner_test(word string, num int);
--显示创建表语句
show create table inner_test;创建内部表,不需要指定 location,在数据库下面产生表目录
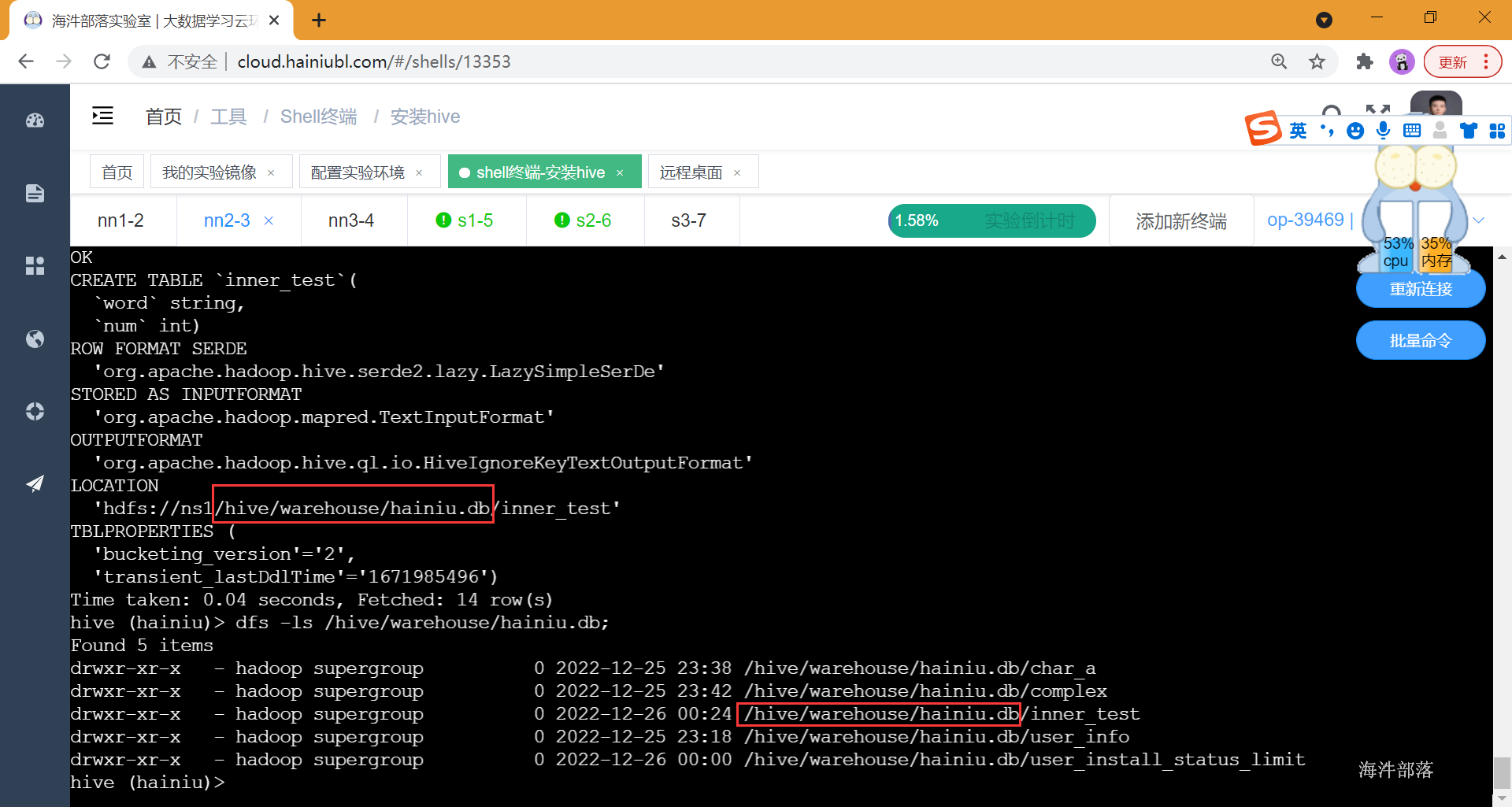
删除内部表,表对应的hdfs目录也一并删除

外部表
--创建外部表的语法格式
CREATE EXTERNAL TABLE ext_test(
col_name data_type ...)
COMMENT 'This is ext_testtable'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001'
STORED AS TEXTFILE
LOCATION '<hdfs_location>';例子:
--创建外部表ext_test
--使用字符‘\001’作为列分隔符
--文件数据是纯文本
--数据存放的hdfs地址:/user/xinniu/hive/ext_test'
CREATE EXTERNAL TABLE ext_test(
word string, num int)
COMMENT 'This is ext_testtable'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001'
STORED AS TEXTFILE
LOCATION '/user/xinniu/hive/ext_test';建表,指定location
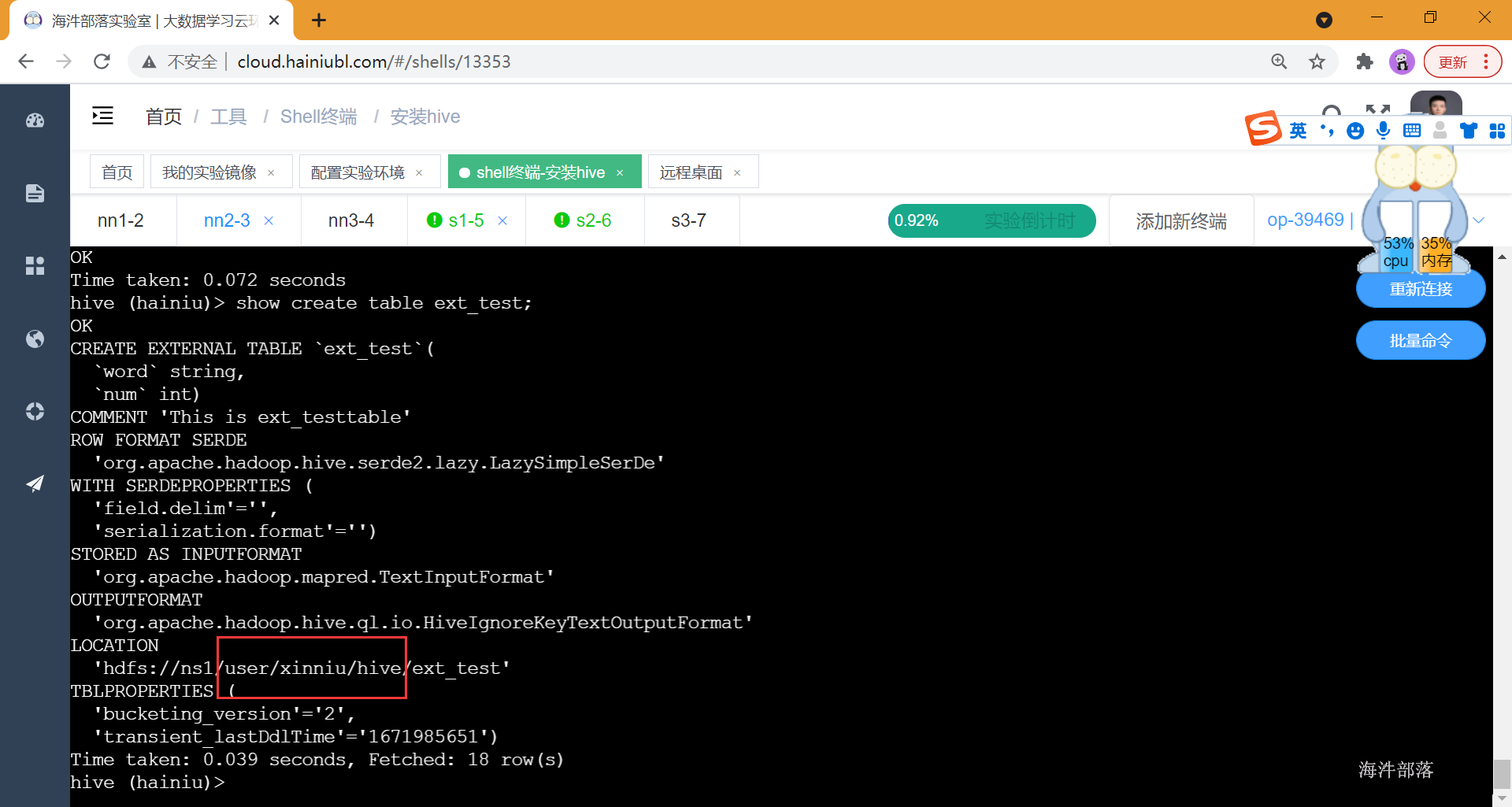
删除表,表对应hdfs目录不删除

4.2.3 创建分区表
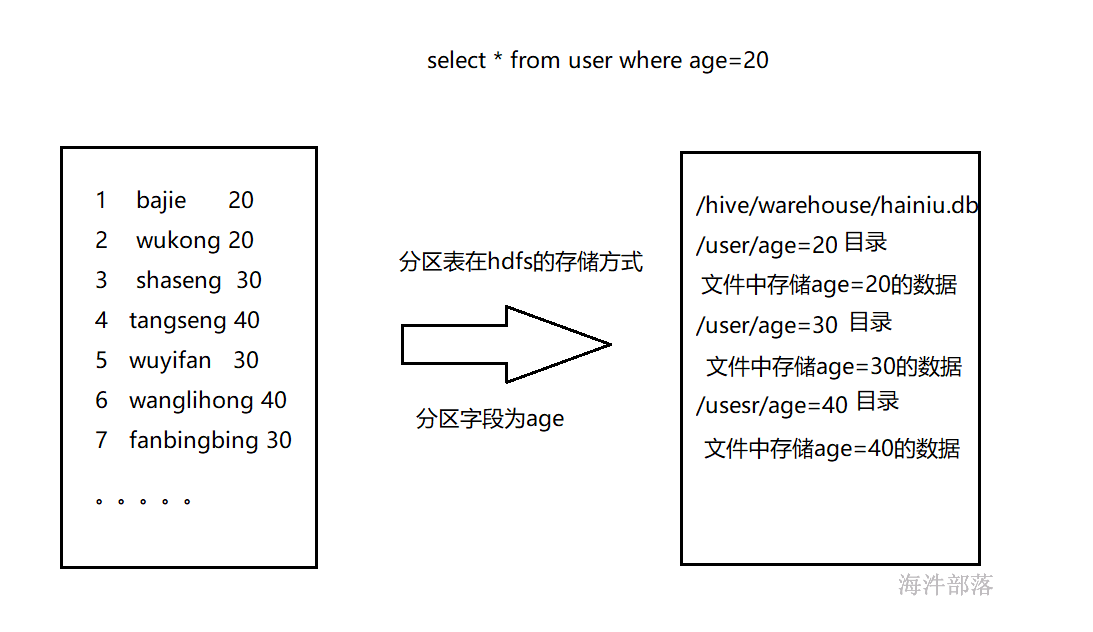
创建分区表的好处是查询时,不用全表扫描,查询时只要指定分区,就可查询分区下面的数据。
分区表可以是内部表,也可以是外部表。
--建表格式
CREATE [EXTERNAL] TABLE par_test(
col_name data_type ...)
COMMENT 'This is the par_test table'
PARTITIONED BY(day STRING, hour STRING)
[ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ]
[LOCATION '/user/hainiu/data/'];其中:
1)添加单个partition 语法格式
--在表中添加单个partition,相当于hdfs:'/……/表名/20141117/00'
alter table 分区表 add IF NOT EXISTS partition(分区字段='值1',分区字段='值2') location '指定分区在HDFS上目录结构';3)添加多个partition 语法格式
--在表中添加多个partition
--相当于hdfs:'/……/表名/20141117/00'
--相当于hdfs:'/……/表名/20141117/01'
alter table par_test add partition(day='20141117',hour='00') location '20141117/00' partition(day='20141117',hour='01') location '20141117/01';4)查看表分区
show partitions tableName;5)删除partition
alter table 表名 drop if exists partition(字段1='值1',字段2='值2');示例1
1)创建分区表
CREATE EXTERNAL TABLE book(
id int,
name string
)
PARTITIONED BY (country string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/user/cz/book';2)给分区表添加一个分区
--添加partition
alter table book add IF NOT EXISTS partition(country='cn') location 'cn';注意:
add partitions的时候,如果指定LOCATIO路径就按指定的路径创建分区目录
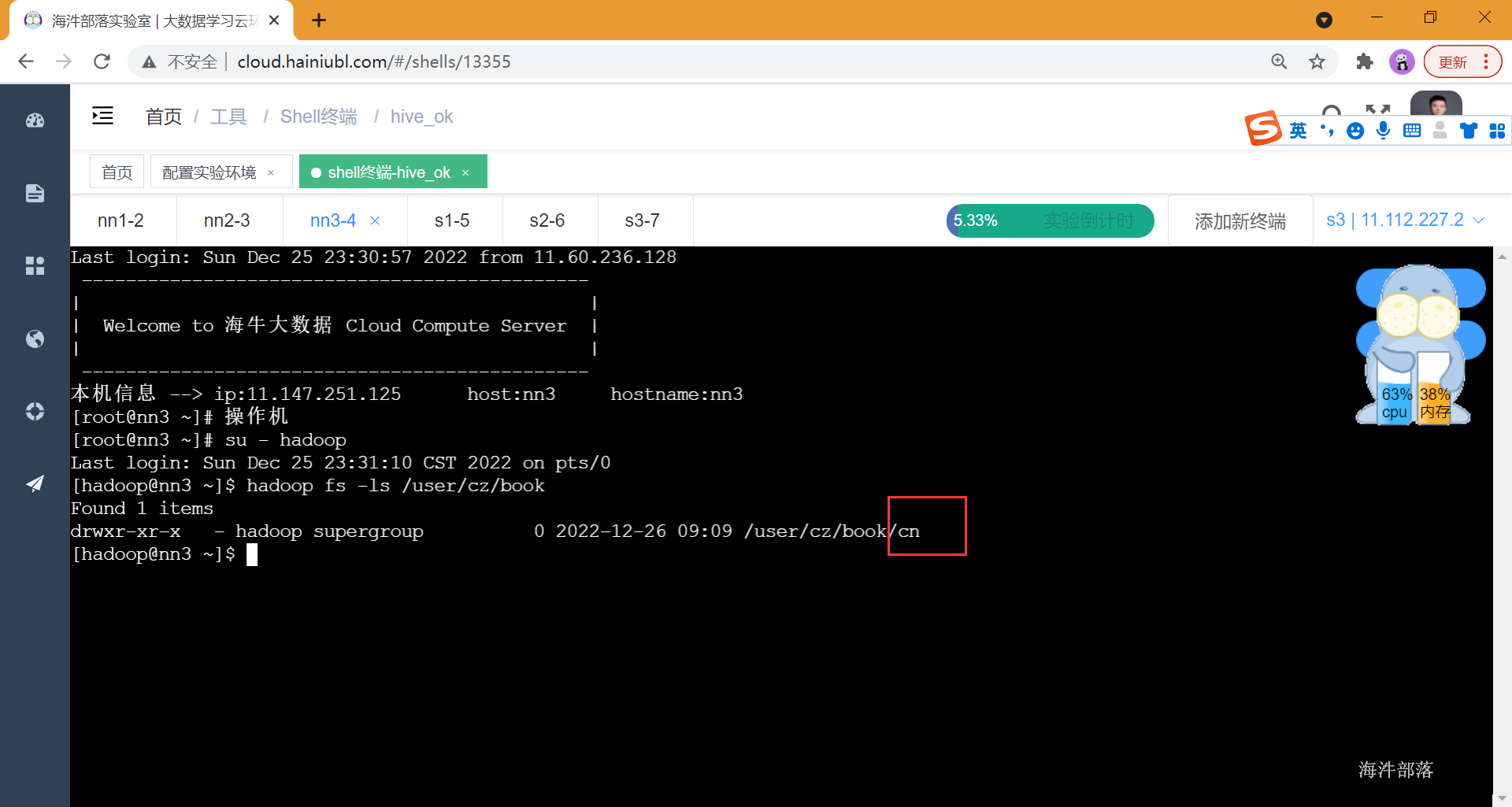
add partitions的时候,如果不指定LOCATIO路径就给你创建一个
--添加partition
alter table book add IF NOT EXISTS partition(country='cn') ;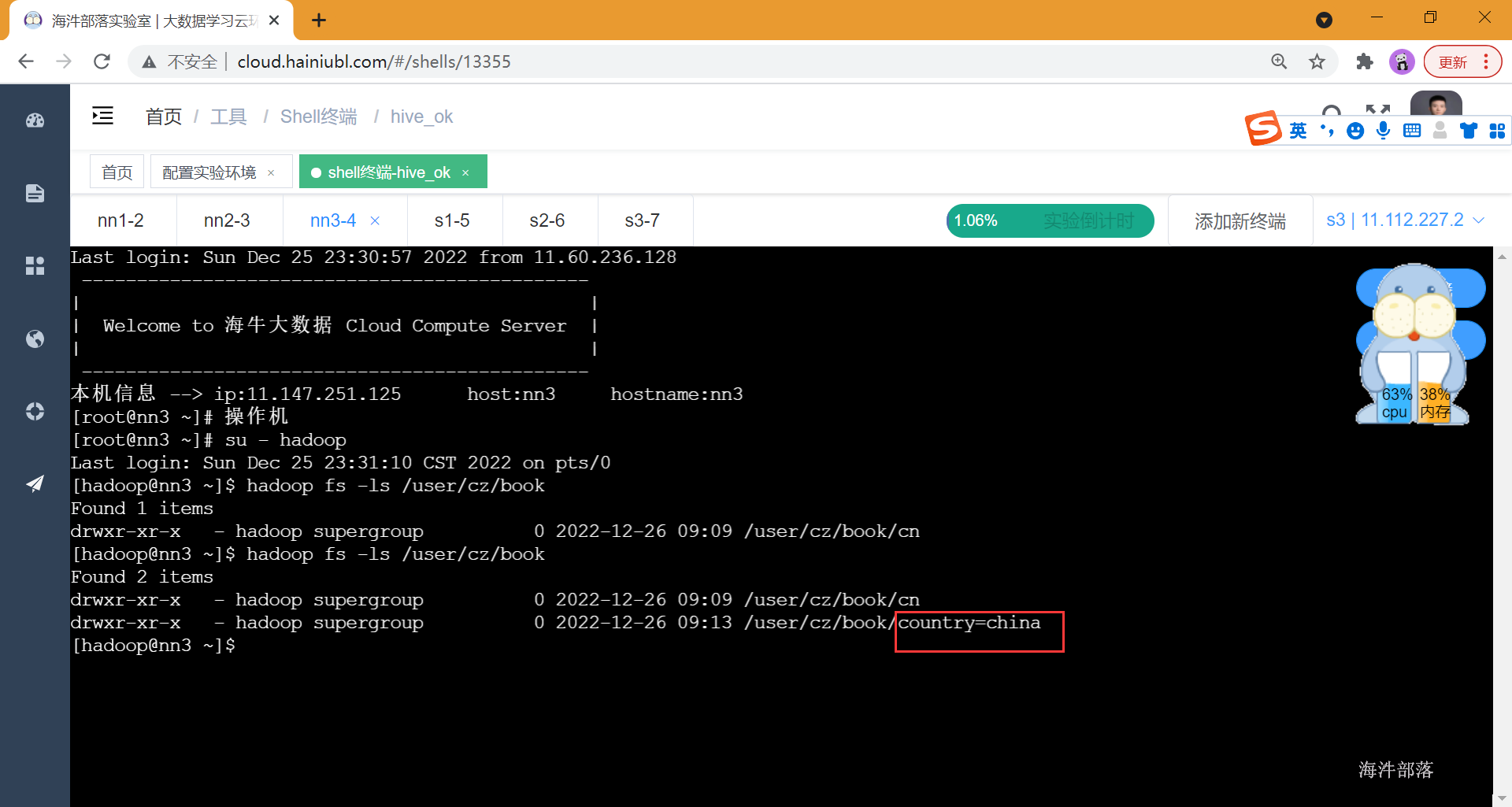
向分区中存放数据
#准备cn.txt文件并上传到cn对应的分区目录
1 shuihu
2 sanguo
3 xiyouji
4 hongloumeng
#上传文件
hadoop fs -put cn /user/cz/book/cn查询分区表中的所有分区数据
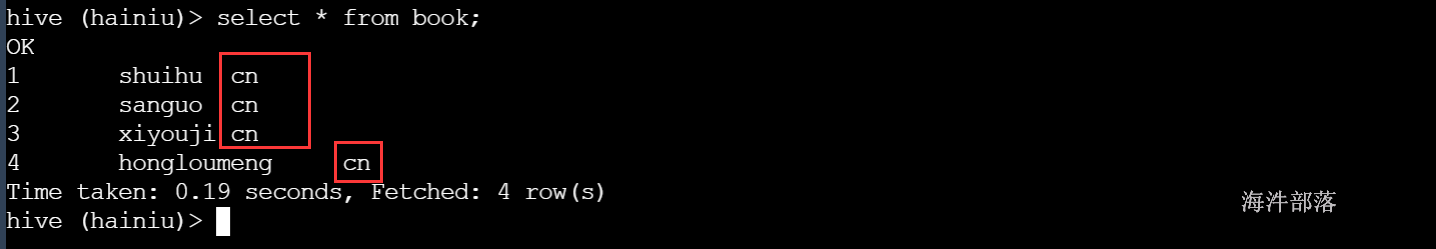
按照之前的逻辑,我们向分区表中创建分区,相当于在hdfs创建一个分区目录,向分区中添加数据,相当于,将数据文件放到分区目录对应的hdfs路径下。
大胆猜想:那能不能手动在hdfs添加一个分区目录,并上上传文件数据,那么在分区表中能否查到新的分区数据呢?
#在hadoop中创建分区目录
hadoop fs -mkdir /user/cz/book/country=en
#准备数据
1 java
2 spring
3 hadoop
#将数据放到en对应的分区目录中
hadoop fs -put en /user/cz/book/country=jp查询发现en分区的数据不存在,只有cn的数据

原因:手动在hdfs创建的分区目录信息,并没有保存到元数据库中,所以查询的时候从mysql元数据库查询不到en的分区信息,所以自然而然读不到en分区的数据。
想要读取到en分区的数据,可以添加en分区的元数据信息到mysql。
手动修复:
执行添加分区的操作会自动将分区信息加入到元数据库中
alter table book add IF NOT EXISTS partition(country='en');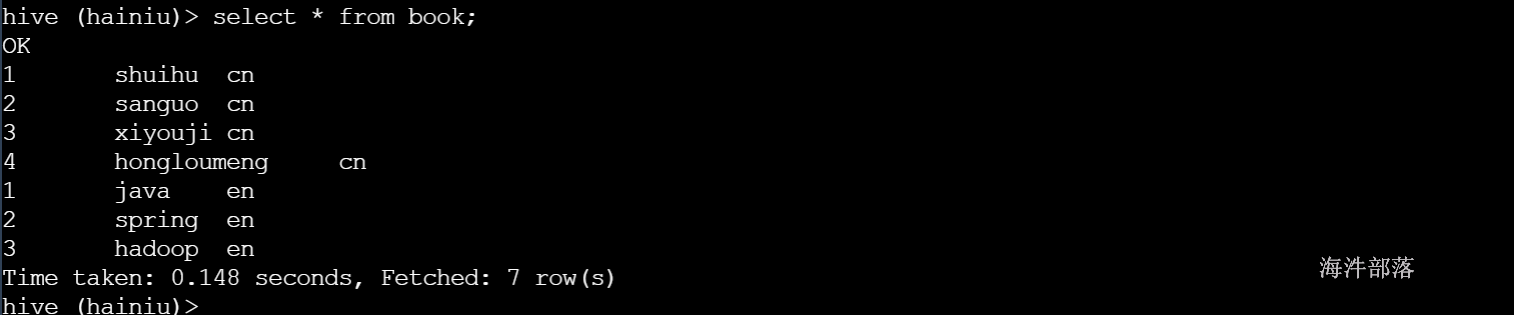
自动修复:
#在hadoop中创建分区目录
hadoop fs -mkdir /user/cz/book/country=jp
#准备数据
1 zhenzi
2 kenan
3 quanyecha
#将数据放到en对应的分区目录中
hadoop fs -put jp /user/cz/book/country=jp查询不到jp分区的数据

此时修复分区
msck repair table book
示例2:
1)创建分区表
CREATE EXTERNAL TABLE student_par(
name string
)
PARTITIONED BY (age int,sex STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/user/cz/student_par';2)给分区表添加一个分区
--添加partition
alter table student_par add IF NOT EXISTS partition(age=10,sex='boy') location '10/boy';
-- 准备数据添加到分区中
zhangsan
lisi
wangwu
zhaoliu
hadoop fs -put user /user/cz/student_par/10/boy如果想查询哪个分区对应location,可以通过SQL元数据查询
select t1.`NAME`, t2.TBL_NAME,t4.PART_NAME, t3.LOCATION from DBS t1, TBLS t2 , SDS t3 , `PARTITIONS` t4
where t1.DB_ID=t2.DB_ID and
t4.SD_ID = t3.SD_ID AND
t2.TBL_ID = t4.TBL_ID and
t1.`NAME` = 'hainiu' AND
t2.TBL_NAME like 'student_par' 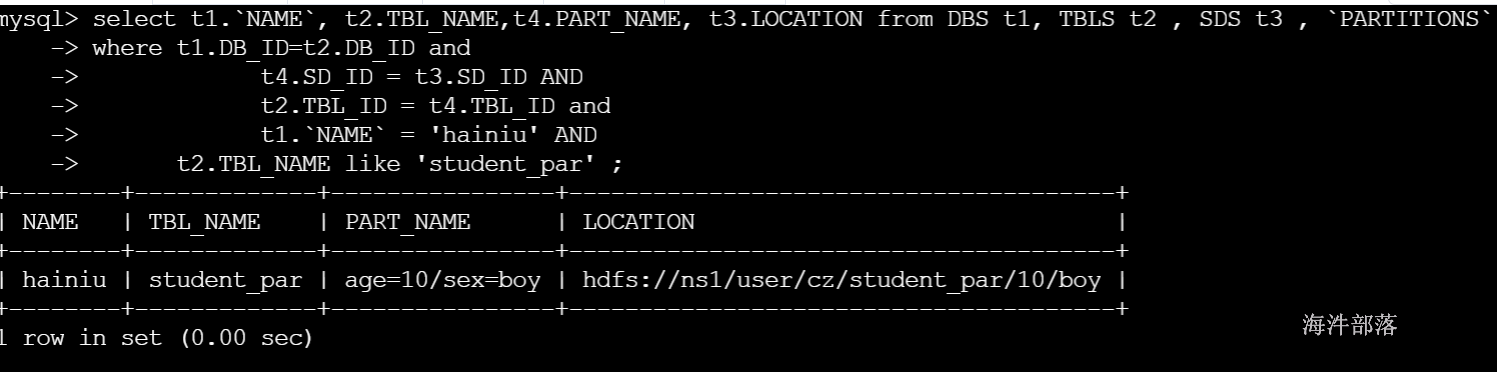
3)给分区表添加多个分区
--再加两个分区
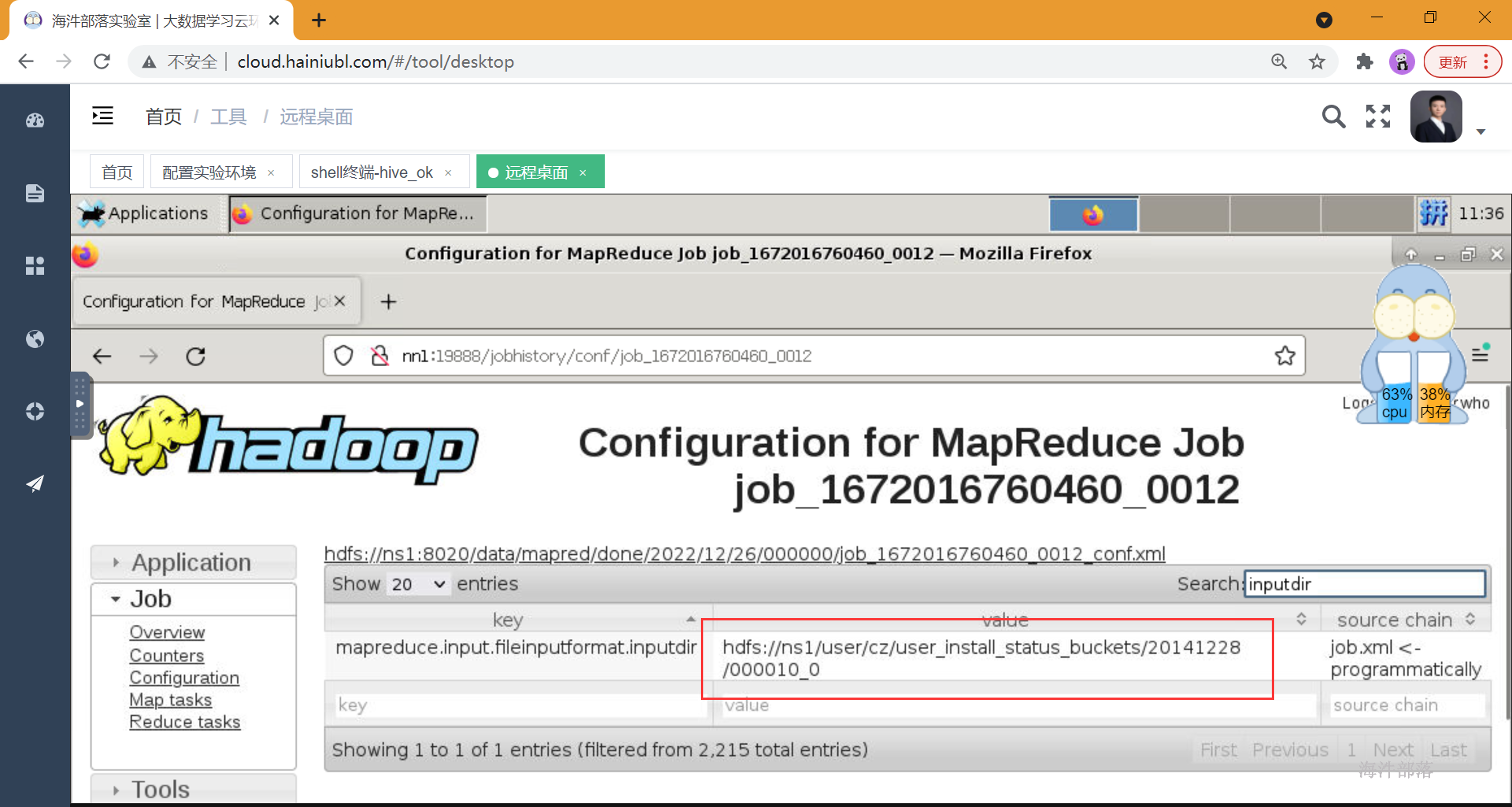
alter table student_par add IF NOT EXISTS partition (age=11,sex='boy') location '11/boy' partition (age=11,sex='girl') location '11/girl';4)如何查看任务扫描输入目录
mapreduce.input.fileinputformat.inputdir
--分区表,不扫描全表
select count(*) from student_par where age=10 and sex='boy';history → configuration , 输入 inputdir
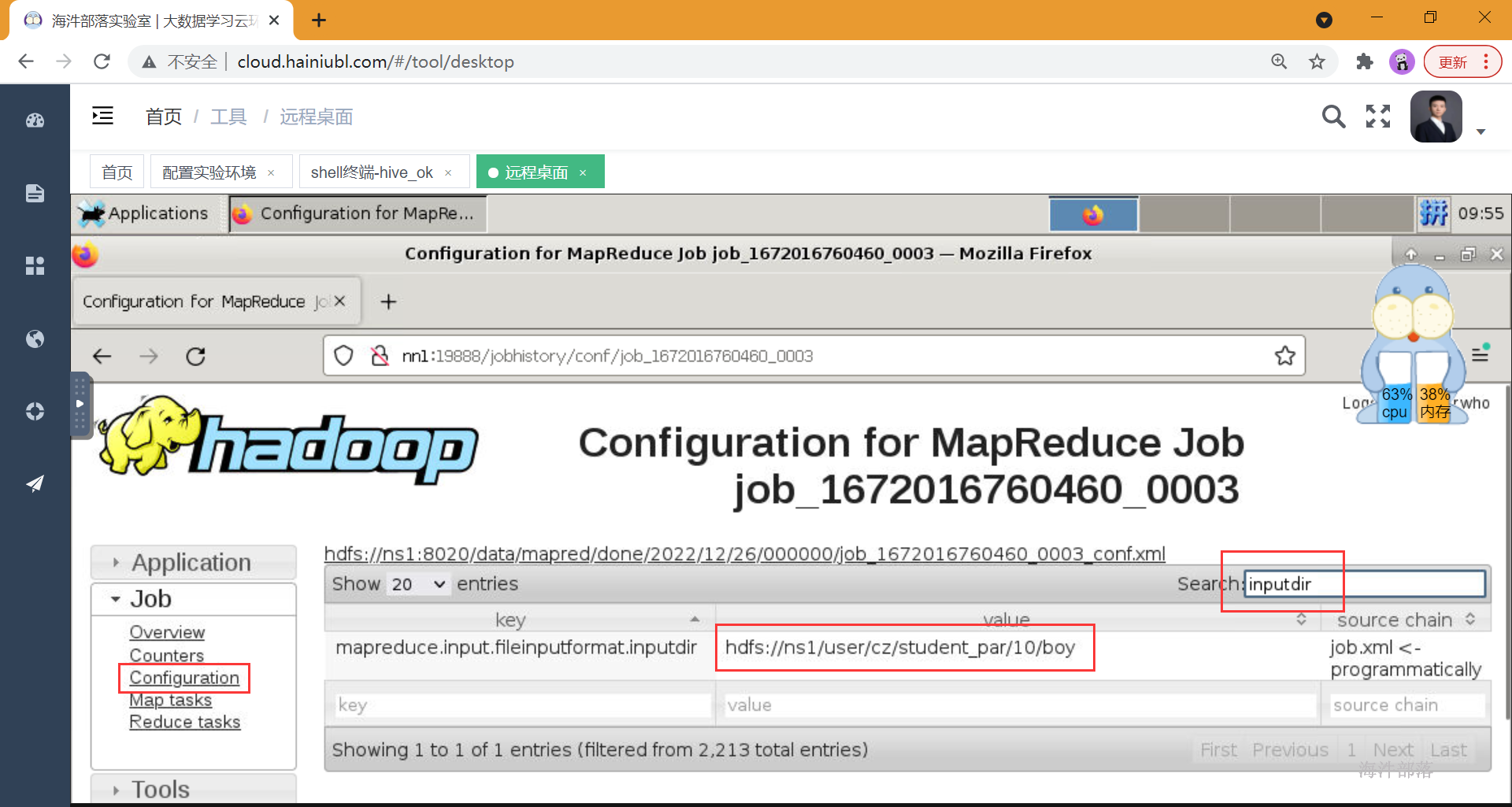
-- 扫描所有分区
select count(*) from student_par ;
注意:要想实现这么个结果,需要把所有分区数据都填一下
#给所有分区添加数据
hadoop fs -put user /user/cz/student_par/11/boy
hadoop fs -put user /user/cz/student_par/11/girl4.2.4 创建分桶表
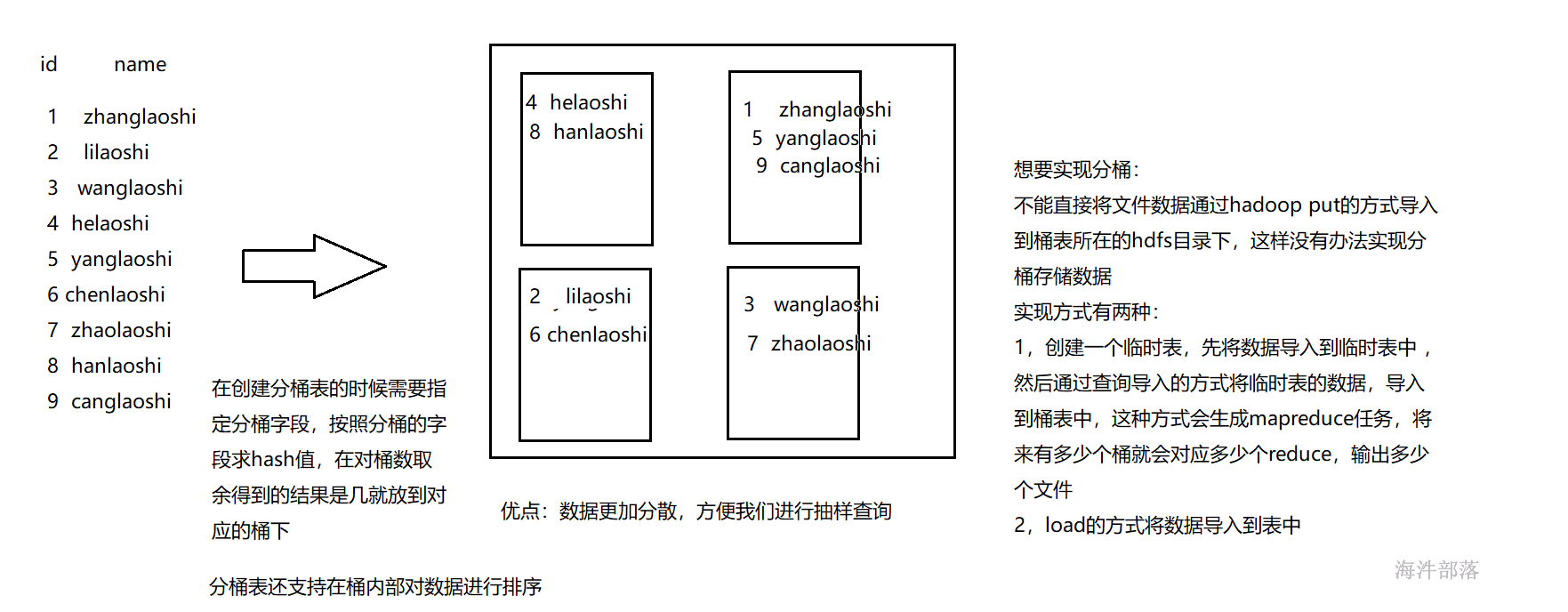
对于每一个表,可以进一步组织成桶,其实就是更细粒度的数据抽样查询。
Bucket是对指定列进行hash,然后根据hash值除以桶的个数进行求余,决定该条记录存放在哪个桶中。
公式:whichBucket = hash(columnValue) % numberOfBuckets
总结:桶表就是对一次进入表的数据进行文件级别的划分。
4.2.4.1 创建桶表
示例1:
创建user_install_status_other 分区表
CREATE TABLE `user_install_status_other`(
`aid` string COMMENT 'from deserializer',
`pkgname` string COMMENT 'from deserializer',
`uptime` bigint COMMENT 'from deserializer',
`type` int COMMENT 'from deserializer',
`country` string COMMENT 'from deserializer',
`gpcategory` string COMMENT 'from deserializer')
PARTITIONED BY (`dt` string)
;导入数据
-- 添加分区
alter table user_install_status_other add if not exists partition (dt='20141228') location '20141228';
-- 导入数据
hadoop fs -put -f cz_user_install_data1 /hive/warehouse/hainiu.db/user_install_status_other/20141228
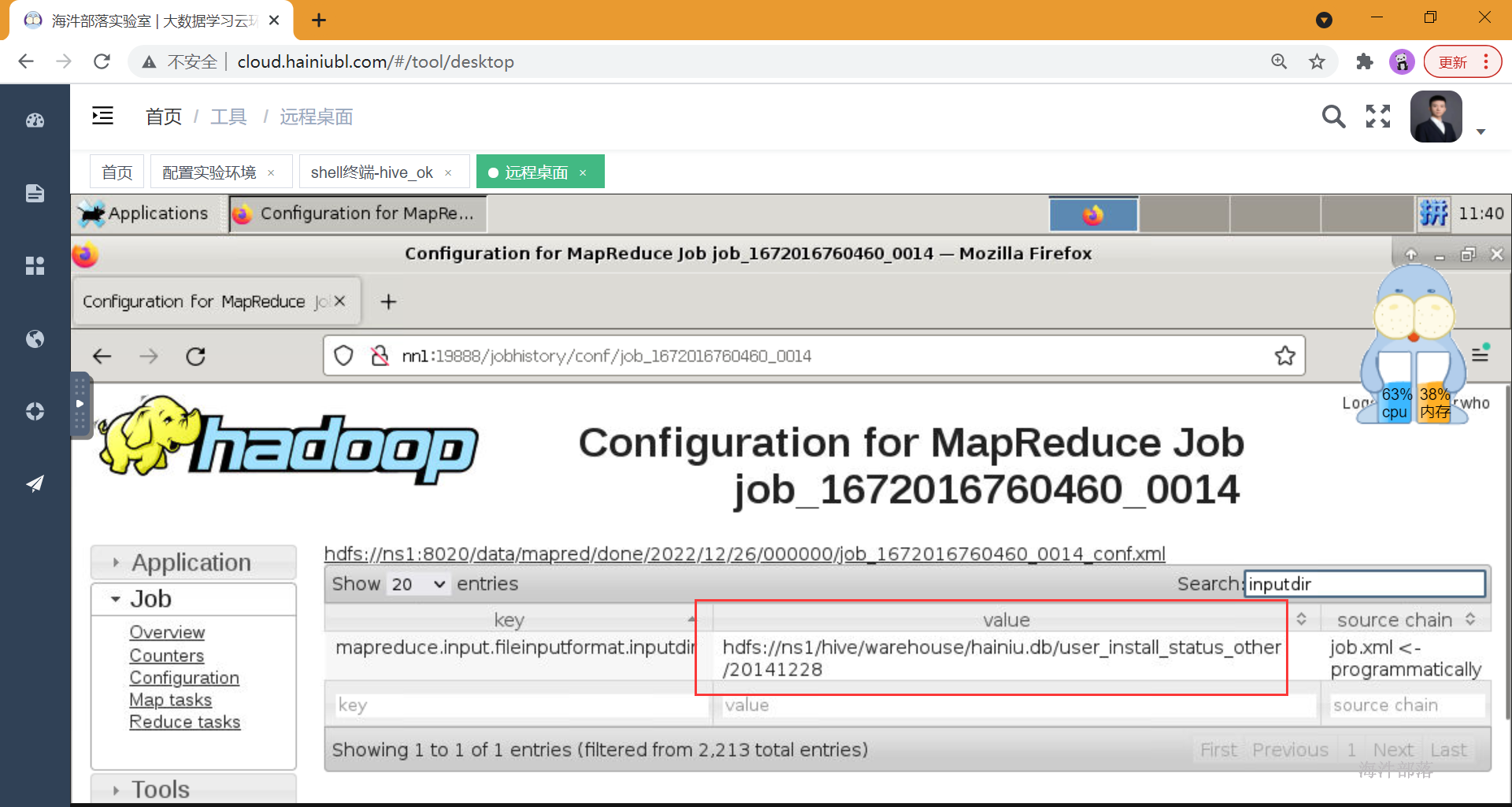
hadoop fs -put -f cz_user_install_data2 /hive/warehouse/hainiu.db/user_install_status_other/20141228对user_install_status_other 表中 20141228分区 的数据按照国家分桶,怎么分合适?
select country, count(*) as num from user_install_status_other where dt='20141228' group by country order by num desc;
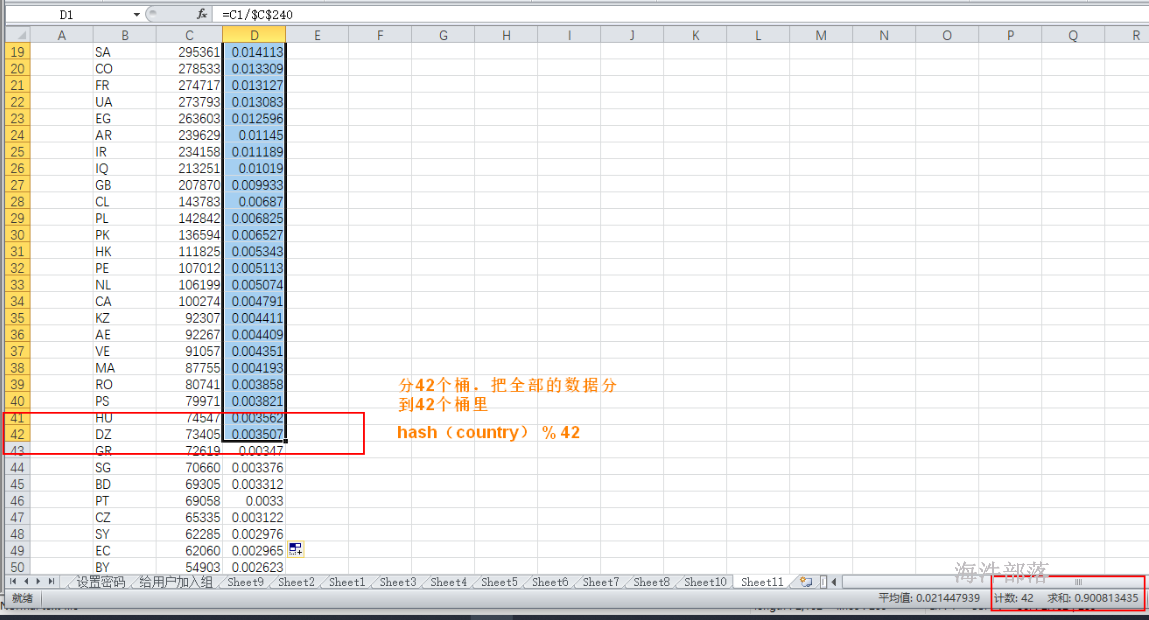
--创建外部表桶表,桶的数量
CREATE EXTERNAL TABLE user_install_status_buckets(
`aid` string,
`pkgname` string,
`uptime` bigint,
`type` int,
`country` string,
`gpcategory` string)
COMMENT 'This is the buckets_table table'
PARTITIONED BY (`dt` string)
CLUSTERED BY(country) SORTED BY(uptime desc) INTO 42 BUCKETS
LOCATION 'hdfs://ns1/user/cz/user_install_status_buckets';
--建partition 分区
alter table user_install_status_buckets add if not exists partition (dt='20141228') location '20141228';
--给分区插入数据
insert overwrite table user_install_status_buckets partition(dt='20141228')
select
aid,
pkgname,
uptime,
type,
country,
gpcategory
from user_install_status_other
where dt='20141228';导入数据时,因为分42个桶,产生42个reduce
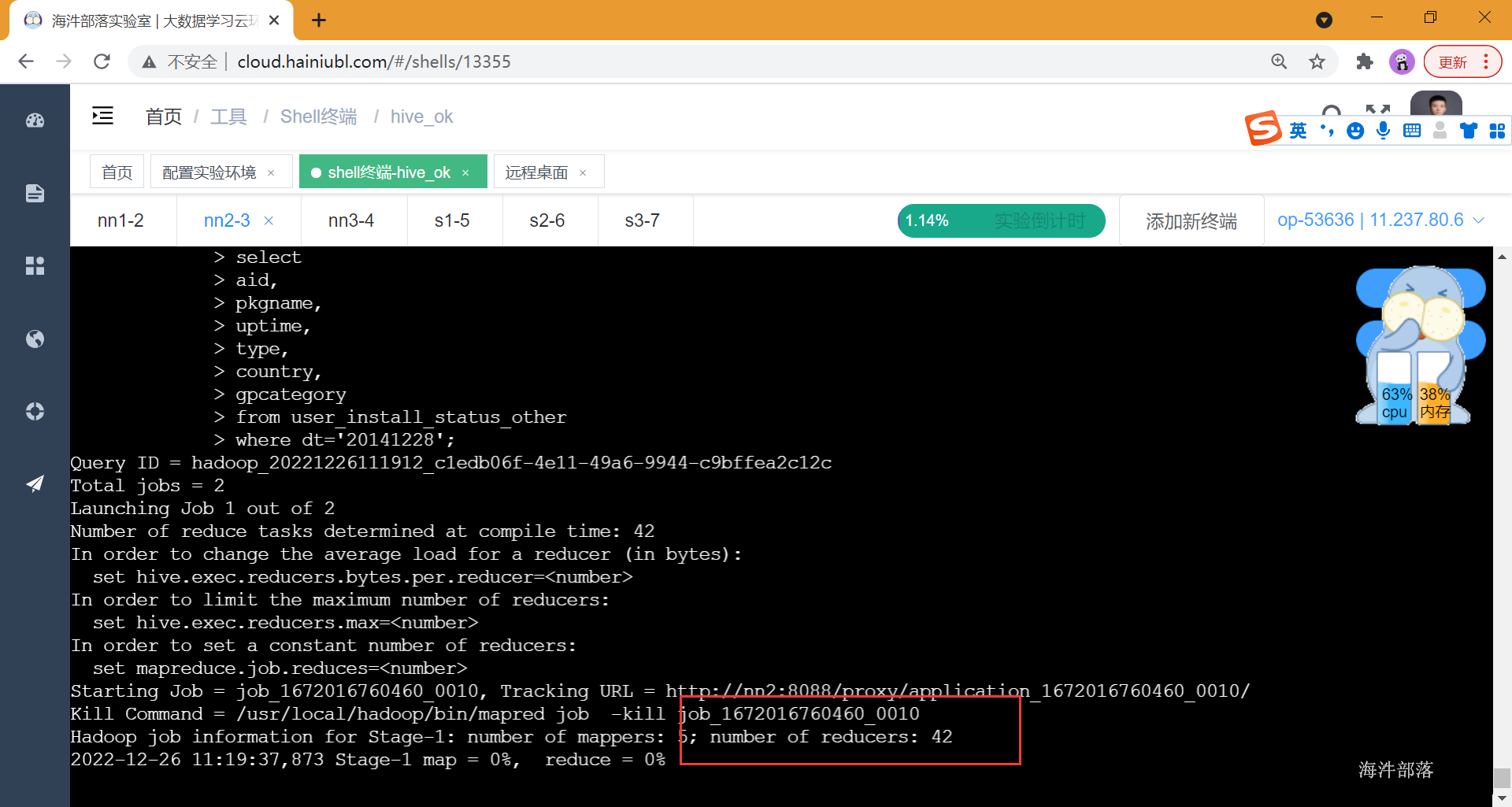
查看表文件,一共42个文件:
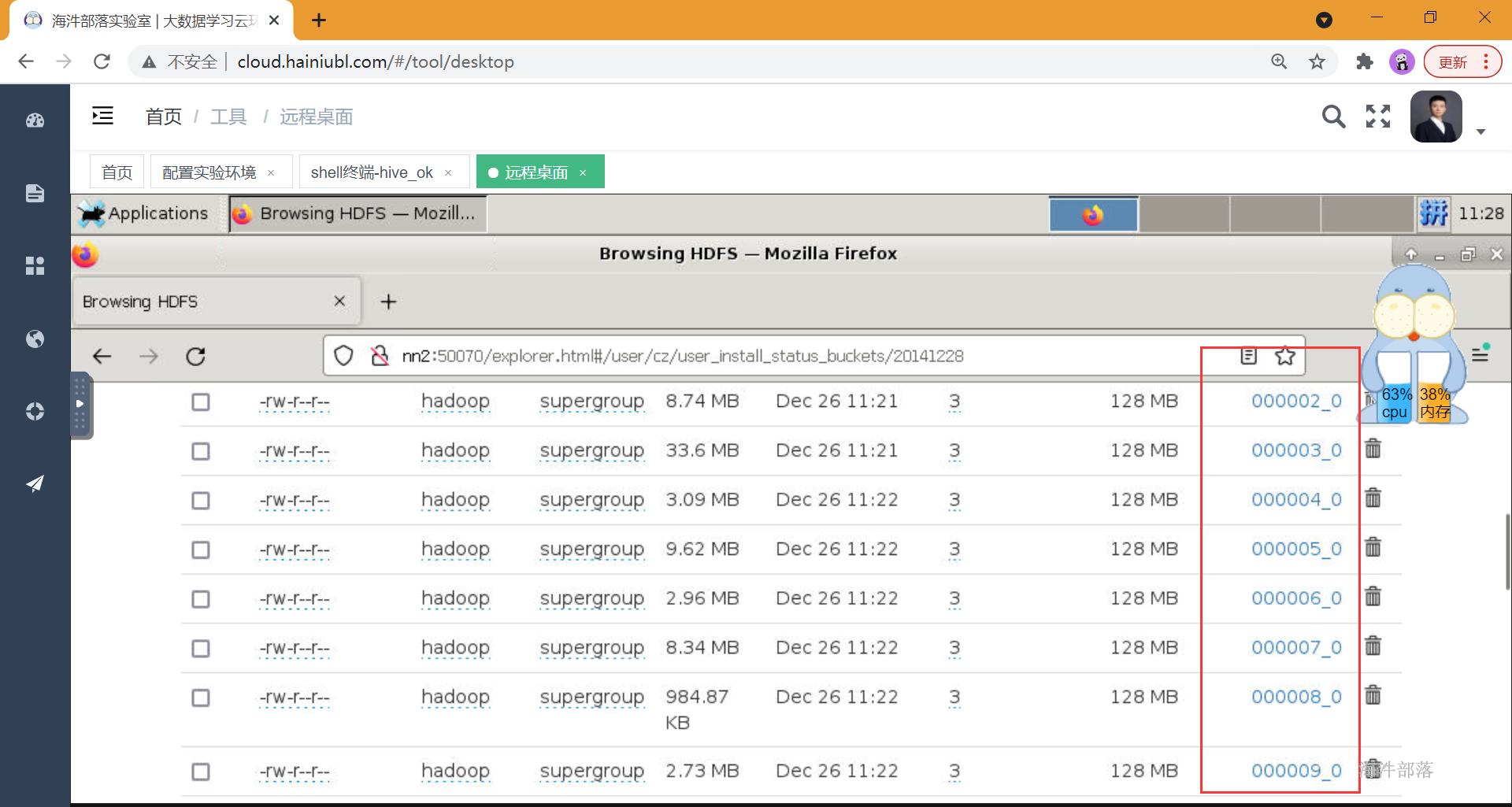
拿个最小的文件查看内部:
文件内部按照uptime 降序排列
hadoop fs -get /user/cz/user_install_status_buckets/20141228/000010_0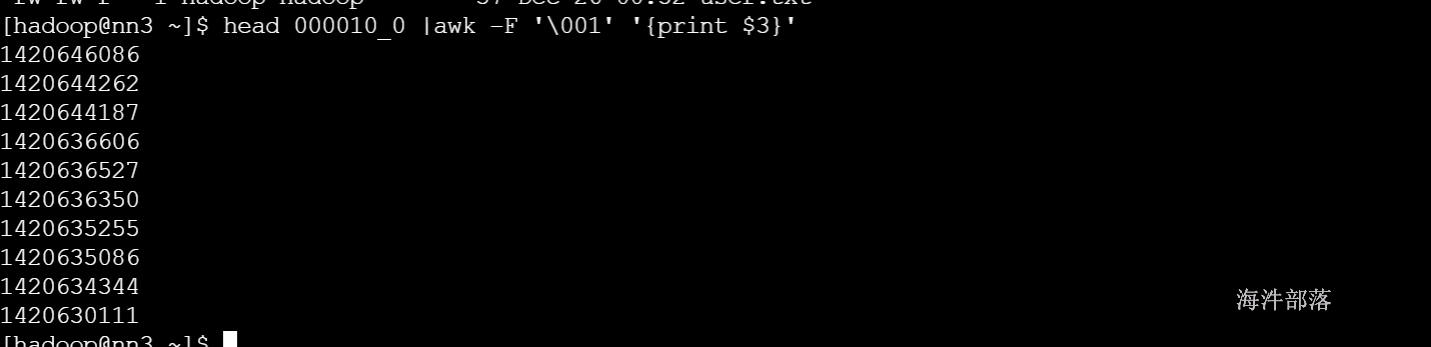
拿GM为例

该文件查看GM条数一样,说明GM都在这个桶里

注意
Hive 0.6.0以前需要设置以下参数,但当前版本不需要设置也可以分桶。
--可以根据bucket的个数的设置reducer的数量
set hive.enforce.bucketing=true;
--有排序的桶需要设置一下
set hive.enforce.sorting=true;4.2.4.2 桶表抽样
当数据量特别大时,对全体数据进行处理存在困难时,抽样就显得尤其重要了。抽样可以从被抽取的数据中估计和推断出整体的特性,是科学实验、质量检验、社会调查普遍采用的一种经济有效的工作和研究方法。
桶表抽样的语法如下:
table_sample: TABLESAMPLE (BUCKET x OUT OF y [ON colname]) 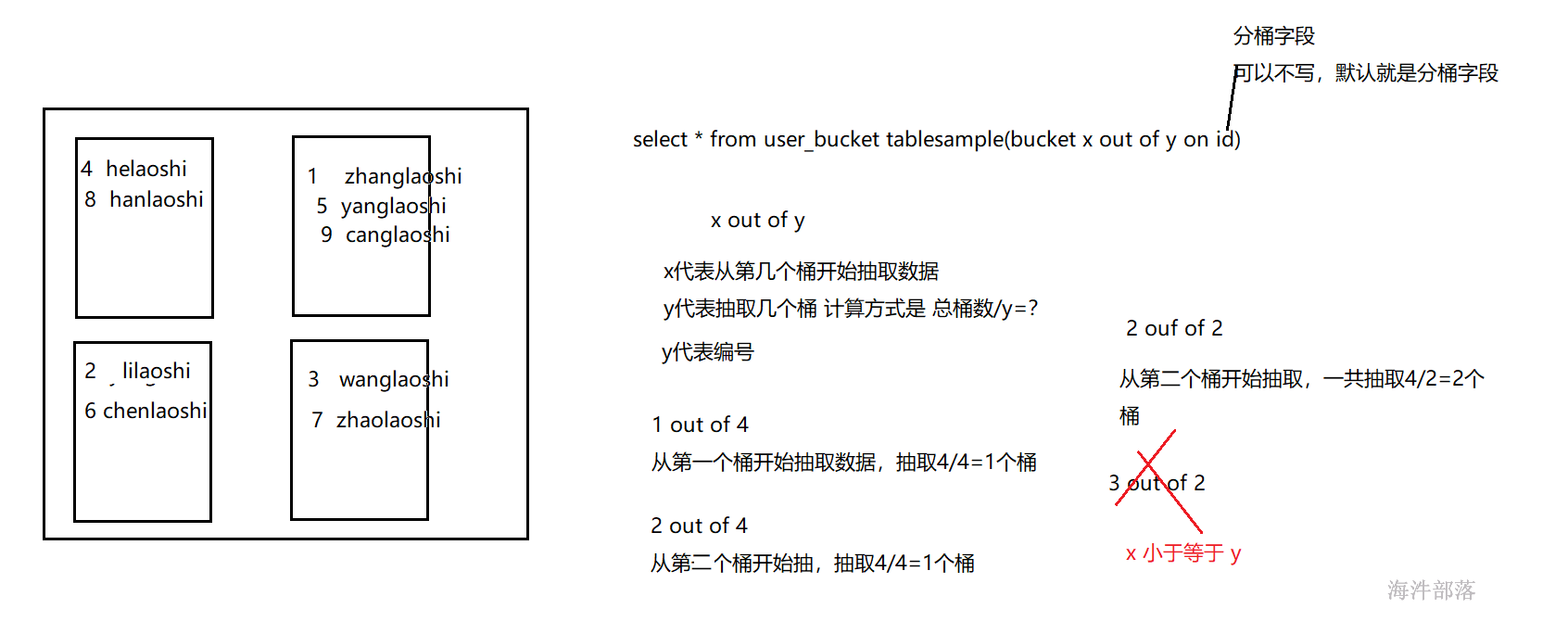
示例:
select * from buckets_table tablesample(bucket 11 out of 42 on country)
桶表抽样,抽指定桶
select count(*) from user_install_status_buckets tablesample(bucket 11 out of 21 on country);
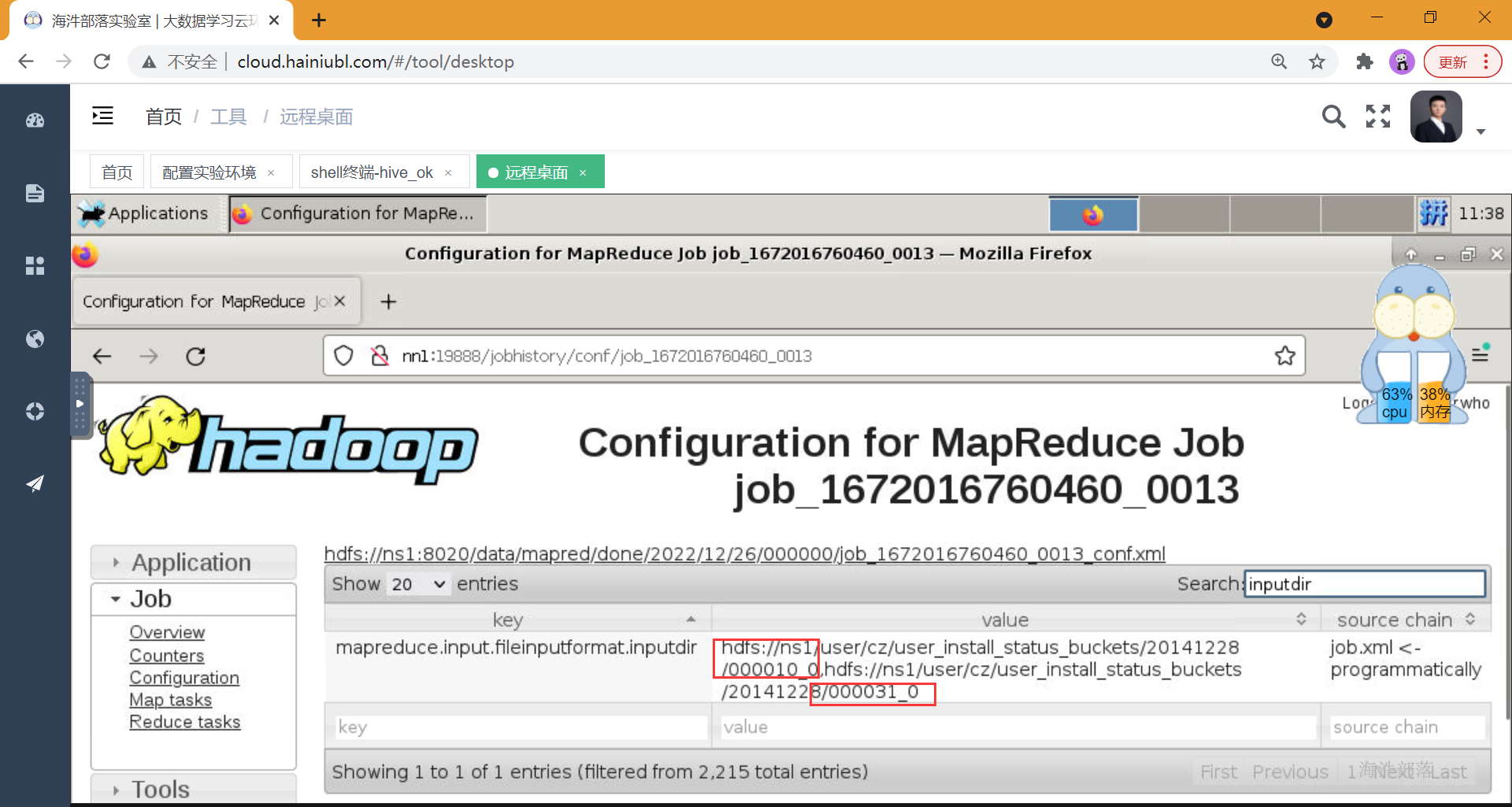
普通表抽样,全盘扫描
select count(*) from user_install_status_other tablesample(bucket 11 out of 42 on country);
结论:
如果桶表分桶字段和抽样字段不一致,扫描全表
如果表不是桶表,抽样扫描全表
如果桶表分桶字段和抽样字段一致,不扫描全表
5 创建AVRO表

schema文件,用json类型表示。
{
"type": "record",
"name": "RunRecord",
"namespace": "com.hainiu",
"fields": [{
"name": "word",
"type": "string"
}, {
"name": "num",
"type": "long"
}
]
}# 将schema文件放到指定的hdfs目录上面
hadoop fs -mkdir /user/cz/config
hadoop fs -put avro.schema /user/cz/config创建avro表
--根据avro.schema.url 对应的目录下的schema文件,创建与文件格式相对应的表结构
CREATE EXTERNAL TABLE IF NOT EXISTS word_avro
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
WITH SERDEPROPERTIES ('avro.schema.url'='/user/cz/config/avro.schema')
STORED AS avro
LOCATION '/user/cz/word_avro';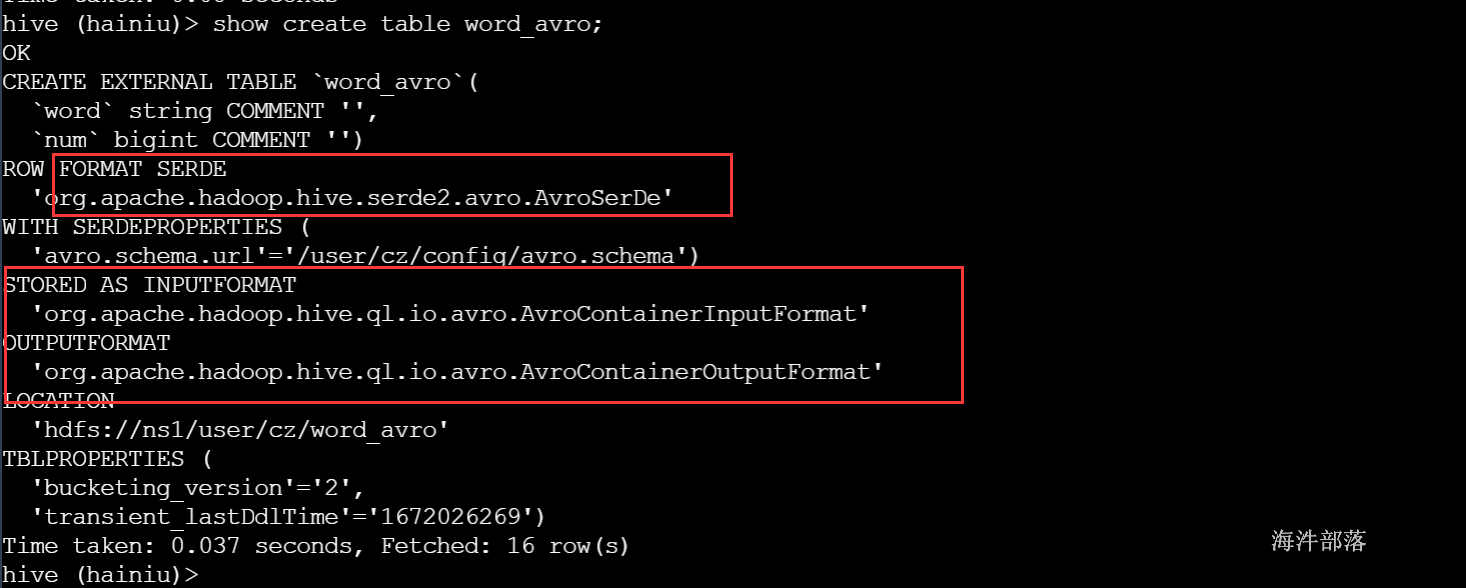
造了一个word_table 表,通过查询word_table 表把数据导入到word_avro 表里
create table word_table(word string, num bigint);导入word_table 表的数据:


-- 导入到 word_avro 表里
insert overwrite table word_avro select word,num from word_table;查询结果:

查看了一下 avro表的文件内容,发现内容是看不懂的数据

修改schema,上传到hdfs,就可以了
{
"type": "record",
"name": "RunRecord",
"namespace": "com.hainiu",
"fields": [{
"name": "word",
"type": "string"
},{
"name": "new_col",
"type": "long",
"default":-1
},{
"name": "num",
"type": "long"
}
]
}增加数据
insert into table word_avro select word,50,num from word_table;
总结:
如果新增字段,需要给新增字段设置默认值,否则查询会报错。
优点:后续数据的字段扩展不影响以前表的使用,或者后续表的修改不影响读取以前的数据。
缺点:数据里面存在冗余的数据,会使数据的文件变的很大。
应用场景:最原始的etl数据使用,因为最原始的数据经常变动结果。使用这种数据格式不受影响。
6 创建orc表
6.1 定义
ORC File,它的全名是Optimized Row Columnar (ORC) file。(有索引有压缩的列式存储格式)据官方文档介绍,这种文件格式可以提供一种高效的方法来存储Hive数据。它的设计目标是来克服Hive其他格式的缺陷。运用ORC File可以提高Hive的读、写以及处理数据的性能。
ORC File格式最主要的优点是在文件中存储了一些轻量级的索引数据。
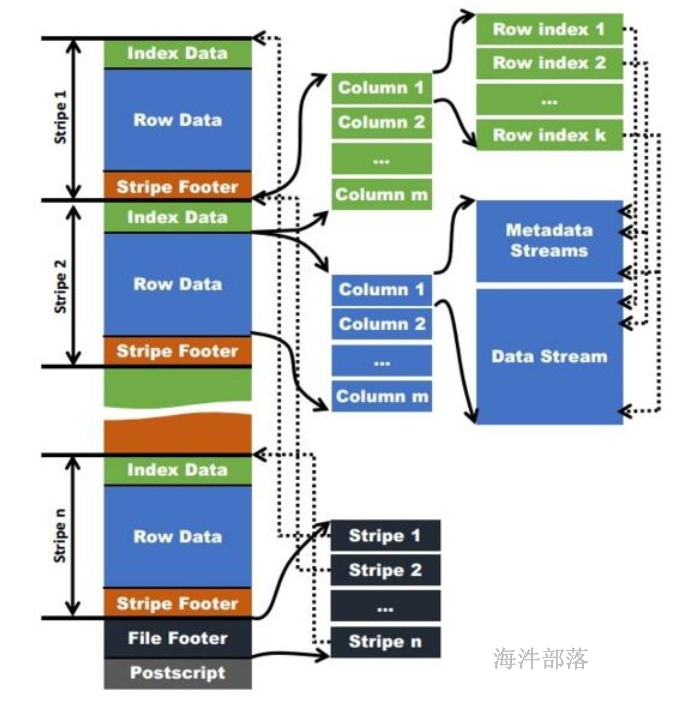
6.2 ORC File文件结构
ORC File包含一组组的行数据,称为stripes,除此之外,ORC File的file footer还包含一些额外的辅助信息。在ORC File文件的最后,有一个被称为postscript的区,它主要是用来存储压缩参数及压缩的大小。在默认情况下,一个stripe的大小为256MB。大尺寸的stripes使得从HDFS读数据更高效。
下图显示出可ORC File文件结构:

其中:
Postscripts中存储该表的行数,压缩参数,压缩大小,列等信息;
FileFooter中包含该表的统计结果,以及各个Stripe的位置信息;
Stripe Footer中包含该stripe的统计结果,包括Max,Min,count等信息;
IndexData中保存了该stripe上数据的位置信息,总行数等信息;
RowData以stream的形式保存了数据的具体信息;
Hive读取数据的时候,根据FileFooter读出Stripe的信息,根据IndexData读出数据的偏移量从而读取出数据。
6.3 Stripe结构
从上图我们可以看出,每个Stripe都包含index data、row data以及stripe footer。Stripe footer包含流位置的目录;Row data在表扫描的时候会用到。
Index data包含每列的最大和最小值以及每列所在的行。行索引里面提供了偏移量,它可以跳到正确的压缩块位置。具有相对频繁的行索引,使得在stripe中快速读取的过程中可以跳过很多行,尽管这个stripe的大小很大。在默认情况下,最大可以跳过10000行。
6.4 ORC类型表与文本类型表的比对
6.4.1 ORC hql 语法及orc文件分析
1)建表 指定 stored as orc
6.4.2 创建ORC表,导入数据
--根据建表语句,创建user_install_status_other表
CREATE EXTERNAL TABLE `user_install_status_other_orc`(
`aid` string COMMENT 'from deserializer',
`pkgname` string COMMENT 'from deserializer',
`uptime` bigint COMMENT 'from deserializer',
`type` int COMMENT 'from deserializer',
`country` string COMMENT 'from deserializer',
`gpcategory` string COMMENT 'from deserializer')
PARTITIONED BY (`dt` string)
STORED AS orc
LOCATION 'hdfs://ns1/user/cz/user_install_status_other_orc'
TBLPROPERTIES ('orc.compress'='SNAPPY', 'orc.create.index'='true');导入数据
--建partition 分区
alter table user_install_status_other_orc add if not exists partition (dt='20141228') location '20141228';
--给分区插入数据
insert overwrite table user_install_status_other_orc partition(dt='20141228')
select
aid,
pkgname,
uptime,
type,
country,
gpcategory
from hainiu.user_install_status_other
where dt='20141228';6.4.3 创建txt格式的表,导入数据
再建一个txt格式的表进行速度对比
--创建user_install_status_txt表
CREATE EXTERNAL TABLE `user_install_status_txt`(
`aid` string,
`pkgname` string,
`uptime` bigint,
`type` int,
`country` string,
`gpcategory` string)
PARTITIONED BY (`dt` string)
STORED AS TEXTFILE
LOCATION 'hdfs://ns1/user/cz/user_install_status_txt';导入数据
--建partition 分区
alter table user_install_status_txt add if not exists partition (dt='20141228') location '20141228';
--给分区插入数据
insert overwrite table user_install_status_txt partition(dt='20141228')
select
aid,
pkgname,
uptime,
type,
country,
gpcategory
from hainiu.user_install_status_other
where dt='20141228';6.4.4 两种类型比较
查询对比
select * from user_install_status_other_orc where dt='20141228' and aid='81af53e9d9247805';

在散列字段上,更能体现ORC结构的查询优势。
因为有索引,可以直接扫描orc文件,不需要执行mapreduce任务。
select * from user_install_status_txt where dt='20141228' and aid='81af53e9d9247805';
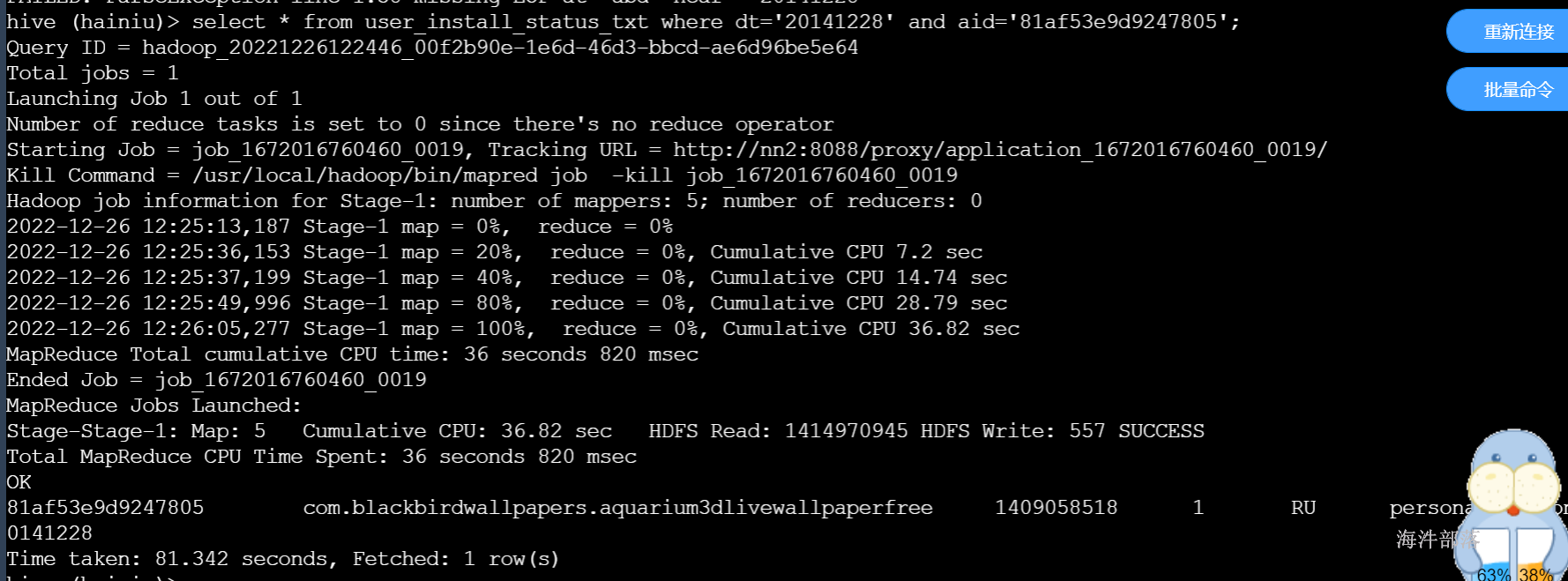
而txt没有索引,需要执行mapreduce任务,找到这条数据。
容量对比

6.4.5 hive可以用hdoop配置的压缩方式
具体参考core-site.xml

如何往textfile 文件中导入压缩格式的文件?
方法1:
-- 1)先设置压缩
--设置hive输出压缩
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
--建表
CREATE EXTERNAL TABLE `user_install_status_gz`(
`aid` string COMMENT 'from deserializer',
`pkgname` string COMMENT 'from deserializer',
`uptime` bigint COMMENT 'from deserializer',
`type` int COMMENT 'from deserializer',
`country` string COMMENT 'from deserializer',
`gpcategory` string COMMENT 'from deserializer')
STORED AS TEXTFILE
LOCATION
'hdfs://ns1/user/cz/user_install_status_gz';
--2)再导入数据
insert overwrite table user_install_status_gz
select
aid,
pkgname,
uptime,
type,
country,
gpcategory
from hainiu.user_install_status_limit;导入数据的结果:

方法2:
CREATE TABLE demo_tab( id int,name string);
--将文本文件,直接用gzip压缩,再上传到表的hdfs目录上。
hadoop fs -put user.gz /hive/warehouse/hainiu.db/demo_tab

7 创建parquet表
Parquet 是面向分析型业务的列式存储格式,由 Twitter 和 Cloudera 合作开发,2015 年 5 月从 Apache 的孵化器里毕业成为 Apache 顶级项目,支持大部分计算框架。
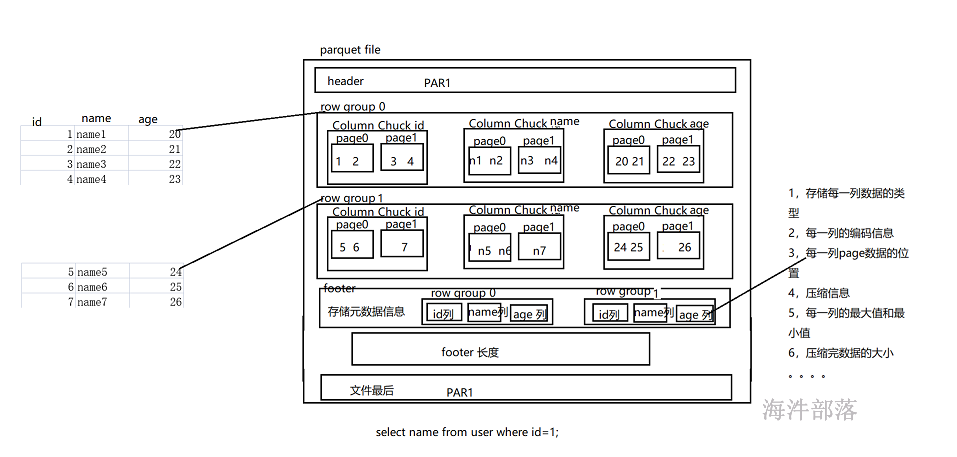
1) Parquet文件由一个文件头(header)就是是该文件的Magic Code,用于校验它是否是一个Parquet文件。
2) 一个或多个紧随其后的行组(Row Group)、Row Group由列块(Column Chuck)、页(Page)组成。
3) 以及一个用于结尾的文件尾(footer)构成。
行组(Row Group):
Parquet 在水平方向上将数据划分为行组,默认行组大小与 HDFS Block 块大小对齐,Parquet 保证一个行组会被一个 Mapper 处理。
列块(Column Chunk):
行组中每一列保存在一个列块中,一个列块具有相同的数据类型,不同的列块可以使用不同的压缩算法。
页(Page):
Parquet 是页存储方式,每一个列块包含多个页,一个页是最小的编码的单位,同一列块的不同页可以使用不同的编码方式。
创建Parquet表
create table if not exists hainiu.word_parquet(word string,num int)
stored as parquet
tblproperties ("parquet.compress"="SNAPPY")导入数据
insert overwrite table hainiu.word_parquet select word,num from word_tmp;
