1 表SQL操作
1.1 通过select数据集创建表
--通过select数据集创建表语法格式
create table table_name [stored as orc]
as
select ......只能是内部表,不支持分区,分桶
示例:
--创建内部表inner_test1
create table inner_test1 as select word,num from word_table;
--查看
select * from inner_test1;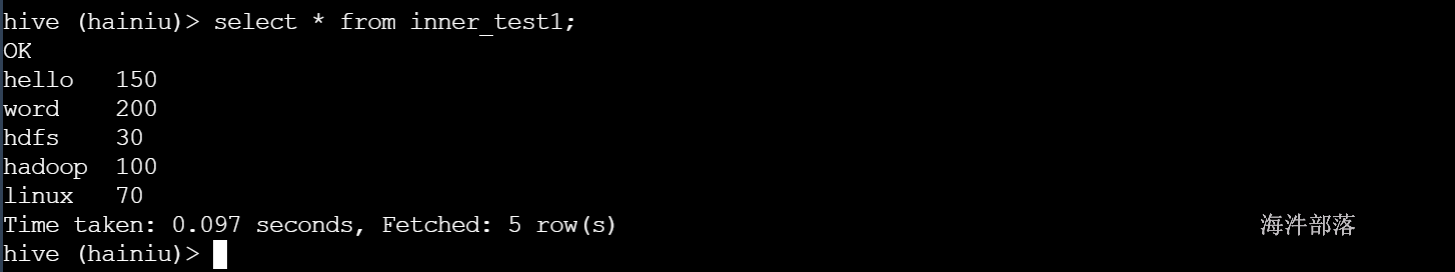
1.2 复制一个空表
--只复制表结构,不复制表数据
CREATE TABLE tabname LIKE tablename;create table inner_test2 like inner_test1;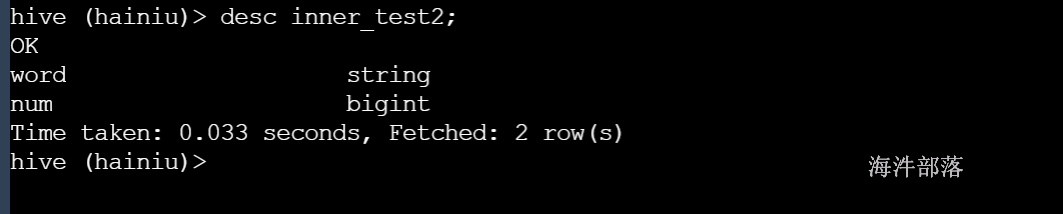
也可以复制分区表
create table inner_test3 like student_par;
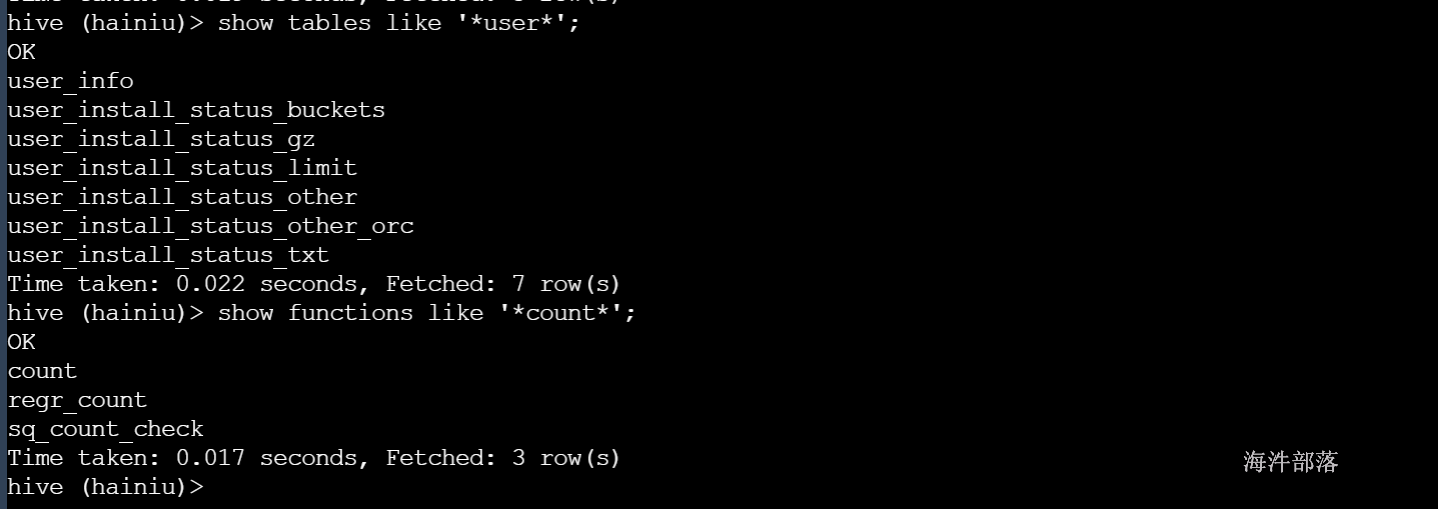
1.3 显示表列表
--显示所有表
SHOW TABLES;
-- 最通用的写法
show tables like '*user*';
-- 显示函数
show fuctions like '*count*';结果显示
1.4 删除表
--删除表
DROP TABLE [IF EXISTS] table_name [PURGE]; 说明:
1)对于内部表来说,删除表的操作的本质是删除表的元数据,然后hadoop fs -rm(将表数据挪到回收站目录, .Trash/Current)。
2)如果增加PURGE则不进回收站数据直接删除,不能恢复;
3)对外部表而言只删除元数据, 不删除数据目录,加PURGE也不删。
示例:
drop table inner_test1;
对于外部表:
drop table book purge;
1.5 清除表(只针对内部表)
--清除表
TRUNCATE TABLE table_name [PARTITION partition_spec];说明:
1)可以删除表和删除分区数据,和drop的区别是不删除元数据(表结构),只删除数据,外部表是不能truncate操作的。

2)外部表不支持使用TRUNCATE语句。

1.6 常用修改表操作

1.6.1 改表名
--改表名
ALTER TABLE table_name RENAME TO new_table_name;
--内部表修改表名
ALTER TABLE user_info RENAME TO user_info_2;
--外部表修改表名
alter table ext_test rename to ext_test_2;说明:
内部表修改了表名之后,表对应的存储文件地址也跟着改,相当于作了HDFS的目录重命名。
外部表不会改对应的location地址。
示例:
-- 分区表外部表
CREATE EXTERNAL TABLE ext_test(
word STRING,
num INT
)
PARTITIONED BY (taskname STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/user/cz/ext_test';
-- 分区表内部表
CREATE TABLE inner_test(
word STRING,
num INT
)
PARTITIONED BY (taskname STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';hdfs路径:
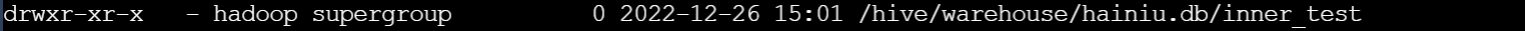
内部表重命名
ALTER TABLE inner_test RENAME TO inner_test_c;hdfs 作了目录重命名
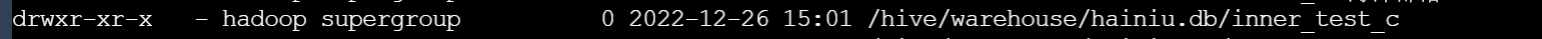
外部表重命名
外部表hdfs位置:

ALTER TABLE ext_test RENAME TO ext_test_c;hdfs位置没有发生变化
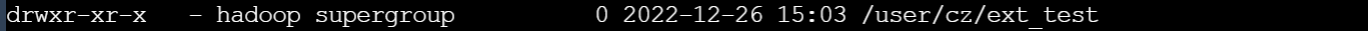
1.6.2 增加表分区
内部表增加表分区,自动创建目录。
外部表增加表分区,自动创建目录。
示例:
1)创建分区表:
-- 分区表外部表
CREATE EXTERNAL TABLE ext_task(
word STRING,
num INT
)
PARTITIONED BY (taskname STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/user/cz/hive46/ext_task';
-- 分区表内部表
CREATE TABLE inner_task(
word STRING,
num INT
)
PARTITIONED BY (taskname STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';2)添加表分区
-- 分区表外部表添加分区
alter table ext_task add IF NOT EXISTS partition(taskname='wordcount') location 'wordcount';
alter table ext_task add IF NOT EXISTS partition(taskname='maxword') location 'maxword';
alter table ext_task add IF NOT EXISTS partition(taskname='sortword') location 'sortword';
-- 分区表内部表添加分区
alter table inner_task add IF NOT EXISTS partition(taskname='wordcount') location 'wordcount';
alter table inner_task add IF NOT EXISTS partition(taskname='maxword') location 'maxword';
alter table inner_task add IF NOT EXISTS partition(taskname='sortword') location 'sortword';分区目录在添加分区时自动创建
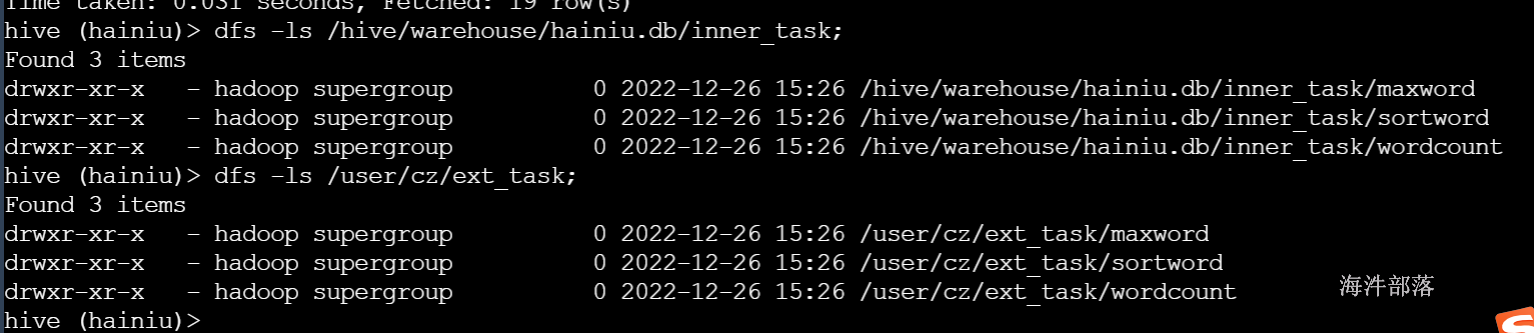
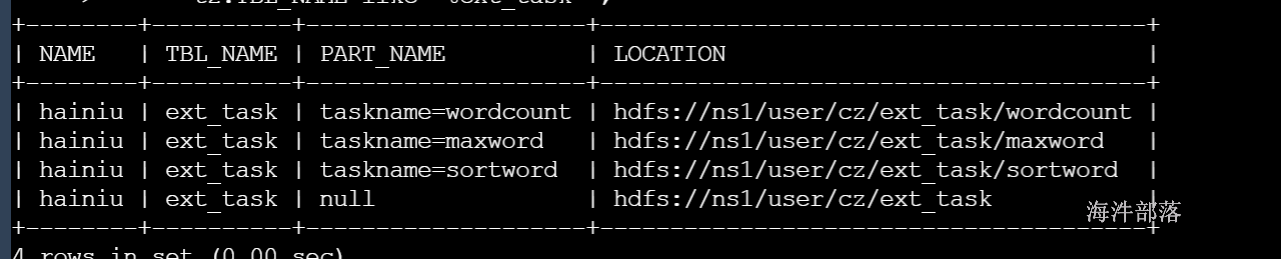
3)查看表的元数据和表分区元数据
-- 查询具体表的分区目录
select t1.`NAME`, t2.TBL_NAME,t4.PART_NAME, t3.LOCATION from DBS t1, TBLS t2 , SDS t3 , `PARTITIONS` t4
where t1.DB_ID=t2.DB_ID and
t4.SD_ID = t3.SD_ID AND
t2.TBL_ID = t4.TBL_ID and
t1.`NAME` = 'hainiu' AND
t2.TBL_NAME like '%ext_task'
UNION
-- 查询具体表的目录
select t1.`NAME`, t2.TBL_NAME,'null', t3.LOCATION from DBS t1, TBLS t2 , SDS t3
where t1.DB_ID=t2.DB_ID and
t2.SD_ID = t3.SD_ID AND
t1.`NAME` = 'hainiu' AND
t2.TBL_NAME like '%ext_task' ;
1.6.4 删除分区
--删除表分区的语法格式
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec[, PARTITION partition_spec, ...];说明:
内部表删除分区,同时删除分区对应的目录。
外部表删除分区不删除分区对应的目录。
示例:
-- 内部表删除分区
alter table inner_task DROP IF EXISTS partition(taskname='sortword');
-- 外部表删除分区
alter table ext_task DROP IF EXISTS partition(taskname='sortword');内部表删除:sortword 分区
元数据删除:

数据也删除:

外部表删除:sortword 分区
元数据删除

数据没删除:

1.6.5 修改表或分区的路径
--修改表或分区路径的语法格式
ALTER TABLE table_name [PARTITION partition_spec] SET LOCATION "new location";说明:
内部表修改分区路径,元数据修改,但hdfs目录没有创建,等导入数据时创建,或者自己主动创建。
外部表修改分区路径,元数据修改,但hdfs目录没有创建,等导入数据时创建,或者自己主动创建。
示例:
--内部表修改分区路径
alter table inner_task PARTITION (taskname='wordcount') set location "hdfs://ns1/hive/warehouse/hainiu.db/inner_task/wordcount1";
--外部表修改分区路径
alter table ext_task PARTITION (taskname='wordcount') set location "hdfs://ns1/user/cz/ext_task/wordcount1";内部表:
修改分区路径:

导入数据后
insert into table inner_task partition(taskname='wordcount') select * from word_table;
-----------------------------
外部表:
修改分区路径:

导入数据后:
insert into table ext_task partition(taskname='wordcount') select * from word_table;
结论:无论是外部表还是内部表,修改分区路径,需要自己手动创建路径,或者等导入数据时创建。
1.6.6 分区重命名
--分区重命名语法格式
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;说明:
如果是内部表,分区重命名,分区对应的地址也会跟着改变,外部表不会。
示例:
--内部表分区重命名会改变分区对应的地址
alter table inner_task partition (taskname='maxword') rename to partition (taskname='maxword01');
--外部表分区重命名不会改变分区对应的地址
alter table ext_task partition (taskname='maxword') rename to partition (taskname='maxword01');内部表修改分区名称,hdfs目录也修改

hdfs目录名称也修改

外部表修改分区名称,只修改元数据


insert into table ext_task partition(taskname='maxword01')
select word,num from word_table;maxword01分区导入数据后

1.6.7 增加表字段
--增加表字段、使用新列集合替换现有数据列的语法格式
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)说明:
1)ADD COLUMNS 可以在表列的最后和分区字段前面增加字段。
示例:
1)增加表字段
alter table ext_test add columns (test_col string);
导入数据
insert into table ext_test_c partition(taskname='wordcount') select word,num, 'aaa' from word_table;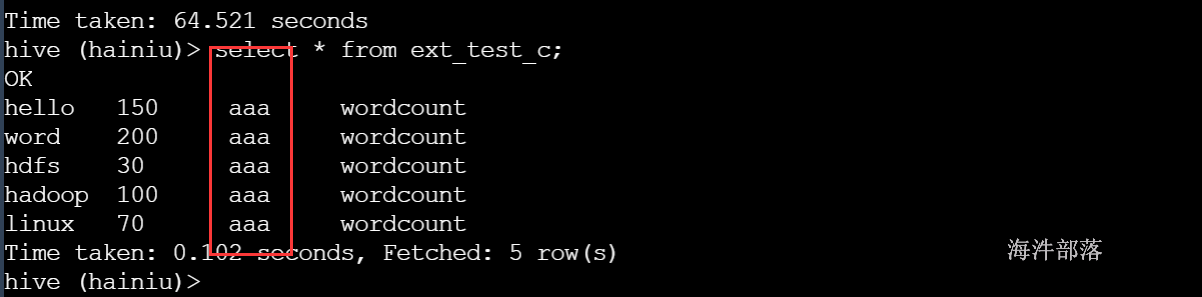
1.6.8 修改表字段
--语法格式
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name] 示例:
alter table ext_test_c CHANGE COLUMN test_col test_col_new string;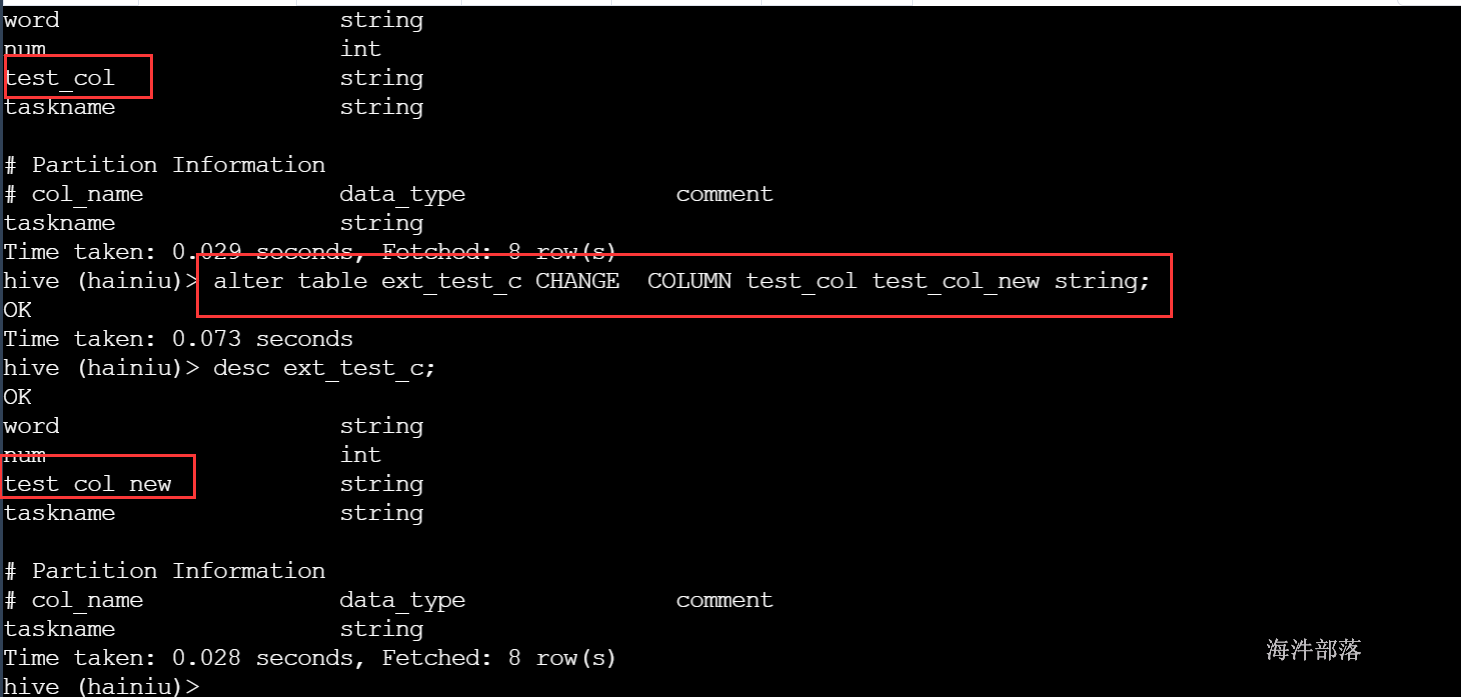
3 数据加载
3.1 load 加载数据
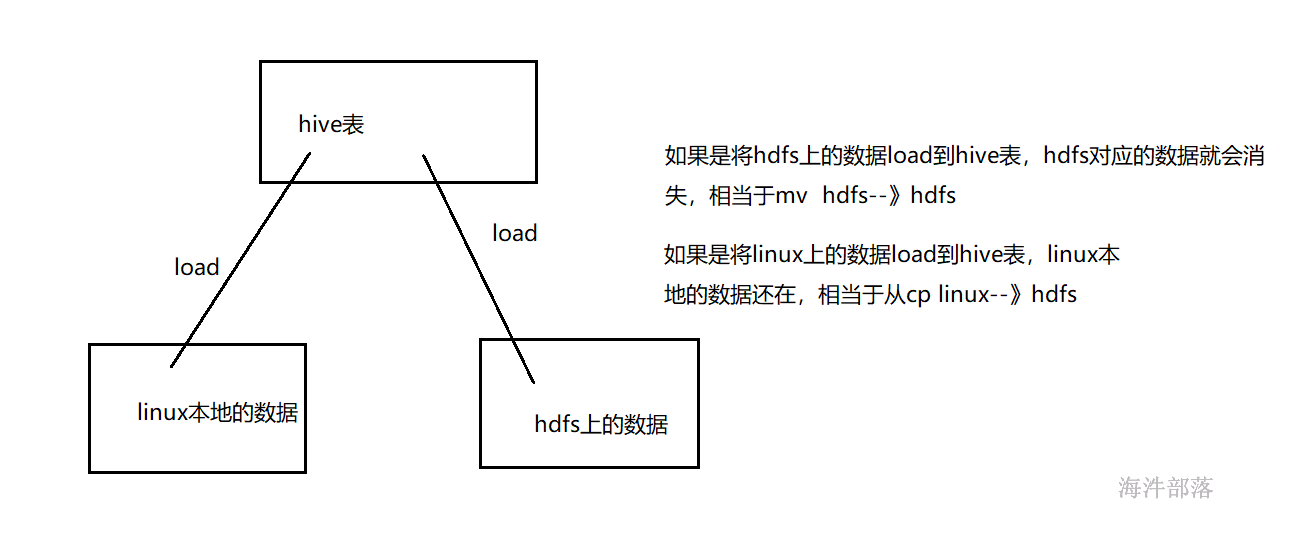
向表添加数据除了可以使用insert语法(不推荐),还可以用hadoop put的方式向表中添加数据。
当然还有一种比较简单的用法就是可以直接通过load的方式加载数据。
3.1.1 语法
--load数据加载语法格式
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]说明:
1)hive 的数据加载不会对本地数据文件做任何处理,只是将文件或目录中的所有文件拷贝到表定义的数据目录,分桶表使用load加载数据会生成mapreduce任务,将数据分到多个桶文件进行存放
2)指定local本地文件上传,如果没有指定local,则是从hdfs上传数据。
3)文件加载hive没有做严格校验,文件格式和压缩选项等匹配需要用户自己保证。
4)分区表要指定具体加载数据分区。
5)如果指定OVERWRITE会覆盖相应表数据或分区数据,相当于 rm 原有目录数据,然后上传新数据文件
-- 以覆盖或追加的方式 , 从linux本地 copy文件到表或表分区里
LOAD DATA LOCAL INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
--以覆盖或追加的方式 , 从hdfs move 文件到表或表分区里
LOAD DATA INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]3.1.2 将hdfs中的文件load到表中(move)
需要把 ext_task1 创建出来
-- 分区表外部表
CREATE EXTERNAL TABLE ext_task1(
word STRING,
num INT
)
PARTITIONED BY (taskname STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/user/cz/ext_task1';1)先创建分区wordcount1
-- 创建分区
alter table ext_task1 add if not exists partition (taskname='wordcount') location 'wordcount';2)再load数据到表分区wordcount中
-- 将数据放到hdfs
hadoop fs -put word /user/cz
--加载hdfs上的数据到表的分区中
load data INPATH '/user/cz/word' overwrite into table ext_task1 PARTITION (taskname='wordcount'); 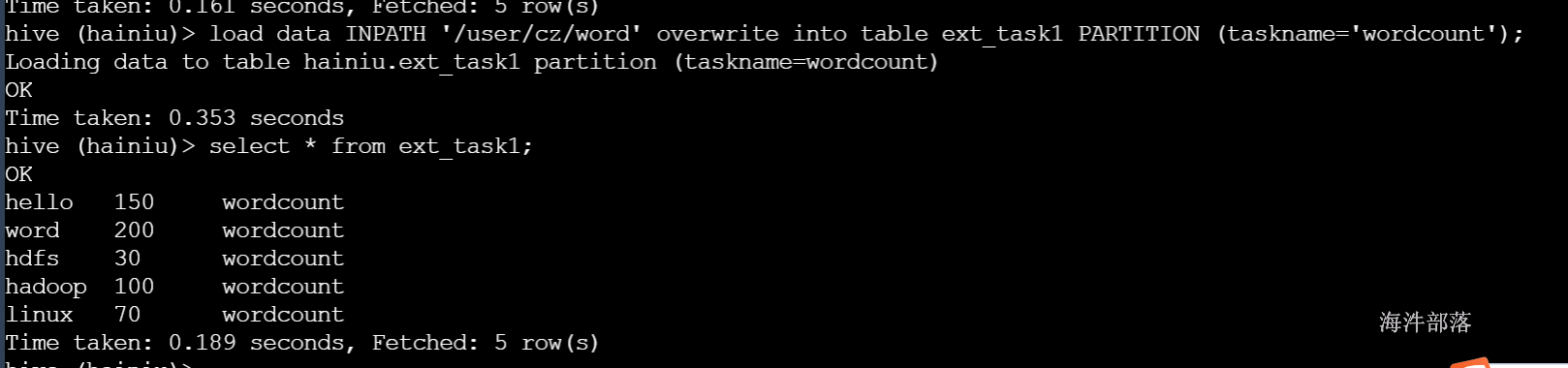
/user/cz这个目录,word文件已经mv走了


如果没有创建分区 wordcount01, load时,会自动创建分区目录,目录名为taskname=wordcount01
-- 将数据放到hdfs
hadoop fs -put word /user/cz分区没有提前创建的时候,load时会自动创建
load data INPATH '/user/cz/word' overwrite into table ext_task1 PARTITION (taskname='wordcount01'); 
也可以使用into导入,into导入时相当于追加数据
load data INPATH '/user/cz/word' into table ext_task1 PARTITION (taskname='wordcount01'); 
3.1.3 将本地文件load到表中
--添加partition
alter table ext_task1 add IF NOT EXISTS partition(taskname='wordcount02') location 'wordcount02';
--本地文件load到表中,相当于将本地文件上传到hdfs中,本地文件不删除
load data local INPATH '/home/hadoop/word' overwrite into table ext_task1 PARTITION (taskname='wordcount02'); 注意:从本地load数据到表的时候,如果用的是overwrite,会帮我们创建一个分区目录,并将数据上传到新创建的目录下

并且linux本地的数据不会消失
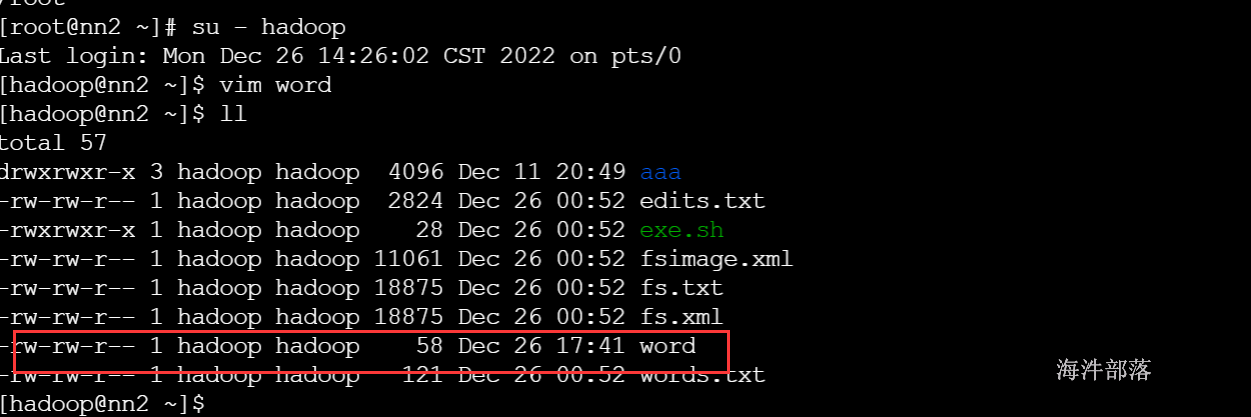
load data local INPATH '/home/hadoop/word' into table ext_task1 PARTITION (taskname='wordcount02'); 追加导入的方式
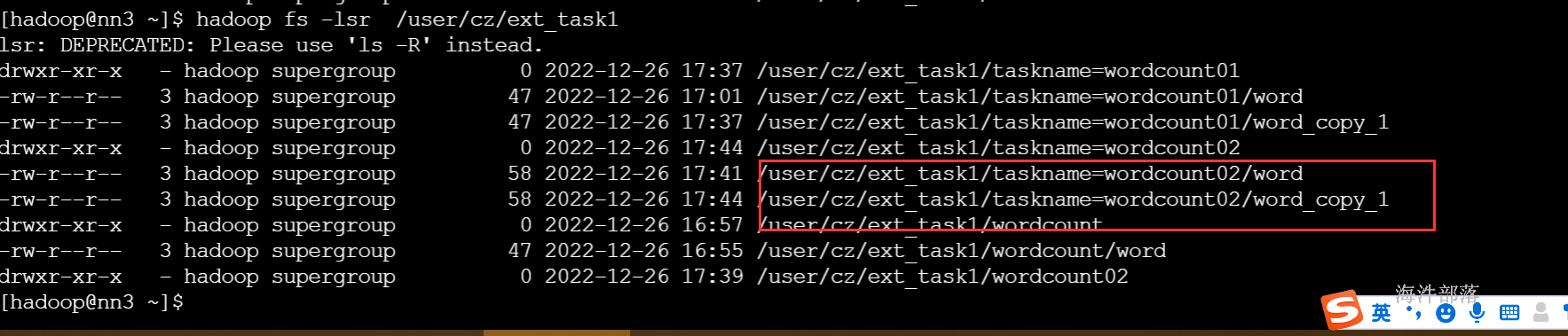
推荐使用从hdfs的方式导入数据
3.2 通过select加载数据

我们还可以通过查询一张表的数据,将查询出来的数据导入另一张表
--通过select,将select数据覆盖表或分区的语法格式
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]]
select_statement1 FROM from_statement;
--通过select,将select数据追加到表或分区的语法格式
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)]
select_statement1 FROM from_statement;说明:
1)当加了 IF NOT EXISTS,如果存在分区就跳过下面的select语句。
2)INSERT OVERWRITE 会覆盖表或分区数据,但覆盖分区时增加IF NOT EXISTS,如果分区已经存在则不会覆盖。
3) INSERT INTO 向表或分区追加数据,不影响历史数据。
示例:
1)将select的数据覆盖到表分区
--添加分区
alter table ext_task1 add IF NOT EXISTS partition(taskname='wordcount03') location 'wordcount03';
--导入数据
insert overwrite table ext_task1 partition(taskname='wordcount03')
select
word,
num
from word_table;
2)通过select,将select数据追加到表分区
insert into table ext_task1 partition(taskname='wordcount03')
select
word,
num
from word_table;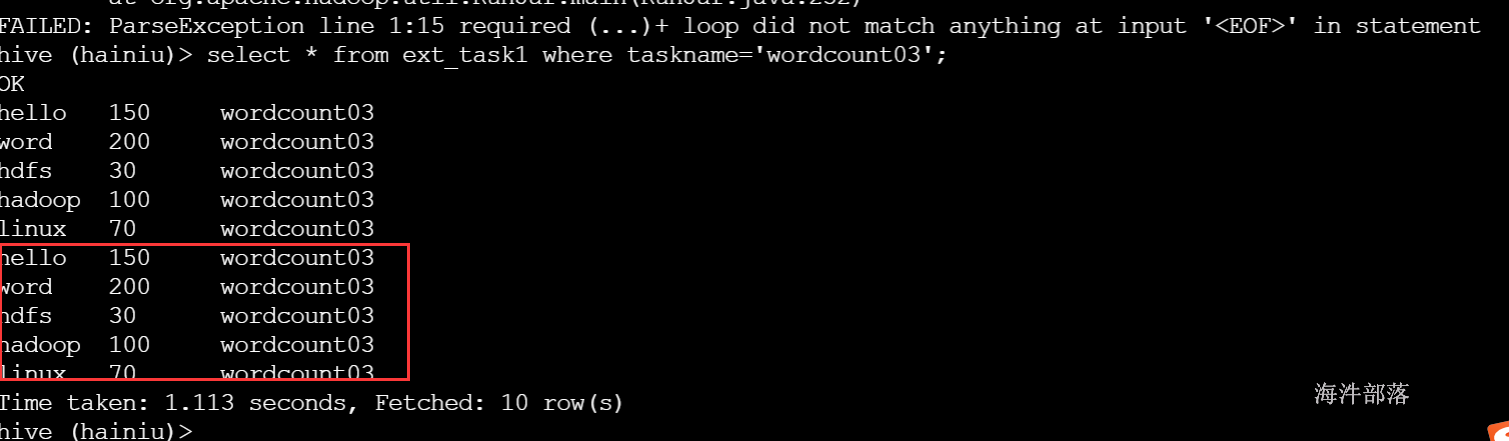
3.3 动态分区
如果有这样一个需求,从一张不是分区表中查询数据导入到分区表中。如果分区的个数比较多的时候,就需要我们多次查询导入,比如下面这个例子:
-- 学生表
CREATE TABLE student(
id int,
name string,
age int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 学生表数据
1 name1 12
2 name2 12
3 name3 13
4 name4 13
5 name5 14
6 name6 14
7 name7 15
8 name8 15
-- 学生分区表
CREATE TABLE student_dyna(
id int,
name string
)
partitioned by (age int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 需求:把学生表的数据导入的学生分区表中
-- 静态分区导入 适合增量数据的处理
-- 添加12岁的分区,导入12岁数据
alter table student_dyna add IF NOT EXISTS partition(age=12) location '12';
insert overwrite table student_dyna partition(age=12)
select id,name from student where age=12;
-- 添加13岁的分区,导入13岁数据
alter table student_dyna add IF NOT EXISTS partition(age=13) location '13';
insert overwrite table student_dyna partition(age=13)
select id,name from student where age=13;
-- 添加14岁的分区,导入14岁数据
alter table student_dyna add IF NOT EXISTS partition(age=14) location '14';
insert overwrite table student_dyna partition(age=14)
select id,name from student where age=14;
-- 添加15岁的分区,导入15岁数据
alter table student_dyna add IF NOT EXISTS partition(age=15) location '15';
insert overwrite table student_dyna partition(age=15)
select id,name from student where age=15;
------------------------
-- 历史数据导入,不适合静态分区,需要要用动态分区
-- hive默认不开启动态分区
--开启动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table student_dyna partition (age)
select id, name, age FROM student; Hive默认是静态分区,我们在插入数据的时候要手动设置分区,如果源数据量很大的时候,那么针对一个分区就要写一个insert,比如说,有很多我们日志数据,我们要按日期作为分区字段,在插入数据的时候手动去添加分区,那样太麻烦。因此,Hive提供了动态分区,动态分区简化了我们插入数据时的繁琐操作。
--设置参数动态分区
--开启动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
------------------------------------------------------------------------
--表示每个节点生成动态分区的最大个数,默认是100
set hive.exec.max.dynamic.partitions.pernode=10000;
--表示一个DML操作可以创建的最大动态分区数,默认是1000
set hive.exec.max.dynamic.partitions=100000;
--表示一个DML操作可以创建的最大文件数,默认是100000
set hive.exec.max.created.files=150000
--将select数据,覆盖到表的动态分区
insert overwrite table table1 partition (ds, hr)
select key, value, ds, hr FROM table2 WHERE ds is not null;建议不将表的所有字段做全分区字段,建议指明分区名,然后再插入数据。
动态分区:分区 字段值必须是有限,可控的。
应用场景:已经有表,然后,有需求需要把原来表按照某个字段进行分区统计时,导入时,可以 开启动态分区一次性导入数据。

4 将数据写入文件系统
4.1 将数据写入一个文件
查询表数据导出到某个文件【linux本地/ hdfs】
--语法格式
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...示例:
1)将select的数据写入到hdfs文件中,多层目录会帮你创建
-- 查询ext_task 表中分区为wordcount 的数据,以AVRO 格式写入到hdfs指定目录
insert overwrite directory 'hdfs://ns1/user/cz/export_data/d1_avro' STORED AS AVRO
select word, num from ext_task where taskname='wordcount';
2)将select的数据写入到本地文件中, 多层目录会自动帮你创建
-- 查询ext_task 表中分区为wordcount 的数据,以text 格式写入到本地目录中
insert overwrite local directory '/home/hadoop/hive_test/d1_text'
select word, num from ext_task where taskname='wordcount';
4.2 将数据写入多个文件
--语法格式
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 row_format
select_statement1 where
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 row_format
select_statement2 where
说明:
1)导出到文件系统的数据都序列化成text,非原始类型字段会序列化成json,导出文件以^A分隔 \n结尾的文本数据。
2)INSERT OVERWRITE 到HDFS目录,可以通过MR job实现并行写入。这样在集群上抽取数据不仅速度快,而且还很方便。
3)批量导出多个文件,需要导出文件的类型一致,如果一个是avro,一个是text,报错。
示例:
从一张表中导出两个文件到不同的路径
无论是否是分区表:如果多个输出目录,导出的格式要相同,否则报错
from ext_task1
insert overwrite directory 'hdfs://ns1/user/cz/output_avro4' STORED AS orc
select
word,
num
where taskname='wordcount01'
insert overwrite local directory '/home/hadoop/hive_test/output_avro4' STORED AS orc
select
word,
num
where taskname='wordcount02' ;
如果多个输出目录,导出的格式不同,会报错。
报错例子:
from student
insert overwrite directory 'hdfs://ns1/user/cz/hive/output_avro5' STORED AS AVRO
select
id,name
where age=12
insert overwrite local directory '/home/hadoop/hive_test/0403/output_avro4' STORED AS orc
select
id,name
where age=13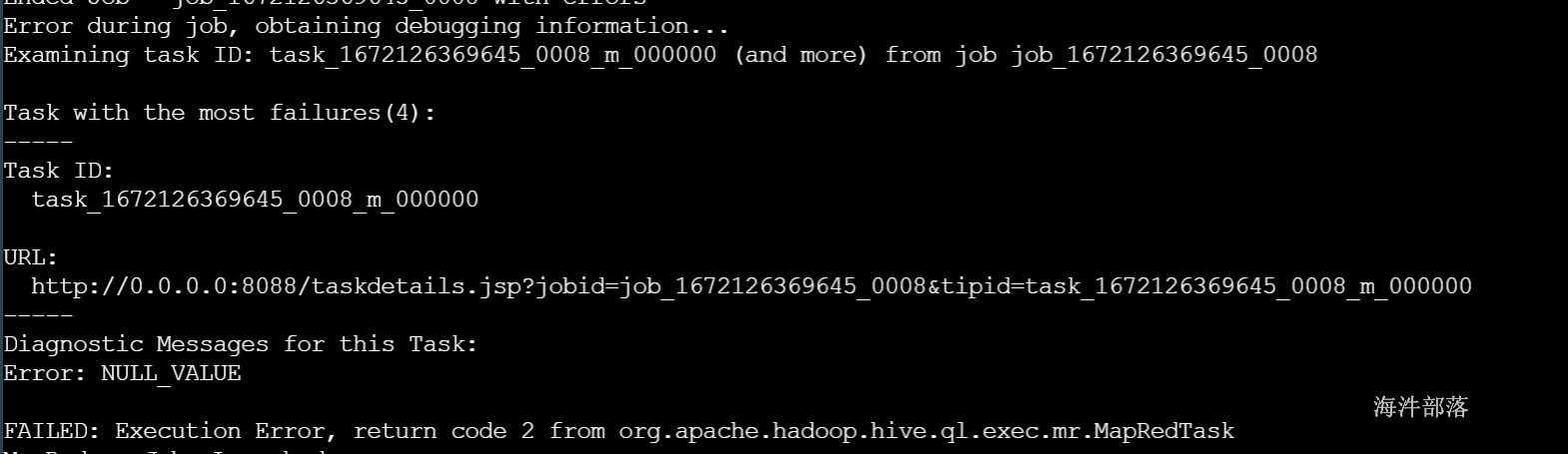
4.3 hive -e 执行命令 导出
-- 导出数据
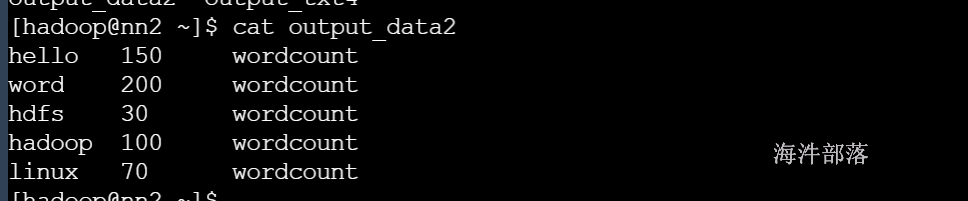
hive -e "use hainiu;select word,num from ext_task where taskname='wordcount';" > ./output_txt4
-- 后台运行,关心错误信息,输出到某个文件里
nohup hive -e "use hainiu;select word,num from ext_task where taskname='wordcount';" 1> ./output_txt5 2>./err.log &
-- 后台运行,错误信息不关心,放到无底洞里
nohup hive -e "use hainiu;select word,num from ext_task where taskname='wordcount';" 1> ./output_txt6 2>/dev/null &
4.4 hive -f 执行SQL文件 导出
[hadoop@op 03]$ vim hivesql.sql
use hainiu; select * from ext_task where taskname='wordcount';
hive -f hivesql.sql > output_data2